
A Machine Learning Approach in Analyzing Bioaccumulation of Heavy Metals in Turbot Tissues

 ,
, 

Abstract
:
1. Introduction
2. Results and Discussion
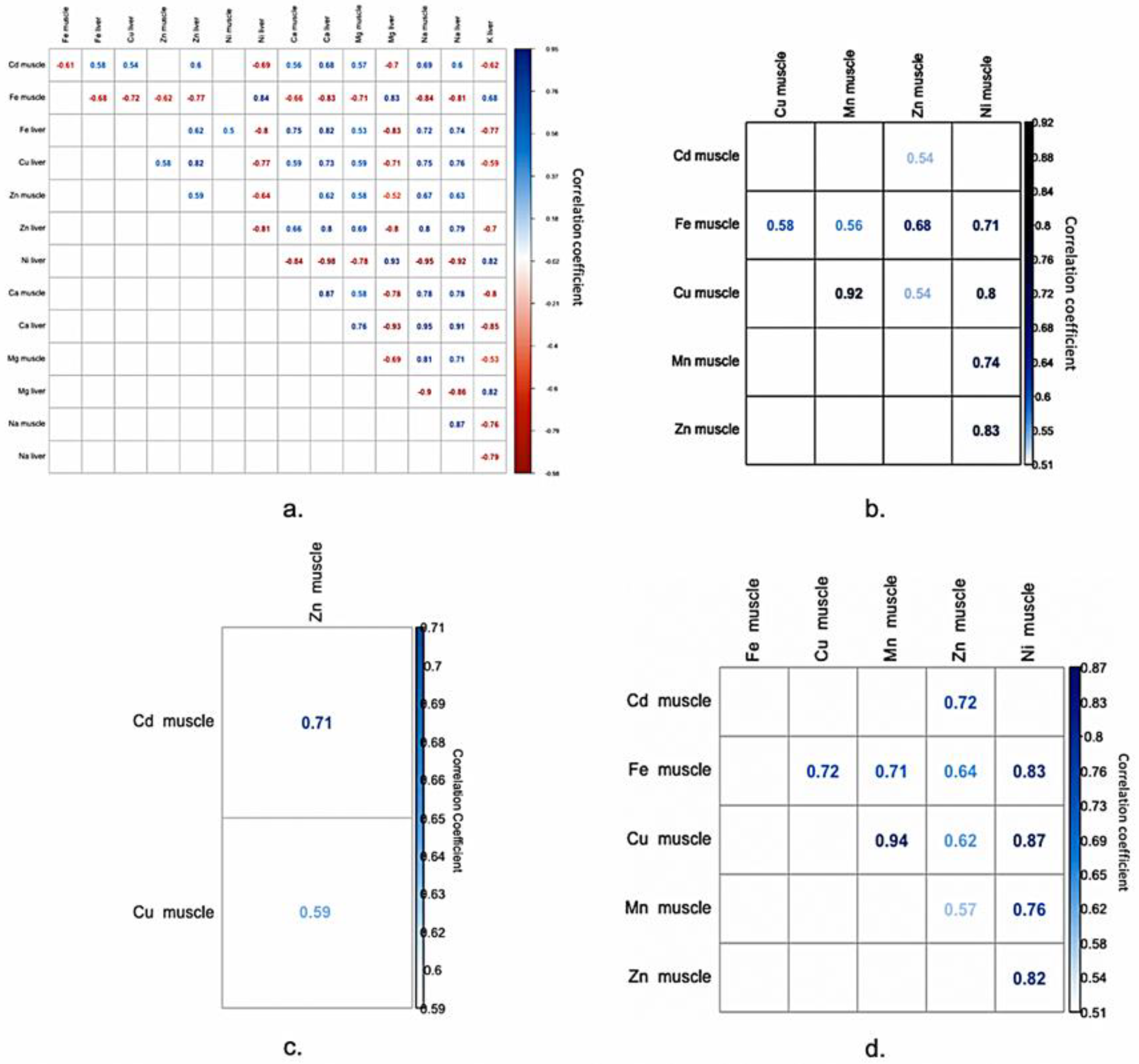
2.1. The Correlation Matrix
2.1.1. Positive Significant Correlations
2.1.2. Negative Significant Correlations
2.2. Predictive Models
2.2.1. The First Group MLR Models
2.2.2. The First Group Non-Linear Tree-Based RF Prediction Models
2.2.3. The Second Group Non-Linear Tree-Based RF Prediction Models
2.2.4. The Third Group MLR Models
2.2.5. The Fourth Group Non-Linear Tree-Based RF Prediction Models
2.2.6. The Fifth Group MLR Models
2.2.7. Feature Importance Overview
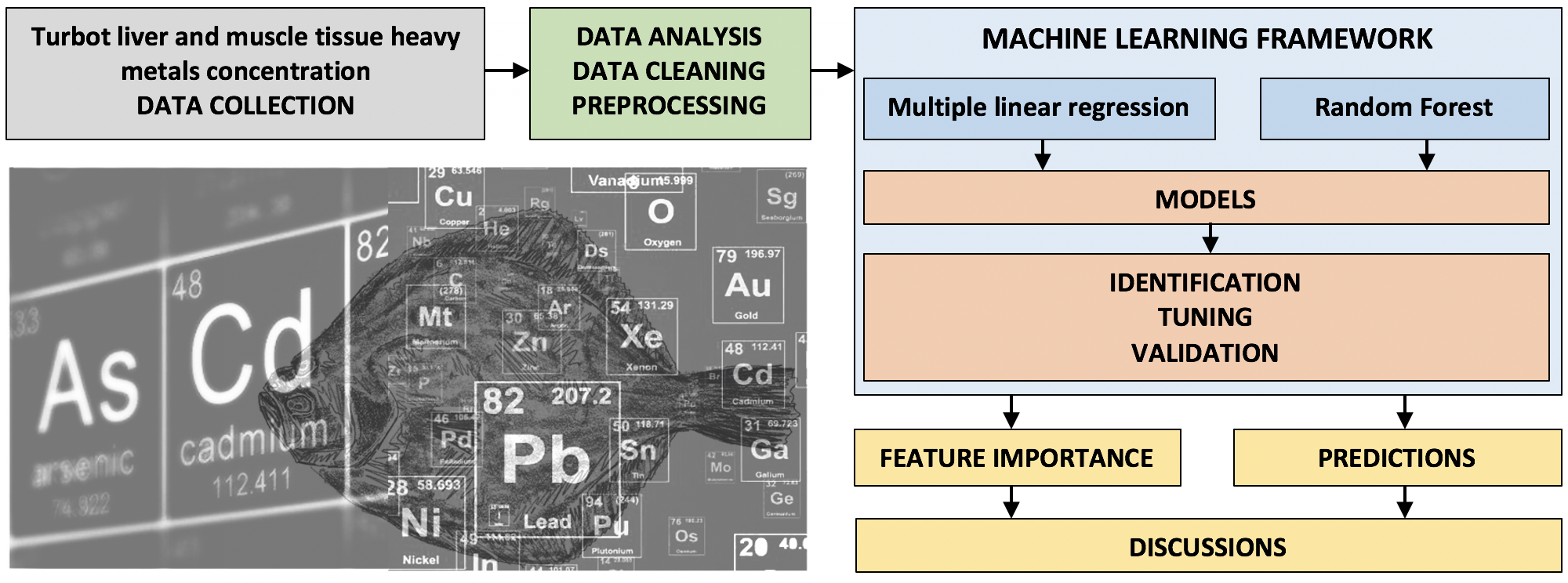
3. Material and Methods
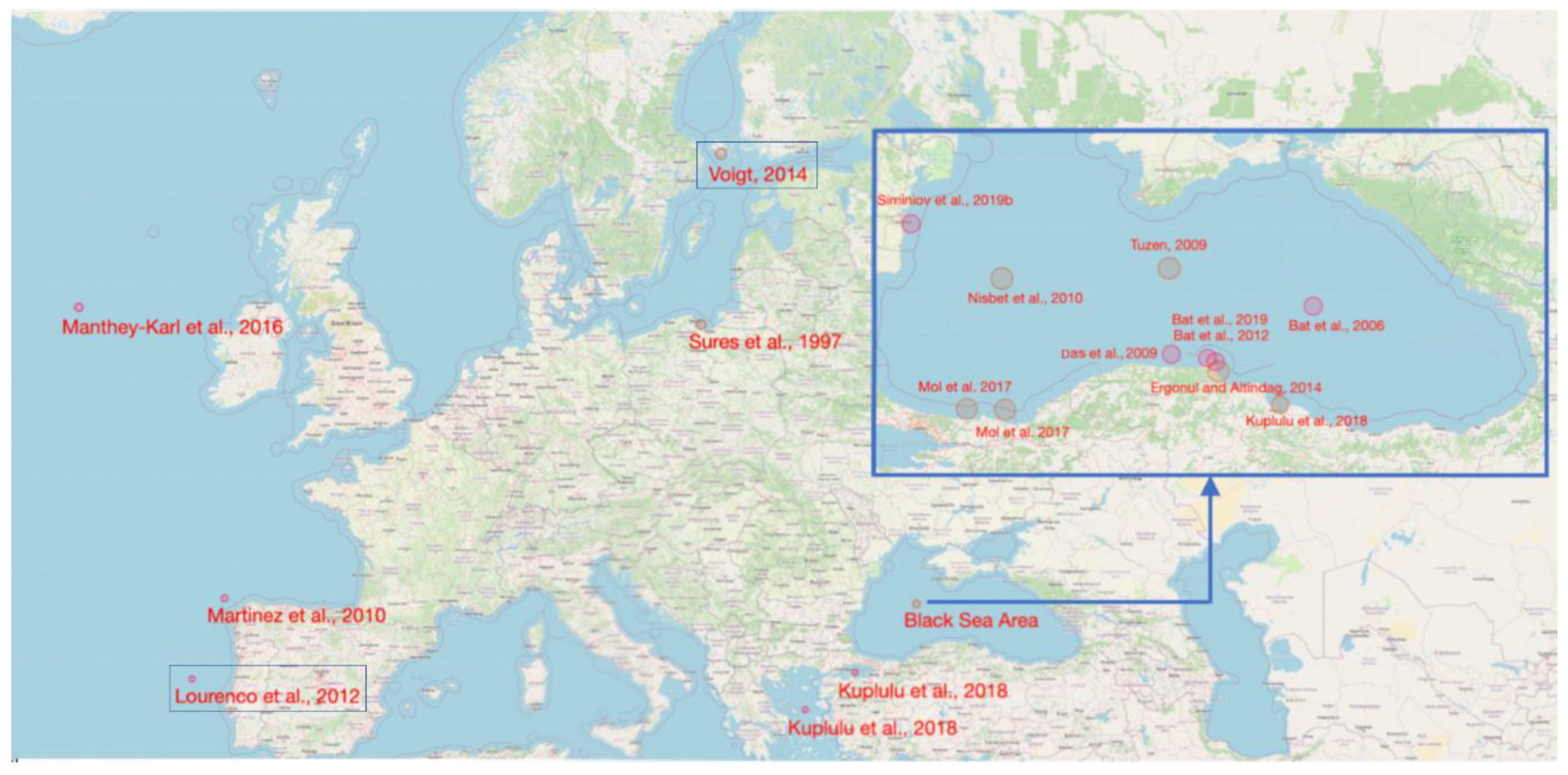
3.1. Study Area
3.2. Heavy Metal Measurement Methods in Scientific Studies Used to Obtain the Dataset Needed by the Development of the Present Paper Analytical Framework
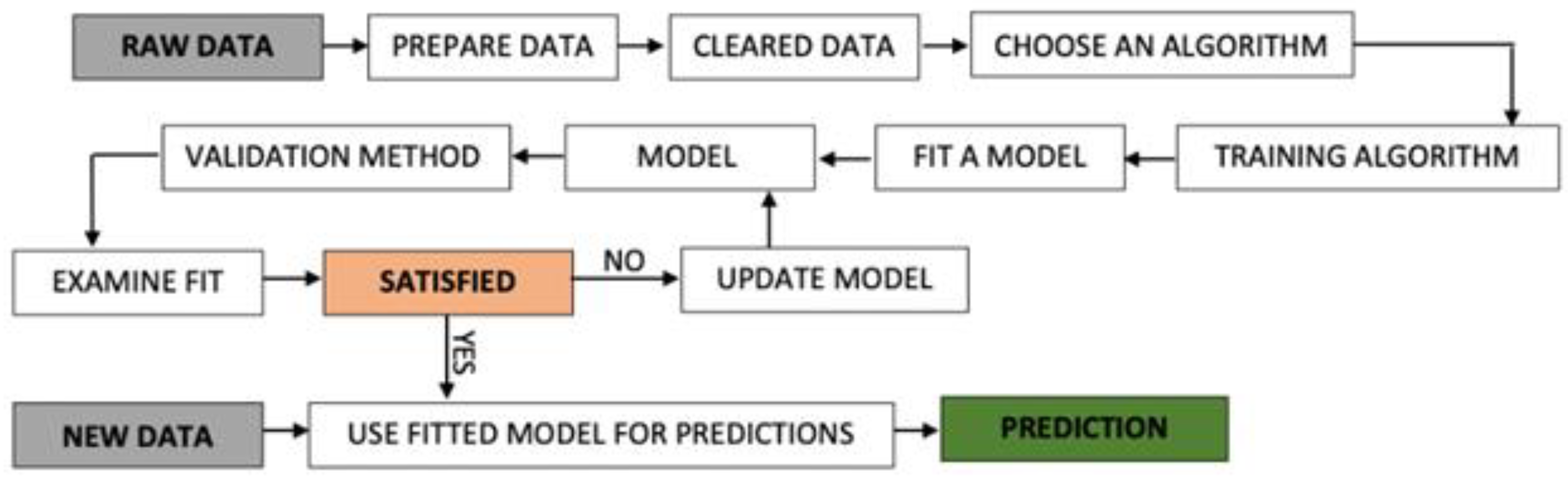
3.3. Analytical Framework Methods
3.3.1. Multiple Linear Regression Method (MLR)
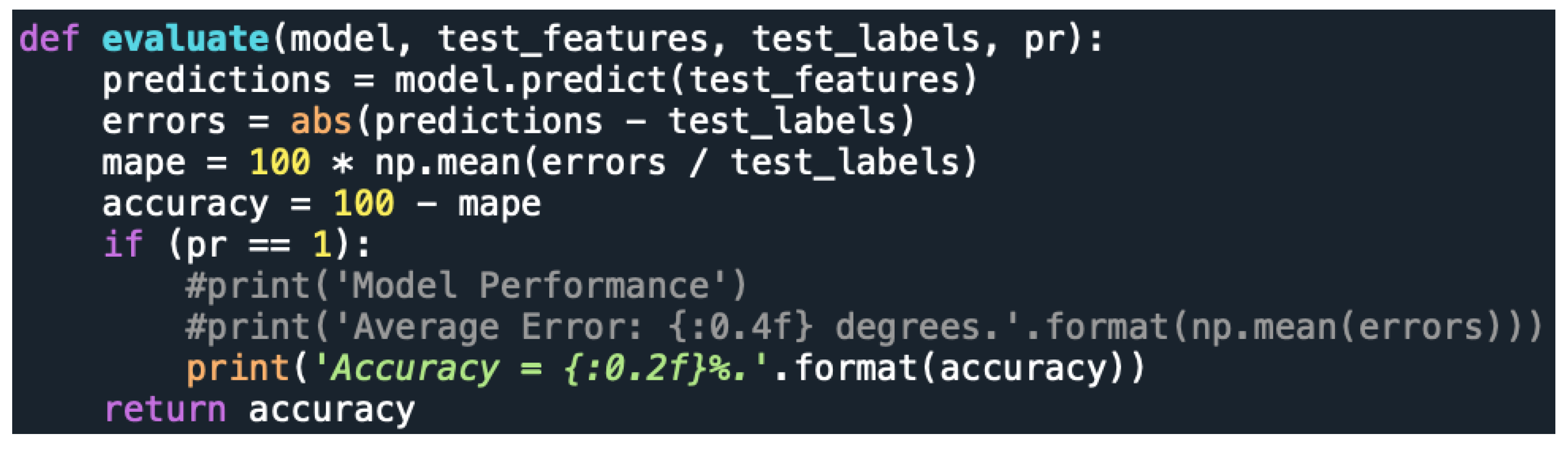
3.3.2. Non-Linear Models, Based on Random Forest (RF) Algorithm
3.4. Dataset Descriptive Statistics
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. of MLR Model | RF Model | RF Regressor |
|---|---|---|
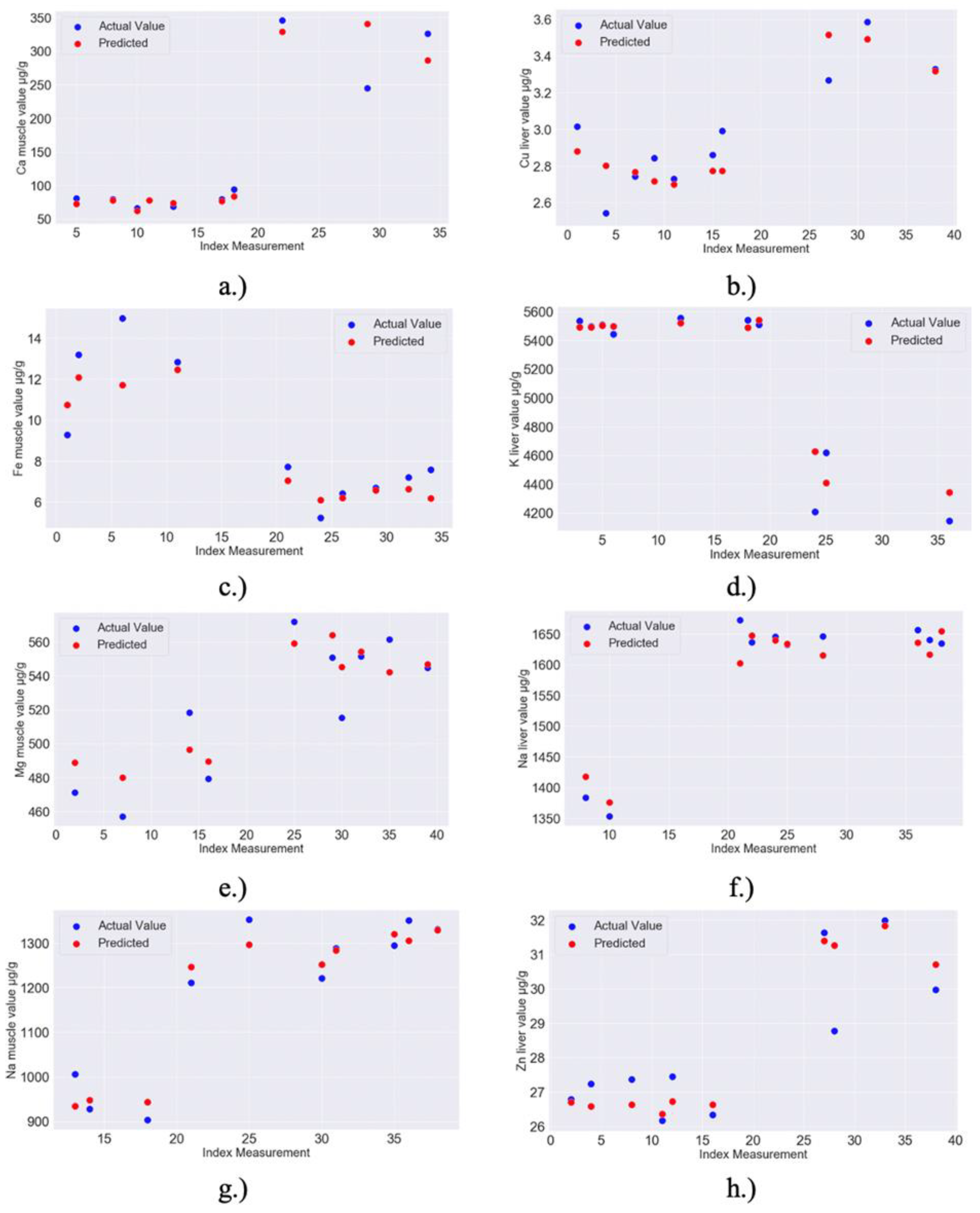
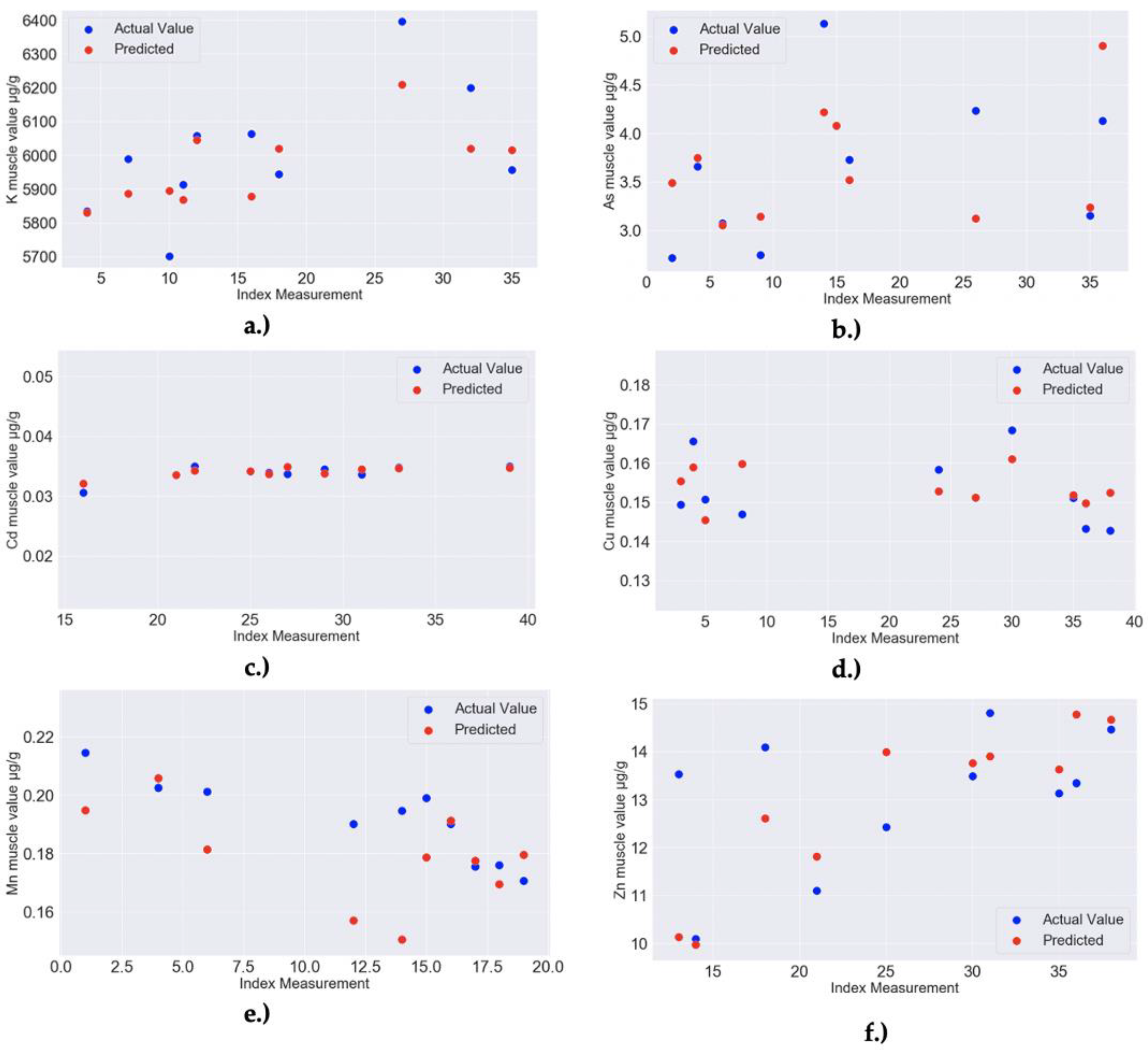
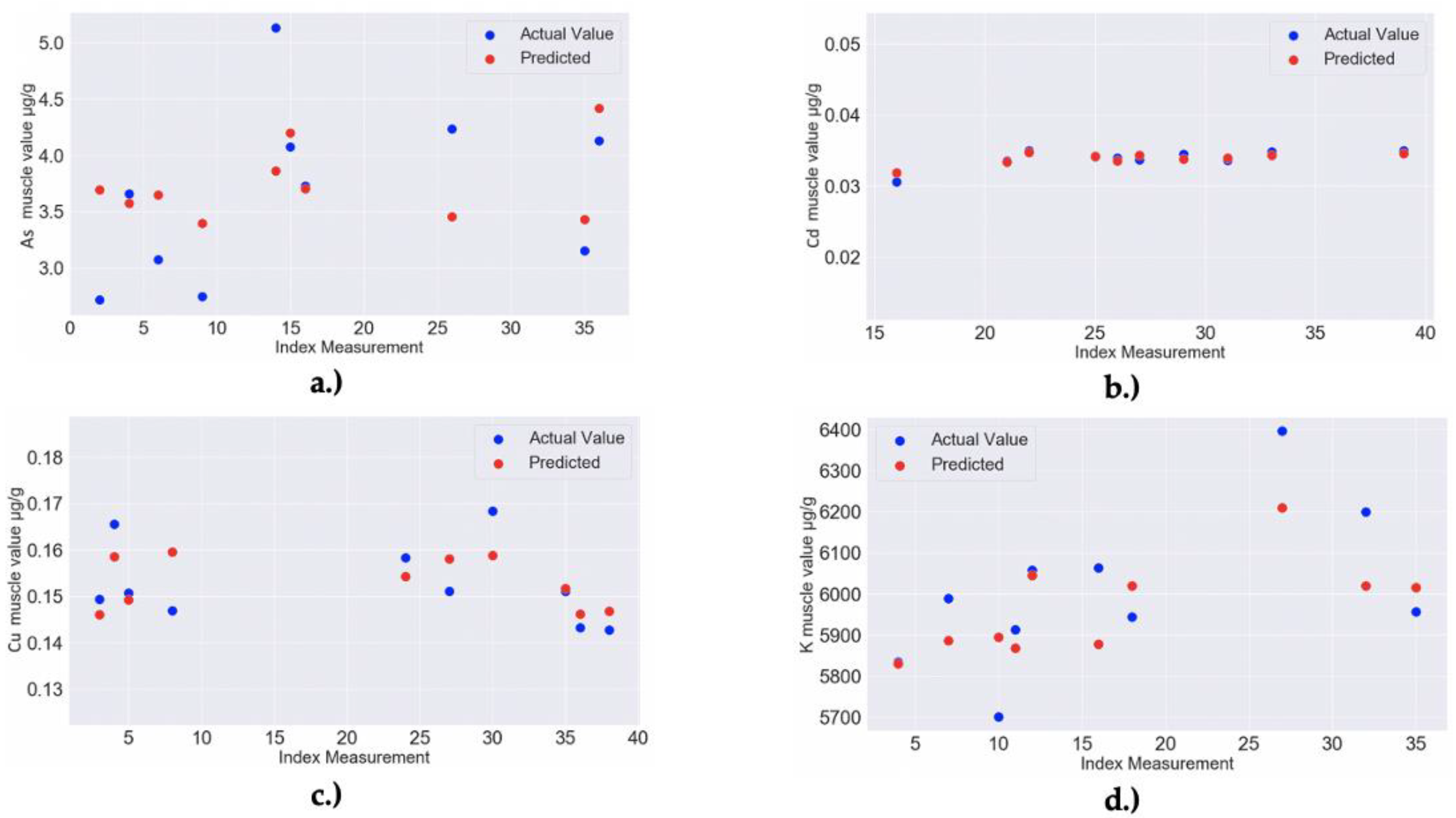
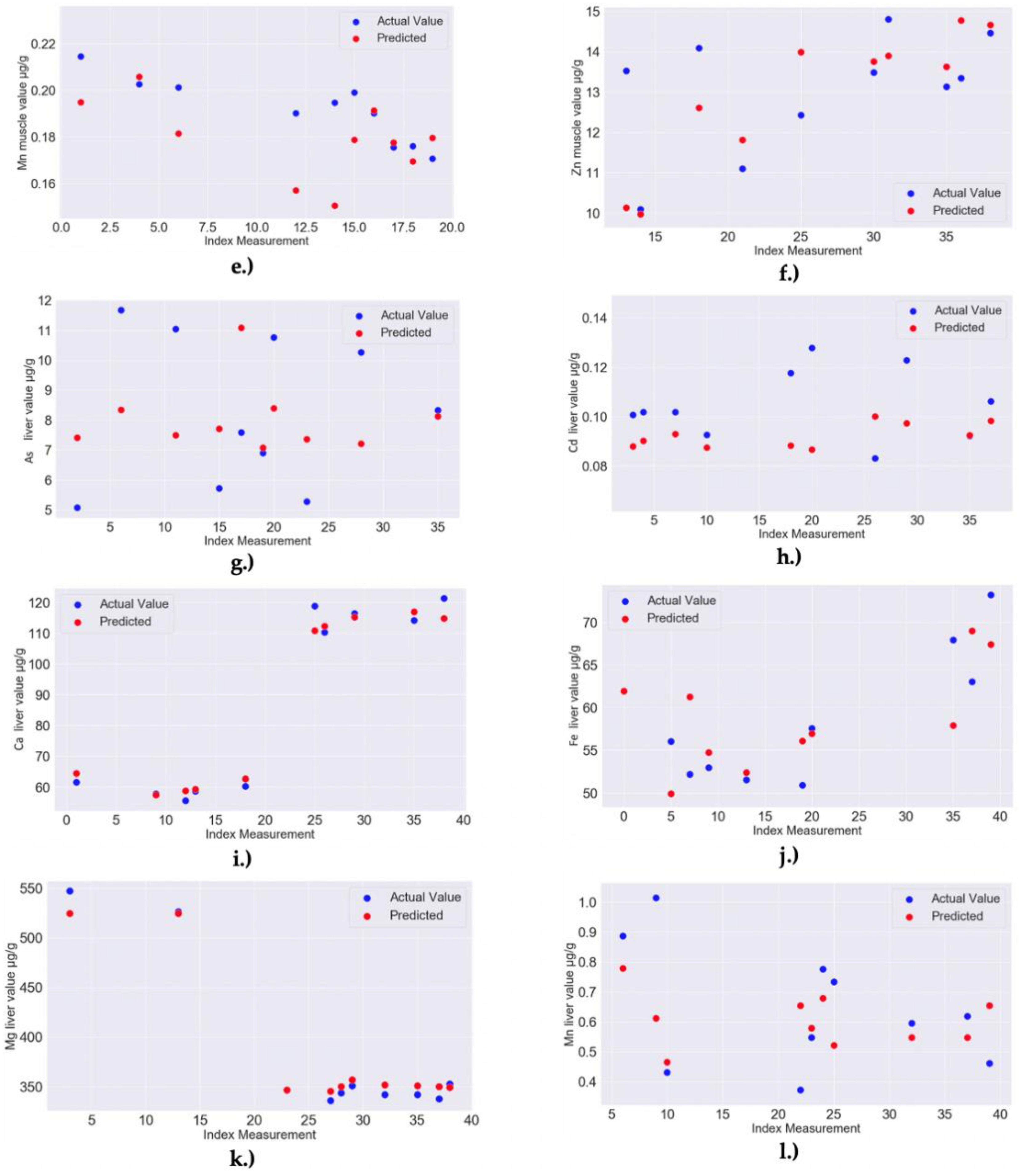
| 1 | RF MODEL: Ca muscle–Feature importance: 0.11 for Ca liver, 0.05 for Na liver, 0.02 for Mg liver, 0.01 for Ni liver and 0.01 for K liver; Model Accuracy: 90.27% (MAPE = 9.73%) | RandomForestRegressor(bootstrap = False, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 4, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 2, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 30, n_jobs = None, oob_score = False, random_state = 256, verbose = 0, warm_start = False) |
| 2 | RF MODEL: Cu liver–Feature importance: 0.06 for Zn liver, 0.04 for Mg liver, 0.03 for Ni liver; Model Accuracy: 95.81% (MAPE = 4.19%) | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 4, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 3, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 110, n_jobs = None, oob_score = False, random_state = 58, verbose = 0, warm_start = False) |
| 3 | RF MODEL: Fe muscle–Feature importance: 0.06 for Na muscle, 0.05 for K liver, 0.04 for Mn liver, 0.04 for Mg muscle, 0.03 for Ni liver; Model Accuracy: 89.48% (MAPE = 10.52%) | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 2, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 3, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 40, n_jobs = None, oob_score = False, random_state = 80, verbose = 0, warm_start = False) |
| 4 | RF MODEL: K liver–Feature importance: 0.14 for Na liver, 0.11 for Ca liver, 0.11 for Ca muscle, 0.09 for Fe liver, 0.04 for Mg liver; Model Accuracy: 97.66% (MAPE = 2.34%) | RandomForestRegressor(bootstrap = False, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 3, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 2, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 30, n_jobs = None, oob_score = False, random_state = 124, verbose = 0, warm_start = False) |
| 5 | RF MODEL: Mg muscle–Feature importance: 0.13 for Na muscle, 0.08 for Zn liver, 0.03 for Ni liver, 0.02 for Cu muscle, 0.02 for Fe muscle; Model Accuracy: 97.01% (MAPE = 2.99%) | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 4, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 3, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 60, n_jobs = None, oob_score = False, random_state = 297, verbose = 0, warm_start = False) |
| 6 | RF MODEL: Na liver–Feature importance: 0.16 for Ca liver, 0.09 for Fe muscle, 0.08 for Mg liver, 0.07 for K liver, 0.02 for Mg muscle; Model Accuracy: 98.48% (MAPE = 1.52%) | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 2, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 2, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 30, n_jobs = None, oob_score = False, random_state = 115, verbose = 0, warm_start = False) |
| 7 | RF MODEL: Na muscle–Feature importance: 0.08 for Fe muscle, 0.06 for Zn liver, 0.04 for Ca muscle, 0.03 for Mg muscle, 0.03 for Ca liver; Model Accuracy: 97.09% (MAPE = 2.91%) | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 4, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 2, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 50, n_jobs = None, oob_score = False, random_state = 273, verbose = 0, warm_start = False) |
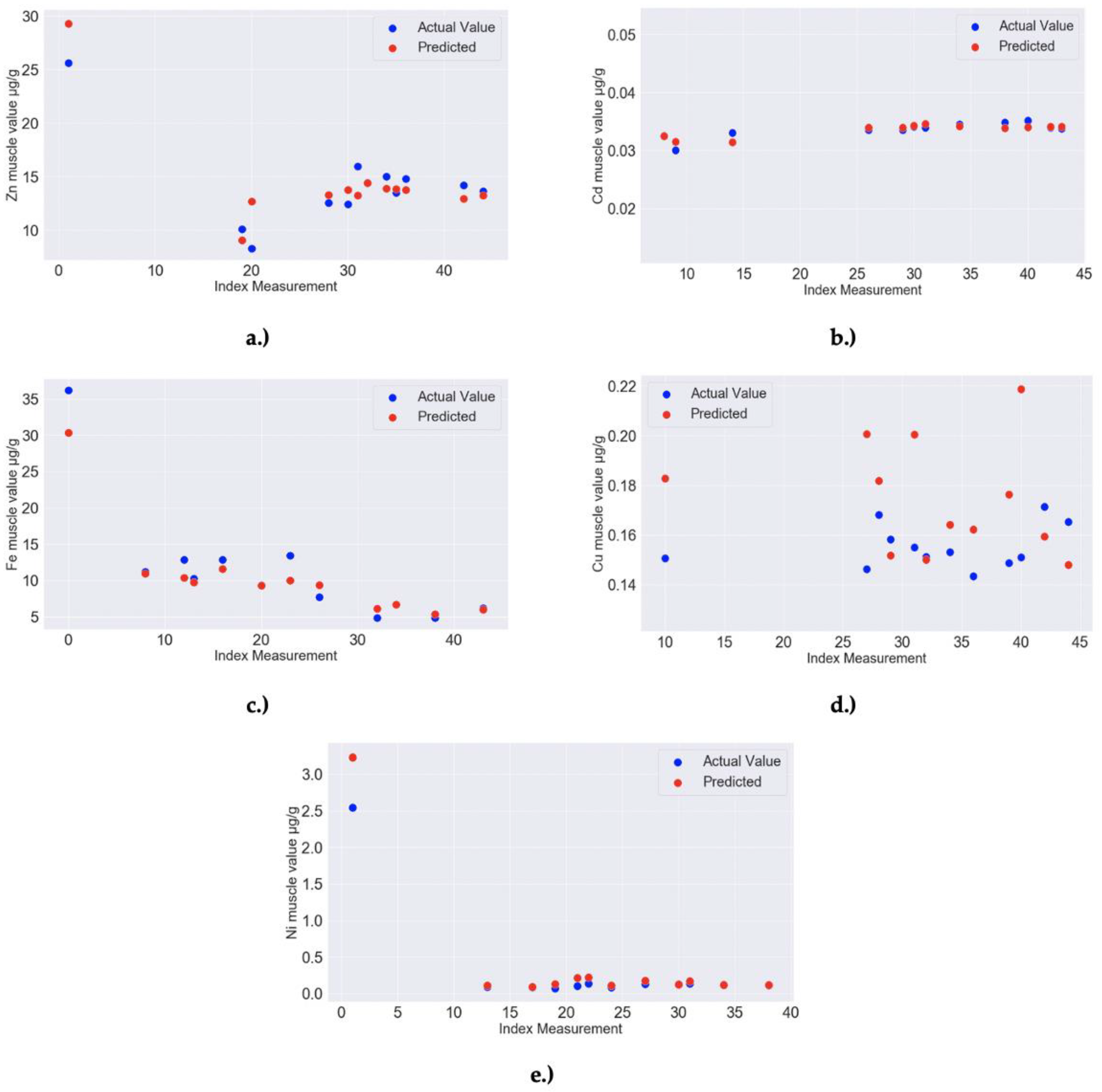
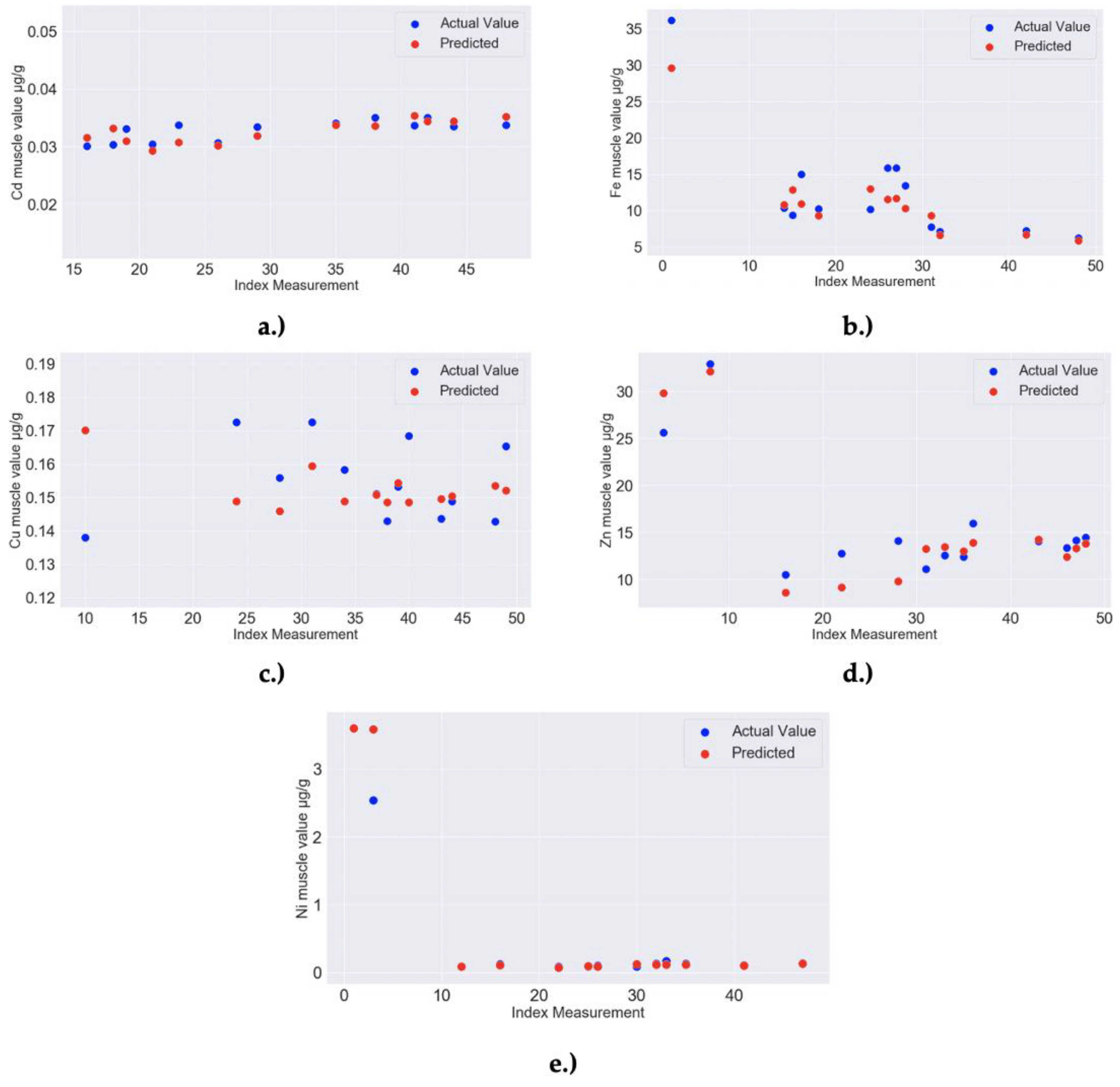
| 8a,b | RF MODEL: Zn liver–Feature importance: 0.04 for Ca liver, 0.01 for Cd liver, 0.01 for Zn muscle, 0.01 for Mn muscle; Model Accuracy: 97.78% (MAPE = 2.22%) | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 4, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 2, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 40, n_jobs = None, oob_score = False, random_state = 299, verbose = 0, warm_start = False) |
| Model No. | RF Model Regressor |
|---|---|
| 9 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 100, max_features = 4, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 3, min_weight_fraction_leaf = 0.0, n_estimators = 200, n_jobs = None, oob_score = False, random_state = 116, verbose = 0, warm_start = False) |
| 10 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 100, max_features = 4, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 3, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 200, n_jobs = None, oob_score = False, random_state = 278, verbose = 0, warm_start = False) |
| 11 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 100, max_features = 4, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 3, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 200, n_jobs = None, oob_score = False, random_state = 15, verbose = 0, warm_start = False) |
| 12 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 100, max_features = 2, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None, oob_score = False, random_state = 237, verbose = 0, warm_start = False) |
| 13 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 2, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 50, n_jobs = None, oob_score = False, random_state = 227, verbose = 0, warm_start = False) |
| 14 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 2, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 90, n_jobs = None, oob_score = False, random_state = 214, verbose = 0, warm_start = False) |
| 15 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 100, max_features = 3, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 3, min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None, oob_score = False, random_state = 43, verbose = 0, warm_start = False) |
| 16 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 100, max_features = 2, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None, oob_score = False, random_state = 201, verbose = 0, warm_start = False) |
| 17 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 100, max_features = 4, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 2, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None, oob_score = False, random_state = 93, verbose = 0, warm_start = False) |
| 18 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 100, max_features = 4, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 2, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None, oob_score = False, random_state = 223, verbose = 0, warm_start = False) |
| 19 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 100, max_features = 3, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 2, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None, oob_score = False, random_state = 192, verbose = 0, warm_start = False) |
| 20 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 100, max_features = 2, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 3, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 200, n_jobs = None, oob_score = False, random_state = 206, verbose = 0, warm_start = False) |
| 21 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = None, max_features = ‘auto’, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, in_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None, oob_score = False, random_state = 173, verbose = 0, warm_start = False) |
| 22 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 4, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 70, n_jobs = None, oob_score = False, random_state = 171, verbose = 0, warm_start = False) |
| 23 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 3, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 2, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None, oob_score = False, random_state = 29, verbose = 0, warm_start = False) |
| 24 | RandomForestRegressor(bootstrap = False, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 3, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 2, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 30, n_jobs = None, oob_score = False, random_state = 237, verbose = 0, warm_start = False) |
| 25 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = None, max_features = ‘auto’, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None, oob_score = False, random_state = 227, verbose = 0, warm_start = False) |
| 26 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = None, max_features = ‘auto’, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None, oob_score = False, random_state = 143, verbose = 0, warm_start = False) |
| 27 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = None, max_features = ‘auto’, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None, oob_score = False, random_state = 45, verbose = 0, warm_start = False) |
| 28 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 3, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 3, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 30, n_jobs = None, oob_score = False, random_state = 104, verbose = 0, warm_start = False) |
| 29 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 3, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 2, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 110, n_jobs = None, oob_score = False, random_state = 223, verbose = 0, warm_start = False) |
| 30 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = None, max_features = ‘auto’, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None, oob_score = False, random_state = 76, verbose = 0, warm_start = False) |
| 31 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 2, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 3, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 60, n_jobs = None, oob_score = False, random_state = 192, verbose = 0, warm_start = False) |
| 32 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 4, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 3, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 50, n_jobs = None, oob_score = False, random_state = 273, verbose = 0, warm_start = False) |
| 33 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 100, max_features = 2, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None, oob_score = False, random_state = 93, verbose = 0, warm_start = False) |
| 34 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 100, max_features = 4, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 3, min_weight_fraction_leaf = 0.0, n_estimators = 90, n_jobs = None, oob_score = False, random_state = 11, verbose = 0, warm_start = False) |
| 35 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 80, max_features = 2, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 3, min_weight_fraction_leaf = 0.0, n_estimators = 90, n_jobs = None, oob_score = False, random_state = 74, verbose = 0, warm_start = False) |
| 36 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 50, max_features = 2, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 3, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 90, n_jobs = None, oob_score = False, random_state = 54, verbose = 0, warm_start = False) |
| 37 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = None, max_features = ‘auto’, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None, oob_score = False, random_state = 102, verbose = 0, warm_start = False) |
| 39 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 2, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 80, n_jobs = None, oob_score = False, random_state = 17, verbose = 0, warm_start = False) |
| 40 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 3, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 3, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 40, n_jobs = None, oob_score = False, random_state = 284, verbose = 0, warm_start = False) |
| 41 | RandomForestRegressor(bootstrap = False, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 2, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 30, n_jobs = None, oob_score = False, random_state = 54, verbose = 0, warm_start = False) |
| 42 | RandomForestRegressor(bootstrap = True, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 2, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None, oob_score = False, random_state = 63, verbose = 0, warm_start = False) |
| 43 | RandomForestRegressor(bootstrap = False, ccp_alpha = 0.0, criterion = ‘mse’, max_depth = 40, max_features = 3, max_leaf_nodes = None, max_samples = None, min_impurity_decrease = 0.0, min_impurity_split = None, min_samples_leaf = 1, min_samples_split = 2, min_weight_fraction_leaf = 0.0, n_estimators = 30, n_jobs = None, oob_score = False, random_state = 22, verbose = 0, warm_start = False) |
| Variable | Unit | Mean | SE Mean | StDev | Min. | Q1 | Median | Q3 | Max. |
|---|---|---|---|---|---|---|---|---|---|
| As muscle | µg g−1 Fresh weight (F.W.) | 3.82 | 0.18 | 1.14 | 2.15 | 2.79 | 3.69 | 4.66 | 6.32 |
| Cd muscle | µg g−1 F.W. | 0.03 | 0.00 | 0.00 | 0.03 | 0.03 | 0.03 | 0.03 | 0.04 |
| Fe muscle | µg g−1 F.W. | 9.13 | 0.58 | 3.68 | 4.33 | 6.26 | 8.40 | 12.84 | 15.87 |
| Cu muscle | µg g−1 F.W. | 0.16 | 0.00 | 0.01 | 0.14 | 0.14 | 0.16 | 0.17 | 0.18 |
| Mn muscle | µg g−1 F.W. | 0.17 | 0.01 | 0.06 | 0.04 | 0.15 | 0.19 | 0.21 | 0.27 |
| Zn muscle | µg g−1 F.W. | 12.18 | 0.47 | 2.99 | 6.17 | 10.20 | 13.14 | 14.39 | 16.13 |
| Ni muscle | µg g−1 F.W. | 0.11 | 0.00 | 0.03 | 0.05 | 0.09 | 0.11 | 0.13 | 0.17 |
| Ca muscle | µg g−1 F.W. | 176.84 | 19.63 | 124.14 | 52.49 | 79.52 | 100.94 | 287.07 | 435.90 |
| Mg muscle | µg g−1 F.W. | 518.08 | 7.47 | 47.25 | 438.42 | 479.67 | 517.38 | 551.31 | 608.88 |
| Na muscle | µg g−1 F.W. | 1116.55 | 31.99 | 202.32 | 831.94 | 917.89 | 1123.59 | 1319.56 | 1394.43 |
| K muscle | µg g−1 F.W. | 6001.23 | 38.72 | 244.91 | 5640.17 | 5778.49 | 5998.94 | 6191.85 | 6453.03 |
| As liver | µg g−1 F.W. | 8.42 | 0.62 | 3.92 | 3.91 | 4.78 | 7.44 | 10.67 | 17.65 |
| Cd liver | µg g−1 F.W. | 0.10 | 0.00 | 0.02 | 0.05 | 0.08 | 0.09 | 0.12 | 0.13 |
| Fe liver | µg g−1 F.W. | 60.34 | 1.69 | 10.68 | 42.12 | 52.39 | 60.16 | 69.88 | 79.81 |
| Cu liver | µg g−1 F.W. | 3.10 | 0.07 | 0.42 | 2.51 | 2.77 | 3.00 | 3.42 | 3.89 |
| Mn liver | µg g−1 F.W. | 0.62 | 0.04 | 0.27 | 0.02 | 0.44 | 0.61 | 0.80 | 1.10 |
| Zn liver | µg g−1 F.W. | 28.63 | 0.40 | 2.50 | 25.27 | 26.45 | 28.01 | 30.74 | 33.93 |
| Ni liver | µg g−1 F.W. | 0.17 | 0.00 | 0.03 | 0.13 | 0.14 | 0.17 | 0.20 | 0.21 |
| Ca liver | µg g−1 F.W. | 85.89 | 4.56 | 28.82 | 51.64 | 58.76 | 82.24 | 115.01 | 121.73 |
| Mg liver | µg g−1 F.W. | 434.82 | 14.94 | 94.52 | 334.09 | 344.36 | 406.76 | 535.68 | 599.18 |
| Na liver | µg g−1 F.W. | 1511.55 | 23.77 | 150.32 | 1217.21 | 1419.67 | 1548.77 | 1645.93 | 1672.52 |
| K liver | µg g−1 F.W. | 4889.04 | 118.62 | 750.23 | 3281.69 | 4252.79 | 5204.22 | 5533.91 | 5580.09 |
| Turbot Weight | kg | 1.39 | 0.02 | 0.15 | 1.20 | 1.26 | 1.36 | 1.48 | 1.70 |
| Turbot Length | cm | 43.46 | 0.31 | 1.94 | 40.20 | 41.77 | 43.70 | 44.98 | 46.80 |
| Variable (µg g−1 F.W.) | Mean | SE Mean | StDev | Min. | Q1 | Median | Q3 | Max. |
|---|---|---|---|---|---|---|---|---|
| Cd muscle | 0.04 | 0.00 | 0.01 | 0.02 | 0.03 | 0.03 | 0.03 | 0.10 |
| Fe muscle | 11.57 | 1.23 | 8.23 | 4.33 | 6.56 | 9.33 | 13.62 | 39.84 |
| Cu muscle | 0.38 | 0.12 | 0.83 | 0.14 | 0.15 | 0.16 | 0.17 | 5.05 |
| Mn muscle | 1.00 | 0.55 | 3.67 | 0.04 | 0.17 | 0.20 | 0.21 | 24.22 |
| Zn muscle | 14.67 | 1.23 | 8.26 | 6.17 | 10.81 | 13.49 | 14.99 | 45.20 |
| Ni muscle | 0.50 | 0.17 | 1.14 | 0.05 | 0.09 | 0.12 | 0.14 | 4.50 |
| Variable (µg g−1 F.W.) | Mean | SE Mean | StDev | Min. | Q1 | Median | Q3 | Max. |
|---|---|---|---|---|---|---|---|---|
| Cd muscle | 0.03 | 0.00 | 0.01 | 0.01 | 0.03 | 0.03 | 0.03 | 0.10 |
| Cu muscle | 0.55 | 0.16 | 1.11 | 0.14 | 0.15 | 0.16 | 0.17 | 5.18 |
| Zn muscle | 15.31 | 1.20 | 8.40 | 6.17 | 11.30 | 13.63 | 15.43 | 45.20 |
| Variable (µg g−1 F.W.) | Mean | SE Mean | StDev | Min. | Q1 | Median | Q3 | Max. |
|---|---|---|---|---|---|---|---|---|
| Cd muscle | 0.03 | 0.00 | 0.01 | 0.01 | 0.03 | 0.03 | 0.03 | 0.10 |
| Fe muscle | 10.67 | 1.09 | 7.42 | 2.60 | 6.09 | 9.17 | 13.46 | 39.84 |
| Cu muscle | 0.37 | 0.12 | 0.82 | 0.14 | 0.15 | 0.16 | 0.17 | 5.05 |
| Mn muscle | 0.93 | 0.53 | 3.61 | 0.04 | 0.17 | 0.20 | 0.22 | 24.22 |
| Zn muscle | 13.91 | 1.01 | 6.86 | 6.17 | 10.41 | 13.42 | 14.98 | 45.20 |
| Ni muscle | 0.41 | 0.15 | 1.03 | 0.02 | 0.08 | 0.11 | 0.14 | 4.50 |
| Variable (µg g−1 F.W.) | Mean | SE Mean | StDev | Min. | Q1 | Median | Q3 | Max. |
|---|---|---|---|---|---|---|---|---|
| Pb muscle | 0.24 | 0.08 | 0.25 | 0.03 | 0.10 | 0.17 | 0.28 | 0.85 |
| Cd muscle | 0.05 | 0.01 | 0.04 | 0.01 | 0.01 | 0.03 | 0.10 | 0.11 |
| As muscle | 0.91 | 0.27 | 0.81 | 0.15 | 0.30 | 0.61 | 1.58 | 2.53 |
References
- Gomes-Silva, G.; Pereira, B.B.; Liu, K.; Chen, B.; Santos, V.S.V.; de Menezes, G.H.T.; Pires, L.P.; Santos, B.M.T.; Oliveira, D.M.; Machado, P.H.A.; et al. Using native and invasive livebearing fishes (Poeciliidae, Teleostei) for the integrated biological assessment of pollution in urban streams. Sci. Total Environ. 2020, 698, 134336. [Google Scholar] [CrossRef]
- van Bussel, C.G.J.; Schroeder, J.P.; Mahlmann, L.; Schulz, C. Aquatic accumulation of dietary metals (Fe, Zn, Cu, Co, Mn) in recirculating aquaculture systems (RAS) changes body composition but not performance and health of juvenile turbot (Psetta maxima). Aquac. Eng. 2014, 61, 35–42. [Google Scholar] [CrossRef]
- Bray, L.; Digka, N.; Tsangaris, C.; Camedda, A.; Gambaiani, D.; de Lucia, G.A.; Matiddi, M.; Miaud, C.; Palazzo, L.; Pérez-del-Olmo, A.; et al. Determining suitable fish to monitor plastic ingestion trends in the Mediterranean Sea. Environ. Pollut. 2019, 247, 1071–1077. [Google Scholar] [CrossRef] [PubMed]
- Giani, D.; Baini, M.; Galli, M.; Casini, S.; Fossi, M.C. Microplastics occurrence in edible fish species (Mullus barbatus and Merluccius merluccius) collected in three different geographical sub-areas of the Mediterranean Sea. Mar. Pollut. Bull. 2019, 140, 129–137. [Google Scholar] [CrossRef]
- Rios-Fuster, B.; Alomar, C.; Compa, M.; Guijarro, B.; Deudero, S. Anthropogenic particles ingestion in fish species from two areas of the western Mediterranean Sea. Mar. Pollut. Bull. 2019. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Garin, O.; Vighi, M.; Aguilar, A.; Tsangaris, C.; Digka, N.; Kaberi, H.; Borrell, A. Boops boops as a bioindicator of microplastic pollution along the Spanish Catalan coast. Mar. Pollut. Bull. 2019, 149, 110648. [Google Scholar] [CrossRef]
- Li, M.; Weis, D.; Smith, K.E.; Shiel, A.E.; Smith, W.D.; Hunt, B.P.V.; Torchinsky, A.; Pakhomov, E.A. Assessing lead sources in fishes of the northeast Pacific Ocean. Anthropocene 2020. [Google Scholar] [CrossRef]
- Zhu, Q.L.; Zhang, X.L.; Hu, W.; Zhang, J.S.; Zheng, J.L. Larimichthys crocea is a suitable bioindicator for monitoring short-term Cd discharge along the coast: An experimental study. Environ. Pollut. 2020, 259, 113849. [Google Scholar] [CrossRef]
- Lacerda, D.; dos Santos Vergilio, C.; da Silva Souza, T.; Viana Costa, L.H.; Rangel, T.P.; Vaz de Oliveira, B.C.; Ribeiro de Almeida, D.Q.; Pestana, I.A.; Gomes de Almeida, M.; de Rezende, C.E. Comparative metal accumulation and toxicogenetic damage induction in three neotropical fish species with distinct foraging habits and feeding preferences. Ecotoxicol. Environ. Saf. 2020, 195, 110449. [Google Scholar] [CrossRef]
- Hinojosa-Garro, D.; von Osten, J.R.; Dzul-Caamal, R. Banded tetra (Astyanax aeneus) as bioindicator of trace metals in aquatic ecosystems of the Yucatan Peninsula, Mexico: Experimental biomarkers validation and wild populations biomonitoring. Ecotoxicol. Environ. Saf. 2020. [Google Scholar] [CrossRef]
- da Silva, J.M.; Alves, L.M.F.; Laranjeiro, M.I.; Silva, A.; Angélico, M.M.; Norte, A.C.; Lemos, M.F.L.; Ramos, J.A.; Novais, S.C.; Ceia, F.R. Mercury levels in commercial mid-trophic level fishes along the Portuguese coast—Relationships with trophic niche and oxidative damage. Ecol. Indic. 2020, 116, 106500. [Google Scholar] [CrossRef]
- Cunningham, P.A.; Sullivan, E.E.; Everett, K.H.; Kovach, S.S.; Rajan, A.; Barber, M.C. Assessment of metal contamination in Arabian/Persian Gulf fish: A review. Mar. Pollut. Bull. 2019, 143, 264–283. [Google Scholar] [CrossRef] [PubMed]
- Nyeste, K.; Dobrocsi, P.; Czeglédi, I.; Czédli, H.; Harangi, S.; Baranyai, E.; Simon, E.; Nagy, S.A.; Antal, L. Age and diet-specific trace element accumulation patterns in different tissues of chub (Squalius cephalus): Juveniles are useful bioindicators of recent pollution. Ecol. Indic. 2019, 101, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Gentès, S.; Coquery, M.; Vigouroux, R.; Hanquiez, V.; Allard, L.; Maury-Brachet, R. Application of the European Water Framework Directive: Identification of reference sites and bioindicator fish species for mercury in tropical freshwater ecosystems (French Guiana). Ecol. Indic. 2019, 106, 105468. [Google Scholar] [CrossRef]
- Dron, J.; Revenko, G.; Chamaret, P.; Chaspoul, F.; Wafo, E.; Harmelin-Vivien, M. Contaminant signatures and stable isotope values qualify European conger (Conger conger) as a pertinent bioindicator to identify marine contaminant sources and pathways. Ecol. Indic. 2019, 107, 105562. [Google Scholar] [CrossRef]
- Viana, L.F.; Súarez, Y.R.; Cardoso, C.A.L.; Lima, S.M.; da Andrade, L.H.C.; Lima-Junior, S.E. Use of fish scales in environmental monitoring by the application of Laser-Induced Breakdown Spectroscopy (LIBS). Chemosphere 2019, 228, 258–263. [Google Scholar] [CrossRef] [PubMed]
- da Silva Souza, T.; Lacerda, D.; Aguiar, L.L.; Martins, M.N.C.; Augusto de Oliveira David, J. Toxic potential of sewage sludge: Histopathological effects on soil and aquatic bioindicators. Ecol. Indic. 2020, 111, 105980. [Google Scholar] [CrossRef]
- Goode, K.L.; Dunphy, B.J.; Parsons, D.M. Environmental metabolomics as an ecological indicator: Metabolite profiles in juvenile fish discriminate sites with different nursery habitat qualities. Ecol. Indic. 2020, 15, 106361. [Google Scholar] [CrossRef]
- Montenegro, D.; Astudillo-García, C.; Hickey, T.; Lear, G. A non-invasive method to monitor marine pollution from bacterial DNA present in fish skin mucus. Environ. Pollut. 2020, 263, 114438. [Google Scholar] [CrossRef]
- Hu, C.; Yang, X.; Gao, L.; Zhang, P.; Li, W.; Dong, J.; Li, C.; Zhang, X. Comparative analysis of heavy metal accumulation and bioindication in three seagrasses: Which species is more suitable as a bioindicator? Sci. Total Environ. 2019, 669, 41–48. [Google Scholar] [CrossRef]
- Mille, T.; Cresson, P.; Chouvelon, T.; Bustamante, P.; Brach-Papa, C.; Sandrine, B.; Rozuel, E.; Bouchoucha, M. Trace metal concentrations in the muscle of seven marine species: Comparison between the Gulf of Lions (North-West Mediterranean Sea) and the Bay of Biscay (North-East Atlantic Ocean). Mar. Pollut. Bull. 2018, 135, 9–16. [Google Scholar] [CrossRef] [Green Version]
- Simionov, I.A.; Cristea, V.; Petrea, S.M.; Mogodan, A.; Nicoara, M.; Baltag, E.S.; Strungaru, S.A.; Faggio, C. Bioconcentration of essential and nonessential elements in black sea turbot (Psetta maxima maeotica, Linnaeus, 1758) in relation to fish gender. J. Mar. Sci. Eng. 2019, 7, 466. [Google Scholar] [CrossRef] [Green Version]
- Polak-Juszczak, L. Bioaccumulation of mercury in the trophic chain of flatfish from the Baltic Sea. Chemosphere 2012. [Google Scholar] [CrossRef] [PubMed]
- Kerambrun, E.; Henry, F.; Perrichon, P.; Courcot, L.; Meziane, T.; Spilmont, N.; Amara, R. Growth and condition indices of juvenile turbot, Scophthalmus maximus, exposed to contaminated sediments: Effects of metallic and organic compounds. Aquat. Toxicol. 2012, 8, 130–140. [Google Scholar] [CrossRef] [PubMed]
- Kerambrun, E.; Henry, F.; Marechal, A.; Sanchez, W.; Minier, C.; Filipuci, I.; Amara, R. A multibiomarker approach in juvenile turbot, Scophthalmus maximus, exposed to contaminated sediments. Ecotoxicol. Environ. Saf. 2012. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kerambrun, E.; Henry, F.; Courcot, L.; Gevaert, F.; Amara, R. Biological responses of caged juvenile sea bass (Dicentrarchus labrax) and turbot (Scophtalmus maximus) in a polluted harbour. Ecol. Indic. 2012, 154, 187–195. [Google Scholar] [CrossRef]
- Kerambrun, E.; Sanchez, W.; Henry, F.; Amara, R. Are biochemical biomarker responses related to physiological performance of juvenile sea bass (Dicentrarchus labrax) and turbot (Scophthalmus maximus) caged in a polluted harbour? Comp. Biochem. Physiol. C Toxicol. Pharmacol. 2011. [Google Scholar] [CrossRef] [Green Version]
- Kilemade, M.; Hartl, M.G.J.; O’Halloran, J.; O’Brien, N.M.; Sheehan, D.; Mothersill, C.; van Pelt, F.N.A.M. Effects of contaminated sediment from Cork Harbour, Ireland on the cytochrome P450 system of turbot. Ecotoxicol. Environ. Saf. 2009. [Google Scholar] [CrossRef]
- Hartl, M.G.J.; Kilemade, M.; Sheehan, D.; Mothersill, C.; O’Halloran, J.; O’Brien, N.M.; van Pelt, F.N.A.M. Hepatic biomarkers of sediment-associated pollution in juvenile turbot, Scophthalmus maximus L. Mar. Environ. Res. 2007. [Google Scholar] [CrossRef] [Green Version]
- Jeffree, R.A.; Warnau, M.; Teyssié, J.L.; Markich, S.J. Comparison of the bioaccumulation from seawater and depuration of heavy metals and radionuclides in the spotted dogfish Scyliorhinus canicula (Chondrichthys) and the turbot Psetta maxima (Actinopterygii: Teleostei). Sci. Total Environ. 2006. [Google Scholar] [CrossRef]
- Stadnicka, J.; Schirmer, K.; Ashauer, R. Predicting concentrations of organic chemicals in fish by using toxicokinetic models. Environ. Sci. Technol. 2012, 46, 3273–3280. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Jiang, Y.; Xu, C.; Yu, L.; Sun, D.; Xu, L.; Hu, F.; Li, H. Comparison of two mathematical prediction models in assessing the toxicity of heavy metal mixtures to the feeding of the nematode Caenorhabditis elegans. Ecotoxicol. Environ. Saf. 2013, 94, 73–79. [Google Scholar] [CrossRef] [PubMed]
- Niu, Y.; Jiang, X.; Wang, K.; Xia, J.; Jiao, W.; Niu, Y.; Yu, H. Meta analysis of heavy metal pollution and sources in surface sediments of Lake Taihu, China. Sci. Total Environ. 2020. [Google Scholar] [CrossRef] [PubMed]
- Qu, C.; Chen, W.; Hu, X.; Cai, P.; Chen, C.; Yu, X.Y.; Huang, Q. Heavy metal behaviour at mineral-organo interfaces: Mechanisms, modelling and influence factors. Environ. Int. 2019, 131, 104995. [Google Scholar] [CrossRef]
- Pintilie, S.; Brânză, L.; Beţianu, C.; Pavel, L.V.; Ungureanu, F.; Gavrilescu, M. Modelling and simulation of heavy metals transport in water and sediments. Environ. Eng. Manag. J. 2007. [Google Scholar] [CrossRef]
- Le, T.T.Y.; Nachev, M.; Grabner, D.; Hendriks, A.J.; Sures, B. Development and validation of a biodynamic model for mechanistically predicting metal accumulation in fish-parasite systems. PLoS ONE 2016, 11, e0161091. [Google Scholar] [CrossRef]
- Azanu, D.; JØrgensen, S.E.; Darko, G.; Styrishave, B. Simple metal model for predicting uptake and chemical processes in sewage-fed aquaculture ecosystem. Ecol. Model. 2016, 319, 130–136. [Google Scholar] [CrossRef]
- Blanco, M.V.; Cattoni, D.I.; Carriquiriborde, P.; Grigera, J.R.; Chara, O. Kinetics of bioaccumulation of heavy metals in Odontesthes bonariensis is explained by a single and common mechanism. Ecol. Model. 2014, 274, 50–56. [Google Scholar] [CrossRef]
- Noegrohati, S. Bioaccumulation dynamics of heavy metals in oreochromis nilotycus: Predicted through a bioaccumulation model constructed based on biotic ligand model (blm). Indones. J. Chem. 2010, 126, 1763–1768. [Google Scholar] [CrossRef]
- Schober, P.; Schwarte, L.A. Correlation coefficients: Appropriate use and interpretation. Anesth. Analg. 2018. [Google Scholar] [CrossRef]
- Rakocevic, J.; Sukovic, D.; Maric, D. Distribution and relationships of eleven trace elements in muscle of six fish species from Skadar Lake (Montenegro). Turk. J. Fish. Aquat. Sci. 2018. [Google Scholar] [CrossRef]
- Le Croizier, G.; Schaal, G.; Gallon, R.; Fall, M.; Le Grand, F.; Munaron, J.M.; Rouget, M.L.; Machu, E.; Le Loc’h, F.; Laë, R.; et al. Trophic ecology influence on metal bioaccumulation in marine fish: Inference from stable isotope and fatty acid analyses. Sci. Total Environ. 2016. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- El-Moselhy, K.M.; Othman, A.I.; Abd El-Azem, H.; El-Metwally, M.E.A. Bioaccumulation of heavy metals in some tissues of fish in the Red Sea, Egypt. Egypt. J. Basic Appl. Sci. 2014. [Google Scholar] [CrossRef] [Green Version]
- Wei, H.; Yu, H.; Zhang, G.; Pan, H.; Lv, C.; Meng, F. Revealing the correlations between heavy metals and water quality, with insight into the potential factors and variations through canonical correlation analysis in an upstream tributary. Ecol. Indic. 2018. [Google Scholar] [CrossRef]
- Jiao, Z.; Li, H.; Song, M.; Wang, L. Ecological risk assessment of heavy metals in water and sediment of the Pearl River Estuary, China. Mater. Sci. Eng. 2018, 394, 1–13. [Google Scholar] [CrossRef]
- Rajkowska, M.; Protasowicki, M. Distribution of metals (Fe, Mn, Zn, Cu) in fish tissues in two lakes of different trophy in Northwestern Poland. Environ. Monit. Assess. 2013. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Perera, P.A.C.T.; Kodithu, P.S.; Sundarabarathy, T.V.V.; Edirisingh, U.; Kodithuwakku, S.P.; Sundarabarathy, T.V.V.; Edirisinghe, U. Bioaccumulation of Cadmium in Freshwater Fish: An Environmental Perspective. Insight Ecol. 2015. [Google Scholar] [CrossRef] [Green Version]
- Ghosh, L.; Adhikari, S.S.A. Accumulation of Heavy Metals in Freshwater Fish-An Assessment of Toxic Interactions with Calcium. Am. J. Food Technol. 2006. [Google Scholar] [CrossRef] [Green Version]
- Okocha, R.C.; Adedeji, O.B. Overview of cadmium toxicity in fish. J. Appl. Sci. Res. 2011, 7, 1195–1207. [Google Scholar]
- Wang, F.; Gao, J.; Zha, Y. Hyperspectral sensing of heavy metals in soil and vegetation: Feasibility and challenges. ISPRS J. Photogramm. Remote Sens. 2018, 136, 73–84. [Google Scholar] [CrossRef]
- Gan, Y.; Wang, L.; Yang, G.; Dai, J.; Wang, R.; Wang, W. Multiple factors impact the contents of heavy metals in vegetables in high natural background area of China. Chemosphere 2017, 184, 1388–1395. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Yuan, X.; Li, T.; Hu, S.; Ji, J.; Wang, C. Characteristics of heavy metal transfer and their influencing factors in different soil-crop systems of the industrialization region, China. Ecotoxicol. Environ. Saf. 2016, 126, 193–201. [Google Scholar] [CrossRef] [PubMed]
- Krupa, E.; Barinova, S.; Romanova, S. The role of natural and anthropogenic factors in the distribution of heavy metals in the water bodies of kazakhstan. Turk. J. Fish. Aquat. Sci. 2019. [Google Scholar] [CrossRef]
- Januar, H.; Dwiyitno; Hidayah, I.; Hermana, I. Seasonal heavy metals accumulation in the soft tissue of anadara granosa mollusc form Tanjung Balai, Indonesia. AIMS Environ. Sci. 2019. [Google Scholar] [CrossRef]
- Whittingham, M.J.; Stephens, P.A.; Bradbury, R.B.; Freckleton, R.P. Why do we still use stepwise modelling in ecology and behaviour? J. Anim. Ecol. 2006. [Google Scholar] [CrossRef]
- Hashim, R.; Song, T.H.; Muslim, N.Z.M.; Yen, T.P. Determination of heavy metal levels in fishes from the lower reach of the kelantan river, Kelantan, Malaysia. Trop. Life Sci. Res. 2014, 25, 2. [Google Scholar]
- Yi, Y.J.; Zhang, S.H. The relationships between fish heavy metal concentrations and fish size in the upper and middle reach of Yangtze River. Procedia Environ. Sci. 2012. [Google Scholar] [CrossRef] [Green Version]
- Biau, G.; Scornet, E. A random forest guided tour. Test 2016. [Google Scholar] [CrossRef] [Green Version]
- Efron, B.; Hastie, T. Computer Age Statistical Inference; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001. [Google Scholar] [CrossRef] [Green Version]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [Green Version]
- Cutler, D.R.; Edwards, T.C.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. Random forests for classification in ecology. Ecology 2007. [Google Scholar] [CrossRef]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random forests for land cover classification. Pattern Recognit. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăgu, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Mahdavi, S.; Salehi, B.; Granger, J.; Amani, M.; Brisco, B.; Huang, W. Remote sensing for wetland classification: A comprehensive review. GIScience Remote Sens. 2018, 55, 623–658. [Google Scholar] [CrossRef]
- Chen, X.; Wang, M.; Zhang, H. The use of classification trees for bioinformatics. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011. [Google Scholar] [CrossRef]
- Goldstein, B.A.; Polley, E.C.; Briggs, F.B.S. Random forests for genetic association studies. Stat. Appl. Genet. Mol. Biol. 2011, 10, 32. [Google Scholar] [CrossRef]
- Chen, X.; Ishwaran, H. Random forests for genomic data analysis. Genomics 2012, 99, 323–329. [Google Scholar] [CrossRef] [Green Version]
- Elnabris, K.J.; Muzyed, S.K.; El-Ashgar, N.M. Heavy metal concentrations in some commercially important fishes and their contribution to heavy metals exposure in palestinian people of Gaza Strip (Palestine). J. Assoc. Arab Univ. Basic Appl. Sci. 2013, 13, 44–51. [Google Scholar] [CrossRef] [Green Version]
- Official Journal of the European Union, L 364/5, 20.12.2006., EC Directive, Directive 2006/1881/EC the Comission of the European Communities Setting Maximum Levels for Certain Contaminants in Foodstuffs; European Union: Brussels, Belgium, 2006.
- Tuzen, M. Toxic and essential trace elemental contents in fish species from the Black Sea, Turkey. Food Chem. Toxicol. 2009. [Google Scholar] [CrossRef]
- Kuplulu, O.; Iplikcioglu Cil, G.; Korkmaz, S.D.; Aykut, O.; Ozansoy, G. Determination of Metal Contamination in Seafood from the Black, Marmara, Aegean and Mediterranean Sea Metal Contamination in Seafood. J. Hell. Vet. Med. Soc. 2018. [Google Scholar] [CrossRef] [Green Version]
- Ergönül, M.B.; Altindağ, A. Heavy metal concentrations in the muscle tissues of seven commercial fish species from sinop coasts of the black sea. Rocz. Ochr. Sr. 2014, 16, 34–51. [Google Scholar]
- Nisbet, C.; Terzi, G.; Pilgir, O.; Sarac, N. Determination of heavy metal levels in fish samples collected from the middle Black Sea. Kafkas Univ. Vet. Fak. Derg. 2010, 16, 119–125. [Google Scholar]
- Bat, L.; Gundogdu, A.; Yardim, O.; Zoral, T.C. Heavy metal amounts in zooplankton and some commercial teleost fish from inner harbor of Sinop, Black Sea. Su Ürünleri Mühendisleri Dern. 2006, 25, 22–27. [Google Scholar]
- Nickel in Drinking-Water, Background Document for Development of WHO Guidelines for Drinking-Water Quality; (WHO/SDE/WSH/07.08/55); World Health Organization: Geneva, Switzerland, 2009.
- Copper in Drinking-Water, Background Document for Development of WHO Guidelines for Drinking-Water Quality; (WHO/SDE/WSH/03.04/88); World Health Organization: Geneva, Switzerland, 2004.
- Dietary Reference Intakes for Vitamin A, Vitamin K, Arsenic, Boron, Chromium, Copper, Iodine, Iron, Manganese, Molybdenum, Nickel, Silicon, Vanadium, and Zinc; Institute of Medicine: Washington, DC, USA, 2001.
- Murray, J.; Burt, J. The Composition of Fish; International Fisheries and Aquatic Research; SIFAR: Concorezzo, Italy, 2001. [Google Scholar]
- Kalantarian, S.H.; Rafee, G.H.; Farhangi, M.; Mojazi, A.B. Effect of different levels of dietary calcium and potassium on growth indices, biochemical composition and some whole body minerals in rainbow trout (Oncorhynchus mykiss) fingerlings. J. Aquac. Res. Dev. 2013. [Google Scholar] [CrossRef] [Green Version]
- Riba, I.; Del Valls, T.Á.; Forja, J.M.; Gómez-Parra, A. The influence of pH and salinity on the toxicity of heavy metals in sediment to the estuarine clam Ruditapes philippinarum. Environ. Toxicol. Chem. 2004, 23, 1100–1107. [Google Scholar] [CrossRef] [Green Version]
- Karar, S.; Hazra, S.; Das, S. Assessment of the heavy metal accumulation in the Blue Swimmer Crab (Portunus pelagicus), northern Bay of Bengal: Role of salinity. Mar. Pollut. Bull. 2019. [Google Scholar] [CrossRef]
- Bielmyer-Fraser, G.K.; Harper, B.; Picariello, C.; Albritton-Ford, A. The influence of salinity and water chemistry on acute toxicity of cadmium to two euryhaline fish species. Comp. Biochem. Physiol. Part C Toxicol. Pharmacol. 2018, 214, 23–27. [Google Scholar] [CrossRef]
- Rostern, N.T. The Effects of Some Metals in Acidified Waters on Aquatic Organisms. Oceanogr. Fish. Open Access J. 2017. [Google Scholar] [CrossRef] [Green Version]
- Mo, N. The Effects of Bioaccumulation of Heavy Metals on Fish Fin Over Two Years. J. Fish. Livest. Prod. 2016. [Google Scholar] [CrossRef]
- Ivanina, A.V.; Sokolova, I.M. Interactive effects of metal pollution and ocean acidification on physiology of marine organisms. Curr. Zool. 2015, 61, 653–668. [Google Scholar] [CrossRef]
- Jezierska, B.; Witeska, M. The Metal Uptake and Accumulation in Fish Living in Polluted Waters. In Soil and Water Pollution Monitoring, Protection and Remediation; Springer: Dodlerk, The Netherlands, 2007. [Google Scholar]
- Strungaru, S.A.; Nicoara, M.; Jitar, O.; Plavan, G. Influence of urban activity in modifying water parameters, concentration and uptake of heavy metals in Typha latifolia L. into a river that crosses an industrial city. J. Environ. Health Sci. Eng. 2015. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Martins, C.I.M.; Eding, E.H.; Verreth, J.A.J. The effect of recirculating aquaculture systems on the concentrations of heavy metals in culture water and tissues of Nile tilapia Oreochromis niloticus. Food Chem. 2011, 126, 1001–1005. [Google Scholar] [CrossRef]
- Roméo, M.; Siau, Y.; Sidoumou, Z.; Gnassia-Barelli, M. Heavy metal distribution in different fish species from the Mauritania coast. Sci. Total Environ. 1999, 232, 169–175. [Google Scholar] [CrossRef]
- Burada, A.; Topa, C.M.; Georgescu, L.P.; Teodorof, L.; Nastase, C.; Seceleanu-Odor, D.; Negrea, B.M.; Iticescu, C. Heavy metals accumulation in plankton and water of four aquatic complexes from Danube Delta area. AACL Bioflux 2014, 7, 301. [Google Scholar]
- Ekström, S.M.; Regnell, O.; Reader, H.E.; Nilsson, P.A.; Löfgren, S.; Kritzberg, E.S. Increasing concentrations of iron in surface waters as a consequence of reducing conditions in the catchment area. J. Geophys. Res. Biogeosci. 2016, 121, 479–493. [Google Scholar] [CrossRef] [Green Version]
- Weber, P.; Behr, E.R.; Knorr, C.D.L.; Vendruscolo, D.S.; Flores, E.M.M.; Dressler, V.L.; Baldisserotto, B. Metals in the water, sediment, and tissues of two fish species from different trophic levels in a subtropical Brazilian river. Microchem. J. 2013, 106, 61–66. [Google Scholar] [CrossRef]
- Sandhi, A.; Landberg, T.; Greger, M. Effect of pH, temperature, and oxygenation on arsenic phytofiltration by aquatic moss (Warnstorfia fluitans). J. Environ. Chem. Eng. 2018, 6, 3918–3925. [Google Scholar] [CrossRef]
- Ventura-Lima, J.; Bogo, M.R.; Monserrat, J.M. Arsenic toxicity in mammals and aquatic animals: A comparative biochemical approach. Ecotoxicol. Environ. Saf. 2011, 74, 211–218. [Google Scholar] [CrossRef] [Green Version]
- Anu, P.R.; Bijoy Nandan, S.; Jayachandran, P.R.; Don Xavier, N.D.; Midhun, A.M.; Mohan, D. Toxicity effects of zinc on two marine diatoms, under varying macronutrient environment. Mar. Environ. Res. 2018, 142, 275–285. [Google Scholar] [CrossRef]
- Zhou, X.; Sun, J.; Tian, Y.; Lu, B.; Hang, Y.; Chen, Q. Hyperspectral technique combined with deep learning algorithm for detection of compound heavy metals in lettuce. Food Chem. 2020, 321, 126503. [Google Scholar] [CrossRef] [PubMed]
- Manthey-Karl, M.; Lehmann, I.; Ostermeyer, U.; Schröder, U. Natural Chemical Composition of Commercial Fish Species: Characterisation of Pangasius, Wild and Farmed Turbot and Barramundi. Foods 2016, 5, 58. [Google Scholar] [CrossRef] [PubMed]
- Martínez, B.; Miranda, J.M.; Nebot, C.; Rodriguez, J.L.; Cepeda, A.F.C. Differentiation of Farmed and Wild Turbot (Psetta Maxima): Proximate Chemical Composition, Fatty Acid Profile, Trace Minerals and Antimicrobial Resistance of Contaminant Bacteria. Food Sci. Technol. Int. 2010, 16. [Google Scholar] [CrossRef]
- Lourenço, H.M.; Afonso, C.; Anacleto, P.; Martins, M.F.; Nunes, M.L.; Lino, A.R. Elemental composition of four farmed fish produced in Portugal. Int. J. Food Sci. Nutr. 2012, 63, 853–859. [Google Scholar] [CrossRef] [PubMed]
- Voigt, H.R. Heavy metals in the coastal environment around Nåtö, Lemland (Åland Islands, Baltic Sea). Memo. Soc. Pro Fauna Flora Fenn. 2014, 90, 5–12. [Google Scholar]
- Sures, B.; Taraschewski, H.; Rokicki, J. Lead and cadmium content of two cestodes, Monobothrium wageneri and Bothriocephalus scorpii and their fish hosts. Parasitol. Res. 1997. [Google Scholar] [CrossRef]
- Simionov, I.A.; Cristea, V.; Petrea, Ş.M.; Sîrbu, E.B. Evaluation of heavy metals concentration dynamics in fish from the black sea coastal area: An overview. Environ. Eng. Manag. J. 2019. [Google Scholar] [CrossRef]
- Mol, S.; Karakulak, F.S.; Ulusoy, S. Assessment of potential health risks of heavy metals to the general public in Turkey via consumption of red mullet, whiting, turbot from the southwest black sea. Turk. J. Fish. Aquat. Sci. 2017. [Google Scholar] [CrossRef]
- Das, Y.K.; Aksoy, A.; Baskaya, R.; Duyar, H.A.; Guvenc, D.; Boz, V. Heavy metal levels of some marine organisms collected in Samsun and Sinop coasts of Black Sea, in Turkey. J. Anim. Vet. Adv. 2009, 8, 496–499. [Google Scholar]
- Bat, L.; Şahin, F.; Üstün, F.; Sezgin, M. Distribution of Zn, Cu, Pb and Cd in the Tissues and Organs of Psetta Maxima from Sinop Coasts of the Black Sea, Turkey. Mar. Sci. 2012. [Google Scholar] [CrossRef] [Green Version]
- Bat, L.; Sahin, F.O.A. Heavy metal contamination of Pleuronectiformes species from Sinop coasts of the Black Sea. Sustain. Agric. Food Environ. Res. 2019. [Google Scholar] [CrossRef]
- Giragosov, V.; Khanaychenko, A. The state-of-art of the Black Sea turbot spawning population off crimea (1998–2010). Turk. J. Fish. Aquat. Sci. 2012. [Google Scholar] [CrossRef]
- Aygun, S.F.; Abanoz, F.G. Determination of heavy metal in anchovy (Engraulis encrasicolus L 1758) and whiting (Merlangius merlangus euxinus, Nordman, 1840) fish in the middle black sea. Kafkas Univ. Vet. Fak. Derg. 2011, 17, S145–S152. [Google Scholar]
- Caador, I.; Costa, J.L.; Duarte, B.; Silva, G.; Medeiros, J.P.; Azeda, C.; Castro, N.; Freitas, J.; Pedro, S.; Almeida, P.R.; et al. Macroinvertebrates and fishes as biomonitors of heavy metal concentration in the Seixal Bay (Tagus estuary): Which species perform better? Ecol. Indic. 2012. [Google Scholar] [CrossRef]
- Hussein, A.; Khaled, A. Determination of metals in tuna species and bivalves from Alexandria, Egypt. Egypt. J. Aquat. Res. 2014. [Google Scholar] [CrossRef] [Green Version]
- Uysal, K.; Emre, Y.; Köse, E. The determination of heavy metal accumulation ratios in muscle, skin and gills of some migratory fish species by inductively coupled plasma-optical emission spectrometry (ICP-OES) in Beymelek Lagoon (Antalya/Turkey). Microchem. J. 2008. [Google Scholar] [CrossRef]
- Acar, O. Determination of cadmium and lead in biological samples by Zeeman ETAAS using various chemical modifiers. Talanta 2001. [Google Scholar] [CrossRef]
- Doner, G.; Akman, S. A comparison of sample preparation procedures for the determination of iron and zinc in bulgur wheat by graphite furnace atomic absorption spectrometry. Anal. Lett. 2000. [Google Scholar] [CrossRef]
- Huang, Y.L.; Chuang, I.C.; Pan, C.H.; Hsiech, C.; Shi, T.S.; Lin, T.H. Determination of chromium in whole blood and urine by graphite furnace AAS. At. Spectrosc. 2000, 21, 10–16. [Google Scholar]
- Tüzen, M. Determination of heavy metals in fish samples of the middle Black Sea (Turkey) by graphite furnace atomic absorption spectrometry. Food Chem. 2003. [Google Scholar] [CrossRef]
- Biau, G. Analysis of a random forests model. J. Mach. Learn. Res. 2012, 13, 1063–1095. [Google Scholar]
- Bifeng, H.; Xue, J.; Zhou, Y.; Shuai, S.; Zhiyi, F.; Yan, L.; Songchao, C.; Lin, Q.; Zhou, S. Modelling bioaccumulation of heavy metals in soil-crop ecosystems and identifying its controlling factors using machine learning. Environ. Pollut. 2020. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; MIT Press: Cambridge, MA, USA, 2017; ISBN 9781351460491. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2000; ISBN 978-1-4614-7137-0. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. Elements of Statistical Learning, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2009; ISBN 9780387848570. [Google Scholar]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Grömping, U. Variable importance in regression models. Wiley Interdiscip. Rev. Comput. Stat. 2015, 7, 137–152. [Google Scholar] [CrossRef]
- Verikas, A.; Gelzinis, A.; Bacauskiene, M. Mining data with random forests: A survey and results of new tests. Pattern Recognit. 2011. [Google Scholar] [CrossRef]
- Boulesteix, A.L.; Janitza, S.; Kruppa, J.; König, I.R. Overview of random forest methodology and practical guidance with emphasis on computational biology and bioinformatics. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012. [Google Scholar] [CrossRef] [Green Version]
- Díaz-Uriarte, R.; Alvarez de Andrés, S. Gene selection and classification of microarray data using random forest. BMC Bioinform. 2006. [Google Scholar] [CrossRef] [Green Version]
- Ziegler, A.; König, I.R. Mining data with random forests: Current options for real-world applications. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2014. [Google Scholar] [CrossRef]
- Athey, S.; Tibshirani, J.; Wager, S. Generalized random forests. Ann. Stat. 2019. [Google Scholar] [CrossRef] [Green Version]



| Parameter | Weight 1 | Weight 2 | Weight 3 | Weight 4 | Weight 5 | Total | Total Per Element |
|---|---|---|---|---|---|---|---|
| Ca muscle | - | 1 | 2 | 1 | 2 | 6 | 14 |
| Ca liver | 3 | 2 | 1 | - | 2 | 8 | |
| K muscle | 2 | 2 | - | 1 | 1 | 6 | 12 |
| K liver | - | 2 | 3 | 1 | - | 6 | |
| Zn muscle | 1 | - | 1 | 1 | - | 3 | 13 |
| Zn liver | 1 | 2 | 4 | 1 | 2 | 10 | |
| Mg muscle | 2 | - | - | 2 | 1 | 5 | 10 |
| Mg liver | 1 | 1 | 1 | - | 2 | 5 | |
| Ni muscle | 2 | - | - | 1 | - | 3 | 8 |
| Ni liver | 1 | 2 | 1 | 2 | 6 | ||
| Fe muscle | 2 | 2 | 1 | - | 1 | 6 | 8 |
| Fe liver | - | 1 | - | 1 | - | 2 | |
| Na muscle | 2 | - | - | 3 | - | 5 | 8 |
| Na liver | 3 | - | - | - | - | 3 | |
| Cu muscle | - | 1 | - | 1 | 1 | 3 | 5 |
| Cu liver | - | 1 | - | - | 1 | 2 | |
| Mn muscle | - | - | - | 1 | 1 | 2 | 5 |
| Mn liver | - | - | 2 | 1 | - | 3 | |
| Cd muscle | - | - | - | 1 | 1 | 2 | 5 |
| Cd liver | 1 | 2 | - | - | - | 3 | |
| As muscle | - | - | 2 | 1 | - | 3 | 5 |
| As liver | 1 | 1 | -- | - | 2 |
| No. | Characteristic | Authors |
|---|---|---|
| 1 | Predictive performance | [58,127] |
| 2 | No overfitting | [127] |
| 3 | Highly Flexible | [126,128,129] |
| 4 | Can capture non-linear dependencies | [126] |
| 5 | Robust when noise is present | [127] |
| 6 | Formalized predictor significance | [58,127,128] |
| 7 | Fast | [128] |
| 8 | Suitable for small datasets | [58] |
| 9 | Efficient when interactions are present | [126] |
| 10 | Small number of model parameters | [58] |
| 11 | Stable | [129] |
| 12 | Good for high dimensional data | [127] |
| 13 | Various type of problems | [58] |
| 14 | Straightforward to use | [129] |
| 15 | Can handle highly correlated predictor variables | [128] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Petrea, Ș.-M.; Costache, M.; Cristea, D.; Strungaru, Ș.-A.; Simionov, I.-A.; Mogodan, A.; Oprica, L.; Cristea, V. A Machine Learning Approach in Analyzing Bioaccumulation of Heavy Metals in Turbot Tissues. Molecules 2020, 25, 4696. https://doi.org/10.3390/molecules25204696
Petrea Ș-M, Costache M, Cristea D, Strungaru Ș-A, Simionov I-A, Mogodan A, Oprica L, Cristea V. A Machine Learning Approach in Analyzing Bioaccumulation of Heavy Metals in Turbot Tissues. Molecules. 2020; 25(20):4696. https://doi.org/10.3390/molecules25204696
Chicago/Turabian StylePetrea, Ștefan-Mihai, Mioara Costache, Dragoș Cristea, Ștefan-Adrian Strungaru, Ira-Adeline Simionov, Alina Mogodan, Lacramioara Oprica, and Victor Cristea. 2020. "A Machine Learning Approach in Analyzing Bioaccumulation of Heavy Metals in Turbot Tissues" Molecules 25, no. 20: 4696. https://doi.org/10.3390/molecules25204696
APA StylePetrea, Ș. -M., Costache, M., Cristea, D., Strungaru, Ș. -A., Simionov, I. -A., Mogodan, A., Oprica, L., & Cristea, V. (2020). A Machine Learning Approach in Analyzing Bioaccumulation of Heavy Metals in Turbot Tissues. Molecules, 25(20), 4696. https://doi.org/10.3390/molecules25204696