1. Introduction
In the analytical chemistry field, it is often essential to separate the components of a mixture to analyze them. Either to identify some components of the mixture or to quantitate them. Multiple separation modes exist to carry this out and reversed-phase liquid chromatography (RP-LC) is one of the most frequent in pharmaceutical analysis. It is also commonly used in other fields such as biochemistry, agricultural sciences, and environmental sciences. To achieve the separation of the different compounds in a mixture in RP-LC, several parameters must be defined and optimized such as stationary phase, mobile phase composition, gradient slope, gradient time, etc. Therefore, the development of an RP-LC method is generally a time-consuming and tedious process. Method development follows a minimum of two experimental phases: screening and optimization phases. The purpose of the screening phase is to acquire knowledge of the experimental space and to identify the parameters and their combinations that have a significant impact on the retention of the compounds. Only the parameters (and their combinations) that are found to be significant are kept for further optimization leading to a reduction in the number of parameters to tune during the next phase. The optimization phase takes place to reach the optimal values for each parameter (i.e., the best conditions) to achieve the separation under some constraints. In addition, robust optimization allows for ensuring the robustness of the method against small variations of the controlled parameters [
1]. These two steps are usually performed with the design of experiment (DoE) methodology. Indeed, this methodology is often presented as a better alternative to one-factor-at-a-time (OFAT) designs [
2]. Besides the benefit of acquiring the information in fewer experiments, the DoE methodology offers the possibility to model the interaction between the distinct parameters. The relationship between the parameters and the studied response may be analyzed with the response surface methodology (RSM). The RSM is developed to study the direction, amplitude and shape of the effect of the parameters on the response, and predict and optimize the response. It defines an equation that models the effect of the parameters on the response. Thanks to this equation, the effect of the parameters and their best combination can be inferred [
1,
3,
4].
Response optimization can be simple when it concerns only one response but it may be complex as it is generally necessary to optimize multiple responses at the same time. In the field of chromatography, this may be interpreted as the fact that peak separation is not the only objective. Indeed, several constraints regarding the sensitivity of the detection, the analysis time, etc. are included in the decision process [
5]. Different approaches were developed to achieve the best compromise between these different criteria, called multiple criteria decision analysis (MCDA). The most popular in the analytical chemistry field is desirability [
1]. To apply it, an individual desirability function is defined for each criterion, to normalize it and specify if the criterion is maximized, minimized or targeted at a specific value. Eventually, it combines all those values, sometimes with different weights, in a single desirability index, with a global desirability function. Some of the advantages of this methodology are that it is easy to understand, easy to use, and versatile. It also comes with a few disadvantages such as the number of parameters to define the functions or the subjectivity of the definition of the weights [
6]. Another one of its disadvantages is that the optimal solution found might be sensitive to the weights attributed to each criterion.
Generally, the development of a chromatographic method begins with some experiments defined by the DoE methodology. Modeling the retention behaviors would help reduce the number of preliminary experiments realized by in silico simulations. Different approaches were developed in an attempt to understand or represent the underlying mechanisms of retention [
7,
8]. Those are useful when it is necessary to explore a large number of conditions to pick the condition that best fits the requirements. To model the chromatographic behavior of molecules as precisely as possible, several mechanistic models were developed. Some are (semi-)empirical such as the linear solvent strength (LSS) [
9] and the Neue–Kuss [
10] models. Others are based on the chemical or physical phenomenon or both partitioning such as the linear free energy relationships (LFER) models, the hydrophobic-subtraction model (HSM) [
11] or the linear solvation energy relationship (LSER) [
12]. They generally offer good performances but they are limited to predicting the retention of compounds that have already been analyzed, therefore they do not completely resolve the issue of the experimental work for new unknown compounds. Several pieces of software enable the performing of these optimizations, among which DryLab™ (Molnar Institute, Berlin, Germany) is possibly the most well-known [
13,
14]. The development of a method for a new sample of known composition that has never been analyzed before generally requires models using a different approach known as quantitative structure–retention relationship (QSRR) models [
15]. The QSRR models are a broad family of models defined only, as its name suggests, by the input and output of the model. They are constructed by establishing a mathematical relationship between structurally derived molecular properties of the compounds that are called molecular descriptors and the target retention time. For this relationship to be assessed, it would need a large number of diversified analytes to cover the range of descriptors for the analytes typically encountered in this analytical context [
16]. Unlike other retention theories, multiple generic underlying models were applied. Some examples of implemented models are the multi-linear regression (MLR) [
17,
18] or the partial least squares (PLS) regression [
19,
20] but more advanced models such as decision tree-based methods [
21,
22,
23] or artificial neural networks [
24,
25] were also used.
However, QSRR models are often limited to predictions for the single chromatographic condition used for their training [
7]. Different research teams have proposed alternatives to overcome this constraint. Muteki et al., proposed an improved QSRR model with descriptors of the mobile and stationary phases adjoining the descriptors of the compounds with an L-PLS model [
26]. Taraji et al., proposed joining the outputs of several QSRR models with RSM [
27]. Wiczling et al., proposed a mechanistic multilevel Bayesian model for monoprotic compounds. They concluded that providing experimental data (at least four for mixtures of compounds) was needed to have accurate predictions [
28,
29].
Joining and optimizing multiple QSRR models with RSM followed by an MCDA would offer a remarkably interesting strategy to assist and accelerate the method development. In this study, a different way of selecting the RSM equation will be tested. The proposed selection will be based on the pKa of the modeled compound to reflect the knowledge of the chemical properties in the retention behavior. The different criteria are calculated in a way to make them robust to the prediction error. A new approach for the MCDA is also developed to work with a distribution of weights instead of fixed values. The proposed strategy allows the user to consider different characteristics desired for the developed method while attributing their relative importance without the complexity of assigning the exact weights that would represent their reasoning. The work presented here is part of a strategy to carry out in silico screening for a reversed-phase liquid chromatography method for small pharmaceutical compounds. In the whole strategy, it would be preceded by QSRR models built on a dataset composed of diverse pharmaceutical-related molecules. Doing this makes it applicable to a wide range of compounds. Those models predict the retention time of known new compounds in known conditions. The objective of this study is to demonstrate that this part of the strategy is efficient and adequate when combined with QSRR models. To demonstrate the good performance of this part of the strategy, it will be applied directly to experimental retention times to assess this part independently and be free from the error of the QSRR models.
2. Results and Discussion
This article is divided into two sections focusing on the RSM and the MCDA defined in this study. Each of them will use a specific set of compounds for the different evaluations. For the RSM section, a small test set composed of 4-nitrophenol, ibuprofen, papaverine, and pindolol is used. For the MCDA section, a bigger test set is used to put the strategy under stress. This larger test set is composed of 2,2′-bipyridine, 4-nitrophenol, ibuprofen, metoclopramide, papaverine, pindolol, and verapamil.
2.1. Response Surface Methodology
2.1.1. Model Development
All the models were built following the procedure described hereunder. Following the principles of design of experiments for factors of more than two levels (there are five levels for the pH), the response surface methodology is applied for each compound. More precisely, it means that a polynomial equation composed of the different factors is fitted to tune the factor coefficient to model the response. In our case, an equation composed of the pH and the slope of the organic modifier gradient is built to predict the retention time of the compound. A stepwise regression is commonly used as it will remove or add (or both) different factors in the equation in multiple steps to find the “best” model according to some criteria, for example, the Akaike information criterion. The strategy proposed in this study differs from this last point. This strategy defines three equations that are fixed: Equations (1)–(3). Instead of removing or adding factors, the equations are chosen for specific cases. The different cases are defined based on the fact that the behavior of the retention time of a compound as a function of the pH follows a sigmoidal curve and that the pH range covered is limited Using only an equation with the relevant factors will limit the number of parameters to tune and the prediction of non-relevant chromatographic behaviors (e.g., pH independence for neutral compounds). In this case, the models were not fit to find the shape of the relationship between the retention time and the pH, and the gradient time. Here, the shape of the relationship is known for three specific cases and information about the sample is used to choose the best equation.
Considering the pH range covered (from 2.7 to 8.0), three different chromatographic behaviors can be observed. The first one is when the pH does not influence the retention. In this case, the equation does not contain the pH as a factor (Equation (1)). The second one is when the pH influences the retention but only one plateau of the sigmoidal curve is observable. This happens when the relevant pKa is close to one of the limits of the pH range covered. In this case, the equation contains the pH with a first- and second-degree factor (Equation (2)). The third one is when the pH also has an effect on the retention and two plateaus are observable. This happens when the relevant pKa is in the middle of the pH range covered. In this case, the equation contains a first-, a second-, and a third-degree factor for the pH to approximate the sigmoidal curve (Equation (3)).
The gradient time is modeled as a linear effect and is included as a first-degree factor.
For all the equations, it is the logarithm of the retention time that is modeled because it gives better performances than modeling the retention time without transformation [
30].
To account for the error of the models, a Student’s t distribution was used to define the distribution of retention time for each model. The degrees of freedom of the distribution were corresponding to the degrees of freedom of the model. The distribution was then scaled with the standard deviation of the residuals and located to the predicted retention time before being sampled.
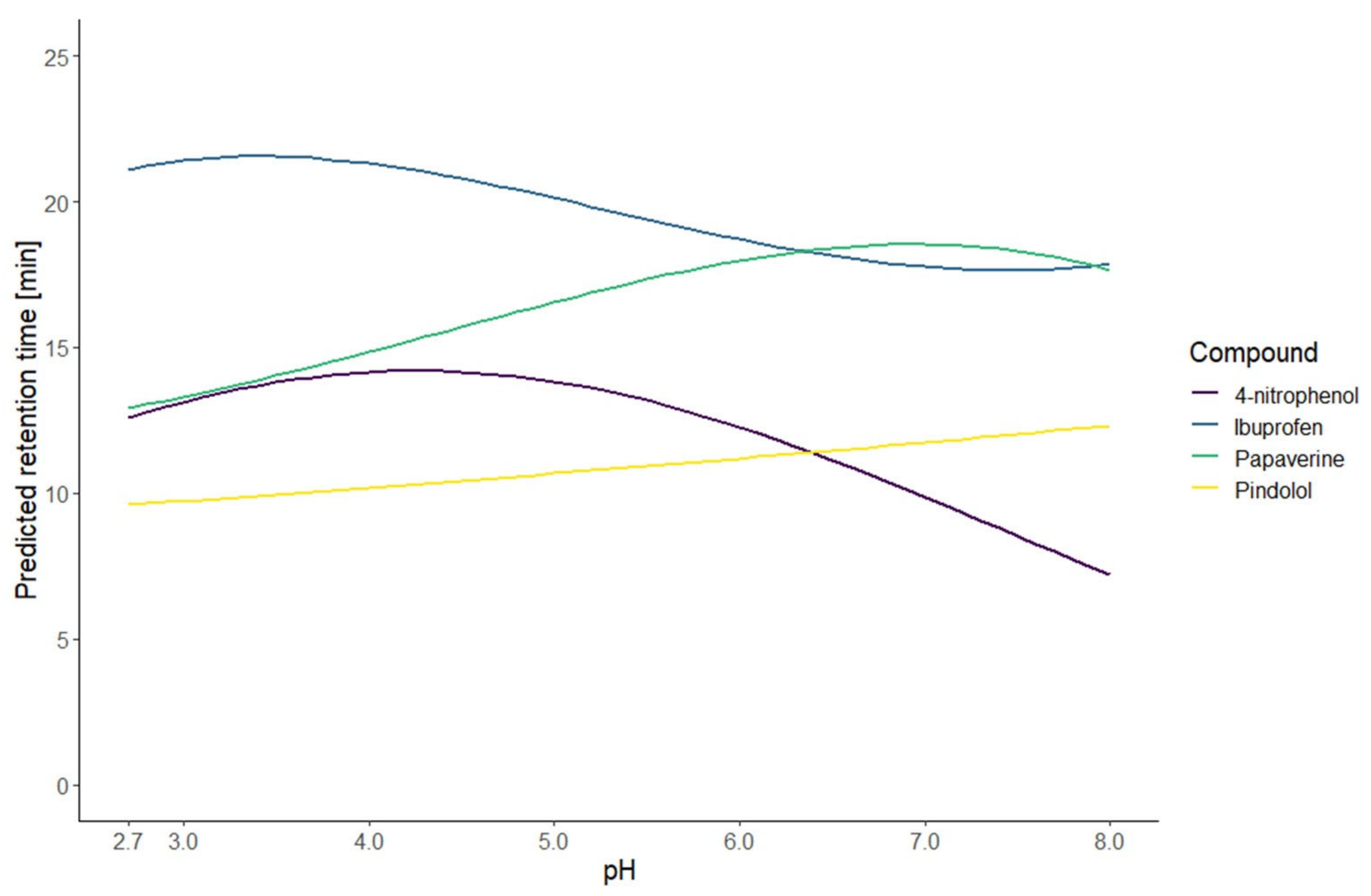
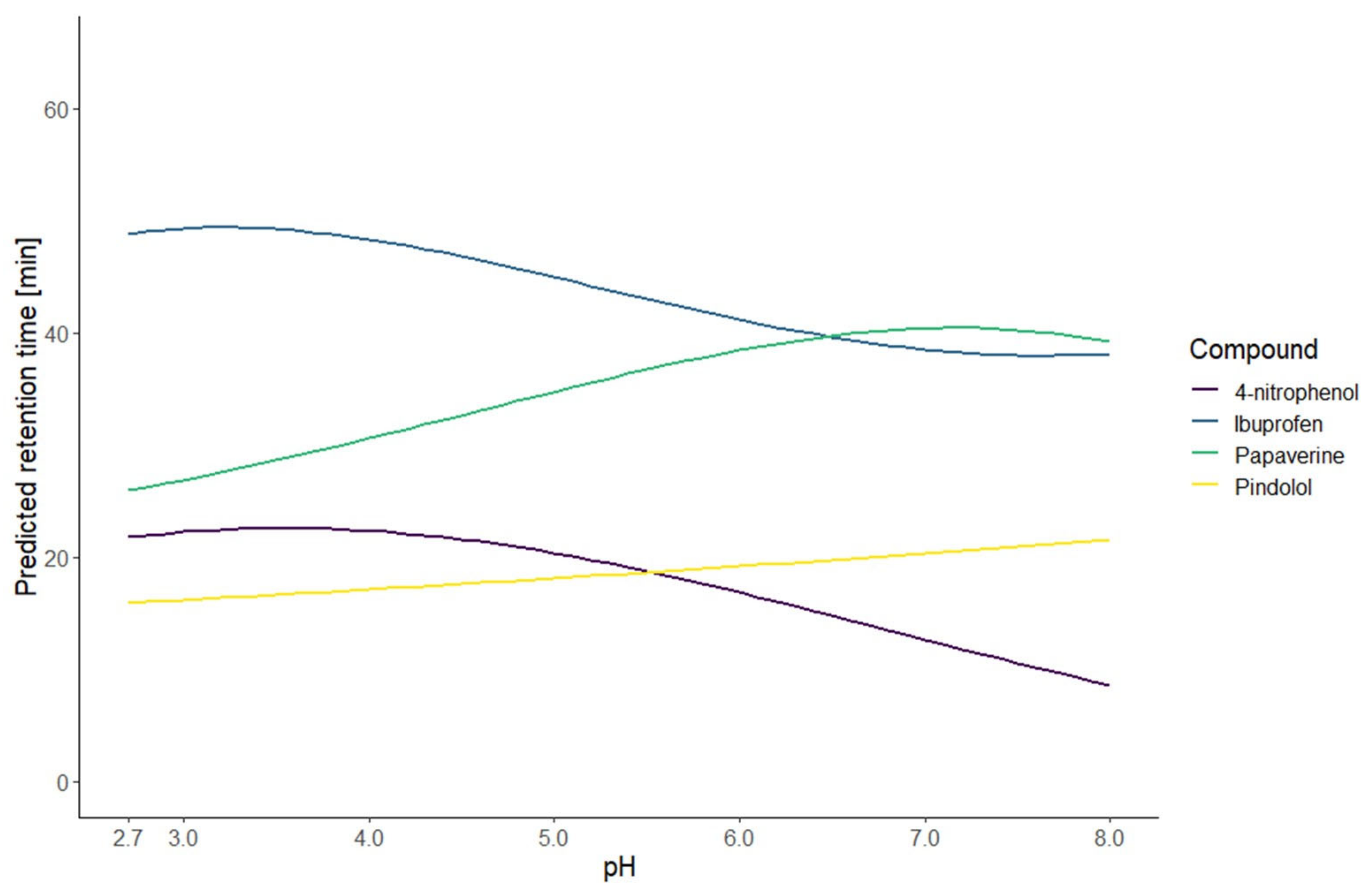
2.1.2. Case Study—Test Set 1
The resulting models of the application of this strategy are illustrated by the predicted retention time curves in
Figure 1 and
Figure 2. To evaluate the first part of the presented strategy, the models were calculated on the first test set. The performance was evaluated with three measurements: the coefficient of determination (R
2), the root mean squared error (RMSE), and the mean absolute percentage error (MAPE) of calibration (RMSEC and MAPE
C) calculated with the data of ten conditions used to build the model and the RMSE and MAPE of prediction (RMSEP and MAPE
P) calculated with the data of two new external conditions. The values presented in
Table 1 show that the model fits the data well. Comparing the values of calibration and prediction, the performance is similar regarding the RMSE, except for the papaverine, meaning that there was no overfitting. The absolute and relative errors shown in
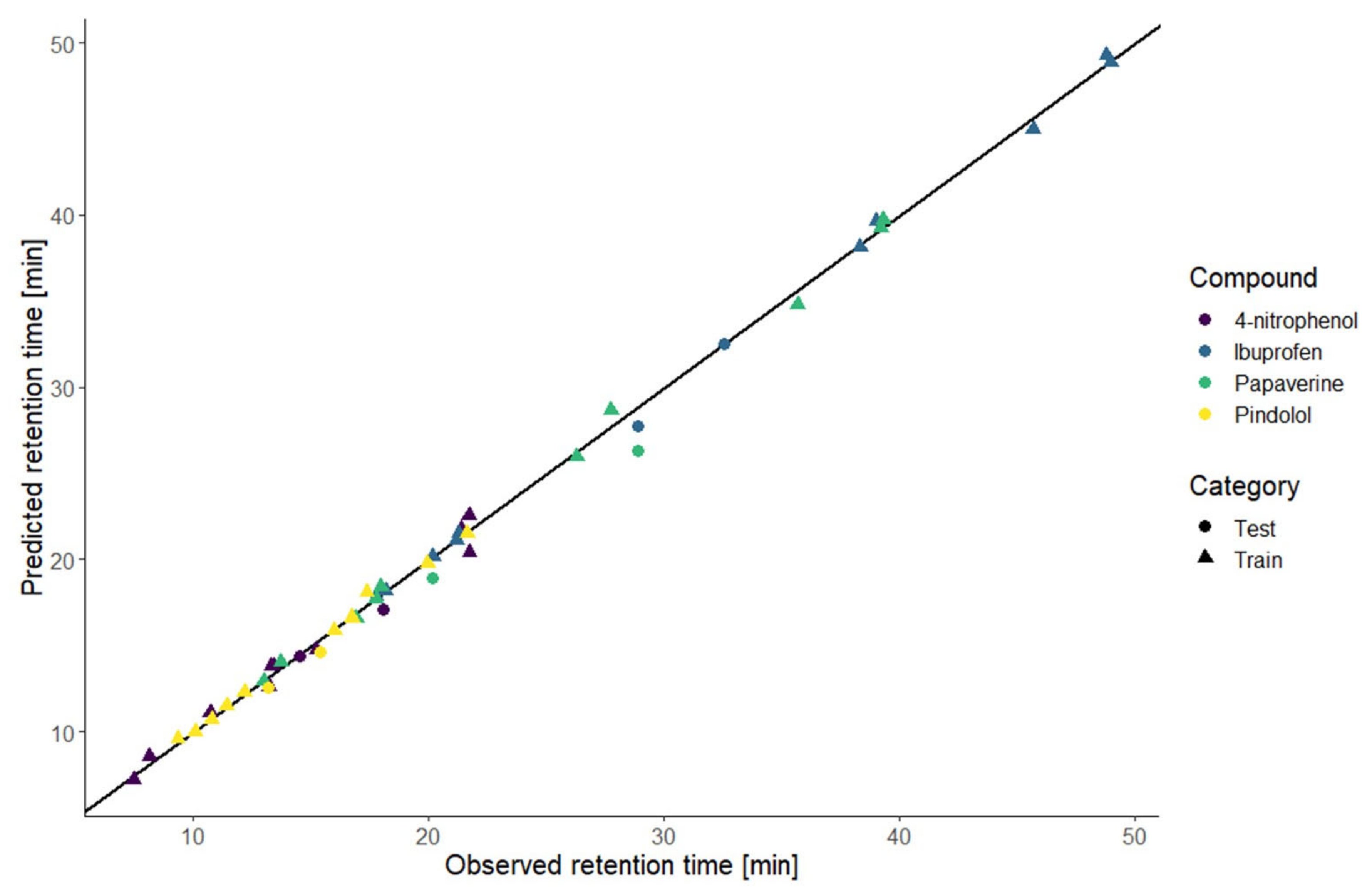
Table 2 indicate that the models predicted well the new conditions. For the papaverine, the performances were a bit worse therefore we could expect the prediction to be poor. The comparison of the predicted and observed retention times for the training and new conditions are illustrated in
Figure 3. This graphic shows the high correlation between the predicted and observed retention times. Those results indicate that the prediction at an intermediate gradient time does not suffer too much from the limitation to a first-degree factor. Furthermore, the results also demonstrate that the choice of the equation to model the retention time based only on the knowledge of the nature of the compound is enough to have accurate predictions.
2.2. Multiple-Criteria Decision Analysis
2.2.1. Method Development
To automate the selection of the best experimental condition, multiple criteria were defined and their responses were gathered into a desirability index.
The following criteria were defined:
The separation: this was defined as the distance between the peaks of the critical pair at the baseline. It was determined by calculating the difference between the retention times that were sampled from the prediction distributions in each condition for each pair of peaks. From this difference, the half-width of the peaks at the baseline was subtracted to represent the real separation of the peaks. Because only the retention time is predicted, both the left and right expected half-width of each peak must be provided by the user. By allowing to provide a left and a right half-width of the peak, the asymmetry of the peak can be considered. This feature is much more useful in the case of a very large difference in concentration or absorbance of the compounds. One extreme example would be the case of the development of a method for the analysis of the impurities of degradation of an active pharmaceutical ingredient (API). The impurities would be in a much lower concentration than the API hence the peaks are much narrower. Such a difference in peak width is important to consider. For the final calculation of the criteria, the 10% percentile of the distribution of difference for each pair of peaks was conserved and the minimum of those values was kept as the result for each condition (Equation (4));
The sensitivity to experimental parameters (robustness of the prediction): this was defined as the rate of change of the separation criteria in the function of the experimental parameters. It was determined by calculating the derivative of the separation in the direction of each criterion and then averaging the absolute values of both derivatives (Equation (5));
The analysis time: this was defined as the minimum analysis time needed to analyze all the compounds in the sample. It was determined by calculating the maximum of the 90% percentile predicted retention time of each compound (Equation (6)).
where
is the separation at pH p and gradient time g;
is a function that gives the 10% quantile;
is the retention time of compound i when ordered by decreasing retention time;
is the left baseline half-width of compound i;
is the right baseline half-width of compound i + 1;
is the identity matrix of dimension n; and M is the number of compounds.
where
is the sensitivity at pH p and gradient time g;
is the rate of change of the separation criterion in the direction of the pH for the considered condition; and
is the rate of change of the separation criterion in the direction of the gradient time for the considered condition.
where
is the analysis time at pH p and gradient time g.
For each of these criteria, a desirability function was defined following the work of Govaerts and Le Bailly de Tilleghem [
31]. The desirability function was designed to maximize the separation, maximize the robustness of the prediction, and minimize the analysis time criteria. Each function parameter was calculated from the lower and upper limits of the criterion. For this study, the minimum value of the criteria was used as the lower limit and the maximum value of the criteria as the upper limit. With this definition, the user does not need to specify the different limits for each criterion. The response of each of these desirability functions was then gathered in a single value, the desirability index, by calculating their weighted geometric mean. The geometric mean is used because it is more restrictive. It would cancel out (the desirability index would be zero) in the extreme case the desirability of one criterion is zero [
5]. The best condition (with the highest desirability index) represents the best compromise between the different criteria that are available (Equation (7)).
The weights are specified by relative importance that emulates the needs of the user:
The separation criterion was assigned a weight of 1. This is the main criterion to achieve a “must have”;
The sensitivity to experimental parameters criterion was assigned a weight of 0.5;
The analysis time criterion was assigned a weight of 0.1. A short analysis time is preferable but not at the cost of separation. It is “nice to have”.
where
is the desirability index at pH p and gradient time g;
is the desirability function for criteria i; and
is the weight of criteria i.
The desirability index threshold determining the optimal conditions was chosen so that the separation criterion is always greater than 0. In the case of the second test set, this corresponded to a desirability index of 0.5.
To render the desirability index less sensitive to the arbitrary choice of the weights, a Dirichlet distribution was constructed based on the previously defined weights multiplied by a factor representing the confidence in those weights. The different ratios of the weights define the location of the distribution. The confidence factor will define the scale of the distribution and it is set at 100 in this study. From this distribution, multiple vectors of weights were sampled and used to calculate the probability to reach the desirability index threshold. This probability is set at 30% because it was for the screening phase and a high chance of success was not needed.
2.2.2. Case Study—Test Set 2
The MCDA strategy was evaluated with the second test set. For the separation criterion, the half-width of all the peaks was defined at 0.5 min.
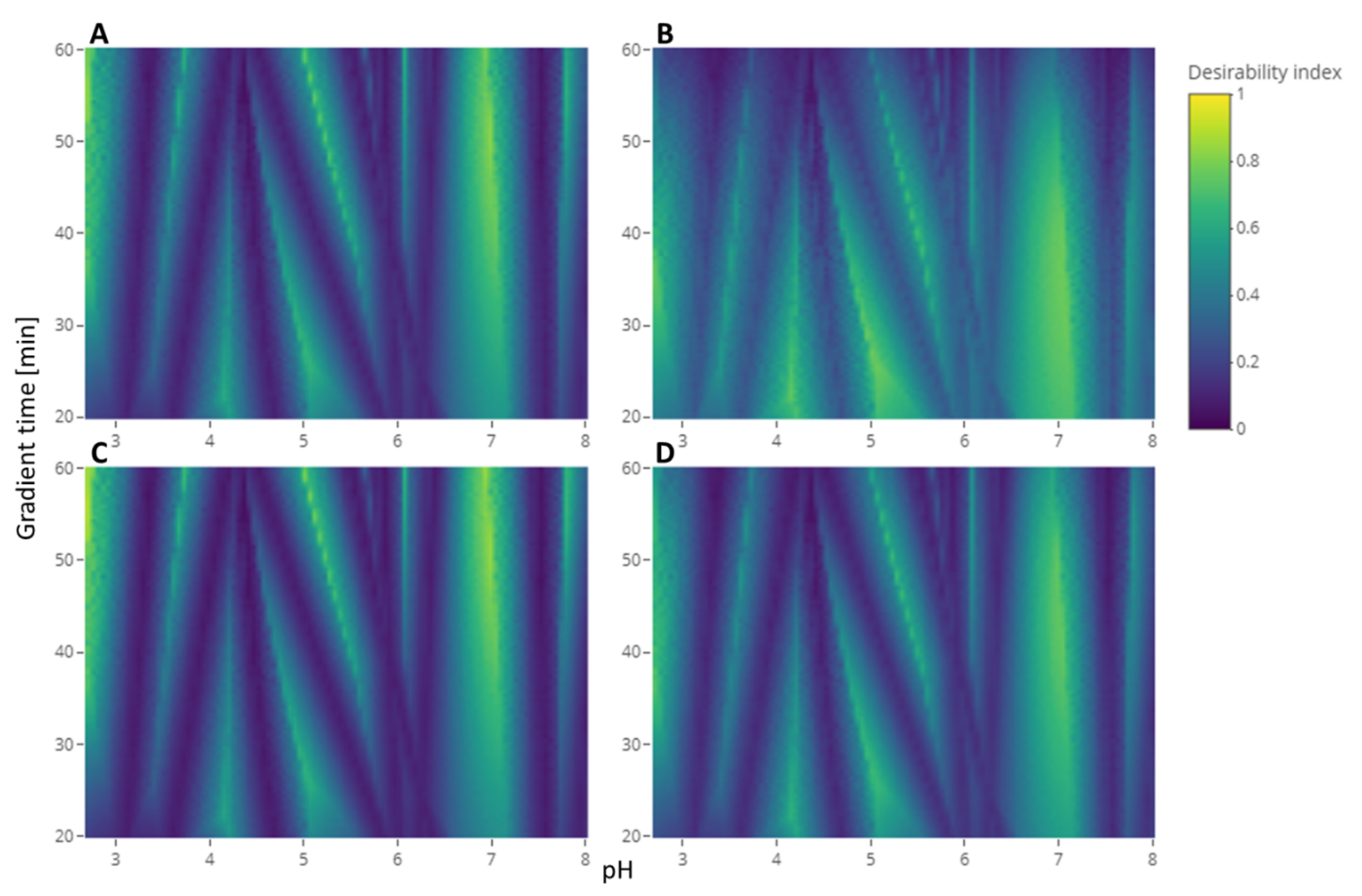
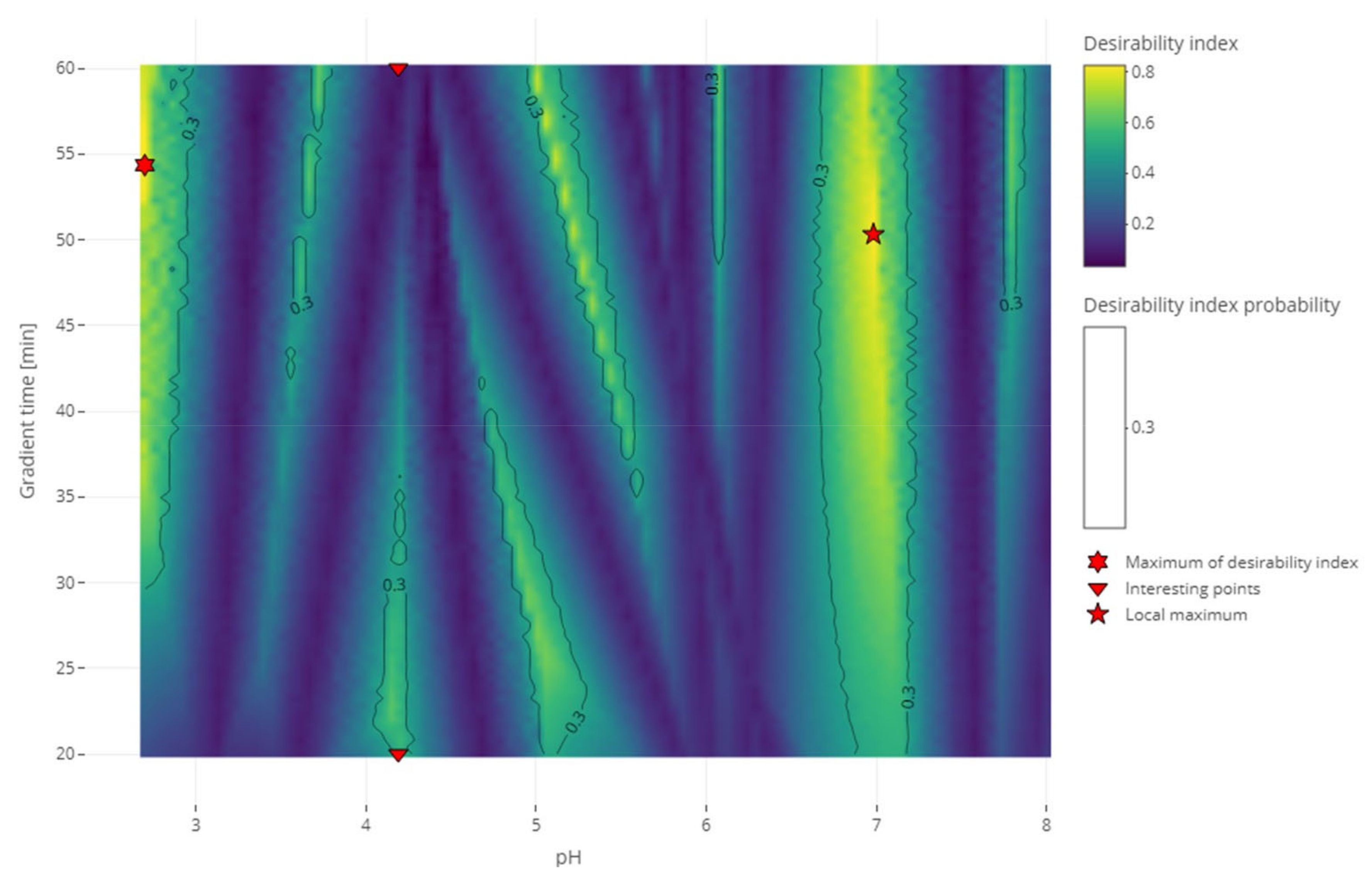
Figure 4 shows different heatmaps of the desirability index of the experimental conditions with different weights attributed to each criterion.
Figure 4A shows the heatmap with the weights that we proposed for this strategy: 1 for the separation criterion, 0.5 for the sensitivity to experimental parameters criterion, and 0.1 for the analysis time criterion. It can be compared to the heatmap of the application of the same strategy without weighting the criteria differently shown in
Figure 4B where all the weights are 1. Giving the same importance to all the criteria leads to less relative importance of the separation criteria, which results in a slimming of the dark blue bands characteristic of the coelution of two compounds. On the contrary,
Figure 4C shows the heatmap where the weights for the sensitivity to the experimental parameters and the analysis time criteria are decreased a little, increasing the relative importance of the separation criterion. On this heatmap, compared to the original, the slim yellow band showing the best condition is brighter. This phenomenon is even more clear in the upper part of the graph because those regions with long gradient times are less penalized by the analysis time criterion. The opposite of this last phenomenon can be observed in
Figure 4D, where this part of the graph is darker than the original. This is resulting from the increase in the analysis criterion weight. The comparison of those heatmaps exhibited the sensitivity of the resulting desirability index to the weights assigned by the user to each criterion. Added to the difficulty for the user to find the correct arbitrary value that will represent its interest the best, complementing the calculation of the desirability index with a distribution of weights would give more confidence in the result. Indeed, after selecting the threshold of the desirability index, the probability to reach this threshold was calculated with different combinations of weights sampled from the distribution. The conditions selected as a result would have a high desirability index in a lot of the weights combinations meaning it was not sensitive to the variations of those weights.
Figure 5 shows the results of the RSM combined with the MCDA strategy applied to the second test set. One can see that the coelution of different compounds is clearly identified with the dark bands of the desirability index. Different regions with a high desirability index can also be identified. Depending on the objective of the analyst, some of those regions can be selected to continue the method development further. The recommendations regarding the lifecycle management of analytical methods begin to change (the International Council for Harmonisation (ICH) is updating the Q2 and creating the Q14 guidelines) [
32,
33]. This will impact the way the analytical methods are developed. Instead of only focusing on the separation (the original objective of HPLC) and the robustness (the objective of analytical quality by design), the newly developed method could be developed to attain other objectives in anticipation of its lifecycle. One of the modifications presented in the ICH Q14 under public consultation is the submission of parameter ranges instead of parameter values for the analytical conditions and that, provided it is regulatory approved, moving within the parameter range does not require notifying the regulatory authorities [
33]. To give a few examples of when the need to change the analytical conditions occurs in a regulated environment, it could happen for a method used to analyze the impurities during stability studies or used the quality control of a drug product [
34]. In the case of the stability studies, the method is developed considering the impurities observed at the beginning of the stability study, but a new impurity might appear and if it coelutes with another of the peaks it would be required to conduct the analysis in another condition. In the case of quality control, a change of condition could be needed after a change of excipient. Although the strategy presented in this article is about the screening phase, it is relevant to already account for the objectives to achieve in the final method. Robustness has already been discussed as being part of the strategy presented in this study thanks to the second criterion. Regarding the lifecycle of the method and the possibility to change the conditions during its lifetime, this is an ambition that will be examined at the end of the strategy. To account for those objectives, two conditions will be investigated. The first one is the condition with the highest desirability index value overall (the global maximum) and the second one is the condition with the highest desirability index value in the largest region selected (local maximum). Those conditions are highlighted in
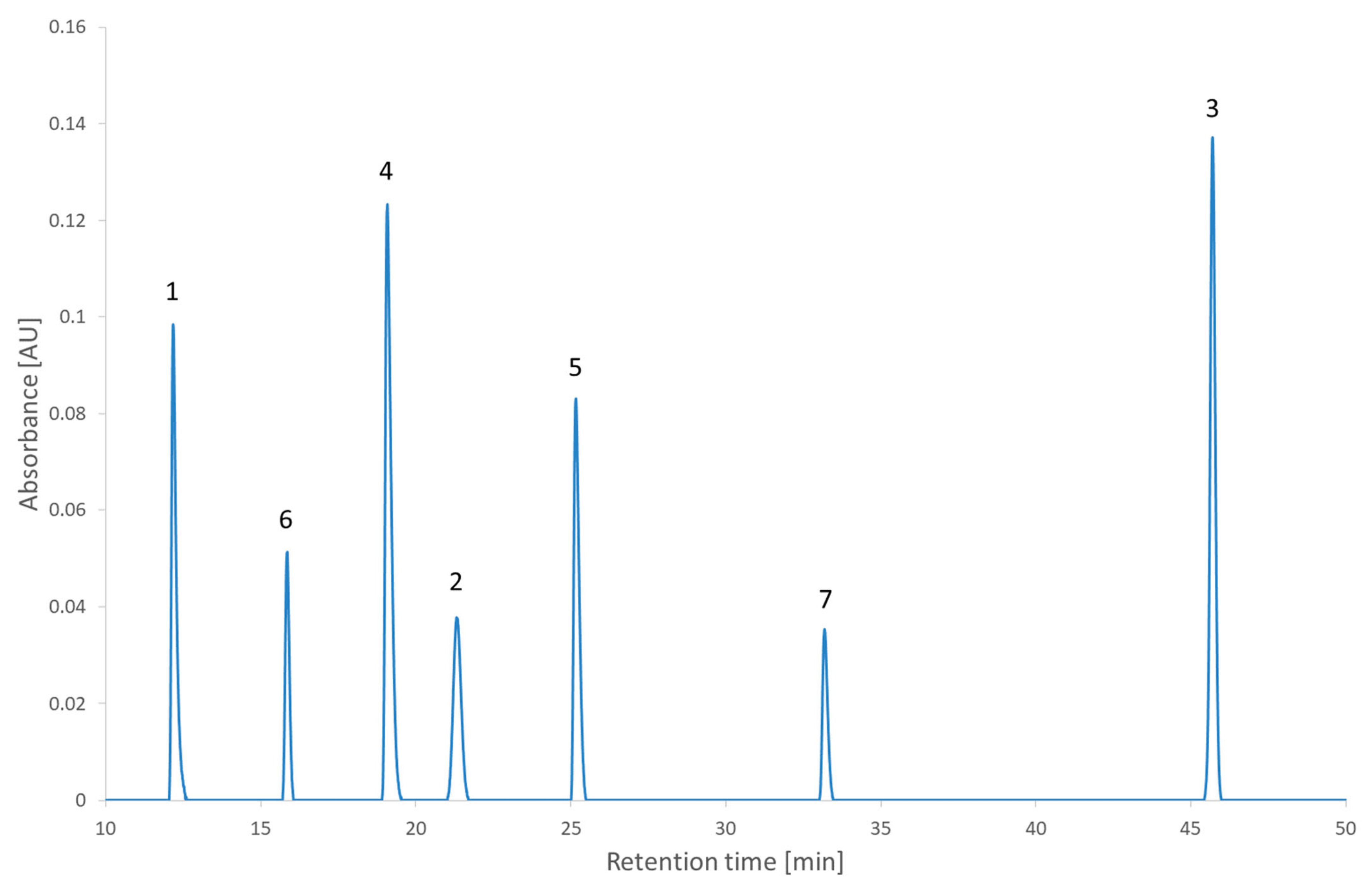
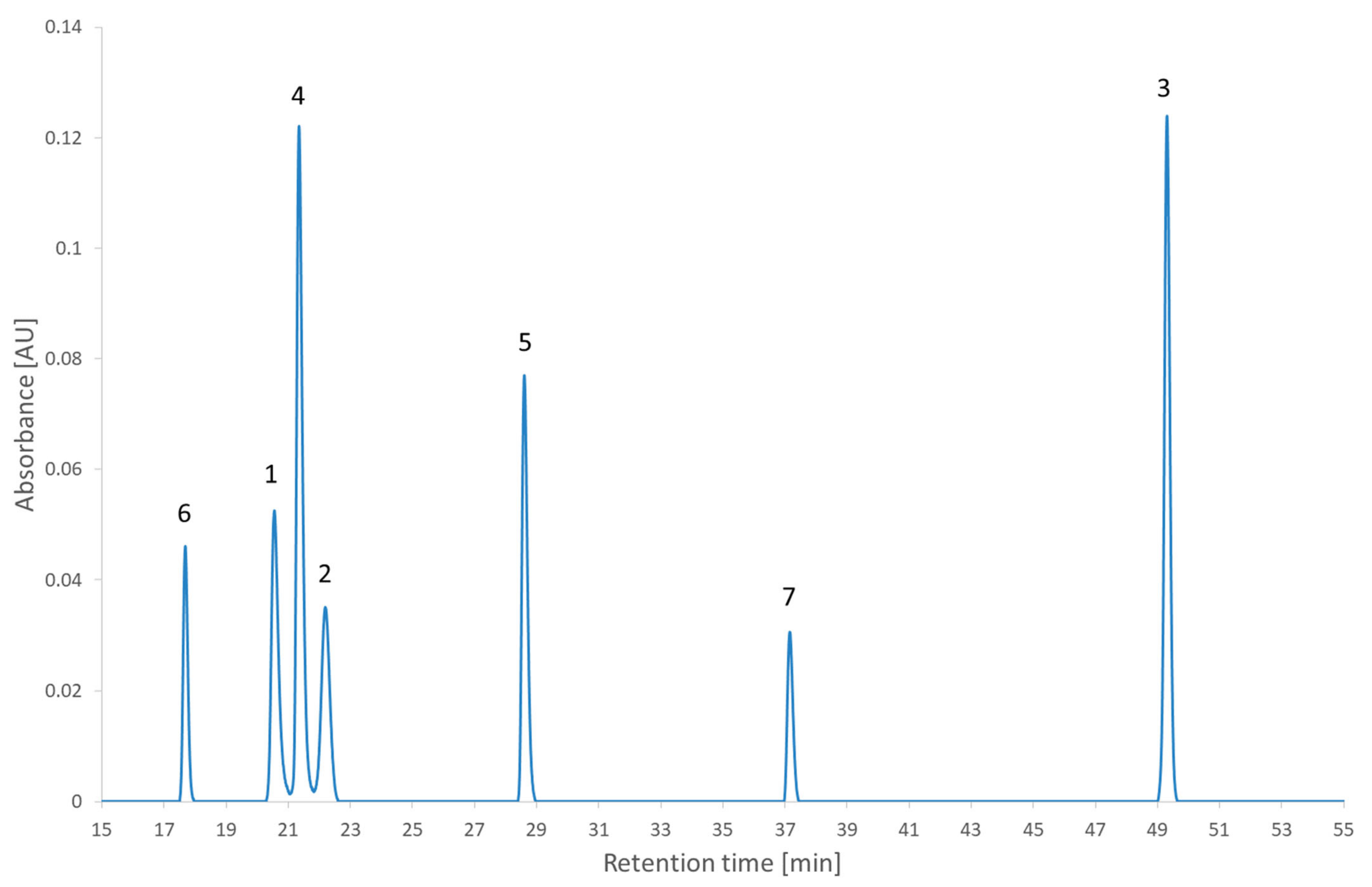
Figure 5 and were realized experimentally to assess the impact of the decision. The experimental chromatogram of the global maximum is illustrated in
Figure 6. The resulting separation was particularly good. Although this is only illustrating the screening step, this is the kind of result that would be expected from the optimization step.
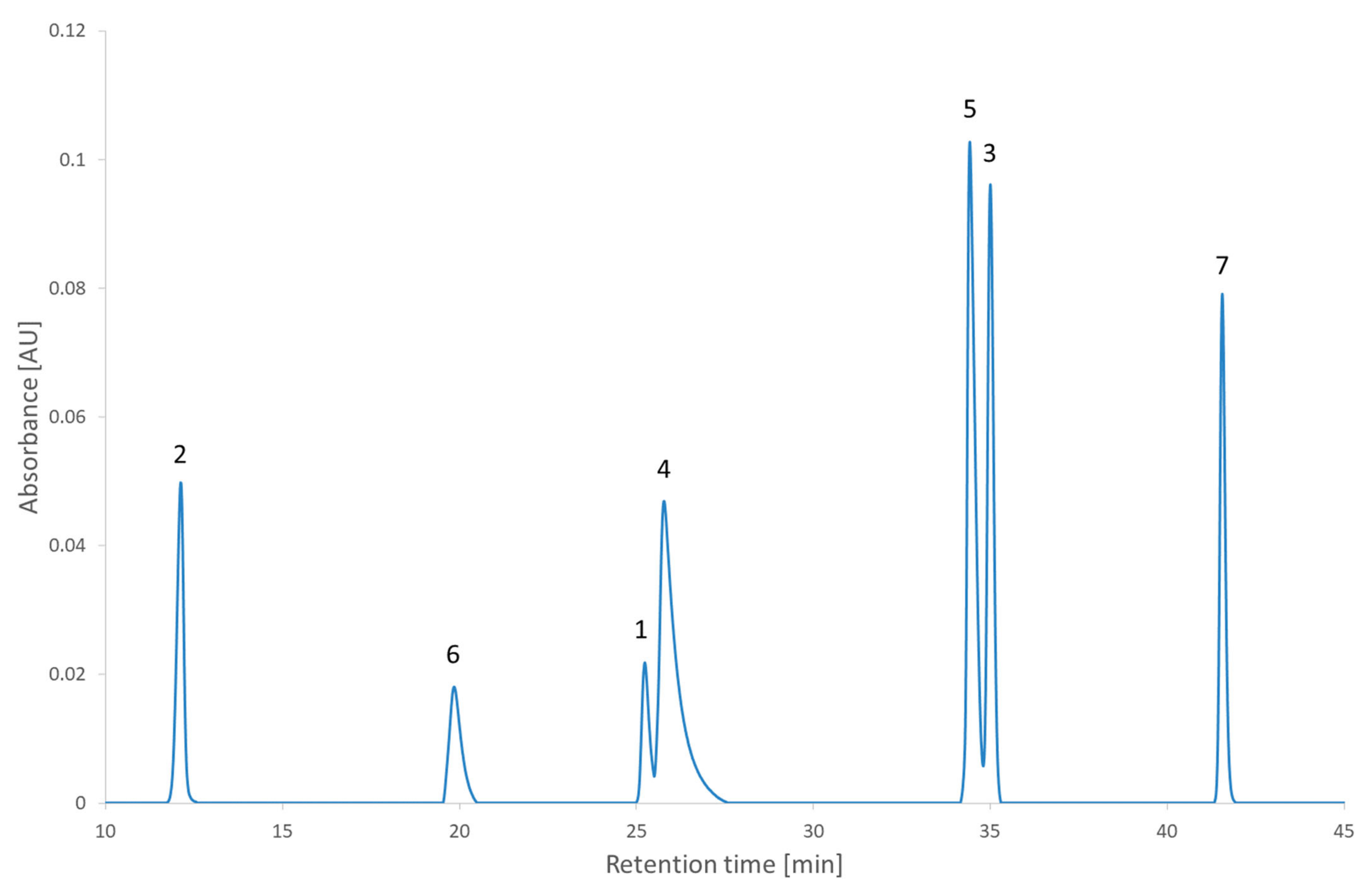
Figure 7 illustrates the chromatogram of a local maximum. Even though the desirability index was high, the actual peaks were not well separated. Indeed, two pairs of peaks (2,2′-bipyridine and metoclopramide, and ibuprofen and papaverine) coeluted nearly completely. This outcome is explained by the error in the prediction. From
Table S4 (Supplementary Materials), it is evident that the two coelutions come from the under-evaluation of the predicted retention time of one of the compounds in each pair. This under evaluation is also observed with the predictions of the global maximum but in that case, the peaks are so distant from each other that it does not impair the actual separation. Supposing the separation of the coeluting peaks could be resolved during the optimization phase, it would be recommended to conduct the analyses corresponding to the highest desirability indices to confirm the selection of the region to continue the method development.
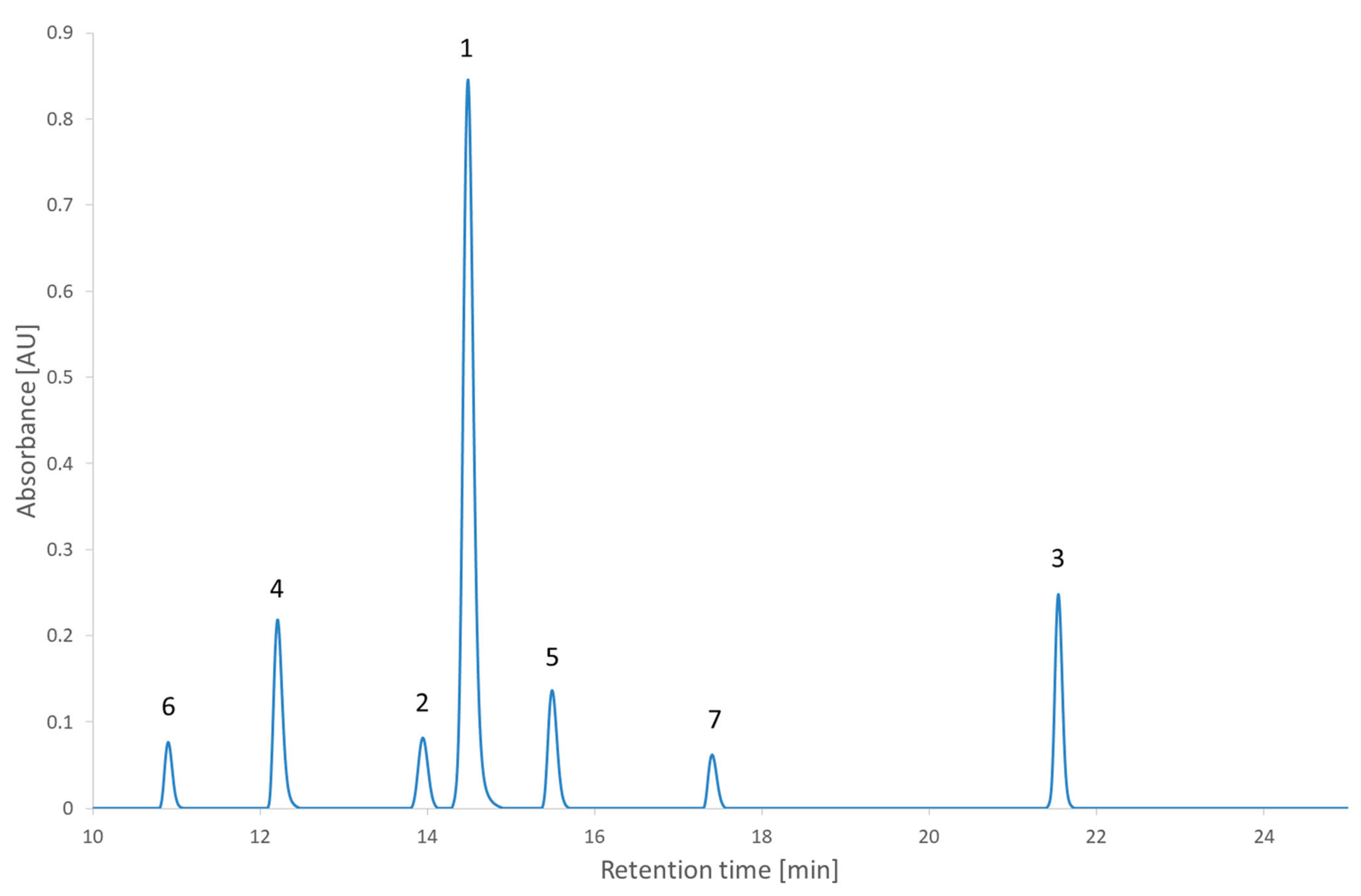
In
Figure 5, two other interesting points are highlighted. They correspond to two conditions at the same pH but with gradient times at the two ends of the range. They were chosen because the condition with the smallest gradient time is considered to be better than the one with the longest retention time. This would usually be considered counterintuitive. From the comparison of
Figure 8 and
Figure 9, the expected increase in all the retention times can be seen. It could also be observed that the peaks of the chromatogram at a 20 min gradient time were better separated than the peaks of the chromatogram at 60 min. This confirms the results of the RSM and the MCDA. These results can be interpreted by the different influences that the change of gradient time will have on each compound. In this second test set, nearly all the compounds have an increased retention time and stay in the same order. The exception is the 2,2′-bipyridine, which was highly influenced by the gradient time, revealed by its shift of position in the order of elution. These results confirm (if needed) that the gradient time can play a role in the selectivity of an RPLC method [
35,
36].
3. Materials and Methods
3.1. Methodology
The part of the strategy presented is structured with the following steps: a response surface model is fitted for each compound in the sample based on experimental retention times. Those retention times replace the retention times predicted by QSRR models that would be used when the complete strategy is applied. To be able to account for the error in the model, a distribution is adapted to the residuals of each model. For a model fitted with the ordinary least squares method, the residuals are expected to follow a normal distribution. Nonetheless, for this study, a more robust alternative, the Student’s t distribution, is used. Its parameters are the mean and the variance of the residuals and the residual degrees of freedom of the model. Predicted retention times in new conditions are sampled from those distributions to calculate different criteria useful for the selection of the best conditions. A desirability function is designed for each of those criteria to rescale them. The output of those desirability functions for all conditions is then aggregated in a single value, the desirability index, which will define the best conditions. This aggregation allows attributing different weights for each criterion. Those weights will be sampled from a Dirichlet distribution which allows for calculating the probability of reaching a specific desirability index while the weights slightly vary.
3.2. Chemicals and Reagent
Ammonium bicarbonate, ammonium formate, and formic acid 99% were purchased from VWR Chemicals (Leuven, Belgium). Milli-Q water from a Merck milli-Q pump. Methanol HPLC gradient grade was purchased from J.T. Baker (Deventer, Netherlands).
Standard compounds: 2,2′-bipyridine, 4-nitrophenol, ibuprofen, metoclopramide, papaverine, verapamil hydrochloride from TCI; pindolol from Abcam (Rozenburg, Netherlands).
3.3. Instrumentation and Chromatographic Conditions
The following compounds were selected for the application of the strategy presented in this study for their diverse chromatographic behaviors: 2,2′-bipyridine, 4-nitrophenol, ibuprofen, metoclopramide, papaverine, pindolol, and verapamil.
The strategy is designed to be applied to predicted retention times in different conditions. Those predicted retention times are replaced by experimental retention times to evaluate the performance of the strategy. The experimental retention times are taken from the dataset described in extenso elsewhere [
37]. The complete dataset is composed of ninety-eight compounds analyzed in reversed-phase liquid chromatography at five pH values (2.7, 3.5, 5.0, 6.5, and 8.0) and two gradient times (0% to 95% methanol in 20 and 60 min) on two C18 columns Waters XSelect HSS T3 2.1 × 100 mm 3.5 μm on three different chromatography systems.
New conditions were realized experimentally to control the prediction performance of new conditions. The samples were analyzed on a Waters Alliance 2695 HPLC coupled with a UV-visible photodiode array detector 2996 module. The separation was achieved on a C18 stationary phase Waters XSelect HSS T3 2.1 × 100 mm 3.5 μm and the flow rate was fixed at 0.3 mL/min. The analytical method was a gradient from 0% to 95% methanol in 40 min followed by a 5 min hold. Different buffers were used to set the pH (3.0 and 6.0) of the mobile phase for the new conditions. The injection volume was set at 10 μL, the column temperature was set at 25°C and the PDA was set to acquire from 209 to 395 nm.
3.4. Sample Preparation
The stock solutions were prepared in water, methanol, or a mixture of both depending on the solubility properties of each compound. The subsequent single compound solutions and mixture solutions were prepared by diluting the stock solutions using water or a mixture of water and methanol to reach the target concentration of 20 μg·mL
−1. A more concentrated solution (40 μg·mL
−1) was necessary to detect the ibuprofen. For detailed information about each compound preparation, see
Table S2 in Supplementary Materials.
Two test sets were used to assess the strategy. The first one was composed of 4-nitrophenol, ibuprofen, papaverine, and pindolol. The second one was composed of 2,2′-bipyridine, 4-nitrophenol, ibuprofen, metoclopramide, papaverine, pindolol, and verapamil.
3.5. Software
Waters® Empower 3 Workgroup (Waters, Milford, MA, USA) was used to control the chromatographic system and to acquire and manage the data.
R version 4.1.1, the packages MCMCpack version 1.6-0, igraph version 1.2.7, and raster version 3.5-2 were used for the analysis of the results.
4. Conclusions
A strategy combining RSM modeling of the retention time of known compounds based on their chemical properties and MCDA robust to the weights attributed by the user was designed with the intention of offering the opportunity to perform an in silico screening as a first step in the method development of a known sample when associated with QSRR models. The presented results showed that the developed strategy could help with the screening phase of the method development. The strategy offers the possibility of reducing the range of the parameters for the optimization step by considering criteria commonly used while taking decisions during method development.
One of the shortcomings of the strategy is the use of a Student’s t distribution after the models to propagate the error. The use of Bayesian models instead would be a better alternative. First, it would offer the possibility to provide more information through the prior distribution of parameters. Second, it would offer the opportunity to directly have access to this error of the model from the ensuing posterior distribution.
One of the limitations of the strategy is that the user needs to provide the expected width of the peaks. To overcome this limitation, one solution could be to define them as proportional to the ratio of the concentration. Another solution would be to make a first single injection to collect the real width. However, this limitation is minor because this is only for the screening step and would be followed by the optimization step.
The advantages of this strategy are that it limits the sensitivity of the decision to the weights allocated at the different criteria. Furthermore, thanks to the different criteria implemented, the strategy allows the user to consider multiple criteria in line with its objectives from the beginning of the method development. After the recommended experimental verification, the selected method would continue to be developed in a region where the desirability index would vary moderately, granting the possibility to adapt the condition without needing to start the whole method development from the beginning.
A long-term objective of the complete strategy would be to develop a user interface to help and guide the user providing all the required information (peak width, weights corresponding to the output of the development, confidence in the weights, desirability index threshold, and probability to reach the desirability index).


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}