
Intelligent Protein Design and Molecular Characterization Techniques: A Comprehensive Review
Abstract
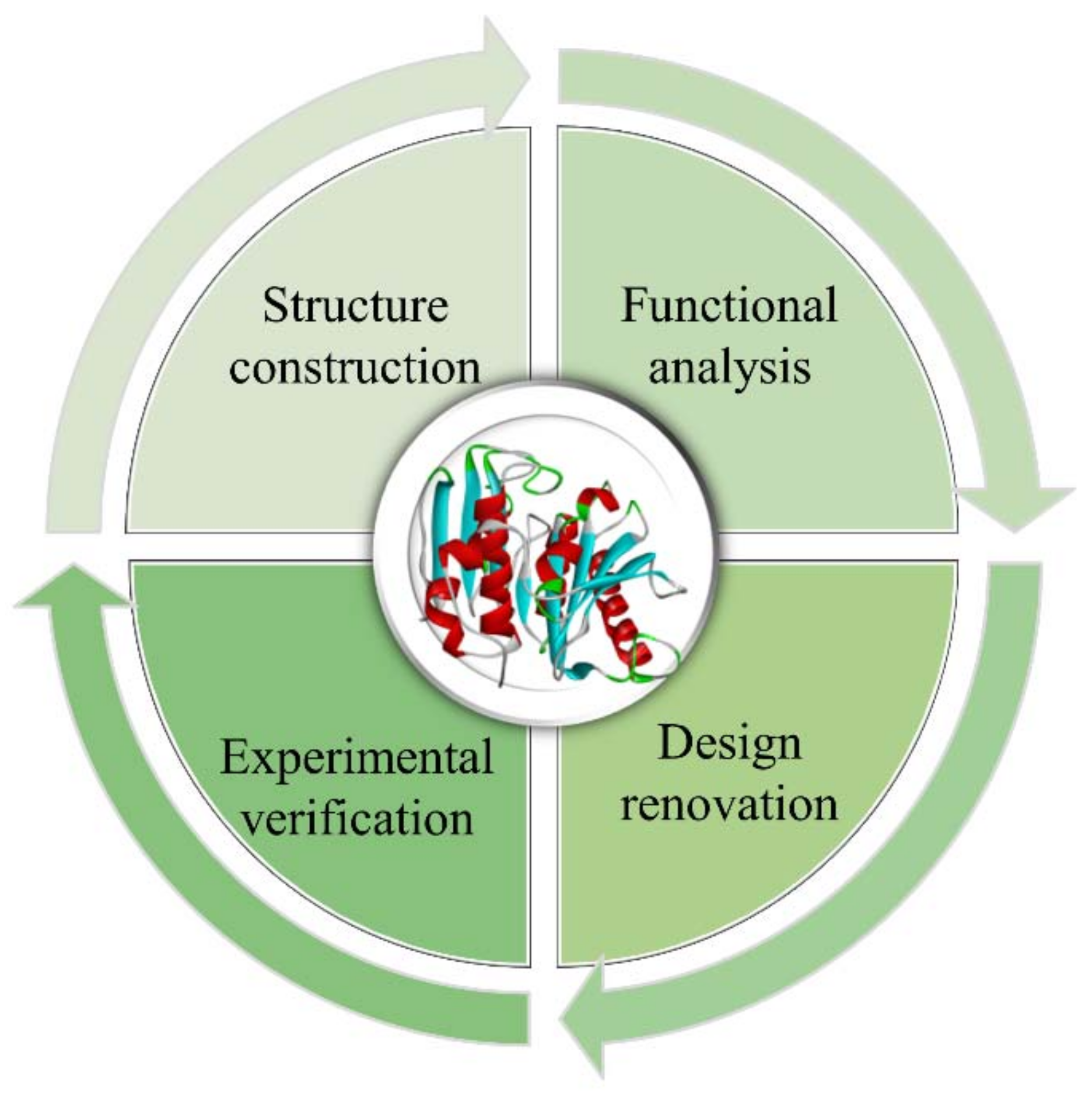
:1. Intelligent Design for Protein Molecules
2. Examples of Applications for Intelligent Protein Design
2.1. Protein Structure Prediction
2.2. Protein Function Prediction
2.3. De Novo Protein Design
3. Macromolecular Characterization Techniques and Their Application in Intelligent Protein Design
3.1. Characterization Based on Traditional Molecular Descriptors
3.2. Sequence-Based Characterization
3.3. Structure-Based Characterization
3.3.1. Graph Structure-Based Characterization
Topology Structure-Based Protein Characterization
Distance Map-Based Protein Characterization
3.3.2. Geometry-Based Characterization
3.4. Hybrid Sequence–Structure-Based Characterization
4. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Woolfson, D.N. A Brief History of De Novo Protein Design: Minimal, Rational, and Computational. J. Mol. Biol. 2021, 433, 167160. [Google Scholar] [CrossRef]
- Meinen, B.A.; Bahl, C.D. Breakthroughs in Computational Design Methods Open up New Frontiers for De Novo Protein Engineering. Protein Eng. Des. Sel. 2021, 34, gzab007. [Google Scholar] [CrossRef] [PubMed]
- Hill, R.B.; Raleigh, D.P.; Lombardi, A.; DeGrado, W.F. De Novo Design of Helical Bundles as Models for Understanding Protein Folding and Function. Acc. Chem. Res. 2000, 33, 745–754. [Google Scholar] [CrossRef] [PubMed]
- Simons, K.T.; Kooperberg, C.; Huang, E.; Baker, D. Assembly of Protein Tertiary Structures from Fragments with Similar Local Sequences Using Simulated Annealing and Bayesian Scoring Functions. J. Mol. Biol. 1997, 268, 209–225. [Google Scholar] [CrossRef] [PubMed]
- Gibney, B.R.; Rabanal, F.; Skalicky, J.J.; Wand, A.J.; Dutton, P.L. Design of a Unique Protein Scaffold for Maquettes. J. Am. Chem. Soc. 1997, 119, 2323–2324. [Google Scholar] [CrossRef]
- Gibney, B.R.; Rabanal, F.; Skalicky, J.J.; Wand, A.J.; Dutton, P.L. Iterative Protein Redesign. J. Am. Chem. Soc. 1999, 121, 4952–4960. [Google Scholar] [CrossRef]
- Dahiyat, B.I.; Mayo, S.L. De Novo Protein Design: Fully Automated Sequence Selection. Science 1997, 278, 82–87. [Google Scholar] [CrossRef]
- Dantas, G.; Kuhlman, B.; Callender, D.; Wong, M.; Baker, D. A Large Scale Test of Computational Protein Design: Folding and Stability of Nine Completely Redesigned Globular Proteins. J. Mol. Biol. 2003, 332, 449–460. [Google Scholar] [CrossRef]
- Kuhlman, B.; Dantas, G.; Ireton, G.C.; Varani, G.; Stoddard, B.L.; Baker, D. Design of a Novel Globular Protein Fold with Atomic-Level Accuracy. Science 2003, 302, 1364–1368. [Google Scholar] [CrossRef]
- Ingraham, J.; Garg, V.K.; Barzilay, R.; Jaakkola, T. Generative Models for Graph-Based Protein Design. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates Inc.: Red Hook, NY, USA, 2019. [Google Scholar]
- Strokach, A.; Becerra, D.; Corbi-Verge, C.; Perez-Riba, A.; Kim, P.M. Fast and Flexible Protein Design Using Deep Graph Neural Networks. Cell Syst. 2020, 11, 402–411.e4. [Google Scholar] [CrossRef]
- Anishchenko, I.; Pellock, S.J.; Chidyausiku, T.M.; Ramelot, T.A.; Ovchinnikov, S.; Hao, J.; Bafna, K.; Norn, C.; Kang, A.; Bera, A.K.; et al. De Novo Protein Design by Deep Network Hallucination. Nature 2021, 600, 547–552. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Lisanza, S.; Juergens, D.; Tischer, D.; Watson, J.L.; Castro, K.M.; Ragotte, R.; Saragovi, A.; Milles, L.F.; Baek, M.; et al. Scaffolding Protein Functional Sites Using Deep Learning. Science 2022, 377, 387–394. [Google Scholar] [CrossRef] [PubMed]
- Röthlisberger, D.; Khersonsky, O.; Wollacott, A.M.; Jiang, L.; DeChancie, J.; Betker, J.; Gallaher, J.L.; Althoff, E.A.; Zanghellini, A.; Dym, O.; et al. Kemp Elimination Catalysts by Computational Enzyme Design. Nature 2008, 453, 190–195. [Google Scholar] [CrossRef] [PubMed]
- Jiang, L.; Althoff, E.A.; Clemente, F.R.; Doyle, L.; Röthlisberger, D.; Zanghellini, A.; Gallaher, J.L.; Betker, J.L.; Tanaka, F.; Barbas, C.F.; et al. De Novo Computational Design of Retro-Aldol Enzymes. Science 2008, 319, 1387–1391. [Google Scholar] [CrossRef]
- Bolon, D.N.; Mayo, S.L. Enzyme-like Proteins by Computational Design. Proc. Natl. Acad. Sci. USA 2001, 98, 14274–14279. [Google Scholar] [CrossRef]
- Kaplan, J.; DeGrado, W.F. De Novo Design of Catalytic Proteins. Proc. Natl. Acad. Sci. USA 2004, 101, 11566–11570. [Google Scholar] [CrossRef]
- Liang, H.; Chen, H.; Fan, K.; Wei, P.; Guo, X.; Jin, C.; Zeng, C.; Tang, C.; Lai, L. De Novo Design of a Beta Alpha Beta Motif. Angew. Chem. Int. Ed. 2009, 48, 3301–3303. [Google Scholar] [CrossRef]
- Bellows, M.L.; Taylor, M.S.; Cole, P.A.; Shen, L.; Siliciano, R.F.; Fung, H.K.; Floudas, C.A. Discovery of Entry Inhibitors for HIV-1 via a New De Novo Protein Design Framework. Biophys. J. 2010, 99, 3445–3453. [Google Scholar] [CrossRef]
- Korendovych, I.V.; Senes, A.; Kim, Y.H.; Lear, J.D.; Fry, H.C.; Therien, M.J.; Blasie, J.K.; Walker, F.A.; DeGrado, W.F. De Novo Design and Molecular Assembly of a Transmembrane Diporphyrin-Binding Protein Complex. J. Am. Chem. Soc. 2010, 132, 15516–15518. [Google Scholar] [CrossRef]
- Mitra, P.; Shultis, D.; Zhang, Y. EvoDesign: De Novo Protein Design Based on Structural and Evolutionary Profiles. Nucleic Acids Res. 2013, 41, W273–W280. [Google Scholar] [CrossRef]
- Fairbrother, W.J.; Ashkenazi, A. Designer Proteins to Trigger Cell Death. Cell 2014, 157, 1506–1508. [Google Scholar] [CrossRef] [PubMed]
- Murphy, G.S.; Sathyamoorthy, B.; Der, B.S.; Machius, M.C.; Pulavarti, S.V.; Szyperski, T.; Kuhlman, B. Computational De Novo Design of a Four-Helix Bundle Protein—DND_4HB. Protein Sci. 2015, 24, 434–445. [Google Scholar] [CrossRef] [PubMed]
- Chevalier, A.; Silva, D.-A.; Rocklin, G.J.; Hicks, D.R.; Vergara, R.; Murapa, P.; Bernard, S.M.; Zhang, L.; Lam, K.-H.; Yao, G.; et al. Massively Parallel De Novo Protein Design for Targeted Therapeutics. Nature 2017, 550, 74–79. [Google Scholar] [CrossRef]
- Löffler, P.; Schmitz, S.; Hupfeld, E.; Sterner, R.; Merkl, R. Rosetta:MSF: A Modular Framework for Multi-State Computational Protein Design. PLoS Comput. Biol. 2017, 13, e1005600. [Google Scholar] [CrossRef]
- Shen, H.; Fallas, J.A.; Lynch, E.; Sheffler, W.; Parry, B.; Jannetty, N.; Decarreau, J.; Wagenbach, M.; Vicente, J.J.; Chen, J.; et al. De Novo Design of Self-Assembling Helical Protein Filaments. Science 2018, 362, 705–709. [Google Scholar] [CrossRef] [PubMed]
- Park, J.; Selvaraj, B.; McShan, A.C.; Boyken, S.E.; Wei, K.Y.; Oberdorfer, G.; DeGrado, W.; Sgourakis, N.G.; Cuneo, M.J.; Myles, D.A.; et al. De Novo Design of a Homo-Trimeric Amantadine-Binding Protein. eLife 2019, 8, e47839. [Google Scholar] [CrossRef] [PubMed]
- Russ, W.P.; Figliuzzi, M.; Stocker, C.; Barrat-Charlaix, P.; Socolich, M.; Kast, P.; Hilvert, D.; Monasson, R.; Cocco, S.; Weigt, M.; et al. An Evolution-Based Model for Designing Chorismate Mutase Enzymes. Science 2020, 369, 440–445. [Google Scholar] [CrossRef]
- Chidyausiku, T.M.; Mendes, S.R.; Klima, J.C.; Nadal, M.; Eckhard, U.; Roel-Touris, J.; Houliston, S.; Guevara, T.; Haddox, H.K.; Moyer, A.; et al. De Novo Design of Immunoglobulin-like Domains. Nat. Commun. 2022, 13, 5661. [Google Scholar] [CrossRef]
- Cao, L.; Coventry, B.; Goreshnik, I.; Huang, B.; Sheffler, W.; Park, J.S.; Jude, K.M.; Marković, I.; Kadam, R.U.; Verschueren, K.H.G.; et al. Design of Protein-Binding Proteins from the Target Structure Alone. Nature 2022, 605, 551–560. [Google Scholar] [CrossRef]
- Liao, J.; Warmuth, M.K.; Govindarajan, S.; Ness, J.E.; Wang, R.P.; Gustafsson, C.; Minshull, J. Engineering Proteinase K Using Machine Learning and Synthetic Genes. BMC Biotechnol. 2007, 7, 16. [Google Scholar] [CrossRef]
- Greener, J.G.; Moffat, L.; Jones, D.T. Design of Metalloproteins and Novel Protein Folds Using Variational Autoencoders. Sci. Rep. 2018, 8, 16189. [Google Scholar] [CrossRef]
- Wang, J.; Cao, H.; Zhang, J.Z.H.; Qi, Y. Computational Protein Design with Deep Learning Neural Networks. Sci. Rep. 2018, 8, 6349. [Google Scholar] [CrossRef] [PubMed]
- Alley, E.C.; Khimulya, G.; Biswas, S.; AlQuraishi, M.; Church, G.M. Unified Rational Protein Engineering with Sequence-Based Deep Representation Learning. Nat. Methods 2019, 16, 1315–1322. [Google Scholar] [CrossRef]
- Chen, X.; Chen, Z.; Xu, D.; Lyu, Y.; Li, Y.; Li, S.; Wang, J.; Wang, Z. De Novo Design of G Protein-Coupled Receptor 40 Peptide Agonists for Type 2 Diabetes Mellitus Based on Artificial Intelligence and Site-Directed Mutagenesis. Front. Bioeng. Biotechnol. 2021, 9, 694100. [Google Scholar] [CrossRef] [PubMed]
- Repecka, D.; Jauniskis, V.; Karpus, L.; Rembeza, E.; Rokaitis, I.; Zrimec, J.; Poviloniene, S.; Laurynenas, A.; Viknander, S.; Abuajwa, W.; et al. Expanding Functional Protein Sequence Spaces Using Generative Adversarial Networks. Nat. Mach. Intell. 2021, 3, 324–333. [Google Scholar] [CrossRef]
- Ferruz, N.; Schmidt, S.; Höcker, B. ProtGPT2 Is a Deep Unsupervised Language Model for Protein Design. Nat. Commun. 2022, 13, 4348. [Google Scholar] [CrossRef]
- Li, S.; Wang, L.; Meng, J.; Zhao, Q.; Zhang, L.; Liu, H. De Novo Design of Potential Inhibitors against SARS-CoV-2 Mpro. Comput. Biol. Med. 2022, 147, 105728. [Google Scholar] [CrossRef]
- Kucera, T.; Togninalli, M.; Meng-Papaxanthos, L. Conditional Generative Modeling for De Novo Protein Design with Hierarchical Functions. Bioinformatics 2022, 38, 3454–3461. [Google Scholar] [CrossRef]
- Dauparas, J.; Anishchenko, I.; Bennett, N.; Bai, H.; Ragotte, R.J.; Milles, L.F.; Wicky, B.I.M.; Courbet, A.; de Haas, R.J.; Bethel, N.; et al. Robust Deep Learning-Based Protein Sequence Design Using ProteinMPNN. Science 2022, 378, 49–56. [Google Scholar] [CrossRef]
- Watson, J.L.; Juergens, D.; Bennett, N.R.; Trippe, B.L.; Yim, J.; Eisenach, H.E.; Ahern, W.; Borst, A.J.; Ragotte, R.J.; Milles, L.F.; et al. De Novo Design of Protein Structure and Function with RFdiffusion. Nature 2023, 620, 1089–1100. [Google Scholar] [CrossRef]
- Jumper, J.; Evans, R.; Pritzel, A.; Green, T.; Figurnov, M.; Ronneberger, O.; Tunyasuvunakool, K.; Bates, R.; Žídek, A.; Potapenko, A.; et al. Highly Accurate Protein Structure Prediction with AlphaFold. Nature 2021, 596, 583–589. [Google Scholar] [CrossRef]
- Tunyasuvunakool, K.; Adler, J.; Wu, Z.; Green, T.; Zielinski, M.; Žídek, A.; Bridgland, A.; Cowie, A.; Meyer, C.; Laydon, A.; et al. Highly Accurate Protein Structure Prediction for the Human Proteome. Nature 2021, 596, 590–596. [Google Scholar] [CrossRef] [PubMed]
- Bileschi, M.L.; Belanger, D.; Bryant, D.H.; Sanderson, T.; Carter, B.; Sculley, D.; Bateman, A.; DePristo, M.A.; Colwell, L.J. Using Deep Learning to Annotate the Protein Universe. Nat. Biotechnol. 2022, 40, 932–937. [Google Scholar] [CrossRef] [PubMed]
- Charoenkwan, P.; Chotpatiwetchkul, W.; Lee, V.S.; Nantasenamat, C.; Shoombuatong, W. A Novel Sequence-Based Predictor for Identifying and Characterizing Thermophilic Proteins Using Estimated Propensity Scores of Dipeptides. Sci. Rep. 2021, 11, 23782. [Google Scholar] [CrossRef] [PubMed]
- Jia, L.; Sun, T.; Wang, Y.; Shen, Y. A Machine Learning Study on the Thermostability Prediction of (R)-ω-Selective Amine Transaminase from Aspergillus Terreus. BioMed Res. Int. 2021, 2021, 2593748. [Google Scholar] [CrossRef] [PubMed]
- Capriotti, E.; Fariselli, P.; Casadio, R. I-Mutant2.0: Predicting Stability Changes upon Mutation from the Protein Sequence or Structure. Nucleic Acids Res. 2005, 33, W306–W310. [Google Scholar] [CrossRef] [PubMed]
- Trimble, J.S.; Crawshaw, R.; Hardy, F.J.; Levy, C.W.; Brown, M.J.B.; Fuerst, D.E.; Heyes, D.J.; Obexer, R.; Green, A.P. A Designed Photoenzyme for Enantioselective [2+2] Cycloadditions. Nature 2022, 611, 709–714. [Google Scholar] [CrossRef] [PubMed]
- Sun, N.; Huang, J.; Qian, J.; Zhou, T.-P.; Guo, J.; Tang, L.; Zhang, W.; Deng, Y.; Zhao, W.; Wu, G.; et al. Enantioselective [2+2]-Cycloadditions with Triplet Photoenzymes. Nature 2022, 611, 715–720. [Google Scholar] [CrossRef]
- Tubiana, J.; Schneidman-Duhovny, D.; Wolfson, H.J. ScanNet: An Interpretable Geometric Deep Learning Model for Structure-Based Protein Binding Site Prediction. Nat. Methods 2022, 19, 730–739. [Google Scholar] [CrossRef]
- Lin, Z.; Akin, H.; Rao, R.; Hie, B.; Zhu, Z.; Lu, W.; dos Santos Costa, A.; Fazel-Zarandi, M.; Sercu, T.; Candido, S.; et al. Language Models of Protein Sequences at the Scale of Evolution Enable Accurate Structure Prediction. bioRxiv 2022. [Google Scholar] [CrossRef]
- Wang, W.; Peng, Z.; Yang, J. Single-Sequence Protein Structure Prediction Using Supervised Transformer Protein Language Models. Nat. Comput. Sci. 2022, 2, 804–814. [Google Scholar] [CrossRef]
- Zhou, X.; Zheng, W.; Li, Y.; Pearce, R.; Zhang, C.; Bell, E.W.; Zhang, G.; Zhang, Y. I-TASSER-MTD: A Deep-Learning-Based Platform for Multi-Domain Protein Structure and Function Prediction. Nat. Protoc. 2022, 17, 2326–2353. [Google Scholar] [CrossRef] [PubMed]
- Chowdhury, R.; Bouatta, N.; Biswas, S.; Floristean, C.; Kharkar, A.; Roy, K.; Rochereau, C.; Ahdritz, G.; Zhang, J.; Church, G.M.; et al. Single-Sequence Protein Structure Prediction Using a Language Model and Deep Learning. Nat. Biotechnol. 2022, 40, 1617–1623. [Google Scholar] [CrossRef] [PubMed]
- Anfinsen, C.B. Principles That Govern the Folding of Protein Chains. Science 1973, 181, 223–230. [Google Scholar] [CrossRef] [PubMed]
- Acharya, K.R.; Lloyd, M.D. The Advantages and Limitations of Protein Crystal Structures. Trends Pharmacol. Sci. 2005, 26, 10–14. [Google Scholar] [CrossRef] [PubMed]
- Cavalli, A.; Salvatella, X.; Dobson, C.M.; Vendruscolo, M. Protein Structure Determination from NMR Chemical Shifts. Proc. Natl. Acad. Sci. USA 2007, 104, 9615–9620. [Google Scholar] [CrossRef]
- Yip, K.M.; Fischer, N.; Paknia, E.; Chari, A.; Stark, H. Atomic-Resolution Protein Structure Determination by Cryo-EM. Nature 2020, 587, 157–161. [Google Scholar] [CrossRef]
- Burley, S.K.; Bhikadiya, C.; Bi, C.; Bittrich, S.; Chao, H.; Chen, L.; Craig, P.A.; Crichlow, G.V.; Dalenberg, K.; Duarte, J.M.; et al. RCSB Protein Data Bank (RCSB.Org): Delivery of Experimentally-Determined PDB Structures alongside One Million Computed Structure Models of Proteins from Artificial Intelligence/Machine Learning. Nucleic Acids Res. 2023, 51, D488–D508. [Google Scholar] [CrossRef]
- UniProt Consortium. UniProt: The Universal Protein Knowledgebase in 2023. Nucleic Acids Res. 2023, 51, D523–D531. [Google Scholar] [CrossRef]
- Magrane, M. UniProt Consortium UniProt Knowledgebase: A Hub of Integrated Protein Data. Database 2011, 2011, bar009. [Google Scholar] [CrossRef]
- Yang, J.; Yan, R.; Roy, A.; Xu, D.; Poisson, J.; Zhang, Y. The I-TASSER Suite: Protein Structure and Function Prediction. Nat. Methods 2015, 12, 7–8. [Google Scholar] [CrossRef] [PubMed]
- Varadi, M.; Anyango, S.; Deshpande, M.; Nair, S.; Natassia, C.; Yordanova, G.; Yuan, D.; Stroe, O.; Wood, G.; Laydon, A.; et al. AlphaFold Protein Structure Database: Massively Expanding the Structural Coverage of Protein-Sequence Space with High-Accuracy Models. Nucleic Acids Res. 2022, 50, D439–D444. [Google Scholar] [CrossRef] [PubMed]
- Baek, M.; DiMaio, F.; Anishchenko, I.; Dauparas, J.; Ovchinnikov, S.; Lee, G.R.; Wang, J.; Cong, Q.; Kinch, L.N.; Schaeffer, R.D.; et al. Accurate Prediction of Protein Structures and Interactions Using a Three-Track Neural Network. Science 2021, 373, 871–876. [Google Scholar] [CrossRef] [PubMed]
- Mirdita, M.; Schütze, K.; Moriwaki, Y.; Heo, L.; Ovchinnikov, S.; Steinegger, M. ColabFold: Making Protein Folding Accessible to All. Nat. Methods 2022, 19, 679–682. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Liu, X.; Chen, W.; Shen, F.; Bi, H.; Ke, G.; Zhang, L. Uni-Fold: An Open-Source Platform for Developing Protein Folding Models beyond AlphaFold. bioRxiv 2022. [Google Scholar] [CrossRef]
- Cheng, S.; Wu, R.; Yu, Z.; Li, B.; Zhang, X.; Peng, J.; You, Y. FastFold: Reducing AlphaFold Training Time from 11 Days to 67 Hours. arXiv 2022, arXiv:2203.00854. [Google Scholar]
- Wang, G.; Fang, X.; Wu, Z.; Liu, Y.; Xue, Y.; Xiang, Y.; Yu, D.; Wang, F.; Ma, Y. HelixFold: An Efficient Implementation of AlphaFold2 Using PaddlePaddle. arXiv 2022, arXiv:2207.05477. [Google Scholar]
- Liu, S.; Zhang, J.; Chu, H.; Wang, M.; Xue, B.; Ni, N.; Yu, J.; Xie, Y.; Chen, Z.; Chen, M.; et al. PSP: Million-Level Protein Sequence Dataset for Protein Structure Prediction. arXiv 2022, arXiv:2206.12240. [Google Scholar]
- Fang, X.; Wang, F.; Liu, L.; He, J.; Lin, D.; Xiang, Y.; Zhang, X.; Wu, H.; Li, H.; Song, L. HelixFold-Single: MSA-Free Protein Structure Prediction by Using Protein Language Model as an Alternative. arXiv 2022, arXiv:2207.13921. [Google Scholar]
- Wu, R.; Ding, F.; Wang, R.; Shen, R.; Zhang, X.; Luo, S.; Su, C.; Wu, Z.; Xie, Q.; Berger, B.; et al. High-Resolution De Novo Structure Prediction from Primary Sequence. bioRxiv 2022. [Google Scholar] [CrossRef]
- Ruffolo, J.A.; Chu, L.-S.; Mahajan, S.P.; Jeffrey, J. Gray Fast, Accurate Antibody Structure Prediction from Deep Learning on Massive Set of Natural Antibodies. bioRxiv 2022. [Google Scholar] [CrossRef]
- Zheng, W.; Wuyun, Q.; Freddolino, P.L.; Zhang, Y. Integrating Deep Learning, Threading Alignments, and a multi-MSA Strategy for High-quality Protein Monomer and Complex Structure Prediction in CASP15. Proteins 2023, 12, 1684–1703. [Google Scholar] [CrossRef] [PubMed]
- Evans, R.; O’Neill, M.; Pritzel, A.; Antropova, N.; Senior, A.; Green, T.; Žídek, A.; Bates, R.; Blackwell, S.; Yim, J.; et al. Protein Complex Prediction with AlphaFold-Multimer. bioRxiv 2021. [Google Scholar] [CrossRef]
- Chen, B.; Xie, Z.; Qiu, J.; Ye, Z.; Xu, J.; Tang, J. Improved the Protein Complex Prediction with Protein Language Models. bioRxiv 2022. [Google Scholar] [CrossRef]
- Steinegger, M.; Söding, J. MMseqs2 Enables Sensitive Protein Sequence Searching for the Analysis of Massive Data Sets. Nat. Biotechnol. 2017, 35, 1026–1028. [Google Scholar] [CrossRef] [PubMed]
- Steinegger, M.; Söding, J. Clustering Huge Protein Sequence Sets in Linear Time. Nat. Commun. 2018, 9, 2542. [Google Scholar] [CrossRef]
- UniProt Consortium. UniProt: The Universal Protein Knowledgebase in 2021. Nucleic Acids Res. 2021, 49, D480–D489. [Google Scholar] [CrossRef]
- Hippe, K.; Gbenro, S.; Cao, R. ProLanGO2: Protein Function Prediction with Ensemble of Encoder-Decoder Networks. In Proceedings of the 11th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics, ACM, Virtual Event, 21–24 September 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Gligorijević, V.; Renfrew, P.D.; Kosciolek, T.; Leman, J.K.; Berenberg, D.; Vatanen, T.; Chandler, C.; Taylor, B.C.; Fisk, I.M.; Vlamakis, H.; et al. Structure-Based Protein Function Prediction Using Graph Convolutional Networks. Nat. Commun. 2021, 12, 3168. [Google Scholar] [CrossRef] [PubMed]
- You, R.; Yao, S.; Mamitsuka, H.; Zhu, S. DeepGraphGO: Graph Neural Network for Large-Scale, Multispecies Protein Function Prediction. Bioinformatics 2021, 37, i262–i271. [Google Scholar] [CrossRef]
- Schug, J.; Diskin, S.; Mazzarelli, J.; Brunk, B.P.; Stoeckert, C.J. Predicting Gene Ontology Functions from ProDom and CDD Protein Domains. Genome Res. 2002, 12, 648–655. [Google Scholar] [CrossRef]
- Das, S.; Lee, D.; Sillitoe, I.; Dawson, N.L.; Lees, J.G.; Orengo, C.A. Functional Classification of CATH Superfamilies: A Domain-Based Approach for Protein Function Annotation. Bioinformatics 2015, 31, 3460–3467. [Google Scholar] [CrossRef] [PubMed]
- Koo, D.C.E.; Bonneau, R. Towards Region-Specific Propagation of Protein Functions. Bioinformatics 2019, 35, 1737–1744. [Google Scholar] [CrossRef] [PubMed]
- Wass, M.N.; Barton, G.; Sternberg, M.J.E. CombFunc: Predicting Protein Function Using Heterogeneous Data Sources. Nucleic Acids Res. 2012, 40, W466–W470. [Google Scholar] [CrossRef] [PubMed]
- Guan, Y.; Myers, C.L.; Hess, D.C.; Barutcuoglu, Z.; Caudy, A.A.; Troyanskaya, O.G. Predicting Gene Function in a Hierarchical Context with an Ensemble of Classifiers. Genome Biol. 2008, 9, S3. [Google Scholar] [CrossRef] [PubMed]
- Törönen, P.; Medlar, A.; Holm, L. PANNZER2: A Rapid Functional Annotation Web Server. Nucleic Acids Res. 2018, 46, W84–W88. [Google Scholar] [CrossRef]
- Mostafavi, S.; Ray, D.; Warde-Farley, D.; Grouios, C.; Morris, Q. GeneMANIA: A Real-Time Multiple Association Network Integration Algorithm for Predicting Gene Function. Genome Biol. 2008, 9, S4. [Google Scholar] [CrossRef]
- Cho, H.; Berger, B.; Peng, J. Compact Integration of Multi-Network Topology for Functional Analysis of Genes. Cell Syst. 2016, 3, 540–548.e5. [Google Scholar] [CrossRef]
- Gligorijević, V.; Barot, M.; Bonneau, R. deepNF: Deep Network Fusion for Protein Function Prediction. Bioinformatics 2018, 34, 3873–3881. [Google Scholar] [CrossRef]
- Regan, L.; DeGrado, W.F. Characterization of a Helical Protein Designed from First Principles. Science 1988, 241, 976–978. [Google Scholar] [CrossRef]
- Siegel, J.B.; Zanghellini, A.; Lovick, H.M.; Kiss, G.; Lambert, A.R.; St. Clair, J.L.; Gallaher, J.L.; Hilvert, D.; Gelb, M.H.; Stoddard, B.L.; et al. Computational Design of an Enzyme Catalyst for a Stereoselective Bimolecular Diels-Alder Reaction. Science 2010, 329, 309–313. [Google Scholar] [CrossRef] [PubMed]
- Siegel, J.B.; Smith, A.L.; Poust, S.; Wargacki, A.J.; Bar-Even, A.; Louw, C.; Shen, B.W.; Eiben, C.B.; Tran, H.M.; Noor, E.; et al. Computational Protein Design Enables a Novel One-Carbon Assimilation Pathway. Proc. Natl. Acad. Sci. USA 2015, 112, 3704–3709. [Google Scholar] [CrossRef] [PubMed]
- Cai, T.; Sun, H.; Qiao, J.; Zhu, L.; Zhang, F.; Zhang, J.; Tang, Z.; Wei, X.; Yang, J.; Yuan, Q.; et al. Cell-Free Chemoenzymatic Starch Synthesis from Carbon Dioxide. Science 2021, 373, 1523–1527. [Google Scholar] [CrossRef] [PubMed]
- Ferguson, A.L.; Ranganathan, R. 100th Anniversary of Macromolecular Science Viewpoint: Data-Driven Protein Design. ACS Macro Lett. 2021, 10, 327–340. [Google Scholar] [CrossRef] [PubMed]
- Huang, B.; Xu, Y.; Hu, X.; Liu, Y.; Liao, S.; Zhang, J.; Huang, C.; Hong, J.; Chen, Q.; Liu, H. A Backbone-Centred Energy Function of Neural Networks for Protein Design. Nature 2022, 602, 523–528. [Google Scholar] [CrossRef]
- An, L.; Hicks, D.R.; Zorine, D.; Dauparas, J.; Wicky, B.I.M.; Milles, L.F.; Courbet, A.; Bera, A.K.; Nguyen, H.; Kang, A.; et al. Hallucination of Closed Repeat Proteins Containing Central Pockets. Nat. Struct. Mol. Biol. 2023, 30, 1755–1760. [Google Scholar] [CrossRef] [PubMed]
- Doyle, L.A.; Takushi, B.; Kibler, R.D.; Milles, L.F.; Orozco, C.T.; Jones, J.D.; Jackson, S.E.; Stoddard, B.L.; Bradley, P. De Novo Design of Knotted Tandem Repeat Proteins. Nat. Commun. 2023, 14, 6746. [Google Scholar] [CrossRef] [PubMed]
- Ovchinnikov, S.; Huang, P.-S. Structure-Based Protein Design with Deep Learning. Curr. Opin. Chem. Biol. 2021, 65, 136–144. [Google Scholar] [CrossRef]
- Anand, N.; Eguchi, R.; Mathews, I.I.; Perez, C.P.; Derry, A.; Altman, R.B.; Huang, P.-S. Protein Sequence Design with a Learned Potential. Nat. Commun. 2022, 13, 746. [Google Scholar] [CrossRef]
- David, L.; Thakkar, A.; Mercado, R.; Engkvist, O. Molecular Representations in AI-Driven Drug Discovery: A Review and Practical Guide. J. Cheminform. 2020, 12, 56. [Google Scholar] [CrossRef]
- Zhang, F.; Zhao, B.; Shi, W.; Li, M.; Kurgan, L. DeepDISOBind: Accurate Prediction of RNA-, DNA- and Protein-Binding Intrinsically Disordered Residues with Deep Multi-Task Learning. Brief. Bioinform. 2022, 23, bbab521. [Google Scholar] [CrossRef]
- Lee, I.; Nam, H. Sequence-Based Prediction of Protein Binding Regions and Drug-Target Interactions. J. Cheminform. 2022, 14, 5. [Google Scholar] [CrossRef]
- Basu, S.; Kihara, D.; Kurgan, L. Computational Prediction of Disordered Binding Regions. Comput. Struct. Biotechnol. J. 2023, 21, 1487–1497. [Google Scholar] [CrossRef] [PubMed]
- Kulmanov, M.; Zhapa-Camacho, F.; Hoehndorf, R. DeepGOWeb: Fast and Accurate Protein Function Prediction on the (Semantic) Web. Nucleic Acids Res. 2021, 49, W140–W146. [Google Scholar] [CrossRef]
- Kulmanov, M.; Hoehndorf, R. DeepGOPlus: Improved Protein Function Prediction from Sequence. Bioinformatics 2020, 36, 422–429. [Google Scholar] [CrossRef] [PubMed]
- Yunes, J.M.; Babbitt, P.C. Effusion: Prediction of Protein Function from Sequence Similarity Networks. Bioinformatics 2019, 35, 442–451. [Google Scholar] [CrossRef]
- Magliery, T.J. Protein Stability: Computation, Sequence Statistics, and New Experimental Methods. Curr. Opin. Struct. Biol. 2015, 33, 161–168. [Google Scholar] [CrossRef]
- Scarabelli, G.; Oloo, E.O.; Maier, J.K.X.; Rodriguez-Granillo, A. Accurate Prediction of Protein Thermodynamic Stability Changes upon Residue Mutation Using Free Energy Perturbation. J. Mol. Biol. 2022, 434, 167375. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Yu, L. EPSOL: Sequence-Based Protein Solubility Prediction Using Multidimensional Embedding. Bioinformatics 2021, 37, 4314–4320. [Google Scholar] [CrossRef]
- Wang, C.; Zou, Q. Prediction of Protein Solubility Based on Sequence Physicochemical Patterns and Distributed Representation Information with DeepSoluE. BMC Biol. 2023, 21, 12. [Google Scholar] [CrossRef] [PubMed]
- Zhou, C.; Yu, H.; Ding, Y.; Guo, F.; Gong, X.-J. Multi-Scale Encoding of Amino Acid Sequences for Predicting Protein Interactions Using Gradient Boosting Decision Tree. PLoS ONE 2017, 12, e0181426. [Google Scholar] [CrossRef]
- Kirkwood, J.; Hargreaves, D.; O’Keefe, S.; Wilson, J. Using Isoelectric Point to Determine the pH for Initial Protein Crystallization Trials. Bioinformatics 2015, 31, 1444–1451. [Google Scholar] [CrossRef]
- Perez-Riverol, Y.; Audain, E.; Millan, A.; Ramos, Y.; Sanchez, A.; Vizcaíno, J.A.; Wang, R.; Müller, M.; Machado, Y.J.; Betancourt, L.H.; et al. Isoelectric Point Optimization Using Peptide Descriptors and Support Vector Machines. J. Proteom. 2012, 75, 2269–2274. [Google Scholar] [CrossRef]
- Aftabuddin, M.; Kundu, S. Hydrophobic, Hydrophilic, and Charged Amino Acid Networks within Protein. Biophys. J. 2007, 93, 225–231. [Google Scholar] [CrossRef]
- Sengupta, D.; Kundu, S. Role of Long- and Short-Range Hydrophobic, Hydrophilic and Charged Residues Contact Network in Protein’s Structural Organization. BMC Bioinform. 2012, 13, 142. [Google Scholar] [CrossRef] [PubMed]
- Durell, S.R.; Ben-Naim, A. Hydrophobic-Hydrophilic Forces in Protein Folding. Biopolymers 2017, 107, e23020. [Google Scholar] [CrossRef] [PubMed]
- Oehme, D.P.; Brownlee, R.T.C.; Wilson, D.J.D. Effect of Atomic Charge, Solvation, Entropy, and Ligand Protonation State on MM-PB(GB)SA Binding Energies of HIV Protease. J. Comput. Chem. 2012, 33, 2566–2580. [Google Scholar] [CrossRef] [PubMed]
- Hebditch, M.; Carballo-Amador, M.A.; Charonis, S.; Curtis, R.; Warwicker, J. Protein–Sol: A Web Tool for Predicting Protein Solubility from Sequence. Bioinformatics 2017, 33, 3098–3100. [Google Scholar] [CrossRef] [PubMed]
- Khurana, S.; Rawi, R.; Kunji, K.; Chuang, G.-Y.; Bensmail, H.; Mall, R. DeepSol: A Deep Learning Framework for Sequence-Based Protein Solubility Prediction. Bioinformatics 2018, 34, 2605–2613. [Google Scholar] [CrossRef]
- Munteanu, C.R.; Pimenta, A.C.; Fernandez-Lozano, C.; Melo, A.; Cordeiro, M.N.D.S.; Moreira, I.S. Solvent Accessible Surface Area-Based Hot-Spot Detection Methods for Protein-Protein and Protein-Nucleic Acid Interfaces. J. Chem. Inf. Model. 2015, 55, 1077–1086. [Google Scholar] [CrossRef]
- Faraggi, E.; Zhou, Y.; Kloczkowski, A. Accurate Single-Sequence Prediction of Solvent Accessible Surface Area Using Local and Global Features. Proteins 2014, 82, 3170–3176. [Google Scholar] [CrossRef]
- Houghtaling, J.; Ying, C.; Eggenberger, O.M.; Fennouri, A.; Nandivada, S.; Acharjee, M.; Li, J.; Hall, A.R.; Mayer, M. Estimation of Shape, Volume, and Dipole Moment of Individual Proteins Freely Transiting a Synthetic Nanopore. ACS Nano 2019, 13, 5231–5242. [Google Scholar] [CrossRef]
- Pathak, P.; Shvartsburg, A.A. Assessing the Dipole Moments and Directional Cross Sections of Proteins and Complexes by Differential Ion Mobility Spectrometry. Anal. Chem. 2022, 94, 7041–7049. [Google Scholar] [CrossRef]
- Wang, J.; Zhao, Y.; Gong, W.; Liu, Y.; Wang, M.; Huang, X.; Tan, J. EDLMFC: An Ensemble Deep Learning Framework with Multi-Scale Features Combination for ncRNA–Protein Interaction Prediction. BMC Bioinform. 2021, 22, 133. [Google Scholar] [CrossRef] [PubMed]
- Suresh, V.; Liu, L.; Adjeroh, D.; Zhou, X. RPI-Pred: Predicting ncRNA-Protein Interaction Using Sequence and Structural Information. Nucleic Acids Res. 2015, 43, 1370–1379. [Google Scholar] [CrossRef] [PubMed]
- Su, X.-R.; Hu, L.; You, Z.-H.; Hu, P.-W.; Zhao, B.-W. Multi-View Heterogeneous Molecular Network Representation Learning for Protein-Protein Interaction Prediction. BMC Bioinform. 2022, 23, 234. [Google Scholar] [CrossRef]
- Liu, Y.; Gong, W.; Zhao, Y.; Deng, X.; Zhang, S.; Li, C. aPRBind: Protein–RNA Interface Prediction by Combining Sequence and I-TASSER Model-Based Structural Features Learned with Convolutional Neural Networks. Bioinformatics 2021, 37, 937–942. [Google Scholar] [CrossRef]
- Hong, X.; Lv, J.; Li, Z.; Xiong, Y.; Zhang, J.; Chen, H.-F. Sequence-Based Machine Learning Method for Predicting the Effects of Phosphorylation on Protein-Protein Interactions. Int. J. Biol. Macromol. 2023, 243, 125233. [Google Scholar] [CrossRef] [PubMed]
- Jandrlić, D.R. SVM and SVR-Based MHC-Binding Prediction Using a Mathematical Presentation of Peptide Sequences. Comput. Biol. Chem. 2016, 65, 117–127. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, Q.; Yu, B.; Yu, Z.; Lawrence, P.J.; Ma, Q.; Zhang, Y. Improving Protein-Protein Interactions Prediction Accuracy Using XGBoost Feature Selection and Stacked Ensemble Classifier. Comput. Biol. Med. 2020, 123, 103899. [Google Scholar] [CrossRef]
- Gu, X.; Chen, Z.; Wang, D. Prediction of G Protein-Coupled Receptors With CTDC Extraction and MRMD2.0 Dimension-Reduction Methods. Front. Bioeng. Biotechnol. 2020, 8, 635. [Google Scholar] [CrossRef]
- Meher, P.K.; Sahu, T.K.; Mohanty, J.; Gahoi, S.; Purru, S.; Grover, M.; Rao, A.R. nifPred: Proteome-Wide Identification and Categorization of Nitrogen-Fixation Proteins of Diaztrophs Based on Composition-Transition-Distribution Features Using Support Vector Machine. Front. Microbiol. 2018, 9, 1100. [Google Scholar] [CrossRef]
- Yang, S.; Wang, Y.; Lin, Y.; Shao, D.; He, K.; Huang, L. LncMirNet: Predicting LncRNA-miRNA Interaction Based on Deep Learning of Ribonucleic Acid Sequences. Molecules 2020, 25, 4372. [Google Scholar] [CrossRef]
- Ma, X.; Guo, J.; Sun, X. Sequence-Based Prediction of RNA-Binding Proteins Using Random Forest with Minimum Redundancy Maximum Relevance Feature Selection. BioMed Res. Int. 2015, 2015, 425810. [Google Scholar] [CrossRef]
- Firoz, A.; Malik, A.; Ali, H.M.; Akhter, Y.; Manavalan, B.; Kim, C.-B. PRR-HyPred: A Two-Layer Hybrid Framework to Predict Pattern Recognition Receptors and Their Families by Employing Sequence Encoded Optimal Features. Int. J. Biol. Macromol. 2023, 234, 123622. [Google Scholar] [CrossRef]
- Collantes, E.R.; Dunn, W.J. Amino Acid Side Chain Descriptors for Quantitative Structure-Activity Relationship Studies of Peptide Analogs. J. Med. Chem. 1995, 38, 2705–2713. [Google Scholar] [CrossRef] [PubMed]
- Mei, H.; Liao, Z.H.; Zhou, Y.; Li, S.Z. A New Set of Amino Acid Descriptors and Its Application in Peptide QSARs. Biopolymers 2005, 80, 775–786. [Google Scholar] [CrossRef]
- Van Westen, G.J.; Swier, R.F.; Cortes-Ciriano, I.; Wegner, J.K.; Overington, J.P.; Ijzerman, A.P.; van Vlijmen, H.W.; Bender, A. Benchmarking of Protein Descriptor Sets in Proteochemometric Modeling (Part 2): Modeling Performance of 13 Amino Acid Descriptor Sets. J. Cheminformatics 2013, 5, 42. [Google Scholar] [CrossRef] [PubMed]
- Zhou, P.; Tian, F.; Wu, Y.; Li, Z.; Shang, Z. Quantitative Sequence-Activity Model (QSAM): Applying QSAR Strategy to Model and Predict Bioactivity and Function of Peptides, Proteins and Nucleic Acids. CAD 2008, 4, 311–321. [Google Scholar] [CrossRef]
- Liang, G.; Li, Z. Factor Analysis Scale of Generalized Amino Acid Information as the Source of a New Set of Descriptors for Elucidating the Structure and Activity Relationships of Cationic Antimicrobial Peptides. QSAR Comb. Sci. 2007, 26, 754–763. [Google Scholar] [CrossRef]
- Tian, F.; Zhou, P.; Li, Z. T-Scale as a Novel Vector of Topological Descriptors for Amino Acids and Its Application in QSARs of Peptides. J. Mol. Struct. 2007, 830, 106–115. [Google Scholar] [CrossRef]
- Yang, L.; Shu, M.; Ma, K.; Mei, H.; Jiang, Y.; Li, Z. ST-Scale as a Novel Amino Acid Descriptor and Its Application in QSAM of Peptides and Analogues. Amino Acids 2010, 38, 805–816. [Google Scholar] [CrossRef] [PubMed]
- Yue, Z.-X.; Yan, T.-C.; Xu, H.-Q.; Liu, Y.-H.; Hong, Y.-F.; Chen, G.-X.; Xie, T.; Tao, L. A Systematic Review on the State-of-the-Art Strategies for Protein Representation. Comput. Biol. Med. 2023, 152, 106440. [Google Scholar] [CrossRef] [PubMed]
- Zaliani, A.; Gancia, E. MS-WHIM Scores for Amino Acids: A New 3D-Description for Peptide QSAR and QSPR Studies. J. Chem. Inf. Comput. Sci. 1999, 39, 525–533. [Google Scholar] [CrossRef]
- Muppirala, U.K.; Honavar, V.G.; Dobbs, D. Predicting RNA-Protein Interactions Using Only Sequence Information. BMC Bioinform. 2011, 12, 489. [Google Scholar] [CrossRef] [PubMed]
- Peng, Z.; Kurgan, L. High-Throughput Prediction of RNA, DNA and Protein Binding Regions Mediated by Intrinsic Disorder. Nucleic Acids Res. 2015, 43, e121. [Google Scholar] [CrossRef] [PubMed]
- Soleymani, F.; Paquet, E.; Viktor, H.; Michalowski, W.; Spinello, D. Protein-Protein Interaction Prediction with Deep Learning: A Comprehensive Review. Comput. Struct. Biotechnol. J. 2022, 20, 5316–5341. [Google Scholar] [CrossRef]
- Zhao, L.; Zhu, Y.; Wang, J.; Wen, N.; Wang, C.; Cheng, L. A Brief Review of Protein-Ligand Interaction Prediction. Comput. Struct. Biotechnol. J. 2022, 20, 2831–2838. [Google Scholar] [CrossRef]
- Singh, V.K.; Maurya, N.S.; Mani, A.; Yadav, R.S. Machine Learning Method Using Position-Specific Mutation Based Classification Outperforms One Hot Coding for Disease Severity Prediction in Haemophilia “A”. Genomics 2020, 112, 5122–5128. [Google Scholar] [CrossRef]
- Shen, H.; Zhang, Y.; Zheng, C.; Wang, B.; Chen, P. A Cascade Graph Convolutional Network for Predicting Protein-Ligand Binding Affinity. Int. J. Mol. Sci. 2021, 22, 4023. [Google Scholar] [CrossRef]
- Béroud, C.; Joly, D.; Gallou, C.; Staroz, F.; Orfanelli, M.T.; Junien, C. Software and Database for the Analysis of Mutations in the VHL Gene. Nucleic Acids Res. 1998, 26, 256–258. [Google Scholar] [CrossRef]
- Mei, S.; Fei, W. Amino Acid Classification Based Spectrum Kernel Fusion for Protein Subnuclear Localization. BMC Bioinform. 2010, 11 (Suppl. S1), S17. [Google Scholar] [CrossRef]
- Li, L.; Luo, Q.; Xiao, W.; Li, J.; Zhou, S.; Li, Y.; Zheng, X.; Yang, H. A Machine-Learning Approach for Predicting Palmitoylation Sites from Integrated Sequence-Based Features. J. Bioinform. Comput. Biol. 2017, 15, 1650025. [Google Scholar] [CrossRef] [PubMed]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. arXiv 2013, arXiv:1310.4546. [Google Scholar]
- Wu, C.; Gao, R.; Zhang, Y.; De Marinis, Y. PTPD: Predicting Therapeutic Peptides by Deep Learning and Word2vec. BMC Bioinform. 2019, 20, 456. [Google Scholar] [CrossRef] [PubMed]
- Miao, Y.; Liu, F.; Hou, T.; Liu, Y. Virtifier: A Deep Learning-Based Identifier for Viral Sequences from Metagenomes. Bioinformatics 2022, 38, 1216–1222. [Google Scholar] [CrossRef]
- Abrahamsson, E.; Plotkin, S.S. BioVEC: A Program for Biomolecule Visualization with Ellipsoidal Coarse-Graining. J. Mol. Graph. Model. 2009, 28, 140–145. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Yang, S.; Li, Q.; Wuchty, S.; Zhang, Z. Prediction of Human-Virus Protein-Protein Interactions through a Sequence Embedding-Based Machine Learning Method. Comput. Struct. Biotechnol. J. 2020, 18, 153–161. [Google Scholar] [CrossRef] [PubMed]
- Li, F.; Yuan, L.; Lu, H.; Li, G.; Chen, Y.; Engqvist, M.K.M.; Kerkhoven, E.J.; Nielsen, J. Deep Learning-Based Kcat Prediction Enables Improved Enzyme-Constrained Model Reconstruction. Nat. Catal. 2022, 5, 662–672. [Google Scholar] [CrossRef]
- Yu, L.; Tanwar, D.K.; Penha, E.D.S.; Wolf, Y.I.; Koonin, E.V.; Basu, M.K. Grammar of Protein Domain Architectures. Proc. Natl. Acad. Sci. USA 2019, 116, 3636–3645. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Yang, X.; Bian, J.; Hogan, W.R.; Wu, Y. Clinical Concept Extraction Using Transformers. J. Am. Med. Inform. Assoc. 2020, 27, 1935–1942. [Google Scholar] [CrossRef]
- Chen, Z.-M.; Cui, Q.; Zhao, B.; Song, R.; Zhang, X.; Yoshie, O. SST: Spatial and Semantic Transformers for Multi-Label Image Recognition. IEEE Trans Image Process 2022, 31, 2570–2583. [Google Scholar] [CrossRef] [PubMed]
- Monteiro, N.R.C.; Oliveira, J.L.; Arrais, J.P. DTITR: End-to-End Drug-Target Binding Affinity Prediction with Transformers. Comput. Biol. Med. 2022, 147, 105772. [Google Scholar] [CrossRef] [PubMed]
- Mazuz, E.; Shtar, G.; Shapira, B.; Rokach, L. Molecule Generation Using Transformers and Policy Gradient Reinforcement Learning. Sci. Rep. 2023, 13, 8799. [Google Scholar] [CrossRef]
- Wang, H.; Guo, F.; Du, M.; Wang, G.; Cao, C. A Novel Method for Drug-Target Interaction Prediction Based on Graph Transformers Model. BMC Bioinform. 2022, 23, 459. [Google Scholar] [CrossRef]
- Rodriguez, M.A.; AlMarzouqi, H.; Liatsis, P. Multi-Label Retinal Disease Classification Using Transformers. IEEE J. Biomed. Health Inform. 2023, 27, 2739–2750. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Narasimhan, K. Improving Language Understanding by Generative Pre-Training. OpenAI Blog. 2018. Available online: https://openai.com/research/language-unsupervised (accessed on 20 October 2023).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners. OpenAI Blog. 2019. Available online: https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf (accessed on 20 October 2023).
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Meier, J.; Rao, R.; Verkuil, R.; Liu, J.; Sercu, T.; Rives, A. Language Models Enable Zero-Shot Prediction of the Effects of Mutations on Protein Function. bioRxiv 2021. [Google Scholar] [CrossRef]
- Rao, R.M.; Liu, J.; Verkuil, R.; Meier, J.; Canny, J.; Abbeel, P.; Sercu, T.; Rives, A. MSA Transformer. bioRxiv 2021. [Google Scholar] [CrossRef]
- Rives, A.; Meier, J.; Sercu, T.; Goyal, S.; Lin, Z.; Liu, J.; Guo, D.; Ott, M.; Zitnick, C.L.; Ma, J.; et al. Biological Structure and Function Emerge from Scaling Unsupervised Learning to 250 Million Protein Sequences. Proc. Natl. Acad. Sci. USA 2021, 118, e2016239118. [Google Scholar] [CrossRef]
- Elnaggar, A.; Heinzinger, M.; Dallago, C.; Rehawi, G.; Wang, Y.; Jones, L.; Gibbs, T.; Feher, T.; Angerer, C.; Steinegger, M.; et al. ProtTrans: Towards Cracking the Language of Lifes Code Through Self-Supervised Deep Learning and High Performance Computing. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7112–7127. [Google Scholar] [CrossRef]
- Madani, A.; Krause, B.; Greene, E.R.; Subramanian, S.; Mohr, B.P.; Holton, J.M.; Olmos, J.L.; Xiong, C.; Sun, Z.Z.; Socher, R.; et al. Large Language Models Generate Functional Protein Sequences across Diverse Families. Nat. Biotechnol. 2023, 41, 1099–1106. [Google Scholar] [CrossRef]
- Verkuil, R.; Kabeli, O.; Du, Y.; Wicky, B.I.M.; Milles, L.F.; Dauparas, J.; Baker, D.; Sercu, T.; Ovchinnikov, S.; Rives, A. Language Models Generalize beyond Natural Proteins. bioRxiv 2022. [Google Scholar] [CrossRef]
- Hie, B.; Candido, S.; Lin, Z.; Kabeli, O.; Rao, R.; Smetanin, N.; Sercu, T.; Alexander Rives, A. A High-Level Programming Language for Generative Protein Design. bioRxiv 2022. [Google Scholar] [CrossRef]
- Qu, G.; Li, A.; Acevedo-Rocha, C.G.; Sun, Z.; Reetz, M.T. The Crucial Role of Methodology Development in Directed Evolution of Selective Enzymes. Angew. Chem. Int. Ed. 2020, 59, 13204–13231. [Google Scholar] [CrossRef] [PubMed]
- Cho, S.Y.; Yun, Y.S.; Jang, D.; Jeon, J.W.; Kim, B.H.; Lee, S.; Jin, H.-J. Ultra Strong Pyroprotein Fibres with Long-Range Ordering. Nat. Commun. 2017, 8, 74. [Google Scholar] [CrossRef] [PubMed]
- Yuan, P.; Bartlam, M.; Lou, Z.; Chen, S.; Zhou, J.; He, X.; Lv, Z.; Ge, R.; Li, X.; Deng, T.; et al. Crystal Structure of an Avian Influenza Polymerase PAN Reveals an Endonuclease Active Site. Nature 2009, 458, 909–913. [Google Scholar] [CrossRef]
- Kircali Ata, S.; Fang, Y.; Wu, M.; Li, X.-L.; Xiao, X. Disease Gene Classification with Metagraph Representations. Methods 2017, 131, 83–92. [Google Scholar] [CrossRef]
- Woodard, J.; Iqbal, S.; Mashaghi, A. Circuit Topology Predicts Pathogenicity of Missense Mutations. Proteins 2022, 90, 1634–1644. [Google Scholar] [CrossRef] [PubMed]
- Senior, A.W.; Evans, R.; Jumper, J.; Kirkpatrick, J.; Sifre, L.; Green, T.; Qin, C.; Žídek, A.; Nelson, A.W.R.; Bridgland, A.; et al. Improved Protein Structure Prediction Using Potentials from Deep Learning. Nature 2020, 577, 706–710. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Anishchenko, I.; Park, H.; Peng, Z.; Ovchinnikov, S.; Baker, D. Improved Protein Structure Prediction Using Predicted Interresidue Orientations. Proc. Natl. Acad. Sci. USA 2020, 117, 1496–1503. [Google Scholar] [CrossRef] [PubMed]
- Zheng, W.; Zhang, C.; Li, Y.; Pearce, R.; Bell, E.W.; Zhang, Y. Folding Non-Homologous Proteins by Coupling Deep-Learning Contact Maps with I-TASSER Assembly Simulations. Cell Rep. 2021, 1, 100014. [Google Scholar] [CrossRef] [PubMed]
- Mortuza, S.M.; Zheng, W.; Zhang, C.; Li, Y.; Pearce, R.; Zhang, Y. Improving Fragment-Based Ab Initio Protein Structure Assembly Using Low-Accuracy Contact-Map Predictions. Nat. Commun. 2021, 12, 5011. [Google Scholar] [CrossRef]
- Pearce, R.; Li, Y.; Omenn, G.S.; Zhang, Y. Fast and Accurate Ab Initio Protein Structure Prediction Using Deep Learning Potentials. PLoS Comput. Biol. 2022, 18, e1010539. [Google Scholar] [CrossRef]
- Olechnovič, K.; Venclovas, Č. Voronota: A Fast and Reliable Tool for Computing the Vertices of the Voronoi Diagram of Atomic Balls. J. Comput. Chem. 2014, 35, 672–681. [Google Scholar] [CrossRef]
- Li, B.; Yang, Y.T.; Capra, J.A.; Gerstein, M.B. Predicting Changes in Protein Thermodynamic Stability upon Point Mutation with Deep 3D Convolutional Neural Networks. PLoS Comput. Biol. 2020, 16, e1008291. [Google Scholar] [CrossRef]
- Jing, B.; Eismann, S.; Suriana, P.; Townshend, R.J.L.; Dror, R. Learning from Protein Structure with Geometric Vector Perceptrons. arXiv 2021, arXiv:2009.01411. [Google Scholar]
- Wang, Y.; Wu, S.; Duan, Y.; Huang, Y. A Point Cloud-Based Deep Learning Strategy for Protein-Ligand Binding Affinity Prediction. Brief. Bioinform. 2022, 23, bbab474. [Google Scholar] [CrossRef]
- Igashov, I.; Olechnovič, K.; Kadukova, M.; Venclovas, Č.; Grudinin, S. VoroCNN: Deep Convolutional Neural Network Built on 3D Voronoi Tessellation of Protein Structures. Bioinformatics 2021, 37, 2332–2339. [Google Scholar] [CrossRef]
- Dapkūnas, J.; Timinskas, A.; Olechnovič, K.; Margelevičius, M.; Dičiūnas, R.; Venclovas, Č. The PPI3D Web Server for Searching, Analyzing and Modeling Protein–Protein Interactions in the Context of 3D Structures. Bioinformatics 2017, 33, 935–937. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Wang, J.; Chang, F.; Gong, W.; Liu, Y.; Li, C. Identification of Metal Ion-Binding Sites in RNA Structures Using Deep Learning Method. Brief. Bioinform. 2023, 24, bbad049. [Google Scholar] [CrossRef] [PubMed]
- Defresne, M.; Barbe, S.; Schiex, T. Protein Design with Deep Learning. Int. J. Mech. Sci. 2021, 22, 11741. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
| Methods | Models | Inputs | Multimeric Structure | Advantages | URLs | References |
|---|---|---|---|---|---|---|
| ColabFold | JAX | MSA-based | Yes | 40–60 × faster prediction than AlphaFold2, and user friendly | https://github.com/sokrypton/ColabFold, accessed on 24 November 2023 | [65] |
| OpenFold | PyTorch | MSA-based | Yes | PyTorch replication of AlphaFold, high flexibility | https://github.com/aqlaboratory/openfold, accessed on 24 November 2023 | N/A |
| Uni-Fold | PyTorch | MSA-based | Yes | Friendly operating environment, and wide hardware adaptation | https://github.com/dptech-corp/Uni-Fold, accessed on 24 November 2023 | [66] |
| FastFold | PyTorch | MSA-based | No | Reduced training time from 11 days to 67 h | https://github.com/hpcaitech/FastFold, accessed on 24 November 2023 | [67] |
| HelixFold | PaddleHelix | MSA-based | No | Improved training and prediction speed, and reduced memory consumption | https://github.com/PaddlePaddle/PaddleHelix/tree/dev/apps/protein_folding/helixfold, accessed on 24 November 2023 | [68] |
| MindSpore-Fold | MindSpore | MSA-based | Yes | Based on MindSpore framework, high performance, and fast prediction speed | https://github.com/mindspore-ai/mindspore, accessed on 24 November 2023 | N/A |
| MEGA-Fold | MindSpore | MSA-based | No | More accurate and efficient protein structure prediction than AlphaFold2 | https://gitee.com/mindspore/mindscience/tree/master/MindSPONGE/applications/MEGAProtein, accessed on 24 November 2023 | [69] |
| EMBER3D | PyTorch | pLM-based | No | Ability to visualize the effect of mutations on predicted structures and high predictive efficiency | https://github.com/kWeissenow/EMBER3D, accessed on 24 November 2023 | N/A |
| ESM-Fold | PyTorch | pLM-based | No | Reduced dependence on MSA input, inference speed is an order of magnitude faster than AlphaFold2 | N/A | [51] |
| HelixFold-Single | PaddleHelix | pLM-based | No | Breaking the speed bottleneck of relying on MSA retrieval models, and prediction accuracy is comparable to AlphaFold2 and nearly a thousand times faster | https://github.com/PaddlePaddle/PaddleHelix/tree/dev/apps/protein_folding/helixfold-single, accessed on 24 November 2023 | [70] |
| OmegaFold | PyTorch | pLM-based | No | Protein homology-independent, easy to install, and overall predictive power comparable to AlphaFold2 and RoseTTAFold | https://github.com/HeliXonProtein/OmegaFold, accessed on 24 November 2023 | [71] |
| IgFold | PyTorch | pLM-based | No | Focus on antibody structure prediction, high prediction accuracy, and prediction time less than 1 min | https://github.com/Graylab/IgFold, accessed on 24 November 2023 | [72] |
| D-I-TASSER | PyTorch | MSA-based | Higher prediction accuracy with online server | https://zhanggroup.org/D-I-TASSER/, accessed on 24 November 2023 | [73] |
| Encoding | Description | Characteristic | Main Category | Application | |
|---|---|---|---|---|---|
| Based on the sequence | k-mer | K-mer is a subsequence of length k that is used to minimize the effects of arbitrary starting points, where k is an integer, ranging from 1 to hundreds. | Reflects the frequency of k-conjoined AAs in the protein sequence. | Based on AA information | [125,126,127] |
| PSSM | Logarithm of the probability of all possible molecular types occurring at each position in a given biological sequence. | Powerful, but neglects the interactions between different residues. | Based on evolutionary information | [128,129] | |
| BLOSUM | Reflects the exchange probability of AA pairs. | Research results vary with the type of matrix. | Based on evolutionary information | [130] | |
| Autocorrelation | The interdependence of AAs in a given sequence. | Reduces the feature space and standardize the sequence length. | Based on physicochemical properties | [131] | |
| CTD | The composition, transition, and distribution (CTD) of AAs in a given sequence. | Reflects the distribution of AAs with diverse structures and physicochemical characters in a given sequence. | Based on physicochemical properties | [132,133,134] | |
| CTriad | The conjoint triad (CTriad) is generally regarded to consist of a combination of three adjacent AAs. | AAs were divided into 7 groups based on the side chain volume and dipole. | Based on physicochemical properties | [135,136] | |
| Z-scales | The Z-scales obtained from the field of quantitative sequence- activity modeling (QSAM). | The most widely used descriptor set in proteochemometric modeling, | Based on physicochemical properties | [137] | |
| VHSE | Vectors of hydrophobic, steric, and electronic properties (VHSE) are derived from principal components analysis (PCA) of independent families of 18 hydrophobic properties, 17 steric properties, and 15 electronic properties, respectively. | VHSE is of relatively definite physicochemical meaning, easy interpretation, and contains more information compared with z scales. | Based on physicochemical properties | [138,139] | |
| ProtFP | Protein Fingerprint (ProtFP) is based on a selection of different AA properties obtained from the AAindex database. | The descriptor was obtained using recursive elimination of the most co-varying properties after starting with the full set of indices. | Based on physicochemical properties | [139,140] | |
| FASGAI | The factor analysis scales of generalized AA information (FASGAI) are derived from 335 physicochemical properties of the 20 natural AAs. | Applying a factor analysis rather than a PCA. | Based on physicochemical properties | [139,141] | |
| Based on the structure | T-scale | Derived from PCA on the 67 kinds of structural and topological variables of 135 AAs. | The 3D properties of each structure are not explicitly considered. | Topology-based representation method | [142] |
| ST-scale | Structural topology scale (ST-scale) was recruited as a novel structural topological descriptor derived from PCA on 827 structural variables of 167 AAs. | The molecular structure was optimized, and 3D information of AAs was used. | Topology-based representation method | [143,144] | |
| MSWHIM | The MSWHIM descriptor set is derived from 36 electrostatic potential properties obtained from the 3D molecule structure. | The number of indicators is simple, easy to calculate, and invariant to the coordinate system. | Geometric-based representation method | [145] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Chen, C.; Yao, G.; Ding, J.; Wang, L.; Jiang, H. Intelligent Protein Design and Molecular Characterization Techniques: A Comprehensive Review. Molecules 2023, 28, 7865. https://doi.org/10.3390/molecules28237865
Wang J, Chen C, Yao G, Ding J, Wang L, Jiang H. Intelligent Protein Design and Molecular Characterization Techniques: A Comprehensive Review. Molecules. 2023; 28(23):7865. https://doi.org/10.3390/molecules28237865
Chicago/Turabian StyleWang, Jingjing, Chang Chen, Ge Yao, Junjie Ding, Liangliang Wang, and Hui Jiang. 2023. "Intelligent Protein Design and Molecular Characterization Techniques: A Comprehensive Review" Molecules 28, no. 23: 7865. https://doi.org/10.3390/molecules28237865
APA StyleWang, J., Chen, C., Yao, G., Ding, J., Wang, L., & Jiang, H. (2023). Intelligent Protein Design and Molecular Characterization Techniques: A Comprehensive Review. Molecules, 28(23), 7865. https://doi.org/10.3390/molecules28237865