
Species Identification of Bovine, Ovine and Porcine Type 1 Collagen; Comparing Peptide Mass Fingerprinting and LC-Based Proteomics Methods

Abstract
:1. Introduction
1.1. Collagen Structure
1.2. Species Identification
2. Molecular Techniques in Species Identification
3. Results
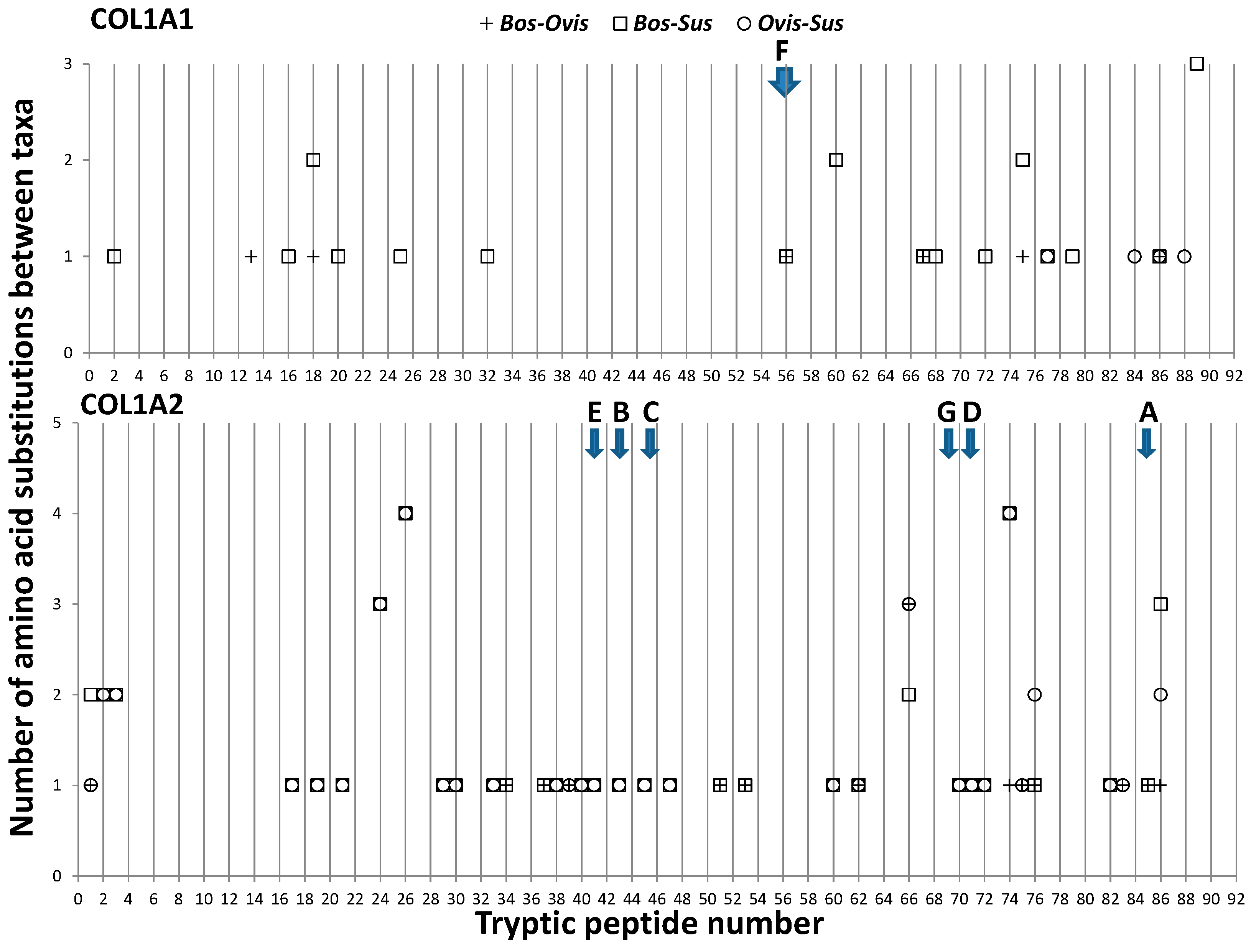
3.1. Collagen Variation between Artiodactyls
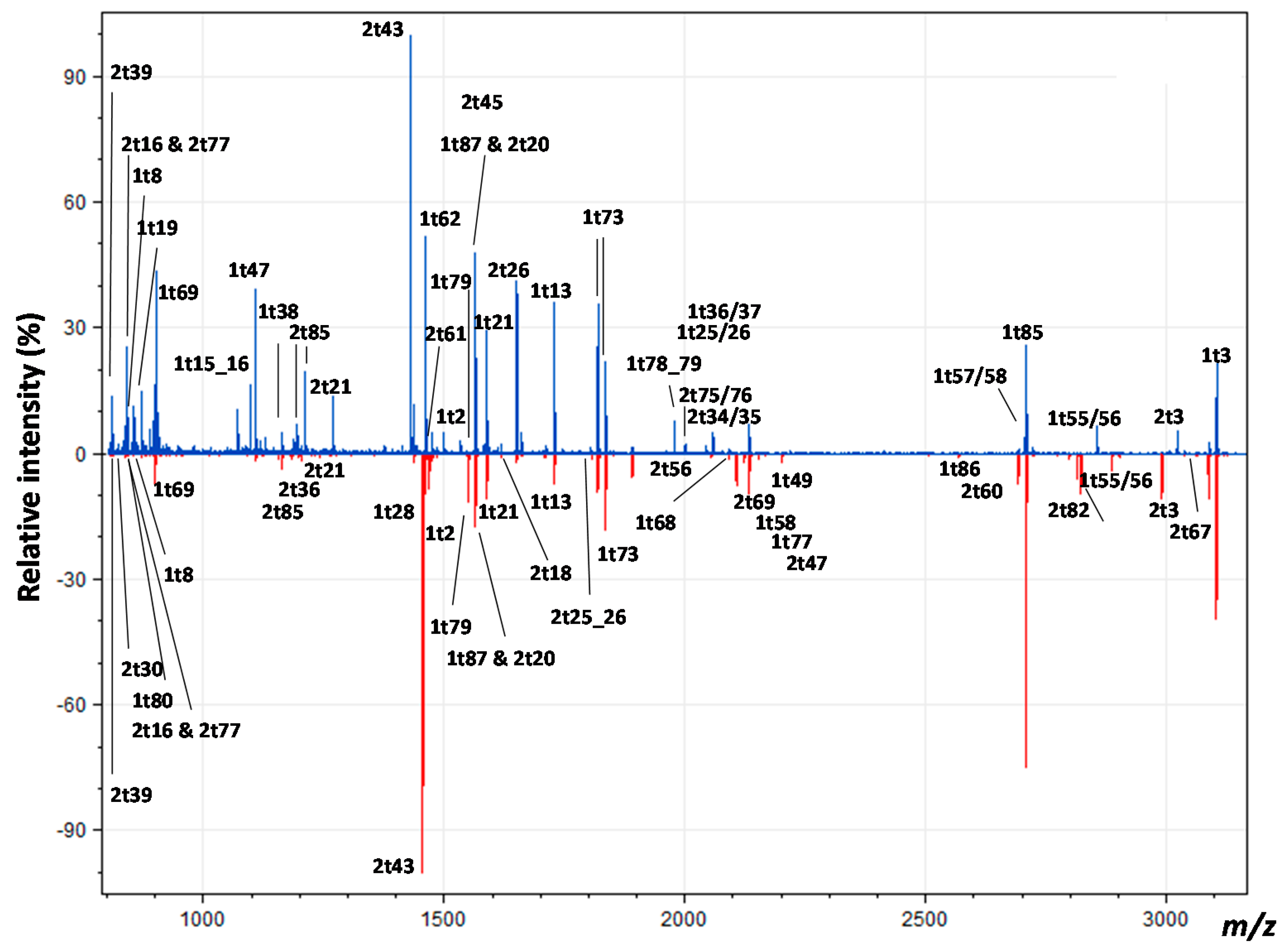
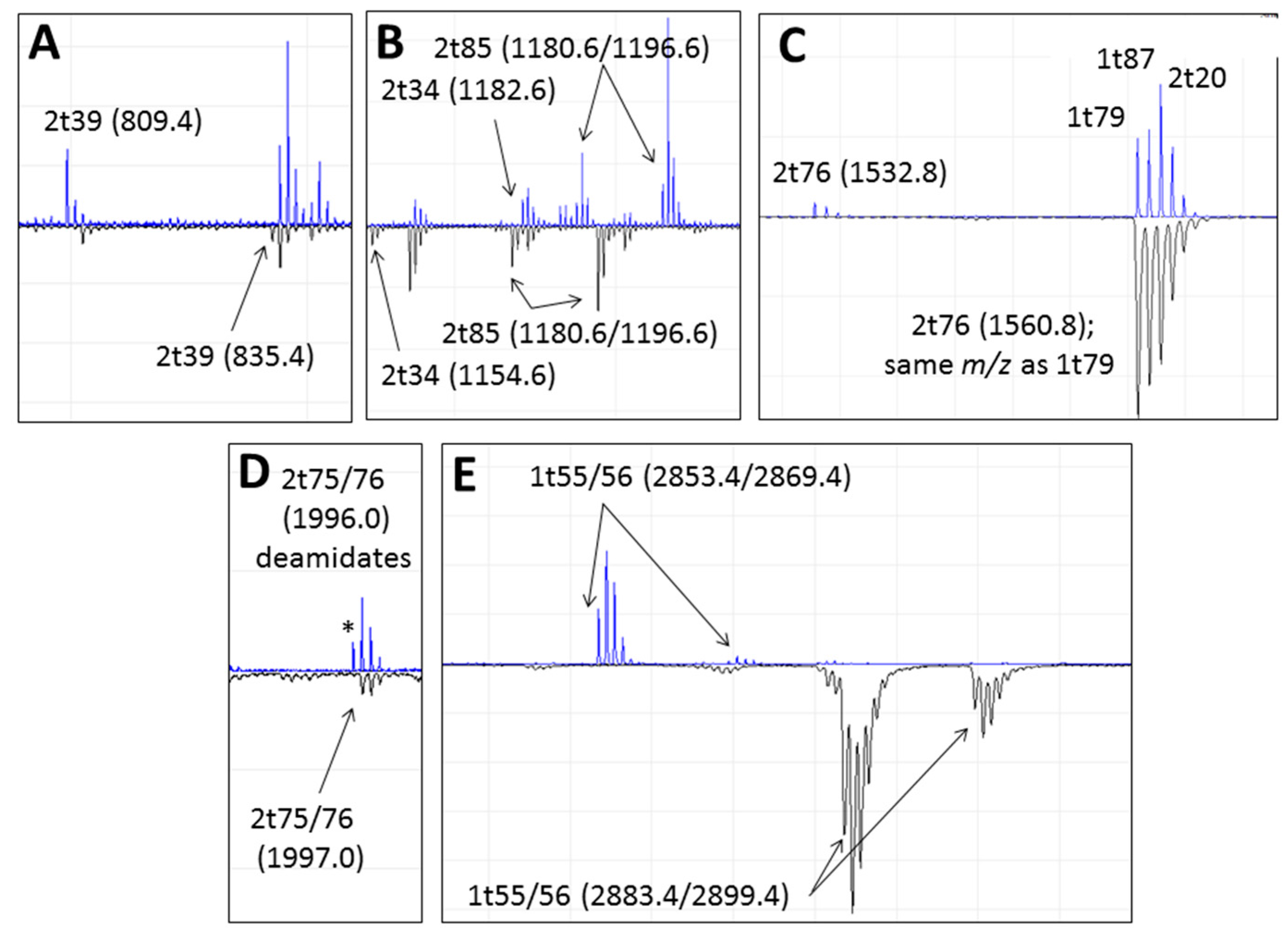
3.2. Peptide Mass Fingerprinting
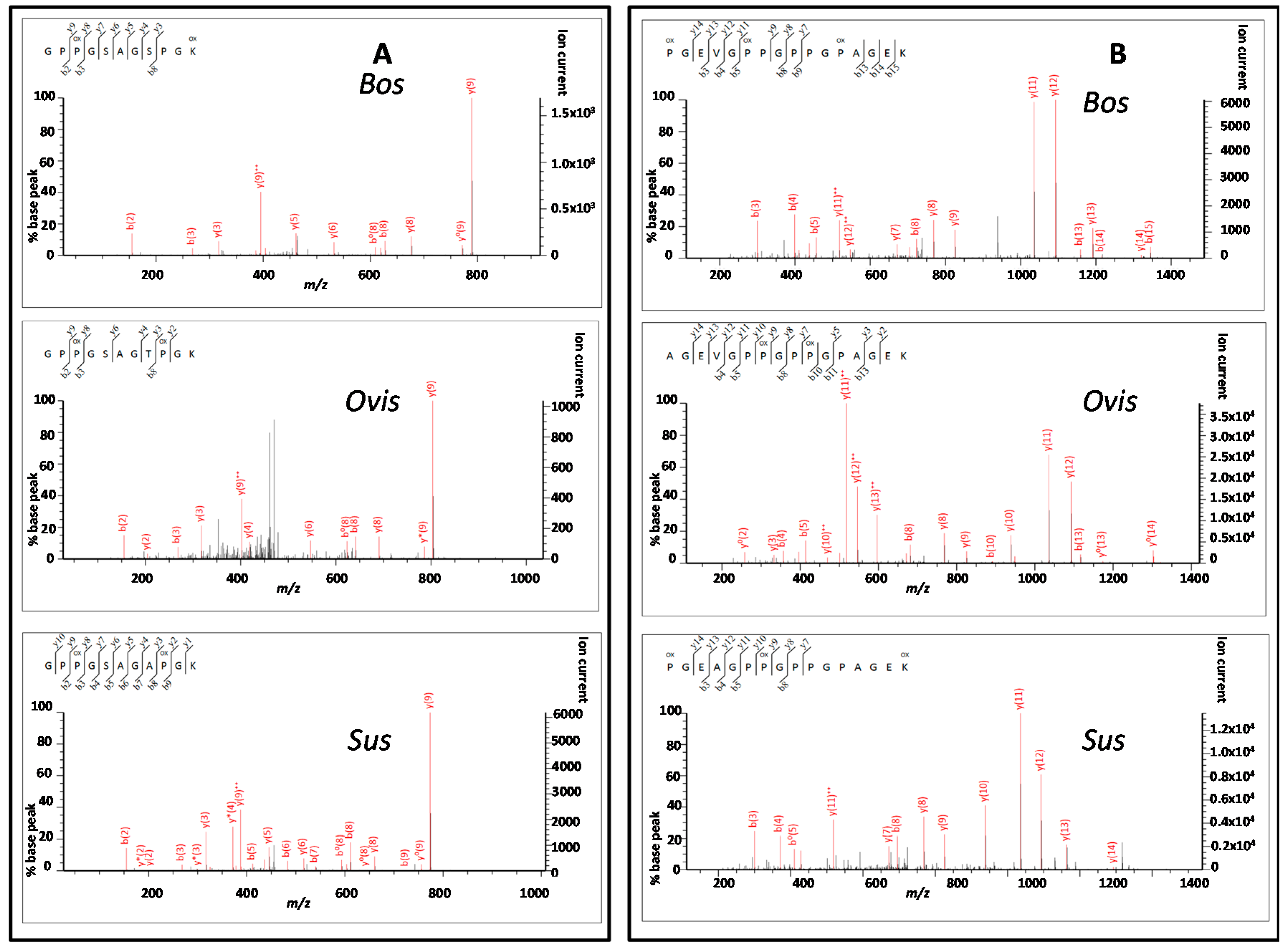
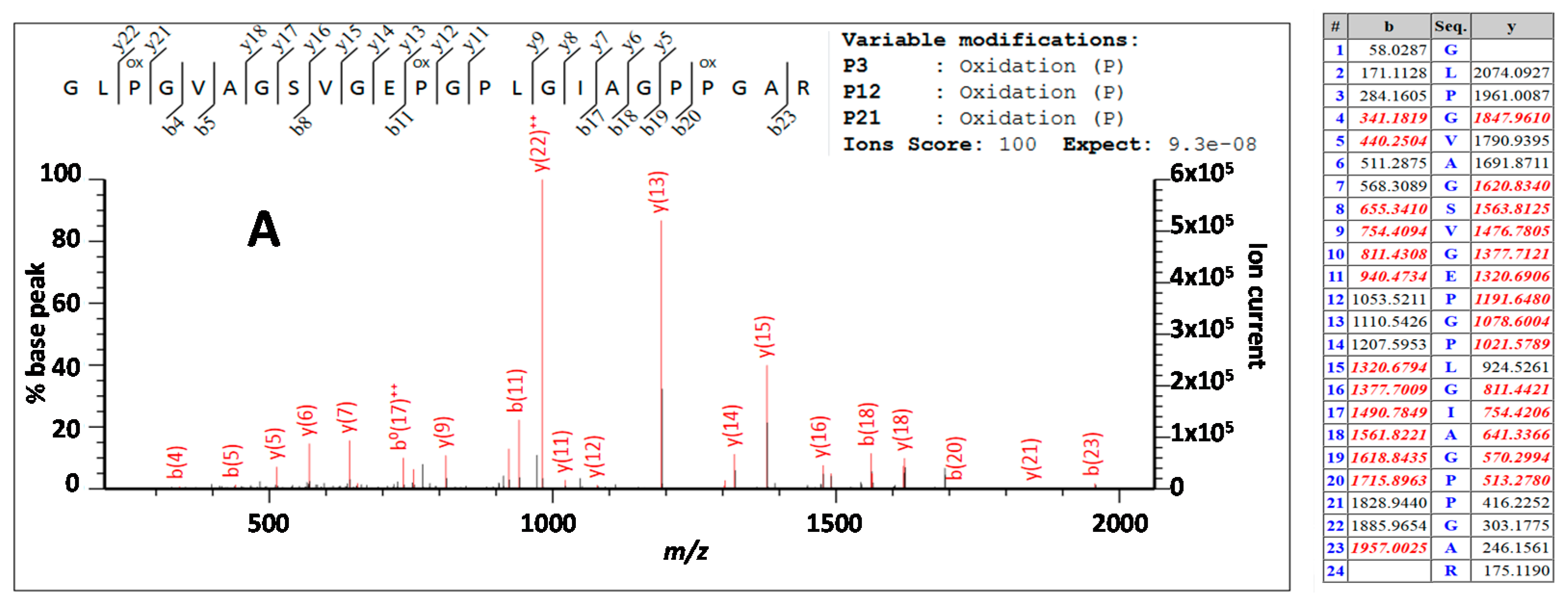
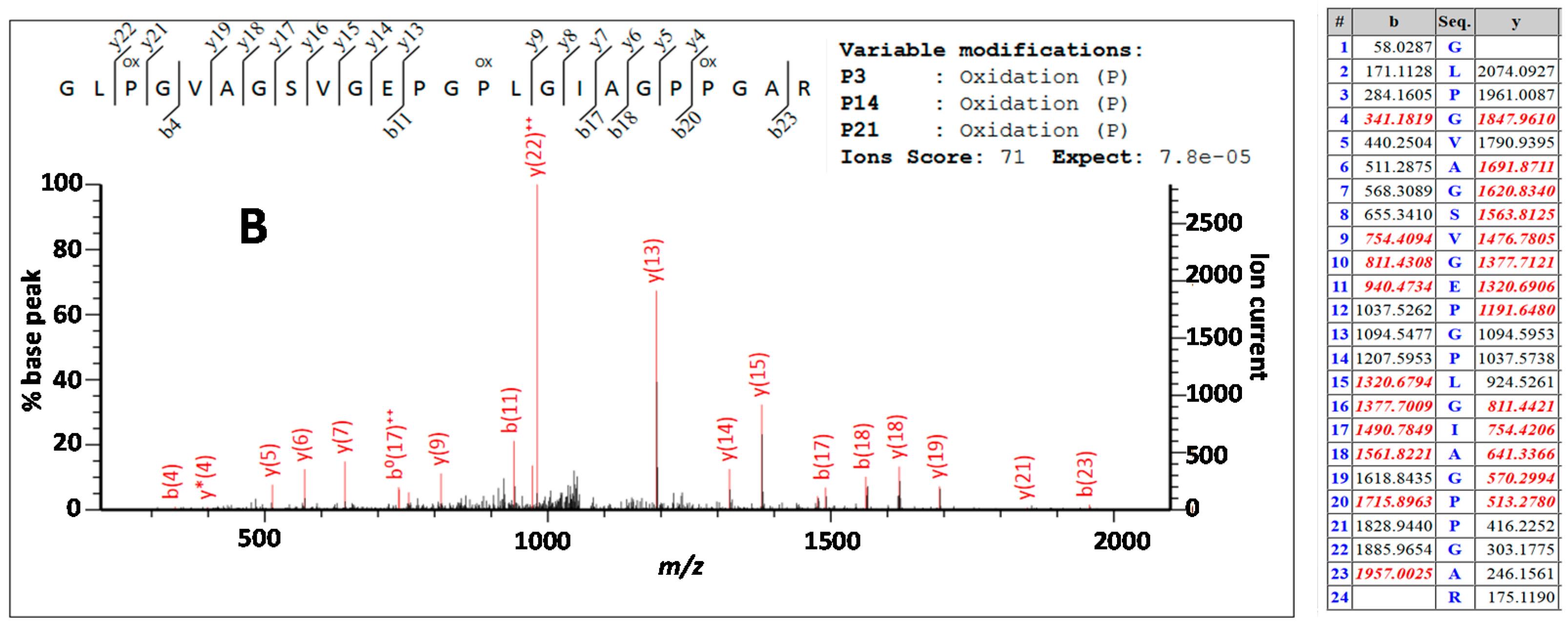
3.3. Peptide Sequencing
4. Discussion
4.1. Regions of Collagen Sequence Variation
4.2. Comparing Peptide Fingerprinting with Sequencing
4.3. Variable Hydroxylation
4.4. Alternative Approaches
5. Materials and Methods
6. Conclusions
Supplementary Materials
Acknowledgments
Conflicts of Interest
References
- Hirai, J.; Matsuda, T. Venous reconstruction using hybrid vascular tissue composed of vascular cells and collagen: Tissue regeneration process. Cell Transplant. 1996, 5, 93–105. [Google Scholar] [CrossRef]
- Liao, S.; Wang, W.; Uo, M.; Ohkawa, S.; Akasaka, T.; Tamura, K.; Cui, F.; Watari, F. A three-layered nano-carbonated hydroxyapatite/collagen/PLGA composite membrane for guided tissue regeneration. Biomaterials 2005, 26, 7564–7571. [Google Scholar] [CrossRef] [PubMed]
- Whitmore, R.; Jones, H.; Windus, W.; Naghski, J. Preparation of hide collagen for food. J. Am. Leather Chem. Assoc. 1970, 65, 382–389. [Google Scholar]
- Gómez-Guillén, M.; Giménez, B.; López-Caballero, M.; Montero, M. Functional and bioactive properties of collagen and gelatin from alternative sources: A review. Food Hydrocoll. 2011, 25, 1813–1827. [Google Scholar] [CrossRef] [Green Version]
- Buckley, M.; Penkman, K.; Wess, T.J.; Reaney, S.; Collins, M. Protein and mineral characterisation of rendered meat and bone meal. Food Chem. 2012, 134, 1267–1278. [Google Scholar] [CrossRef] [PubMed]
- Sapkota, A.R.; Lefferts, L.Y.; McKenzie, S.; Walker, P. What do we feed to food-production animals? A review of animal feed ingredients and their potential impacts on human health. Environ. Health Perspect. 2007, 115, 663–670. [Google Scholar] [CrossRef] [PubMed]
- Van Raamsdonk, L.; von Holst, C.; Baeten, V.; Berben, G.; Boix, A.; de Jong, J. New developments in the detection and identification of processed animal proteins in feeds. Anim. Feed Sci. Technol. 2007, 133, 63–83. [Google Scholar] [CrossRef]
- Fumière, O.; Dubois, M.; Baeten, V.; von Holst, C.; Berben, G. Effective PCR detection of animal species in highly processed animal byproducts and compound feeds. Anal. Bioanal. Chem. 2006, 385, 1045–1054. [Google Scholar] [CrossRef] [PubMed]
- Davis, S.J.; Beckett, J.V. Animal husbandry and agricultural improvement: The archaeological evidence from animal bones and teeth. Rural Hist. 1999, 10, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Behrensmeyer, A.K.; Western, D.; Boaz, D.E.D. New perspectives in vertebrate paleoecology from a recent bone assemblage. Paleobiology 1979, 5, 12–21. [Google Scholar]
- Ramachandran, G.; Kartha, G. Structure of collagen. Nature 1954, 174, 269–270. [Google Scholar] [CrossRef] [PubMed]
- Rich, A.; Crick, F. The structure of collagen. Nature 1955, 4489, 915–916. [Google Scholar] [CrossRef]
- Jenkins, C.L.; Bretscher, L.E.; Guzei, I.A.; Raines, R.T. Effect of 3-hydroxyproline residues on collagen stability. J. Am. Chem. Soc. 2003, 125, 6422–6427. [Google Scholar] [CrossRef] [PubMed]
- Yamauchi, M.; Shiiba, M. Lysine hydroxylation and cross-linking of collagen. In Post-Translational Modifications of Proteins; Springer: Heidelberg, Germany, 2008; pp. 95–108. [Google Scholar]
- Rybczynski, N.; Gosse, J.C.; Harington, C.R.; Wogelius, R.A.; Hidy, A.J.; Buckley, M. Mid-Pliocene warm-period deposits in the High Arctic yield insight into camel evolution. Nat. Commun. 2013, 4, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Covington, A.; Song, L.; Suparno, O.; Koon, H.; Collins, M. Link-lock: An explanation of the chemical stabilisation of collagen. J. Soc. Leather Technol. Chem. 2008, 92, 1–7. [Google Scholar]
- Bottero, M.T.; Dalmasso, A. Animal species identification in food products: Evolution of biomolecular methods. Vet. J. 2011, 190, 34–38. [Google Scholar] [CrossRef] [PubMed]
- Premanandh, J. Horse meat scandal—A wake-up call for regulatory authorities. Food Control 2013, 34, 568–569. [Google Scholar] [CrossRef]
- Berben, G.; Baeten, V.; Fumière, O.; Veys, P.; Boix, A.; von Holst, C. Methods of detection, species identification and quantification of processed animal proteins in feedingstuffs. Biotechnol. Agron. Soc. Environ. 2009, 13, 59–70. [Google Scholar]
- Baeten, V.; Reiner, A.M.; Sinnaeve, G.; Dardenne, P. Analysis of feedingstuffs by near-infrared microscopy (NIRM): Detection and quantification of meat and bone meal (MBM). In Proceedings of the 6th International Symposium on Food Authenticity and Safety, Nantes, France, 28–30 November 2001.
- Gizzi, G.; Holst, C.; Baeten, V.; Berben, G.; Raamsdonk, L. Determination of processed animal proteins, including meat and bone meal, in animal feed. J. AOAC Int. 2004, 87, 1334–1341. [Google Scholar] [PubMed]
- Kim, S.H.; Huang, T.S.; Seymour, T.A.; Wei, C.I.; Kempf, S.C.; Bridgman, C.R.; Momcilovic, D.; Clemens, R.A.; An, H. Development of immunoassay for detection of meat and bone meal in animal feed. J. Food Prot. 2005, 68, 1860–1865. [Google Scholar] [PubMed]
- Lahiff, S.; Glennon, M.; O’Brien, L.; Lyng, J.; Smith, T.; Maher, M.; Shilton, N. Species-specific PCR for the identification of ovine, porcine and chicken species in meat and bone meal (MBM). Mol. Cell. Probes 2001, 15, 27–35. [Google Scholar] [CrossRef] [PubMed]
- Outram, A.K.; Knüsel, C.J.; Knight, S.; Harding, A.F. Understanding complex fragmented assemblages of human and animal remains: A fully integrated approach. J. Archaeol. Sci. 2005, 32, 1699–1710. [Google Scholar] [CrossRef]
- Fletcher, S.M.; Dolton, P.; Harris-Smith, P.W. Species identification of blood and saliva stains by enzyme-linked immunoassay (ELISA) using monoclonal antibody. J. Forensic Sci. 1984, 29, 67–74. [Google Scholar] [CrossRef] [PubMed]
- Kang’ethe, E.; Gathuma, J. Species identification of autoclaved meat samples using antisera to thermostable muscle antigens in an enzyme immunoassay. Meat Sci. 1987, 19, 265–270. [Google Scholar] [CrossRef]
- Asensio, L.; González, I.; García, T.; Martín, R. Determination of food authenticity by enzyme-linked immunosorbent assay (ELISA). Food Control 2008, 19, 1–8. [Google Scholar] [CrossRef]
- Kreuz, G.; Zagon, J.; Broll, H.; Bernhardt, C.; Linke, B.; Lampen, A. Immunological detection of osteocalcin in meat and bone meal: A novel heat stable marker for the investigation of illegal feed adulteration. Food Addit. Contam. A 2012, 29, 716–726. [Google Scholar] [CrossRef] [PubMed]
- Buckley, M.; Collins, M.; Thomas-Oates, J.; Wilson, J.C. Species identification by analysis of bone collagen using matrix-assisted laser desorption/ionisation time-of-flight mass spectrometry. Rapid Commun. Mass Spectrom. 2009, 23, 3843–3854. [Google Scholar] [CrossRef] [PubMed]
- Buckley, M.; Fraser, S.; Herman, J.; Melton, N.; Mulville, J.; Pálsdóttir, A. Species identification of archaeological marine mammals using collagen fingerprinting. J. Archaeol.Sci. 2014, 41, 631–641. [Google Scholar] [CrossRef] [Green Version]
- Demirev, P.A.; Lin, J.S.; Pineda, F.J.; Fenselau, C. Bioinformatics and mass spectrometry for microorganism identification: Proteome-wide post-translational modifications and database search algorithms for characterization of intact H. pylori. Anal. Chem. 2001, 73, 4566–4573. [Google Scholar] [CrossRef] [PubMed]
- Welker, M. Proteomics for routine identification of microorganisms. Proteomics 2011, 11, 3143–3153. [Google Scholar] [CrossRef] [PubMed]
- Balizs, G.; Weise, C.; Rozycki, C.; Opialla, T.; Sawada, S.; Zagon, J.; Lampen, A. Determination of osteocalcin in meat and bone meal of bovine and porcine origin using matrix-assisted laser desorption ionization/time-of-flight mass spectrometry and high-resolution hybrid mass spectrometry. Anal. Chim. Acta 2011, 693, 89–99. [Google Scholar] [CrossRef] [PubMed]
- Pappin, D.J.; Hojrup, P.; Bleasby, A.J. Rapid identification of proteins by peptide-mass fingerprinting. Curr. Biol. 1993, 3, 327–332. [Google Scholar] [CrossRef]
- Sommerer, N.; Centeno, D.; Rossignol, M. Peptide mass fingerprinting. In Plant Proteomics; Springer: Heidelberg, Germany, 2007; pp. 219–234. [Google Scholar]
- McDonald, W.H.; Yates, J., III. Shotgun proteomics: Integrating technologies to answer biological questions. Curr. Opin. Mol. Ther. 2003, 5, 302–309. [Google Scholar] [PubMed]
- Michalski, A.; Cox, J.; Mann, M. More than 100,000 detectable peptide species elute in single shotgun proteomics runs but the majority is inaccessible to data-dependent LC-MS/MS. J. Proteome Res. 2011, 10, 1785–1793. [Google Scholar] [CrossRef] [PubMed]
- Sweeney, S.M.; Orgel, J.P.; Fertala, A.; McAuliffe, J.D.; Turner, K.R.; di Lullo, G.A.; Chen, S.; Antipova, O.; Perumal, S.; Ala-Kokko, L.; et al. Candidate cell and matrix interaction domains on the collagen fibril, the predominant protein of vertebrates. J. Biol. Chem. 2008, 283, 21187–21197. [Google Scholar] [CrossRef] [PubMed]
- Boot-Handford, R.P.; Tuckwell, D.S. Fibrillar collagen: The key to vertebrate evolution? A tale of molecular incest. Bioessays 2003, 25, 142–151. [Google Scholar] [CrossRef] [PubMed]
- Doyle, B.B.; Hukins, D.W.; Hulmes, D.J.; Miller, A.; Woodhead-Galloway, J. Collagen polymorphism: Its origins in the amino acid sequence. J. Mol. Biol. 1975, 91, 79–99. [Google Scholar] [CrossRef]
- Han, S.; Makareeva, E.; Kuznetsova, N.V.; DeRidder, A.M.; Sutter, M.B.; Losert, W.; Phillips, C.L.; Visse, R.; Nagase, H.; Leikin, S. Molecular mechanism of type I collagen homotrimer resistance to mammalian collagenases. J. Biol. Chem. 2010, 285, 22276–22281. [Google Scholar] [CrossRef] [PubMed]
- De Souza, S.; Brentani, R. Collagen binding site in collagenase can be determined using the concept of sense-antisense peptide interactions. J. Biol. Chem. 1992, 267, 13763–13767. [Google Scholar] [PubMed]
- Slatter, D.A.; Farndale, R.W. Structural constraints on the evolution of the collagen fibril: Convergence on a 1014-residue COL domain. Open Biol. 2015, 5. [Google Scholar] [CrossRef] [PubMed]
- Roepstorff, P.; Fohlman, J. Letter to the editors. Biol. Mass Spectrom. 1984, 11, 601. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.; Liu, T.; Wang, Q.; Chen, L.; Lei, J.; Luo, J.; Ma, G.; Su, Z. Mass spectrometric detection of marker peptides in tryptic digests of gelatin: A new method to differentiate between bovine and porcine gelatin. Food Hydrocoll. 2009, 23, 2001–2007. [Google Scholar] [CrossRef]
- Henkel, W.; Dreisewerd, K. Cyanogen bromide peptides of the fibrillar collagens I, III, and V and their mass spectrometric characterization: Detection of linear peptides, peptide glycosylation, and cross-linking peptides involved in formation of homo-and heterotypic fibrils. J. Proteome Res. 2007, 6, 4269–4289. [Google Scholar] [CrossRef] [PubMed]
- Basak, T.; Vega-Montoto, L.; Zimmerman, L.J.; Tabb, D.L.; Hudson, B.G.; Vanacore, R.M. Comprehensive characterization of glycosylation and hydroxylation of basement membrane collagen IV by high-resolution mass spectrometry. J. Proteome Res. 2016, 15, 245–258. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Park, A.C.; Davis, N.A.; Russell, J.D.; Kim, B.; Brand, D.D.; Lawrence, M.J.; Ge, Y.; Westphall, M.S.; Coon, J.J.; et al. Comprehensive mass spectrometric mapping of the hydroxylated amino acid residues of the α1(V) collagen chain. J. Biol. Chem. 2012, 287, 40598–40610. [Google Scholar] [CrossRef] [PubMed]
- Arsenault, P.R.; Heaton-Johnson, K.J.; Li, L.S.; Song, D.; Ferreira, V.S.; Patel, N.; Master, S.R.; Lee, F.S. Identification of prolyl hydroxylation modifications in mammalian cell proteins. Proteomics 2015, 15, 1259–1267. [Google Scholar] [CrossRef] [PubMed]
- Nielsen-Marsh, C.M.; Richards, M.P.; Hauschka, P.V.; Thomas-Oates, J.E.; Trinkaus, E.; Pettitt, P.B.; Karavanić, I.; Poinar, H.; Collins, M.J. Osteocalcin protein sequences of Neanderthals and modern primates. Proc. Natl. Acad. Sci. USA 2005, 102, 4409–4413. [Google Scholar] [CrossRef] [PubMed]
- Picotti, P.; Aebersold, R. Selected reaction monitoring-based proteomics: Workflows, potential, pitfalls and future directions. Nat. Methods 2012, 9, 555–566. [Google Scholar] [CrossRef] [PubMed]
- Law, K.P.; Lim, Y.P. Recent advances in mass spectrometry: Data independent analysis and hyper reaction monitoring. Expert Rev. Proteom. 2013, 10, 551–566. [Google Scholar] [CrossRef] [PubMed]
- Wadsworth, C.; Buckley, M. Proteome degradation in fossils: Investigating the longevity of protein survival in ancient bone. Rapid Commun. Mass Spectrom. 2014, 28, 605–615. [Google Scholar] [CrossRef] [PubMed]
- Buckley, M.; Gu, M.; Shameer, S.; Patel, S.; Chamberlain, A. High-throughput collagen fingerprinting of intact microfaunal remains; a low-cost method for distinguishing between murine rodent bones. Rapid Commun. Mass Spectrom. 2016, 30, 1–8. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Peptide Label * | Sequence | Peptide Label * | Sequence |
|---|---|---|---|
| 1t1 | QLSYGYDEK | 1t47 (√) | GVQGPPGPAGPR |
| 1t2 (√) | STGISVPGPMGPSGPR; -A--------------(S) | 1t48 | GANGAPGNDGAK |
| 1t3 (√) | GLPGPPGAPGPQGFQGPPGEPGEPGASGPMGPR | 1t49 (√) | GDAGAPGAPGSQGAPGLQGMPGER |
| 1t4 | GPPGPPGK | 1t50 | GAAGLPGPK |
| 1t5 | NGDDGEAGK | 1t51 | GDR |
| 1t6 | PGR | 1t52 | GDAGPK |
| 1t7 | PGER | 1t53 | GADGAPGK |
| 1t8 (√) | GPPGPQGAR | 1t54 | DGVR |
| 1t9 | GLPGTAGLPGMK | 1t55 (F) (√) | GLTGPIGPPGPAGAPGDK |
| 1t10 | GHR | 1t56 (F) (√) | GEAGPSGPAGPTGAR; --T------------(O; S) |
| 1t11 | GFSGLDGAK | 1t57 (√) | GAPGDR |
| 1t12 | GDAGPAGPK | 1t58 (√) | GEPGPPGPAGFAGPPGADGQPGAK |
| 1t13 (√) | GEPGSPGENGAPGQMGPR; ----------T-------(O) | 1t59 | GEPGDAGAK |
| 1t14 | GLPGER | 1t60 | GDAGPPGPAGPAGPPGPIGNVGAPGPK; -----------T-------S-------(S) |
| 1t15 (√) | GR | 1t61 | GAR |
| 1t16 (√) | PGAPGPAGAR; --P-------(S) | 1t62 (√) | GSAGPPGATGFPGAAGR |
| 1t17 | GNDGATGAAGPPGPTGPAGPPGFPGAVGAK | 1t63 | VGPPGPSGNAGPPGPPGPAGK |
| 1t18 | GEGGPQGPR; --A------(O); --A----A-(S) | 1t64 | EGSK |
| 1t19 (√) | GSEGPQGVR | 1t65 | GPR |
| 1t20 | GEPGPPGPAGAAGPAGNPGADGQPGAK; -------------------------G-(S) | 1t66 | GETGPAGR |
| 1t21 (√) | GANGAPGIAGAPGFPGAR | 1t67 | PGEVGPPGPPGPAGEK; A---------------(O); ---A------------(S) |
| 1t22 | GPSGPQGPSGPPGPK | 1t68 (√) | GAPGADGPAGAPGTPGPQGIAGQR; -S----------------------(S) |
| 1t23 | GNSGEPGAPGSK | 1t69 (√) | GVVGLPGQR |
| 1t24 | GDTGAK | 1t70 | GER |
| 1t25 (√) | GEPGPTGIQGPPGPAGEEGK; -------V------------(S) | 1t71 | GFPGLPGPSGEPGK |
| 1t26 (√) | R | 1t72 | QGPSGASGER; -----P---- (S) |
| 1t27 | GAR | 1t73 (√) | GPPGPMGPPGLAGPPGESGR |
| 1t28 (√) | GEPGPAGLPGPPGER | 1t74 | EGAPGAEGSPGR |
| 1t29 | GGPGSR | 1t75 | DGSPGAK; --A----(O); --A—-P-(S) |
| 1t30 | GFPGADGVAGPK | 1t76 | GDR |
| 1t31 | GPAGER | 1t77 (√) | GETGPAGPPGAPGAPGAPGPVGPAGK; --S-----------------------(S) |
| 1t32 | GAPGPAGPK; -S-------(S) | 1t78 (√) | SGDR |
| 1t33 | GSPGEAGR | 1t79 (√) | GETGPAGPAGPIGPVGAR; -----------V------(S) |
| 1t34 | PGEAGLPGAK | 1t80 (√) | GPAGPQGPR |
| 1t35 | GLTGSPGSPGPDGK | 1t81 | GDK |
| 1t36 (√) | TGPPGPAGQDGR | 1t82 | GETGEQGDR |
| 1t37 (√) | PGPPGPPGAR | 1t83 | GIK |
| 1t38 (√) | GQAGVMGFPGPK | 1t84 | GHR |
| 1t39 | GAAGEPGK | 1t85 (√) | GFSGLQGPPGPPGSPGEQGPSGASGPAGPR |
| 1t40 | AGER | 1t86 (√) | GPPGSAGSPGK; -------T---(O); -------A---(S) |
| 1t41 | GVPGPPGAVGPAGK | 1t87 (√) | DGLNGLPGPIGPPGPR |
| 1t42 | DGEAGAQGPPGPAGPAGER | 1t88 | GR |
| 1t43 | GEQGPAGSPGFQGLPGPAGPPGEAGK | 1t89 | TGDAGPAGPPGPPGPPGPPGPPSGGYDLSFLPQPPQEK------V------------------F-F----------(S) |
| 1t44 | PGEQGVPGDLGAPGPSGAR | 1t90 | AHDGGR |
| 1t45 | GER | 1t91 | YYR |
| 1t46 | GFPGER | 1t92 | A |
| Peptide Label | Sequence | Peptide Label | Sequence |
|---|---|---|---|
| 2t1 | QFDAK; ---G-(O); -Y-G-(S) | 2t45 (C) (√) | GPPGESGAAGPTGPIGSR; -----------A------(S) |
| 2t2 | G-G-GPGPMGLMGPR; -V-A-----------(S) | 2t46 | GPSGPPGPDGNK |
| 2t3 (√) | GPPGASGAPGPQGFQGPPGEPGEPGQTGPAGAR; -----V-----------A---------------(S) | 2t47 (√) | GEPGVVGAPGTAGPSGPSGLPGER-----L------------------(S) |
| 2t4 | GPPGPPGK | 2t48 | GAAGIPGGK |
| 2t5 | AGEDGHPGK | 2t49 | GEK |
| 2t6 | PGR | 2t50 | GETGLR |
| 2t7 | PGER | 2t51 | GDIGSPGR; --V-----(O); --V-----(S) |
| 2t8 | GVVGPQGAR | 2t52 | DGAR |
| 2t9 | GFPGTPGLPGFK | 2t53 | GAPGAIGAPGPAGANGDR; -----V------------(O; S) |
| 2t10 | GIR | 2t54 | GEAGPAGPAGPAGPR |
| 2t11 | GHNGLDGLK | 2t55 | GSPGER |
| 2t12 | GQPGAPGVK | 2t56 (√) | GEVGPAGPNGFAGPAGAAGQPGAK |
| 2t13 | GEPGAPGENGTPGQTGAR | 2t57 | GER |
| 2t14 | GLPGER | 2t58 | GTK |
| 2t15 | GR | 2t59 | GPK |
| 2t16 | VGAPGPAGAR | 2t60 (√) | GENGPVGPTGPVGAAGPSGPNGPPGPAGSR-----------------A------------(S) |
| 2t17 | GSDGSVGPVGPAGPIGSAGPPGFPGAPGPK; -N----------------------------(S) | 2t61 (√) | GDGGPPGATGFPGAAGR |
| 2t18 (√) | GELGPVGNPGPAGPAGPR | 2t62 | TGPPGPSGISGPPGPPGPAGK; ------A--------------(O); I--------------------(S) |
| 2t19 | GEVGLPGLSGPVGPPGNPGANGLPGAK-------V-------------------(S) | 2t63 | EGLR |
| 2t20 (√) | GAAGLPGVAGAPGLPGPR | 2t64 | GPR |
| 2t21 (√) | GIPGPVGAAGATGAR; -----A---------(S) | 2t65 | GDQGPVGR |
| 2t22 | GLVGEPGPAGSK | 2t66 | SGETGASGPPGFVGEK; T--P--A---------(O); T-----------A---(S) |
| 2t23 | GESGNK | 2t67 (G) (√) | GPSGEPGTAGPPGTPGPQGLLGAPGFLGLPGSR |
| 2t24 | GEPGAVGQPGPPGPSGEEGK; -----A-PQ-----------(S) | 2t68 | GER |
| 2t25 (√) | R | 2t69 (D) (√) | GLPGVAGSVGEPGPLGIAGPPGAR |
| 2t26 (√) | GSTGEIGPAGPPGPPGLR; -PN--V--S----------(S) | 2t70 | GPPGNVGNPGVNGAPGEAGR; ----A---------------(S) |
| 2t27 | GNPGSR | 2t71 | DGNPGNDGPPGR; -----S------(S) |
| 2t28 | GLPGADGR | 2t72 | DGQPGHK; ---A---(S) |
| 2t29 | AGVMGPAGSR; ------P---(S) | 2t73 | GER |
| 2t30 (√) | GATGPAGVR; -P-------(S) | 2t74 | GYPGNAGPVGAAGAPGPQGPVGPVGK; -----------------------T--(O); -----P—A-----------A---A--(S) |
| 2t31 | GPNGDSGR | 2t75 (√) | HGNR; --S-(O) |
| 2t32 | PGEPGLMGPR | 2t76 (√) | GEPGPAGAVGPAGAVGPR; -----V------------(O); -------S----------(S) |
| 2t33 | GFPGSPGNIGPAGK | 2t77 | GPSGPQGIR |
| 2t34 (√) | EGPVGLPGIDGR; ---A--------(O;S) | 2t78 | GDK |
| 2t35 (√) | PGPIGPAGAR | 2t79 | GEPGDK |
| 2t36 (√) | GEPGNIGFPGPK | 2t80 | GPR |
| 2t37 | GPSGDPGK; --T-----(O;S) | 2t81 | GLPGLK |
| 2t38 | AGEK; N---(S) | 2t82 (√) | GHNGLQGLPGLAGHHGDQGAPGAVGPAGPR; ----------------------P-------(S) |
| 2t39 (√) | GHAGLAGAR; -------P-(O) | 2t83 | GPAGPSGPAGK; -----T-----(O) |
| 2t40 | GAPGPDGNNGAQGPPGLQGVQGGK; ----------------P-------(S) | 2t84 | DGR |
| 2t41 (E) (√) | GEQGPAGPPGFQGLPGPAGTAGEAGK; -----------------------V--(S) | 2t85 (A) (√) | IGQPGAVGPAGIR; T------------(O; S) |
| 2t42 (E) (√) | PGER | 2t86 | GSQGSQGPAGPPGPPGPPGPPGPSGGGYEFGFDGDFYR; ----------------------------D---------(O)----------------------------D--YE-----(S) |
| 2t43 (B) (√) | GLPGEFGLPGPAGAR; -------------P-(S) | ||
| 2t44 | GER | 2t87 | A |
| Peptide Label | Bos | Ovis | Sus |
|---|---|---|---|
| 1t18 | 41 (m.c.) | 35 | 47 |
| 1t67 | 45 | 88 | 48 |
| 1t75 | 46 (m.c.) | 55 (m.c.) | 5/14 (m.c.) * |
| 1t86 | 56 | 38 | 62 |
| 2t1 | 43 (m.c.) | 56 (m.c.) | 69 (m.c.) |
| 2t51 | 35 (m.c.) | 25 | 35 |
| 2t62 | 50 | 37 | 56 |
| 2t66 | 81 | 59 | 80 |
| 2t74 | 80 | 48 | 77 |
© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Buckley, M. Species Identification of Bovine, Ovine and Porcine Type 1 Collagen; Comparing Peptide Mass Fingerprinting and LC-Based Proteomics Methods. Int. J. Mol. Sci. 2016, 17, 445. https://doi.org/10.3390/ijms17040445
Buckley M. Species Identification of Bovine, Ovine and Porcine Type 1 Collagen; Comparing Peptide Mass Fingerprinting and LC-Based Proteomics Methods. International Journal of Molecular Sciences. 2016; 17(4):445. https://doi.org/10.3390/ijms17040445
Chicago/Turabian StyleBuckley, Mike. 2016. "Species Identification of Bovine, Ovine and Porcine Type 1 Collagen; Comparing Peptide Mass Fingerprinting and LC-Based Proteomics Methods" International Journal of Molecular Sciences 17, no. 4: 445. https://doi.org/10.3390/ijms17040445
APA StyleBuckley, M. (2016). Species Identification of Bovine, Ovine and Porcine Type 1 Collagen; Comparing Peptide Mass Fingerprinting and LC-Based Proteomics Methods. International Journal of Molecular Sciences, 17(4), 445. https://doi.org/10.3390/ijms17040445