Genetic Architecture of Early Vigor Traits in Wild Soybean




Abstract
:1. Introduction
2. Results
2.1. Correlation in Phenotypic Traits
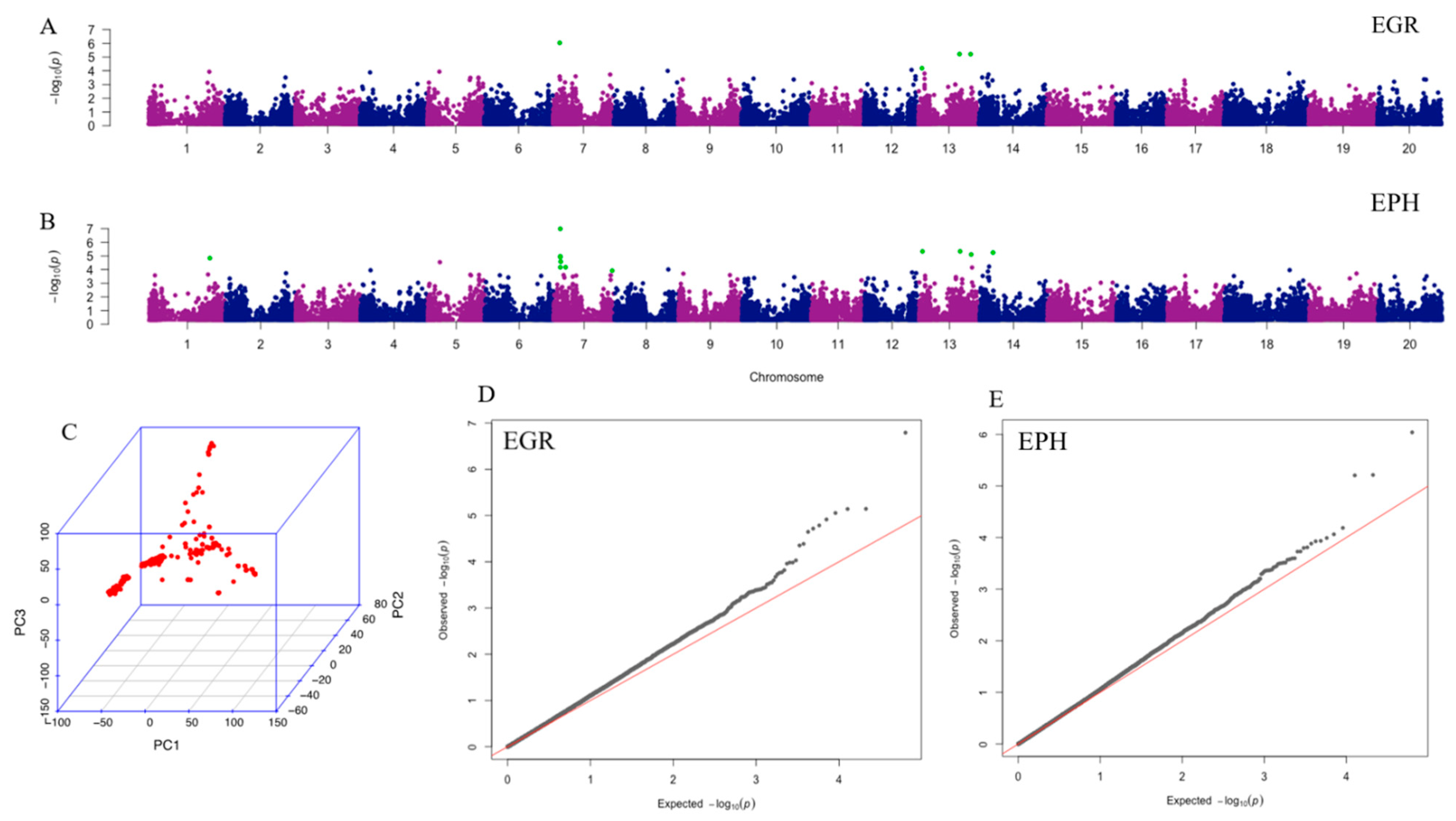
2.2. Genome-Wide Association Analysis
2.3. In-Depth Candidate Loci Investigation
3. Discussion
4. Materials and Methods
4.1. Plant Materials and Phenotyping
4.2. Genotypic Data
4.3. Phenotype Analysis
4.4. Genome-Wide Association Analysis
4.5. Investigation of Candidate Loci
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- OECD/FAO. OECD-FAO Agricultural Outlook 2016–2025; OECD Publishing: Paris, France, 2016. [Google Scholar] [CrossRef]
- Tester, M.; Langridge, P. Breeding technologies to increase crop Production in a changing world. Science 2010, 327, 818–822. [Google Scholar] [CrossRef] [PubMed]
- Kim, M.Y.; Lee, S.; Van, K.; Kim, T.H.; Jeong, S.C.; Choi, I.Y.; Kim, D.S.; Lee, Y.S.; Park, D.; Ma, J.; et al. Whole-genome sequencing and intensive analysis of the undomesticated soybean (Glycine soja Sieb. and Zucc.) genome. Proc. Natl. Acad. Sci. USA 2010, 107, 22032–22037. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.H.; Zhou, G.; Ma, J.; Jiang, W.; Jin, L.G.; Zhang, Z.; Guo, Y.; Zhang, J.; Sui, Y.; Zheng, L.; et al. De novo assembly of soybean wild relatives for pan-genome analysis of diversity and agronomic traits. Nat. Biotechnol. 2014, 32, 1045–1052. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sedivy, E.J.; Wu, F.Q.; Hanzawa, Y. Soybean domestication: The origin, genetic architecture and molecular bases. New Phytol. 2017, 214, 539–553. [Google Scholar] [CrossRef] [Green Version]
- Carter, T.E.; Hymowitz, T.; Nelson, R.L. Biogeography, local adaptation, vavilov, and genetic diversity in soybean. Biol. Resour. Migr. 2004, 47–59. [Google Scholar]
- Li, Y.-H.; Zhao, S.-C.; Ma, J.-X.; Li, D.; Yan, L.; Li, J.; Qi, X.-T.; Guo, X.-S.; Zhang, L.; He, W.-M.; et al. Molecular footprints of domestication and improvement in soybean revealed by whole genome re-sequencing. BMC Genomics. 2013, 14, 579. [Google Scholar] [CrossRef] [Green Version]
- Wen, Z.X.; Boyse, J.F.; Song, Q.J.; Cregan, P.B.; Wang, D.C. Genomic consequences of selection and genome-wide association mapping in soybean. BMC Genomics. 2015, 16. [Google Scholar] [CrossRef] [Green Version]
- Kim, M.Y.; Van, K.; Kang, Y.J.; Kim, K.H.; Lee, S.H. Tracing soybean domestication history: From nucleotide to genome. Breed. Sci. 2012, 61, 445–452. [Google Scholar] [CrossRef] [Green Version]
- Akram, S.; Hussain, B.N.; Al Bari, M.A.; Burritt, D.J.; Hossain, M.A. Genetic Variability and Association Analysis of Soybean (Glycine max (L.) Merrill) for Yield and Yield Attributing Traits. Plant. Gene Trait. 2016, 7. [Google Scholar] [CrossRef]
- Filho, J.M. Seed vigor testing: An overview of the past, present and future perspective. Sci. Agr. 2015, 72, 363–374. [Google Scholar] [CrossRef] [Green Version]
- Isely, D. Vigor tests. In Proceedings of the Association of official Seed Analysts; Society of Commercial Seed Technologists (SCST): Moline, IL, USA; Association of Official Seed Analysts: Ithaca, NY, USA, 1957; pp. 176–182. Available online: https://www.jstor.org/stable/45136792 (accessed on 26 April 2020).
- Borevitz, J.O.; Nordborg, M. The impact of genomics on the study of natural variation in Arabidopsis. Plant. Physiol. 2003, 132, 718–725. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Klein, R.J.; Zeiss, C.; Chew, E.Y.; Tsai, J.-Y.; Sackler, R.S.; Haynes, C.; Henning, A.K.; SanGiovanni, J.P.; Mane, S.M.; Mayne, S.T.; et al. Complement factor H polymorphism in age-related macular degeneration. Science 2005, 308, 385–389. [Google Scholar] [CrossRef] [PubMed]
- Korte, A.; Farlow, A. The advantages and limitations of trait analysis with GWAS: A review. Plant. Methods 2013, 9, 29. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brachi, B.; Morris, G.P.; Borevitz, J.O. Genome-wide association studies in plants: The missing heritability is in the field. Genome Biol. 2011, 12, 232. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.P.; Singh, A.; Mueller, D.S.; Singh, A.K. Genome-wide association and epistasis studies unravel the genetic architecture of sudden death syndrome resistance in soybean. Plant. J. 2015, 84, 1124–1136. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Li, C.; Davis, E.L.; Wang, J.; Griffin, J.D.; Kofsky, J.; Song, B.H. Genome-wide association study of resistance to soybean cyst nematode (Heterodera glycines) HG Type 2.5.7 in wild soybean (Glycine soja). Front. Plant. Sci. 2016, 7, 1214. [Google Scholar] [CrossRef] [Green Version]
- Kim, M.; Diers, B. Fine mapping of the SCN resistance QTL cqSCN-006 and cqSCN-007 from Glycine soja PI 468916. Crop. Sci. 2013, 53, 775–785. [Google Scholar] [CrossRef]
- Anderson, J.E.; Kono, T.J.; Stupar, R.M.; Kantar, M.B.; Morrell, P.L. Environmental association analyses identify candidates for abiotic stress tolerance in Glycine soja, the wild progenitor of cultivated soybeans. G3 (Bethesda) 2016, 6, 835–843. [Google Scholar] [CrossRef] [Green Version]
- Leamy, L.J.; Zhang, H.; Li, C.; Chen, C.Y.; Song, B.H. A genome-wide association study of seed composition traits in wild soybean (Glycine soja). BMC Genomics. 2017, 18, 18. [Google Scholar] [CrossRef] [Green Version]
- Kofsky, J.; Zhang, H.Y.; Song, B.H. The untapped genetic reservoir: The past, current, and future applications of the wild soybean (Glycine soja). Front. Plant. Sci. 2018, 9. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Mittal, N.; Leamy, L.J.; Barazani, O.; Song, B.H. Back into the wild—Apply untapped genetic diversity of wild relatives for crop improvement. Evol. Appl. 2017, 10, 5–24. [Google Scholar] [CrossRef] [PubMed]
- Prince, S.J.; Song, L.; Qiu, D.; Maldonado Dos Santos, J.V.; Chai, C.; Joshi, T.; Patil, G.; Valliyodan, B.; Vuong, T.D.; Murphy, M.; et al. Genetic variants in root architecture-related genes in a Glycine soja accession, a potential resource to improve cultivated soybean. BMC Genomics. 2015, 16, 132. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Asekova, S.; Kulkarni, K.P.; Patil, G.; Kim, M.; Song, J.T.; Nguyen, H.T.; Grover Shannon, J.; Lee, J.-D. Genetic analysis of shoot fresh weight in a cross of wild (G. soja) and cultivated (G. max) soybean. Mol. Breed. 2016, 36, 103. [Google Scholar] [CrossRef]
- Concibido, V.C.; La Vallee, B.; McLaird, P.; Pineda, N.; Meyer, J.; Hummel, L.; Yang, J.; Wu, K.; Delannay, X. Introgression of a quantitative trait locus for yield from Glycine soja into commercial soybean cultivars. Appl. Genet. 2003, 106, 575–582. [Google Scholar] [CrossRef] [PubMed]
- Wee, C.-D.; Hashiguchi, M.; Ishigaki, G.; Muguerza, M.; Oba, C.; Abe, J.; Harada, K.; Akashi, R. Evaluation of seed components of wild soybean (Glycine soja) collected in Japan using near-infrared reflectance spectroscopy. Plant. Genet. Resour. Charact. Util. 2018, 16, 94–102. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, J.; Jiang, W.; Liu, J.; Yang, S.; Gai, J.; Li, Y. Identification and analysis of NaHCO3 stress responsive genes in wild soybean (Glycine soja) roots by RNA-seq. Front. Plant. Sci 2016, 7, 1842. [Google Scholar] [CrossRef] [Green Version]
- Ning, W.; Zhai, H.; Yu, J.; Liang, S.; Yang, X.; Xing, X.; Huo, J.; Pang, T.; Yang, Y.; Bai, X. Overexpression of Glycine soja WRKY20 enhances drought tolerance and improves plant yields under drought stress in transgenic soybean. Mol. Breed. 2017, 37, 19. [Google Scholar] [CrossRef]
- Lee, J.-D.; Shannon, J.G.; Vuong, T.D.; Nguyen, H.T. Inheritance of salt tolerance in wild soybean (Glycine soja Sieb. and Zucc.) accession PI483463. J. Hered. 2009, 100, 798–801. [Google Scholar] [CrossRef]
- Hu, Z.A.; Wang, H.X. Salt tolerance of wild soybean (Glycine soja) in populations evaluated by a new method. Soybean Genet. Newsl. 1997, 24, 79–80. [Google Scholar]
- Yang, D.-S.; Zhang, J.; Li, M.-X.; Shi, L.-X. Metabolomics analysis reveals the salt-tolerant mechanism in Glycine soja. J. Plant. Growth Regul. 2017, 36, 460–471. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, Z.; Wen, Z.; Gu, C.; An, Y.C.; Bales, C.; DiFonzo, C.; Song, Q.; Wang, D. Fine mapping of the soybean aphid-resistance genes Rag6 and Rag3c from Glycine soja 85-32. Appl. Genet. 2017, 130, 2601–2615. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Zhang, Z.; Bales, C.; Gu, C.; DiFonzo, C.; Li, M.; Song, Q.; Cregan, P.; Yang, Z.; Wang, D. Mapping novel aphid resistance QTL from wild soybean, Glycine soja 85-32. Appl. Genet. 2017, 130, 1941–1952. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.Y.; Song, B.H. RNA-seq data comparisons of wild soybean genotypes in response to soybean cyst nematode (Heterodera glycines). Genom Data 2017, 14, 36–39. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Kjemtrup-Lovelace, S.; Li, C.; Luo, Y.; Chen, L.P.; Song, B.H. Comparative RNA-seq analysis uncovers a complex regulatory network for soybean cyst nematode resistance in wild soybean (Glycine soja). Sci. Rep. 2017, 7, 9699. [Google Scholar] [CrossRef] [Green Version]
- Yuan, C.; Zhang, L.; Zhao, H.; Wang, Y.; Liu, X.; Dong, Y.; Hartman, G.L. RNA-seq analysis for soybean cyst nematode resistance of Glycine soja (wild soybean). Oil Crop. Sci. 2019, 4, 33–46. [Google Scholar]
- Yu, N.; Diers, B.W. Fine mapping of the SCN resistance QTL cqSCN-006 and cqSCN-007 from Glycine soja PI 468916. Euphytica 2017, 213, 54. [Google Scholar] [CrossRef]
- Winter, S.M.J.; Shelp, B.J.; Anderson, T.R.; Welacky, T.W.; Rajcan, I. QTL associated with horizontal resistance to soybean cyst nematode in Glycine soja PI464925B. Theor. Appl. Genet. 2007, 114, 461–472. [Google Scholar] [CrossRef]
- Wang, D.; Diers, B.W.; Arelli, P.R.; Shoemaker, R.C. Loci underlying resistance to Race 3 of soybean cyst nematode in Glycine soja plant introduction 468916. Theor. Appl. Genet. 2001, 103, 561–566. [Google Scholar] [CrossRef]
- Kabelka, E.A.; Carlson, S.R.; Diers, B.W. Localization of two loci that confer resistance to soybean cyst nematode from Glycine soja PI 468916. Crop. Sci. 2005, 45, 2473–2481. [Google Scholar] [CrossRef]
- Hesler, L.S. Resistance to soybean aphid among wild soybean lines under controlled conditions. Crop. Prot. 2013, 53, 139–146. [Google Scholar] [CrossRef]
- Wang, D.; Graef, G.; Procopiuk, A.; Diers, B. Identification of putative QTL that underlie yield in interspecific soybean backcross populations. Theor. Appl. Genet. 2004, 108, 458–467. [Google Scholar] [CrossRef] [PubMed]
- Sun, D.; Li, W.; Zhang, Z.; Chen, Q.; Ning, H.; Qiu, L.; Sun, G. Quantitative trait loci analysis for the developmental behavior of soybean (Glycine max L. Merr.). Theor. Appl. Genet. 2006, 112, 665–673. [Google Scholar] [CrossRef] [PubMed]
- Mansur, L.; Orf, J.; Chase, K.; Jarvik, T.; Cregan, P.; Lark, K. Genetic mapping of agronomic trait using recombinant inbred lines of soybean. Crop. Sci. 1996, 36, 1327–1336. [Google Scholar] [CrossRef]
- Guzman, P.; Diers, B.W.; Neece, D.; St Martin, S.; LeRoy, A.; Grau, C.; Hughes, T.; Nelson, R.L. QTL associated with yield in three backcross-derived populations of soybean. Crop. Sci. 2007, 47, 111–122. [Google Scholar] [CrossRef]
- Grant, D.; Nelson, R.T.; Cannon, S.B.; Shoemaker, R.C. SoyBase, the USDA-ARS soybean genetics and genomics database. Nucleic Acids Res. 2009, 38, D843–D846. [Google Scholar] [CrossRef]
- Griesen, D.; Su, D.; Bérczi, A.; Asard, H. Localization of an ascorbate-reducible cytochrome b561 in the plant tonoplast. Plant. Physiol. 2004, 134, 726–734. [Google Scholar] [CrossRef] [Green Version]
- Qi, X.; Li, M.W.; Xie, M.; Liu, X.; Ni, M.; Shao, G.; Song, C.; Kay-Yuen Yim, A.; Tao, Y.; Wong, F.L.; et al. Identification of a novel salt tolerance gene in wild soybean by whole-genome sequencing. Nat. Commun 2014, 5, 4340. [Google Scholar] [CrossRef] [Green Version]
- Verelst, W.; Asard, H. Analysis of an Arabidopsis thaliana protein family, structurally related to cytochromes b561 and potentially involved in catecholamine biochemistry in plants. J. Plant Physiol. 2004, 161, 175–181. [Google Scholar] [CrossRef]
- Weng, J.; Xie, C.; Hao, Z.; Wang, J.; Liu, C.; Li, M.; Zhang, D.; Bai, L.; Zhang, S.; Li, X. Genome-wide association study identifies candidate genes that affect plant height in Chinese elite maize (Zea mays L.) inbred lines. PLoS ONE 2011, 6, e29229. [Google Scholar] [CrossRef] [Green Version]
- Lin, Z.; Ho, C.-W.; Grierson, D. AtTRP1 encodes a novel TPR protein that interacts with the ethylene receptor ERS1 and modulates development in Arabidopsis. J. Exp. Bot. 2009, 60, 3697–3714. [Google Scholar] [CrossRef] [Green Version]
- Schapire, A.L.; Valpuesta, V.; Botella, M.A. TPR proteins in plant hormone signaling. Plant. Signal. Behav. 2006, 1, 229–230. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Greenboim-Wainberg, Y.; Maymon, I.; Borochov, R.; Alvarez, J.; Olszewski, N.; Ori, N.; Eshed, Y.; Weiss, D. Cross talk between gibberellin and cytokinin: The Arabidopsis GA response inhibitor SPINDLY plays a positive role in cytokinin signaling. Plant. Cell 2005, 17, 92–102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Larkin, R.M.; Stefano, G.; Ruckle, M.E.; Stavoe, A.K.; Sinkler, C.A.; Brandizzi, F.; Malmstrom, C.M.; Osteryoung, K.W. REDUCED CHLOROPLAST COVERAGE genes from Arabidopsis thaliana help to establish the size of the chloroplast compartment. Proc. Natl. Acad. Sci. USA 2016, 113, E1116–E1125. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Song, Q.; Hyten, D.L.; Jia, G.; Quigley, C.V.; Fickus, E.W.; Nelson, R.L.; Cregan, P.B. Development and evaluation of SoySNP50K, a high-density genotyping array for soybean. PLoS ONE 2013, 8, e54985. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Song, Q.; Cregan, P.B.; Nelson, R.L.; Wang, X.; Wu, J.; Jiang, G.-L. Genome-wide association study for flowering time, maturity dates and plant height in early maturing soybean (Glycine max) germplasm. BMC Genomics. 2015, 16, 217. [Google Scholar] [CrossRef] [Green Version]
- Browning, B.L.; Browning, S.R. A unified approach to genotype imputation and haplotype-phase inference for large data sets of trios and unrelated individuals. Am. J. Hum. Genet. 2009, 84, 210–223. [Google Scholar] [CrossRef] [Green Version]
- Browning, B.L.; Browning, S.R. Efficient multilocus association testing for whole genome association studies using localized haplotype clustering. Genet. Epidemiol. Off. Publ. Int. Genet. Epidemiol. Soc. 2007, 31, 365–375. [Google Scholar] [CrossRef]
- Goh, L.; Yap, V.B. Effects of normalization on quantitative traits in association test. BMC Bioinform. 2009, 10, 415. [Google Scholar] [CrossRef] [Green Version]
- Endelman, J.B.; Jannink, J.L. Shrinkage estimation of the realized relationship matrix. G3 (Bethesda) 2012, 2, 1405–1413. [Google Scholar] [CrossRef]
- Lipka, A.E.; Tian, F.; Wang, Q.; Peiffer, J.; Li, M.; Bradbury, P.J.; Gore, M.A.; Buckler, E.S.; Zhang, Z. GAPIT: Genome association and prediction integrated tool. Bioinformatics 2012, 28, 2397–2399. [Google Scholar] [CrossRef] [Green Version]
- Bradbury, P.J.; Zhang, Z.; Kroon, D.E.; Casstevens, T.M.; Ramdoss, Y.; Buckler, E.S. TASSEL: Software for association mapping of complex traits in diverse samples. Bioinformatics 2007, 23, 2633–2635. [Google Scholar] [CrossRef] [PubMed]
- Leamy, L.J.; Pomp, D.; Eisen, E.; Cheverud, J.M. Pleiotropy of quantitative trait loci for organ weights and limb bone lengths in mice. Physiol. Genom. 2002, 10, 21–29. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Johnson, R.C.; Nelson, G.W.; Troyer, J.L.; Lautenberger, J.A.; Kessing, B.D.; Winkler, C.A.; O’Brien, S.J. Accounting for multiple comparisons in a genome-wide association study (GWAS). BMC Genomics. 2010, 11, 724. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Benjamini, Y.; Hochberg, Y. Controlling the false discovery rate—A practical and powerful approach to multiple testing. J. R. Stat. Soc. Ser. B 1995, 57, 289–300. [Google Scholar] [CrossRef]
- Goodstein, D.M.; Shu, S.; Howson, R.; Neupane, R.; Hayes, R.D.; Fazo, J.; Mitros, T.; Dirks, W.; Hellsten, U.; Putnam, N. Phytozome: A comparative platform for green plant genomics. Nucleic Acids Res. 2011, 40, D1178–D1186. [Google Scholar] [CrossRef]
- Berardini, T.Z.; Reiser, L.; Li, D.; Mezheritsky, Y.; Muller, R.; Strait, E.; Huala, E. The Arabidopsis information resource: Making and mining the “gold standard” annotated reference plant genome. Genesis 2015, 53, 474–485. [Google Scholar] [CrossRef] [Green Version]
- Conesa, A.; Götz, S.; García-Gómez, J.M.; Terol, J.; Talón, M.; Robles, M. Blast2GO: A universal tool for annotation, visualization and analysis in functional genomics research. Bioinformatics 2005, 21, 3674–3676. [Google Scholar] [CrossRef] [Green Version]
- Shin, J.-H.; Blay, S.; McNeney, B.; Graham, J. LDheatmap: An R function for graphical display of pairwise linkage disequilibria between single nucleotide polymorphisms. J. Stat. Softw. 2006, 16, 1–10. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Trait | Phenotypic Variation | Positive Significant Correlation between Traits | ||||
|---|---|---|---|---|---|---|
| Mean | StDev | CV | EPH | Node Count | Inter-Node Length | |
| EGR | 16.02 | 8.34 | 52.05 | 0.9861 | 0.7023 | 0.8674 |
| EPH | 244.68 | 127.2 | 51.99 | - | 0.6911 | 0.8838 |
| Node Count | 4.34 | 0.93 | 21.33 | - | - | 0.3449 |
| Inter-node Length | 54.55 | 24.97 | 45.76 | - | - | - |
| SNP | Chr | Position | r2 | Location | Associated Gene | Associated QTL | p-value | q-value | CB | GB | GFDR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EGR | ss715598271 | 7 | 4924020 | 0.1085 | Intron | Glyma.07G055900.1 | Plant Height 19-5 [43] | 9.14E-07 | 0.001431 | * | * | * |
| ss715614175 | 13 | 19487316 | 0.071 | Intergenic | - | Plant Height 26-11 [44] | 6.50E-05 | 0.042055 | - | - | - | |
| ss715615103 | 13 | 31173270 | 0.0911 | Intergenic | - | 6.12E-06 | 0.006046 | * | - | - | ||
| ss715616082 | 13 | 39280839 | 0.0944 | 5UTR | Glyma.13G292800.1 | 6.23E-06 | 0.006046 | * | - | - | ||
| EPH | ss715579500 | 1 | 45269059 | 0.0792 | Intergenic | - | 2.26E-05 | 0.028024 | * | - | - | |
| ss715598269 | 7 | 4915929 | 0.0682 | Intron | Glyma.07G055800.1 | Plant Height 19-5 [43] | 1.04E-04 | 0.027144 | - | - | - | |
| ss715598270 | 7 | 4918294 | 0.0834 | 3UTR | Glyma.07G055800.1 | Plant Height 19-5 [43] | 1.64E-05 | 0.010022 | * | - | - | |
| ss715598271 | 7 | 4924020 | 0.1242 | Intron | Glyma.07G055900.1 | Plant Height 19-5 [43] | 1.62E-07 | 0.000254 | * | * | * | |
| ss715598272 | 7 | 4928272 | 0.0817 | Intron | Glyma.07G055900.1 | Plant Height 19-5 [43] | 1.92E-05 | 0.010022 | * | - | - | |
| ss715598304 | 7 | 5214440 | 0.0816 | Intergenic | - | Plant Height 19-5 [43] Plant Height 3-3 [45] Plant Height 25-6 [46] | 4.11E-05 | 0.016091 | - | - | - | |
| ss715598895 | 7 | 8788505 | 0.0668 | Intron | Glyma.07G094100.1 | 1.04E-04 | 0.027144 | - | - | - | ||
| ss715598145 | 7 | 42926704 | 0.0628 | CDS | Glyma.07G251700.1 | 1.86E-04 | 0.041611 | - | - | - | ||
| ss715614175 | 13 | 19487316 | 0.09 | Intergenic | - | Plant Height 26-11 [44] | 7.24E-06 | 0.007026 | * | - | - | |
| ss715615103 | 13 | 31173270 | 0.0893 | Intergenic | - | 7.18E-06 | 0.007026 | * | - | - | ||
| ss715616082 | 13 | 39280839 | 0.0874 | 5UTR | Glyma.13G292800.1 | 1.22E-05 | 0.007893 | * | - | - | ||
| ss715620138 | 14 | 9595999 | 0.0873 | Intergenic | - | 8.84E-06 | 0.013826 | * | - | - | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kofsky, J.; Zhang, H.; Song, B.-H. Genetic Architecture of Early Vigor Traits in Wild Soybean. Int. J. Mol. Sci. 2020, 21, 3105. https://doi.org/10.3390/ijms21093105
Kofsky J, Zhang H, Song B-H. Genetic Architecture of Early Vigor Traits in Wild Soybean. International Journal of Molecular Sciences. 2020; 21(9):3105. https://doi.org/10.3390/ijms21093105
Chicago/Turabian StyleKofsky, Janice, Hengyou Zhang, and Bao-Hua Song. 2020. "Genetic Architecture of Early Vigor Traits in Wild Soybean" International Journal of Molecular Sciences 21, no. 9: 3105. https://doi.org/10.3390/ijms21093105
APA StyleKofsky, J., Zhang, H., & Song, B. -H. (2020). Genetic Architecture of Early Vigor Traits in Wild Soybean. International Journal of Molecular Sciences, 21(9), 3105. https://doi.org/10.3390/ijms21093105