1. Introduction
Diversity is a founding, but at the same time, complex concept in ecology. More than species diversity in the community, understood as a group of interdependent organisms of different species growing or living together in a specified habitat, diversity can be related to genetic diversity within populations or diversity of functional traits. However, for most ecologists, diversity has to do with the number and abundance of species in the community, and a lot of attempts have been made to express this concept numerically. Because of this, a high number of diversity indices have been proposed showing different aspects of the community structure, taking into account factors ranging from the number of species and the relative abundance or biomass of these species, to the taxonomic or functional relationships between them [
1]. Although it is generally agreed that diversity is a multidimensional concept and that the use of diversity indices depends on what effect on diversity you want to detect, there is no consensus about the indices that should be used in each case. However, traditional or classical diversity indices such as Species Richness (
S), Shannon (
H′) or Pielou’s evenness (
J′), are usually chosen to describe biological communities because, at least, they are easy to calculate and allow comparisons with previous works. Although in recent years, a new family of diversity indices, known as Hill numbers, have been preferred because they have shown more desired properties than the raw form [
2,
3]; for example, they obey an intuitive replication principle or doubling property and they are all expressed in units of effective numbers of species [
4].
Taking into account changes of diversity along transects or across environmental gradients, the concept of beta diversity emerges. Although there is some controversy [
5,
6], it is generally agreed that beta diversity measures the species that change between samples or sites composing a community, mainly due to species replacement or species loss [
7]. The concept of beta diversity was originally proposed by Whittaker [
8,
9], and their measures were summarized by Chao and Chiu [
10] in two major approaches: (i) the diversity decomposition approach that consists of decomposing the total diversity (gamma) into its within-community component (alpha) and between-community component (beta), which can be applied to species richness as well as to other diversity indices involving abundances in their calculations; and (ii) the variance framework approach that includes various factors from clustering or ordination analysis to dissimilarity measures between pairs of sites (e.g., [
5,
11,
12]) to compute beta diversity. Moreover, dissimilarity indices allow the distinction of species loss (or nestedness) and species replacement (or turnover) components of beta diversity and can be extended to multiple-site measures [
7].
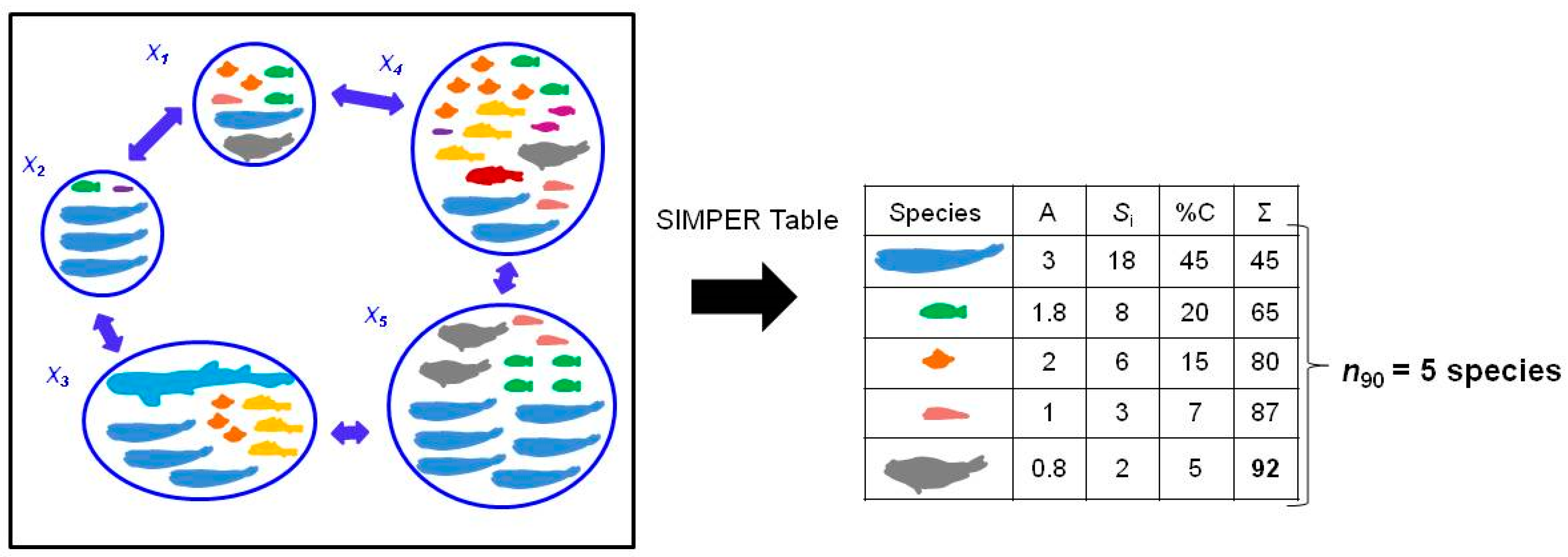
N90 is a diversity index developed by Farriols et al. [
13], based on the results of the Similarity Percentage (SIMPER) analysis [
14]. This analysis takes into account the similarity in species composition between pairs of samples of a group to calculate the average similarity within the group (or within-group similarity). The
N90 index represents the number of species contributing up to the 90% of within-group similarity in a group of samples, based on the calculation of the contribution of each species. Like SIMPER analysis
N90 uses the Bray–Curtis similarity index as proposed by Clarke [
14]. Following the variance framework, within-group similarity could be interpreted as an inverse measure of beta diversity. The hypothesis behind the
N90 index is that impacted communities may see both the frequency of occurrence and the evenness of the distribution of species abundances reduced among samples. This leads to a decrease in
N90 due to the retreat of species populations to the localities presenting the most favorable ecological conditions.
The aim of this work is to explore the properties of N90 compared to other diversity indices involving number of species and abundance in their calculation. To do so we compared N90 to classical diversity indices and their alpha, gamma and beta versions. Following the variance framework approach, we have also compared N90 to beta diversity measures accounting for nestedness and turnover and to within-group similarity from SIMPER analysis. We have used a non-real data set with several groups of samples showing different values of abundance distributions and number of species between samples to compare the values of all indices with N90. We have also used two real data sets of demersal fish communities along large and short depth gradients with higher influence of turnover and nestedness, respectively, to correlate the same indices with N90.
4. Discussion
We have presented the
N90 diversity index, which is based on the results of the SIMPER analysis and represents the number of species contributing up to ninety percent of within-group similarity in a group of samples. The hypothesis behind the index is that impacted communities may see both the frequency of occurrence and the evenness of the distribution of species abundances reduced among samples. This leads to a decrease in
N90 due to the retreat of species populations to the localities presenting the most favorable ecological conditions. The
N90 diversity index has the following advantages when compared to other diversity indices: (i) easy interpretation—units are number of species as in species richness (
S), but, at the same time, the high dependence on sample size of
S [
23,
24,
25] is less important in
N90, as rare species are not usually among the main contributors to within-group similarity; (ii) more sensitivity to anthropogenic impacts and environmental variability and their synergistic effects [
13]; (iii) it assesses diversity for the whole set of samples in the group (usually representing a community or ecosystem) instead of operating at sample level and averaging values afterwards, or alternatively, pooling data from different samples (e.g., an
S value taking into account all species appearing in all samples); and (iv) species identity is preserved because the
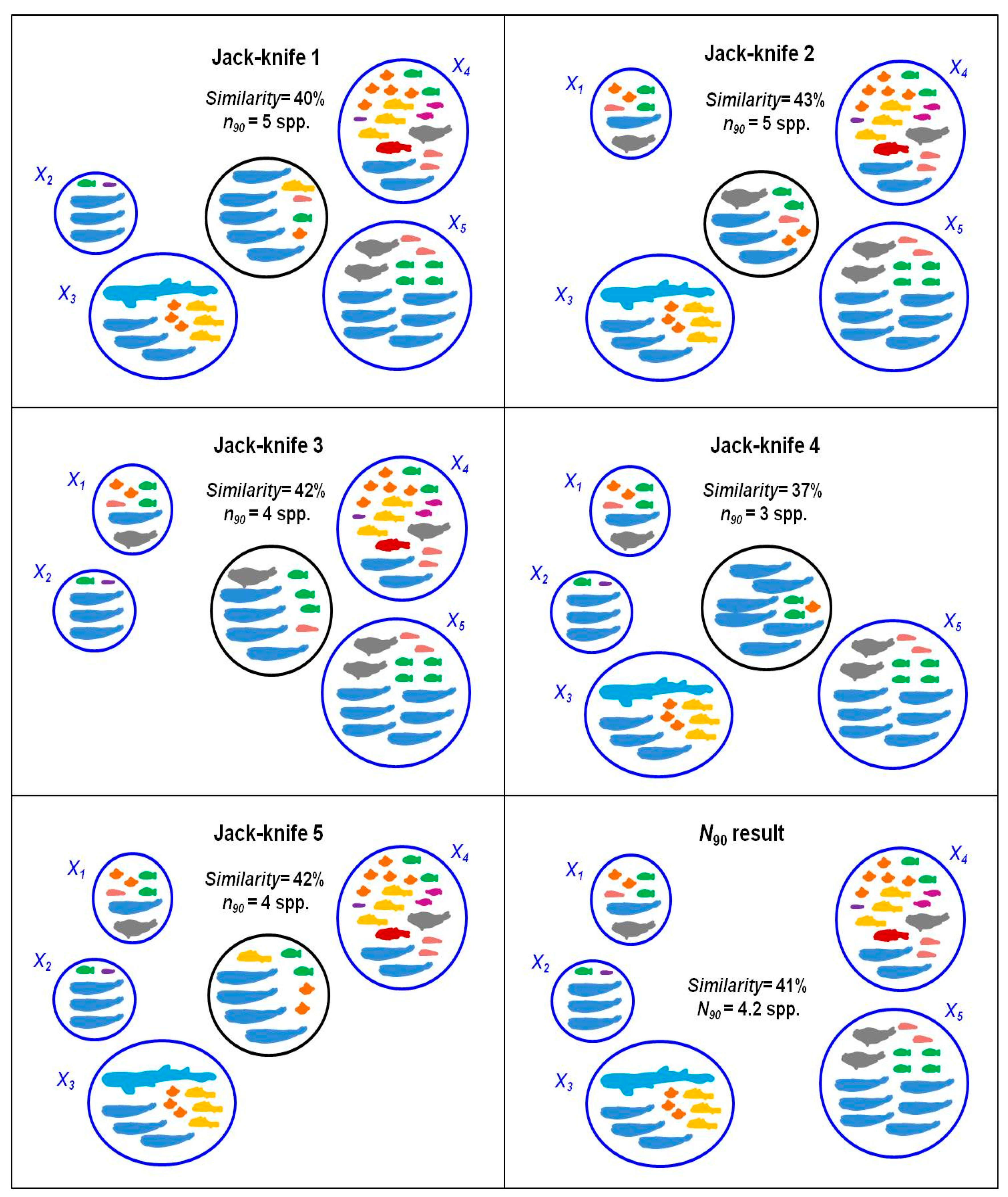
N90 index is accompanied by a SIMPER table showing within-group species contribution to the 90% similarity. Finally, thanks to the re-sampling routine implemented in the calculation of
N90, the index has a dispersion value associated that allows the comparison of values between areas or different periods.
The application of the
N90 index to a non-real data set has enabled us to see the variation of the index to controlled changes in abundance distribution and number of species between samples in several groups and compare it to a battery of values of other indices. As expected, when abundances of all species are equal, a higher value of
N90 is reached when these abundances are equally distributed among samples. And like all the other indices,
N90 do not change when the abundance of all species in all samples changes equally. The main cause of decreases in
N90 under these limited conditions is the disappearance of species in the group (decreases in gamma
S). In that sense, the null contribution of absent species to Bray–Curtis similarity, and therefore to
N90, is another advantage of the index, to avoid the consideration of those communities that do not share any species as being similar [
15].
N90 is also sensitive to abundance evenness at the gamma level, reflected in decreases in the index in groups with identical samples (i.e., maximum similarity) but lower gamma
H′,
H1 and
J’. The detection of changes in abundance distribution of species between samples is important in the detection of diversity loss due to the fishing-induced retreatment of species populations to localities presenting the most favourable ecological conditions. For that reason, it is important that
N90 is based on a measure of similarity between samples influenced by the evenness of abundance at the gamma level, like Bray–Curtis. Besides, the use of absolute abundance in the calculation of
N90 is preferred to allow the index to capture these changes in abundance distributions. Although these calculations based on non-real data give an idea about the behavior of
N90 under repeatable and controlled conditions, its application to a real data set allows the analysis of data under natural conditions, with more variations in values of abundance distributions among samples. Changes in
N90 due to nestedness and turnover of species between samples are discussed below.
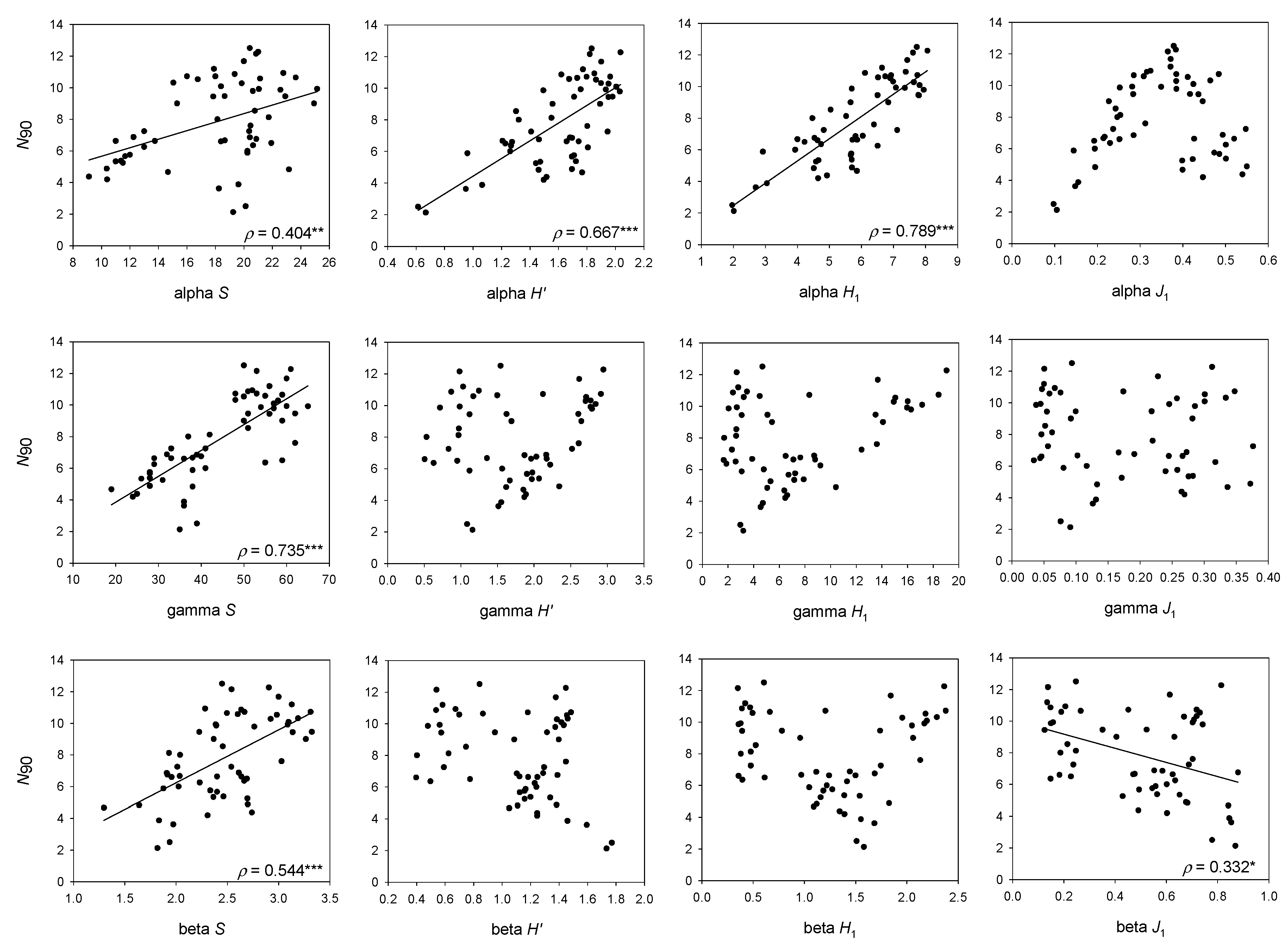
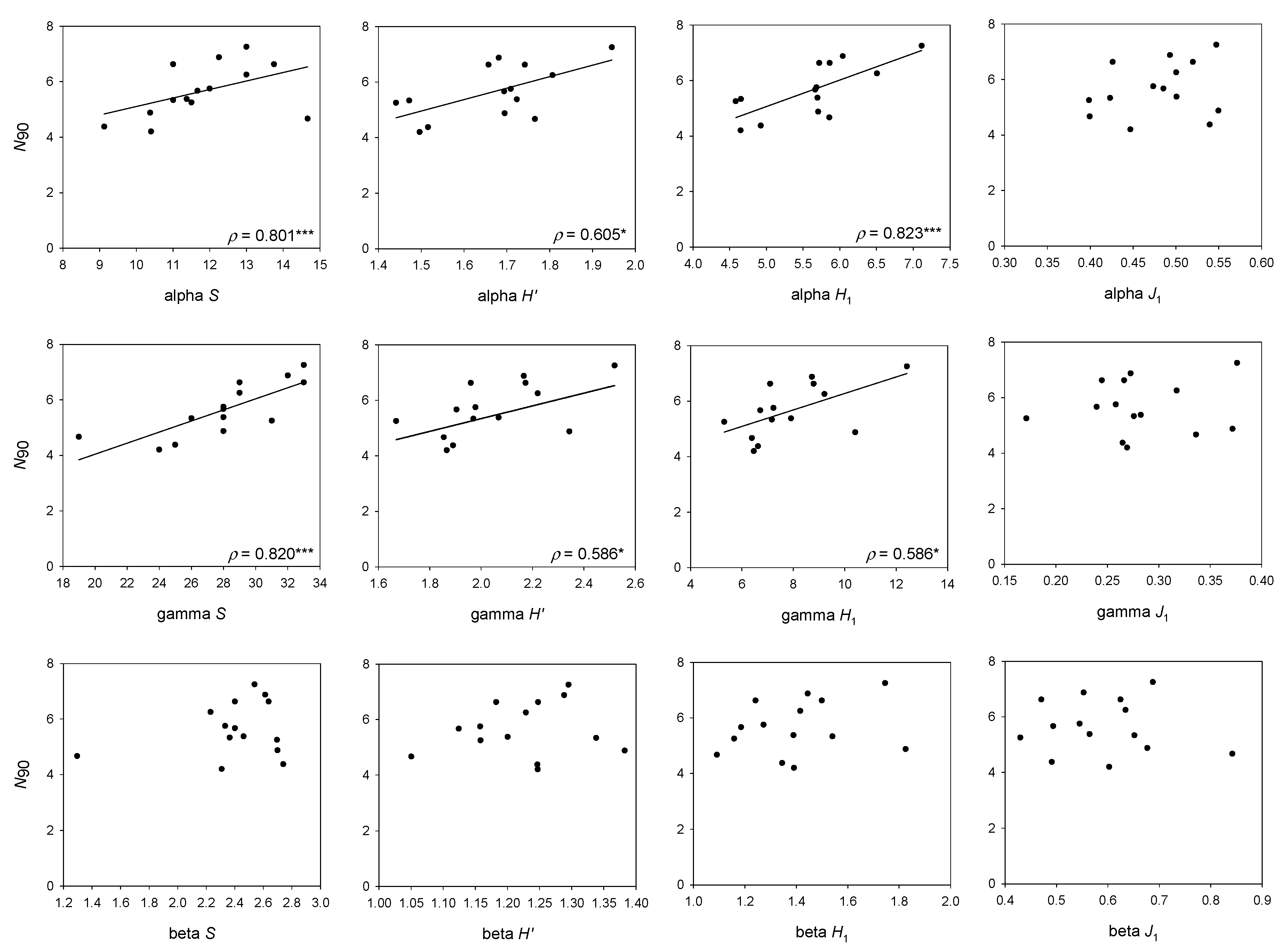
For the whole bathymetric range considered, the higher correlation of N90 with the effective form of alpha H′ shows that values of N90, whose calculation is based on the comparison of the abundances of each pair of samples composing the group or community, are more similar to a mean value of H1 in the samples of the group or the community (alpha H1) than H1 calculated for the whole community (gamma H1). This means that frequent species in the group or community contribute more to N90 than abundant species (i.e., with absolute abundant values) in the whole community. This is endorsed by the high correlation of N90 and total number of species in the whole group of samples or community (gamma S). The difference between alpha, beta and gamma S is that alpha S takes the mean number of species in the community, beta S the replacement of species between samples of the community and gamma S is the total number of species in the community. Thus, the high correlation of N90 with gamma S has an easy explanation, because the species identity is not lost and the total number of species in the community is taken into account during the calculation of N90. However, N90 is not equal to gamma S, because it only takes into account the species that contribute to 90% similarity in the group of samples—or in other words, the species that are more representative in terms of frequency of appearance and abundance from the group of samples in the community.
Having N90 at halfway between alpha H1 and gamma S (mean N90 was 7.8, mean gamma S was 44.3 and mean alpha H1 was 5.8, for the whole set of samples) may favor the detection of the reduction in total (gamma) S through reductions in the frequency of occurrence, and on mean (alpha) H1 through reductions in the evenness of the distribution of species abundances among samples in impacted communities. Altogether, this would allow the detection of the diversity loss due to fishing.
The positive correlation of N90 with beta S denotes that beta S would increase due to an increase in the total number of species (gamma S), not compensated for by an increase in mean S (alpha S). However, at least some of the species increasing gamma S, although not frequent enough to change the mean S, would be evenly distributed enough to contribute to the value of the N90, allowing this index to account for some portion of the beta diversity.
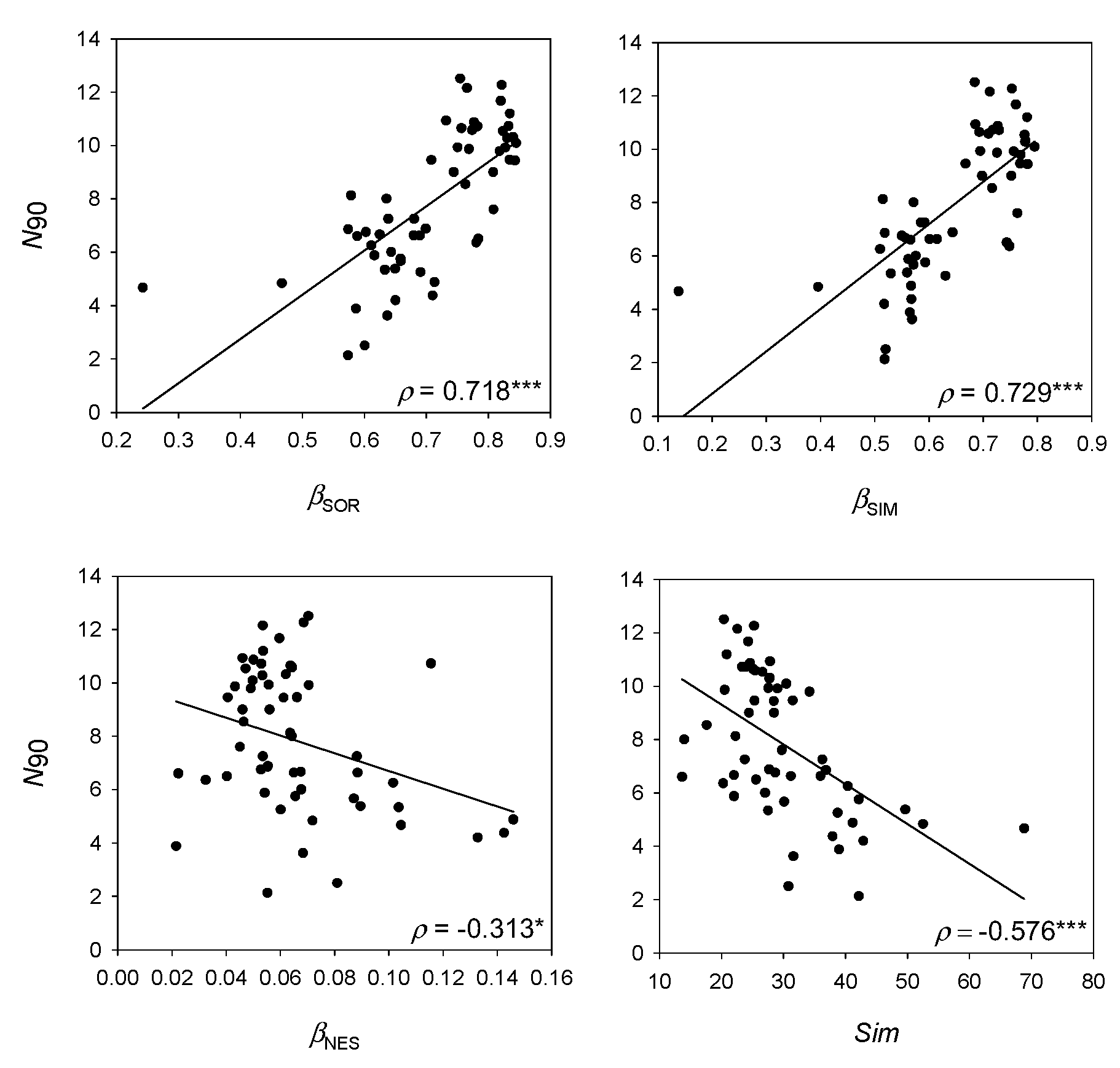
N90 showed higher correlation with the turnover component of beta diversity than with nestedness, meaning that species replacement between samples has a higher weight in the calculation of the index than species loss. Previous works aimed to detect changes in diversity due to fishing impacts have shown that
N90 is influenced by both turnover and nestedness. On one hand, species loss was the main cause of decreases in
N90 in trawled demersal fish communities [
13,
26,
27]. On the other, changes in diversity of epibenthic communities due to trawling were detected through the replacement of some vulnerable species by others more adapted to fishing, hence not involving a decrease in
N90 values between impacted and non-impacted areas [
28]; in that sense, we could expect that nestedness would be more important component of
N90 than turnover. However, considering the data analyzed includes a large bathymetric range (50–800 m depth), turnover seems more plausible than species loss because the main factor structuring the community in the study area, as in the rest of the Mediterranean (e.g., [
27]), is depth and not fishing impact. In any case, and because both processes can influence the results of
N90, it is important to emphasize that the identity of the species is not lost during its calculation and the associated SIMPER table with the species contribution to similarity permits the knowledge of which species contribute to
N90 and if changes in
N90 are due to loss or replacement of species in the community.
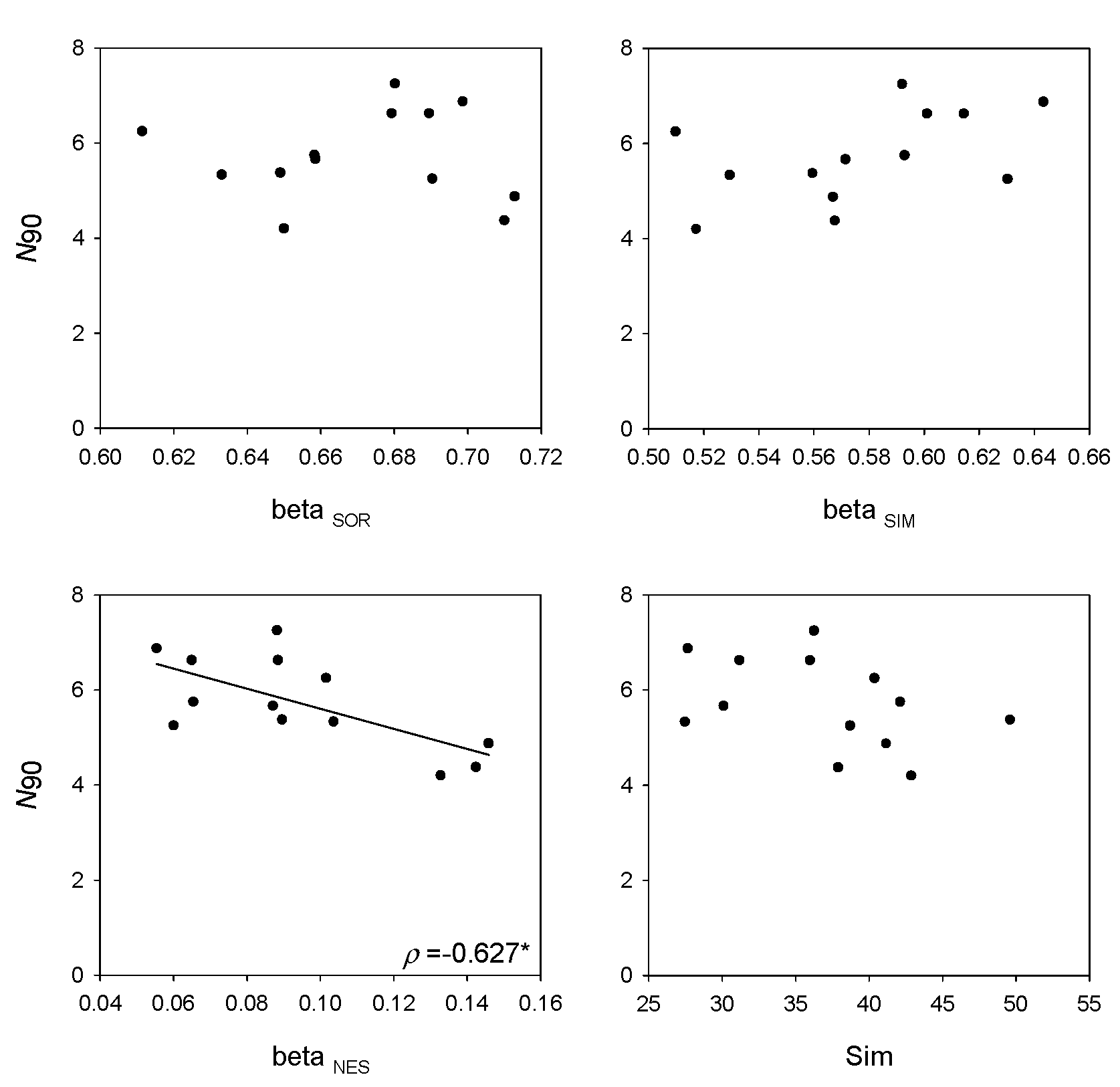
Within-group similarity can be seen as an inverse measure of beta diversity and is based on the Bray–Curtis similarity index, which includes abundance of species in the calculation. On the contrary, measures of turnover and nestedness are calculated from presence–absence data [
7]. The lower correlation of
N90 and within-group similarity compared to measures of nestedness and turnover reinforces the idea conceived from this work that the frequency of appearances of species has more weight in the calculation of
N90 than the distribution of abundances between samples. However, the high correlation of
N90 with beta diversity measures and the fact that it is an indexed measure whose calculation relies on a similarity index, lead to it being included in the group of beta diversity indices.
The application of the analysis to middle slope stratum deepens in the results obtained for the whole depth range. In this stratum the correlation of
N90 with alpha and gamma
S increases. Additionally,
N90 shows a higher correlation with nestedness than with turnover components of beta diversity. The difference between the whole depth range analysis and middle slope is that in the last case, the same community is considered in different years, whereas several demersal fish communities are considered when we analyze the larger depth gradient (e.g., [
26,
27]). Altogether, this indicates that
N90 reflects an increase in gamma
S due to the replacement of species between different communities when the whole depth range is considered, reflected by an increase of
N90. While in a particular stratum, i.e., within the same bathymetric assemblage where species turnover or replacement is lower between samples, species loss and differences in number of species are the main causes of change. However, and contrary to communities mainly influenced by turnover, the fact that nestedness can impact gamma
H1, which in turn impacts
N90, must also be considered. In any case,
N90 provides different information depending on whether we analyze heterogeneous or homogenous communities, with communities in which more species show a more even spread of their abundance showing higher values of
N90 at any gradient of change.
Again, the associated SIMPER results will allow us to elucidate the relative importance of nestedness and turnover components of beta diversity on
N90, and hence, identify the effects of impacts on marine communities. This has been proved in previous works where SIMPER tables allowed the identification of species that disappeared from the community due to their vulnerability to fishing activities, like elasmobranchs, or to their state of exploitation, like some by-catch species of bottom trawl fishery in the Balearic Islands in areas subjected to a high level of bottom trawling [
13]. It also allowed the identification of species replaced by smaller ones in a trawled area [
28]. As such, the study of the ecology of species that contribute to
N90 through the SIMPER table is relevant to determine if fishing has caused a change in diversity due to the loss of vulnerable species or replacement by those more adapted to fishing impacts. However, this advantage is also useful for general ecological studies, in order to detect which kind of species are structuring the community.
Up to now, the
N90 index has contributed to the comparison and explanation of specific data pools of exploited marine ecosystems and their living resources; it has been applied in the Mediterranean to assess the impact of fishing exploitation on the diversity of demersal fish and epi-benthic communities, both at narrow and broad bathymetric and geographical scales and considering both continuous and stratified approaches regarding levels of fishing effort [
13,
26,
27,
28]. In all cases,
N90 displayed a better response to fishing pressure compared to other diversity indices covering a wide variety of aspects like the number of species and their relative abundance, as well as their taxonomic and functional position [
23,
29,
30,
31,
32,
33]
Table 3, showing lower values in impacted communities.
N90 has also been applied to assess spatio-temporal variations of diversity in fishing waste from north-western Mediterranean bottom trawl fishery [
34]. In that case, similar results were obtained for species richness, but
N90 gave information not only about the number of species but also on the species composition of the waste.
Indicators, defined as variables, pointers or indices of a phenomenon, are needed to support the implementation of the Ecosystem Approach to Fisheries, as they can provide information on the state of the ecosystems by tracking those components and attributes that may be adversely impacted by fishing, like diversity [
35]. For the above-mentioned reasons, the
N90 index can be a useful indicator for this. In addition,
N90 also detects fishing impacts by fluctuating in response to environmental variation [
11], making this index sensitive to the synergies between climate and fishing impacts at the community level. The sensitivity of
N90 to reductions in the frequency of occurrence and the evenness of the distribution of species abundances among samples in impacted communities, together with the identification of both effects of fishing impacts, species replacement and species loss [
13,
26,
28], make the
N90 diversity index an alternative to ‘traditional’ diversity indices when trying to monitor fishing impacts within the current context of global change. Additionally, the comparison of
N90 with a battery of indices to explore its properties performed here will make it more useful to those who decide to use it.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





