1. Introduction
Deformation measurement during laboratory testing on construction materials aims at determining the intrinsic characteristics of the considered object. The examination of the deformation and the knowledge of the applied load (e.g., a mechanical or thermal load) allows the analysis of the mathematical model that describes the behaviour of a construction element.
Several instruments can be used to measure object deformations during loading tests. However, the most widely adopted tools are
linear-variable-differential-transformers (LVDTs) and
strain gauges [
1], which provide the magnitude of the displacement with the investigation of the changes of electrical resistance due to a load. These tools are considered proven techniques, with an accuracy of ±1 μm or even less, and they give real-time data. On the other hand, they only provide 1D measurements limited to the area in which the sensor is fixed. In addition, a connection with a control unit is necessary and after destructive tests these kinds of sensors can be damaged. Thus, LVDTs or strain gauges are not a convenient choice in the case of extensive analysis on the whole body, in which a great number of 3D points with a good spatial distribution must be measured.
Image-based methods can analyse the whole deformation field of a body by tracking a vast number of points distributed on the object. Images contain all the information to derive 3D measurements from multiple 2D image coordinates with limited cost and good accuracies. In fact, image-based techniques have been used in several applications which involve the determination of the shape of a body and its changes, with satisfactory results in terms of completeness, precision and time [
2–
5]. These are also known as vision metrology applications. Some commercial cameras (or photogrammetric ones), tripods, light sources and synchronization devices are the components needed to obtain high precision 3D measurements for a large number of points. However, the extraction of 3D information from 2D images is not a simple issue and algorithms for image processing must be developed in order to obtain an automated elaboration.
The goal of image-based methods in material testing is the estimation of accurate 3D coordinates starting from 2D measurements in the images through a perspective mathematical formulation between the object and its projection into several images. Some commercial software allow the analysis of the dynamic changes of several targets distributed on the object in an fully automatic way, but if markerless images are employed no commercial automatic solutions are available on the market. Moreover, the procedure becomes a full-field non-contact technique only without targets, when the natural texture of the object is directly used (generally after a preliminary enhancement with filters that modify the local contrast of the image). For instance, this kind of analysis provides the detection and the measurement in fluids, where LVDTs and strain gauges cannot be employed.
Basically, the precision achievable with image-based techniques depends on the size of the investigated elements [
6]. For experiments in a controlled environment a standard deviation of the object coordinates in the order of 1:100,000 of the largest object dimension is expected, but during analysis in repeatable system configurations (e.g., with fixed cameras) a precision of 1:250,000 has been achieved [
7,
8]. In [
9] a hyper redundancy network is used for the study of the deformations of a radio telescope, with an accuracy in the range of 1:580,000 to 1:670,000 obtainable through the use of more images than those strictly necessary. For instance, two images per station enhance the effective angular measurement resolution of a factor of 1.4, while four images per station lead to a factor of 2. In film-based photogrammetric measurements of big antennas this idea has led to an accuracy approaching one part in a million [
10].
As the technological development of commercial low-cost cameras is rapidly increasing, image-based methods and low-cost software are commonly used in several sectors (e.g., archaeology [
11], geology [
12], medicine [
13]) with good results in terms of precision. However, photogrammetric methods have a limited use for material testing in civil engineering. This is mainly due to the lack of automatic processing algorithms and user-friendly software, especially in the case of markerless images.
Some low-cost digital cameras and targets can be a convenient solution for the analysis of the whole surface of an object. The employed targets can be really inexpensive (a piece of white paper with a black mark is sufficient for many applications), while in the case of more exhaustive experiments they can be printed on metal plates or can be made of retro-reflective materials. The centre of the target can be automatically measured with a high precision (up to ±0.01 pixel) in a fully automated way, improving the precision of the corresponding 3D coordinates.
A group of targets permanently fixed on the object provides a regular mesh for all deformation analyses. These dense points can approximate the deformation field of the whole body. A fundamental advantage of an image-based method is the possibility of analysing more targets than those strictly necessary, without increasing the cost of the test and with a limited worsening of the processing time. However, in some applications targets cannot be employed (e.g., for fluid elements) and automatic methods based on the natural texture of the body must be developed. This kind of analysis is more complicated, especially in the case of bad surfaces without details. This fact limits the use of image-based methods inside civil engineering laboratories.
This paper presents three image-based algorithms capable of analysing the deformation field of a generic object during a loading test. These methods work with targets but also with markerless images and can determine the 3D coordinates of a huge number of points in an automatic way. They are currently employed in some civil engineering laboratories, where several building materials and structural elements are tested with satisfactory results in terms of accuracy. In several applications these methods integrate or substitute traditional sensors and provide additional information, which are useful for more complete and detailed investigations.
We focus on the measurement of a finite number of points with a good distribution, while other existing approaches present the extension of the measurement problem to the whole surface of the body [
14]. Our choice is motivated by the needs of structural engineers, who were interested in the analysis of particular points in crucial locations. Another different approach is presented in [
15], in which a system for modelling the interaction behaviour of real objects (including deformations) was developed. A fully automated image-based measurement system is described in [
16].
The first tool here presented allows the estimation of crack variations in fluid fibre-reinforced specimens (Section 2). This is a new non-conventional application for which there are no commercial solutions. This task required the development of an ad hoc sensor for image acquisition and an algorithm for the automatic identification of the cracking process. In particular, a CMOS sensor was transformed into a crackmeter device. The other tools were developed for dynamic 2D and 3D measurements on standard structural elements (e.g., beams, pillars, foundations, walls…) and can operate with targets (like commercial software) but also without markers (Section 3). This last option provides new measurements during tests where only limited information can be achieved with traditional sensors. In order to demonstrate the potential of these photogrammetric methods, a theoretical explanation and several examples are shown and discussed, with a check of the achievable accuracy. Moreover, the advantages (and disadvantages) about the use of low-cost digital cameras are reported and discussed, with a comparison with traditional sensors.
2. Crack Aperture Estimation in Fluid Specimens
2.1. Overview
Cracks are expected for several construction materials during their service ability [
17], especially in the case of reinforced-concrete elements. However, a significant variation of the crack aperture can lead to a progressive deterioration of the steel reinforcement rod with a consequent worsening of the stability of the structure. For these reasons, crack monitoring plays a fundamental role during inspections and laboratory probes. The study of new techniques able to avoid or mitigate the cracking process is a field of research of primary importance in civil engineering. Some innovative solutions based on the use of fibres (in addition to existing mixtures) demonstrated the possibility to limit the propagation of the cracks.
Laboratory testing on fibre-reinforced specimens allow one to study the effect of different fibres and mixture components (water, cement, sand…), in order to determine the best compromise for real applications. A traditional analysis is based on the study of the aperture, shape, location and orientation of cracks with small specimens that simulate the behaviour of the real object.
To monitor the aperture of a crack during standard tests strain gauges are generally used. However, civil engineers needed more exhaustive and specific measurements than those achievable with these standard sensors. In fact, strain gauges allow only one-point and one-dimensional measurements [
18], after a stable application of the sensor on the specimen. These kinds of information are useful in the case of traditional laboratory applications, but they are insufficient for exhaustive and detailed scientific analysis focused on the development of innovative materials. Indeed, the needs of civil engineers required the development of more advanced solutions.
Another issue regards the state of the body: all measurements on the specimens begin after the casting, when the specimens is liquid, and preliminary data about the number of expected cracks and their positions are not available. For these reasons, a new solution capable of analysing the deformations in these particular working conditions was necessary.
The developed tool for such measurements is composed of a mechanical arm carrying a digital camera (
Figure 1) and an algorithm for automatic multi-image processing. A thermal chamber, which contains the sensor used to photograph the specimens, allows controlled and stable testing conditions. Then, an automated positioning system moves a CMOS INFINITY 1–3 camera (3.1 megapixels) equipped with a 200 mm lens over the specimen. All images are captured for several positions at different epochs by planning the trajectory of the mechanical arm and the number of shots. Each image covers an area of 18 mm × 13.8 mm roughly and its inspection allows the detection of very small details. The robotic arm moves the camera along prefixed directions in order to photograph the whole specimens. This operation can be repeated several times and the images can be used for a multi-epoch investigation to detect dynamic variations. As a typical test may require several days, hundreds of images can be collected. Therefore, a useful choice (before analysing all images) is related to a rapid visual check of the images of the last epoch in order to select the images which contain a crack. The remaining images can be removed from the elaboration to speed up the whole processing.
2.2. Crack detection and Image Coordinate Measurement
The estimation of the crack aperture is carried out with an automated algorithm capable of detecting a crack in each single image by measuring its border coordinates (in pixels). Then, a procedure based on simple geometric considerations between the camera and the specimen allows the estimation of the crack aperture in metric units.
Image coordinates can be automatically measured with the methodology proposed in [
19], in which a tool named IMCA (IMage Crack Aperture) was developed by the authors for crack measurement during structure inspections. The same procedure is used in these experiments, but some changes were necessary to adapt the algorithm in the case of fibre-reinforced specimens and repetitive experimental conditions. The new procedure uses a filtering algorithm that detects the image coordinates of a crack by means of an intelligent reduction of the colour depth. This technique can be assumed as a conversion of the original RGB image to a new binary image (0 is the crack while 1 means background). As the radiometric content of a generic image is expressed by three functions which correspond to the colours (red, green and blue) of Bayer’s filter [
20] covering the sensor, this new strategy uses this information to automate the measurement phase. We denote these functions as
R(
i,
j),
G(
i,
j) and
B(
i,
j), in which (
i,
j) are the coordinated of a generic pixel. The behaviour of the RGB functions along a cross-section of a crack is quite simple: they rapidly decrease and increase in the crack and have a quite constant value far from the crack. Starting from these simple considerations, a filtering algorithm was developed. It is based on the minimum values
Rmin,
Gmin,
Bmin of the functions (in the middle of the crack) and the values
RA GB BC in which the slope of the functions changes. These values can be estimated with the analysis of some cross-section and then used for the completion of the test. A “global level”
L can be estimated for the crack as follows:
and represents the parameter to filter the image. For any generic pixel (
i,
j) of the image a local level
L’(
i,
j) can be estimated by considering its radiometric content:
The creation of the filtered image is carried out by comparing
L’ and
L as follows:
| L’(i, j) − L > 0 | pixel ∈ CRACK; |
| L’(i, j) − L = 0 | pixel ∈ BORDER; |
| L’(i, j) − L < 0 | pixel ∉ {CRACK or BORDER}. |
This method uses the whole RGB content of an image, while other existing techniques (e.g., [
21,
22]) work with their combinations and need a preliminary conversion to create a new gray-scale image. This choice is motivated by the results obtained with the proposed methodology, although we are testing a procedure which uses the green channel.
The main advantage during laboratory testing, with repetitive working conditions, is the possibility of estimating a preliminary global level, which can be considered a constant for specific applications. In fact, if illumination conditions are stable (in this case a LED is permanently employed for all images) the global level does not vary significantly during the test. In addition, small errors in this phase can be considered systematic errors and can be removed during the estimation of the aperture variations. After some tests we estimated an optimal level for fibre-reinforced concrete elements equal to 0.19.
2.3. Crack Aperture Estimation
To estimate the crack aperture a transformation between image and object spaces must be employed. As the analysis starts with a fluid specimen (its external surface is horizontal), the robotic arm was assembled in order to generate 2D horizontal movements. With this particular configuration, image and object planes (or camera sensor and specimen surface) are parallel and the camera maps the object through a similarity transformation where the scale is the only unknown. This simple solution allows an easy computation of object coordinates without using more complex transformations requiring the knowledge of several parameters. A more detailed description about this procedure is shown in Section 3.2, because an extension of this transformation is used in another tool, while for this particular application the scale number is the ambiguity.
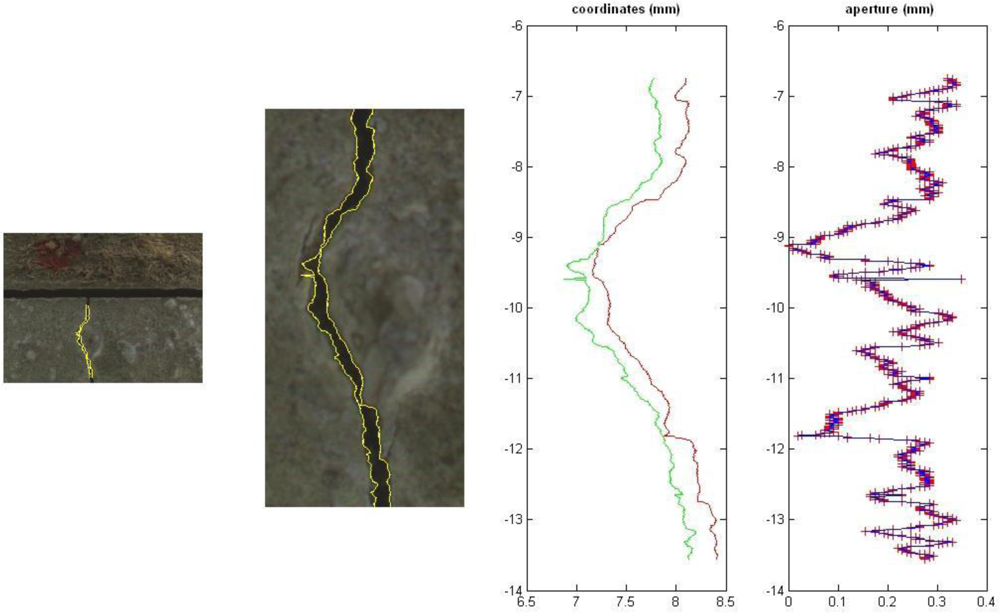
The scale factor was estimated by measuring the size of a pixel projected onto a reference object (a small metal plate) placed on the specimen. The size of this object was measured with a calliper: it is sufficient to divide the width of the plate by the number of pixel picturing the object to determine the scale factor. With the INFINITY camera a pixel covers an area of 9 μm × 9 μm, which is also the accuracy of the implemented tool (see next section for further details). The output interface of the tool, which gives a graphical and numerical visualization of the crack aperture, is shown in
Figure 2. The procedure is quite simple: the user just has to select a crack in an image and the dynamic analysis can be carried out in automatic way. This task is performed by considering corresponding images taken at different epochs. Lastly, the aperture variations can be estimated by using the variations detected at different epochs (relative measurements).
2.4. Accuracy of the Method
To check the accuracy of the implemented method a comparison with other sensors is mandatory. Nowadays, a system capable of measuring the aperture variations in fluid elements with an accuracy and a density better than the implemented tool is not available. This means that accuracy cannot be checked with experiments on fluid specimens. To overcome this drawback we developed an alternative solution with a solid object and a special micrometric sledge (
Figure 3), which is composed of two plates (the first one is fixed while the second one can be moved with two micrometric screws in order to simulate a planar motion). Two mechanical gauges provide the magnitude of the displacements with an accuracy superior to ±0.01 mm. The sledge allows one to simulate the aperture of a “synthetic crack”, where all points have the same displacement (rigid motion). Anyway, this is sufficient to check the accuracy of the image-based method.
A Nikon D80 camera equipped with a 90 mm lens was placed over the sledge in order to determine the simulated variation with the implemented tool. The mathematical relation between image and object spaces was estimated with a special calibration frame, composed of points with known coordinates (see Section 3.2). From a theoretical point of view, the precision of object coordinates
σXY can be estimated with a simple formula:
where
d is the camera-object distance,
c the focal length of the camera and
σxy the image coordinate precision. The fundamental assumption of
Equation 3 is the parallelism between image and object planes.
However,
Equation 3 gives a theoretical precision that must be compared with real data (useful for a preliminary knowledge about the expected accuracy). In our tests we placed the camera with a distance
d1 equal to 600 mm, then we reduced the distance to
d2 = 220 mm. Both mechanical and image-based measurements were compared and the results showed a standard deviation of the differences of ±0.037 mm (
d1 = 600 mm) and ±0.012 mm (
d2 = 220 mm). Supposing that the precision of the filtering algorithm is equal to ±1 pixel, a theoretical precision of ±0.04 mm and ±0.014 mm can be estimated with the camera used in both configurations (pixel size is 0.0061 mm). This means that the precision of the implemented tool is equal to the GSD (Ground Sampling Distance), which represents the projection of a pixel onto the object. To improve the precision of the object coordinates the camera-object distance can be reduced or the focal length can be increased. However, in both cases the angle of view is progressively reduced and a smaller part of the object can be imaged. The best choice is a compromise between precision and imaged area. Several other comparisons validated the proposed results and confirm the expected accuracy in the case of the INFINITY camera (a pixel projected onto the object is ±0.009 mm).
3. 2D Deformation Measurements
3.1. Overview of the Implemented Method
During some tests the analysis of 3D movements is not strictly necessary. In fact, if the analyzed object is flat (e.g., the external surface of a beam), the estimation of a 2D motion is more than sufficient for several experiments. This fact leads to a simplification of the measurement problem, with a reduction of the degrees of freedom for a generic point of the object. Moreover, there is an advantage in terms of cost: a single image for each epoch becomes sufficient to analyze the movements of all points. Starting from the image coordinates of point (xi, yi) the corresponding object coordinates (Xi, Yi) can be calculated by using a 2D homography. Beyond the reduction of the number of cameras (a fixed camera is sufficient, thus synchronization devices are not mandatory), a rigorous calibration of the camera is not needed. However, the influence of an uncalibrated camera on the final results should be carefully considered, although the whole operation can be carried out without knowing the intrinsic parameters of the camera used. This could be an advantage when no information about the used sensor is available. This aspect is analyzed with more details in Section 3.5.
The equipment includes a camera placed on a tripod and an algorithm able to track all image points and to estimate real movements. The acquisition frequency depends on several factors and varies with the investigated object and the selected load. For this reason it is not possible to fix an optimal value for every experiment. This means that an ad-hoc sampling frequency must be estimated before the beginning of the test by considering several factors (e.g., load, expected deformation, object, texture…). Probably, the best solution is to acquire more images than those strictly needed. Then, images can be decimated.
The implementation of an ad-hoc software was necessary because commercial solutions for fully automated image processing are not available on the market. Some commercial packages (e.g., Australis, iWitness, PhotoModeler…) work with targets, but if markers cannot be employed the elaboration needs tedious interactive measurements. In addition, these software packages generally work with two or more cameras, while the situation with a single image needs a different mathematical formulation.
3.2. Target Localization and Matching
Several targets distributed on the object are a valid support in image-based deformation measurements. A regular mesh of targets allows one to analyze the whole surface of the body, while the use of traditional sensors (e.g., strain gauges or LVDTs) increases the cost and needs complex connections with control units. For these reasons, photogrammetric targets are a cheap solution with a simple connection on the analyzed body. During several real surveys, all targets can be printed (e.g., a black dot with a white background), while for more advanced and extensive analysis they can be made of metal.
Figure 4 shows a typical analysis with targets: the surface of the beam can be considered a flat object and a regular mesh allows the measurement of its deformation field. In this case, six LVDTs were used, but they offer few measurements along prefixed directions. With this in mind, the target-based image solution is more convenient.
All targets can be automatically matched by using a 2D normalized cross-correlation technique between a target template and the image [
23]. Basically, the method supposes that the target template (a perfect image of the target, which can be easily created with any software for image visualization or editing) is similar to the target used during the survey.
An automated search of the target(s) in the whole image can be carried out by comparing the template with the local content of the image (a preliminary conversion of the original RGB image to a new grayscale one must be performed). The measurement of the centre of the target in the image is carried out by moving the template
f(
x,
y) in a search window (or in the whole image), with a sequence of small displacements (e.g., one or two pixels). For each position the normalized correlation coefficient
ρ(
x,
y) between
f(
x,
y) and the local content of the image
g(
x,
y) (“patch”) can be estimated with the relation:
where (
x,
y,
x’,
y’) are the centers of template and patch and
μf and
μg are the mean values of intensity of
f and
g. The size of the patch is (2
N + 1) × (2
M + 1) pixels. The centre of the target can be assumed at max [
ρ(
x,
y)] with an additional constraint on the minimal value (e.g., 0.7). Sub-pixel precision can be achieved by estimating the first derivative of
ρ(
x,
y) [
24].
This method is easy to implement and fast from a computational point of view [
25], but it takes into account only two shifts between template and image. In the case of real surveys there are several other deformities such as scale variations or rotations, affine deformations, illumination changes and so on. They lead to poor results with this basic geometric model. In [
26] a modified cross-correlation approach was developed to consider all these deformities by reshaping the patch with an affine transformation, which is more suitable for real surveys. However, we prefer to use the method proposed in [
27] and coined
Least Squares Matching (LSM).
Starting from a perfect similarity between the template and the patch:
the LSM method takes into account a more realistic situation, in which
equation 5 is not consistent and a noise
e(
x,
y) is added:
To operate with the Gauss-Markov Least Squares estimation model
g(
x,
y) must be linearized at an approximate location with a first order Taylor’s expansion:
where an affine transformation is considered as geometric model (a radiometric correction is not used because illumination conditions are stable if light sources are used during experiments in controlled conditions):
The parameters
a0 and
b0 (shifts) are unknown values that indicates the centre of the target, while the other coefficients can be used to adjust shape deformations.
Equation 6 can be cast in the form:
Finally, the unknown parameters can be grouped into a vector:
and the system can be written as:
in which
lk =
f(x, y) −
g (
x0,
y0). The solution is given by:
In order to complete the linearization with a Taylor’s expansion, a set of initial approximations for the unknowns is chosen as follows:
and then the solution is computed iteratively with a stop criteria (e.g., on the estimated sigma-naught). In the implemented version of the LSM algorithm, some tests to check the determinability of parameters (10) were included; further information about this aspect can be found in [
28].
The LSM method ensures high precision measurements (up to ±0.01 pixels) and is an optimal choice in the case of targets. However, it cannot be considered as an alternative to cross-correlation: cross-correlation provides good approximate values about target locations and LSM refines center coordinates. Thus, the combined use of both these techniques is strictly mandatory in order to automate the whole analysis.
3.3. Computation of Object Coordinates and Dynamical Analysis
Object coordinates can be calculated by using image coordinates and a transformation between image and object spaces. In the case of flat objects all points lie on the same plane and the mathematical transformation between image and object spaces can be described with a 2D homography.
The relation between an image point in homogenous coordinates (
xi,
yi, 1)
T and the corresponding object coordinates (
Xi,
Yi, 1)
T is:
or, in a compact form:
H contains the parameters of the transformation and has a rank deficiency, thus only eight elements are independent and an external constraint must be used (we set the last elements c3 equal to 1). To obtain inhomogeneous coordinates it is sufficient to divide image and object coordinates by their third coordinate.
This leads to the inhomogeneous form of the planar homography:
which are linear in the elements of
H. In fact, a multiplication by the denominator leads to:
To estimate the eight coefficients of
H some correspondences between the image and object spaces must be known (at least four points). Given
m corresponding points,
Equations (17) provide a system of 2
m equations that can be solved
via Least Squares [
29].
The measurements of the object points needed to estimate H can be carried out with several techniques (e.g., total station, calibrated frames …). Moreover, H is estimated for the first epoch and then assumed constant during the next phases. Indeed, if the camera is placed on a stable tripod the transformation does not change and 2D displacements can be directly estimated by using image coordinates.
A better strategy to visualize the results is based on the removal of the perspective effect from the images. Here, the homography H estimated for the first image can be applied to all images before measuring the image coordinates. The measurement of image coordinates with the rectified images provides object coordinates.
Figure 5 shows some rectified images for the beam sequence. As can be seen, images present a distortion that cannot be removed if calibration is unknown. This generates an error in the final results (more details about the influence of image distortion are presented in Section 3.5). The circle represents the position of each target for the first epoch, while the length of each line gives 2D movements (a known scale factor is needed).
Figure 6 shows a detail. In this case the positions of some targets measured at different epochs are shown, in which the first image is used for this visualization. Target coordinates can be measured interactively and this kind of visualization offers a global visualization about the deformation field.
3.4. Automated Elaboration of Target-Less Images
Targets are very useful to monitor deformations emerging in loading tests: they can be easily measured with a high precision and their application onto the body is simple and cheap. However, in some cases targets cannot be permanently installed or can be lost during the test. To overcome this drawback a synthetic texture can be generated (e.g., by painting the object) but we developed a new solution capable of working with target-less images. It uses the natural texture of the object after a preliminary image enhancement. Interest operators can be used to detect a sufficient number of features in the first image of the sequence. Then, these features are tracked with the proposed methodology based on cross-correlation and LSM along the sequence.
Before the beginning of the test it is highly recommended to process some images. This operation is really useful to verify the quality of the images and the possibility to use the natural texture (i). In the case of a failure with the natural features, a procedure based on synthetic corners (ii) can be used. The application of targets onto the object remains the last choice when the previous method cannot be employed.
Several features can be detected in an image (e.g., corners, edges, regions…) and several operators are available (probably too many to be listed here). For a more exhaustive review the reader is referred to [
30–
32]. The method used in the implemented tool is the FAST (Features from Accelerated Segment Test) operator [
33], which is a corner detector for high speed processing, today employed in video analysis and tracking. The functioning of FAST is based on the analysis of a circle of 16 pixels around a generic corner
p. A pixel is a corner if
n contiguous pixels are all brighter than the intensity
Ip of the candidate pixel plus a threshold
t, or all darker than
Ip −
t.
The choice of this operator is supported by the impressive number of corners that can be extracted from an image. However, corners are extracted only for the first image of the sequence, while for the next ones a tracking via cross-correlation and LSM is used.
In some cases images might present a bad texture and a limited number of corners could be extracted. In addition, the distribution of points could be inhomogeneous. To solve this problem a procedure based on a preliminary image enhancement can be used. Many methods are today available and generally work by considering global parameters: most software for image enhancement have automatic functions capable of modifying the contrast of the image, but the same level is used for the whole image. If a homogenous distribution of all points is needed this can lead to a poor solution. This is the reason why we prefer to optimize the contrast locally. Wallis [
34] proposed an
ad hoc image filter which splits the image into small rectangular blocks. These blocks are progressively analyzed by considering their local statistics.
The Wallis filter has the form:
where:
and:
If and Io are the filtered and original images, r0 and r1 the additive and multiplicative parameters, mo and so the mean and standard deviation of original images, mt and st the target mean and standard deviation for the filtered images, c the contrast expansion constant and b the brightness forcing constant. Basically, the user has to select the block size: a small block (e.g., 7 × 7 pixels) results in a strong enhancement, while a large block (e.g., 131 × 131 pixels) generates a loss of detail.
For each single block mo and so are estimated and the resulting values are assigned to the central pixel of each block, while for other pixels these values are estimated with a bilinear interpolation. The target mean and standard deviation mt and st are manually selected. Normally, for an 8-bit image a good choice of the target mean is 127, while the target standard deviation value can be 50. Good values for the constant expansion constant c are in the range [0.7, 1], while for the brightness forcing constant b the suggested range is [0.5, 1]. An optimal combination of all these parameters can be determined with few tries in which a visual check of the filtered image is sufficient. Moreover, it is possible to extract FAST corners and check their number and distribution.
Figure 7 shows the original image of a small beam (a) and the detected corners with the FAST operator (b). As can be seen, few points can be measured. The filtered image (c) provides more corners (d) with a better distribution. At the end of the process points can be mapped (d) onto a “quasi” regular grid (in this case each cell is 50 × 50 pixels roughly).
The dynamic analysis is carried out by filtering all images and tracking the original FAST corners with cross-correlation and LSM along the image sequence, which must be filtered with the same parameters. It is also recommended to use stable illumination conditions during the analysis (e.g., external light sources like lamps), a very high acquisition frequency according to the duration of the test (to limit the differences between consecutive images) and small blocks (e.g., 9 × 9 pixels) for the filtering process (to reduce the effect of local deformations during the test). Moreover, this procedure should be used when limited deformations are expected. With these experimental conditions we verified that only a limited number of points is lost during the sequence analysis.
3.5. Influence of Camera Calibration
The mathematical analysis proposed in Section 3.3 demonstrated that no information about the camera used is required when the relation between image and object spaces is a planar homography. Thus, image coordinates and few reference object points are adequate to complete the elaboration. Camera calibration is intended as the process to estimate the intrinsic parameters of the camera, comprehending the principal distance, principal point and distortion coefficients. A good calibration is an essential prerequisite for precise and reliable measurements from images, and is widely adopted in several surveys where high accuracies must be achieved. Several software use an 8-terms model derived from the original formulation for image distortion proposed by Brown [
35]:
where Δ
x and Δ
y are the corrections for a generic image point with coordinates (
x,
y),
x* =
x −
xp and
y* =
y −
yp are the image coordinates referred to the principal point,
r2 =
x*
2 −
y*
2 is the squared radial distance.
The coefficients k1, k2, k3 model the radial distortion. In particular, the coefficient k1 is generally sufficient during most surveys, but when a high accuracy is needed, the coefficients k2 and k3 have to be used as well. Tangential distortion, that is due to a misalignment of the camera lenses along the optical axis, can be modeled with p1 and p2. The magnitude of tangential distortion is limited if compared to radial distortion, especially with wide-angle lenses.
Digital cameras should be calibrated periodically, because several issues about the stability of the sensor could arise. A standard camera calibration procedure can be performed by using known points (and few images), or without any external information and special coded targets. The former (termed as field calibration) needs external 3D information provided through a framework with several targets, whose 3D coordinates have been previously measured (e.g., with a total station). The latter (self-calibration) is based on a free-net adjustment [
36] in which points with known 3D coordinates are not necessary. The calibration framework needs a set of targets, which are measured in the images. Furthermore, some additional mathematical constraints and a block composed of several images with a suitable network geometry are needed. For a general review about calibration methods the reader is referred to [
37].
Equations 21 allow one to model image distortion in order to correct each single measured image point. In addition, distortion coefficients can be used to derive distortion-free images, although this operation needs a longer elaboration time. If calibration is given, the correction of image coordinates should be always carried out in order to improve the precision of the final result. However, image distortion can be considered locally constant, thus when different epochs are analyzed its contribute can be assumed as a systematic error and removed by using relative differences. Anyway, this assumption is valid for small point displacements, therefore a camera should be always calibrated especially with consumer cameras and wide-angle lenses.
5. Conclusions
In this paper three image-based tools for measurement of deformations in laboratory testing on construction materials were presented. Because of their user-friendliness they can be used by people who are not necessarily skilled in image analysis, computer vision, photogrammetry and vision metrology. These methods provide more information than that obtainable with traditional sensors. In addition, when targets cannot be applied the natural surface of the object can be used. In the case of bodies with a bad texture a synthetic texture can be created by painting the object. However, some new techniques based on a preliminary image enhancement of the local radiometric content of the image and feature extraction and matching can be applied to extract a sufficient number of points to complete the analysis.
The implemented image-based methods can provide 2D and 3D measurement for a vast number of points and allows the analysis of the whole body. Moreover, the procedure is highly automated and only few semi-automatic measurements for the image(s) of the first epoch are needed (e.g., target localization, visual check, removal of the scale ambiguity,…). The dynamic analysis can be considered a fully automatic phase and 2D or 3D measurements can be rapidly estimated after the end of the test. All these tools were implemented to work with building materials, in which the global deformation is limited with respect to the object size. During several standard tests on construction elements (e.g., pillars, beams…) the methods demonstrated good results even in the case of strong deformities of the body. These experimental tests demonstrated an accuracy of these methods similar to that achievable with traditional electrical or mechanical sensors, however, the use of digital cameras allows the elaboration of a larger number of 2D or 3D points with a better spatial distribution.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












