2.1. Array Model
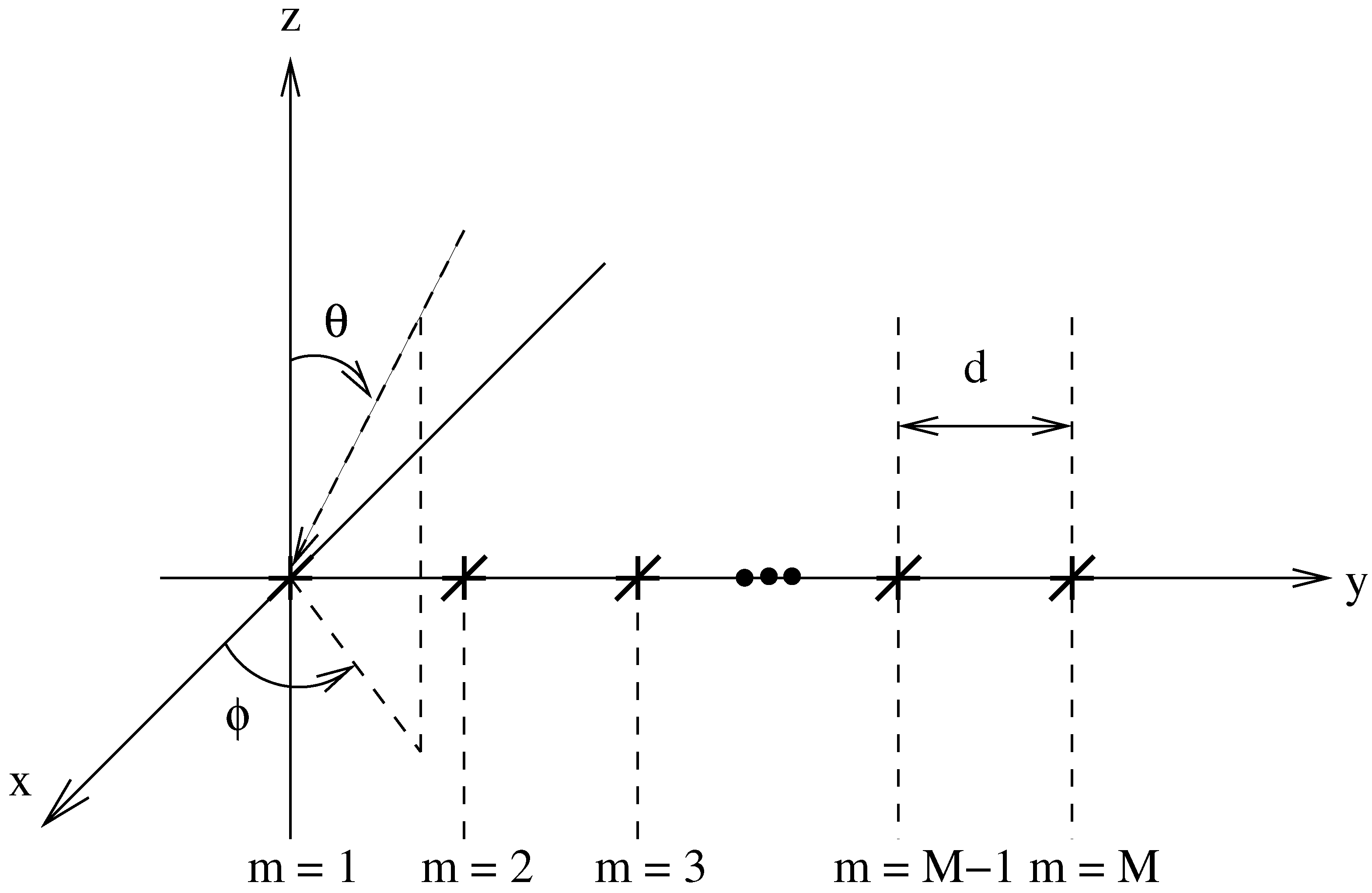
Figure 1 shows the tripole array structure being considered. There are
M tripole locations spread over the y-axis with an adjacent separation distance
d. For each tripole, there are three orthogonally orientated dipoles, one parallel to each axis. Also shown is a signal with its DOA defined by the angles
θ and
ϕ, which are limited as follows:
and
. A plane-wave signal model is assumed,
i.e., the signal impinges upon the array from the far field.
Figure 1.
An array model with M potential tripole locations shown.
Figure 1.
An array model with M potential tripole locations shown.
The spatial steering vector of the array is given by
where
λ is the wavelength of the signal of interest. For tripoles, the spatial-polarization coherent vector contains information about a signal’s polarisation and is given by [
27]:
where
is the auxiliary polarization angle and
is the polarization phase difference.
Now, the array can be split into three sub-arrays, one parallel to each axis. The steering vector of each of these sub-arrays is complex-valued and given by:
and
respectively.
The response of the array is given by
with
where
is the weight coefficient for the
dipole orientated parallel to the
i-axis (
) and
denotes the Hermitian transpose. Similarly, we also have
where
is the contribution of the
dipole to the overall steering vector parallel to the
i-axis.
In what follows, we address the problem of designing a sparse linear tripole array, where there are two issues to be solved. Firstly, we have to find the optimal tripole locations, as there will no longer be a uniform adjacent tripole separation of d. Secondly, we have to find the weight coefficients that give an acceptable beam response. We propose to use design methods based on CS to solve these problems.
2.2. Compressive Sensing Based Design of Sparse Tripole Arrays
Suppose
is a reference response which we wish to achieve. First, consider
Figure 1 as being a grid of potential tripole locations. In this instance,
is the potential aperture of the array and
M is a large number. Sparseness is then introduced by selecting the weight coefficients to give as few active tripoles as possible, or, in other words, as few non-zero valued weight coefficients as possible. This has to be done while still giving a designed response that is close to the desired one.
This problem is formulated as
where
is the
norm of the weight coefficients and used as an estimate of the number of nonzero weight coefficients in
,
i.e., an approximation to the
norm,
is the vector holding the desired beam response at the sampled angular and polarisation points of interest,
is the matrix composed of the corresponding steering vectors and
α places a limit on the allowed difference between the desired and the designed responses. Therefore, by minimising
in Equation (
9), we are minimising the number of tripoles we have to use, while the constraint ensures that we still get a good approximation of the reference response.
In detail,
and
are respectively given by
where
L is the number of points sampled at each dimension of the desired beam response and
denotes the transpose operation. In this work,
is the ideal response,
i.e., a value of one for the mainlobe and zeros for the other entries. It would also be possible to use other reference responses if desired, for example, a response which defines a maximum sidelobe level or one with nulls at a given direction.
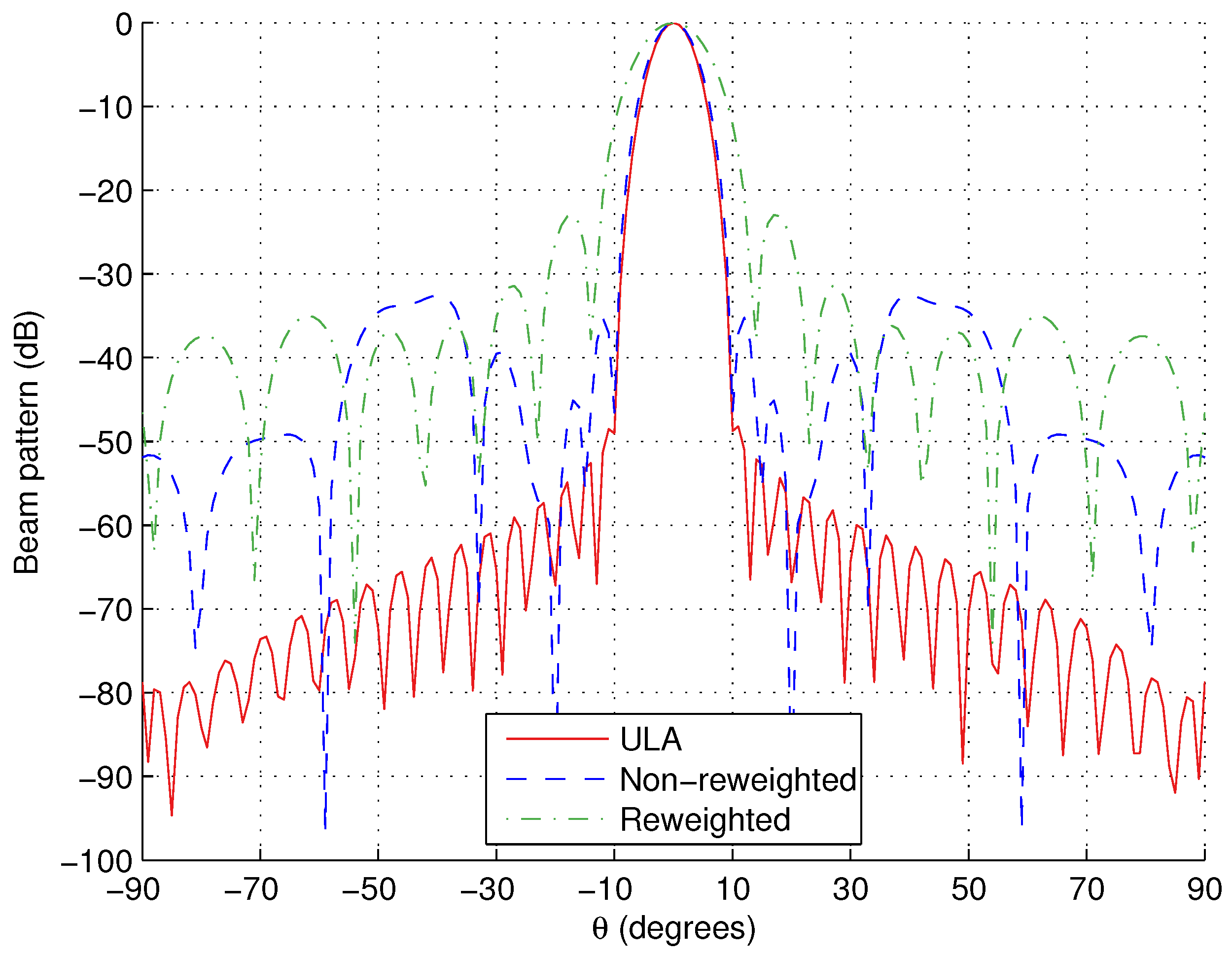
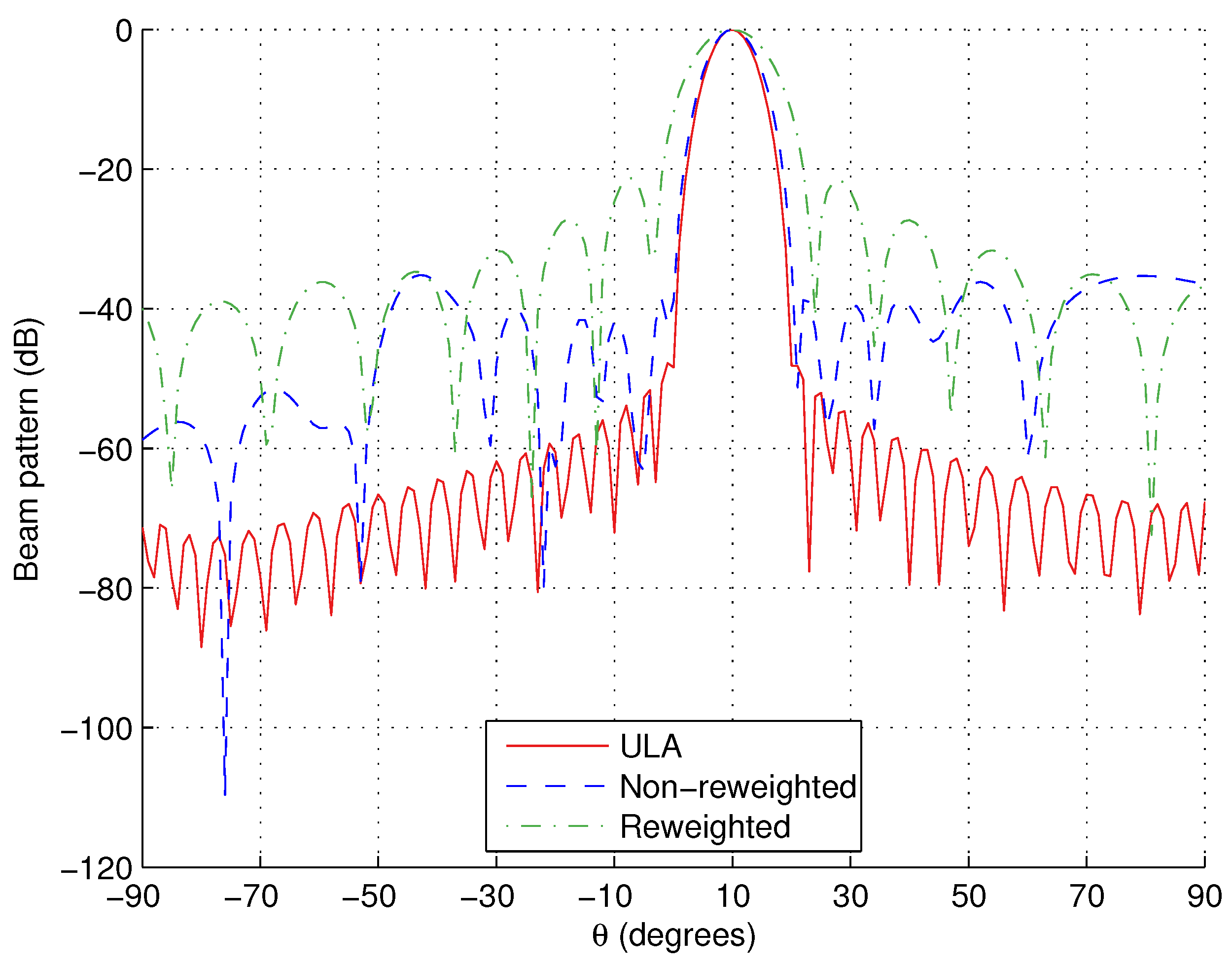
Note, we have to choose L to be large enough to ensure that all angular and polarisation points of interest are being considered. However, the larger L is, the longer the computation time will be. An acceptable compromise seems to be to sample the sidelobe regions every . We can also help improve the sparsity of the solution by increasing the value of M. A larger value of M gives a denser grid which is more likely to include the optimal locations. As a result, the same amount of error between designed and reference responses can be obtained using fewer tripoles. However, we will get to the point where the optimal locations will be already included on the grid and further increases will only serve to lengthen the computation time. This means there is again a compromise to be achieved when selecting the value of M, and this will be explored in the design examples we present in this paper.
One problem with the above formulation is that the three complex weight coefficients associated with each tripole can not be guaranteed to be minimised simultaneously. As a result, we may not be able to obtain a sparse solution even if we have a sparse weight vector
after the minimisation. In other words, it would be possible to end up only removing a single dipole from each potential location rather than truly introducing sparsity by removing complete tripoles. Therefore, we further modify the formulation in Equation (
9) by converting it into a modified
norm minimisation.
First, we rewrite Equation (
9) as
where
and
. Here
contains the weight coefficients for all the dipoles that make up the tripole at the
grid location. Therefore, by minimising the value of
t the second constraint in Equation (
12) ensures the combined weight coefficients for the tripoles are also minimised.
Now, we decompose
t to
,
. This allows us to minimise the combined weight coefficients for each tripole separately. In vector form, we have
Then, Equation (
12) can be rewritten as
Now, define
and
where
is the contribution of the
dipole parallel to the
axis to the steering vector of the array,
gives the real component of a scalar and
gives the imaginary component of a scalar and
gives the real components of a vector/matrix and
gives the imaginary components of a vector/matrix. Here, we have included the values of
in
as we want to automatically find them with the weight coefficients instead of them being predetermined. We then use
to select the values of
for minimisation, and the zeros are added in
to ensure they do not contribute to the error between the reference and designed responses.
Then, the final formulation is as follows
which can be solved using cvx, a package for specifying and solving convex programs [
49,
50].
As with the traditional CS based design methods, the solution can be improved by considering the problem as a series of iteratively solved reweighted minimisations to bring the solution closer to that of the
norm minimisation [
20,
21,
22]. This is achieved by the addition of a reweighting term which is found from the previous iteration and penalises small non-zero valued weight coefficients more heavily, meaning all non-zero valued coefficients are treated in a more uniform manner (as for the
norm minimisation). As a result, these small non-zero valued weight coefficients are less likely to be repeated in the next iteration and the sparsity of the solution is improved.
In this form, the problem is formulated as follows
where we now have
and
This is then solved iteratively until the number of non-zero valued weight coefficients has remained constant for a few iterations.
Note, the term
ϵ is added for numerical stability and should be set slightly smaller than the minimum implemented weight coefficient for a single tripole. However, its addition means that a zero-valued weight coefficient in one iteration will not be guaranteed to be repeated in the next. This has the result of meaning a solution is not always guaranteed, but when a solution is possible, it will usually be achieved in less than 10 iterations. For the first iteration, Equation (
20) can be solved and the reweighting terms introduced from the second iteration onwards. Finally,
gives the current estimate of the weight coefficients for the
tripole, whereas
gives the estimate from the previous iteration.







{kind=link}
{kind=link}
{kind=link}

