
Random Forest-Based Recognition of Isolated Sign Language Subwords Using Data from Accelerometers and Surface Electromyographic Sensors


Abstract
:1. Introduction
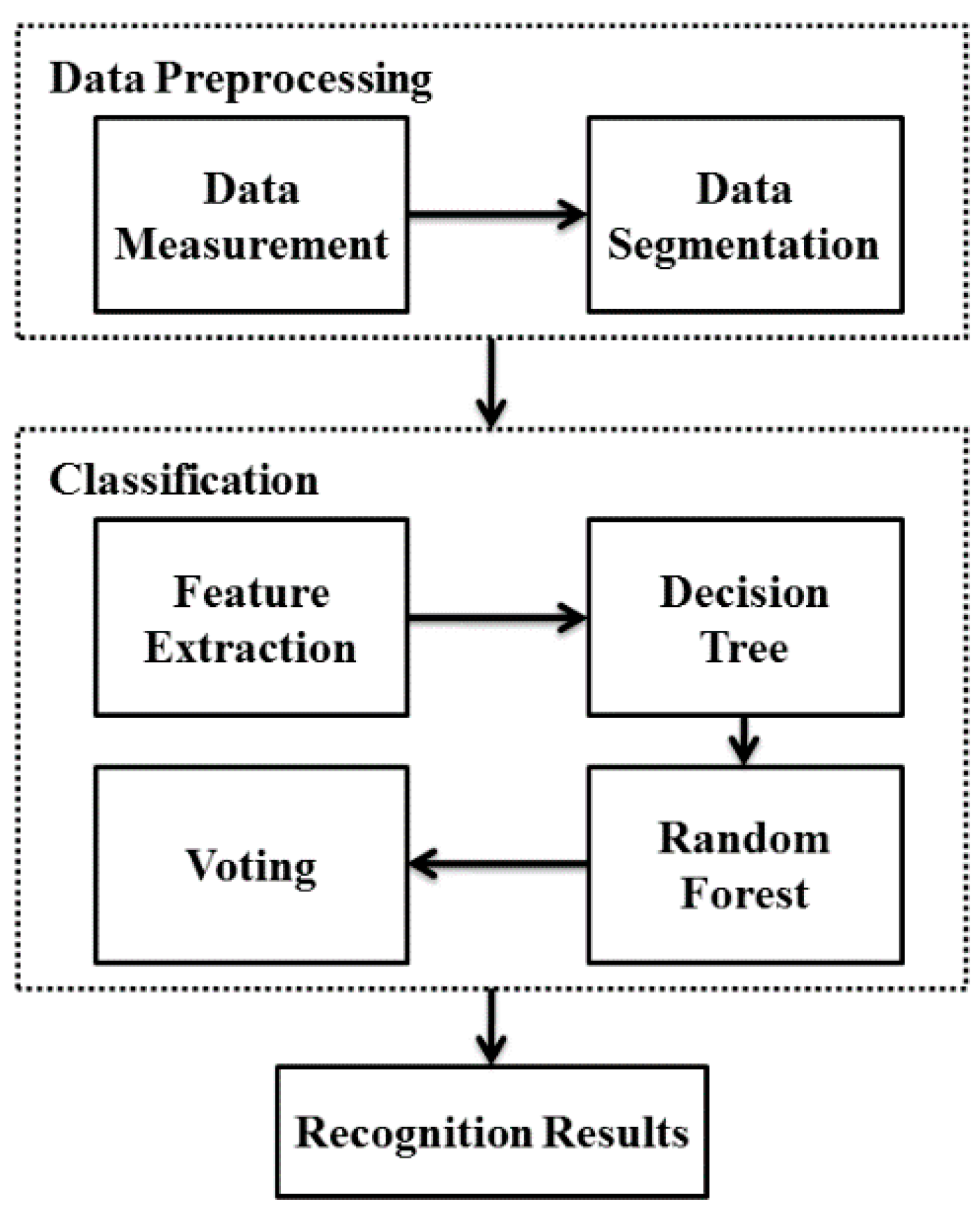
2. Method

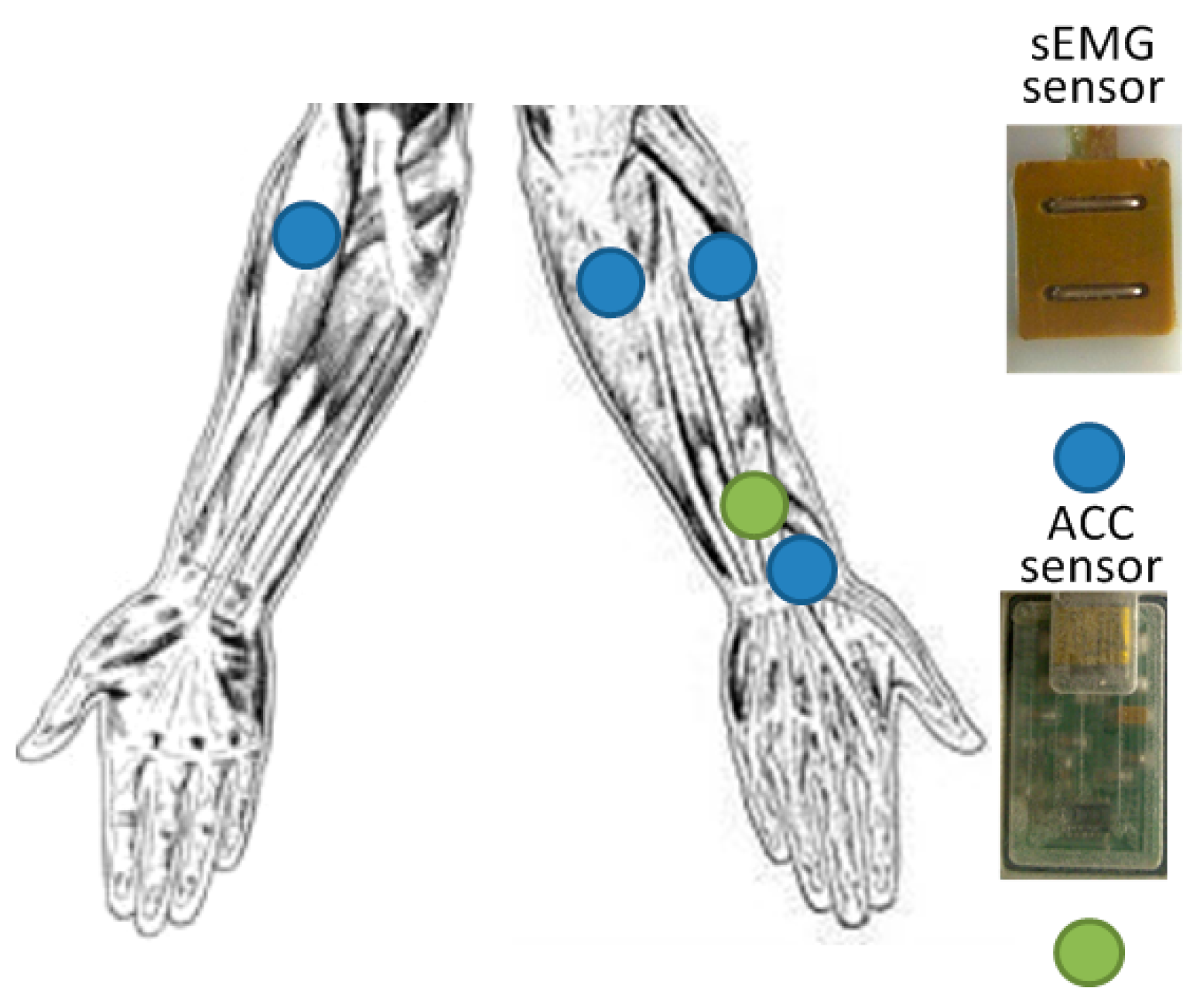
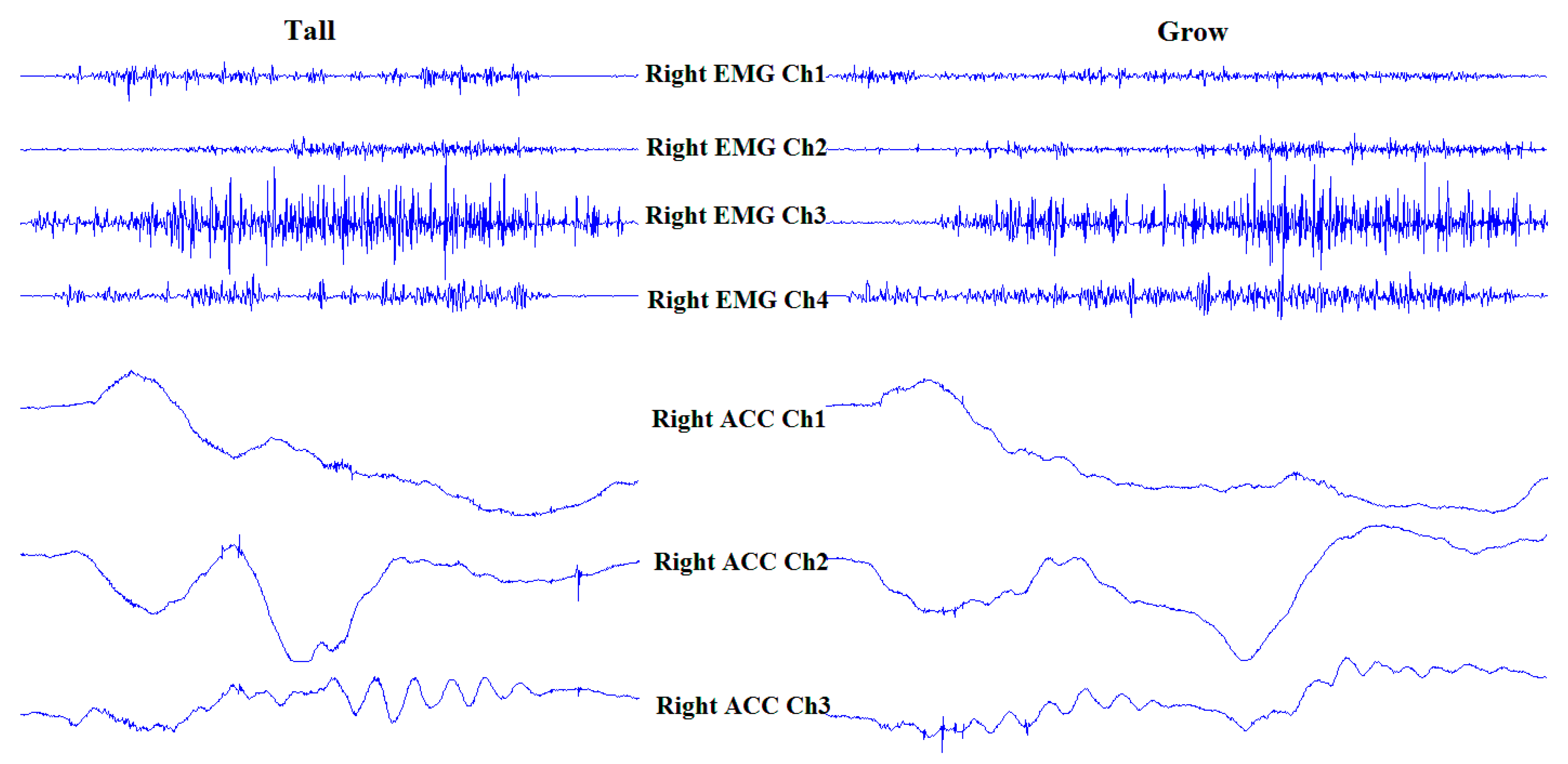
2.1. Data Measurement

2.2. Data Segmentation
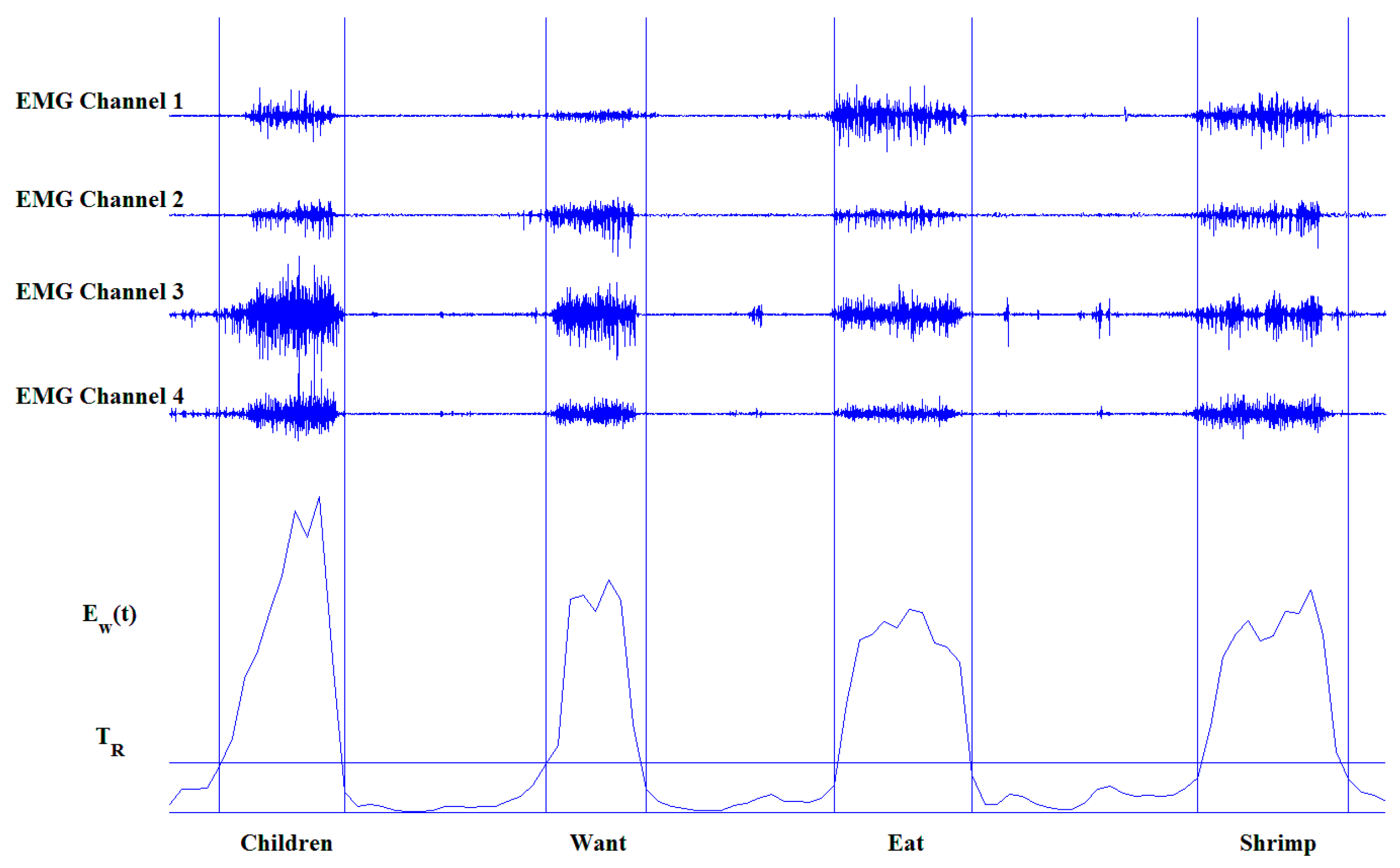
- Step 1: To divide the four-channel sEMG signals into time-shifting chunks with a sliding window. With an increased length of sliding window, both the computation complexity and the accuracy will decrease. In this study, the sampling rate of the sEMG sensor is 1 kHz and the duration of a CSL subword is generally about one second. Based on segmentation experiments with different window size and overlap, 128 ms (128 samples) window length and 64 ms (64 samples) window increment was confirmed to be able to balance the computational complexity and segmentation accuracy.
- Step 2: To calculate the average energy of four sEMG channels for each windowed data chunk according to Equation (1), where x means the signal, t means the index of the data chunk and i means the index of the sEMG channel:
- Step 3: To detect the starting index ts and the ending index te of each subword segment. In this step, the time series {EW(t)} were compared with a predefined threshold TR, which was set as the twenty percent of the mean of the EW(t) of the signer’s maximal voluntary contraction. When EW(t), EW(t + 1) and EW(t + 2) are larger than TR but EW(t − 1) and EW(t − 2) are lower than TR, the starting point (ts) is determined. Similarly, when EW(t), EW(t − 1) and EW(t − 2) are larger than TR, but EW(t + 1) and EW(t + 2) are lower than TR, the end point (te) is found. te − ts + 1 should be larger than 8 to avoid the influence of instant noise.
- Step 4: To enforce the same boundaries on the sEMG channels of the non-dominant hand and the ACC channels of both hands based on the boundaries detected in Step 3.

2.3. Feature Extraction
- Mean Absolute Value (MAV) [27]: Describes the energy of signals. The MAV of sEMG or ACC signal of non-dominant hand is used to distinguish one-handed or two-handed subwords:where x(n) represents the sEMG or ACC signal in a segment and N denotes the length of the segment.
- Autoregressive (AR) Coefficient [24]: AR model describes the current signal x(n) as the linear combination of previous k samples x(n − k) plus white noise w(n). AR coefficients (ak) have been proven to be effective in SLR. The definition of the AR model is given by Equation (3), and p is the order of the AR model:
- Mean: Describes the amplitude level of signals. The mean of the acceleration signal is used to describe the orientation of each subword:where x(n) represents the ACC signals in a segment and N denotes the length of the acceleration signal.
- Variance (VAR) [27]: Describes the intensity of the signal changing with time. The VAR of the acceleration signal is used to judge the movement range of a subword:
- Linear Predication Coefficient (LPC): LPC model describes each sample of signals as a linear combination of previous k samples x(n − k) as Equation (6) showswhere p is the order of LPC and lk denotes the k-order coefficient.
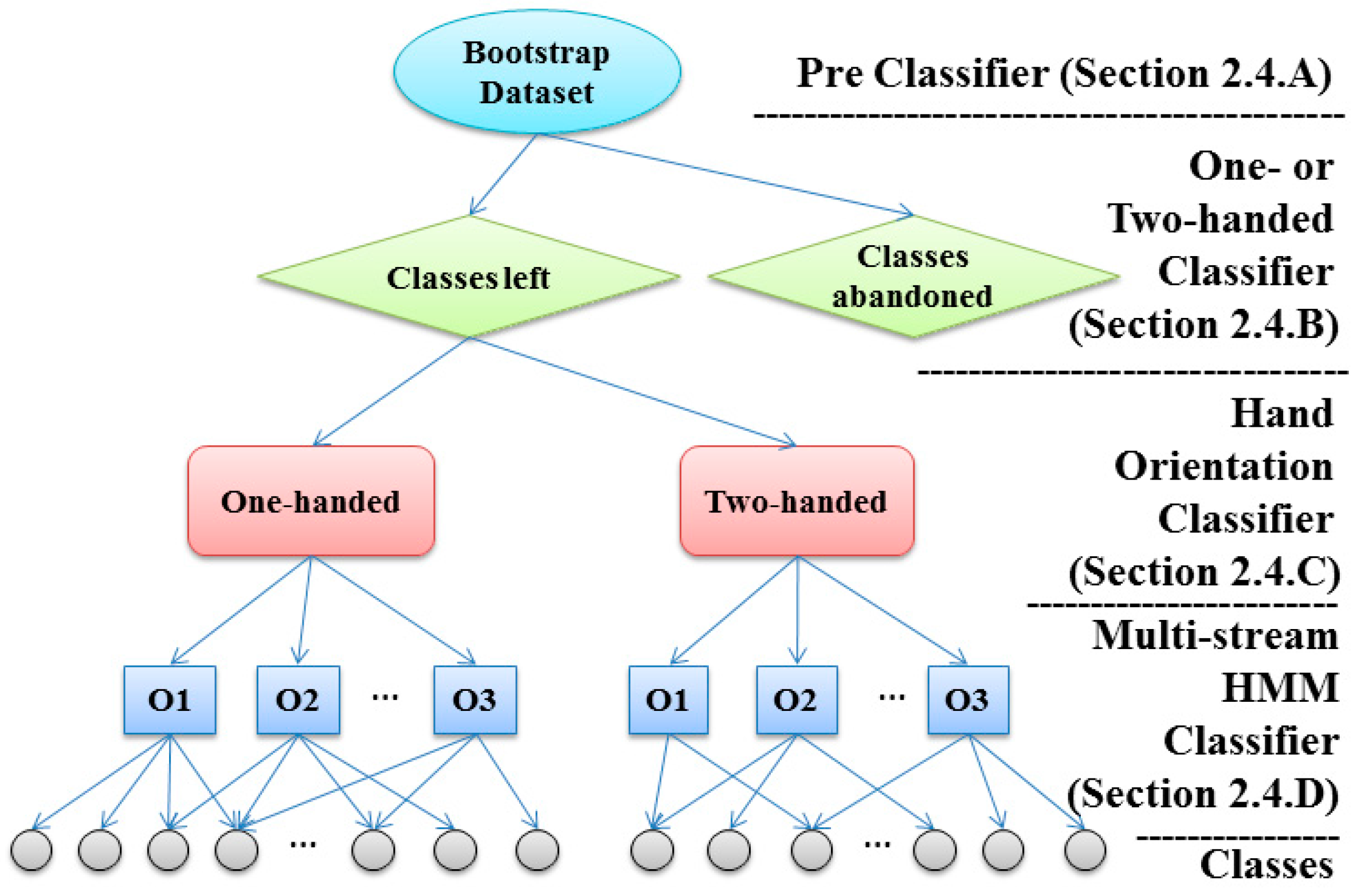
2.4. Random Forest-Based Classification


2.4.1. Improved Decision Tree of Random Forest
A. Pre-Classifier

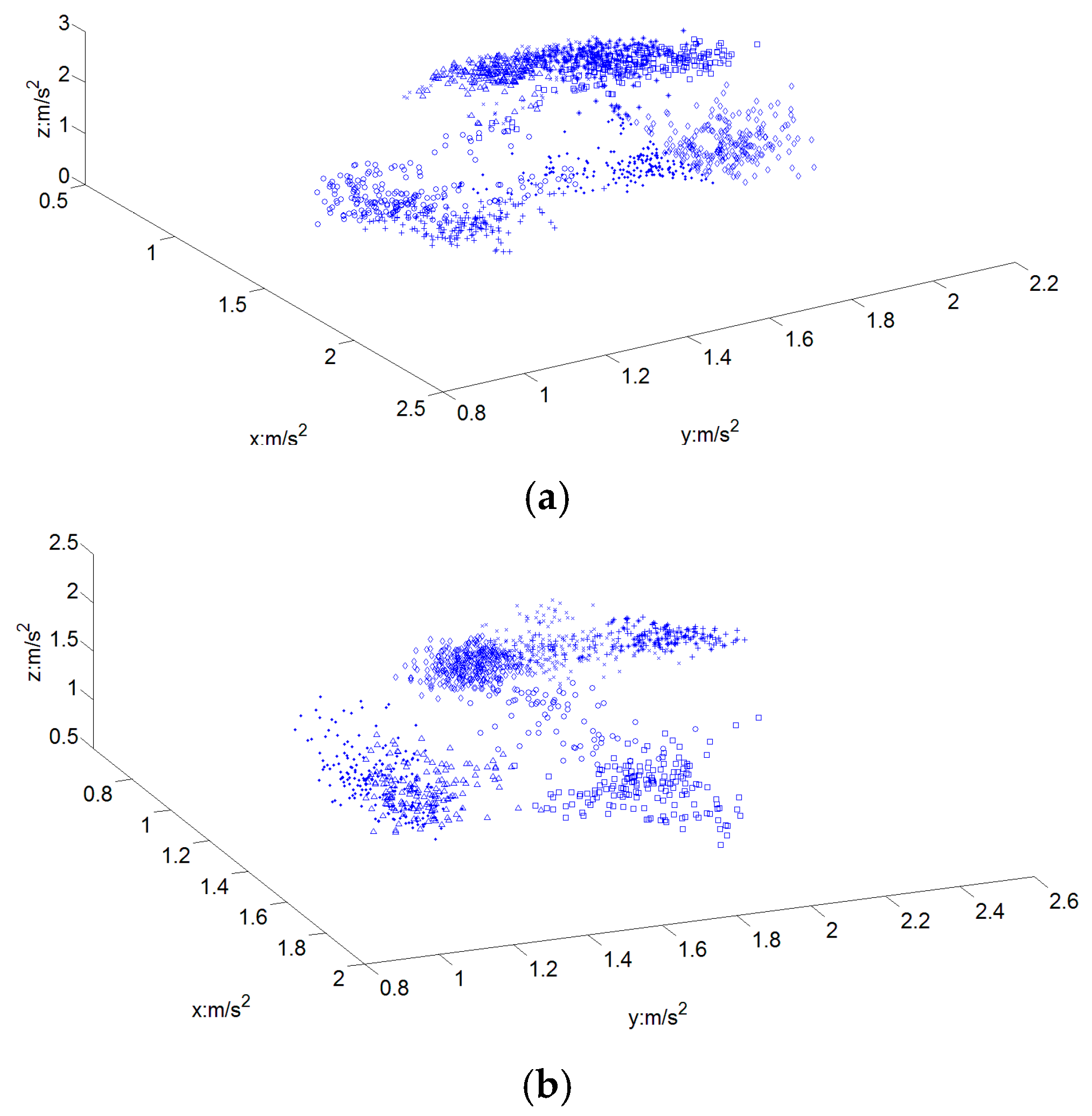
B. One- or Two-Handed Classifier
C. Hand Orientation Classifier

D. Multi-Stream HMM Classifier
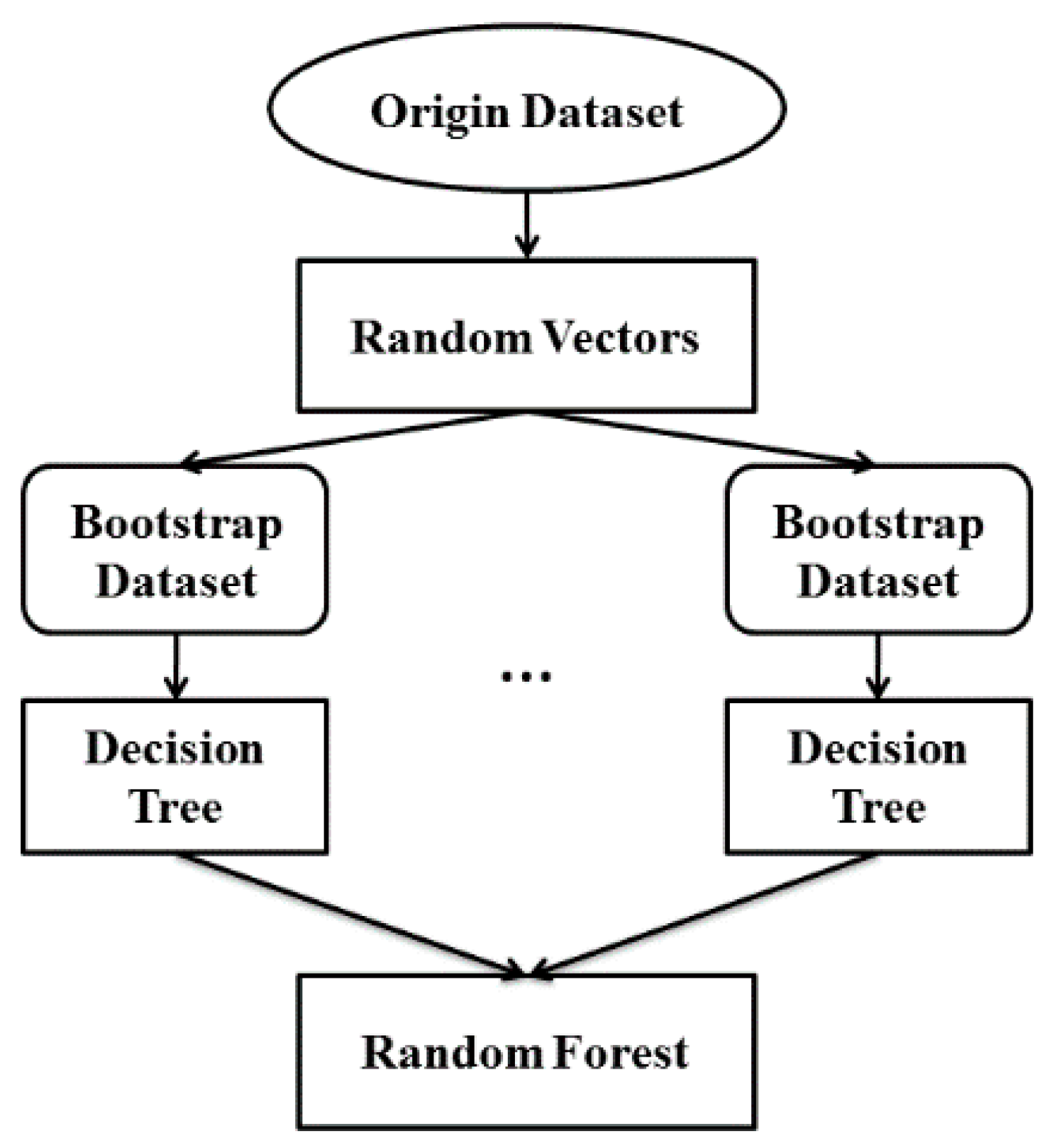
2.4.2. Random Forests
- Generate the training set of each decision tree in random forest. For the subword i, extract sample with Ni times of this subword in the origin training set at random with replacement. The final result will be the training set of the decision tree used to train the parameter of the decision tree by the rules previously described.
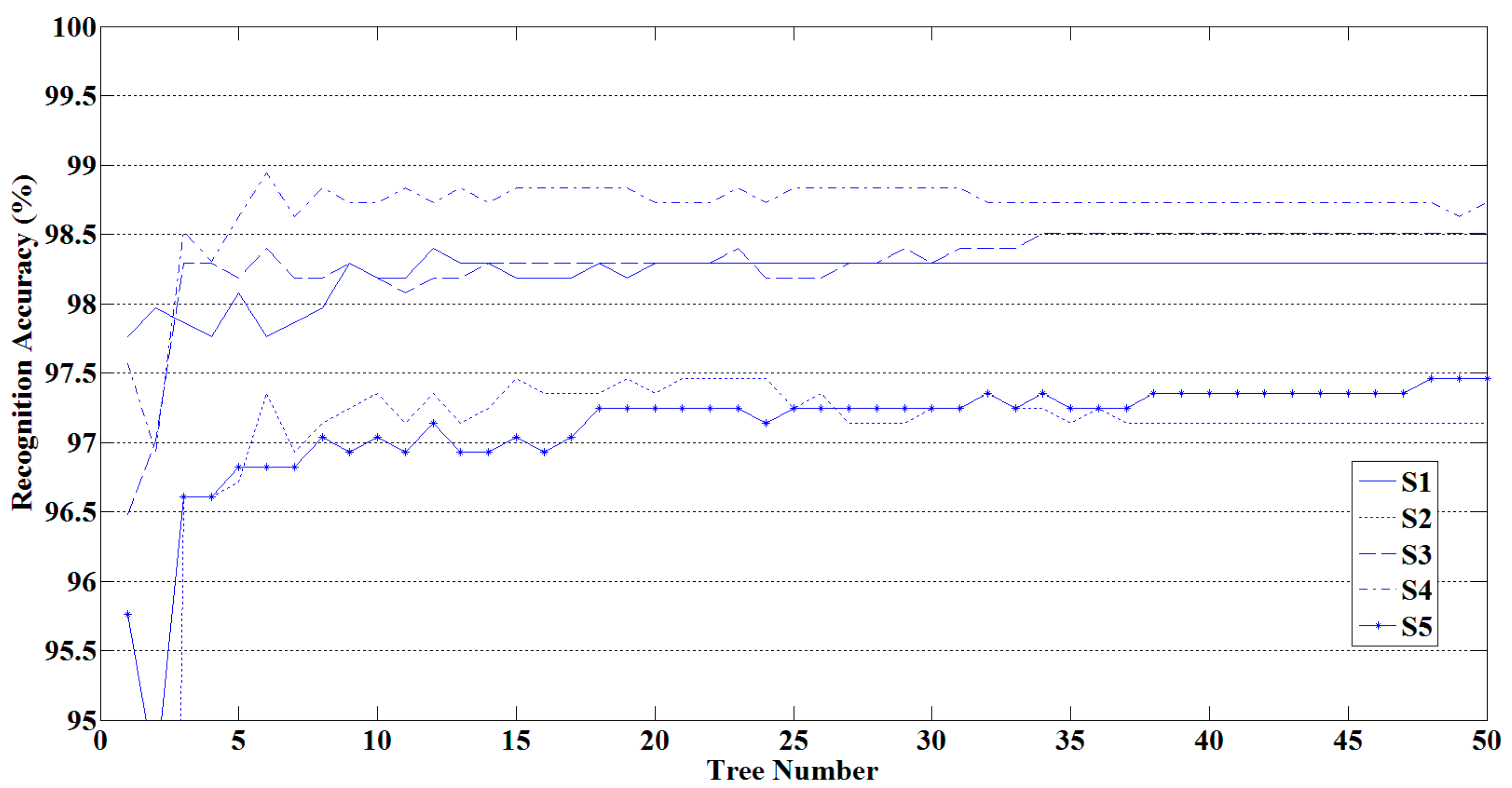
- Determine whether the number of decision trees meet the preset scale of random forest, if not, repeat steps above. The preset scale was determined by calculating the recognition rate under different scales of random forest. The smallest scale which best ensured accuracy greater than 90% was selected. In the testing phase, each decision tree in the random forest generated a recognition result, and the final result of the random forest was considered to be the most frequent class in the recognition results of all decision trees.
3. Results and Analysis
3.1. Subwords Recognition Results
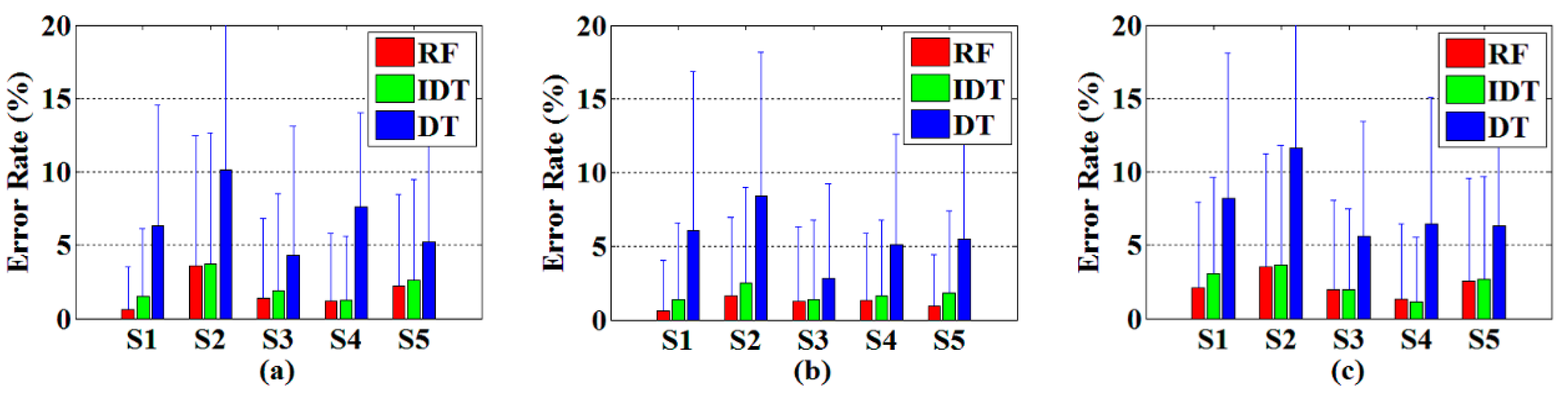
3.1.1. Recognition Results of the Improved Decision Tree

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S1 | S2 | S3 | S4 | S5 | Mean ± Standard Deviation | ||
|---|---|---|---|---|---|---|---|
| One- or Two-handed | 99.79% | 99.55% | 99.40% | 100% | 99.51% | 99.65% ± 0.24% | |
| Hand Orientation | 98.89% | 97.67% | 98.74% | 98.99% | 98.07% | 98.47% ± 0.57% | |
| Multi-stream HMM | IDT | 98.63% | 97.36% | 98.31% | 98.36% | 97.96% | 98.12% ± 0.49% |
| DT | 95.79% | 94.78% | 97.32% | 97.04% | 95.15% | 96.02% ± 1.13% | |
3.1.2. The Influence of the Scale of Random Forest on Recognition Results

3.1.3. Recognition Results of Random Forest-Based Method

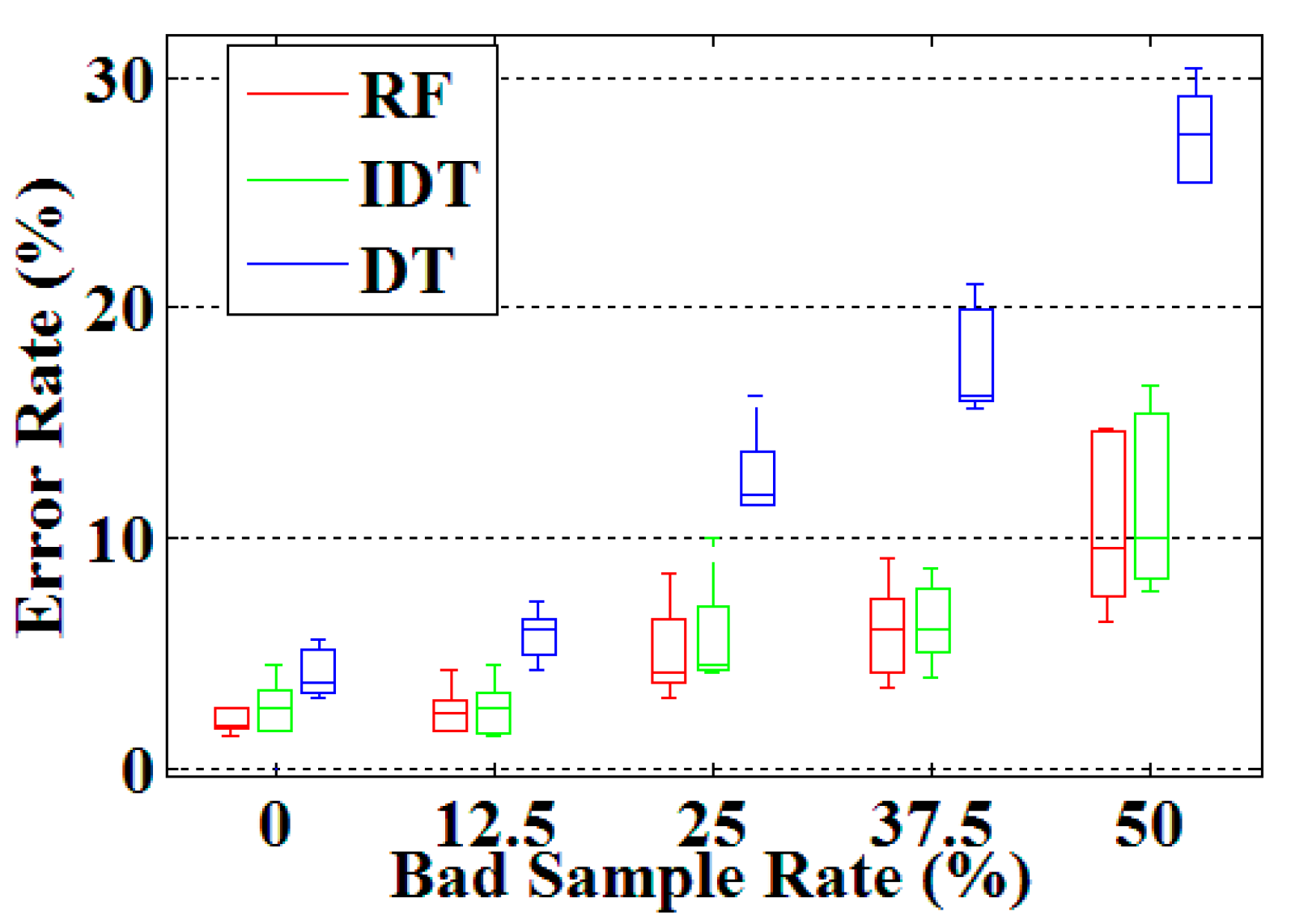
3.2. Robustness Testing Results

4. Discussion and Future Work
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Li, Y.; Chen, X.; Zhang, X.; Wang, K.; Wang, Z.J. A sign-component-based framework for Chinese sign language recognition using accelerometer and sEMG data. IEEE Trans. Biomed. Eng. 2012, 59, 2695–2704. [Google Scholar] [PubMed]
- Ding, L.; Martinez, A.M. Modelling and recognition of the linguistic components in American sign language. Image Vis. Comput. 2009, 27, 1826–1844. [Google Scholar] [CrossRef] [PubMed]
- Trigueiros, P.; Ribeiro, F.; Reis, L.P. Vision-based Portuguese sign language recognition system. Adv. Intell. Syst. 2014, 275, 605–617. [Google Scholar]
- Fang, G.; Gao, W.; Zhao, D. Large vocabulary sign language recognition based on fuzzy decision trees. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2004, 34, 305–314. [Google Scholar] [CrossRef]
- Doliotis, P.; Athitsos, V.; Kosmopoulos, D.; Perantonis, S. Hand Shape and 3D Pose Estimation Using Depth Data From a Single Cluttered Frame. In Advances in Visual Computing—8th International Symposium, ISVC 2012, Rethymnon, Crete, Greece, 16–18 July 2012, Revised Selected Papers, Part I; Springer Berlin Heidelberg: Berlin, Germany, 2012; pp. 148–158. [Google Scholar]
- Li, Y.; Chen, X.; Tian, J.; Zhang, X.; Wang, K.; Yang, J. Automatic recognition of sign language subwords based on portable accelerometer and EMG sensors. In Proceedings of the 2010 International Conference on Multimodal Interfaces and the Workshop on Machine Learning for Multimodal Interaction, Beijing, China, 8–10 November 2010; p. 17.
- Grobel, K.; Assan, M. Isolated sign language recognition using hidden Markov models. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Orlando, FL, USA, 12–15 October 1997; pp. 162–167.
- Fels, S.S.; Hinton, G.E. Glove-talk: A neural network interface between a data-glove and a speech synthesizer. IEEE Trans. Neural Netw. 1993, 4, 2–8. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Gao, W.; Shan, S. An approach based on phonemes to large vocabulary Chinese sign language recognition. In Proceedings of the 5th IEEE International Conference on Automatic Face and Gesture Recognition, Washington, WA, USA, 20–21 May 2002; pp. 411–416.
- Gao, W.; Fang, G.; Zhao, D.; Chen, Y. Transition movement models for large vocabulary continuous sign language recognition. In Proceedings of the 6th IEEE International Conference on Automatic Face and Gesture Recognition, Seoul, Korea, 17–19 May 2004; pp. 553–558.
- Fang, G.; Gao, W.; Zhao, D. Large-vocabulary continuous sign language recognition based on transition-movement models. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2007, 37, 1–9. [Google Scholar] [CrossRef]
- Roy, S.H.; Cheng, M.S.; Chang, S.-S.; Moore, J.; de Luca, G.; Nawab, S.H.; de Luca, C.J. A combined sEMG and accelerometer system for monitoring functional activity in stroke. IEEE Trans. Neural Sys. Rehabil. Eng. 2009, 17, 585–594. [Google Scholar] [CrossRef] [PubMed]
- Oskoei, M.A.; Hu, H. Myoelectric control systems—A survey. Biomed. Signal Process. Control 2007, 2, 275–294. [Google Scholar] [CrossRef]
- Kim, J.; Wagner, J.; Rehm, M.; André, E. Bi-channel sensor fusion for automatic sign language recognition. In Proceedings of the 8th IEEE International Conference on Automatic Face & Gesture Recognition, Amsterdam, The Netherlands, 17–19 September 2008; pp. 1–6.
- Kosmidou, V.E.; Hadjileontiadis, L.J. Sign language recognition using intrinsic-mode sample entropy on sEMG and accelerometer data. IEEE Trans. Biomed. Eng. 2009, 56, 2879–2890. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Tian, Z.; Sun, L.; Estevez, L.; Jafari, R. Real-time American sign language recognition using wrist-worn motion and surface EMG sensors. In Proceedings of the IEEE 12th International Conference on Wearable and Implantable Body Sensor Networks (BSN), Cambridge, MA, USA, 9–12 June 2015; pp. 1–6.
- Lin, K.; Wu, C.; Huang, X.; Ding, Q.; Gao, X. A robust gesture recognition algorithm based on surface EMG. In Proceedings of the 7th International Conference on Advanced Computational Intelligence (ICACI), Wuyi, China, 27–29 March 2015; pp. 131–136.
- Chen, X.; Zhang, X.; Zhao, Z.-Y.; Yang, J.-H.; Lantz, V.; Wang, K.-Q. Hand gesture recognition research based on surface EMG sensors and 2D-accelerometers. In Proceedings of the 11th IEEE International Symposium on Wearable Computers, Boston, MA, USA, 11–13 October 2007; pp. 11–14.
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random forests for land cover classification. Pattern Recogn. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Bernard, S.; Adam, S.; Heutte, L. Using random forests for handwritten digit recognition. In Proceedings of the 9th International Conference on Document Analysis and Recognition, Parana, Brazil, 23–26 September 2007; pp. 1043–1047.
- Zhang, X.; Chen, X.; Li, Y.; Lantz, V.; Wang, K.; Yang, J. A framework for hand gesture recognition based on accelerometer and EMG sensors. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2011, 41, 1064–1076. [Google Scholar] [CrossRef]
- Department for Education and Employment, China Disabled Persons’ Federation; China Association of the Deaf. Chinese Sign Language, 2nd ed.; HuaXia Press: Beijing, China, 2003. [Google Scholar]
- Li, X.; Zhou, P.; Aruin, A.S. Teager-Kaiser energy operation of surface EMG improves muscle activity onset detection. Ann. Biomed. Eng. 2007, 35, 1532–1538. [Google Scholar] [CrossRef] [PubMed]
- Phinyomark, A.; Hirunviriya, S.; Nuidod, A.; Phukpattaranont, P.; Limsakul, C. Evaluation of EMG Feature Extraction for Movement Control of Upper Limb Prostheses Based on Class Separation Index. In 5th Kuala Lumpur International Conference on Biomedical Engineering 2011—(BIOMED 2011) 20–23 June 2011, Kuala Lumpur, Malaysia; Springer Berlin Heidelberg: Berlin, Germany, 2011; pp. 750–754. [Google Scholar]
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, R.; Chen, X.; Cao, S.; Zhang, X. Random Forest-Based Recognition of Isolated Sign Language Subwords Using Data from Accelerometers and Surface Electromyographic Sensors. Sensors 2016, 16, 100. https://doi.org/10.3390/s16010100
Su R, Chen X, Cao S, Zhang X. Random Forest-Based Recognition of Isolated Sign Language Subwords Using Data from Accelerometers and Surface Electromyographic Sensors. Sensors. 2016; 16(1):100. https://doi.org/10.3390/s16010100
Chicago/Turabian StyleSu, Ruiliang, Xiang Chen, Shuai Cao, and Xu Zhang. 2016. "Random Forest-Based Recognition of Isolated Sign Language Subwords Using Data from Accelerometers and Surface Electromyographic Sensors" Sensors 16, no. 1: 100. https://doi.org/10.3390/s16010100
APA StyleSu, R., Chen, X., Cao, S., & Zhang, X. (2016). Random Forest-Based Recognition of Isolated Sign Language Subwords Using Data from Accelerometers and Surface Electromyographic Sensors. Sensors, 16(1), 100. https://doi.org/10.3390/s16010100