
An Energy-Efficient Skyline Query for Massively Multidimensional Sensing Data


Abstract
:1. Introduction
- We design a dynamic filter tuple and a local cutting tuple, propose a calculation method of the two types of filter tuples and analyse the effectiveness of the cutting tuple in depth.
- Based on the above dynamic filter tuples and the local cutting tuple, we propose E2Sky, a query recovery mechanism, which adopts node cut and tuple cut inside the node algorithm.
- We design detailed performance evaluation experiments. The experimental results show that the E2Sky algorithm reduces the transmission consumption of the skyline query recovery greatly, with a small calculation overhead.
2. Related Work
3. Problem Definition


4. Query Result Collection Algorithms in E2Sky
4.1. Initialization of the Query Result Collection
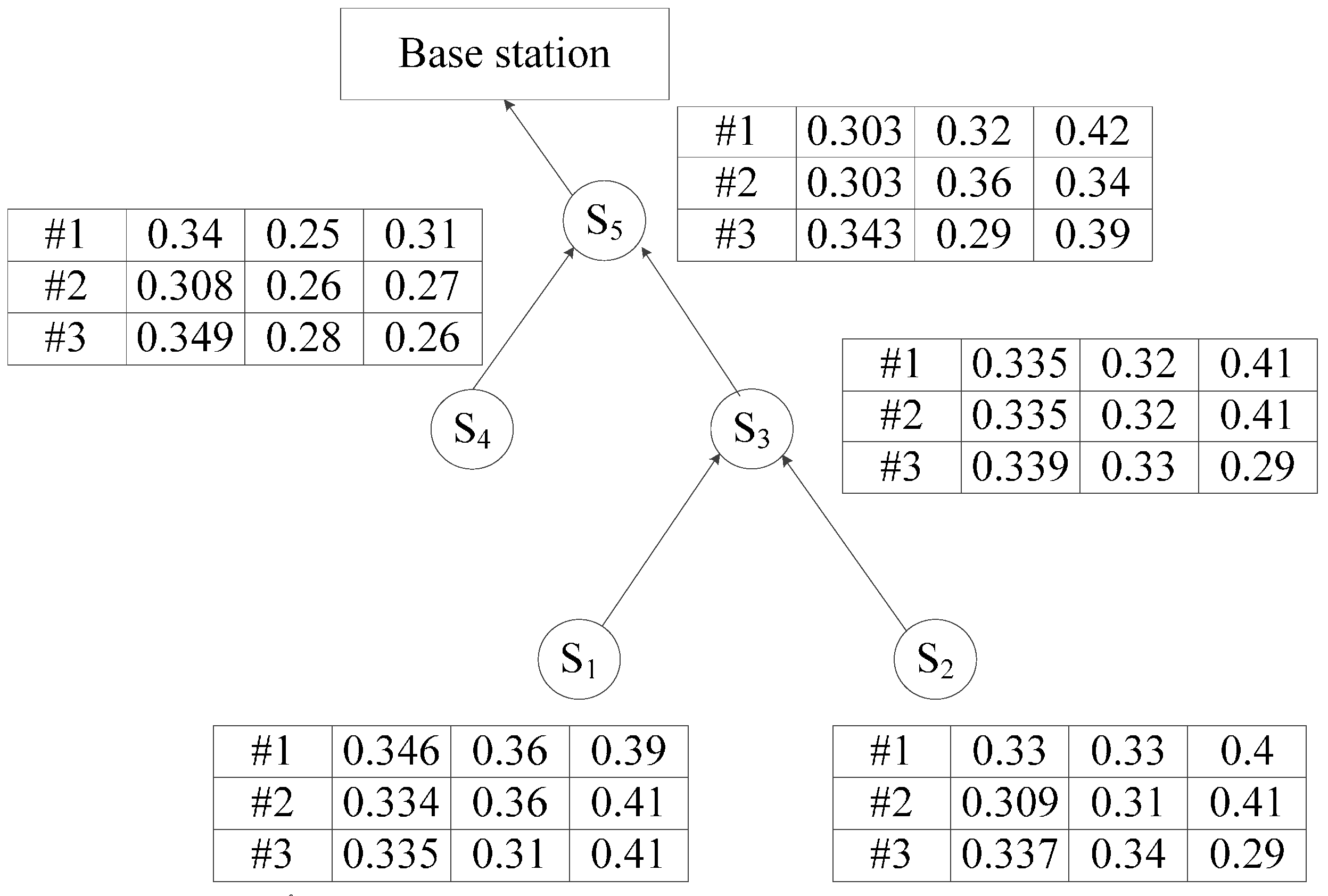
4.1.1. Design of the Data Structure
Query Data Tuple

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Node Label | Attribute Values | Maximum Value | Minimum Value | Attribute Space |
|---|---|---|---|---|
| id | NLA(a,r) | max | min | reg |
Dynamic Filter Tuple
| Node Label | Minimum Value of M | Minimum Value of N | Minimum Value of R |
|---|---|---|---|
| id | max_m | Min_m | reg_m |
4.1.2. Initialization of the Query Result Collection Algorithm
| Algorithm 1 Initialization of the Query Result Collection |
| Input: original node set V = {S1, S2, ..., Sn}, the original data collected by node Si(i = 0, 1, ..., n) Output:TB_qdata table, TB_Sfilters table 1: for ∀ Si ∈ V do { 2: Si normalizes the collected original data 3: Compute and add max, min, reg attributes to form qdata 4: Si sends its qdata tuple to its father node Si+1 5: Si+1 gathers the collected qdata to form the TB_qdata table 6: Fetch the minimum value of max, the minimum value of the attribute min, and the minimum value of the attribute reg of every tuple in the Si+1. TB_qdata table to form the tuple Si+1.filter_tuple 7: Si+1 sends each filter_tuple tuple to its father node Si+2 to form the TB_Sfilters table 8: end for |
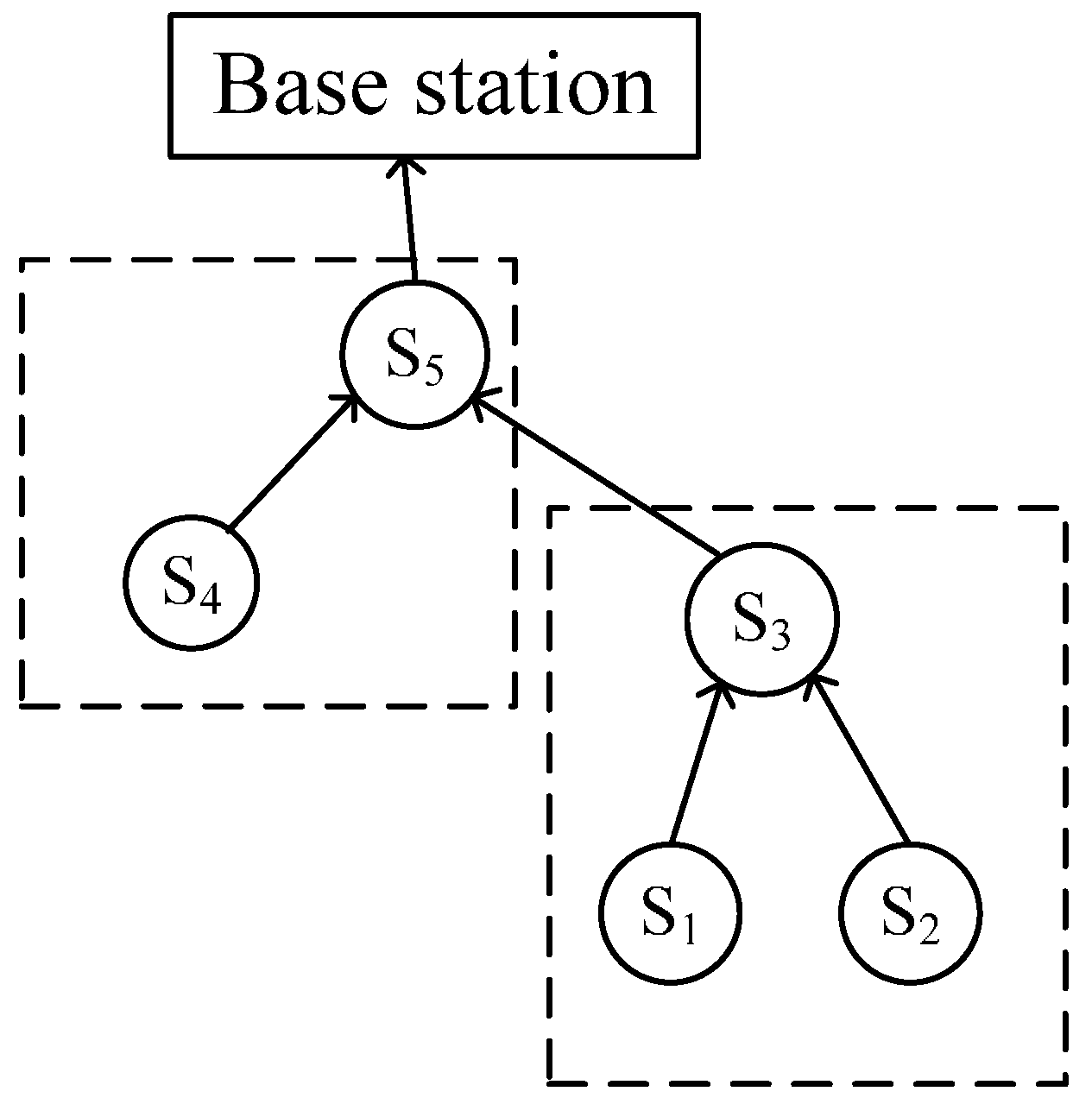
4.2. Node Cut
4.2.1. Node Domination Relation Theorems
4.2.2. Node Cut Algorithm
| Algorithm 2 Node Cut |
| Input: The set M of nodes that own the TB_Sfilters table. Output: The certain node set Q={S1, S2, ..., Sm} and a new query route. 1: for ∀ Si∈M do // From bottom to top, the sensor conducts the algorithm to the node in M on the query route in turn 2: while | UQ |>1 do // the number of nodes in UQ is greater than 1 3: { 4: According to Theorem 3, the sensor finds the node Sp that has the minimum min_m value in the Si.TB_Sfilters table of UQ and moves it from UQ to Q 5: According to Theorem 4, the sensor compares Sp.max_m with ∀ Sn.min_m(Sn ∈ UQ), and the algorithm deletes the node that is dominated by the node Sp in UQ 6: } 7: if Sq.max_m<Sl.min_m then //now, Sq is the latest node put into Q, and Sl is the last node in UQ 8: deletes Sl from UQ 9: else moves Sl from UQ to Q 10: end if 11: The sensor deletes the nodes that do not belong to Q in the query route // generates a new query route 12: end for |
4.3. Tuple Cut Inside the Node
4.3.1. Extraction of Cutting Tuples
| Node Label | Smallest Attribute Space |
|---|---|
| id | reg_ms |
4.3.2. Cutting the Tuples Inside the Node
| Algorithm 3 Cutting the Tuples Inside the Node |
| Input: The set M of the nodes that own the TB_Sfilters table Output: skyline data result 1: for ∀ Si∈M do // From bottom to top, the sensor conducts the algorithm to the nodes in M on the query route in turn 2: create bcut_tuple by using Si.TB_Sfilters 3: if id-value of bcut_tuple is equal to Si.id-value then 4: create cut_tuple by using Si. TB_qdatas and cut data in Si.TB_qdatas. 5: Si sends cut_tuple to its child nodes on the query route 6: else 7: Si sends bcut_tuple to the node Sj with the same id. Here, Sj is the child node of Si 8: create cut_tuple by using Sj. 9: Sj sends cut_tuple to Si 10: Si sends cut_tuple to the other child nodes on the query route in turn, except for Sj. 11: end if 12: the sensor received cut_tuple to conduct a local cut for the data in the TB_qdata table and deletes the non_skyline data. 13: Then, the sensor sends the skyline data up to its father node Si. 14: if Si is one of the nodes of the query route, then 15: the skyline data received combine with the local data and send it to the father node 16: else 17: send the skyline data that were received to the father node 18: endif 19: end for |
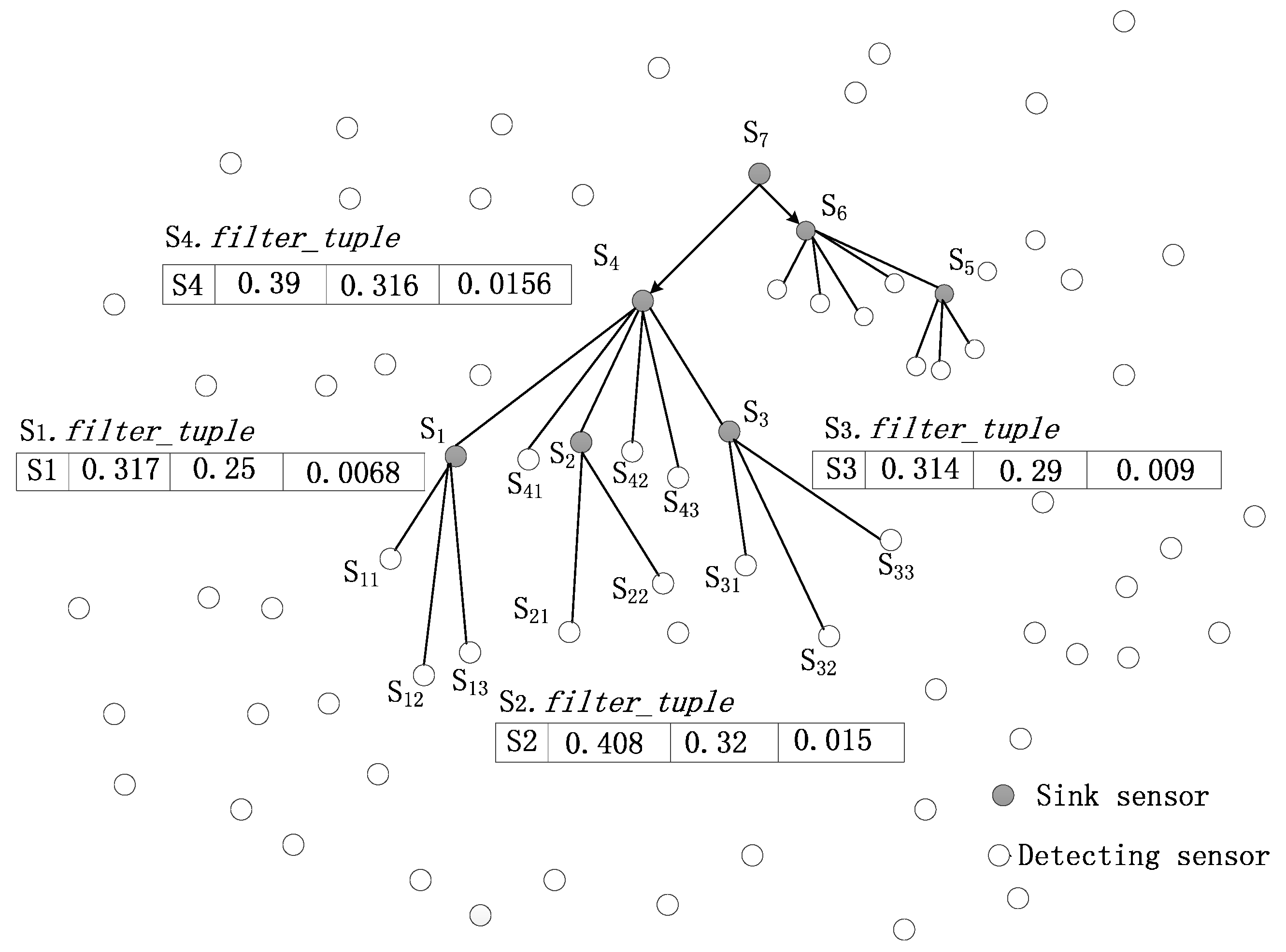
4.4. E2SQ Query Analysis and Illustrations

| Id | Temperature | Humidity | Wind_Speed | Wire_Angle | Max | Min | Reg |
|---|---|---|---|---|---|---|---|
| S11 | 0.317 | 0.25 | 0.31 | 0.313 | 0.317 | 0.25 | 0.0077 |
| S12 | 0.328 | 0.26 | 0.27 | 0.2939 | 0.328 | 0.26 | 0.0068 |
| S13 | 0.326 | 0.32 | 0.33 | 0.315 | 0.33 | 0.315 | 0.011 |
| Id | Temperature | Humidity | Wind_Speed | Wire_Angle | Max | Min | Reg |
|---|---|---|---|---|---|---|---|
| S21 | 0.315 | 0.32 | 0.41 | 0.4 | 0.41 | 0.32 | 0.018 |
| S22 | 0.346 | 0.33 | 0.33 | 0.408 | 0.408 | 0.33 | 0.015 |
| Id | Temperature | Humidity | Wind_Speed | Wire_Angle | Max | Min | Reg |
|---|---|---|---|---|---|---|---|
| S31 | 0.303 | 0.32 | 0.33 | 0.353 | 0.353 | 0.303 | 0.011 |
| S32 | 0.309 | 0.31 | 0.309 | 0.314 | 0.314 | 0.309 | 0.009 |
| S33 | 0.343 | 0.29 | 0.41 | 0.383 | 0.41 | 0.29 | 0.016 |
| Id | Temperature | Humidity | Wind_Speed | WIRE_ANGLE | Max | Min | Reg |
|---|---|---|---|---|---|---|---|
| S1 | 0.338 | 0.35 | 0.4 | 0.335 | 0.4 | 0.335 | 0.0159 |
| S2 | 0.337 | 0.34 | 0.39 | 0.365 | 0.39 | 0.337 | 0.0163 |
| S3 | 0.316 | 0.35 | 0.4 | 0.353 | 0.4 | 0.316 | 0.0156 |
| S41 | 0.334 | 0.36 | 0.41 | 0.358 | 0.41 | 0.334 | 0.0176 |
| S42 | 0.334 | 0.36 | 0.41 | 0.358 | 0.41 | 0.334 | 0.0176 |
| S43 | 0.346 | 0.36 | 0.46 | 0.383 | 0.46 | 0.346 | 0.0219 |
| Id | Max_M | Min_M | Reg_M |
|---|---|---|---|
| S1 | 0.317 | 0.25 | 0.0068 |
| S2 | 0.408 | 0.32 | 0.015 |
| S3 | 0.314 | 0.29 | 0.009 |
| S4 | 0.39 | 0.316 | 0.0156 |
5. Performance Evaluation
5.1. Experimental Setting
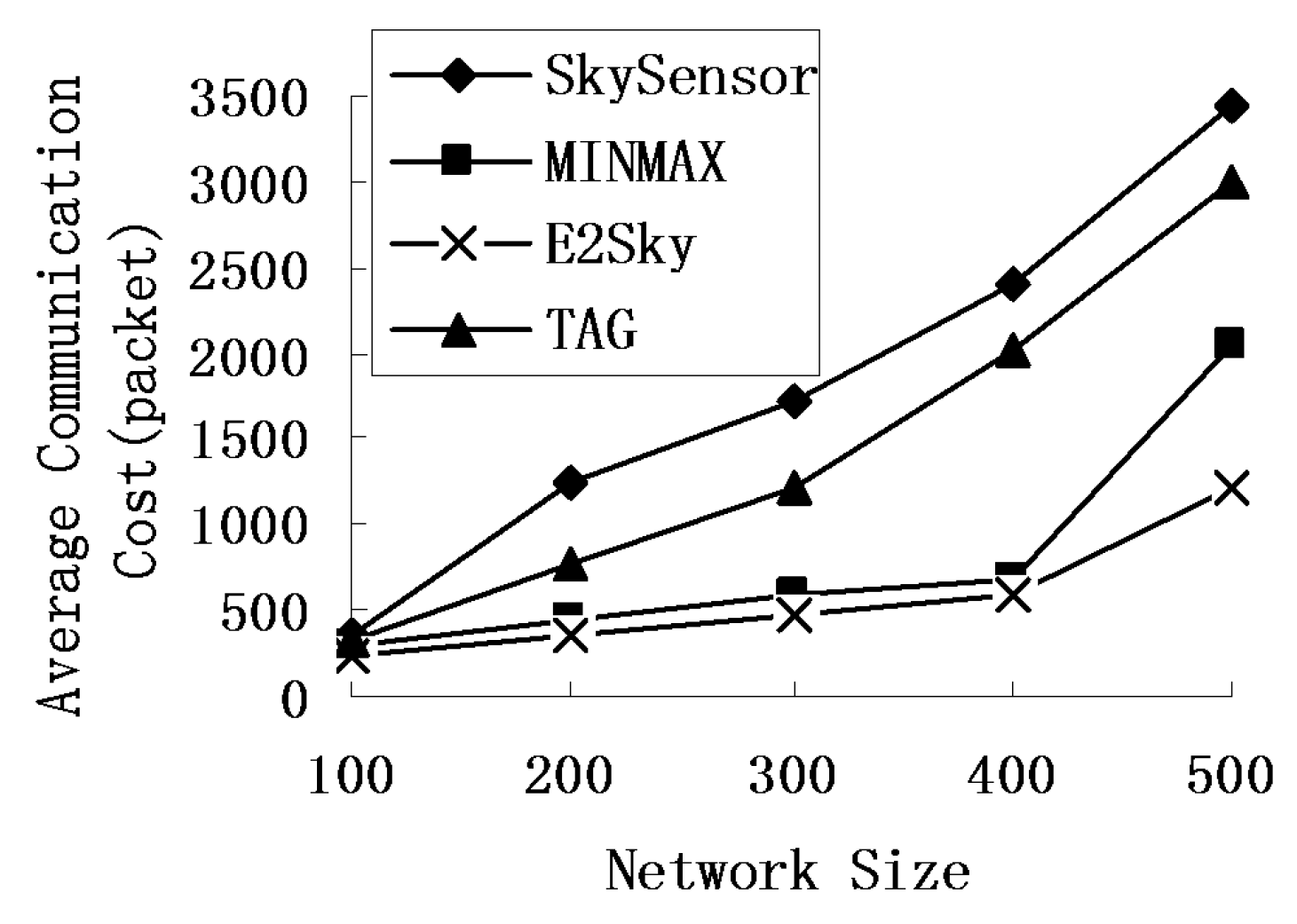
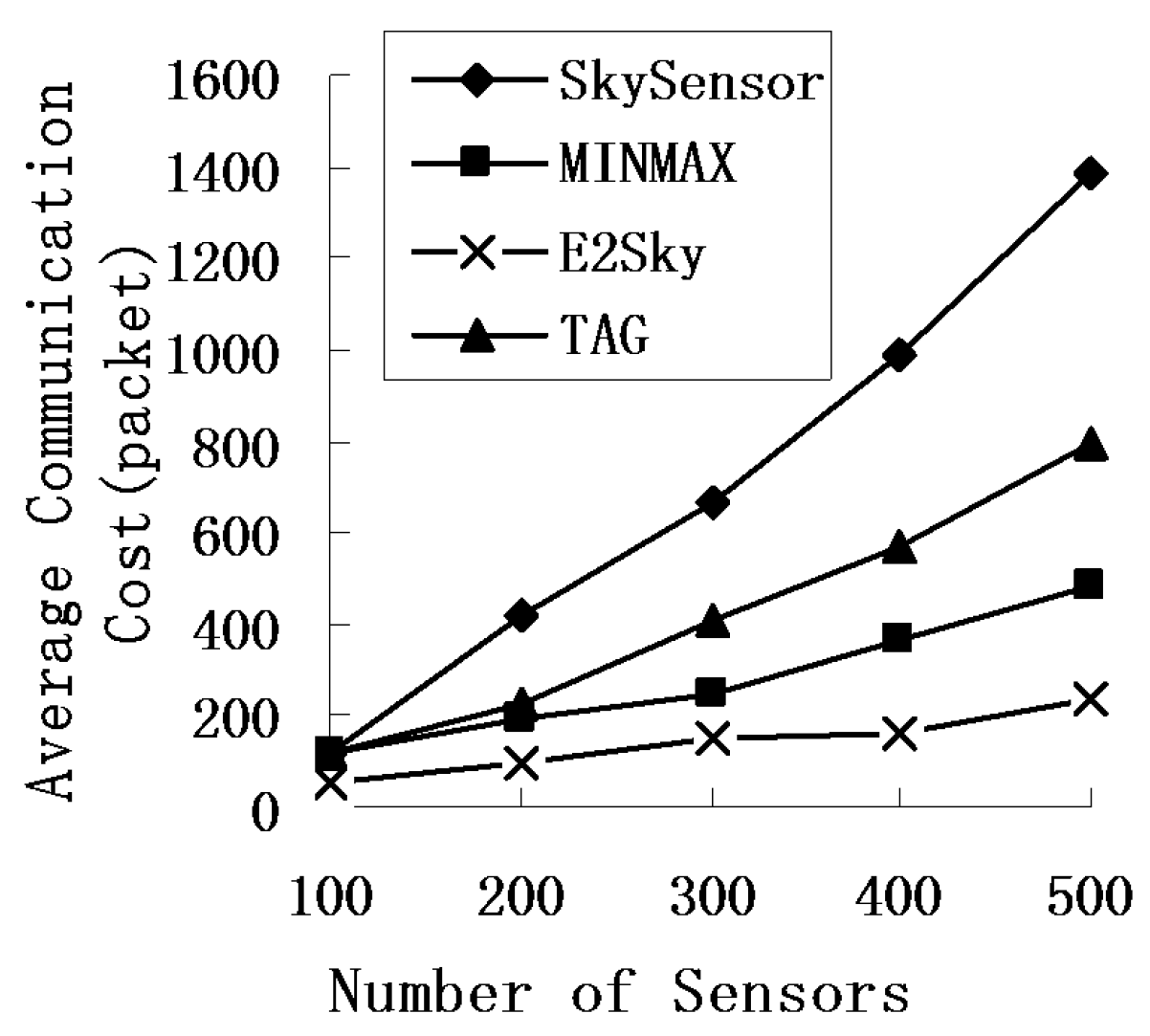
5.2. Average Communications Cost



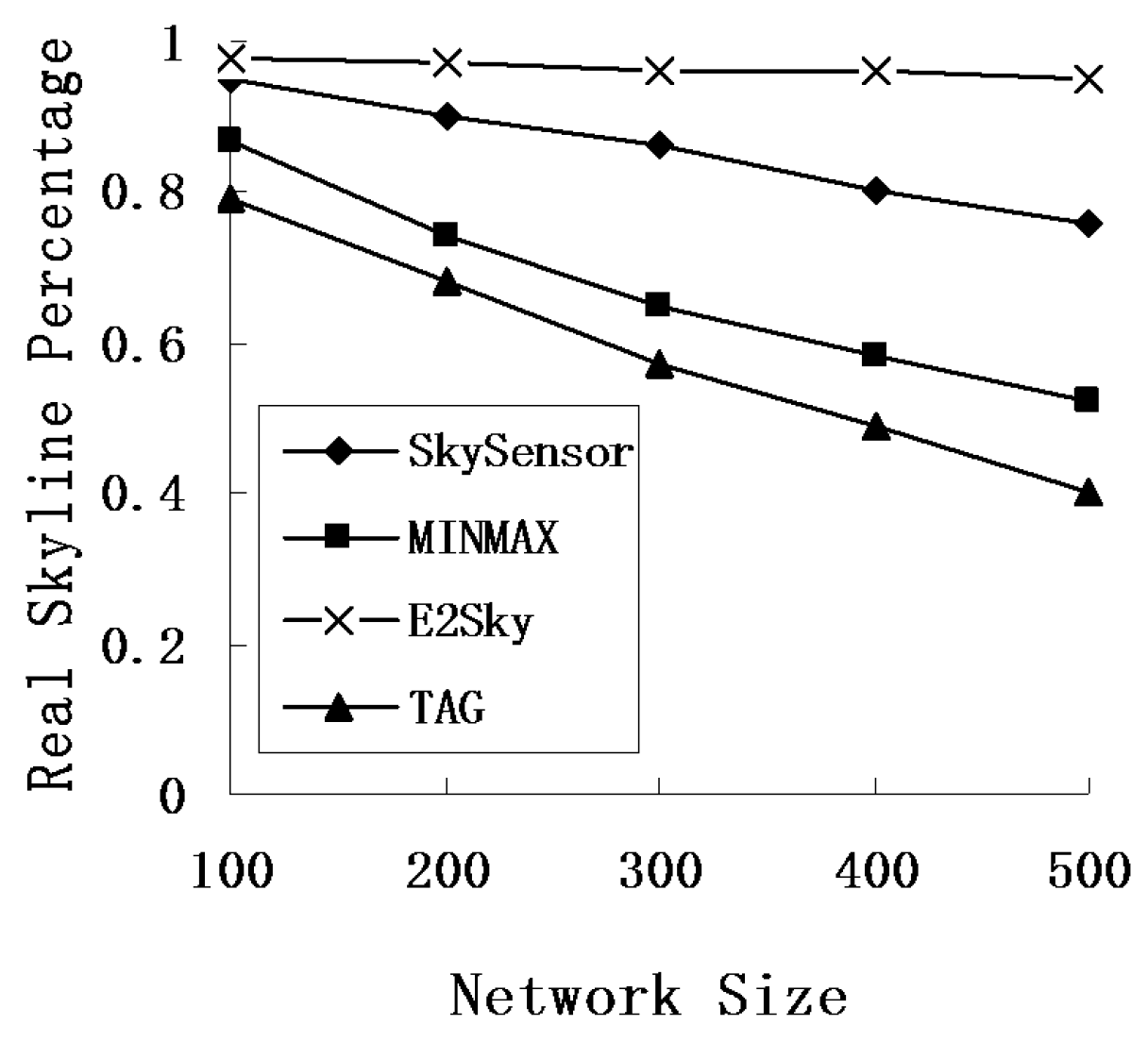
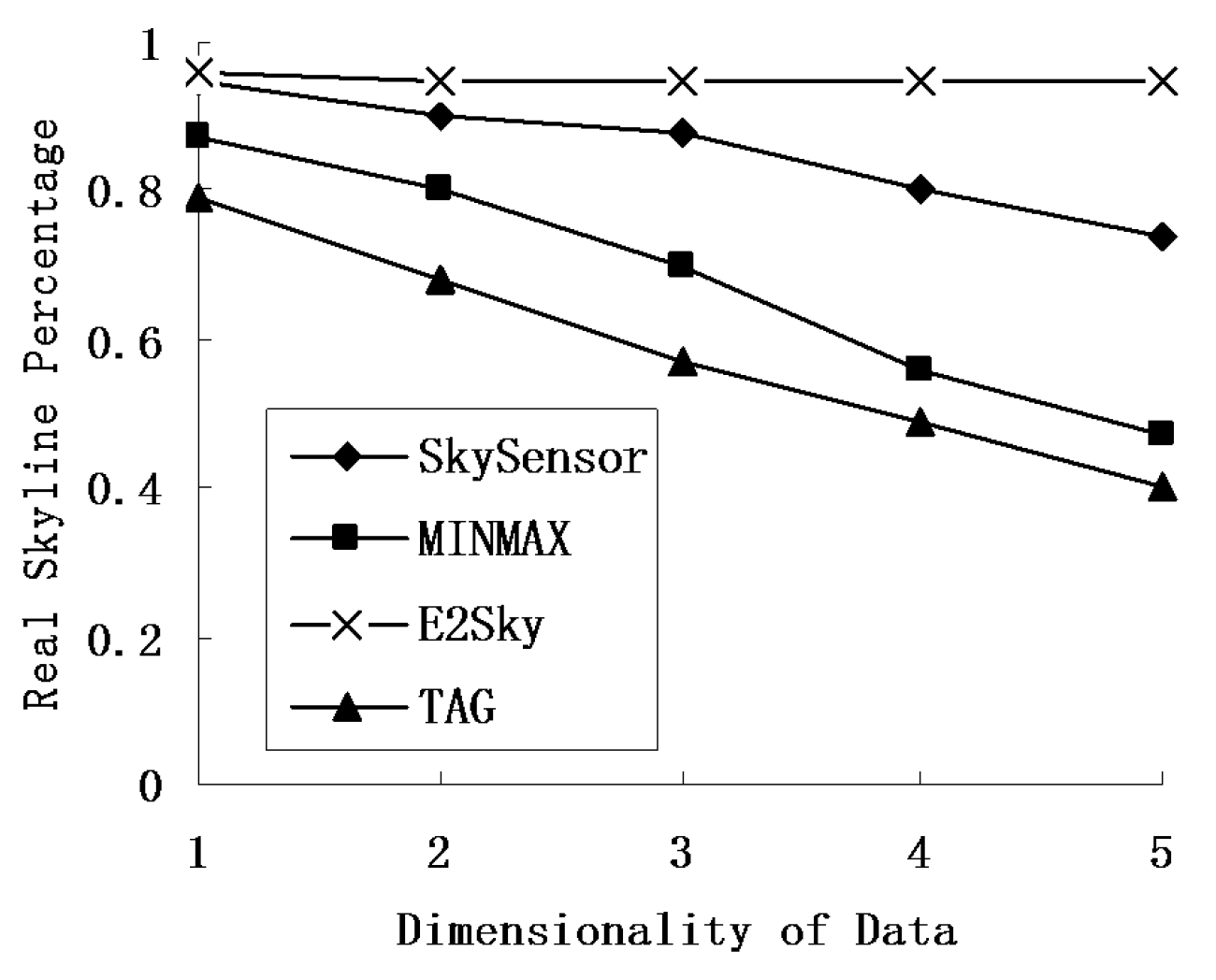
5.3. Accuracy of the Skyline Result



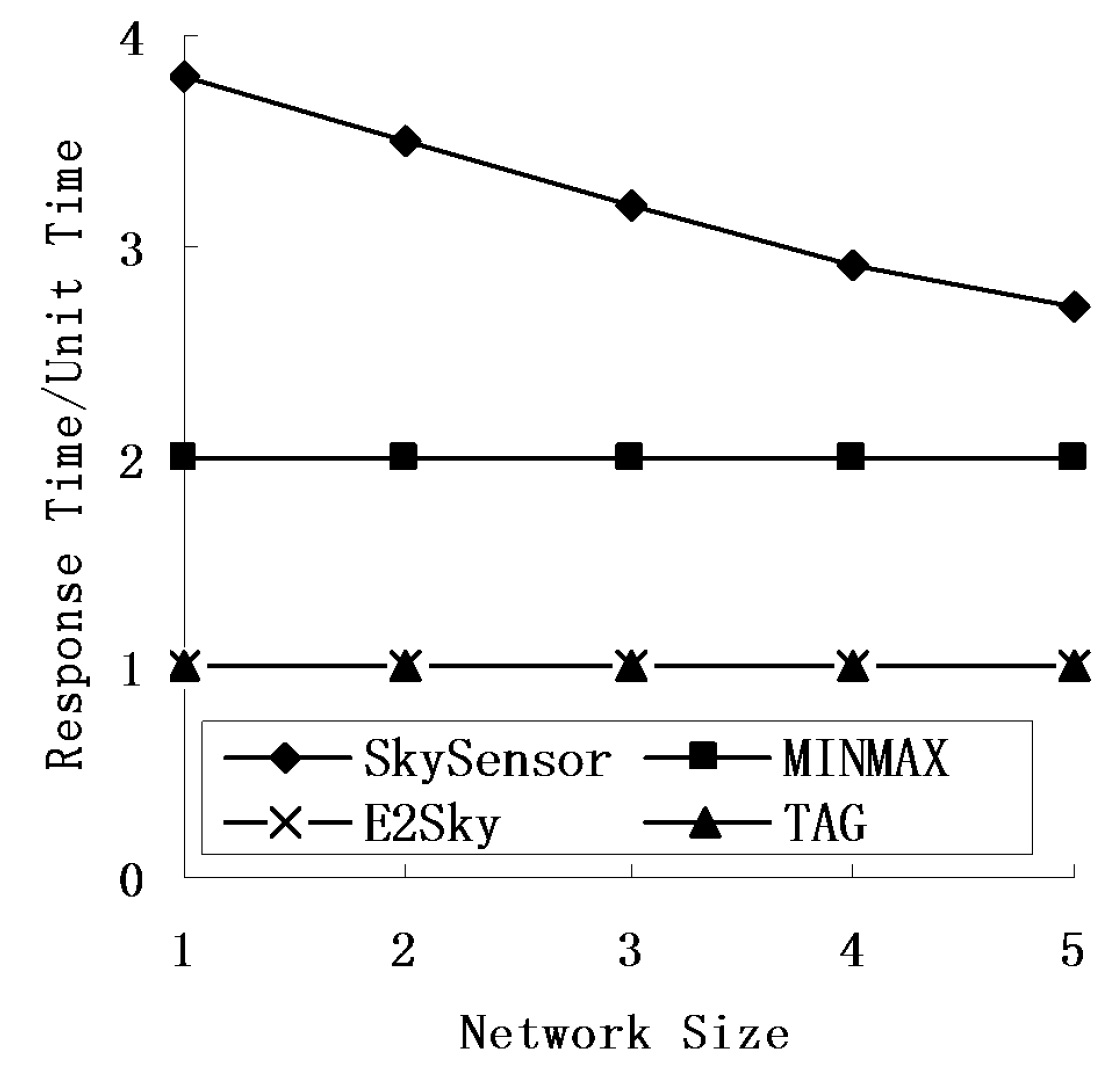
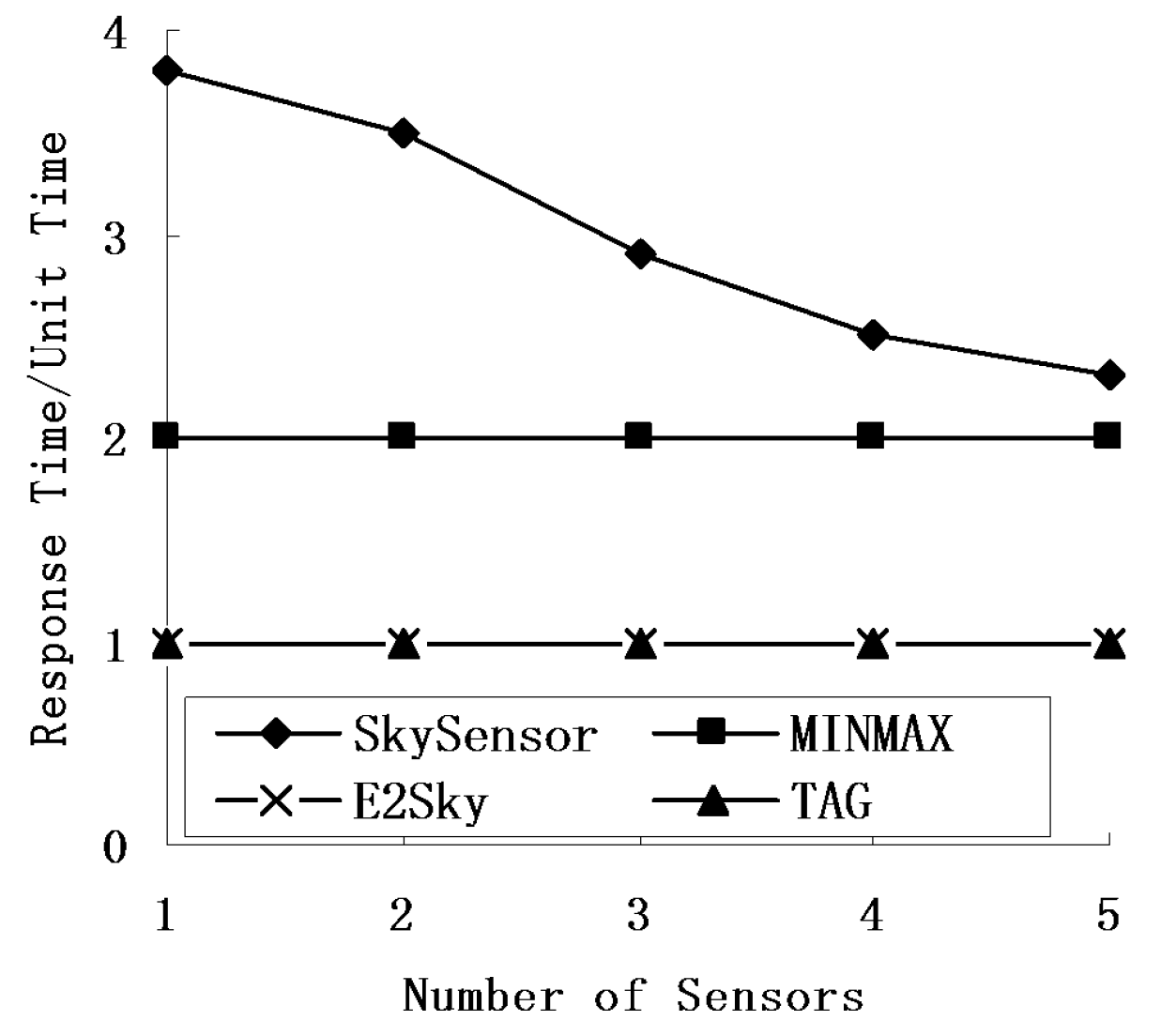
5.4. Response Time



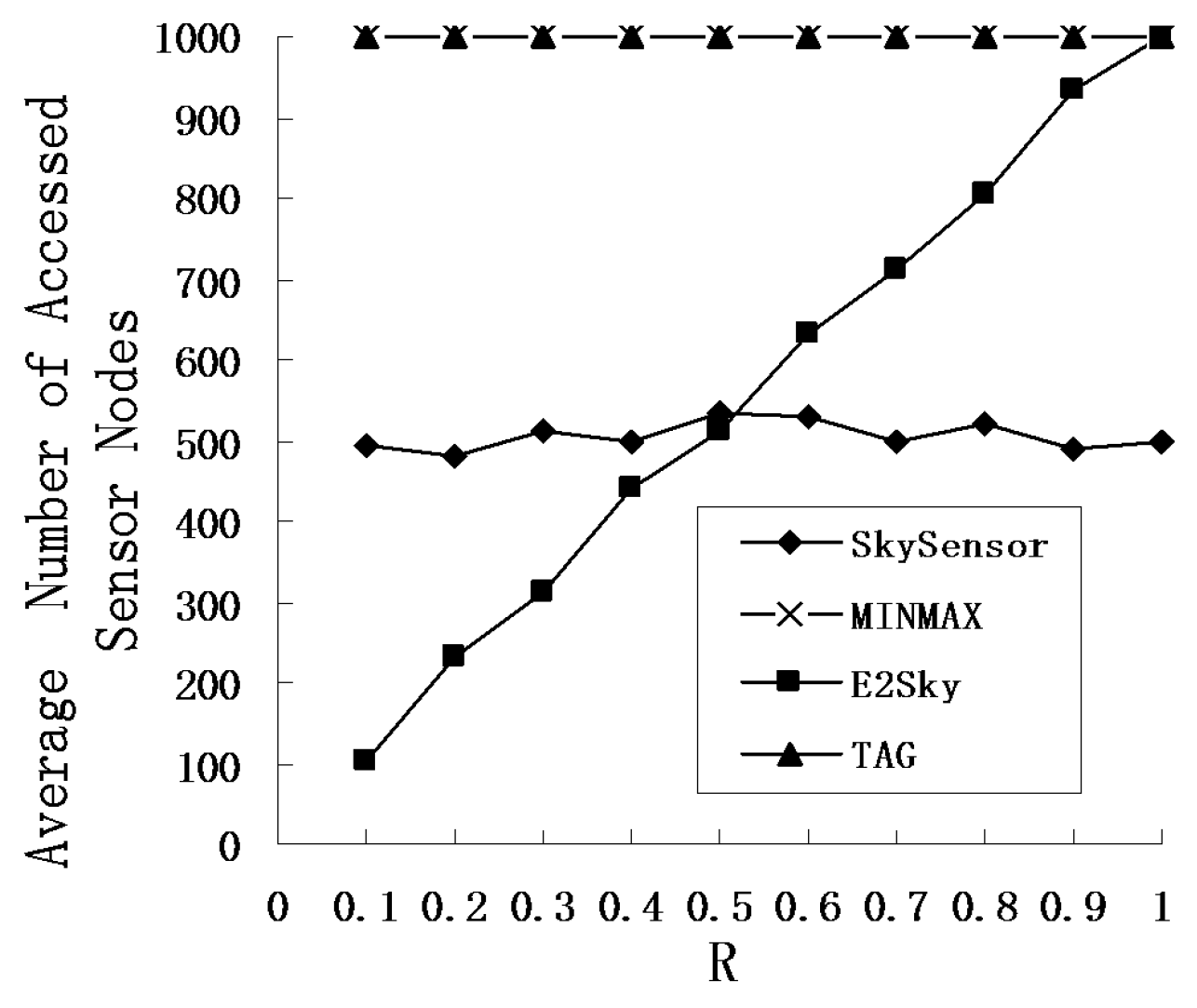
5.5. Average Number of Accessed Sensor Nodes

6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- VGungor, C.; Lu, B.; Hancke, G.P. Opportunities and Challenges of Wireless Sensor Networks in Smart Grid. IEEE Trans. Ind. Electron. 2010, 57, 3557–3564. [Google Scholar] [CrossRef]
- McGranaghan, M.; Deaver, B. Sensors and Monitoring Challenges in the Smart Grid. In Proceedings of the Future of Instrumentation International Workshop (FIIW), Gatlinburg, TN, USA, 8–9 October 2012; pp. 1–4.
- Wei, W.; Yang, X.L.; Shen, P.Y.; Zhou, B. Holes detection in anisotropic sensornets: Topological methods. Int. J. Distrib. Sens. Netw. 2012. [Google Scholar] [CrossRef]
- Wang, G.; Xin, J.; Chen, L.; Liu, Y. Energy-efficient reverse skyline query processing over wireless sensor networks. IEEE Trans. Knowl. Data Eng. 2012, 24, 1259–1275. [Google Scholar] [CrossRef]
- Moslehi, K.; Kumar, R. Smart Grid-A Reliability Perspective. In Proceedings of the Innovative Smart Grid Technologies (ISGT), Gaithersburg, MA, USA, 19–21 January 2010; pp. 1–8.
- Gungor, V.; Sahin, D.; Kocak, T.; Ergut, S.; Buccella, C.; Cecati, C.; Hancke, G. A survey on smart grid potential applications and communication requirements. IEEE Trans. Ind. Inf. 2012, 9, 28–42. [Google Scholar] [CrossRef]
- Singh, A. Smart Grid Sensor. Int. J. Eng. Res. Appl. 2012, 9, 28–42. [Google Scholar]
- Hu, Y.L.; Sun, Y.F.; Yin, B.C. Information Sensing and Interaction Technology in Internet of Things. Chin. J. Comput. 2012, 35, 1147–1163. [Google Scholar] [CrossRef]
- Poovendran, R. Cyber-Physical Systems: Close Encounters between Two Parallel Worlds. IEEE Proc. 2010, 98, 1363–1366. [Google Scholar] [CrossRef]
- Lee, E.A. Cyber Physical Systems: Design Challenges. In Proceedings of the 11th IEEE Symposium on Object Oriented Real-Time Distributed Computing (ISORC), Orlando, FL, USA, 5–7 May 2008; pp. 363–369.
- Zou, Z.; Hu, C.; Zhang, F.; Zhao, H.; Shen, S. WSNs Data Acquisition by Combining Hierarchical Routing Method and Compressive Sensing. Sensors 2014, 14, 16766–16784. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Deng, Q.; Liu, W.; Song, B. A query approach of supporting variable physical window in large-scale smart grid. In Proceedings of the 15th International Conference on Web-Age Information Management, Macau, China, 16–18 June 2014; pp. 311–322.
- Stokes, A.B.; Fernandes, A.; Paton, N.W. Adapting to Node Failure in Sensor Network Query Processing. Big Data; Springer: Berlin Heidelberg, Germany, 2013; pp. 33–47. [Google Scholar]
- Borzsonyi, S.; Stocker, K.; Kossmann, D. The Skyline Operator. In Proceedings of the 17th International Conference on Data Engineering, Washington, DC, USA, 2–6 April 2001; pp. 421–430.
- Chomicki, J.; Godfrey, P.; Gryz, J. Skyline with presorting. In Proceeding of the ICDE, Bangalore, India, 8 March 2003; pp. 717–816.
- Tan, K.L.; Eng, P.K.; Ooi, B.C. Efficient Progressive Skyline Computation. In Proceedings of the VLDB of the Conference, Rome, Italy, 11–14 September 2001; Volume 1, pp. 301–310.
- Kossmann, D.; Ramsak, F.; Rost, S. Shooting Stars in the Sky: An Online Algorithm for Skyline Queries. In Proceedings of the VLDB, Hong Kong, China, 20–23 August 2002; pp. 275–286.
- Papadias, D.; Tao, Y.; Fu, G.; Seeger, B. Progressive Skyline Computation in Database Systems. Proc. ACM Trans. Database Syst. 2005, 30, 41–82. [Google Scholar] [CrossRef]
- Huang, Z.; Jansen, C.S.; Lu, H.; Ooi, B.C. Skyline Queries against Mobile Lightweight Devices in MANETs. In Proceedings of the ICDE, Atlanta, GA, USA, 3–4 April 2006; pp. 66–76.
- Chung, Y.D.; Lee, S.K. In-network processing for skyline queries in sensor networks. IEICE Trans. Commun. 2007, 90, 3452–3459. [Google Scholar]
- Chen, H.; Zhou, S.; Guan, J. Towards Energy-Efficient Skyline Monitoring in Wireless Sensor Networks. In Proceedings of the 4th European Conference on Wireless Sensor Networks (EWSN), Delft, The Netherlands, 29–31 January 2007; pp. 101–116.
- Xin, J.C.; Wang, G.R. Continuous skyline nodes query processing over wireless sensor networks. Chin. J. Comput. 2012, 35, 2415–2430. [Google Scholar] [CrossRef]
- Xin, J.; Wang, G.; Chen, L.; Zhang, X.; Wang, Z. Continuously Maintaining Sliding Window Skylines in a Sensor Network. In Proceedings of the 12th International Conference on Database Systems for Advanced Applications, DASFAA, Bangkok, Thailand, 9–12 April 2007; pp. 509–521.
- Xin, J.; Wang, G.; Zhang, X. Energy-Efficient Skyline Queries over Sensor Network Using Mapped Skyline Filters. In Proceedings of the Joint 9th Asia-Pacific Web Conference and 8th International Conference on Web-Age Information Management, Huangshan, China, 14–15 July 2007; pp. 144–156.
- Su, I.; Chung, Y.; Lee, C.; Lin, Y. Efficient skyline query processing in wireless sensor networks. J. Parallel Distrib. Comput. 2010, 70, 680–698. [Google Scholar] [CrossRef]
- Madden, S.; Franklin, M.J.; Hellerstein, J.M.; Hong, W. TAG: A Tiny Aggregation Service for Ad-Hoc Sensor Networks. ACM SIGOPS Oper. Syst. Rev. 2002, 36, 131–146. [Google Scholar] [CrossRef]
- Peng, Y.; Song, Q.; Yu, Y.; Wang, F. Fault-tolerant routing mechanism based on network coding in wireless mesh networks. Netw. Computer Appl 2014, 27, 259–272. [Google Scholar] [CrossRef]
- Wei, W.; Yong, Q. Information potential fields navigation in wireless Ad-Hoc sensor networks. Sensors 2011, 11, 4794–4807. [Google Scholar] [CrossRef] [PubMed]
- Wei, W.; Xu, Q.; Wang, L.; Hei, X.H.; Shen, P.Y. GI/Geom/1 queue based on communication model for mesh networks. Int. J. Commun. Syst. 2014, 27, 3013–3029. [Google Scholar] [CrossRef]
- Wei, W.; Yang, X.L.; Zhou, B.; Feng, J.; Shen, P.Y. Combined energy minimization for image reconstruction from few views. Math. Probl. Eng. 2012, 8, 1094–1099. [Google Scholar] [CrossRef]
- Wei, W.; Qiang, Y.; Zhang, J. A Bijection between Lattice-Valued Filters and Lattice-Valued Congruences in Residuated Lattices. Math. Probl. Eng. 2013, 32, 1437–1450. [Google Scholar]
- Jin, X.; Zhang, Q.; Zeng, P.; Kong, F.; Xiao, Y. Collision-free multichannel superframe scheduling for IEEE 802.15.4 cluster-tree networks. Int. J. Sens. Netw. 2014, 15, 246–258. [Google Scholar] [CrossRef]
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Wei, W.; Deng, Q.; Liu, W.; Song, H. An Energy-Efficient Skyline Query for Massively Multidimensional Sensing Data. Sensors 2016, 16, 83. https://doi.org/10.3390/s16010083
Wang Y, Wei W, Deng Q, Liu W, Song H. An Energy-Efficient Skyline Query for Massively Multidimensional Sensing Data. Sensors. 2016; 16(1):83. https://doi.org/10.3390/s16010083
Chicago/Turabian StyleWang, Yan, Wei Wei, Qingxu Deng, Wei Liu, and Houbing Song. 2016. "An Energy-Efficient Skyline Query for Massively Multidimensional Sensing Data" Sensors 16, no. 1: 83. https://doi.org/10.3390/s16010083
APA StyleWang, Y., Wei, W., Deng, Q., Liu, W., & Song, H. (2016). An Energy-Efficient Skyline Query for Massively Multidimensional Sensing Data. Sensors, 16(1), 83. https://doi.org/10.3390/s16010083