
Hierarchical Sparse Learning with Spectral-Spatial Information for Hyperspectral Imagery Denoising

Abstract
:1. Introduction
- (1)
- First, we present a spectral–spatial data extraction approach for HSI based on their high structural correlations in the spectral domain. Using this approach, the spectral bands, with similar and continuous features can be adaptively segmented into the same band-subset.
- (2)
- Second, a hierarchical dictionary model is organized by the prior distributions and hyper-prior distributions to deeply illustrate the noisy HSI. It depicts the noiseless data by utilizing the dictionary, in which the spatial consistency is exploited by Gaussian process. Meanwhile, by decomposing the noise term into Gaussian noise term and sparse noise term, the proposed method can well represent the intrinsic noise properties.
- (3)
- Last but not the least, many experiments performed under different conditions are displayed. Compared with other state-of-the-art denoising approaches, the suggested method shows superior performance on suppressing various noises, including Gaussian noise, Poisson noise, dead pixel lines and stripes.
2. Sparse Learning for Denoising 2D Images
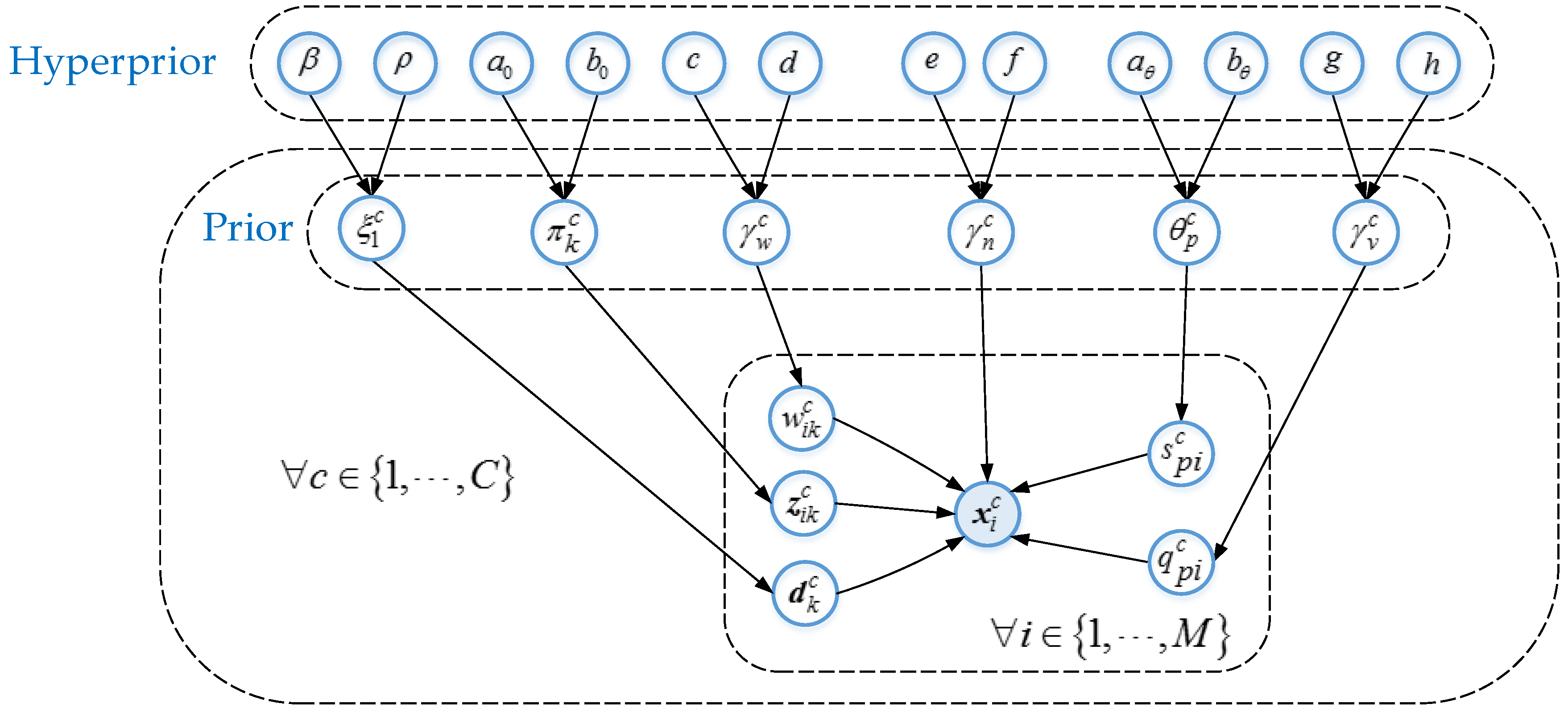
3. HSI Denoising with Spectral-Spatial Information and Hierarchical Sparse Learning
3.1. Spatial-Spectral Data Extraction
3.2. Hierarchical Sparse Learning for Denoising Each Band-Subset
4. Experimental Results and Discussion
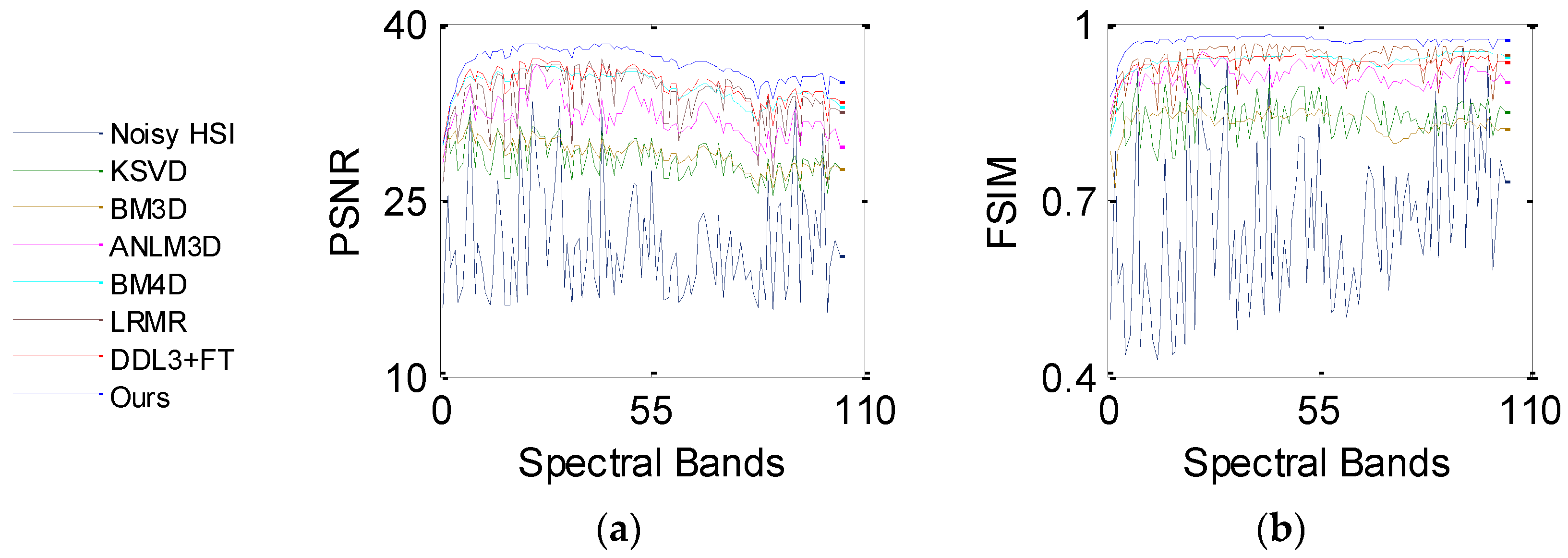
4.1. Experiment on Simulated Data
4.2. Experiment on Real Data
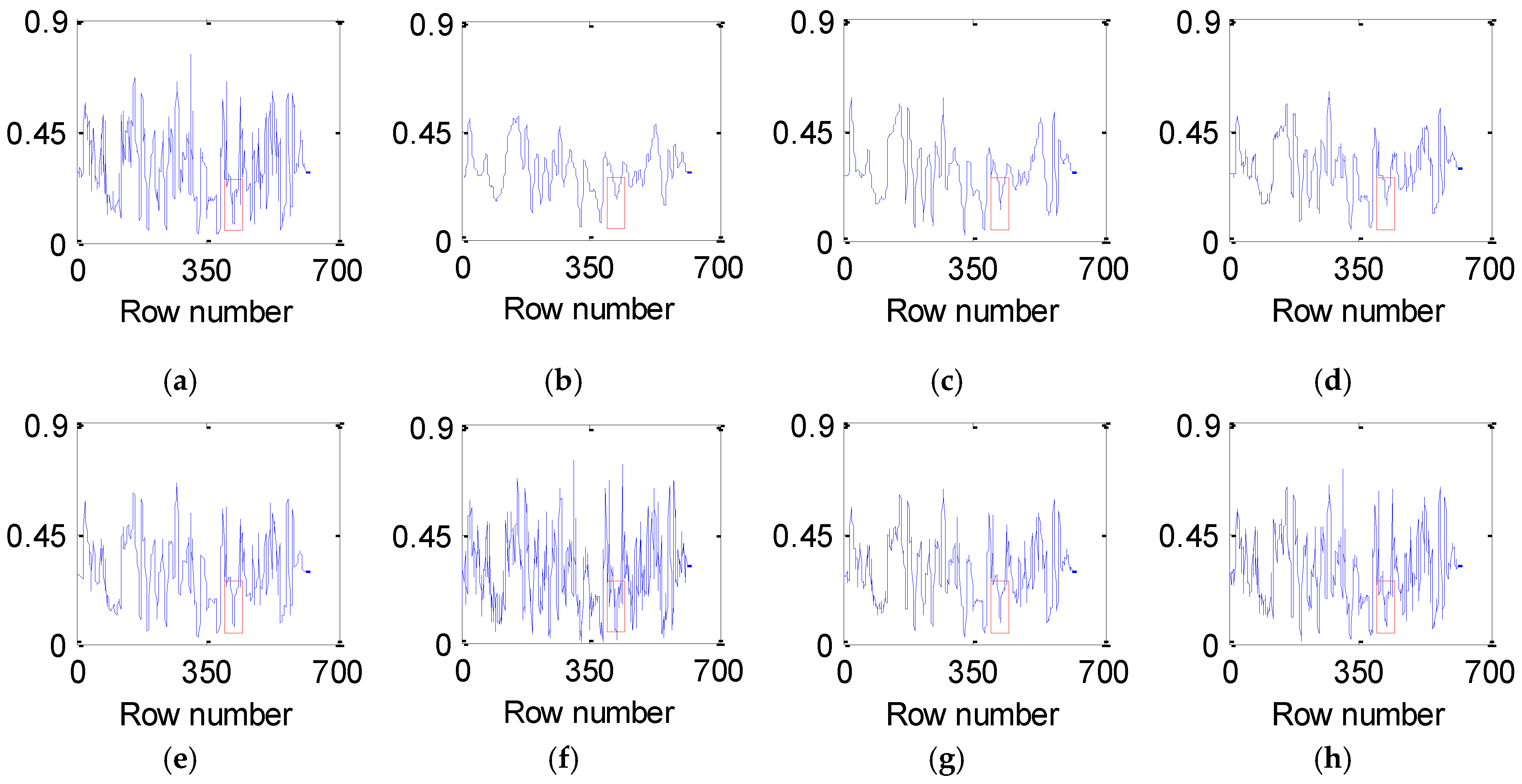
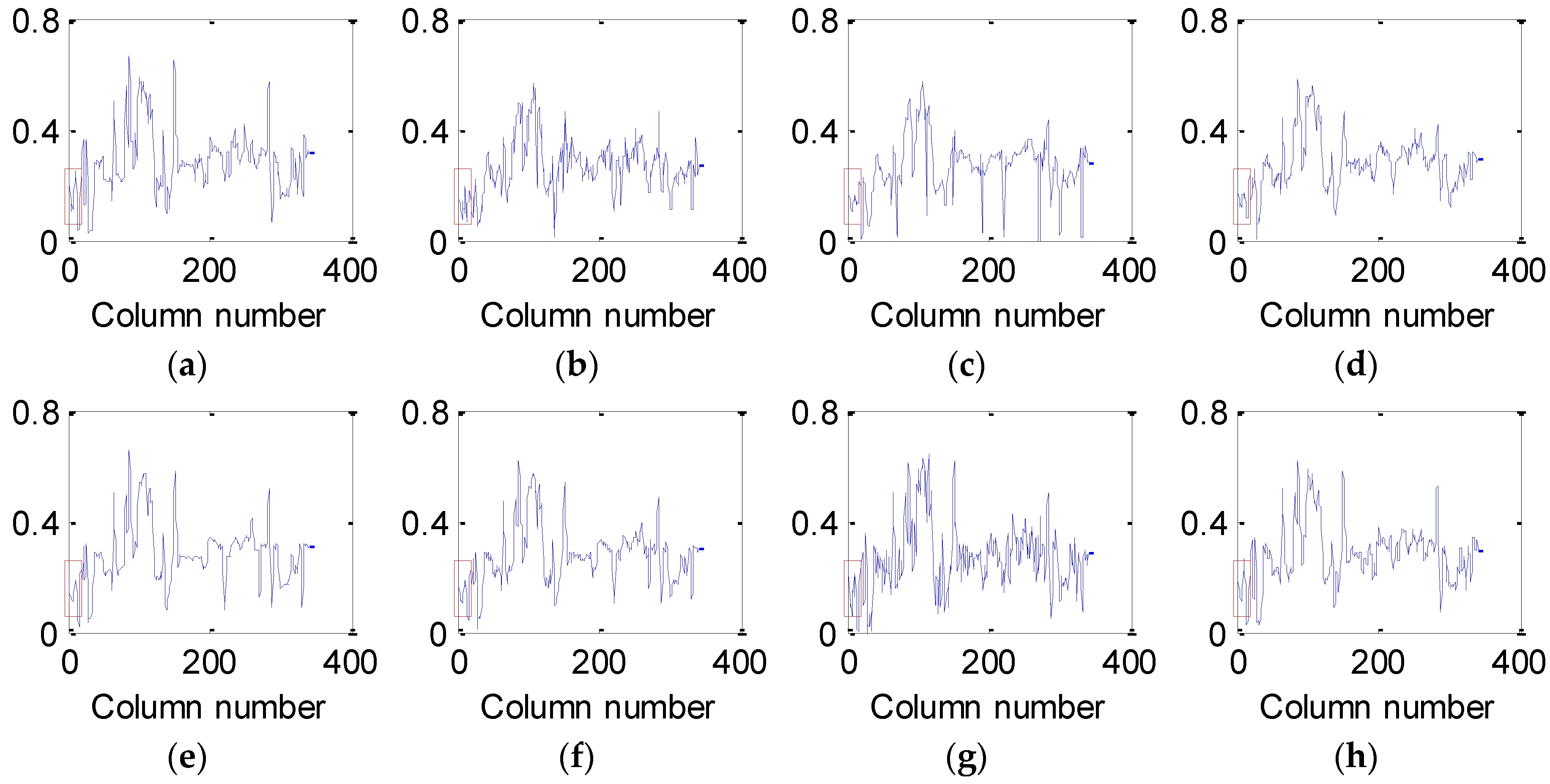
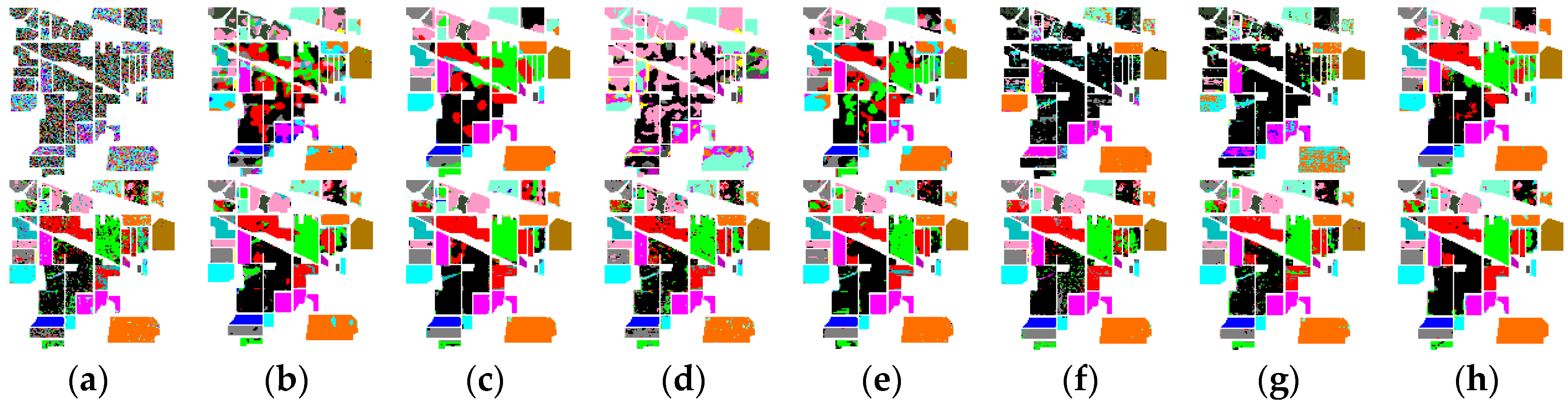
4.2.1. Denoising for Urban Data
4.2.2. Experimental Results on Indian Pines Data
4.3. Discussion
4.3.1. Threshold Parameter η
4.3.2. The Sparse Noise Term
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
References
- Van der Meer, F.D.; van der Werff, H.M.; van Ruitenbeek, F.J.; Hecker, C.A.; Bakker, W.H.; Noomen, M.F.; van der Meijde, M.; Carranza, E.J.M.; de Smeth, J.B.; Woldai, T. Multi-and Hyperspectral geologic remote sensing: A review. Int. J. Appl. Earth Obs. Geoinf. 2012, 14, 112–128. [Google Scholar] [CrossRef]
- Lu, G.; Fei, B. Medical hyperspectral imaging: A review. J. Biomed. Opt. 2014, 19, 010901. [Google Scholar] [CrossRef] [PubMed]
- Gmur, S.; Vogt, D.; Zabowski, D.; Moskal, L.M. Hyperspectral analysis of soil nitrogen, carbon, carbonate, and organic matter using regression trees. Sensors 2012, 12, 10639–10658. [Google Scholar] [CrossRef] [PubMed]
- Lam, A.; Sato, I.; Sato, Y. Denoising hyperspectral images using spectral domain statistics. In Proceedings of the IEEE International Conference on Pattern Recognition (ICPR’12), Tsukuba, Japan, 11–15 November 2012; pp. 477–480.
- Fu, P.; Li, C.Y.; Xia, Y.; Ji, Z.X.; Sun, Q.S.; Cai, W.D.; Feng, D.D. Adaptive noise estimation from highly textured hyperspectral images. Appl. Opt. 2014, 53, 7059–7071. [Google Scholar] [CrossRef] [PubMed]
- Chen, G.Y.; Qian, S.E. Denoising and dimensionality reduction of hyper-spectral imagery using wavelet packets, neighbour shrinking and principal component analysis. Int. J. Remote Sens. 2009, 30, 4889–4895. [Google Scholar] [CrossRef]
- Beck, A.; Teboulle, M. Fast gradient-based algorithms for constrained total variation image denoising and deblurring problems. IEEE Trans. Image Process. 2009, 18, 2419–2434. [Google Scholar] [CrossRef] [PubMed]
- Buades, A.; Coll, B.; Morel, J.M. A non-local algorithm for image denoising. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 7–12 June 2005; pp. 60–65.
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for Sparse Representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Dabov, K.; Foi, A.; Karkovnik, V. Image denoising by sparse 3Dtransform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2094. [Google Scholar] [CrossRef] [PubMed]
- Karami, A.; Yazdi, M.; Asli, A.Z. Noise reduction of hyperspectral images using kernel non-negative Tucker decomposition. IEEEJ. Sel. Top. Signal Process. 2011, 5, 487–493. [Google Scholar] [CrossRef]
- Chen, G.Y.; Qian, S.E. Denoising of hyperspectral imagery using principal component analysis and wavelet shrinkage. IEEE Trans. Geosci.Remote Sens. 2011, 49, 973–980. [Google Scholar] [CrossRef]
- Manjón, J.V.; Pierrick, C.; Luis, M.B.; Collins, D.L.; Robles, M. Adaptive non-local means denoising of MR images with spatially varying noise levels. J. Magn. Reson. Imaging 2010, 31, 192–203. [Google Scholar] [CrossRef] [PubMed]
- Qian, Y.T.; Ye, M.C. Hyperspectral imagery restoration using nonlocal spectral-spatial structured sparse representation with noise estimation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 499–515. [Google Scholar] [CrossRef]
- Aggarwal, H.K.; Majumdar, A. Hyperspectral Image Denoising Using Spatio-Spectral Total Variation. IEEE Trans. Geosci. Remote Sens. 2016, 13, 442–446. [Google Scholar] [CrossRef]
- Yuan, Q.Q.; Zhang, L.P.; Shen, H.F. Hyperspectral image denoising employing a spectral–spatial adaptive total variation model. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3660–3677. [Google Scholar] [CrossRef]
- Li, J.; Yuan, Q.Q.; Shen, H.F.; Zhang, L.P. Hyperspectral image recovery employing a multidimensional nonlocal total variation model. Signal Process. 2015, 111, 230–446. [Google Scholar] [CrossRef]
- Liao, D.P.; Ye, M.C.; Jia, S.; Qian, Y.T. Noise reduction of hyperspectral imagery based on nonlocal tensor factorization. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Melbourne, Australia, 21–26 July 2013; pp. 1083–1086.
- Maggioni, M.; Katkovnik, V.; Egiazarian, K.; Foi, A. Nonlocal transform-domain filter for volumetric data denoising and reconstruction. IEEE Trans. Image Process. 2013, 22, 119–133. [Google Scholar] [CrossRef] [PubMed]
- Xu, L.L.; Li, F.; Wong, A.; Clausi, D.A. Hyperspectral Image Denoising Using a Spatial–Spectral Monte Carlo Sampling Approach. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3025–3038. [Google Scholar] [CrossRef]
- Zhong, P.; Wang, R.S. Jointly learning the hybrid CRF and MLR model for simultaneous denoising and classification of hyperspectral imagery. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 1319–1334. [Google Scholar] [CrossRef]
- Yuan, Q.Q.; Zhang, L.P.; Shen, H.F. Hyperspectral image denoising with a spatial–spectral view fusion strategy. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2314–2325. [Google Scholar] [CrossRef]
- Mairal, J.; Bach, F.; Ponce, J. Sparse Modeling for Image and Vision Processing. Found. Trends Comput. Graph. Vis. 2014, 8, 85–283. [Google Scholar] [CrossRef] [Green Version]
- Wu, D.; Zhang, Y.; Chen, Y. 3D sparse coding based denoising of hyperspectral images. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium, Milan, Italy, 26–31 July 2015; pp. 3115–3118.
- Xing, Z.; Zhou, M.; Castrodad, A.; Sapiro, G.; Carin, L. Dictionary learning for noisy and incomplete hyperspectral images. SIAM J. Imaging Sci. 2012, 5, 33–56. [Google Scholar] [CrossRef]
- Li, J.; Yuan, Q.Q.; Shen, H.F.; Zhang, L.P. Noise Removal from Hyperspectral Image with Joint Spectral-Spatial Distributed Sparse Representation. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5425–5439. [Google Scholar] [CrossRef]
- Ye, M.C.; Qian, Y.T.; Zhou, J. Multitask sparse nonnegative matrix factorization for joint spectral–spatial hyperspectral imagery denoising. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2621–2639. [Google Scholar] [CrossRef]
- Rasti, B.; Sveinsson, J.R.; Ulfarsson, M.O.; Benediktsson, J.A. Hyperspectral image denoising using a new linear model and Sparse Regularization. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Melbourne, Australia, 21–26 July 2013; pp. 457–460.
- Yang, J.X.; Zhao, Y.Q.; Chan, J.C.W.; Kong, S.G. Coupled Sparse Denoising and Unmixing with Low-Rank Constraint for Hyperspectral Image. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1818–1833. [Google Scholar] [CrossRef]
- Zhu, R.; Dong, M.Z.; Xue, J.H. Spectral nonlocal restoration of hyperspectral images with low-rank property. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3062–3067. [Google Scholar]
- Zhang, H.Y.; He, W.; Zhang, L.P.; Shen, H.F.; Yuan, Q.Q. Hyperspectral image restoration using low-rank matrix recovery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4729–4743. [Google Scholar] [CrossRef]
- He, W.; Zhang, H.Y.; Zhang, L.P.; Shen, H.F. Total-variation-regularized low-rank matrix factorization for hyperspectral image restoration. IEEE Trans. Geosci. Remote Sens. 2016, 54, 178–188. [Google Scholar] [CrossRef]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4959–4962.
- Huo, L.; Feng, X.; Huo, C.; Pan, C. Learning deep dictionary for hyperspectral image denoising. IEICE Trans. Inf. Syst. 2015, 7, 1401–1404. [Google Scholar] [CrossRef]
- Donoho, D.L. For most large underdetermined systems of linear equations the minimal -norm solution is also the sparsest solution. Commun. Pure Appl. Math. 2006, 59, 797–829. [Google Scholar] [CrossRef]
- Mairal, J.; Bach, F.; Ponce, J. Task-driven dictionary learning. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 791–804. [Google Scholar] [CrossRef] [PubMed]
- Shah, A.; David, K.; Ghahramani, Z.B. An empirical study of stochastic variational inference algorithms for the beta Bernoulli process. In Proceedings of the 32nd International Conference on Machine Learning (ICML‘15), Lille, France, 6–11 July 2015.
- Thiagarajan, J.J.; Ramamurthy, K.N.; Spanias, A. Learning stable multilevel dictionaries for sparse representations. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 1913–1926. [Google Scholar] [CrossRef] [PubMed]
- Yan, R.M.; Shao, L.; Liu, Y. Nonlocal hierarchical dictionary learning using wavelets for image denoising. IEEE Trans. Image Process. 2013, 22, 4689–4698. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Papyan, V.; Elad, M. Multi-scale patch-based image restoration. IEEE Trans. Image Process. 2016, 25, 249–261. [Google Scholar] [CrossRef] [PubMed]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B. Bayesian Data Analysis; Chapman & Hall/CRC: Boca Raton, FL, USA, 2014. [Google Scholar]
- Rasmussen, C.; Williams, C. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Makitalo, M.; Foi, A. Noise parameter mismatch in variance stabilization, with an application to Poisson-Gaussian noise estimation. IEEE Trans. Image Process. 2014, 23, 5349–5359. [Google Scholar] [CrossRef] [PubMed]
- Casella, G.; George, E.I. Explaining the Gibbs sampler. Am. Stat. 1992, 46, 167–174. [Google Scholar]
- Rodriguez, Y.G.; Davis, R.; Scharf, L. Efficient Gibbs Sampling of Truncated Multivariate Normal with Application to Constrained Linear Regression; Columbia University: New York, NY, USA, 2004. [Google Scholar]
- Zhang, L.; Zhang, L.; Mou, X.Q.; Zhang, D. FSIM: A Feature Similarity Index for Image Quality Assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Wu, Z.; Wei, Z. Spectral–Spatial Classification of Hyperspectral Image Based on Low-Rank Decomposition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2370–2380. [Google Scholar] [CrossRef]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Initial HSI | KSVD | BM3D | ANLM3D | BM4D | LRMR | DDL3+FT | Ours | |
|---|---|---|---|---|---|---|---|---|
| OA | 15.74% | 57.96% | 81.2% | 25.17% | 69.27% | 48.38% | 49.12% | 83.76% |
| 0.0912 | 0.5368 | 0.7803 | 0.2135 | 0.679 | 0.3664 | 0.4284 | 0.8109 |
| Initial HSI | KSVD | BM3D | ANLM3D | BM4D | LRMR | DDL3+FT | Ours | |
|---|---|---|---|---|---|---|---|---|
| OA | 74.39% | 87.96% | 0.9215% | 81.06% | 87.59% | 87.18% | 85.92% | 90.35% |
| 0.7183 | 0.8531 | 0.8673 | 0.775 | 0.8568 | 0.8548 | 0.8442 | 0.8726 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Jiao, L.; Yang, S. Hierarchical Sparse Learning with Spectral-Spatial Information for Hyperspectral Imagery Denoising. Sensors 2016, 16, 1718. https://doi.org/10.3390/s16101718
Liu S, Jiao L, Yang S. Hierarchical Sparse Learning with Spectral-Spatial Information for Hyperspectral Imagery Denoising. Sensors. 2016; 16(10):1718. https://doi.org/10.3390/s16101718
Chicago/Turabian StyleLiu, Shuai, Licheng Jiao, and Shuyuan Yang. 2016. "Hierarchical Sparse Learning with Spectral-Spatial Information for Hyperspectral Imagery Denoising" Sensors 16, no. 10: 1718. https://doi.org/10.3390/s16101718
APA StyleLiu, S., Jiao, L., & Yang, S. (2016). Hierarchical Sparse Learning with Spectral-Spatial Information for Hyperspectral Imagery Denoising. Sensors, 16(10), 1718. https://doi.org/10.3390/s16101718