1. Introduction
Physical activity recognition based on sensors is a growing area of interest given the great advances in wearable sensors, and the common use of smartphone with powerful embedded sensors. Wearable sensors are getting less obtrusive allowing using sensors for longer periods of time. Applications in various domains are taking advantage of the ease of obtaining data to monitor personal activities and behavior in order to deliver proactive and personalized services.
Although many activity recognition systems have been developed for more than two decades, there are still open issues to be tackled with new techniques. Lara et al. [
1] envisions six designing challenges for activity recognition: (1) the selection of attributes and sensors; (2) the construction of portable, unobtrusive, and inexpensive data acquisition system; (3) the design of feature extraction and inference methods; (4) data collection under realistic conditions; (5) the flexibility to support new users without the need to re-train the system; and (6) energy consumption. This list of challenges is not exhaustive given that there are other challenges common to various activity recognition scenarios. Recognizing concurrent activities, recognizing interleaved activities, ambiguity of interpretation, and multiple residents are challenges of the nature of human activities defined by [
2] needed to be addressed also. We address in this paper one of the main challenges of human activity recognition (HAR) mentioned above: Flexibility. We adopted the flexibility in HAR defined by Lara et al. [
1]. In [
1], flexibility is contemplated as the ability of the classifier to support new users without the need to collect additional data of the user and re-train the system.
Flexibility in activity recognition classifiers can be considered regarding different aspects. For example, flexibility is considered by [
3] as the ability of the classifier to recognize different kinds of activities: Common daily activities, activities specific for a certain group of persons, or activities that are rarely performed. Bulling et al. [
4] is more interested in generalization ability of the activity recognition classifier. They categorized activity recognition system taking into account if the level of generalization is user independent, user specific and robust to cope with temporal variations. In summary, classifiers must be able to cope with multiple persons performing activities on multiple days, and in multiple runs containing repetitions of the set of activities.
Human activity recognition systems generate generic or universal models using training data from several users. These models are then applied to new users without the need to retrain the generic model. Other systems are more focused in specific users that generate personal models that perform the train-test processes only with data of the subject of interest. Recently, personalization of physical activity recognition approaches deal with a new subject from whom data is not available in training phase in a subject- independent system [
5]. Nevertheless, personalization approaches only address one aspect of generalization.
In previous work, we presented the results of the first tests applying artificial hydrocarbon networks (AHN) for human activity recognition task in [
6], using raw sensor data of a public dataset containing five basic and distinctive activity classes (sitting-down, standing-up, standing, walking, and sitting). We compared models generated with ten well-known supervised learning methods against AHN method focusing in the comparison against deep learning method. From this preliminary analysis we concluded that AHN are suitable for activity recognition.
Results of a thorough experimental analysis to prove that AHN classifier are very competitive and robust for physical activity recognition was presented in [
7]. In that paper we focused in one challenge of HAR: To deal with incomplete noise tolerance. Four experiments were designed using raw data and one window-based approach of another public database with 18 more complex activity classes.
Our goal in this work is to present artificial hydrocarbon networks as a flexible approach in a human activity recognition system. We consider flexibility of the approach mainly regarding the ability to support new users (user-independent). We are also concerned the ability to support variations of the same subject in a user-specific approach, and the ability to handle new or irrelevant activities, so we designed some experiments regarding these issues. Since we are using a public dataset for experimentation, real-time variations due to sensors or user behavior are out of the scope of this work.
In order to evaluate the performance of artificial hydrocarbon networks based classifier, three kinds of experiments were designed using Attal et al.’s methodology [
8]. For each case scenario, the performance of the proposed artificial hydrocarbon networks based classifier was compared with eighteen supervised techniques frequently used in activity recognition systems. Case 1 experiment was designed to assess the performance for all individuals, case 2 experiment assesses the performance of our classifier for user-independent scenario. The first case experiment used cross validation evaluation schema, and the second case used leave-one-subject-out validation. The third experiment (case 3) was designed to test the performance of our classifier for user-dependent scenario. In this case, the classifiers were trained and tested for each individual with her/his own data, and average accuracy and standard deviation was computed.
The rest of the paper is as follows.
Section 2 discusses related work in flexibility in human activity recognition systems. A brief description of artificial hydrocarbon networks (AHN) technique is presented in
Section 3. Our proposed AHN-classifier is presented in
Section 4. In
Section 5, experimentation is presented, and in
Section 6, the results are discussed. Conclusions and directions for future research are described in
Section 7.
2. Flexibility in Human Activity Recognition
Every person performs activities in different manner depending on their characteristics such as age, gender, weight, and health condition. Even the same person can change the way of performing an activity depending in the time of the day, emotional and physical state among other thinks. Therefore, the flexibility of a classifier to cope with this diversity of manners of performing the same activity is still one of the main issues of human activity recognition (HAR) [
1]. The measures of wearable sensors gathered from a male elderly, a child or a handicapped person doing the same activity present significant differences.
One of the main characteristics considered when evaluating human activity recognition systems is flexibility [
1]. Although flexibility in a HAR classifier is usually thought regarding the generalization ability in recognizing activities for a new person, it is also considered as the ability of recognizing new activities for one person, or even new runs or sessions to prove robustness over time [
4]. In other applications, for example in the video surveillance domain [
9] it is more important to consider the classifiers flexibility regarding the ability for adding new activities, namely new and unusual events. Bulling et al. [
4] include the characteristic generalization in a HAR system. They identify user-independent systems, user –specific systems, and temporal systems. Lara et al. [
1] define the classifier flexibility level as user-specific and monolithic (for user-independent).
In the user-specific approach, the system is designed to work with a certain user and to self-adapt to his/her characteristics. Specific approaches are mainly recommended when the users are elderly people, patients with some health problems or disabled. User-dependent systems are frequently used in assisted-living domain given that elderly and people with health problems present differences in their main characteristics that hamper the performance of a generic classifier [
8,
10,
11]. Recently, Capela et al. [
12] compared activity recognition with able-bodies and stroke participants, proving that their classifiers performed worse for stroke participants. Regarding their performance, as expected, user-specific models have better performance, but are not generalizable. The main drawback of this approach is that a new model must be done for each user; the system must be retrained.
Unlike the specific approach, user-independent systems need to be flexible enough to work with different users [
1]. It is important for this kind of systems to be able to keep good performance if new users arrive. Generic or universal models are created from time series dataset of measured attributes from a small or large set of individuals performing each different activity. Depending on case use scenarios, new users may arrive to the activity recognition process. Too many or new activities can also be performed by individuals, making it difficult for one model to cope with all those differences. One way to solve this problem is to create groups with similar characteristics and/or similar activities performed.
Some systems like [
13], carry out subject-dependent and subject-independent analysis to prove that their classification technique is able to cope with multiple persons, but is also well fitted to build a specific oriented model.
Recently, personalization of physical activity recognition has gained interest. Personalization approaches try to deal with the fact that training for activity recognition is usually done on a large number of subjects, and then applied with a new subject from whom data is not available in training phase [
5]. Each person has different characteristics that ultimately cause high variance in the activity recognition performance for each subject. Personalization approaches try to cope with these differences adapting the model created with large number of subjects for its application with new users [
3,
5,
14]. In [
14], the authors create a model for basic activity recognition based on a decision tree technique, and they change the thresholds of the decision nodes afterwards based on labeled data of each new user. Berchtold et al. [
3] present a modular classifier approach based on Recurrent Fuzzy Inference Systems (RFIS). In the later approach the best classifier module is selected from a set of classifiers, and it is adapted to work with new users. In works [
3,
14], parameters are changed of a general model in order to adapt this universal model to new users. The drawback of this approach is that the general model is either to simple to cope with challenging activity tasks and variety of users, or the model is to complex and therefore entails great computational costs. Reiss [
5] presents a different method of personalization in which the general model consists in a set of classifiers weighted the same. A strategy based on weighted majority voting is applied to increase the performance of the model for new users. Instead of retaining classifiers, the method retains only weights reducing the computational complexity.
Personalization of physical activity recognition applications is a valid approach to deal with new subject from whom data is not available in training phase in a subject-independent system. Nevertheless, personalization approaches only address one aspect of generalization [
15].
A number of researches have explored transfer learning for activity recognition [
16]. Transfer learning is the ability to extend what has been learned in one context to new context [
17,
18]. This approach allows reusing the knowledge previously obtained in a source to a new target population. Roggen et al. [
19] defined a run-time adaptive activity recognition chain (adARC) to deal with variations due to placement of sensors, behavior of the user over time, and sensing infrastructure. This architecture allows adaptation according to the recognition of new conditions of the system. The smartphone-based framework of self-learning schema presented in Guo et al. [
20] is able to recognize unpredictable activities without any knowledge in the training dataset. They also support variations in smartphone orientation. Li et al. [
21] proposed a generic framework for human motion recognition based on smartphones. They presented features to deal with variations due to sensor position and orientation, and user motion patterns.
Regarding experimentation design, feature selection can help or hinder the flexibility performance of a HAR classifier. Given the great variability in the performance of activities between different subjects, and even in the same subject at different time, features derived from wearable sensors can lead to great variability. “A good feature set should show little variation between repetitions of the same movements and across different subjects but should vary considerably between different activities” [
22]. It is very important to find the best subset of features that combined deliver the best predictors.
Regarding the classifier evaluation scheme, subject-dependent and subject-independent methods of evaluation analysis have been used [
13].
Preece et al. [
22] commented that cross-validation can be done in evaluations between different subjects and within-subject. In user–independent (or between-subject) oriented systems, training is made with almost every subject and test with leave one or a few subjects out. The train-test process is repeated until all subjects have been tested. For the within-subject case, train-test process is made only with the data of a subject, and this process is repeated for data of all subjects available. Average accuracy must be calculated from the results of train-test repetitions in both cases. Lara et al. [
1] describe similar evaluation schemes in order to assess the flexibility power of a classifier for each kind of generalization. They state that cross validation or leave-one-out validation schemes are used in user-independent analysis. “Leave-one-person-out is used to assess generalization to an unseen user for a user-independent recognition system” [
5].
4. Description of the Artificial Hydrocarbon Networks Based Classifier
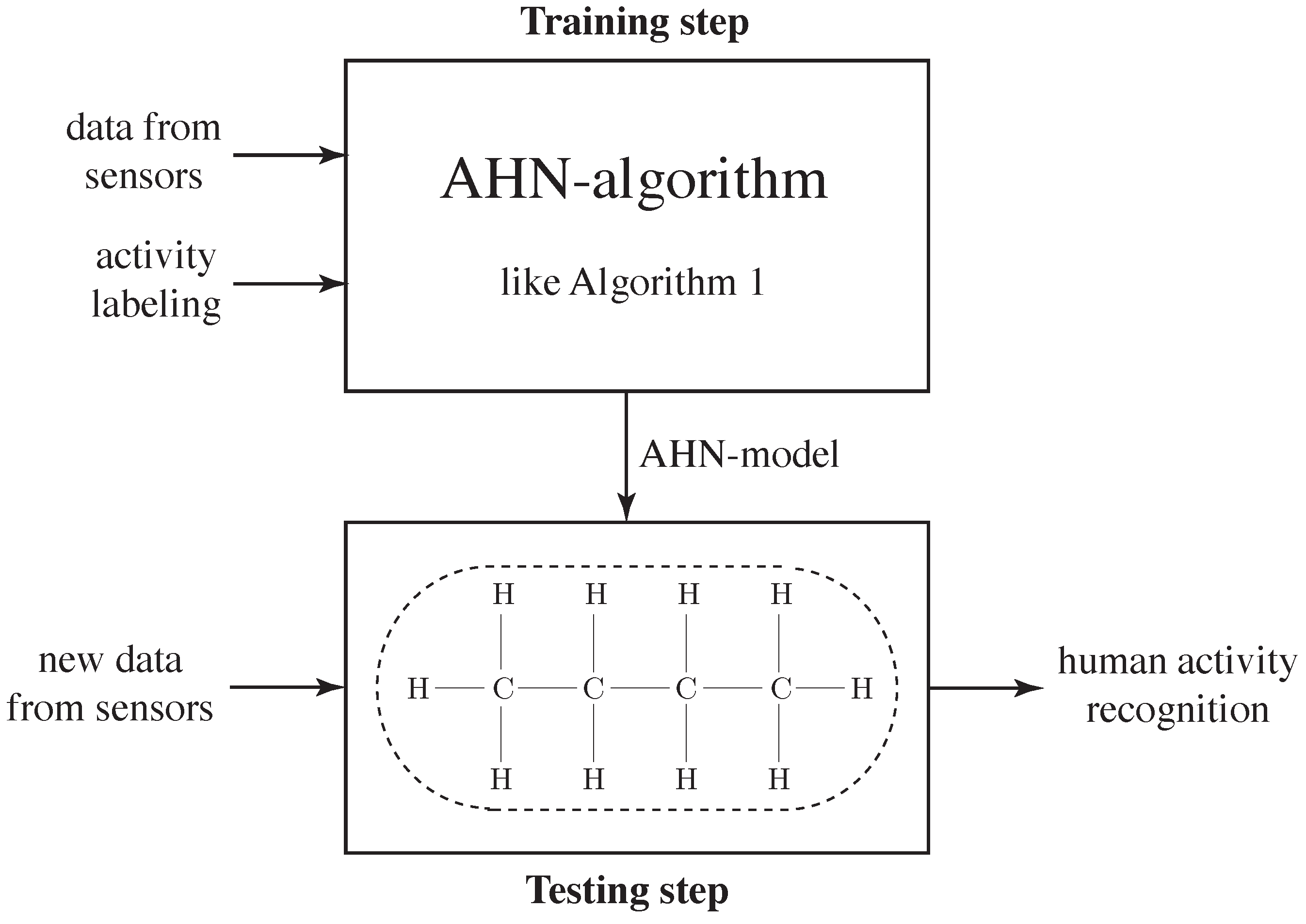
This work considers training and using an AHN-classifier as a flexible approach in human activity recognition systems. In fact, this AHN-classifier is computed and employed in two steps: Training-and-testing and implementation, as shown in
Figure 2. Previous work in this direction can be found in [
6,
7].
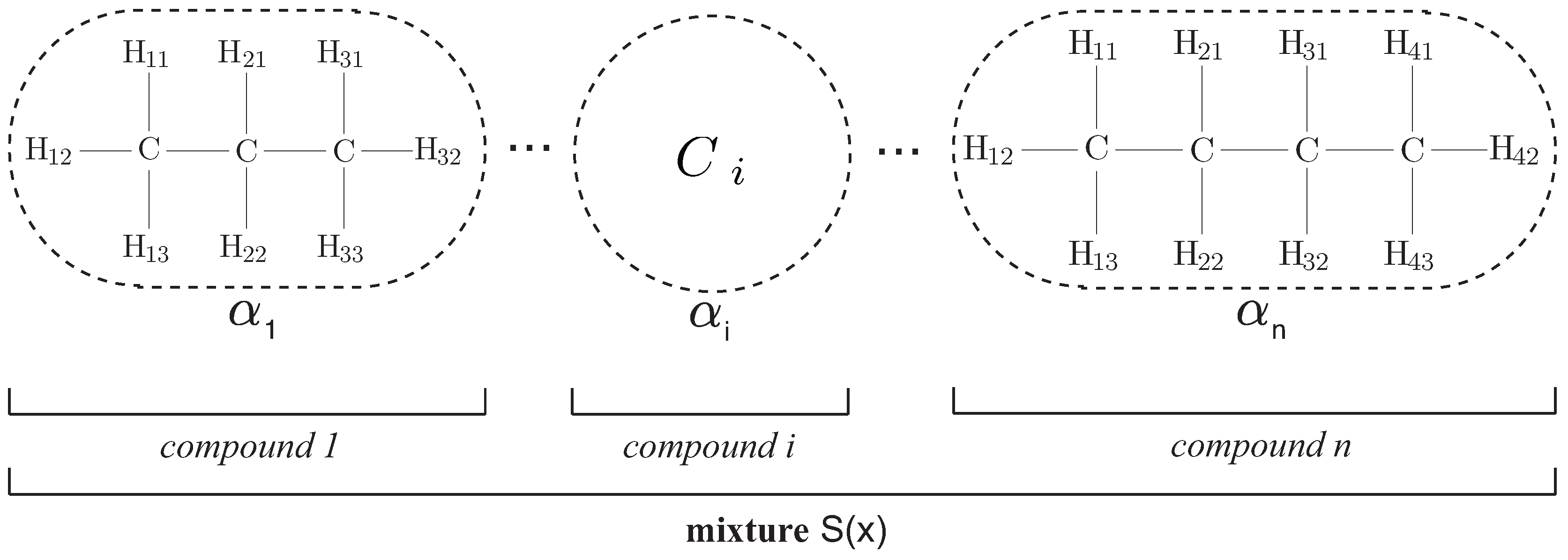
Currently, the AHN-classifier considers that sensor data has already processed in N features for all , and has organized in Q samples, each one associated to its proper label representing the jth activity in the set of all possible activities Y for ; where, J is the number of different activities in the data set. Thus, samples are composed of features and labels as -tuples of the form for all .
Considering that there is a dataset of
Q samples of the form defined above, then the AHN-classifier is built and trained using the AHN-algorithm shown in Algorithm 1. It should be noted that this proposal is using a simplified version of artificial hydrocarbon networks. Thus, the AHN-classifier is composed of one saturated and linear hydrocarbon compound, i.e., no mixtures were considered (see
Figure 1 for a hydrocarbon compound reference). In that sense, the inputs of the AHN-algorithm are the following: The training dataset Σ is a subset of
R samples, from the original dataset, as (
7), the number of molecules
n in the hydrocarbon compound is proposed to be the number of different activities (
), and the learning rate
and the tolerance value
ϵ are positive numbers selected manually. Notice that the number of molecules in the compound is an empirical value, thus no pairing between classes and molecules occurs. At last, the AHN-algorithm will compute all parameters in the AHN-classifier: Hydrogen and carbon values, as well as the bounds of molecules.
For testing and validating the AHN-classifier, the remaining samples P from the original data set (i.e., such that ) conforms the testing data set. Then, the testing data set is introduced to the AHN-classifier, previously computed, and the output response is rounded in order to obtain whole numbers as labels. If output values were out the permitted labels, they were considered as the nearest defining label. Lastly, validation of the classifier is calculated using some metrics. Moreover, new sample data can be also used in the AHN-classifier for recognizing and monitoring a human activity based on the corresponding features.
6. Results and Discussion
This section presents the results of the comparison between the proposed AHN-classifier and other eighteen supervised methods as a flexible approach for human activity recognition systems. Then, a discussion is also presented.
6.1. Case 1: All Subjects Using Cross-Validation
A cross-validation with 10-folds and 5-repetitions was computed in the training step to obtain a suitable model.
Table 6 summarizes the results of this experiment sorted in descending order by accuracy. Additionally,
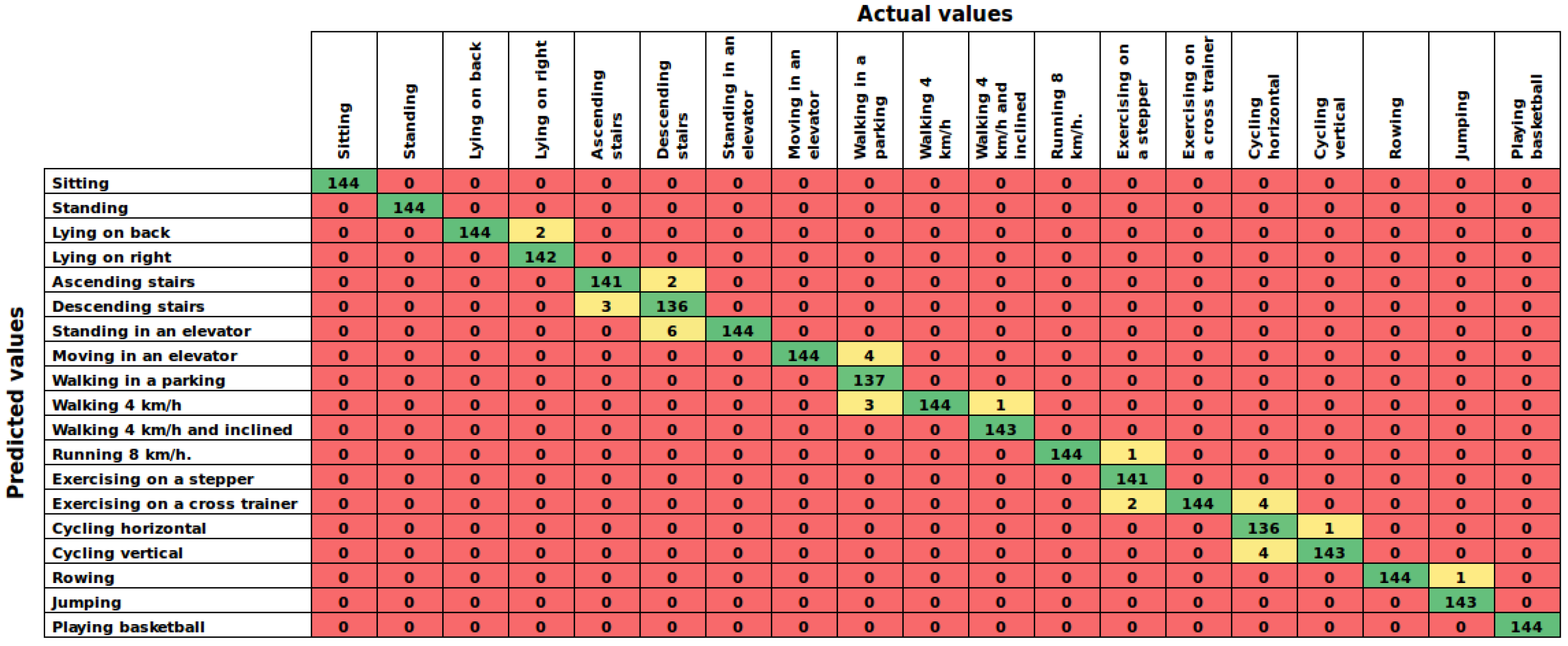
Figure 6 shows the confusion matrix of the proposed AHN-classifier. As noted, the proposed AHN-classifier ranks in second place with an accuracy of
such below to the deep learning based classifier. Then, mixture discriminant analysis, C5.0 decision trees, random forest and SVM with radial function are in the top of the list.
6.2. Case 2: User-Independent Performing Leave-One Subject-Out
This experiment is based on the well-known leave-one subject-out technique [
1], aiming to prove how well is the AHN-classifier to predict activities in new subjects.
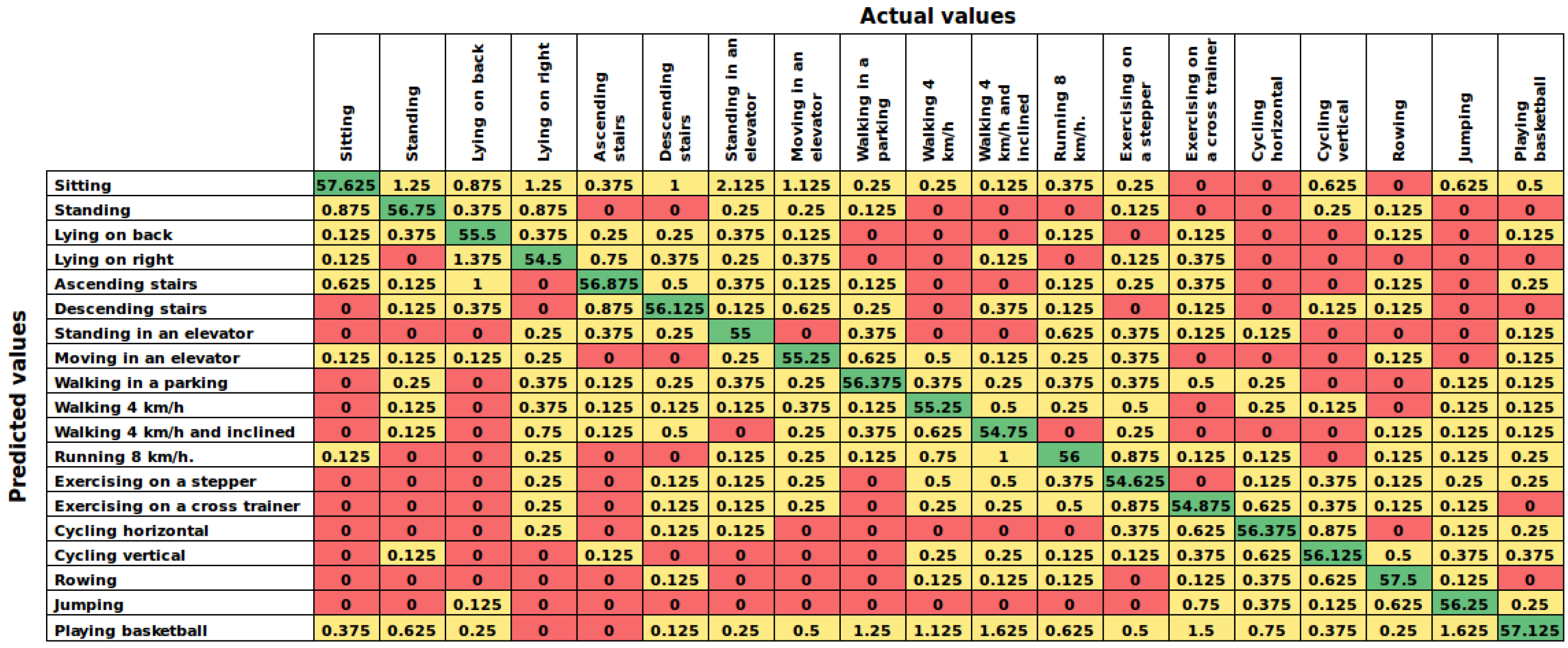
Table 7 shows the overall performance of the supervised models sorted in descending order by accuracy, and
Table 8 shows the performance of each model. In addition,
Figure 7 shows the average confusion matrix of the AHN-classifier. In this case, the AHN-classifier also ranks in second place with a mean accuracy of
just below the deep learning based classifier. Additionally, penalized discriminant analysis, shrinkage discriminant analysis, mixture discriminant analysis and nearest shrunken centroids are also in the top of the list.
6.3. Case 3: User-Dependent Performing Cross-Validation within a Subject
This experiment considers building eight different models from each of the subjects in order to measure the performance of the AHN-classifier in a user-specific approach.
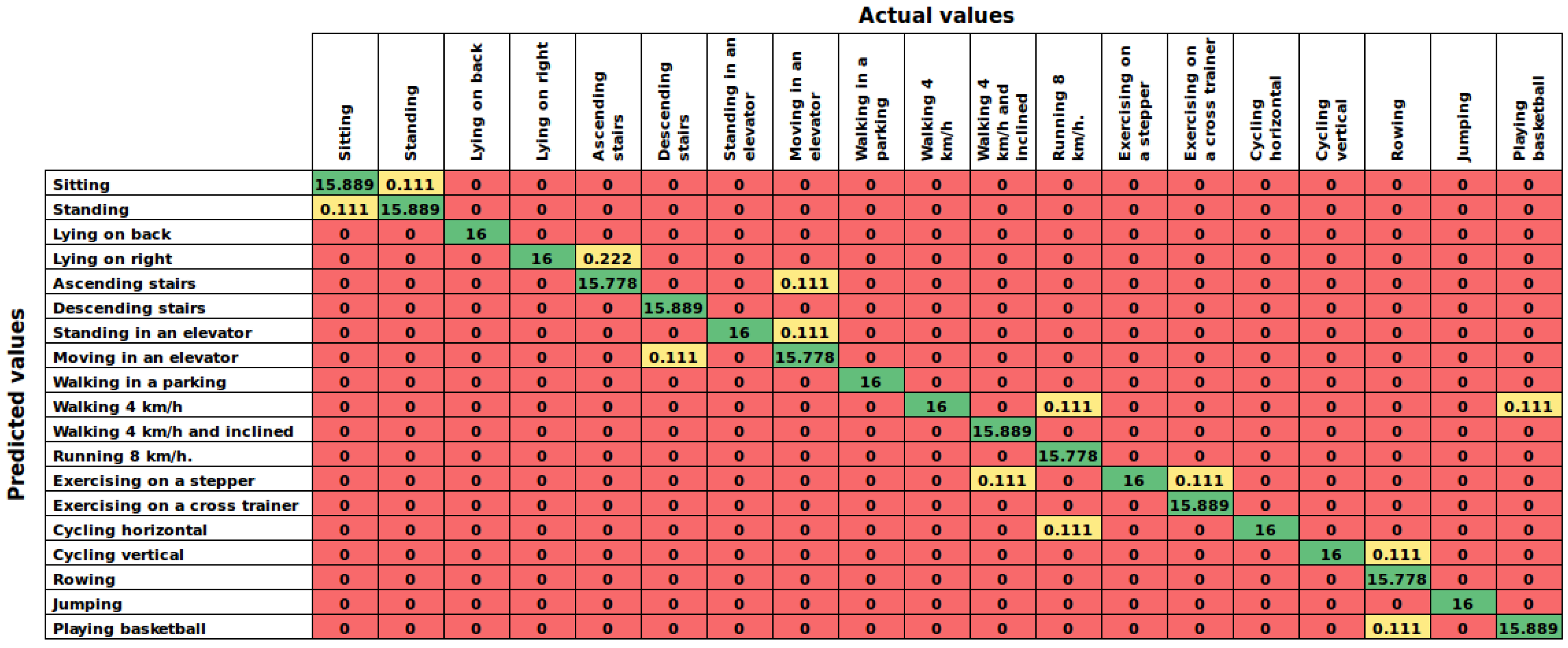
Table 9 summarizes the overall results of this experiment sorted in descending order by accuracy, and
Table 10 shows the performance of each model. Additionally,
Figure 8 reports the confusion matrix of the proposed AHN-classifier. The proposed AHN-classifier ranks at the first place with a mean accuracy of
. Currently, deep learning, mixture discriminant analysis, shrinkage discriminant analysis and penalized discriminant analysis are also in the top of the list.
6.4. Discussion
As noted above, the proposed AHN-classifier outperformed in the three case experiments. In addition, we conducted a paired
t-test analysis to find out if the differences between the accuracy of the AHN-classifier performance and the other supervised model performances are statistically significant.
Table 11 summarizes the
p-values of this test for cases 2 and 3 using a
confidence level. As shown, any
p-value greater than
(bold values in
Table 11) means that the null hypothesis about the equality of accuracy values between model performances is accepted, otherwise accuracy values between model performances are not statistically equal and the hypothesis is denied. In that sense, the AHN-classifier can be fairly compared with those model performances with a
p-value less than
, concluding that the AHN-classifier is significantly better than mixture discriminant analysis based classifier and those below the seventh position in
Table 8 for case 2. In addition, the AHN-classifier is significantly better than those model performances below the third position in
Table 10. To this end, it is shown that the AHN-classifier is significantly equivalent to deep learning in both cases 2 and 3. In fact, these experiments and their
t-test analysis consider to validate that the AHN-classifier is suitable as a flexible approach for HAR systems based on: The ability to support new users (user-independent), and the ability to build models for a specific user. Furthermore, new and unknown activities need more tests before validating its flexibility. From now, we handle and filter them before the main human activity classification.
On one hand, the proposed AHN-classifier reached
(case 1) when dealing with a HAR system using all subjects for training and testing. In the user-independent performance (case 2), results computed
of accuracy in cross-validation over subjects and leave-one subject-out experiments. Then, analyzing the confusion matrices of both experiments (
Figure 6 and
Figure 7), it can be seen that false predictions are very close to the diagonal (true positives). In the cross-validation experiment (case 1), we can observed that the activities predicted are very similar to the actual activities. For example, the AHN-classifier predicted lying on back when the actual activity was lying on right side. Likewise, it predicted walking at 4 km/h on flat when the actual activity was walking in a parking lot. In the leave-one subject-out experiment (case 2), the maximum average window counts value has to be 60, the number of window counts per activity, at each element in the chart of
Figure 7. Then, it can be observed that true positive counts are very close to the maximum value and the others are close to zero. It means that the AHN-classifier is able to truly classify human activities with a very low misclassification.
On the other hand, in user-dependent approach, the proposed AHN-classifier reached
of accuracy in cross-validation within a subject. In some cases such as
subject-4 and
subject-6, the AHN-classifier predicts
of the activities carried out by the subject. This is a slight advantage over the other five top supervised models (see
Table 9). The same behavior in the confusion matrix of this experiment (
Figure 8) was found as in the other cases.
It is important to note that deep learning, i.e., DNN, based classifier is the only model that outperforms the AHN-classifier in the first two cases. Conversely, the AHN-classifier kept at the top of the benchmark experiments in comparison with deep learning which dropped to the second place in case 3.
In terms of the unknown-activity detection module using the AHN-classifier, the experimentation shows a suggested way in which the AHN-based classifier can discriminate known and unknown activities by themselves, using the centers of molecules. The latter actually reflects the parameter interpretability property of AHN, since the centers of molecules serve as features to find correspondence between training and new data. Thus, a proper training of a single AHN-classifier should deal with both human activity classification and detecting unknown activities at the same time. Particularly to this work, the centers of molecules were not employed in the main experimentation (cases 1, 2 and 3) since the sensor signals are clearly related to known activities in the dataset.
From
Table 5, some computational issues can be identified in the AHN-classifier. Particularly, the training time of the AHN (
s) exceeded
times the maximum training time (
s) performed by the other methods. This step is time-consuming mainly on the splitting procedure at each iteration of Algorithm 1 and the inner building function (
1) used for running the LSE method. In the current work, this is not a problem. However, if real-time HAR systems are implemented, an improvement on this computational issue will be handled. For instance, another splitting procedure might be considered.
To this end, the AHN-classifier can achieve a flexible approach for user-dependent, user-independent, or both scenarios, in human activity recognition, as described in this work.
7. Conclusions and Future Work
In order to cope with real-world activity recognition challenges, a supervised machine learning technique must be flexible. In this paper, we considered flexibility of the approach regarding: The ability to support new users (user-independent). We were also concerned the ability to support variations of the same subject in a user-specific approach, and the ability to handle new or irrelevant activities.
In that sense, we presented a novel supervised machine learning method called artificial hydrocarbon networks as a flexible approach for human activity recognition. The AHN-classifier performance was compared with eighteen commonly used supervised techniques. We also designed an unknown-activity detection module that performs a rough classification to handle new and irrelevant activities. For our user-independent and user-dependent case scenarios, our results showed that AHN-classifier remained at the top of the other classifiers.
Our results demonstrated that artificial hydrocarbon networks classifier serves as a flexible approach when building a human activity recognition system with either user-dependent or user-independent approaches.
For future research, we must address flexibility regarding the ability to recognize new and complex activities. Also, the parameter interpretability of AHN will be deeply analyzed to determine the conditions and training procedures to perform human activity recognition and unknown-activity detection with a single AHN-based model. Further experimentation is also needed in order to prove flexibility when intra-subject variability occurs. Another challenge to be attended is to demonstrate that our AHN-classifier is well suited for real-time HAR systems, using other sensor configurations and improvements of computational issues at the training step of the method.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







