
A Novel Wearable Sensor-Based Human Activity Recognition Approach Using Artificial Hydrocarbon Networks



Abstract
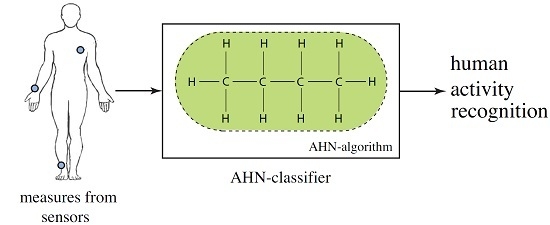
:
1. Introduction
2. Sensor-Based Human Activity Recognition
2.1. Noise in the Human Activity Recognition Classification Process
- Developing learning techniques that effectively and efficiently deal with noisy types of data is a key aspect in machine learning.
- There is a need for comparisons of the effect of noise on different learning paradigms.
2.2. Machine Learning Techniques Used for Human Activity Recognition
- “The variability in activities, sensors and features means that it is not possible to directly compare classification accuracies between different studies.”
- “... there is no classifier which performs optimally for a given activity classification problem.”
- “... there is a need for further studies investigating the relative performance of the range of different classifiers for different activities and sensor features and with large numbers of subjects.”
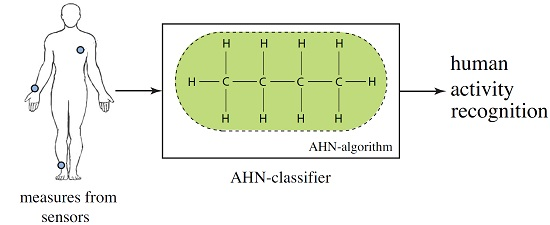
3. Artificial Hydrocarbon Networks as a Supervised Learning Method
3.1. Artificial Organic Networks
3.2. Artificial Hydrocarbon Networks Algorithm
| Algorithm 1 AHN algorithm for saturated and linear hydrocarbon compounds. |
| Input: a training dataset , the number of molecules in the compound and a tolerance value . |
| Output: the saturated and linear hydrocarbon compound . |
| Initialize an empty compound . |
| Create a new saturated linear compound C like Equation (2). |
| Randomly initialize intermolecular distances . |
| while do |
| Determine all bounds of C using . |
| for each j-th molecule in C do |
| Determine all parameters of behavior in Equation (1) using an optimization process. |
| end-for |
| Build the compound behavior ψ of C using Equation (3). |
| Update intermolecular distances using Equations (4) and (5). |
| end-while |
| Update with C and ψ. |
| return |
3.3. Characteristics of Artificial Hydrocarbon Networks
- Stability: This characteristic considers that the artificial hydrocarbon networks algorithm minimizes the changes in its output response when inputs are slightly changed [27]. This is the main characteristic that promotes using AHN as a supervised learning method.
- Robustness: This characteristic implies that artificial hydrocarbon networks can deal with uncertain or noisy data. The literature reports that AHN can deal with noisy data as it filters information, e.g., AHN has been used in audio filtering [27,31]. Additionally, ensembles of artificial hydrocarbon networks and fuzzy inference systems can also deal with uncertain data, for example in intelligent control systems, like in [29,30].
- Metadata: Molecular parameters like bounds, intermolecular distances and hydrogen values can be used as metadata to partially understand underlying information or to extract features. In [27], it reports that the artificial organic networks method packages information in several molecules that might be interpreted as subsystems in the overall domain. For example, these metadata have been used in facial recognition approaches [27].
4. Artificial Hydrocarbon Networks-Based Classifier for HAR Systems
5. Case Study: Physical Activity Monitoring Using Artificial Hydrocarbon Networks
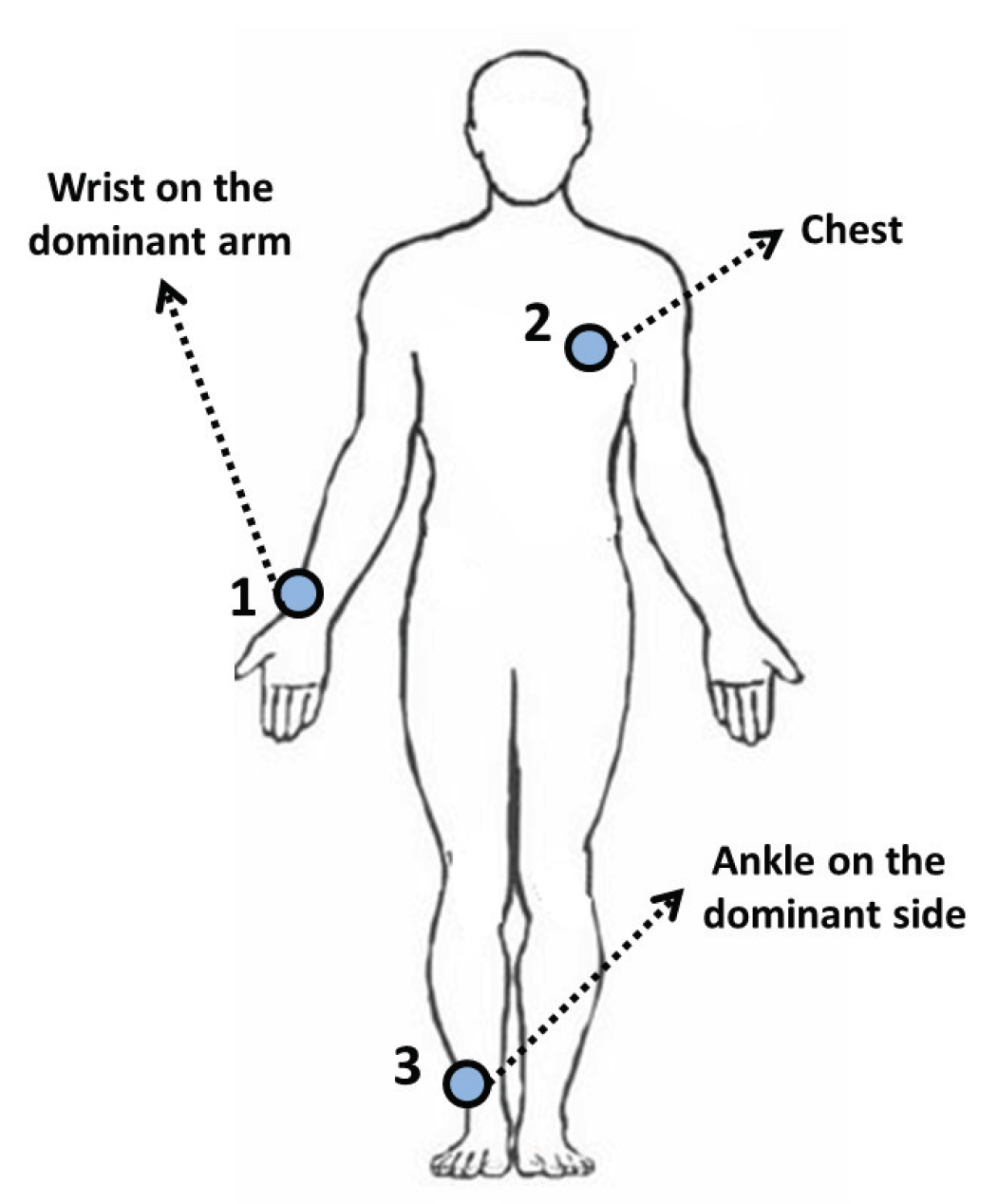
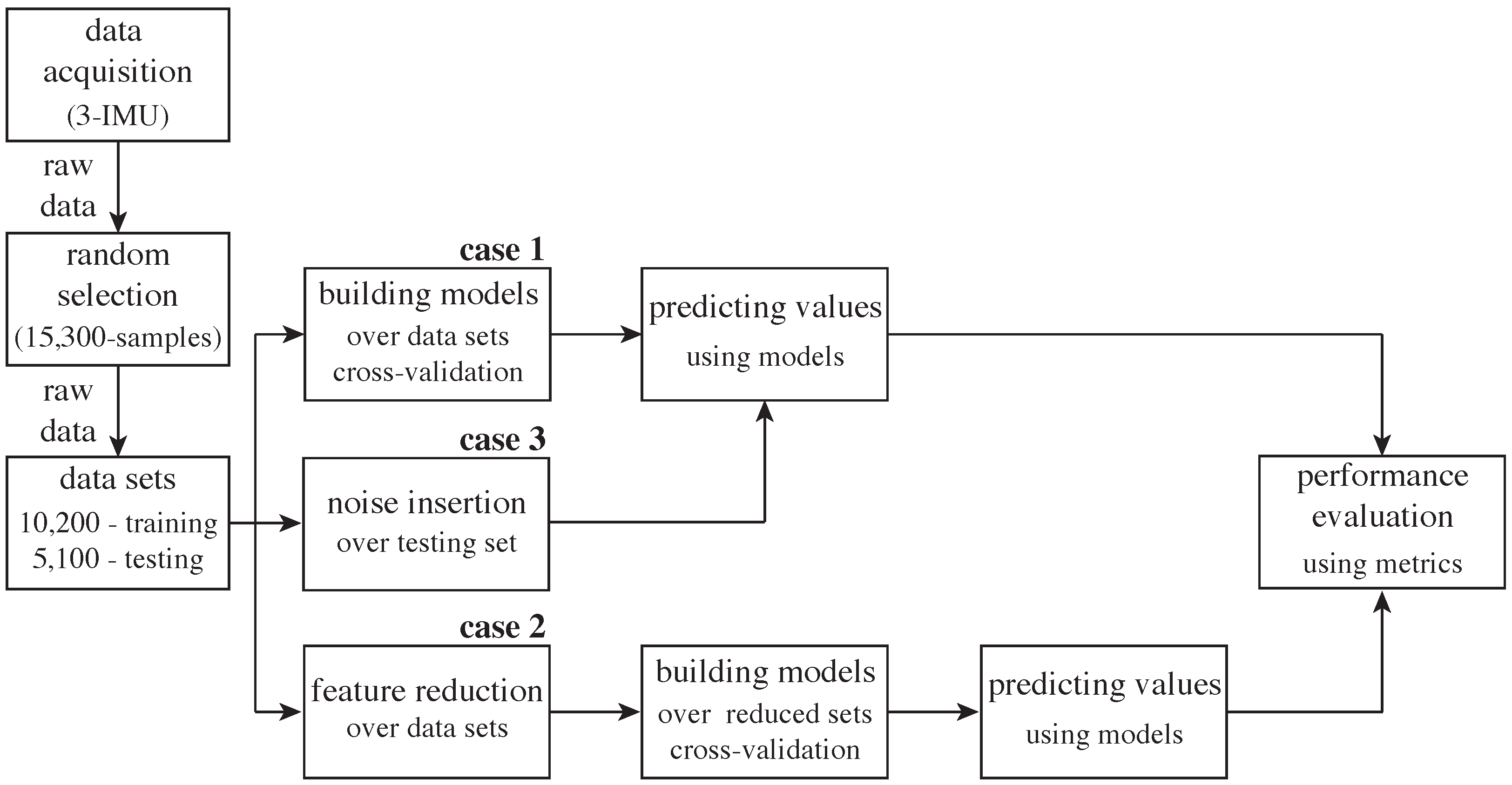
5.1. Dataset Description
5.2. Methodology for Building Supervised Models
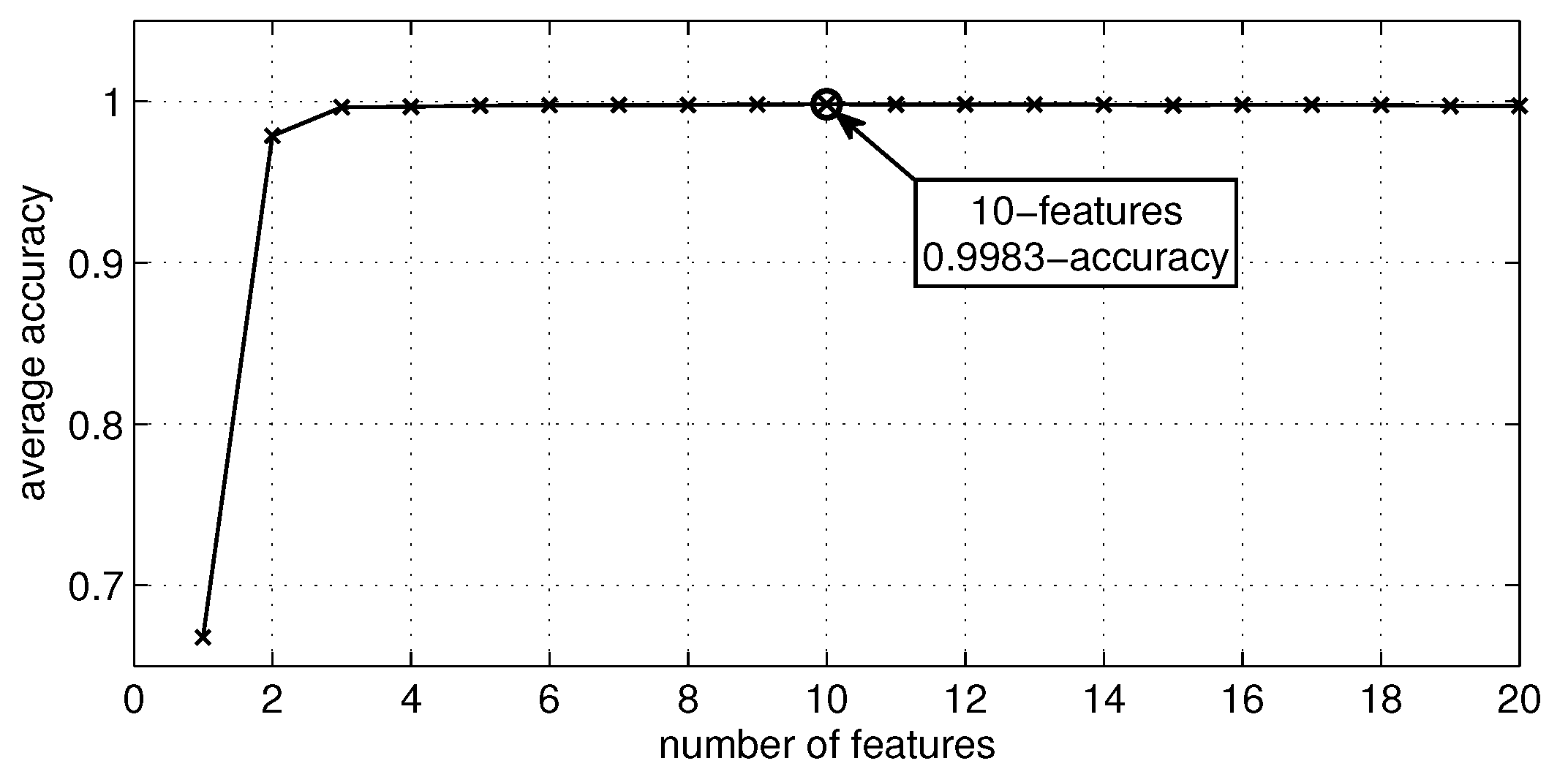
- Case 2: This experiment conducts a feature reduction over the feature set of the previous case, using the well-known recursive feature elimination (RFE) method [34,35]. Table 4 shows the ten retained features, and Figure 4 shows the accuracy curve of its validation. In fact, this experiment aims to compute human activity recognition with the minimal set of raw signals from the sensors’ channels, since minimizing the number of sensors and the usage of their channels is a challenging problem in HAR [9]. The features retained from the initial set of features by the automatic RFE method can apparently contain presumably redundant features (e.g., accelerometers 16 g and 6 g) or some variables that presumably can lead to overfitting. Regarding these two concerns, Guyon et al. [35] proved with simple examples that “noise reduction and consequently better separation may be obtained by adding variables that are presumably redundant” [35]. Thus, sometimes, variables that are apparently redundant, as in our case, can enhance the prediction power when they are combined. At last, the same measures of classification, recognition and monitoring performance were computed.
- Case 3: This experiment evaluates noise tolerance in all supervised classifiers using noisy datasets. For instance, Zhu and Wu [36] describe different types of noise generation: in the input attributes and/or in the output class; in training data and/or in test data; in the most noise-sensitive attribute or in all attributes at once. Thus, we decided to generate noise only in some input feature values of some samples of the testing dataset. In order to add noise in a numeric attribute, the authors in [36] suggest selecting a random value that is between the maximal and the minimal values of the feature. For our experimentation, we first randomly removed some feature values using a 7%, 15% and 30% data selection in order to simulate missing values and then automatically replaced the null values with the mean of the related feature, as some data mining tools suggest [37]. In fact, this method can be considered as random noise insertion, given that generated missing data are replaced with a value. Notice that supervised models built for this experiment are the same classifiers as those built in the first experiment.
5.3. Metrics
6. Experimental Results and Discussion
6.1. Comparative Analysis on Physical Activity Monitoring
6.2. Comparative Analysis on Supervised Model Performance under Noisy Data
6.3. Comparative Analysis on the Majority Voting Across Windows-Based Strategy
6.4. Discussion
7. Conclusions and Future Work
Author Contributions
Conflicts of Interest
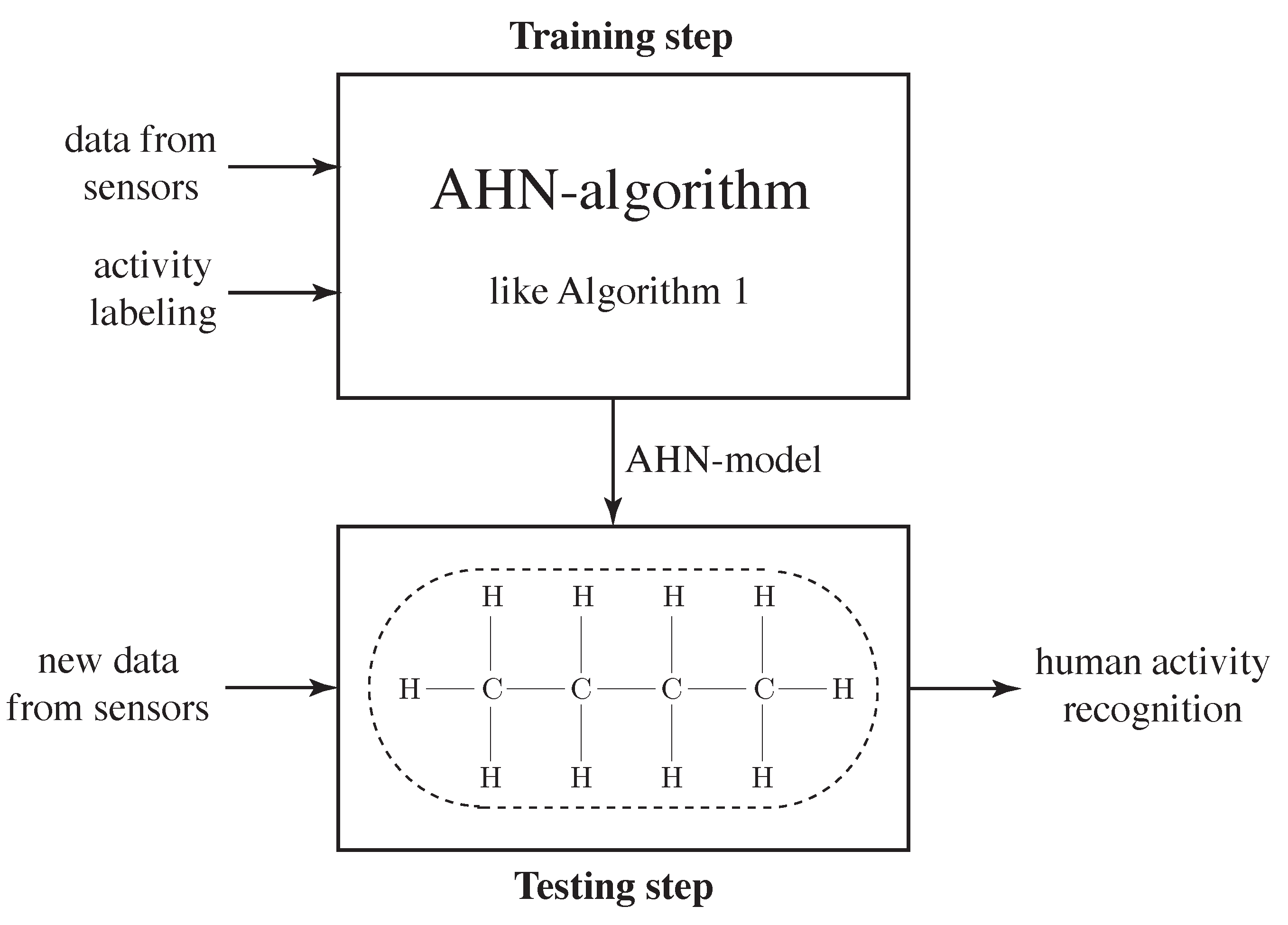
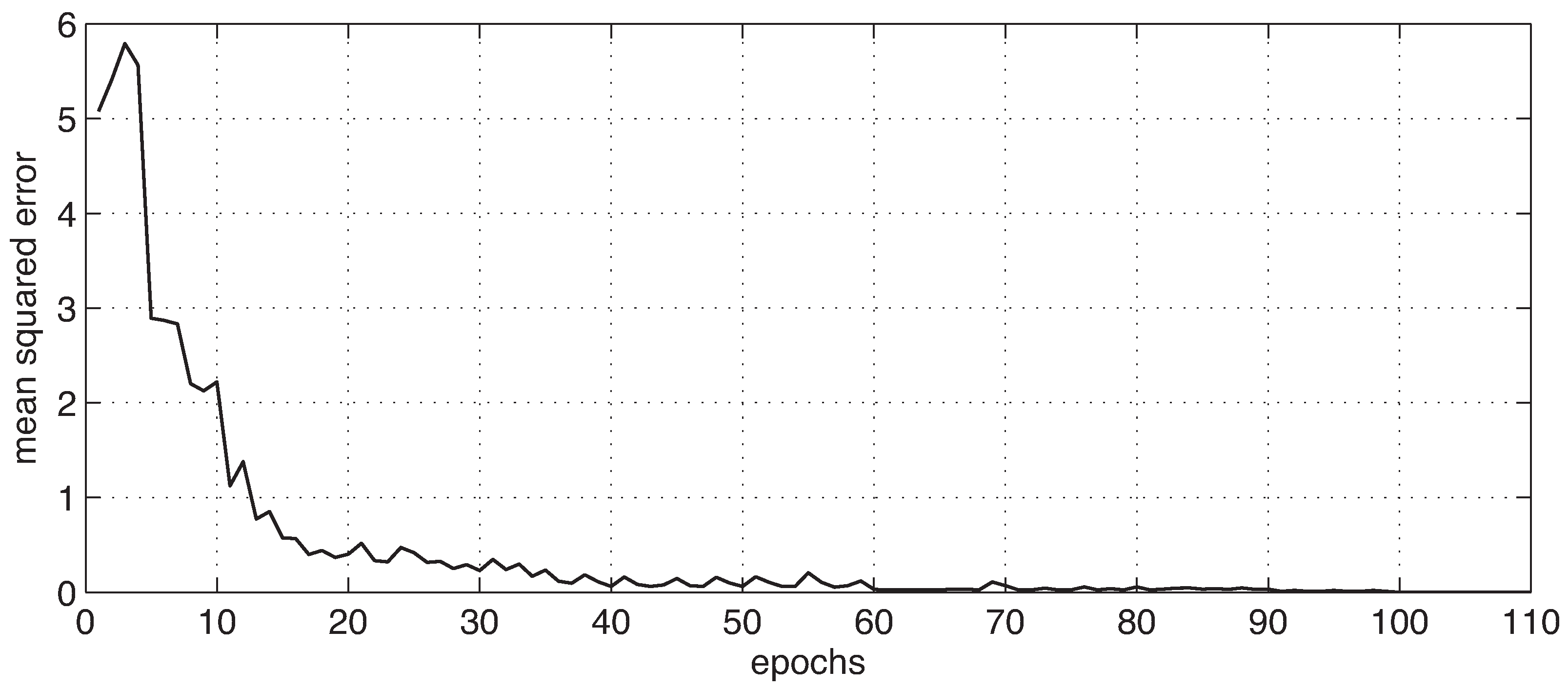
Appendix A. Artificial Hydrocarbon Networks: A Numerical Example
Appendix A.1. Training Step

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. Sample | y | No. Sample | y | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 4.3213 | 3.6221 | 5.0002 | 1 | 11 | 6.9039 | 4.9760 | 3.3688 | 2 | |
| 2 | 4.2141 | 2.3912 | 6.8321 | 1 | 12 | 7.3675 | 2.3451 | 3.5782 | 2 | |
| 3 | 4.3803 | 6.7115 | 6.8618 | 1 | 13 | 7.4727 | 4.6783 | −4.3858 | 2 | |
| 4 | 3.6646 | 3.5900 | 6.4806 | 1 | 14 | 7.7866 | 5.0108 | 3.4829 | 2 | |
| 5 | 3.2687 | 6.6652 | 6.3268 | 1 | 15 | 6.9858 | 6.8510 | 0.7049 | 2 | |
| 6 | 3.6156 | 4.5413 | 6.6895 | 1 | 16 | 6.8830 | 15.7787 | −3.0057 | 3 | |
| 7 | 3.3436 | 5.9303 | 6.4620 | 1 | 17 | 7.5271 | 17.8117 | −3.1938 | 3 | |
| 8 | 4.4932 | 3.3761 | 5.4943 | 1 | 18 | 7.7992 | 16.9416 | −2.3485 | 3 | |
| 9 | 4.8778 | 2.0918 | 5.5466 | 1 | 19 | 6.9773 | 16.6224 | −2.2307 | 3 | |
| 10 | 4.9102 | 5.1102 | 5.4166 | 1 | 20 | 7.0529 | 17.0954 | 0.4050 | 3 |
Appendix A.1.1. Define the Training Set
Appendix A.1.2. Determine Configuration Parameters
Appendix A.1.3. Run AHN-Algorithm
| t | |||
|---|---|---|---|
| 1 | (−0.04, 0.33, −0.01) | (3.27, 3.23, 3.56, 3.54) | (0.11, 0.48, 0.14) |
| 2 | (0.36, 0.53, 0.71) | (3.62, 3.98, 4.51, 5.22) | (0.16, 0.33, 0.51) |
| 3 | (0.06, 0.14, 0.15) | (−4.39, −4.32, −4.19, −4.04) | (0.21, 0.29, 0.30) |
| Parameters | Values |
|---|---|
| (0.0, 0.0, 10.94; 0.0, 0.0, 26.99; 0.0, 0.0, 0.0) | |
| (0.0, 0.0; 0.0, 16.02) | |
| (0.0, 0.0, 10.94; 0.0, 0.0, 26.99; 0.0, 0.0, 0.0) | |
| σ | (1, 1, 0) |
| L | (3.27, 3.38, 3.86, 3.99) |
| (3.62, 3.78, 4.11, 4.62) | |
| (−4.39, −4.17, −3.89, −3.59) |
Appendix A.2. Testing Step
| No Sample | y | |
|---|---|---|
| 2 | 1 | 1 |
| 3 | 1 | 1 |
| 4 | 1 | 1 |
| 8 | 1 | 1 |
| 9 | 1 | 1 |
| 10 | 1 | 1 |
| 11 | 2 | 2 |
| 12 | 2 | 2 |
| 17 | 3 | 3 |
| 20 | 3 | 3 |
References
- Avci, A.; Bosch, S.; Marin-Perianu, M.; Marin-Perianu, R.; Havinga, P. Activity recognition using inertial sensing for healthcare, wellbeing and sports applications: A survey. In Proceedings of the 23rd International Conference on Architecture of Computing Systems, Hannover, Germany, 22–25 February 2010; pp. 1–10.
- Preece, S.J.; Goulermas, J.Y.; Kenney, L.P.; Howard, D.; Meijer, K.; Crompton, R. Activity identification using body-mounted sensors-a review of classification techniques. Physiol. Meas. 2009, 30, 1–33. [Google Scholar] [CrossRef] [PubMed]
- Guidoux, R.; Duclos, M.; Fleury, G.; Lacomme, P.; Lamaudiere, N.; Maneng, P.; Paris, L.; Ren, L.; Rousset, S. A Smartphone-driven methodology for estimating physical activities and energy expenditure in free livng conditions. J. Biomed. Inform. 2014, 52, 271–278. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Hoey, J.; Nugent, C.D.; Cook, D.J.; Yu, Z. Sensor-based activity recognition. IEEE Trans. Syst. Man. Cybern. C Appl. Rev. 2012, 42, 790–808. [Google Scholar] [CrossRef]
- Ugulino, W.; Cardador, D.; Vega, K.; Velloso, E.; Milidiú, R.; Fuks, H. Wearable computing: Accelerometers’ data classification of body postures and movements. In Advances in Artificial Intelligence—SBIA 2012; Springer: Berlin, Germany; Heidelberg, Germany, 2012; pp. 52–61. [Google Scholar]
- Reyes, J. Smartphone-Based Human Activity Recognition; Springer Theses; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Bouarfa, L.; Jonker, P.; Dankelman, J. Discovery of high-level tasks in the operating room. J. Biomed. Inform. 2011, 44, 455–462. [Google Scholar] [CrossRef] [PubMed]
- Nettleton, D.F.; Orriols-Puig, A.; Fornells, A. A study of the effect of different types of noise on the precision of supervised learning techniques. Artif. Intell. Rev. 2010, 33, 275–306. [Google Scholar] [CrossRef]
- Lara, O.D.; Labrador, M.A. A survey on human activity recognition using wearable sensors. IEEE Commun. Surv. Tutor. 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Roggen, D.; Calatroni, A.; Rossi, M.; Holleczek, T.; Förster, K.; Tröster, G.; Lukowicz, P.; Bannach, D.; Pirkl, G.; Ferscha, A.; et al. Collecting complex activity datasets in highly rich networked sensor environments. In Proceedings of the IEEE Seventh International Conference on Networked Sensing Systems, Kassel, Germany, 15–18 June 2010; pp. 233–240.
- Dohnálek, P.; Gajdoš, P.; Moravec, P.; Peterek, T.; SnáŠel, V. Application and comparison of modified classifiers for human activity recognition. Prz. Elektrotech. 2013, 89, 55–58. [Google Scholar]
- Reiss, A.; Stricker, D. Introducing a new benchmarked dataset for activity monitoring. In Proceedings of the IEEE 16th International Symposium on Wearable Computers (ISWC), Newcastle, UK, 18–22 June 2012; pp. 108–109.
- Reiss, A.; Stricker, D. PAMAP2 physical activity monitoring monitoring data set. In Dataset from the Department Augmented Vision, DFKI, Saarbrücken, Germany, August 2012.
- Gordon, D.; Schmidtke, H.; Beigl, M. Introducing new sensors for activity recognition. In Proceedings of the Workshop on How to Do Good Research in Activity Recognition at the 8th International Conference on Pervasive Computing, Helsinki, Finland, 17 May 2010; pp. 1–4.
- Ravi, N.; Dandekar, N.; Mysore, P.; Littman, M.L. Activity recognition from accelerometer data. In Proceedings of the 17th Conference on Innovative Applications of Artificial Intelligence (IAAI), Pittsburgh, PA, USA, 9–13 July 2005; AAAI Press: Pittsburgh, PA, USA, 2005; Volume 3, pp. 1541–1546. [Google Scholar]
- Mannini, A.; Sabatini, A.M. Machine learning methods for classifying human physical activity from on-body accelerometers. Sensors 2010, 10, 1154–1175. [Google Scholar] [CrossRef] [PubMed]
- Sagha, H.; Digumarti, S.T.; Millán, J.D.R.; Chavarriaga, R.; Calatroni, A.; Roggen, D.; Tröster, G. Benchmarking classification techniques using the opportunity human activity dataset. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Anchorage, AK, USA, 9–12 October 2011; IEEE: Anchorage, AK, USA, 2011; pp. 36–40. [Google Scholar]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J. A survey of online activity recognition using mobile phones. Sensors 2015, 15, 2059–2085. [Google Scholar] [CrossRef] [PubMed]
- Vishwakarma, S.; Agrawal, A. A survey on activity recognition and behavior understanding in video surveillance. Vis. Comput. 2013, 29, 983–1009. [Google Scholar] [CrossRef]
- Chavarriaga, R.; Roggen, D.; Ferscha, A. Workshop on Robust Machine Learning Techniques for Human Activity Recognition; IEEE: Anchorage, AK, USA, 2011. [Google Scholar]
- Ponce, H.; Martinez-Villaseñor, L.; Miralles-Pechuan, L. Comparative Analysis of Artificial Hydrocarbon Networks and Data-Driven Approaches for Human Activity Recognition, Lecture Notes in Computer Science; Springer: Berlin, Germany; Heidelberg, Germany, 2015; Volume 9454, pp. 150–161. [Google Scholar]
- Lara, O. On the Automatic Recognition of Human Activities Using Heterogeneous Wearable Sensors. Ph.D. Thesis, University of South California, Los Angeles, CA, USA, 2012. [Google Scholar]
- Luštrek, M.; Kaluža, B. Fall detection and activity recognition with machine learning. Informatica 2009, 33, 205–212. [Google Scholar]
- Ross, R.; Kelleher, J. A Comparative Study of the Effect of Sensor Noise on Activity Recognition Models. In Evolving Ambient Intelligence; Springer: Berlin/Heidelberg, Germany, 2013; pp. 151–162. [Google Scholar]
- Chavarriaga, R.; Sagha, H.; Calatroni, A.; Digumarti, S.T.; Tröster, G.; Millán, J.D.R.; Roggen, D. The Opportunity challenge: A benchmark database for on-body sensor-based activity recognition. Pattern Recognit. Lett. 2013, 34, 2033–2042. [Google Scholar] [CrossRef]
- Ponce, H.; Ayala-Solares, R. The Power of Natural Inspiration in Control Systems; Studies in Systems, Decision and Control; Springer: Berlin/Heidelberg, Germany, 2016; Volume 40, pp. 1–10. [Google Scholar]
- Ponce, H.; Ponce, P.; Molina, A. Artificial Organic Networks: Artificial Intelligence Based on Carbon Networks; Studies in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2014; Volume 521. [Google Scholar]
- Ponce, H.; Ponce, P.; Molina, A. The Development of an Artificial Organic Networks Toolkit for LabVIEW. J. Comput. Chem. 2015, 36, 478–492. [Google Scholar] [CrossRef] [PubMed]
- Ponce, H.; Ponce, P.; Molina, A. A Novel Robust Liquid Level Controller for Coupled-Tanks Systems Using Artificial Hydrocarbon Networks. Expert Syst. Appl. 2015, 42, 8858–8867. [Google Scholar] [CrossRef]
- Ponce, H.; Ponce, P.; Molina, A. Artificial Hydrocarbon Networks Fuzzy Inference System. Math. Probl. Eng. 2013, 2013, 1–13. [Google Scholar] [CrossRef]
- Ponce, H.; Ponce, P.; Molina, A. Adaptive Noise Filtering Based on Artificial Hydrocarbon Networks: An Application to Audio Signals. Expert Syst. Appl. 2014, 41, 6512–6523. [Google Scholar] [CrossRef]
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial on human activity recognition using body-worn inertial sensors. ACM Comput. Surv. 2014, 46, 1–33. [Google Scholar] [CrossRef]
- Attal, F.; Mohammed, S.; Dedabrishvili, M.; Chamroukhi, F.; Oukhellou, L.; Amirat, Y. Physical Human Activity Recognition Using Wearable Sensors. Sensors 2015, 15, 31314–31338. [Google Scholar] [CrossRef] [PubMed]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Zhu, X.; Wu, X. Class Noise vs. Attribute Noise: A quantitative Study. Artif. Intell. Rev. 2004, 22, 177–210. [Google Scholar] [CrossRef]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA Data Mining Software: An Update. SIGKDD Explor. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]








| Framework Level | Description |
|---|---|
| implementation | training and inference |
| mathematical model | structure and functionality |
| chemical heuristic rules | first molecules, then compounds, lastly mixtures |
| interactions | bonds in atoms and molecules, relations in compounds |
| types of components | atoms, molecules, compounds, mixtures |
| No. | Performed Activities | Activity Description |
|---|---|---|
| 1 | Lying | This movement is lying flat, slightly changing position or stretching a little bit. |
| 2 | Sitting | Refers to sitting in a chair in any posture. It also includes more comfortable positions as leaning or crossing your legs. |
| 3 | Standing | This position includes the natural movements of a person who is standing, swaying slightly, gesturing or talking. |
| 4 | Walking | This activity is a stroll down the street at a moderate speed of approximately 5 km/h. |
| 5 | Running | The people who made this activity ran at a moderate speed; taking into account non-high level athletes. |
| 6 | Cycling | A bicycle was used for this movement, and people pedaled as on a quiet ride. An activity requiring great effort was not requested. |
| 7 | Nordic walking | For this activity, it was required that persons that were inexperienced walked on asphalt using pads. |
| 8 | Watching TV | This position includes the typical movements of someone who is watching TV and changes the channel, lying on one side or stretching his or her legs. |
| 9 | Computer work | The typical movements of someone who works with a computer: mouse movement, movement of neck, etc. |
| 10 | Car driving | All movements necessary to move from the office to the house for testing sensors. |
| 11 | Ascending stairs | During this activity, the necessary movements up to a distance of five floors were recorded; from the ground floor to the fifth floor. |
| 12 | Descending stairs | This movement is the opposite of the former. Instead of climbing the stairs, the activity of descending them was recorded. |
| 13 | Vacuum cleaning | Refers to all of the activities necessary to clean a floor of the office. It also includes moving objects, such as rugs, chairs and wardrobes. |
| 14 | Ironing | It covers the necessary movements to iron a shirt or a t-shirt. |
| 15 | Folding laundry | It consists of folding clothes, such as shirts, pants and socks. |
| 16 | House cleaning | These are the movements that a person makes while cleaning a house; such as moving chairs to clean the floor, throwing things away, bending over to pick up something, etc. |
| 17 | Playing soccer | In this activity, individuals are negotiating, running the ball, shooting a goal or trying to stop the ball from the goal. |
| 18 | Rope jumping | There are people who prefer to jump with both feet together, and there are others who prefer to move one foot first and then the other. |
| No. | Method Name | Parameters | Case 1 & Case 3 | Case 2 | Configurations |
|---|---|---|---|---|---|
| 1 | AdaBoost | size, decay, bag | (150, 3, 3) | (150, 3, 3) | 27 |
| 2 | Artificial Hydrocarbon Networks | molecules, eta, epsilon | (18, 0.1, 0.0001) | (18, 0.1, 0.0001) | 1 |
| 3 | C4.5 Decision Trees | c | (0.25) | (0.25) | 1 |
| 4 | k-Nearest Neighbors | kmax, distance, kernel | (9, 2, 1) | (9, 2, 1) | 3 |
| 5 | Linear Discriminant Analysis | – | – | – | 1 |
| 6 | Mixtures Discriminant Analysis | subclasses | (4) | (4) | 3 |
| 7 | Multivariate Adaptive Regression Splines | degree | (1) | (1) | 1 |
| 8 | Naive Bayes | fl, use_kernel | (0, true) | (0, true) | 2 |
| 9 | Nearest Shrunken Centroids | threshold | (2.512) | (1.363) | 3 |
| 10 | Artificial Neural Networks | size, decay | (5, 0) | (5, 0) | 9 |
| 11 | Random Forest | mtry | (26) | (6) | 3 |
| 12 | Rule-Based Classifier | threshold, pruned | (0.25, true) | (0.25, true) | 1 |
| 13 | Stochastic Gradient Boosting | n.trees, depth, shrinkage | (150, 3, 0.1) | (150, 2, 0.1) | 9 |
| 14 | SVM with Linear Kernel | c | (1) | (1) | 1 |
| 15 | SVM with Radial Basis Function Kernel | sigma, c | (0.0179, 1) | (0.0748, 1) | 3 |
| Sensor | Features Selected | Feature Number |
|---|---|---|
| hand | temperature | 4 |
| chest | temperature | 21 |
| z-axis 3D-accelerometer 16 g | 24 | |
| z-axis 3D-accelerometer 6 g | 27 | |
| y-axis 3D-magnetometer | 32 | |
| z-axis 3D-magnetometer | 33 | |
| ankle | temperature | 38 |
| x-axis 3D-magnetometer | 48 | |
| z-axis 3D-magnetometer | 50 | |
| first orientation | 51 |
| Activities | Sub 1 | Sub 2 | Sub 3 | Sub 4 | Sub 5 | Sub 6 | Sub 7 | Sub 8 | Sub 9 | Total |
|---|---|---|---|---|---|---|---|---|---|---|
| Lying | - | - | - | - | - | - | - | - | 8 | |
| Sitting | - | - | - | - | - | - | - | - | 8 | |
| Standing | - | - | - | - | - | - | - | - | 8 | |
| Walking | - | - | - | - | - | - | - | - | 8 | |
| Running | - | - | - | - | - | 5 | ||||
| Cycling | - | - | - | - | - | - | - | 7 | ||
| Nordic walking | - | - | - | - | - | - | - | 7 | ||
| Watching TV | - | 1 | ||||||||
| Computer work | - | - | - | - | 4 | |||||
| Car driving | - | 1 | ||||||||
| Ascending stairs | - | - | - | - | - | - | - | - | 8 | |
| Descending stairs | - | - | - | - | - | - | - | - | 8 | |
| Vacuum cleaning | - | - | - | - | - | - | - | - | 8 | |
| Ironing | - | - | - | - | - | - | - | - | 8 | |
| Folding laundry | - | - | - | - | 4 | |||||
| House cleaning | - | - | - | - | - | 5 | ||||
| Playing soccer | - | - | 2 | |||||||
| Rope jumping | - | - | - | - | - | 5 |
| No. | Method Name | Accuracy | Sensitivity | Precision | -Score | Sensitivity | Precision | -Score |
|---|---|---|---|---|---|---|---|---|
| 1 | C4.5 Decision Trees | 0.9880 | 0.9994 | 0.9893 | 0.9943 | 0.9886 | 0.9885 | 0.9938 |
| 2 | Rule-Based Classifier | 0.9876 | 0.9993 | 0.9890 | 0.9942 | 0.9883 | 0.9882 | 0.9937 |
| 3 | Artificial Hydrocarbon Networks | 0.9829 | 0.9829 | 0.9831 | 0.9910 | 0.9830 | 0.9832 | 0.9910 |
| 4 | SVM with Linear Kernel | 0.9827 | 0.9989 | 0.9828 | 0.9908 | 0.9833 | 0.9834 | 0.9911 |
| 5 | SVM with Radial Basis Function Kernel | 0.9745 | 0.9985 | 0.9752 | 0.9867 | 0.9746 | 0.9747 | 0.9865 |
| 6 | Random Forest | 0.9727 | 0.9986 | 0.9819 | 0.9902 | 0.9743 | 0.9797 | 0.9890 |
| 7 | Stochastic Gradient Boosting | 0.9725 | 0.9725 | 0.9805 | 0.9893 | 0.9740 | 0.9815 | 0.9899 |
| 8 | k-Nearest Neighbors | 0.9718 | 0.9984 | 0.9724 | 0.9852 | 0.9711 | 0.9717 | 0.9849 |
| 9 | Mixture Discriminant Analysis | 0.9714 | 0.9982 | 0.9717 | 0.9848 | 0.9724 | 0.9729 | 0.9854 |
| 10 | AdaBoost | 0.9710 | 0.9982 | 0.9774 | 0.9877 | 0.9726 | 0.9780 | 0.9880 |
| 11 | Multivariate Adaptive Regression Splines | 0.9553 | 0.9974 | 0.9621 | 0.9794 | 0.9572 | 0.9609 | 0.9788 |
| 12 | Linear Discriminant Analysis | 0.9382 | 0.9962 | 0.9398 | 0.9672 | 0.9399 | 0.9418 | 0.9683 |
| 13 | Naive Bayes | 0.9327 | 0.9962 | 0.9459 | 0.9704 | 0.9350 | 0.9438 | 0.9692 |
| 14 | Artificial Neural Networks | 0.8976 | 0.9939 | 0.9019 | 0.9457 | 0.8984 | 0.9020 | 0.9458 |
| 15 | Nearest Shrunken Centroids | 0.7031 | 0.9820 | 0.7006 | 0.8178 | 0.7073 | 0.7063 | 0.8218 |
| Average | 0.9468 | 0.9941 | 0.9502 | 0.9716 | 0.9480 | 0.9504 | 0.9718 |
| No. | Method Name | Accuracy | Sensitivity | Precision | -Score | Sensitivity | Precision | -Score |
|---|---|---|---|---|---|---|---|---|
| 1 | Stochastic Gradient Boosting | 0.9898 | 0.9898 | 0.9907 | 0.9950 | 0.9900 | 0.9900 | 0.9947 |
| 2 | Artificial Hydrocarbon Networks | 0.9741 | 0.9741 | 0.9746 | 0.9864 | 0.9744 | 0.9741 | 0.9861 |
| 3 | AdaBoost | 0.9657 | 0.9979 | 0.9674 | 0.9824 | 0.9675 | 0.9686 | 0.9831 |
| 4 | Random Forest | 0.9655 | 0.9982 | 0.9768 | 0.9874 | 0.9673 | 0.9744 | 0.9861 |
| 5 | Rule-Based Classifier | 0.9604 | 0.9979 | 0.9716 | 0.9846 | 0.9617 | 0.9693 | 0.9833 |
| 6 | C4.5 Decision Trees | 0.9571 | 0.9976 | 0.9647 | 0.9809 | 0.9586 | 0.9629 | 0.9799 |
| 7 | k-Nearest Neighbors | 0.7222 | 0.9834 | 0.7217 | 0.8325 | 0.7291 | 0.7255 | 0.8351 |
| 8 | Multivariate Adaptive Regression Splines | 0.7061 | 0.9825 | 0.7357 | 0.8413 | 0.7159 | 0.7392 | 0.8437 |
| 9 | SVM with Radial Basis Function Kernel | 0.6549 | 0.9791 | 0.6526 | 0.7832 | 0.6619 | 0.6601 | 0.7887 |
| 10 | Naive Bayes | 0.6069 | 0.9758 | 0.6506 | 0.7807 | 0.6125 | 0.6615 | 0.7888 |
| 11 | Mixture Discriminant Analysis | 0.5853 | 0.9750 | 0.5684 | 0.7181 | 0.5929 | 0.5746 | 0.7232 |
| 12 | SVM with Linear Kernel | 0.5386 | 0.9720 | 0.5196 | 0.6772 | 0.5487 | 0.5296 | 0.6858 |
| 13 | Artificial Neural Networks | 0.5092 | 0.9703 | 0.4631 | 0.6270 | 0.5190 | 0.4716 | 0.6349 |
| 14 | Linear Discriminant Analysis | 0.4792 | 0.9683 | 0.4676 | 0.6307 | 0.4853 | 0.4773 | 0.6396 |
| 15 | Nearest Shrunken Centroids | 0.4216 | 0.9645 | 0.4131 | 0.5784 | 0.4191 | 0.4209 | 0.5863 |
| Average | 0.7358 | 0.9818 | 0.7359 | 0.8257 | 0.7403 | 0.7400 | 0.8293 |
| No. | Method Name | Accuracy | Sensitivity | Precision | -Score | Sensitivity | Precision | -Score |
|---|---|---|---|---|---|---|---|---|
| 1 | Random Forest | 0.9825 | 0.9990 | 0.9830 | 0.9909 | 0.9833 | 0.9830 | 0.9909 |
| 2 | Stochastic Gradient Boosting | 0.9722 | 0.9722 | 0.9754 | 0.9868 | 0.9733 | 0.9747 | 0.9864 |
| 3 | Artificial Hydrocarbon Networks | 0.9696 | 0.9696 | 0.9700 | 0.9839 | 0.9691 | 0.9696 | 0.9837 |
| 4 | Rule-Based Classifier | 0.9484 | 0.9970 | 0.9532 | 0.9747 | 0.9497 | 0.9521 | 0.9740 |
| 5 | C4.5 Decision Trees | 0.9459 | 0.9969 | 0.9519 | 0.9739 | 0.9478 | 0.9507 | 0.9732 |
| 6 | SVM with Radial Basis Function Kernel | 0.9276 | 0.9957 | 0.9281 | 0.9607 | 0.9278 | 0.9285 | 0.9609 |
| 7 | AdaBoost | 0.9151 | 0.9949 | 0.9242 | 0.9582 | 0.9181 | 0.9256 | 0.9590 |
| 8 | k-Nearest Neighbors | 0.9059 | 0.9944 | 0.9066 | 0.9484 | 0.9060 | 0.9075 | 0.9490 |
| 9 | Mixture Discriminant Analysis | 0.8816 | 0.9928 | 0.8830 | 0.9347 | 0.8831 | 0.8856 | 0.9362 |
| 10 | SVM with Linear Kernel | 0.8796 | 0.9928 | 0.8786 | 0.9322 | 0.8800 | 0.8792 | 0.9326 |
| 11 | Multivariate Adaptive Regression Splines | 0.8755 | 0.9924 | 0.9055 | 0.9469 | 0.8759 | 0.9083 | 0.9486 |
| 12 | Linear Discriminant Analysis | 0.8339 | 0.9899 | 0.8367 | 0.9069 | 0.8353 | 0.8398 | 0.9088 |
| 13 | Artificial Neural Networks | 0.7820 | 0.9870 | 0.7764 | 0.8691 | 0.7842 | 0.7782 | 0.8703 |
| 14 | Naive Bayes | 0.7769 | 0.9868 | 0.7957 | 0.8810 | 0.7811 | 0.7964 | 0.8815 |
| 15 | Nearest Shrunken Centroids | 0.6202 | 0.9771 | 0.6076 | 0.7493 | 0.6235 | 0.6125 | 0.7531 |
| Average | 0.8811 | 0.9892 | 0.8851 | 0.9332 | 0.8825 | 0.8861 | 0.9339 |
| No. | Method Name | Accuracy | Sensitivity | Precision | -Score | Sensitivity | Precision | -Score |
|---|---|---|---|---|---|---|---|---|
| 1 | Artificial Hydrocarbon Networks | 0.9547 | 0.9547 | 0.9596 | 0.9781 | 0.9546 | 0.9592 | 0.9779 |
| 2 | k-Nearest Neighbors | 0.9425 | 0.9425 | 0.9433 | 0.9692 | 0.9418 | 0.9433 | 0.9692 |
| 3 | SVM with Radial Basis Function Kernel | 0.9249 | 0.9249 | 0.9308 | 0.9621 | 0.9238 | 0.9314 | 0.9624 |
| 4 | Naive Bayes | 0.9182 | 0.9182 | 0.9343 | 0.9638 | 0.9209 | 0.9328 | 0.9630 |
| 5 | Stochastic Gradient Boosting | 0.8402 | 0.8402 | 0.8729 | 0.9278 | 0.8387 | 0.8767 | 0.9302 |
| 6 | SVM with Linear Kernel | 0.8400 | 0.8400 | 0.8550 | 0.9177 | 0.8394 | 0.8579 | 0.9195 |
| 7 | Mixture Discriminant Analysis | 0.7975 | 0.7975 | 0.8113 | 0.8909 | 0.7986 | 0.8148 | 0.8931 |
| 8 | AdaBoost | 0.7755 | 0.7755 | 0.8209 | 0.8960 | 0.7724 | 0.8252 | 0.8988 |
| 9 | Random Forest | 0.7498 | 0.7498 | 0.8263 | 0.8986 | 0.7477 | 0.8313 | 0.9017 |
| 10 | Linear Discriminant Analysis | 0.7478 | 0.7478 | 0.7668 | 0.8622 | 0.7489 | 0.7710 | 0.8650 |
| 11 | Rule-Based Classifier | 0.7414 | 0.7414 | 0.8039 | 0.8851 | 0.7370 | 0.8043 | 0.8855 |
| 12 | C4.5 Decision Trees | 0.7335 | 0.7335 | 0.7984 | 0.8815 | 0.7290 | 0.8014 | 0.8835 |
| 13 | Multivariate Adaptive Regression Splines | 0.6824 | 0.6824 | 0.7610 | 0.8569 | 0.6791 | 0.7684 | 0.8619 |
| 14 | Nearest Shrunken Centroids | 0.6761 | 0.6761 | 0.6820 | 0.8044 | 0.6809 | 0.6884 | 0.8090 |
| 15 | Artificial Neural Networks | 0.5214 | 0.5214 | 0.5339 | 0.6892 | 0.5253 | 0.5307 | 0.6865 |
| Average | 0.7897 | 0.7897 | 0.8200 | 0.8922 | 0.7892 | 0.8225 | 0.8938 |
| No. | Method Name | Accuracy | Sensitivity | Precision | -Score | Sensitivity | Precision | -score |
|---|---|---|---|---|---|---|---|---|
| 1 | Naive Bayes | 0.8798 | 0.8798 | 0.9090 | 0.9491 | 0.8816 | 0.9087 | 0.9489 |
| 2 | Artificial Hydrocarbon Networks | 0.8786 | 0.8786 | 0.9052 | 0.9470 | 0.8793 | 0.9044 | 0.9466 |
| 3 | k-Nearest Neighbors | 0.8608 | 0.8608 | 0.8681 | 0.9257 | 0.8604 | 0.8708 | 0.9273 |
| 4 | SVM with Radial Basis Function Kernel | 0.8043 | 0.8043 | 0.8349 | 0.9051 | 0.8024 | 0.8374 | 0.9067 |
| 5 | Stochastic Gradient Boosting | 0.6967 | 0.6967 | 0.7822 | 0.8705 | 0.6950 | 0.7905 | 0.8759 |
| 6 | SVM with Linear Kernel | 0.6747 | 0.6747 | 0.7365 | 0.8410 | 0.6750 | 0.7419 | 0.8448 |
| 7 | Nearest Shrunken Centroids | 0.6302 | 0.6302 | 0.6605 | 0.7883 | 0.6354 | 0.6675 | 0.7935 |
| 8 | AdaBoost | 0.6302 | 0.6302 | 0.7315 | 0.8367 | 0.6249 | 0.7392 | 0.8421 |
| 9 | Mixture Discriminant Analysis | 0.6098 | 0.6098 | 0.6525 | 0.7823 | 0.6116 | 0.6579 | 0.7863 |
| 10 | Random Forest | 0.5514 | 0.5514 | 0.7378 | 0.8390 | 0.5474 | 0.7463 | 0.8449 |
| 11 | Rule-Based Classifier | 0.5496 | 0.5496 | 0.6913 | 0.8082 | 0.5446 | 0.6926 | 0.8093 |
| 12 | Linear Discriminant Analysis | 0.5449 | 0.5449 | 0.5988 | 0.7412 | 0.5483 | 0.6050 | 0.7461 |
| 13 | C4.5 Decision Trees | 0.5308 | 0.5308 | 0.6693 | 0.7925 | 0.5255 | 0.6760 | 0.7976 |
| 14 | Multivariate Adaptive Regression Splines | 0.4688 | 0.4688 | 0.6439 | 0.7731 | 0.4634 | 0.6548 | 0.7814 |
| 15 | Artificial Neural Networks | 0.4559 | 0.4559 | 0.5271 | 0.6824 | 0.4563 | 0.5295 | 0.6845 |
| Average | 0.6511 | 0.6511 | 0.7299 | 0.8321 | 0.6501 | 0.7348 | 0.8357 |
| No. | Method Name | Accuracy | Sensitivity | Precision | -Score | Sensitivity | Precision | -Score |
|---|---|---|---|---|---|---|---|---|
| 1 | Stochastic Gradient Boosting | 0.9952 | 0.9952 | 0.9996 | 0.9974 | 0.9963 | 0.9962 | 0.9980 |
| 2 | Random Forest | 0.9951 | 0.9951 | 0.9996 | 0.9974 | 0.9963 | 0.9959 | 0.9978 |
| 3 | Rule-Based Classifier | 0.9866 | 0.9866 | 0.9990 | 0.9928 | 0.9894 | 0.9857 | 0.9924 |
| 4 | Artificial Hydrocarbon Networks | 0.9845 | 0.9845 | 0.9991 | 0.9919 | 0.9844 | 0.9752 | 0.9870 |
| 5 | SVM with Radial Basis Function Kernel | 0.9635 | 0.9635 | 0.9973 | 0.9804 | 0.9698 | 0.9662 | 0.9818 |
| 6 | C4.5 Decision Trees | 0.9630 | 0.9630 | 0.9973 | 0.9797 | 0.9709 | 0.9652 | 0.9812 |
| 7 | Multivariate Adaptive Regression Splines | 0.9574 | 0.9574 | 0.9966 | 0.9778 | 0.9669 | 0.9673 | 0.9822 |
| 8 | AdaBoost | 0.9474 | 0.9474 | 0.9959 | 0.9736 | 0.9498 | 0.9621 | 0.9792 |
| 9 | SVM with Linear Kernel | 0.9441 | 0.9441 | 0.9958 | 0.9690 | 0.9550 | 0.9508 | 0.9732 |
| 10 | k-Nearest Neighbors | 0.9141 | 0.9140 | 0.9942 | 0.9530 | 0.9183 | 0.9122 | 0.9518 |
| 11 | Naive Bayes | 0.9093 | 0.9093 | 0.9939 | 0.9518 | 0.9208 | 0.9150 | 0.9532 |
| 12 | Artificial Neural Networks | 0.8879 | 0.8879 | 0.9923 | 0.9388 | 0.9032 | 0.8909 | 0.9393 |
| 13 | Mixture Discriminant Analysis | 0.8868 | 0.8868 | 0.9922 | 0.9379 | 0.9026 | 0.8914 | 0.9396 |
| 14 | Linear Discriminant Analysis | 0.7748 | 0.7748 | 0.9847 | 0.8700 | 0.7941 | 0.7797 | 0.8711 |
| 15 | Nearest Shrunken Centroids | 0.6199 | 0.6199 | 0.9727 | 0.7350 | 0.6285 | 0.5972 | 0.7414 |
| Average | 0.9153 | 0.9153 | 0.9940 | 0.9498 | 0.9231 | 0.9167 | 0.9513 |
| Actual Values | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lying | Sitting | Standing | Walking | Running | Cycling | Nordic walking | Watching TV | Computer Work | Car Driving | Ascending Stairs | Descending Stairs | Vacuum Cleaning | Ironing | Folding laundry | House Cleaning | Playing Soccer | Rope Jumping | ||
| Lying | 23985 | 19 | 1 | 22 | 30 | 7 | 13 | 3 | 0 | 6 | 0 | 10 | 0 | 0 | 0 | 0 | 3 | 0 | |
| Sitting | 13 | 23567 | 6 | 22 | 8 | 1 | 1 | 0 | 0 | 0 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 1 | |
| Standing | 0 | 20 | 23542 | 30 | 10 | 5 | 11 | 0 | 0 | 0 | 1 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Walking | 2 | 109 | 48 | 23567 | 19 | 16 | 38 | 0 | 0 | 0 | 7 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Running | 0 | 133 | 47 | 70 | 14760 | 14 | 78 | 0 | 0 | 0 | 7 | 11 | 1 | 0 | 0 | 0 | 1 | 0 | |
| Cycling | 0 | 47 | 75 | 85 | 19 | 20616 | 66 | 0 | 0 | 0 | 10 | 21 | 1 | 0 | 0 | 0 | 1 | 1 | |
| Nordic walking | 0 | 74 | 129 | 134 | 32 | 120 | 20676 | 0 | 65 | 3 | 43 | 41 | 14 | 2 | 0 | 7 | 3 | 1 | |
| Watching TV | 0 | 4 | 69 | 31 | 26 | 73 | 35 | 2961 | 35 | 10 | 27 | 29 | 17 | 2 | 0 | 19 | 1 | 1 | |
| Computer work | 0 | 4 | 18 | 17 | 21 | 51 | 21 | 33 | 11790 | 7 | 37 | 31 | 31 | 9 | 3 | 18 | 2 | 0 | |
| Car driving | 0 | 7 | 12 | 6 | 22 | 37 | 14 | 0 | 37 | 2957 | 49 | 50 | 41 | 20 | 1 | 27 | 4 | 2 | |
| Ascending stairs | 0 | 1 | 6 | 1 | 10 | 21 | 19 | 0 | 36 | 4 | 23638 | 55 | 66 | 42 | 9 | 11 | 6 | 2 | |
| Predicted values | Descending stairs | 0 | 0 | 2 | 3 | 10 | 10 | 10 | 0 | 17 | 1 | 64 | 23569 | 72 | 72 | 12 | 33 | 8 | 8 |
| Vacuum cleaning | 0 | 0 | 17 | 3 | 17 | 12 | 13 | 0 | 20 | 2 | 90 | 103 | 23684 | 190 | 70 | 90 | 30 | 40 | |
| Ironing | 0 | 7 | 26 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 7 | 16 | 30 | 23592 | 34 | 34 | 8 | 20 | |
| Folding laundry | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 6 | 20 | 24 | 41 | 11820 | 27 | 15 | 15 | |
| House cleaning | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 2 | 8 | 14 | 19 | 22 | 14690 | 11 | 14 | |
| Playing soccer | 0 | 0 | 0 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 6 | 12 | 5 | 9 | 28 | 32 | 5883 | 69 | |
| Rope jumping | 0 | 8 | 2 | 8 | 4 | 17 | 5 | 3 | 0 | 10 | 6 | 8 | 0 | 2 | 1 | 12 | 24 | 14826 | |
| No. | Method Name | Accuracy | Sensitivity | Precision | -Score | Sensitivity | Precision | -Score |
|---|---|---|---|---|---|---|---|---|
| 1 | Artificial Hydrocarbon Networks | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 2 | Rule-Based Classifier | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 3 | C4.5 Decision Trees | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 4 | Random Forest | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 5 | Stochastic Gradient Boosting | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 6 | k-Nearest Neighbors | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 7 | SVM with Radial Basis Function Kernel | 0.9841 | 0.9841 | 0.9846 | 0.9916 | 0.9873 | 0.9886 | 0.9938 |
| 8 | SVM with Linear Kernel | 0.9786 | 0.9786 | 0.9791 | 0.9887 | 0.9843 | 0.9821 | 0.9904 |
| 9 | Multivariate Adaptive Regression Splines | 0.9770 | 0.9770 | 0.9785 | 0.9882 | 0.9832 | 0.9844 | 0.9914 |
| 10 | AdaBoost | 0.9627 | 0.9627 | 0.9651 | 0.9808 | 0.9681 | 0.9732 | 0.9853 |
| 11 | Naive Bayes | 0.9571 | 0.9571 | 0.9604 | 0.9785 | 0.9651 | 0.9603 | 0.9785 |
| 12 | Artificial Neural Networks | 0.9460 | 0.9460 | 0.9478 | 0.9714 | 0.9570 | 0.9481 | 0.9718 |
| 13 | Mixture Discriminant Analysis | 0.9365 | 0.9365 | 0.9412 | 0.9677 | 0.9500 | 0.9421 | 0.9684 |
| 14 | Linear Discriminant Analysis | 0.8444 | 0.8444 | 0.8508 | 0.9148 | 0.8583 | 0.8528 | 0.9166 |
| 15 | Nearest Shrunken Centroids | 0.6857 | 0.6857 | 0.6593 | 0.7872 | 0.7018 | 0.6773 | 0.8014 |
| Average | 0.9515 | 0.9515 | 0.9511 | 0.9713 | 0.9570 | 0.9539 | 0.9732 |
| Actual Values | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lying | Sitting | Standing | Walking | Running | Cycling | Nordic Walking | Watching TV | Computer Work | Car Driving | Ascending Stairs | Descending Stairs | Vacuum Cleaning | Ironing | Folding Laundry | House Cleaning | Playing Soccer | Rope Jumping | ||
| Lying | 96 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Sitting | 0 | 96 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Standing | 0 | 0 | 96 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Walking | 0 | 0 | 0 | 96 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Running | 0 | 0 | 0 | 0 | 60 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Cycling | 0 | 0 | 0 | 0 | 0 | 84 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Nordic walking | 0 | 0 | 0 | 0 | 0 | 0 | 84 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Watching TV | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Computer work | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 48 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Car driving | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Ascending stairs | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 96 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Predicted values | Descending stairs | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 96 | 0 | 0 | 0 | 0 | 0 | 0 |
| Vacuum cleaning | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 96 | 0 | 0 | 0 | 0 | 0 | |
| Ironing | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 96 | 0 | 0 | 0 | 0 | |
| Folding laundry | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 48 | 0 | 0 | 0 | |
| House cleaning | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 60 | 0 | 0 | |
| Playing soccer | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 24 | 0 | |
| Rope jumping | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 60 | |
| Actual Values | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lying | Sitting | Standing | Walking | Running | Cycling | Nordic Walking | Watching TV | Computer Work | Car Driving | Ascending Stairs | Descending Stairs | Vacuum Cleaning | Ironing | Folding Laundry | House Cleaning | Playing Soccer | Rope Jumping | ||
| Lying | 297 | 3 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | |
| Sitting | 0 | 284 | 1 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Standing | 0 | 3 | 291 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Walking | 1 | 3 | 0 | 292 | 2 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | |
| Running | 0 | 3 | 1 | 0 | 291 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | |
| Cycling | 0 | 1 | 0 | 2 | 1 | 294 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | |
| Nordic walking | 0 | 2 | 3 | 3 | 2 | 4 | 291 | 3 | 3 | 1 | 5 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | |
| Watching TV | 0 | 0 | 0 | 0 | 0 | 1 | 4 | 241 | 4 | 2 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | |
| Computer work | 0 | 1 | 2 | 1 | 1 | 0 | 0 | 1 | 241 | 3 | 1 | 2 | 0 | 0 | 1 | 1 | 0 | 0 | |
| Car driving | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 2 | 2 | 240 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | |
| Ascending stairs | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 291 | 1 | 0 | 2 | 1 | 0 | 0 | 0 | |
| Predicted values | Descending stairs | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 292 | 1 | 1 | 1 | 1 | 1 | 0 |
| Vacuum cleaning | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 2 | 1 | 293 | 2 | 1 | 3 | 2 | 0 | |
| Ironing | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 293 | 0 | 0 | 1 | 1 | |
| Folding laundry | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 241 | 2 | 0 | 0 | |
| House cleaning | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 2 | 239 | 4 | 1 | |
| Playing soccer | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 3 | 239 | 3 | |
| Rope jumping | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 2 | 295 | |
| Actual Values | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lying | Sitting | Standing | Walking | Running | Cycling | Nordic Walking | Watching TV | Computer Work | Car Driving | Ascending Stairs | Descending Stairs | Vacuum Cleaning | Ironing | Folding Laundry | House Cleaning | Playing Soccer | Rope Jumping | ||
| Lying | 288 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | |
| Sitting | 0 | 286 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Standing | 0 | 0 | 283 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Walking | 0 | 0 | 0 | 285 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Running | 0 | 0 | 0 | 0 | 284 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
| Cycling | 0 | 0 | 2 | 1 | 1 | 285 | 1 | 8 | 0 | 0 | 1 | 2 | 0 | 2 | 0 | 2 | 0 | 0 | |
| Nordic walking | 6 | 12 | 4 | 9 | 6 | 7 | 294 | 6 | 3 | 1 | 6 | 11 | 5 | 12 | 2 | 5 | 0 | 0 | |
| Watching TV | 0 | 0 | 1 | 1 | 2 | 3 | 0 | 236 | 6 | 0 | 2 | 0 | 2 | 0 | 3 | 1 | 0 | 1 | |
| Computer work | 0 | 1 | 3 | 1 | 2 | 0 | 2 | 0 | 238 | 4 | 1 | 1 | 0 | 1 | 3 | 1 | 0 | 0 | |
| Car driving | 4 | 0 | 2 | 3 | 0 | 2 | 3 | 0 | 2 | 242 | 3 | 0 | 2 | 1 | 2 | 2 | 0 | 0 | |
| Ascending stairs | 1 | 1 | 3 | 0 | 3 | 1 | 0 | 0 | 1 | 1 | 287 | 3 | 2 | 0 | 2 | 2 | 0 | 0 | |
| Predicted values | Descending stairs | 0 | 0 | 2 | 0 | 2 | 1 | 0 | 0 | 0 | 2 | 0 | 283 | 0 | 0 | 2 | 1 | 0 | 0 |
| Vacuum cleaning | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 289 | 0 | 0 | 0 | 1 | 0 | |
| Ironing | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 284 | 0 | 0 | 1 | 1 | |
| Folding laundry | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 236 | 0 | 1 | 0 | |
| House cleaning | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 235 | 0 | 0 | |
| Playing soccer | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 241 | 5 | |
| Rope jumping | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5 | 293 | |
| Actual Values | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lying | Sitting | Standing | Walking | Running | Cycling | Nordic Walking | Watching TV | Computer Work | Car Driving | Ascending Stairs | Descending Stairs | Vacuum Cleaning | Ironing | Folding Laundry | House Cleaning | Playing Soccer | Rope Jumping | ||
| Lying | 263 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | |
| Sitting | 0 | 268 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Standing | 0 | 0 | 244 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Walking | 0 | 0 | 0 | 253 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Running | 0 | 2 | 0 | 0 | 254 | 0 | 0 | 0 | 2 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | |
| Cycling | 3 | 4 | 1 | 1 | 1 | 253 | 2 | 9 | 1 | 3 | 2 | 0 | 1 | 5 | 3 | 0 | 1 | 0 | |
| Nordic walking | 17 | 22 | 20 | 26 | 19 | 16 | 278 | 20 | 6 | 3 | 16 | 17 | 19 | 31 | 8 | 10 | 1 | 0 | |
| Watching TV | 1 | 0 | 13 | 1 | 5 | 5 | 8 | 221 | 2 | 0 | 2 | 2 | 5 | 4 | 2 | 3 | 0 | 0 | |
| Computer work | 1 | 0 | 4 | 2 | 2 | 5 | 5 | 0 | 221 | 4 | 3 | 2 | 9 | 0 | 5 | 3 | 0 | 0 | |
| Car driving | 7 | 2 | 3 | 10 | 5 | 6 | 3 | 0 | 9 | 231 | 4 | 6 | 4 | 2 | 9 | 2 | 1 | 1 | |
| Ascending stairs | 5 | 1 | 13 | 5 | 9 | 10 | 4 | 0 | 4 | 9 | 269 | 5 | 7 | 1 | 5 | 6 | 1 | 0 | |
| Predicted values | Descending stairs | 2 | 1 | 2 | 1 | 4 | 3 | 0 | 0 | 3 | 0 | 1 | 265 | 1 | 0 | 4 | 1 | 1 | 0 |
| Vacuum cleaning | 1 | 0 | 0 | 1 | 1 | 2 | 0 | 0 | 2 | 0 | 3 | 2 | 254 | 1 | 1 | 0 | 7 | 1 | |
| Ironing | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 256 | 0 | 0 | 0 | 0 | |
| Folding laundry | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 212 | 0 | 1 | 2 | |
| House cleaning | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 225 | 2 | 1 | |
| Playing soccer | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 225 | 6 | |
| Rope jumping | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8 | 289 | |
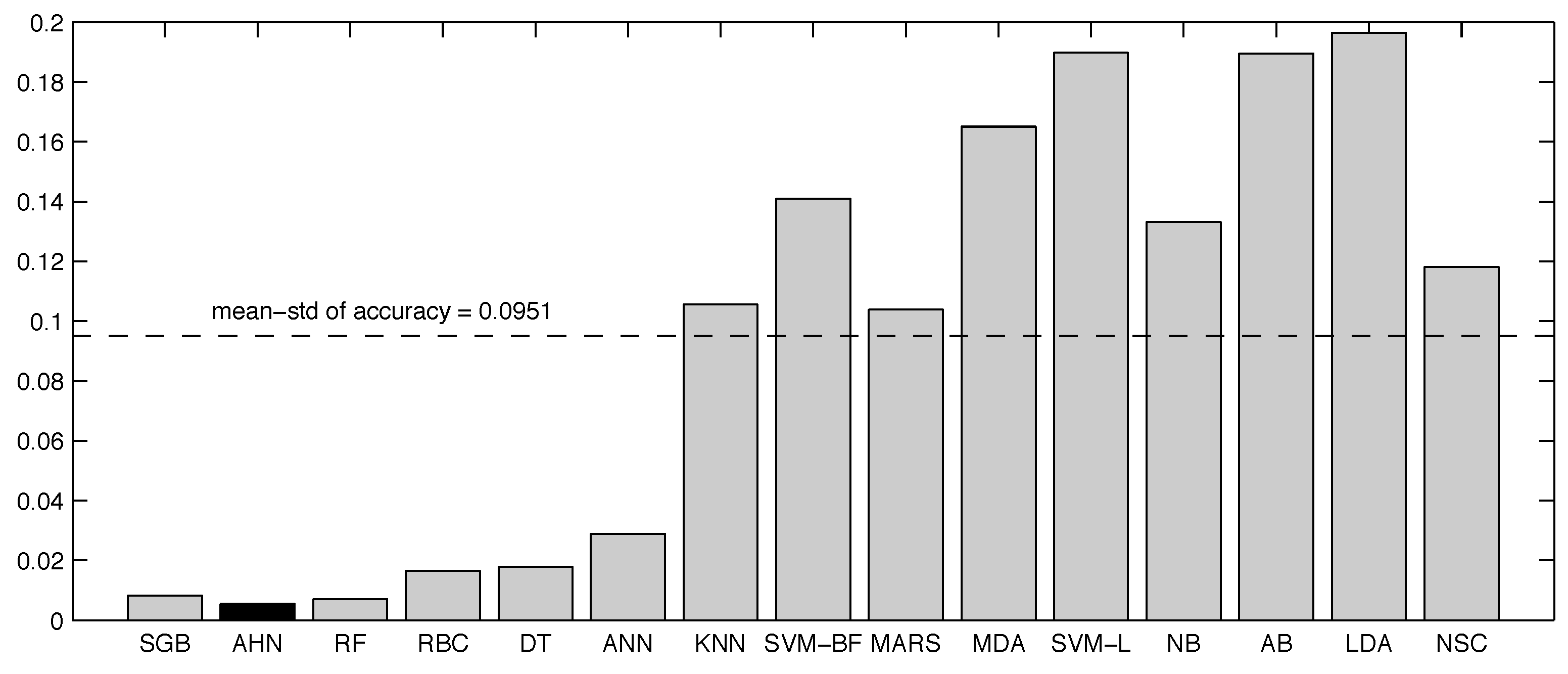
| No. | Method Name | Complete Dataset | 7% Noisy Dataset | Reduced Dataset | Accuracy | σ Accuracy |
|---|---|---|---|---|---|---|
| 1 | Stochastic Gradient Boosting | 0.9725 | 0.9722 | 0.9898 | 0.9782 | 0.0082 |
| 2 | Artificial Hydrocarbon Networks | 0.9829 | 0.9696 | 0.9741 | 0.9756 | 0.0055 |
| 3 | Random Forest | 0.9727 | 0.9825 | 0.9655 | 0.9736 | 0.0070 |
| 4 | Rule-Based Classifier | 0.9876 | 0.9484 | 0.9604 | 0.9655 | 0.0164 |
| 5 | C4.5 Decision Trees | 0.9880 | 0.9459 | 0.9571 | 0.9637 | 0.0178 |
| 6 | Artificial Neural Networks | 0.8976 | 0.9151 | 0.9657 | 0.9261 | 0.0289 |
| 7 | k-Nearest Neighbors | 0.9718 | 0.9059 | 0.7222 | 0.8666 | 0.1056 |
| 8 | SVM with Radial Basis Function Kernel | 0.9745 | 0.9276 | 0.6549 | 0.8524 | 0.1409 |
| 9 | Multivariate Adaptive Regression Splines | 0.9553 | 0.8755 | 0.7061 | 0.8456 | 0.1039 |
| 10 | Mixture Discriminant Analysis | 0.9714 | 0.8816 | 0.5853 | 0.8127 | 0.1650 |
| 11 | SVM with Linear Kernel | 0.9827 | 0.8796 | 0.5386 | 0.8003 | 0.1898 |
| 12 | Naive Bayes | 0.9327 | 0.7769 | 0.6069 | 0.7722 | 0.1331 |
| 13 | AdaBoost | 0.9710 | 0.7820 | 0.5092 | 0.7541 | 0.1895 |
| 14 | Linear Discriminant Analysis | 0.9382 | 0.8339 | 0.4792 | 0.7505 | 0.1965 |
| 15 | Nearest Shrunken Centroids | 0.7031 | 0.6202 | 0.4216 | 0.5816 | 0.1181 |
| Average | 0.9468 | 0.8811 | 0.7358 | 0.8546 | 0.0951 |
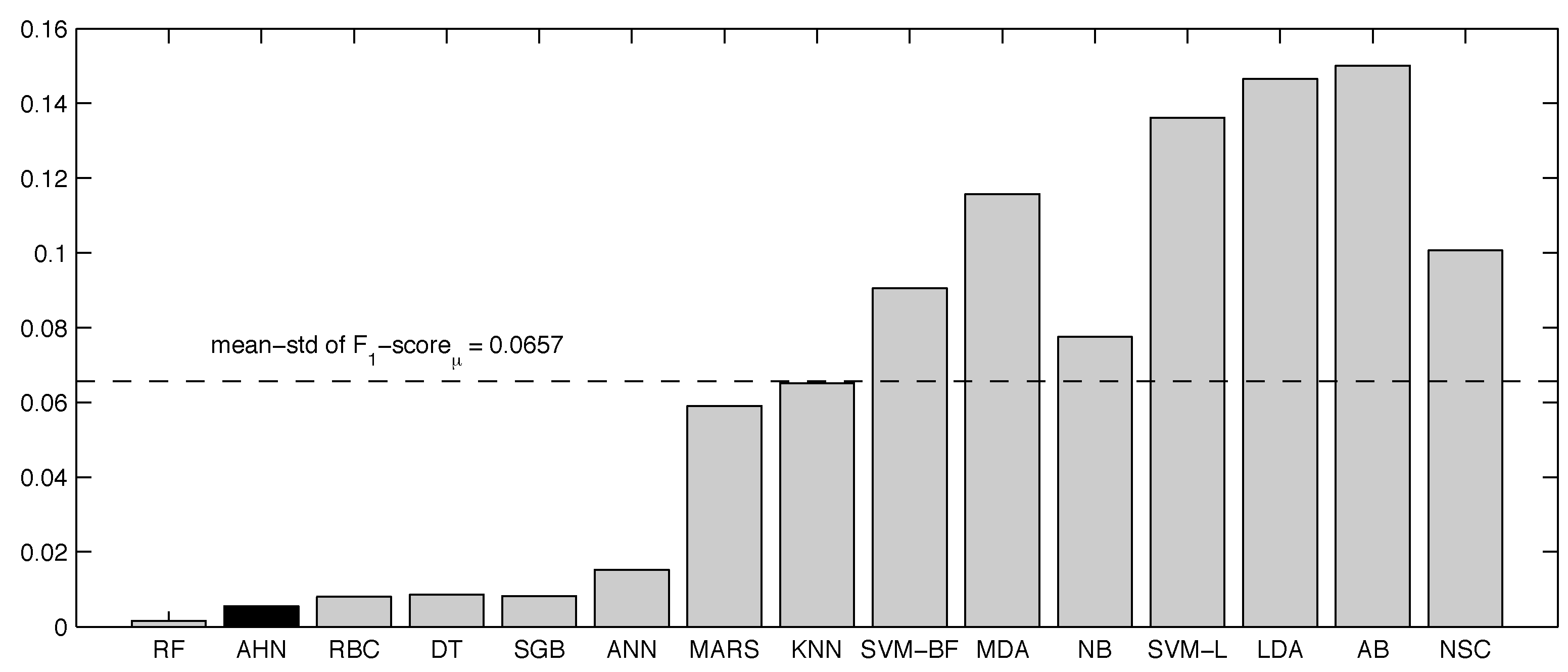
| No. | Method Name | Complete Dataset | 7% Noisy Dataset | Reduced Dataset | -Score | σ -Score |
|---|---|---|---|---|---|---|
| 1 | Random Forest | 0.9902 | 0.9909 | 0.9874 | 0.9895 | 0.0015 |
| 2 | Artificial Hydrocarbon Networks | 0.9910 | 0.9839 | 0.9864 | 0.9871 | 0.0029 |
| 3 | Rule-Based Classifier | 0.9942 | 0.9747 | 0.9846 | 0.9845 | 0.0080 |
| 4 | C4.5 Decision Trees | 0.9943 | 0.9739 | 0.9809 | 0.9830 | 0.0085 |
| 5 | Stochastic Gradient Boosting | 0.9725 | 0.9722 | 0.9898 | 0.9782 | 0.0082 |
| 6 | Artificial Neural Networks | 0.9457 | 0.9582 | 0.9824 | 0.9621 | 0.0152 |
| 7 | Multivariate Adaptive Regression Splines | 0.9794 | 0.9469 | 0.8413 | 0.9226 | 0.0590 |
| 8 | k-Nearest Neighbors | 0.9852 | 0.9484 | 0.8325 | 0.9220 | 0.0651 |
| 9 | SVM with Radial Basis Function Kernel | 0.9867 | 0.9607 | 0.7832 | 0.9102 | 0.0905 |
| 10 | Mixture Discriminant Analysis | 0.9848 | 0.9347 | 0.7181 | 0.8792 | 0.1157 |
| 11 | Naive Bayes | 0.9704 | 0.8810 | 0.7807 | 0.8774 | 0.0775 |
| 12 | SVM with Linear Kernel | 0.9908 | 0.9322 | 0.6772 | 0.8667 | 0.1362 |
| 13 | Linear Discriminant Analysis | 0.9672 | 0.9069 | 0.6307 | 0.8349 | 0.1465 |
| 14 | AdaBoost | 0.9877 | 0.8691 | 0.6270 | 0.8279 | 0.1501 |
| 15 | Nearest Shrunken Centroids | 0.8178 | 0.7493 | 0.5784 | 0.7152 | 0.1006 |
| Average | 0.9705 | 0.9322 | 0.8254 | 0.9094 | 0.0657 |
| No. | Method Name | Accuracy | σ Accuracy | 7% (acc) | 15% (acc) | 30% (acc) | -Score | σ -Score | 7% () | 15% () | 30% () |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Artificial Hydrocarbon Networks | 0.9343 | 0.0398 | 0.9696 | 0.9547 | 0.8786 | 0.9697 | 0.0162 | 0.9839 | 0.9781 | 0.9470 |
| 2 | k-Nearest Neighbors | 0.9031 | 0.0334 | 0.9059 | 0.9425 | 0.8608 | 0.9478 | 0.0178 | 0.9484 | 0.9692 | 0.9257 |
| 3 | SVM with Radial Basis Function Kernel | 0.8856 | 0.0575 | 0.9276 | 0.9249 | 0.8043 | 0.9426 | 0.0266 | 0.9607 | 0.9621 | 0.9051 |
| 4 | Naive Bayes | 0.8583 | 0.0597 | 0.7769 | 0.9182 | 0.8798 | 0.9313 | 0.0361 | 0.8810 | 0.9638 | 0.9491 |
| 5 | Stochastic Gradient Boosting | 0.8363 | 0.1125 | 0.9722 | 0.8402 | 0.6967 | 0.9284 | 0.0475 | 0.9868 | 0.9278 | 0.8705 |
| 6 | SVM with Linear Kernel | 0.7981 | 0.0887 | 0.8796 | 0.8400 | 0.6747 | 0.8970 | 0.0400 | 0.9322 | 0.9177 | 0.8410 |
| 7 | AdaBoost | 0.7736 | 0.1163 | 0.9151 | 0.7755 | 0.6302 | 0.8970 | 0.0496 | 0.9582 | 0.8960 | 0.8367 |
| 8 | Mixture Discriminant Analysis | 0.7629 | 0.1136 | 0.8816 | 0.7975 | 0.6098 | 0.8693 | 0.0641 | 0.9347 | 0.8909 | 0.7823 |
| 9 | Random Forest | 0.7612 | 0.1762 | 0.9825 | 0.7498 | 0.5514 | 0.9095 | 0.0625 | 0.9909 | 0.8986 | 0.8390 |
| 10 | Rule-Based Classifier | 0.7465 | 0.1629 | 0.9484 | 0.7414 | 0.5496 | 0.8893 | 0.0680 | 0.9747 | 0.8851 | 0.8082 |
| 11 | C4.5 Decision Trees | 0.7367 | 0.1695 | 0.9459 | 0.7335 | 0.5308 | 0.8826 | 0.0741 | 0.9739 | 0.8815 | 0.7925 |
| 12 | Linear Discriminant Analysis | 0.7089 | 0.1212 | 0.8339 | 0.7478 | 0.5449 | 0.8368 | 0.0700 | 0.9069 | 0.8622 | 0.7412 |
| 13 | Multivariate Adaptive Regression Splines | 0.6756 | 0.1661 | 0.8755 | 0.6824 | 0.4688 | 0.8590 | 0.0710 | 0.9469 | 0.8569 | 0.7731 |
| 14 | Nearest Shrunken Centroids | 0.6422 | 0.0243 | 0.6202 | 0.6761 | 0.6302 | 0.7807 | 0.0231 | 0.7493 | 0.8044 | 0.7883 |
| 15 | Artificial Neural Networks | 0.5864 | 0.1408 | 0.7820 | 0.5214 | 0.4559 | 0.7469 | 0.0864 | 0.8691 | 0.6892 | 0.6824 |
| Average | 0.7740 | 0.1055 | 0.8811 | 0.7897 | 0.6511 | 0.8858 | 0.0502 | 0.9332 | 0.8922 | 0.8321 |
| No. | Method Name | Training Time (s) | Testing Time (ms) | ||
|---|---|---|---|---|---|
| Complete Dataset | Reduced Dataset | Complete Dataset | Reduced Dataset | ||
| 1 | AdaBoost | 20.39 | 6.19 | 0.55 | 0.60 |
| 2 | Artificial Hydrocarbon Networks | 72.61 | 61.53 | 1.71 | 0.92 |
| 3 | C4.5 Decision Trees | 2.23 | 0.91 | 0.03 | 0.02 |
| 4 | k-Nearest Neighbors | 6.87 | 3.26 | 0.60 | 0.21 |
| 5 | Linear Discriminant Analysis | 10.23 | 0.13 | 0.04 | 0.01 |
| 6 | Mixture Discriminant Analysis | 7.23 | 5.02 | 0.21 | 0.15 |
| 7 | Multivariate Adaptive Regression Splines | 40.26 | 7.72 | 0.07 | 0.03 |
| 8 | Naive Bayes | 29.30 | 5.76 | 56.55 | 11.04 |
| 9 | Nearest Shrunken Centroids | 0.08 | 0.08 | 0.01 | 0.01 |
| 10 | Artificial Neural Networks | 18.29 | 12.14 | 0.02 | 0.01 |
| 11 | Random Forest | 24.73 | 8.97 | 0.03 | 0.04 |
| 12 | Rule-Based Classifier | 3.62 | 1.19 | 0.03 | 0.02 |
| 13 | Stochastic Gradient Boosting | 16.54 | 5.48 | 0.07 | 0.07 |
| 14 | SVM with Linear Kernel | 3.51 | 3.91 | 0.10 | 0.07 |
| 15 | SVM with Radial Basis Function Kernel | 26.20 | 36.38 | 1.90 | 3.02 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ponce, H.; Martínez-Villaseñor, M.D.L.; Miralles-Pechuán, L. A Novel Wearable Sensor-Based Human Activity Recognition Approach Using Artificial Hydrocarbon Networks. Sensors 2016, 16, 1033. https://doi.org/10.3390/s16071033
Ponce H, Martínez-Villaseñor MDL, Miralles-Pechuán L. A Novel Wearable Sensor-Based Human Activity Recognition Approach Using Artificial Hydrocarbon Networks. Sensors. 2016; 16(7):1033. https://doi.org/10.3390/s16071033
Chicago/Turabian StylePonce, Hiram, María De Lourdes Martínez-Villaseñor, and Luis Miralles-Pechuán. 2016. "A Novel Wearable Sensor-Based Human Activity Recognition Approach Using Artificial Hydrocarbon Networks" Sensors 16, no. 7: 1033. https://doi.org/10.3390/s16071033
APA StylePonce, H., Martínez-Villaseñor, M. D. L., & Miralles-Pechuán, L. (2016). A Novel Wearable Sensor-Based Human Activity Recognition Approach Using Artificial Hydrocarbon Networks. Sensors, 16(7), 1033. https://doi.org/10.3390/s16071033