The GMDPSO makes use of the network topology of candidate relay nodes to guide particle’s position and velocity updates. The greedy strategy originated from greedy forwarding mechanism is proposed to direct particles to move towards better position. Some small operators, such as position initialization and memory mechanism, are introduced to speed up convergence. This section will describe the proposed algorithm in detail. The whole framework of GMDPSO is given in Algorithm 1.
The positions are iteratively updated until the termination condition is satisfied. In our approach, there are two termination conditions: predefined iteration number and accuracy requirements. Once one of the two conditions is satisfied, the algorithm stops and the particle Gbest is found, Gbest.X represents the clustering result or routing result.
5.2.1. Fitness Function Derivation
Fitness function is an important issue because it directly affects the final results. Now, we construct our fitness function (
fitness) to evaluate the individual particle of population, in GMDPSO, the optimal tree is built such that it minimizes the
fitness value. We have three objectives when build the optimal routing tree for
Sinki (i.e.,
PTreei):
The first one is to maximize the lifetime of the routing tree to achieve energy-consumption balancing;
The second one is to minimize the length of the routing tree to achieve energy conservation and enhance reliability; and
the third one is to minimize the communication delay to enhance network throughout. In order to tune the three objectives to build optimal routing tree, we need to normalize the above three objectives and use the weight sum approach (WSA) [
28] to construct our multi-objective fitness function
fitness. Therefore, our fitness function depends on the following parameters:
- (1)
Lifetime of relay node
Our first objective is to maximize the routing tree lifetime, which is defined as the time interval from the establishment of the routing tree till its first relay node dies (FND). This is possible if we can maximize the lifetime of relay node that has least lifetime. Let
be the kth relay node on the Pathj. The lifetime of
is defined as follows:
where
Eres(
) is the residual energy of relay node
, and
is its consumed energy. It can be seen from Equation (7) that, even though
keeps more
Eres(
), it maybe die faster if its
is bigger than others at the same time.
Now, we begin the energy consumption analysis for relay node.
must consume energy to forward the incoming data packets, which come from source node whose routing path to sink goes through it. Before calculating the routing energy consumption, it is needed to calculate the total number of incoming packets, which come from other relay node toward sink. Since multi routing paths may share some relay nodes, the number of incoming packets can be recursively calculated as follows:
The relay node
will consume its energy to receive
Nin(
) incoming packets and forward them. Therefore, the total data forwarding energy consumption of
can be calculated as follows:
where
m is the size of data packet.
Let
be the minimum lifetime of the routing tree
PTreei. Therefore, our first objective is:
Using Equation (9) to substitute the
in Equation (7), then,
It can be seen that, if
Eres(
) and
Nin(
) are fixed, then
lf(
) is negatively correlated with dis(
,
). Therefore, it can be deduced that relay node with minimum lifetime is the relay node with the longest transition distance. That is,
where argmax
f(
x) returns the value of
x that maximizes
f(
x).
Bigger
means smaller fitness value. Therefore,
fitness is inversely proportional to the
, i.e.,
where 0 < 1/
≤ 1.
is used to avoid node with lower residual energy being selected as sharing relay node whose load burden is heavy.
- (2)
Routing Path Length
In our network mode, the energy is mainly consumed to collect network statuses and forward data to sink. The unicast local flooding mechanism is adopted to save energy for collecting network statuses. It is well known that the energy consumption of sensor node in WSNs is subject to the transmission distance—shorter data dissemination paths lead to decreased energy consumption together with increased throughput and reliability, which also can be deduced from Equation (9). Therefore, our second objective is to minimize the length of the routing tree to minimize the forwarding data energy consumption. Let
be routing tree of
. Now, we calculate the total energy consumption of
PTreei (i.e.,
). According to Equation (9), the energy consumption of each routing path
(
⊆
), i.e.,
, can be calculated as follows:
Therefore,
can be calculated as follow:
For each
Pathj assume that no packet is lost during routing data to agent, then
Nin(
) is the same for each relay node in
Pathj which can be considered as a constant value. Let
Nin(
) =
Nin. Then Equation (14) is improved as follows:
where
is length of the routing path
. It is can be seen that
is only positively correlated with routing path.
Therefore, to minimize
, the total routing tree length
Len(
PTreei) needs to be minimized. That is, our second objective can be described as follows:
Smaller
Len (
) is better. Therefore,
fitness is proportional to the
Len (
) i.e.,
Now, we normalize
Len (
PTreei) by
allLen, i.e.,
allLen can be calculated as follows:
where
NV is the number of candidate relay nodes. Therefore,
It can be deduced from Equation (21) that 0 < Len (PTreei) ≤ 1.
- (3)
Communication Delay
End-to-end delay is another important performance metric of MWSNs. Given a fixed channel bandwidth, less the delay, higher the throughout. Let
be the total communication delay of
. Then
can be calculated as following:
Therefore, our third objective is:
Clearly, smaller
is better. Then our
fitness is proportional to the
i.e.,
Similar with Equation (19),
also can be normalized as follows:
After normalizing the above three objectives, the final fitness function for
is:
where
ω1,
ω2 and
ω3 are three control parameters, 0 <
ωi ≤ 1 and
ω1 +
ω2 +
ω3 = 1. In the paper, we give the same weight to them, that is,
ω1 =
ω2 =
ω3 = 0.33.
5.2.2. Particles Representation
How to encode the routing tree is very critical. To make GMDPSO feasible for discrete MWSNs scenario, the position and velocity of particle in our protocol are redefined.
Definition 1 (Position). The position vector provides a routing tree. The position vector of ith particle is defined as Xi = {, , , …, }, where = N − 1 is dimension of Xi which means the number of candidate relay nodes excluding the agent, the d component ∈ {0, N} is the sensor ID, which maps nodek (k = ) as the next relay node of noded. That is to say, indicates that noded forwards data to nodek.
Notably,
Xi means a routing path tree that includes multi routing paths from multi source nodes to the same root node. Suppose mobile sink
Sinki has
NS source nodes, and then
Xi includes
NS routing paths. A graphical illustration of particle representation can be seen in
Figure 4.
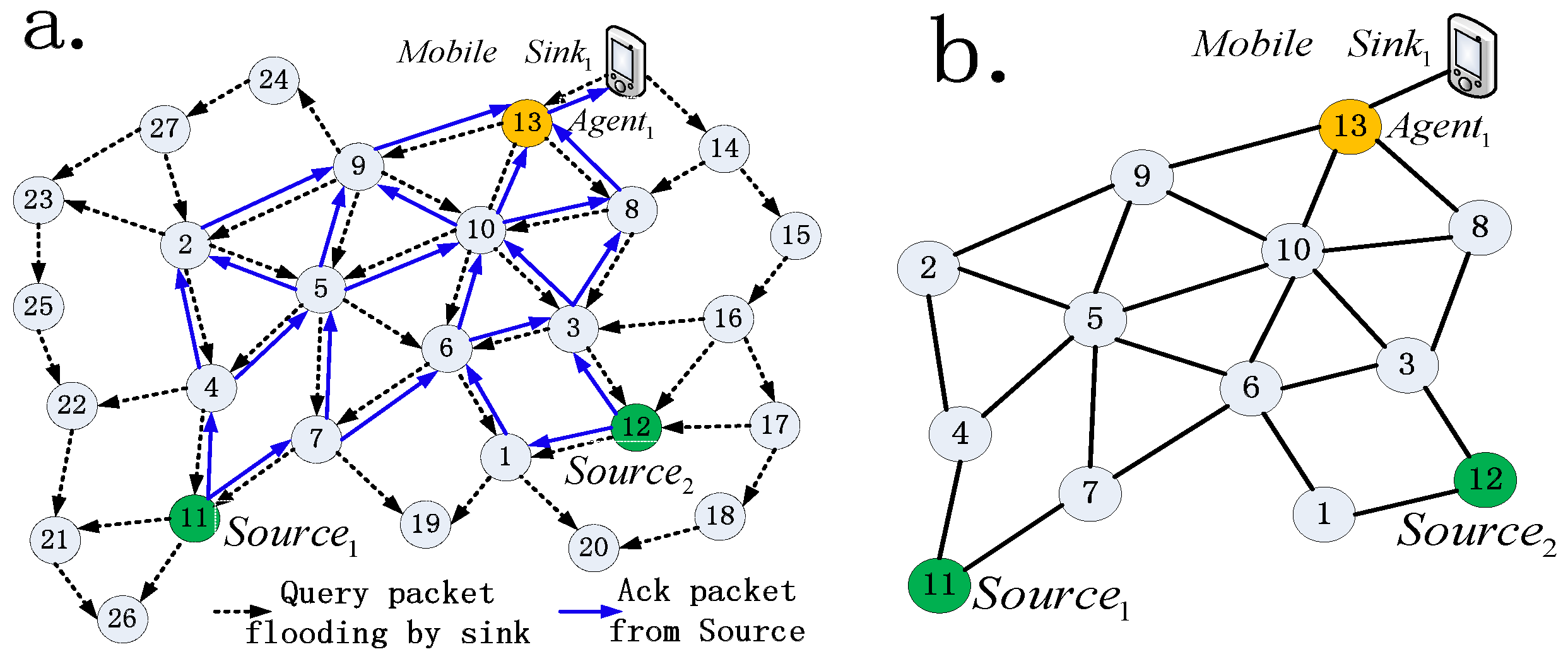
Illustration 1. Consider mobile sink Sinki masters a subnet of MWSN G (V, E) with 13 sensor nodes and one mobile node as shown in Figure 4a. V = {node1, node2, …, node13}. node13 is selected as agent, node11 and node12 are two source nodes, which means two routing paths will be built. The dimension of the particle position vector is = N − 1 = 13 − 1 = 12. As shown in Figure 4b. Particle i is encoded as Xi = {, , , …, } = {6, 9, 10, 5, 9, 5, 5, 13, 13, 13, 4, 3}, in Xi, for example, = 4 indicates that source node node11 sends data packet to node4. A routing tree is constructed by decoding the encoded particle, in which each route path from a source node to sink can be built by appending relay nodes one by one till the agent node is selected as the end.
As shown in
Figure 4c, the path tree can be decoded as follows: firstly, the routing path of
Source1 (i.e.,
node11) is built as
Path1:
Source1→node
4→node
5→node9→
Agent1.Then, routing path of
Source2 (i.e.,
node12) is built as
Path2:
Source2→node
3→node
10→
Agent1, and at last, the whole routing tree can be constructed by combining
Path1 and
Path2.
It can be seen from
Figure 4 that our discrete position definition is straightforward and easy to decode and will lower the computational complexity, especially in the case of large-scale MWSNs, because the dimensions of the fitness function is equal to the size of candidate relay nodes collected by sink which is smaller than the entire MWSN size.
Definition 2 (Velocity). Velocity is a very crucial component in PSO, by working on the position vector, it guides a particle and determines whether it can reach its destination and by how fast it could. Our discrete velocity of particle i is defined as Vi = {, , …, }, where ∈{0,1} is binary-coded, = 1 means that the corresponding element in Xi will be changed, otherwise, keeps its original state. and have the same dimension.
In canonical PSO, velocity is used to learn knowledge from itself and swarm and finally leads the particle to a better position. In addition, a threshold Vmax is used to inhibit particles from flying out of the boundaries because there is a situation whereby when the speed of a particle is substantial. Unlike the continuous optimization, we have known that, in our discrete MWSNs scenarios, to compare two different routing paths from the same source node to the same agent, we only take care about whether their relay nodes are the same. Furthermore, we only need to compare the two relay nodes ID value in the same position of two different routing paths. There are only two results: is equal or no, therefore, the velocity can be encoded binary, and we defined 0 means two relay nodes are the same, 1 means they are different.
The first motivation of the velocity definition is to actually reflect the differences between two position vectors. The second motivation of the velocity definition is to prevent particles from flying away, because our velocity is binary-coded, we no longer need Vmax parameter.
5.2.3. Particle Swarm Initialization
A good initialization mechanism can reduce the searching space to reach global optima faster and promote diversity. Conventional random initialization method for PSO based algorithm is not applicable for our algorithm. The main reason is that random sequence of edges usually results in invalid routing tree that does not terminate on the agent node or that have loops. Therefore, we need to design a more efficient initialization method for our protocol. Based on our particle representation for discrete MWSNs, the position vectors initialization focus on how to map the next relay node, in other words, how to select the next relay node for the current one, for example, how to map another node as the next relay node for current node noded. Our main idea to solve this problem is that the next relay node for the current one is randomly selected from its neighbors. The mapping is done as follows:
Let
Neig(node
d) = {node
1, node
2, …, node
K} = {
|0 ≤
j ≤
& 0 < A[d, j] < ∞} be the neighbors of node
d, and A is the adjacent matrix for
G (
V, E),Then,
where Index (
Neig(node
d),
n) is an indexing function that indexes
nth node of
Neig(node
d) as the next relay node, and
n is a randomly generated uniformly distributed integer number.
Table 2 shows the nodes and their neighbors. Besides,
Table 1 also illustrates how the next relay node is chosen.
In order to reduce the randomicity and blindness of swarm initialization, and at the same time speed up the convergence of our algorithm, the position vectors are initialized in such way:
Step 1 Agent node is forced to be mapped as the relay node of its neighbor nodes (seeing the blue number in
Figure 4b. In detail, firstly, position vector of
i particle is empty, that is,
Xi = (0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0). Then assign agent node (i.e., node
13) to its neighbor nodes, as shown in
Table 2, then
Xi = ({0, 0, 0, 0, 0, 0, 0, 13, 13, 13, 0, 0}. Marker ‘-’ in
Table 2 means that the relay node of the corresponding node is specified directly instead of choosing from its neighbors using Equation (27).
Step 2 Maps agent’s neighbors to be relay node of the agent’s neighbor’s neighbor. Notably, if some of the agent’s neighbors have the same neighbor, which cause more than one node will be mapped as the relay node of the same neighbor at the same time, and then we chose the nearest neighbor as the relay node. For example, as shown in
Table 2, the neighbor of the agent (i.e., node
13) is
Neig (node
13) = {node
8, node
9, node
10}, then node
13 is the common next relay node of
Neig (node
13). Next, we assign node
8, node
9, and node
10 to their neighbors respectively.
Neig(node
8)∪
Neig(node
9)∪
Neig(node
10) = {node
2, node
3, node
5, node
6}, which means that node
8, node
9, and node
10 should be assigned to node
2, node
3, node
5 and node
6 ,that is to say, the third column of
Table 2 (i.e., column n) of the corresponding nodes, i.e., node
8, node
9, node
10, node
2, node
3, node
5 and node
6 should be marked with ‘-’. It is easy to be seen form
Figure 4a that
Neig (node
2) = node
9,
Neig (node
6) = node
10. For node
5, because
Neig (node
9)∩
Neig(node
10) = {node
5}, which means that node
9 can be chosen as the next relay node for node
5, and so do node
10. We chose node
9 as the relay node of node
5 with assumption that node
9 is the nearest neighbor of node
5. For node
6, we choose node
10 as its next relay node in the same way. After finished
Step 2, then the position vector
Xi will look as following:
Xi = {0, 9, 10, 0, 9, 10, 0, 13, 13, 13, 0, 0}.
Step 3 The relay nodes of remaining nodes are mapped by randomly choosing a node from their neighbor. For example, for Source1 (i.e., node11), let random n = 1, then its first neighbor is chosen as the next relay node.
Step 4 Finally, after finished the above three initiation steps, position vector Xi is initiated as Xi = {6, 9, 10, 5, 9, 10, 5, 13, 13, 13, 4, 3}.
It is worth noting that the invalid routing tree, in which contains one or more invalid routing path (that does not terminate on the agent node or that have loops), will be punished with a very high fitness.
The velocity vectors are initialized as all-zero vectors. The Pbest vectors are initialized in the same manner as the position vectors, and the vector is set as the best position vector in the original population.
Comparing to the conventional random initialization, the advantages of our initiation method are follows:
- (1)
Since node can and only can select its next relay node from its neighbors based on the network topology of G(V, E), our method takes advantage of this feature to reduce the vast search space significantly.
- (2)
In our method, agent node and its neighbors are mapped firstly in step1 and step3, and this reduces the likelihood of invalid routing path. In addition, it further reduces search space and drives particle to find its personal best position faster. That is, it speeds the algorithm convergence.
5.2.4. Velocity and Position Update
In canonical PSO, velocity gives a particle the moving direction and tendency. After updating its velocity, the particle builds its new position using the new velocity. However, in the proposed algorithm, the particle position and velocity vectors have been redefined in a discrete integer form, and thus, the mathematical updating rules in the canonical continuous PSO no longer fit the discrete case. In order to meet the requirements of building routing tree in discrete MWSNs, the particle’s velocity and position updating rules have been redefined as follows:
where
w is the dimensional inertial weight vector,
c1 and
c2 are two
dimensional cognitive and social components,
r1 and
r2 are two
dimensional random vectors in rang [0,1]. Equation (28) is used to update the old velocity, and Equation (29) is the position updating rule. It can be observed that the new updating rules take the same form in canonical PSO but different the key operator. The following will detail our new operators in discrete PSO.
Definition 3 (Position Operator). ⊝. Position ⊝ Position builds a velocity vector. Assume that we are given two position vector Xi = {, , … } and Xj = {, , , …, }, Xi ⊝ Xj = V = {v1, v2, …, }, the element vd is defined as: Definition 3 is inspired from the following two aspects:
First, it is well known that, in canonical PSO, a particle adjusts its velocity by learning from its old velocity (Vi(t)), personal best position (Pbesti-Xi(t)) and the swarm global best position (Gbest-Xi(t)). It can be seen that the learning process is actually a comparison between the positions, that is to say, two position vectors should generate a velocity vector. Second, two position vectors represent two different routing trees. The defined ⊝ operation actually is used to find which relay nodes are different between these two routing paths, and these differences will give a particle the fly direction.
Definition 4 (Velocity Operator). ⊕. Velocity ⊕ Velocity is also a velocity vector. Given two velocity vectors V1 = {, , …, } and V2 = {, , …, }, then V3 = V1 V2 = {, , …, }. can be compute as follows: Suppose V1 = Pbesti ⊝Xi(t) and V2 = Gbest ⊝Xi(t), then, condition1 means that once the kth relay node in particle i (i.e., = 1) needs to be changed, which is decided by its own knowledge (i.e., = 1) or by swarm knowledge (i.e., = 1) or both of them (i.e., = 1 & = 1), it must be changed finally. The definition of the operator ⊕ is easy to understand and easy to perform. Moreover, it can ensure binary-coded consistency for velocity, which is easier for the position to work with.
Definition 5 (Coefficient × Velocity). Coefficient × Velocity is still velocity vector. Given the Coefficient ω and the velocity vector V1 = , , …, }, then V2 = ω × V1 = {, , …, }. Where can be compute as follows:condition1 means that if a relay node needs to be changed , then change it without regard to the ω. Condition2 and condition3 are conditions for mutation operation of particle, which means that although a relay node does not need to be changed(i.e., = 0), it still maybe be changed in a mutation probability (i.e., 0.5). Mutation operation of particle can promote the diversity of particles and avoid falling into the local optimum.
Definition 6 (Position Updating Operator)
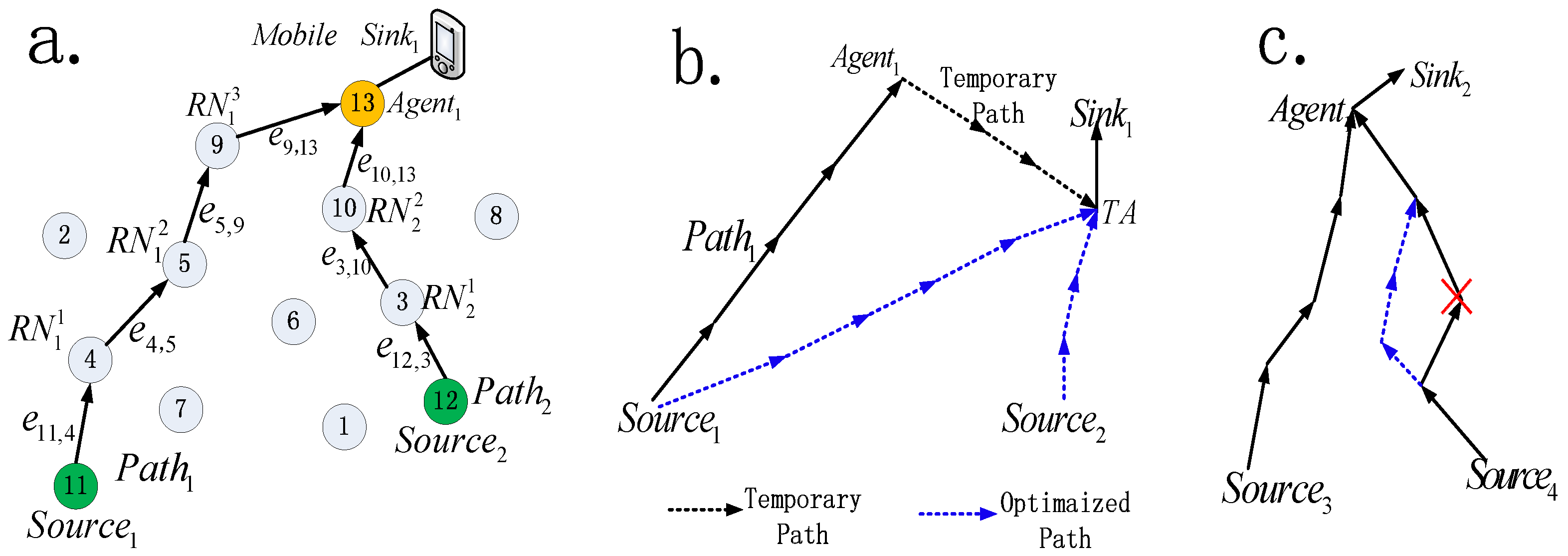
⊗. ⊗ is very important component in our update rules, which is used by particle to update its position with its new velocity. Position ⊗ Velocity generates a new position. A good design for operator ⊗ should drive a particle to a better position. Given an old position Xt = {, , …, } and a new velocity Vt+1 = {, , …, }, then the new position Xt+1 = Xt ⊗ Vt+1 = {, , …, }, the element of Xt+1 can be computed as follows:where ∈ means that the old node is selected as a relay node in the in Xt+1, in other words, if is not a relay node, it need not to be changed. Notably, Xi means a routing path tree that contains NS routing path branches, and Pathj is only one routing path branch of the routing path tree. Therefore, only these old nodes will be changed that satisfies the following conditions simultaneously: they are chosen as the relay nodes and their corresponding velocities are set to 1, i.e. . bestRNi is the node ID which can be calculated by:argmink f(k) returns the value of k that minimizes f(k). φ is calculated using the following equation:where i→k means that nodek is chosen as the next relay node of nodei. fit(x) is the fitness function (i.e., Equation (26)), and fit(Pathj(i→k)) means that we only calculate the fitness value of the two adjacent relay nodes in Pathj. Similar to greedy forwarding mechanism, Equation (35) means we choose the best next relay node for the current node from all its neighbors. However, unlike greedy mechanism that only chooses the nearest neighbor as the best next relay node, our approach chooses the neighbor node, which achieves the best balance of lifetime, distance and delay as the best next relay node by using our fitness function. Therefore, with the beginning from Sourcej. Pathj can be built by selecting the best relay node one after one until the agent node is chosen, and Pathj that is built in this way is the optimal routing path. For example, let first bestRN1 be , then is the current optimal routing path. Let be the bestRN2 of , is the current optimal routing path. Then,where Pathj is also the optimal routing. Using the same way, the other routing branches of Xt can be built. Next, the fitness of the Xt can be calculated using Equation (26). This search mechanism of bestRNi (i.e., Equation (34)) actually act as our particle searching strategy in GMDPSO, in which a particle update its position by selecting the next relay node that can generate the largest decrement of the fitness value, so it can be regard as a greedy local search strategy.
Our motivation of searching bestRNi in this way is based on the divide-conquer strategy, in order to build an optimal routing tree of Xt, we firstly build each optimal routing path branch of Xi respectively. When all routing path branches are built completely, then, the whole routing path tree is finished. Similarly, in order to build the optimal routing path branch Pathj, we choose the best next relay node for the previous relay node one after one, until the whole Pathj is completed.
However, Equation (34) is only used to build the single optimal routing path branch, rather than build the routing path tree (i.e.,
Xi). Because when we choose the best relay node for the current node of
Pathj, we do not consider the effect of the other routing path branch. Therefore, this method may neglect such a case, each routing branch is optimal, but the whole routing tree are weak due to the intersection relay nodes of multi routing paths. In other words, optimal routing path branches do not mean the optimal routing tree. As shown in
Figure 5, many source nodes send their data packets to same next relay node, and these relay nodes will consume more energy to forward more packets. For example,
node6 need forward data packets of
Source1,
Source2 and
Source3 to
node10, while,
node10 needs forward data packets of
Source1,
Source2,
Source3,
Source4 and
Source5 to
Agent1. The worst result is that these sharing relay nodes will die quickly because they deplete their energy of forwarding too many packets. This will lead to the expensive routing recover.
Therefore, after all of individual optimal routing path branches are built, the corresponding routing tree Xi should be evaluated using fitness function.
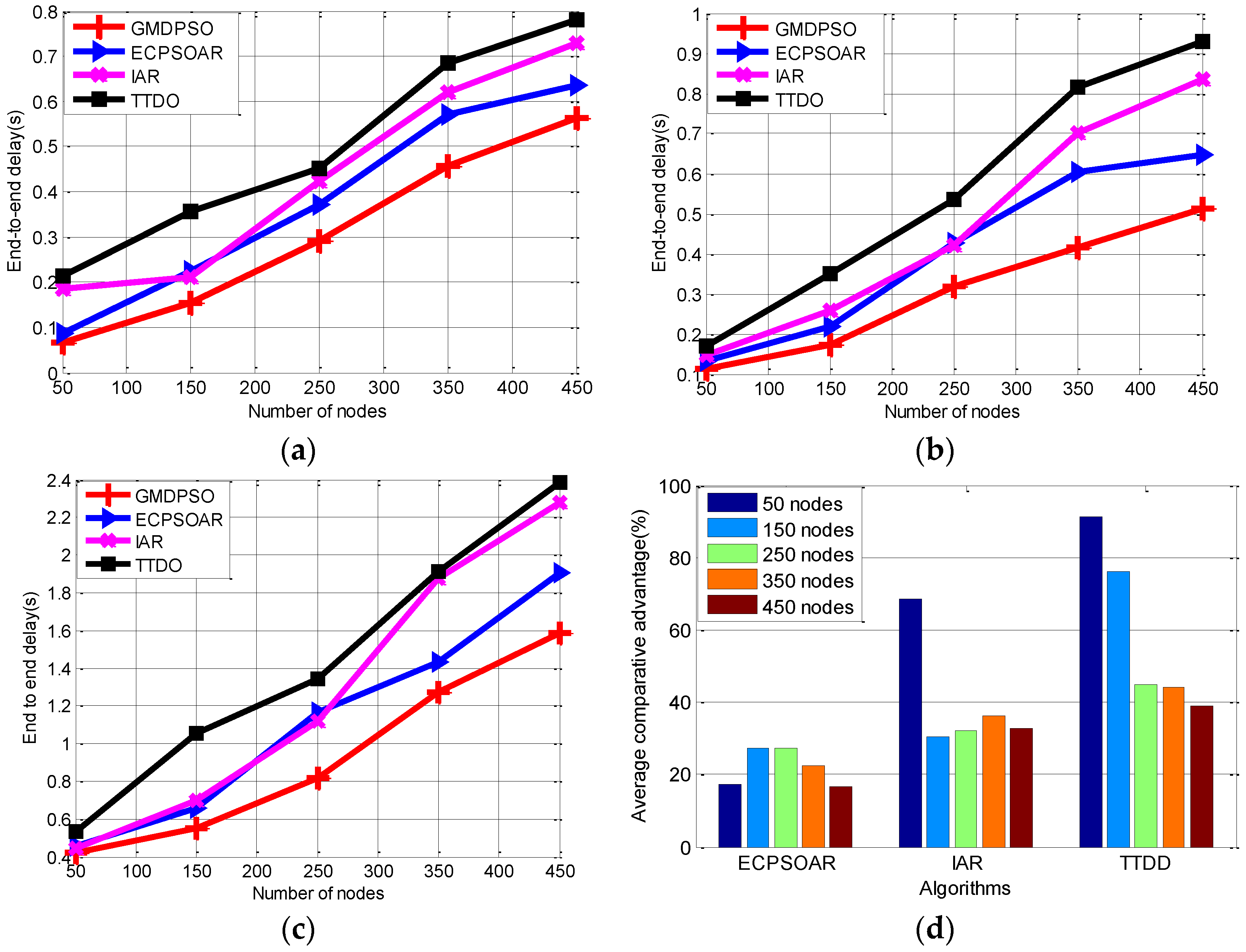
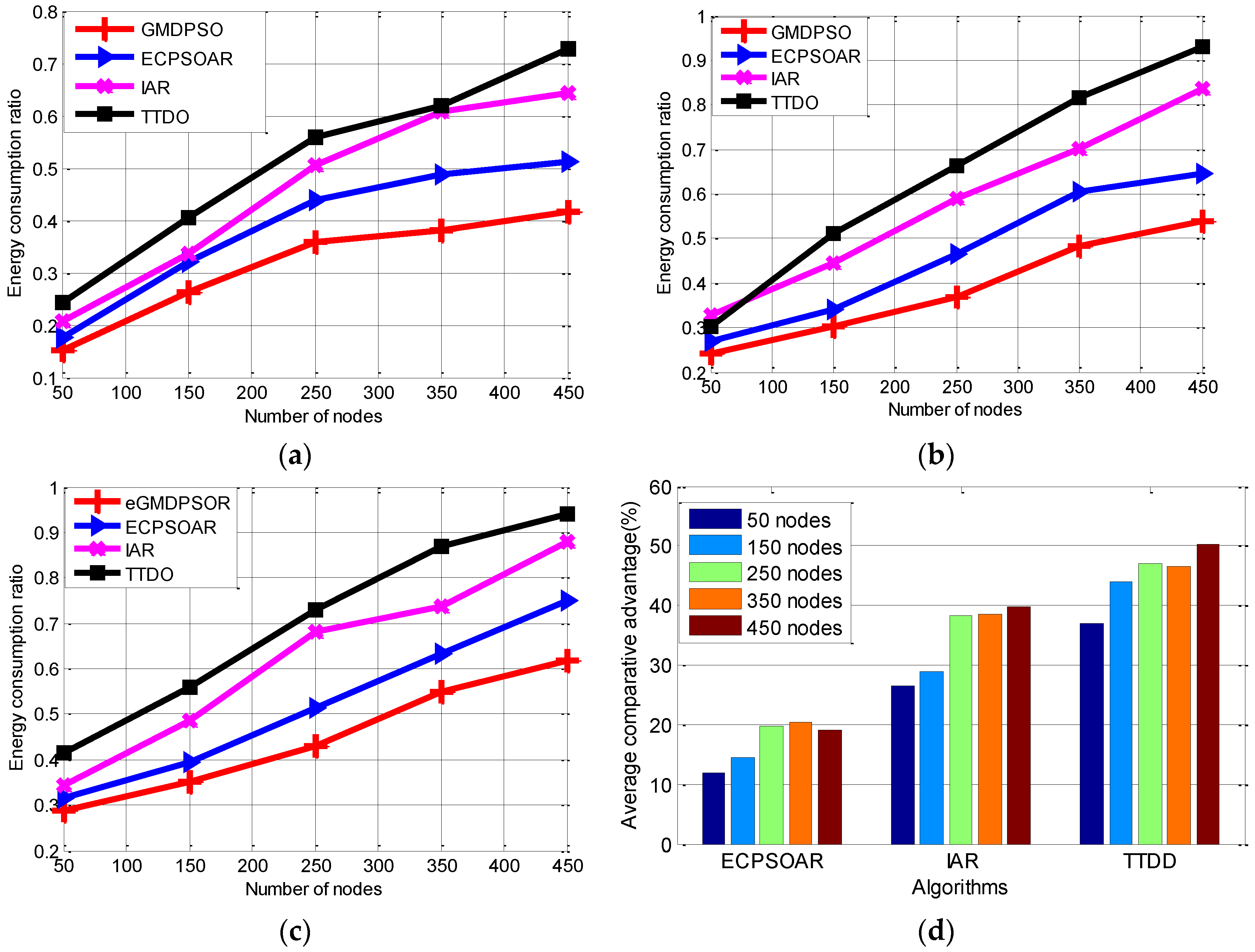
From the above description of our new GMDPSO algorithm, the proposed algorithm has the following features: (1) with a concise framework; (2) the newly defined particle position and velocity are direct and easy to decode; and (3) redefined updating rules based on the new operators are easy to realize and will significantly reduce the computational complexity, especially for large-scale WSNs.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}