1. Introduction
Infrared small target detection has been widely used in the airborne early warning, infrared guidance, surveillance and tracking and other fields [
1,
2,
3,
4]. In these applications, the infrared small targets have the following characteristics: (1) often immersed in strong noises or complex background (cloud clutter, plants and buildings, etc.), (2) with less texture and shape Information, (3) non-cooperative and without fixed law of movement. These characteristics make it very difficult to detect infrared small targets, and it has always been the hot and difficult issue of infrared detection field.
Because of the movement (jitter) of the infrared observation platform or the change of the imaging background, it is difficult to obtain the accurate infrared background by sequential detection methods [
5,
6,
7], because the infrared small targets are easily mistaken for background and vice versa. In this case, the single frame detection methods have received a great attention recently, and are valid for infrared small target detection with static or changing backgrounds [
8,
9,
10]. However, it is difficult to suppress clutters (cloud boundary, targe-like artifacts), which are very similar to real targets from the view of high intensities, because of the limited target information available in a single frame. Fortunately, the commonality of targets in the spatio-temporal domain can be used to build better target detection models and suppress suspected clutters and noise.
To the best of our knowledge, tracklets information are rarely used in existing infrared target detection methods. Note that tracklets information are widely used in tracking problem, in which the target position in the first frame is given in advance [
11,
12]. However, there is no such prior target information in detection problem in which either a small target exists in a frame or not is still ambiguous.
As discussed above, upon encountering suspected targets or clutters, using the commonality of targets in the spatio-temporal domain is necessary for better detection performance. The commonality features of targets in the spatial domain can be utilized by combining two one-dimensional dense and sparse reconstruction models [
13,
14]. Different from the one-dimensional dense and sparse reconstruction models [
13,
14], in this paper we consider the two-dimensional form of dense and sparse reconstruction no longer transforming a matrix to a vector. A two-dimensional dense reconstruction model is proposed based on the global singular value decomposition (SVD) [
15], which sets the first few singular values equal to zero and preserves the remaining singular values unchanged. However, this method does not give a general method to select the scope of singular values, and the center-bias mechanism will suppress small targets located at the edges of the image while suppressing clutters or noise. To address this limitation of the global SVD-based reconstruction method [
15], we use differences of adjacent singular values to select the proper singular value scope for target extraction, and meanwhile use a sigmoid function to regularize the singular values in order to suppress the background components. The intuition is that each singular value indicates the ability of the corresponding sub-image to approximate the original image. In [
8,
16], the authors give one-dimensional sparse reconstruction models based on the patch-image model. However, these methods have the following limitations: (1) The detection performance depends largely on the patch size (it was set to
in [
8] or
in [
16]), and the patch vectorization and the pixel reconstruction from overlapped patches could also increase the running time of the algorithm. Moreover, in the patch-image model, one target may appear in different locations of several aligned patches, and after vectorization the intrinsic structure and correlations in the image could be broken, which could influence the separation of target and background later; (2) The algorithm uses L1-norm to measure the sparsity of small targets, but L1-norm treats each pixel independently in terms of intensity, thus the pixels with higher intensities (cloud border, artifacts), are easily mistaken for target pixels, and difficult to be removed through a global threshold [
8]. Due to our observation, in an infrared background image, columns (rows) also have non-local self-correlation property and columns (rows) in distant locations are approximately linearly correlated with each other. Hence, to address the first limitation of the patch-image model, we directly consider each column (row) of an image as a column (row) of the observation matrix instead of dividing the image into patches and forming a patch vectorization matrix. Thus, we refer the proposed sparse reconstruction model as a global sparse reconstruction model. Moreover, we exploit entry-wise prior in the sparse reconstruction model to better separate targets from complex backgrounds. The intuition behind the entry-wise prior is that, each pixel in a target should be weighted differently according to its local weighted entropy which measures the local difference between the target and neighboring background. Thus, both the local target features and the global background features are incorporated into the proposed sparse reconstruction model.
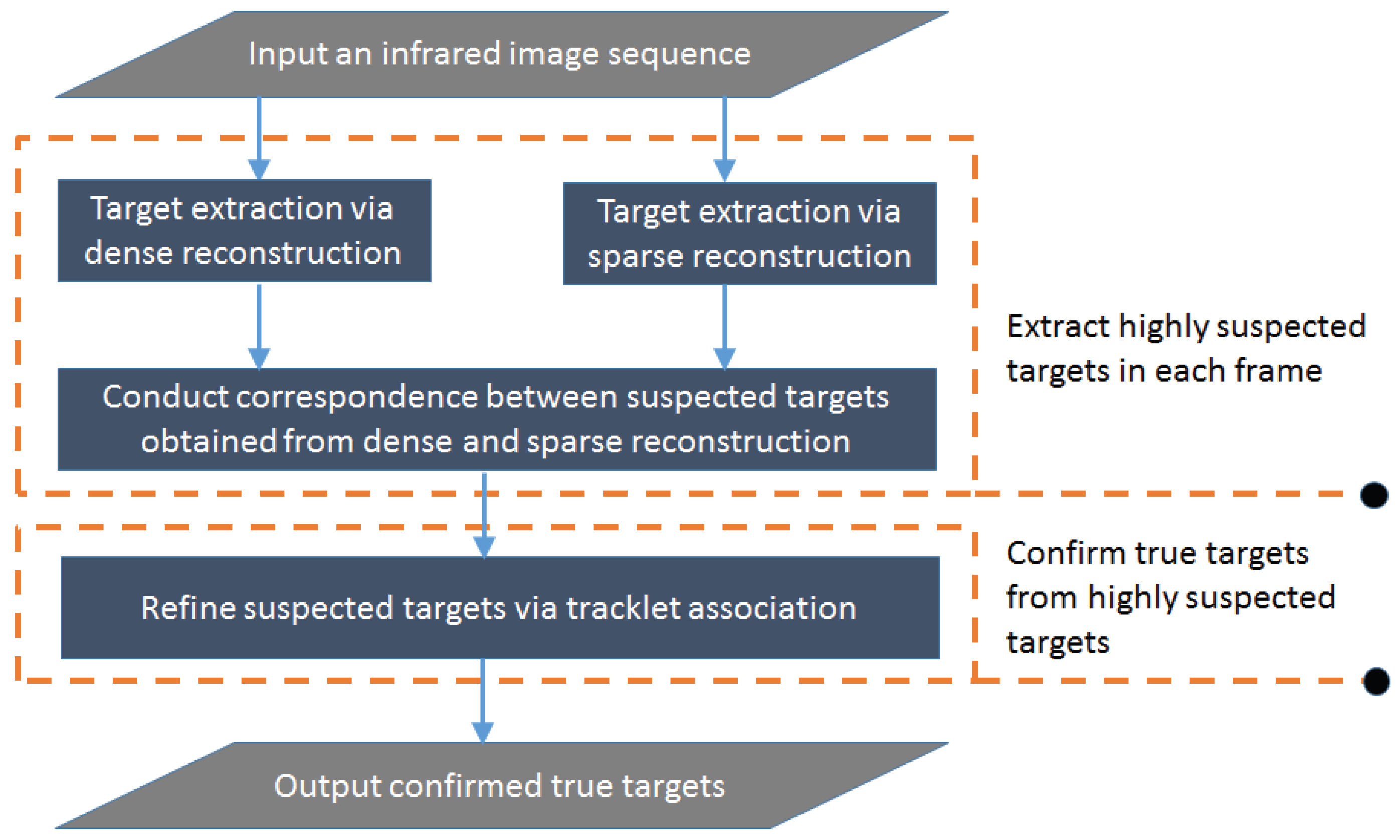
For each frame, to increase the confidence level that candidates are real targets, correspondence between suspected targets obtained by dense and sparse reconstructions is conducted to suppress clutters and false alarms further. As we know, the target region in an infrared image has striking discontinuity with the surrounding background. However, due to our observation, the pixels with higher intensities (cloud border, artifacts) as a whole also have this property. Because of the limited target information available in a single frame, these targe-like false alarms could also be detected as real targets. In order to suppress false alarms further, especially the highly suspected targets, in this paper we adopt multiple frame target refinement by tracklets association, based on the facts that real targets and false alarms have different movement characteristics, and false alarms should not be temporally continuous between successive frames like real targets. Due to that the spatio-temporal target commonality is used to refine the rough detection result of each frame in this paper, thus we refer to the propose method as a target co-detection model.
In this paper, we propose a novel infrared target co-detection model that combines the self-correlation features of backgrounds and the commonality features of targets in the spatio-temporal domain to detect infrared small targets in a sequence of images with complex backgrounds. In the first step, the dense reconstruction model is proposed to extract a coarse target map with benefit of regularization of singular values. In the second step, we design a sparse reconstruction model to extract a sparse target map. In the third step, the correspondence between suspected targets of two types of target maps are conducted to suppress clutters and noise. In the fourth step, the tracklets are associated to suppress false alarms and form trajectories which are used to confirm targets for each frame.
The contributions of this paper are summarized as: (1) A dense target extraction method based on regularization of singular values is proposed. Due to the introduction of a sigmoid function, the background components in the target map can be inhibited further. It should be noticed that we do not minimize the nuclear norm but only use the singular value information; (2) A sparse target extraction method based on entry-wise weighted robust principal component analysis is presented. The entry-wise weight uses the structure prior based on the local difference between the target and neighboring background existing in a natural scene from viewpoint of human recognition, which can promote the complex background suppression effect and keep the small target, and (3) we propose a false alarm suppression and target refinement method based on location correlation of the dense and sparse reconstruction maps for a single frame and tracklet association of the location correlation maps for successive frames. Based on the spatio-temporal commonality features of targets, this method can effectively detect small targets and suppress false alarms as much as possible.
The remainder of this paper is organized as follows.
Section 2 reviews the related work from the view of processing units in the target detection.
Section 3 presents our detection approach comprising of single frame target extraction and multiple frame target refinement. The evaluation on real infrared data set and comparisons are presented in
Section 4. Conclusions are given in
Section 5.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}