1. Introduction
The inertial navigation system (INS) is an entirely autonomous navigation system, in the sense that it precisely provides the navigation parameters for the carrier without the aid of a signal from an external device. As is well known, the performance of INS operated on a moving base is heavily influenced by the accuracy of transfer alignment, which is an important research interest of modern navigation techniques. In particular, the alignment issue between a main INS (MINS) and a slave INS (SINS) has drawn extensive attention, partially due to its widespread application in diverse carriers. For the MINS/SINS system, the unknown parameters of SINS are commonly initialized by MINS at the very beginning. The inevitable initial misalignments will lead to poor accuracy of the follow-on navigation operation, and thus, the alignment stage of SINS is necessitated. In [
1], the rapid transfer alignment (RTA) on the basis of the “attitude plus velocity” matching scheme was originally proposed to estimate the attitude errors between two INSs. Then, the misalignment angles of SINS with respect to the local navigation frame can be indirectly determined. Compared with traditional transfer alignment, the RTA has superiorities in both model observability and convergence rate, and it has been widely applied for both military and civilian purpose [
1,
2,
3].
The central concerns of RTA are the estimation accuracy and convergence rate, both of which are intimately related to the performance of the filtering algorithm. For the RTA with the linearized model and Gaussian noise, the capacity of the Kalman filter (KF) that provides optimal estimation has been authoritatively verified through numerical simulation and field tests [
1]. However, the INS sometimes has to be initiated in a complicated environment, and higher demanding standards are put forward to the filtering algorithm. First, for some quick response missions, the initial misalignment angles of INS may be notably large, and significant nonlinearity will be brought into the model description of RTA [
2]. That is, the nonlinear character of the filtering algorithm should be deliberately considered. In addition, the precision of observations severely influences the performance of RTA. Nevertheless, in practice, the phenomenon of uncertain observations frequently occurs due to the existence of multiple disturbances, including outliers, the time delay of data transmission, the coupling effect between the lever arm and deformation, etc. [
4,
5]. The suppression of negative effects induced by these disturbances is of crucial importance to the improvement of the accuracy and stability of RTA. For this purpose, accurate modeling methods have been developed as intuitive solutions for the compensation of these disturbances [
6,
7,
8]. Yet, the complexity of the model will be severely increased, and the un-modeled errors will destroy the veracity of model. Another way is to take these disturbances as uncertain interfering input of the model, and against the negative effect by means of the robust filtering algorithm. On the premise of the bounded energy of noise, one effective method is the H
filter, which intends to minimize the downside on estimation results in the worst case of the un-modeled disturbance and uncertainty. Contrary to KF, the H
filter requires neither statistical noise properties, nor the exact system model and provides robust and accurate estimations, while the uncertain parameters exist in the model description [
9].
Many solutions, as exemplified by the Krein space approach and the game theory approach, have been developed for the linear H
problem [
9,
10,
11,
12]. Afterward, these solutions are naturally adopted for nonlinear systems with the utilization of the first-order linearization method; to be more precise, the extended H
filter (EH
F) [
13,
14]. However, the EH
F inherits the drawbacks of the extended Kalman filter, i.e., the cumbersome computation of Jacobians and the deterioration of estimation performance in the presence of significant nonlinearity. Recent decades have witnessed the development of sample-point filters on the basis of deterministic sampling quadrature methods (as exemplified by the unscented transform, the cubature integration rule, the Gauss–Hermite quadrature rule, etc.), which either approximate the probability distribution function representing state estimates by a set of sample-points or approximate the nonlinear functions using polynomial expansions [
15,
16,
17,
18]. The emergence of these quadrature methods facilitates the arising of the derivative-free H
filter (DFH
F), such as the unscented H
filter, cubature H
filter (CH
F) and sparse-grid quadrature H
filter [
19,
20,
21]. Compared with EH
F, the DFH
F releases the restriction of computing Jacobians and achieves high accuracy, as the posterior estimations are accurately approximated to certain order. However, the approximations given by deterministic sampling quadrature methods cannot eliminate systematic errors that exist in the solution of DFH
F [
15]. That is, the estimation accuracy will be degraded while significant nonlinearity exists in the model description. Moreover, the boundedness and convergence of estimation error cannot be guaranteed due to the local validity of these quadrature methods. To overcome these disadvantages, as of late, a novel filter, named the stochastic integration filter (SIF), was proposed to provide asymptotically exact estimation for nonlinear systems [
22,
23,
24]. The core of SIF is the stochastic spherical-radial integration rule (SSRIR), which approximates the probability distribution function of posterior estimation by a set of randomly-chosen sample-points [
25]. Contrary to the deterministic sampling quadrature methods, the SSRIR can theoretically eliminate the systematic error with increasing iterations. Therefore, it can be reasonably concluded that the incorporation of SSRIR with the framework of DFH
F will result in a filter with high accuracy and strong robustness, but there were few published literature works focused on this study. This paper is devoted to developing a stochastic integration H
filter (SIH
F) to address the RTA issue with the coexistence of significant nonlinearity and uncertain observation noise statistics. For the first time, the SSRIR is combined with the framework of DFH
F, and the resulting SIH
F achieves estimation with both accuracy and robustness. Numerical simulation and the van test are separately executed for the validation of the proposed method. The results demonstrate that the SIH
F has better performance than the previous, well-known CH
F and SIF.
The rest of this paper is organized as follows: The nonlinear model of RTA is briefly introduced in
Section 2.
Section 3 firstly represents the preliminaries of the H
technique and the EH
F. Then, the derivation of SIH
F is described in detail. Numerical simulation is executed in
Section 4, in order to demonstrate the superiorities of SIH
F compared with the CH
F and SIF. In
Section 5, the validity of the proposed method is further verified through a van test. The conclusions are given in
Section 6.
2. System Modeling of Rapid Transfer Alignment
The aim of system modeling is to describe the error propagation principle of RTA. In this section, the process model and observation model of RTA with the nonlinear characteristic are briefly introduced. The system modeling lays the foundation for the development of the filtering algorithm in the following section.
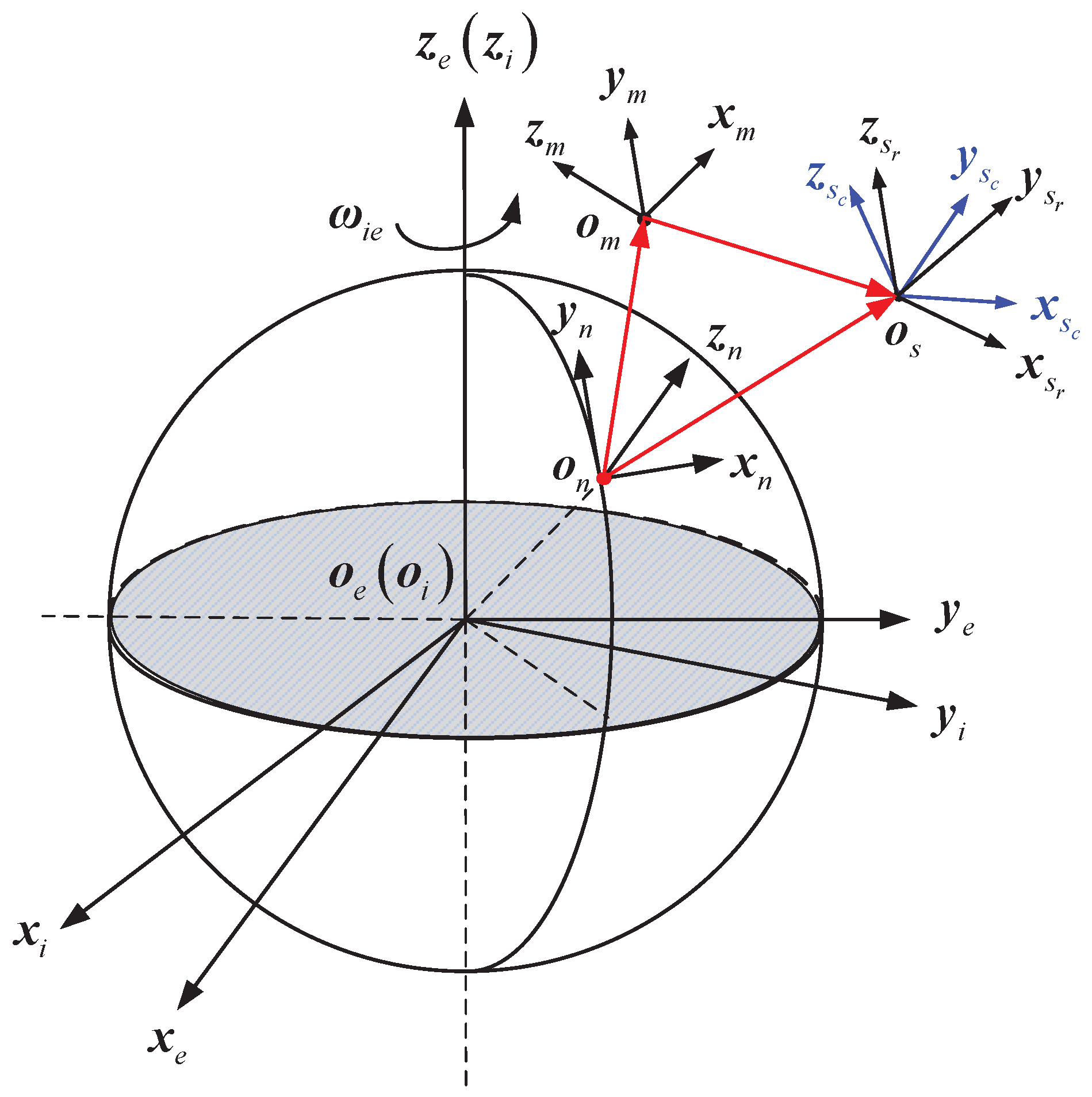
The definitions of coordinate systems used in system modeling are shown in
Figure 1, where
i-frame denotes the inertial frame,
e-frame denotes the Earth-centered Earth-fixed frame,
n-frame denotes the local navigation frame,
m-frame denotes the body frame of MINS,
-frame denotes the body frame of SINS and
-frame denotes the calculated body frame of SINS. Note that all of these coordinated systems are right handed and Cartesian; the detailed specifications of these coordinate systems can be found in [
2].
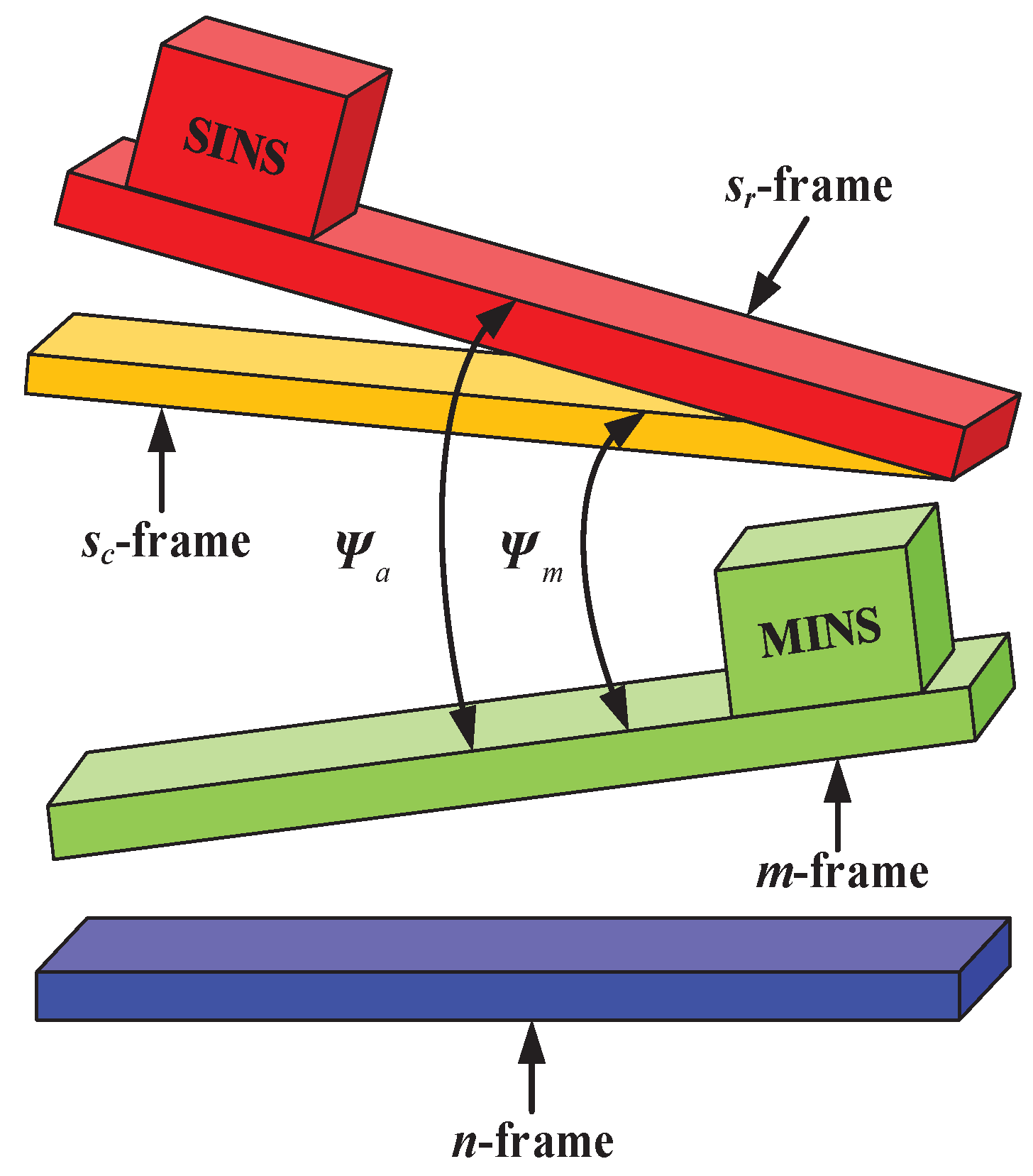
In this paper, the two INSs are assumed to be directly installed on the carrier, and the sketch map of misalignment angles between the MINS and SINS is represented in
Figure 2, where
represents the misalignment angles between the
m-frame and the
-frame and
represents the misalignment angles between the
m-frame and the
-frame. The eventual purpose of RTA is to determine the attitude transformation matrix from
-frame to
n-frame. Since the errors of MINS have been well compensated by the external aid of the device, the attitude parameters given by MINS can be viewed as reliable. In other words, the goal of RTA can be indirectly achieved by estimating the attitude errors between the two INSs, i.e.,
. However, due to the inherent accumulative errors of sensors, only the inertial data sensed by SINS projected in the
-frame imply the misalignment information. Therefore, the description of error propagation is the prerequisite of RTA.
Generally, the process model of RTA includes the attitude error equation, velocity error equation, dynamic models of inertial sensors and actual physical misalignment angles. The attitude error equation mainly describes the function relationship between
and
. Assuming that large misalignment angles exist in all three axes, the attitude error equation of RTA is given by [
2]:
where
is defined as:
and
, (
) denotes the measurable misalignment angle in the corresponding axis;
is the unit matrix;
denotes the attitude transformation matrix from the
m-frame to the
-frame;
represents the attitude transformation matrix from the
-frame to the
m-frame;
is the angular velocity of the
-frame relative to the
n-frame projected in the
-frame;
is the constant drift of the gyroscope with dynamic model
;
is the noise term of the attitude error equation.
On the basis of the velocity solution given by the strapdown algorithm, the velocity error equation can be described as [
2]:
where
is the velocity error vector projected in the
n-frame;
is the angular velocity of the
e-frame relative to the
i-frame projected in the
n-frame;
is the specific force sensed by SINS projected in the
-frame;
is the angular velocity of the
n-frame relative to the
e-frame projected in the
n-frame;
is the attitude transformation matrix from the
m-frame to the
n-frame, and it is commonly provided by MINS in real time;
is the constant bias of the accelerometer with dynamic model
;
is the noise term of the velocity error equation. Note, the derivation of Equation (
3) assumes that the acceleration induced by the lever arm effect has been well compensated.
Due to the impact of vibration and flexure, the modeling of
makes a compromise between the complexity and accuracy, that is [
1]:
where
is the noise term with covariance
.
Choosing the state vector as
, the process model of RTA can be represented as follows:
The modeling of observation relies on the matching scheme of RTA. In this paper, the measurable misalignment angles and velocity error are chosen as observations. That is:
where
represents the function that calculates the Euler angle from the attitude transformation matrix;
and
denote the velocity of SINS and MINS projected in their own body frame, respectively.
The observation model is given by:
where
is the observation noise. The coefficient matrix
is described as:
The system modeling of RTA implies that many factors could affect the precision of observations provided by MINS; for instance, the unreliable signal from the external aid of the device, the random time-delay effect, the coupling effect of the lever arm and deformation, etc. These unpredictable disturbances may induce uncertain statistics of observation noise, which motivates the investigation of the nonlinear filtering method to improve both the accuracy and robustness of RTA.
3. Stochastic Integration H Filter
In this section, the derivations of SIHF are described in detail. First, the preliminaries of the H technique and EHF are briefly represented. Then, the general form of DFHF is given as the prerequisite of derivations. At last, the construction of SSRIR is introduced to evaluate the Gaussian weighted integrals in DFHF, and SIHF can be consequently achieved by combining the SSRIR with the framework of DFHF.
3.1. Preliminaries of the H Technique
A representative nonlinear discrete-time system can be represented as follows:
where
is the state vector;
is the observation vector;
is the signal to be estimated;
and
are the process model and the observation model, respectively;
is a known matrix, which will be replaced by the identity matrix for estimating the whole state vector in this study; the process noise
and observation noise
are assumed to be the signals with bounded energy, but unknown statistics, i.e.,
,
.
Let
be the estimation error; the essential purpose of the H
technique is to estimate
to minimize
under the worst case of initial estimation error, process noise and observation noise. For this purpose, the game theory approach gives a celebrated cost function, so as to map the disturbances and uncertainties to the estimation error. That is:
where
denotes the initial covariance of the state vector and
and
are the covariance of process noise and observation noise, respectively. The norm notation stands for
.
The H
filter sequentially estimates
to satisfy the following inequality:
where notation
stands for the supremum;
represents the error attenuation parameter that is empirically set to a constant value or iteratively computed in real time [
19,
21].
3.2. Extended H Filter and Derivative-Free H Filter
As an intuitive extension of the linear H
solution, the EH
F has been well studied to achieve suboptimal solutions for a nonlinear system with uncertainties [
13,
14]. The implementation of EH
F is represented as follows:
where
is the predicted mean with covariance
;
is the filtered mean with covariance
;
and
represent the Jacobian matrices of
evaluated at the filtered mean
and
evaluated at the predictive mean
, respectively;
is the gain matrix;
is the auxiliary matrix.
Though the first-order Taylor expansion is utilized in EHF to approximate the nonlinear model, the rough linearization method may degrade the estimation accuracy or even induce divergence in the presence of significant nonlinearity. Moreover, the computation of Jacobians is also an inevitable difficulty for the complicated model description. To overcome the limitations of EHF, multiple DFHFs have been proposed on the basis of deterministic sampling quadrature methods. Without loss of generality, the general form of DFHF is represented as follows.
Analogous to the nonlinear filter with the Gaussian assumption, the prediction step of DFH
F is given by:
where
denotes the variable
subject to the Gaussian probability distribution function with mean
and covariance
, and this notation is available for other equations.
Under the assumption that the integrated state vector needs to be estimated, the filtering step of DFH
F can be described as:
where
is the gain matrix;
is the predicted observation with covariance
;
is the cross-covariance between the state vector and observation vector. Note that these three statistics of observation involve the computation of Gaussian weighted integrals, that is:
The auxiliary matrix
is given by:
In contrast to the EH
F, the prediction step of DFH
F is explicitly replaced by the general Gaussian approximations, i.e., Equations (
18) and (
19). Furthermore, on the basis of the statistical linear error propagation method, the statistics related to Jacobian matrix
in Equations (
13), (
16) and (
17) are substituted by the following approximations [
26]:
3.3. Stochastic Spherical-Radial Integration Rule
It is worth noting that the general form of DFHF requires the evaluation of Gaussian weighted integrals with the form . In general, these nonlinear integrals cannot be analytically solved, and the numerical approximation method is required. Contrary to the previous deterministic sampling methods, in this paper, the SSRIR is employed for the evaluation of . Note that two transformations must be implemented to convert the nonlinear integral expression to the standard form.
The first transformation relates to the integration variable, i.e.,
, where
is the lower triangular matrix obtained from the Cholesky decomposition of covariance
. That is:
where
is the dimension of
.
The second transformation concerns the conversion of the integral variable to the radial-spherical coordinate system. Let
, where
. The domain of definition for radius is
. The integral can be rewritten as:
In this stage,
can be regarded as the combination of radial integration with the form
and spherical integration for the unit
-sphere with the form
. The stochastic radial integration rule (SRIR) and stochastic spherical integration rule (SSIR) can be obtained from the following two Lemmas [
25]:
Lemma 1. Assuming a set of weights are computed by the following equation:where , and the set of sample points are extracted from the joint PDF . Then, an unbiased degree SRIR can be obtained for , that is: Lemma 2. Let be a deterministic -degree spherical integration rule for , and is a uniformly chosen orthogonal matrix. Then, is an unbiased -degree SSIR for .
Note, the selection of weights
and sample points
is not unique; various deterministic spherical integration rules are given in [
25].
In this paper, a three-degree SRIR and three-degree SSIR are adopted. Especially, the three-degree spherical integration rule in Lemma 2 is given by:
where
is the surface of the unit
-sphere;
is the surface content of
;
denotes the unit vector with “1” in the
i-th element and “0” in other positions.
The SSRIR can be obtained by constructing a product of a
-degree SRIR and a
-degree SSIR, that is:
where
denotes the total number of the sample points;
is the sample point with weight
.
The approximation of
based on SSRIR with
N iterations can be obtained as:
where
denotes the
l-th
.
In theory, the statistics of function
, including the mean, covariance and cross-covariance, should be separately approximated by SSRIR. However, in consideration of the computational cost, these statistics are commonly approximated in a single run of SSRIR [
22]. For completeness, the detailed implementation of SSRIR with constant iterations is represented as follows:
Initialize the number of iterations . Define the maximum number of iterations as . Set the initial mean value , initial covariance and initial cross-covariance ; where is the dimension of .
While
, use Equation (
33) to generate the SSRIR-based sample points
and corresponding weights
at the
l-th iteration.
Calculate the statistics of
at the current iteration:
Set , and shift to Step 2.
For simplicity, the implementation of SSRIR can be compactly denoted as:
If the process model in (
9) is nonlinear, Equations (
18) and (
19) can be substituted with:
Analogously, if the observation model in (
9) is nonlinear, Equations (
22)–(
24) can be substituted with:
Eventually, Equations (
20), (
21), (
25), (
39) and (
40) are composed of the integrated SIH
F method. The flowchart of the SIH
F algorithm is shown in
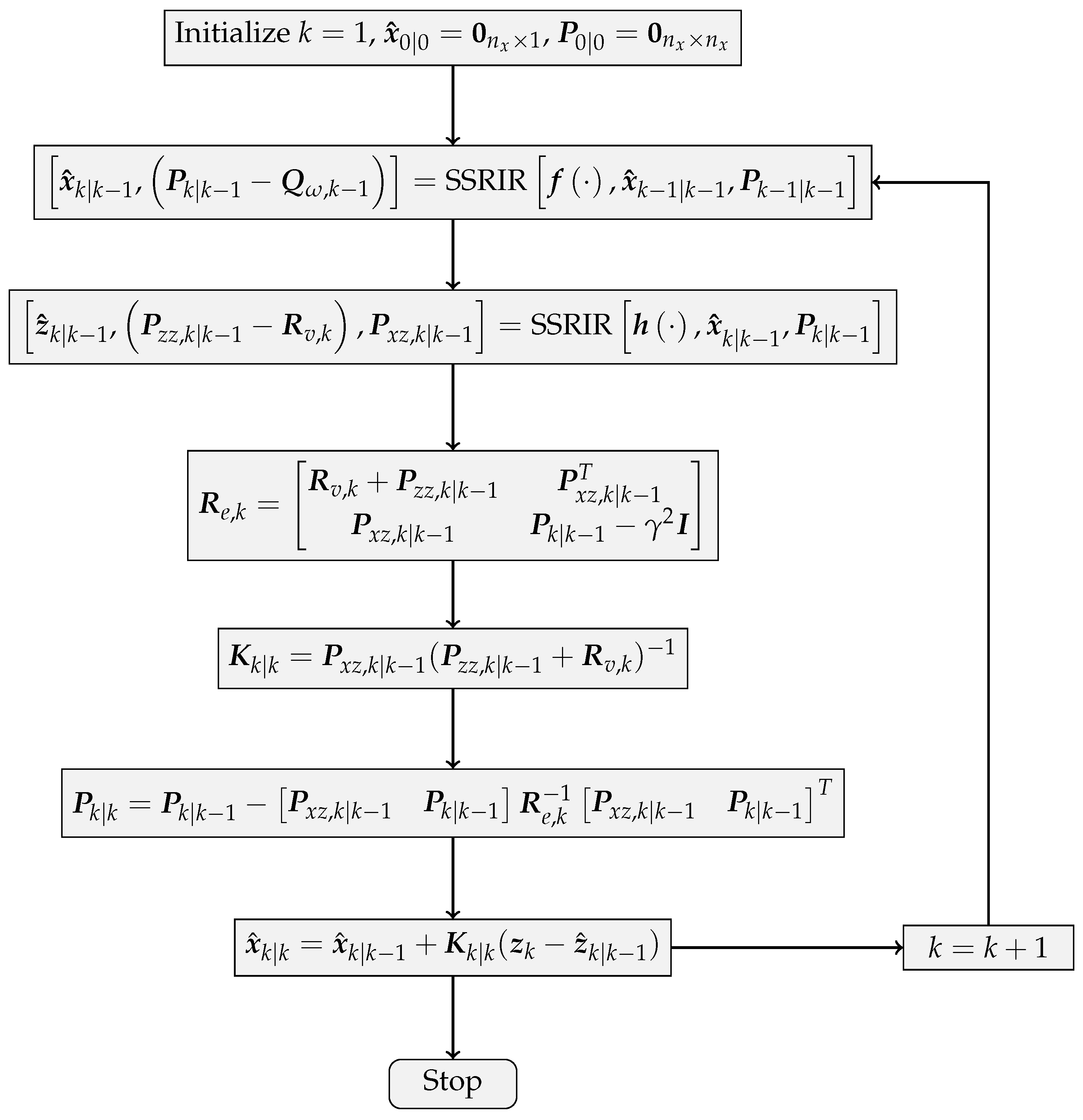
Figure 3.
Figure 3 implies that the SSRIR is incorporated with the framework of DFH
F so as to approximate the nonlinear function in the model description. Compared with the traditional SIF, the SIH
F introduces the cost function described in Equation (
10) and aims to estimate the state under the worst initial error and model uncertainty.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
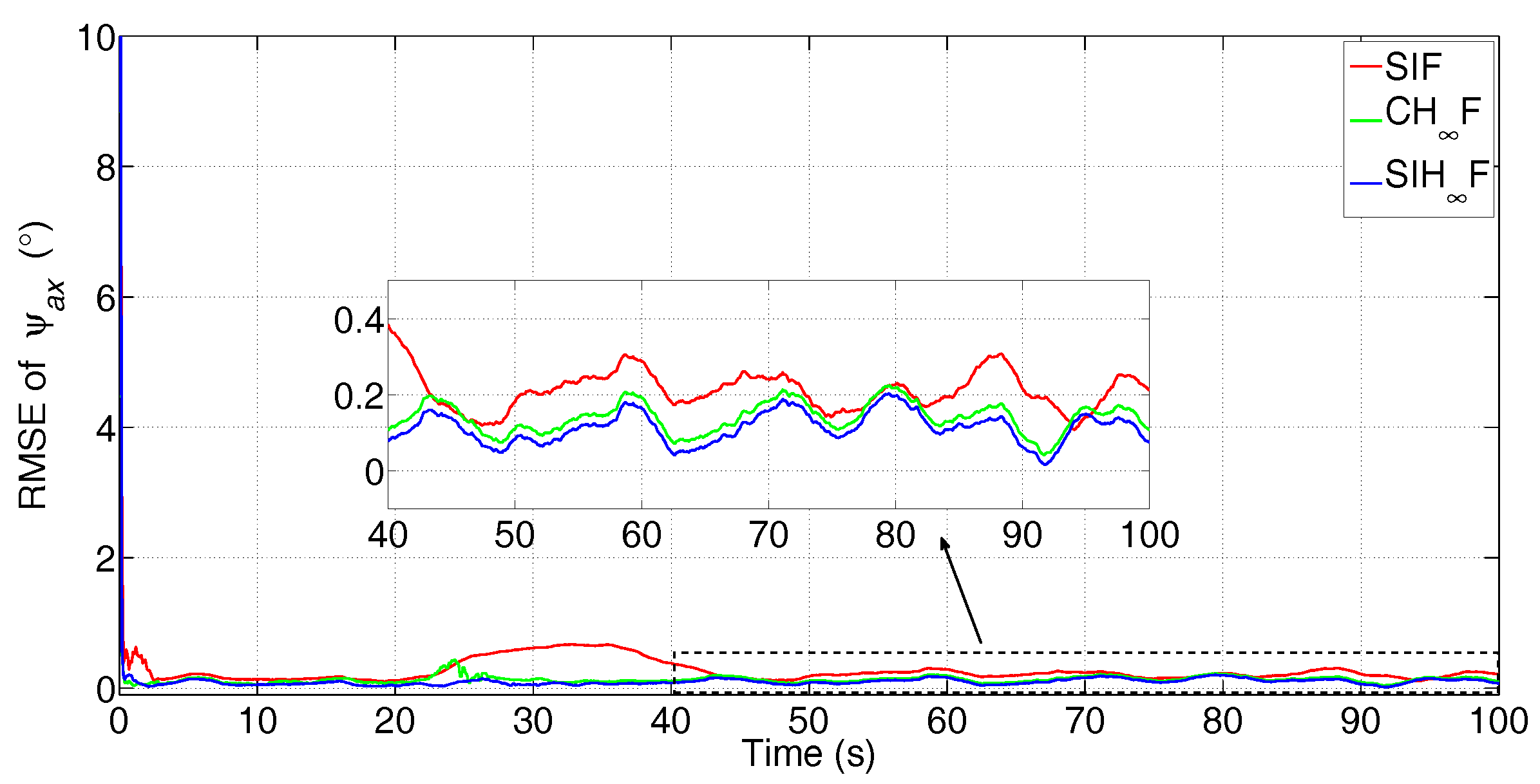{kind=link}
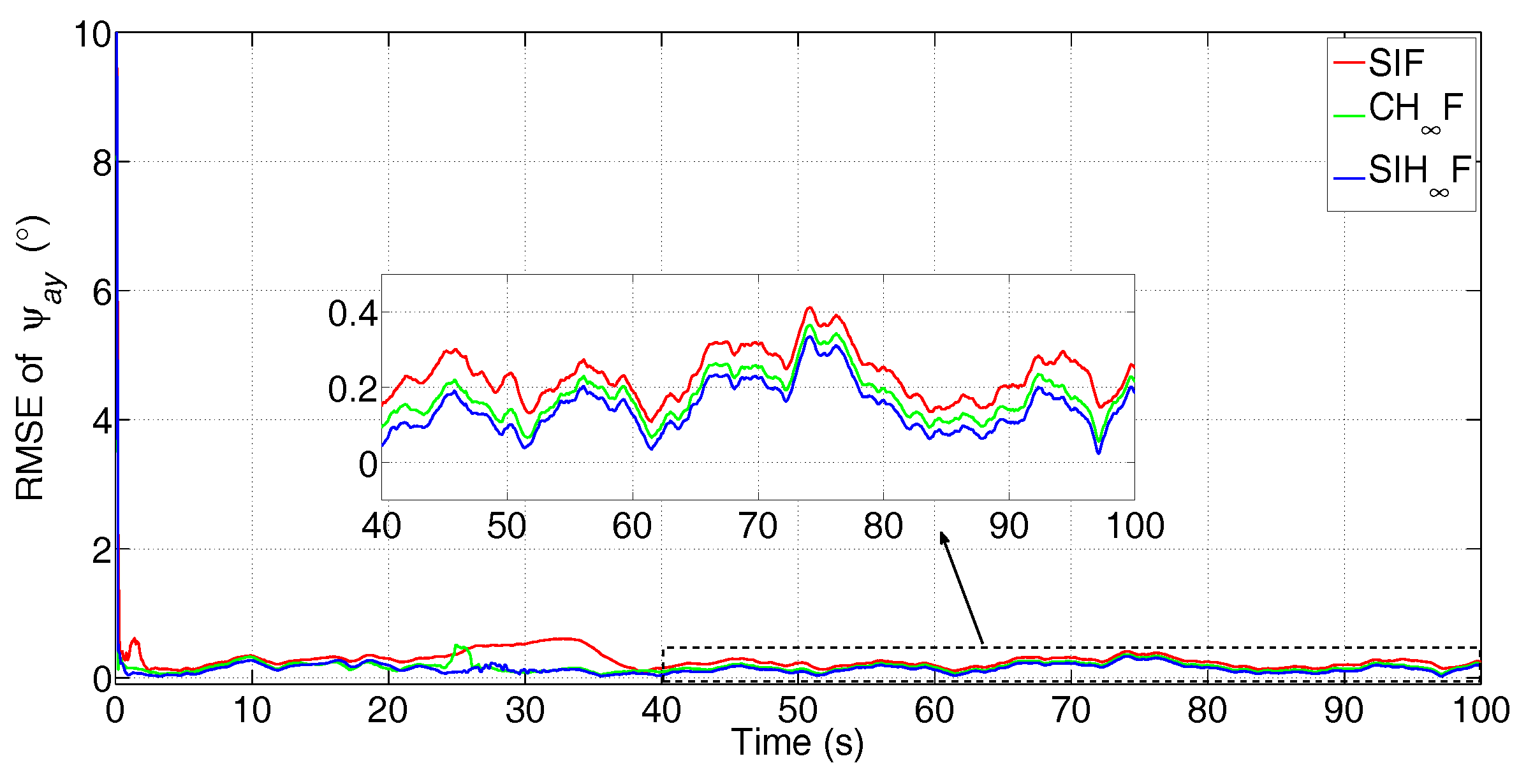{kind=link}
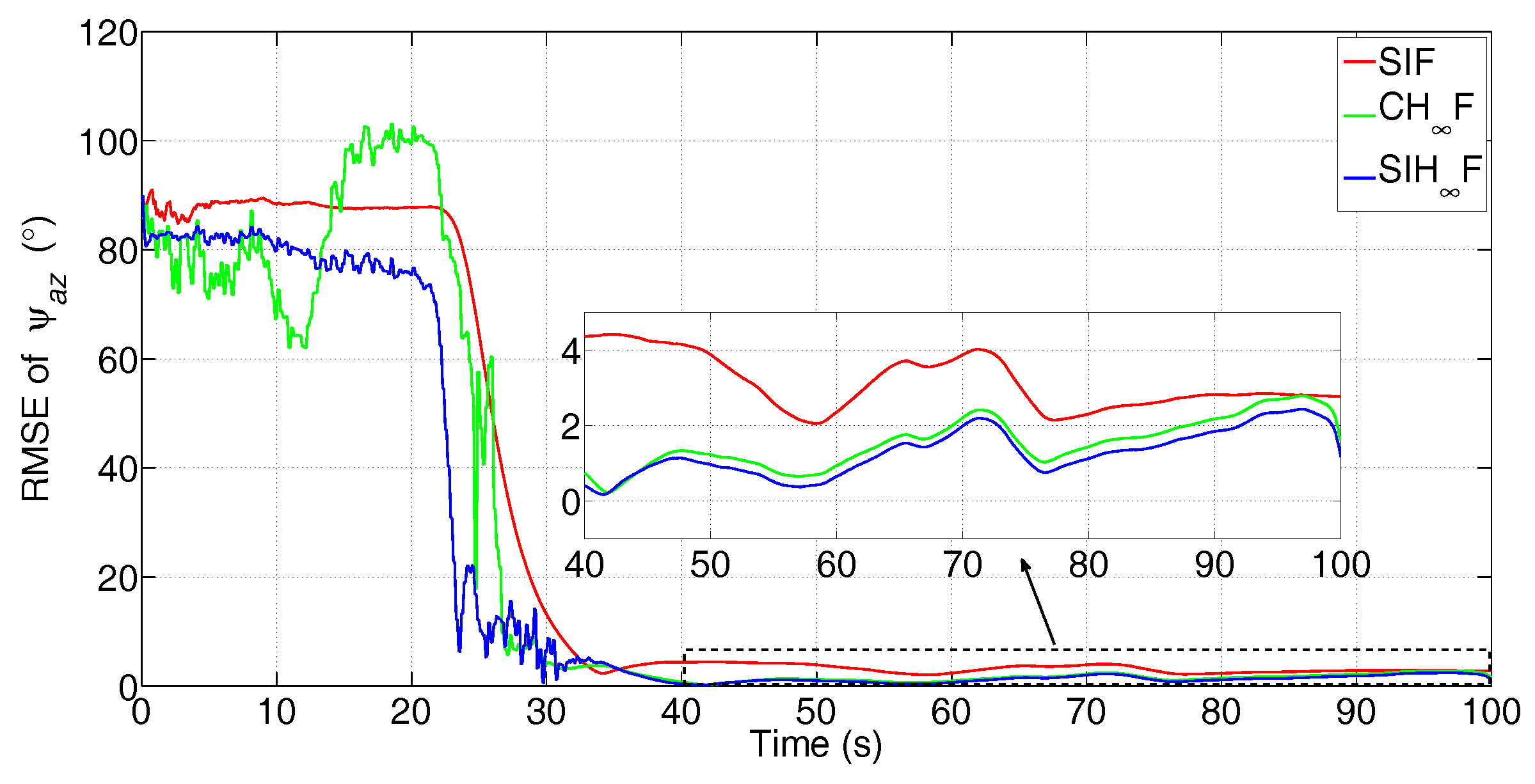{kind=link}
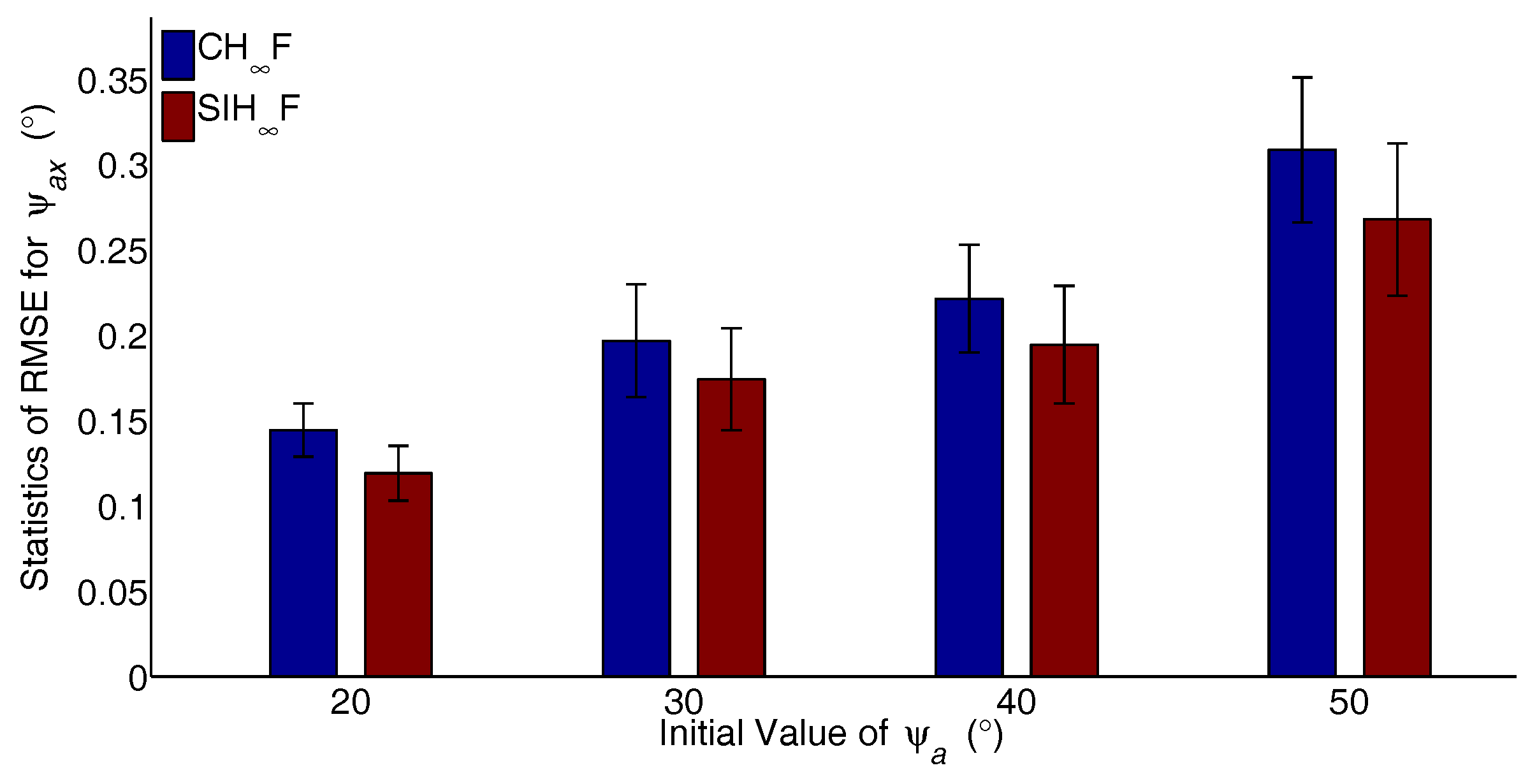{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
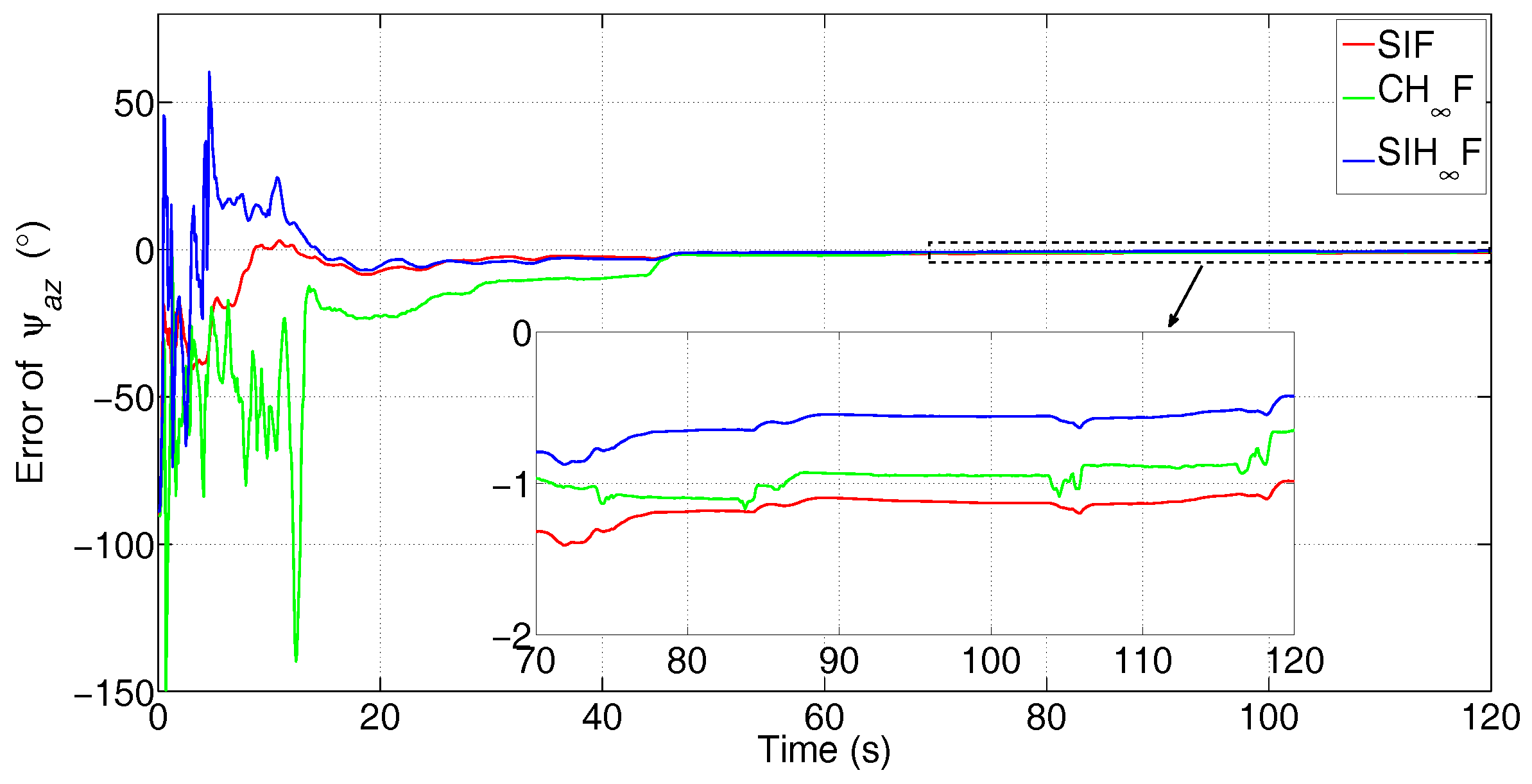{kind=link}