
Facial Expression Recognition with Fusion Features Extracted from Salient Facial Areas

Abstract
:1. Introduction
2. Methodology
2.1. Faces Alignment and Salient Facial Areas Definitude
2.2. Salient Areas Normalization and Features Extraction
2.2.1. Salient Areas Normalization
2.2.2. Features Extraction
2.3. Features Correction and Features Fusion
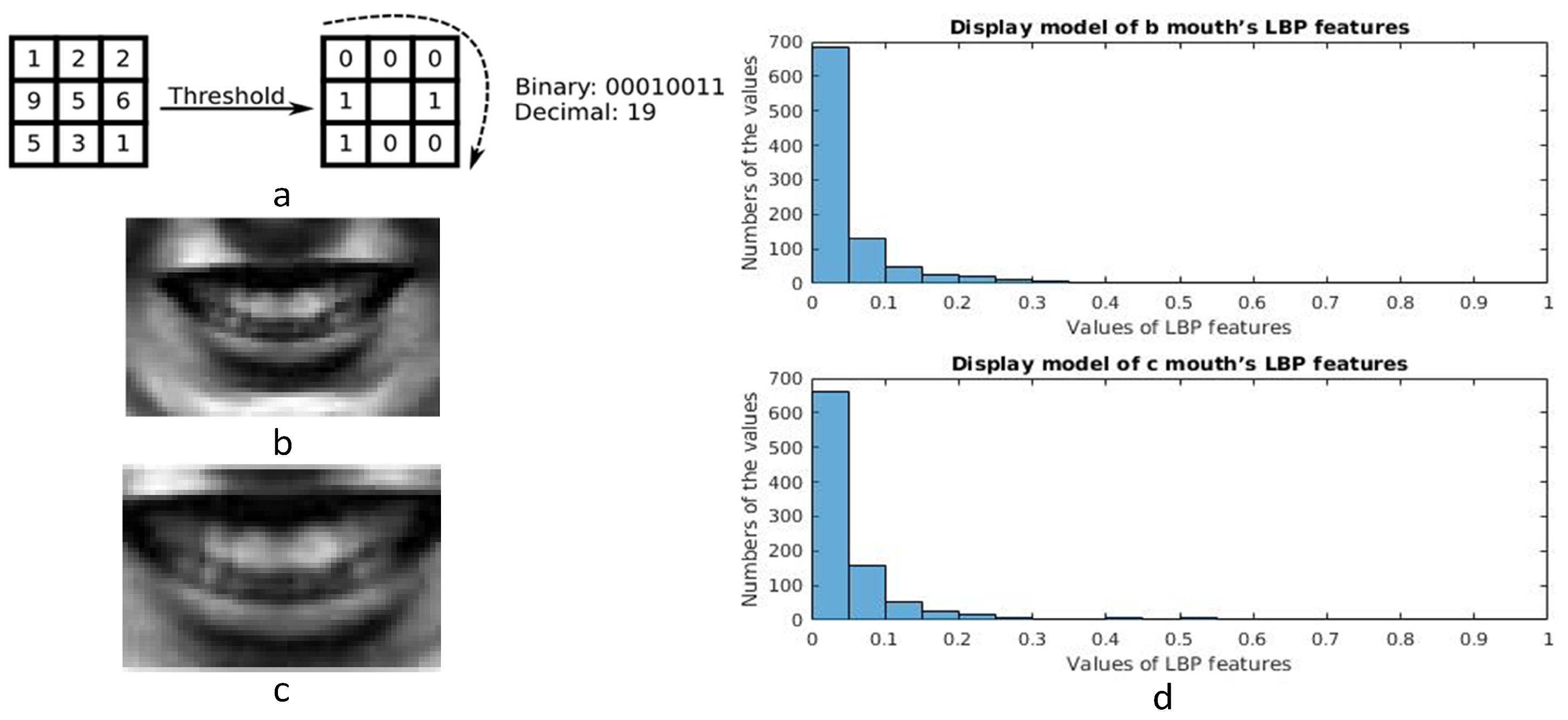
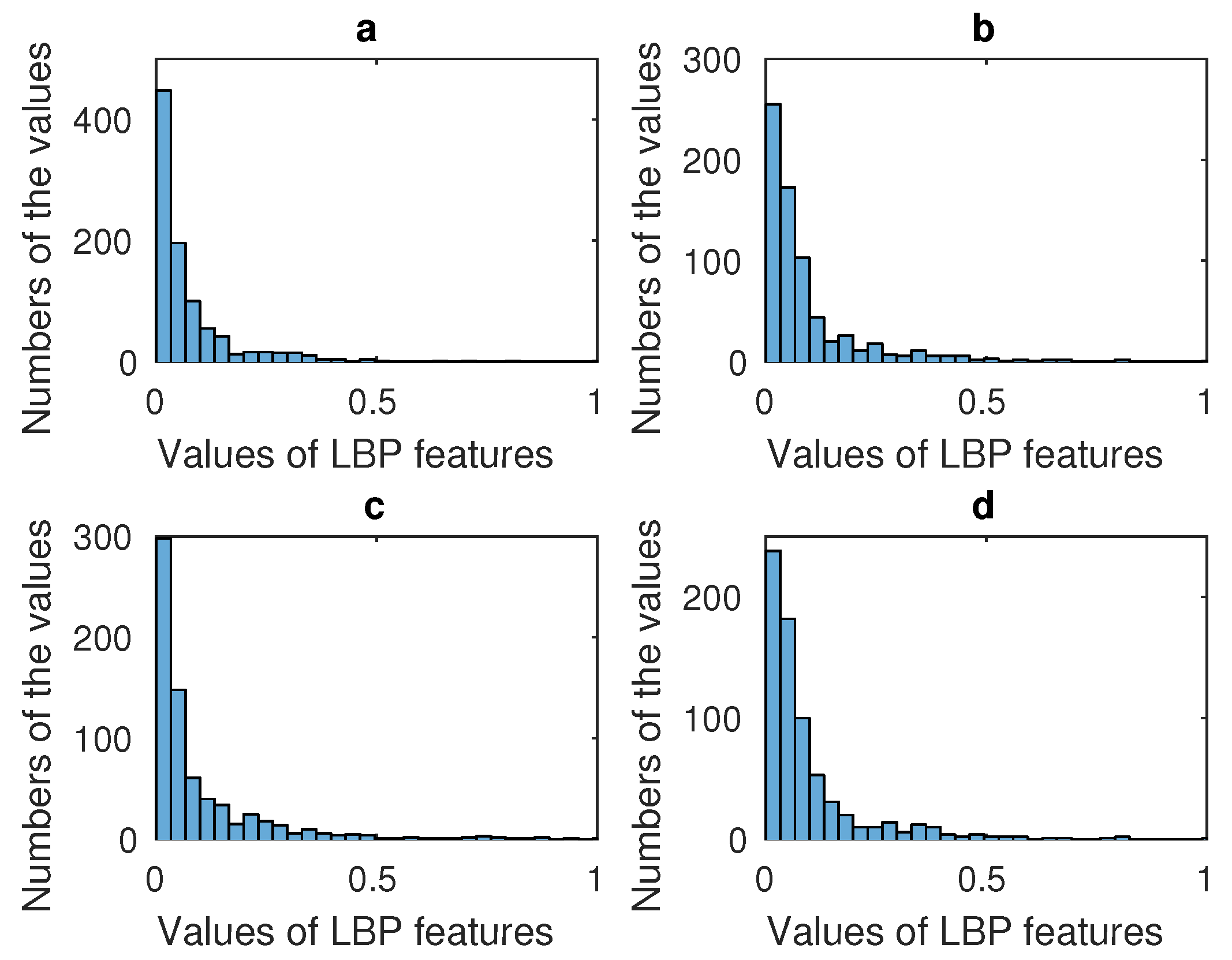
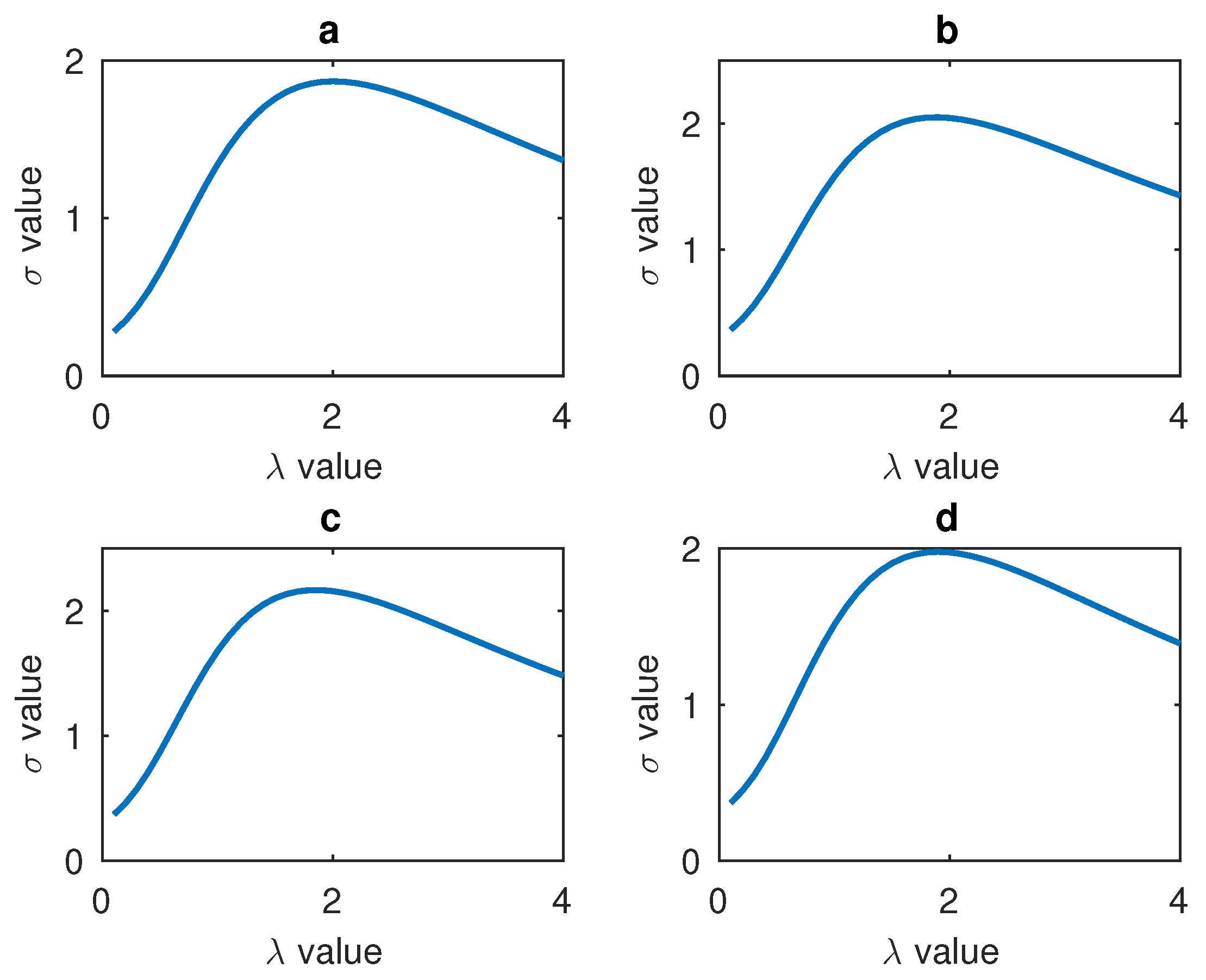
2.3.1. LBP Correction
2.3.2. HOG Processing and Features Fusion
2.4. Principal Component Analysis( PCA) and Classifiers
3. Database Processing
3.1. CK+ Database
3.2. JAFFE Database
4. Experiments
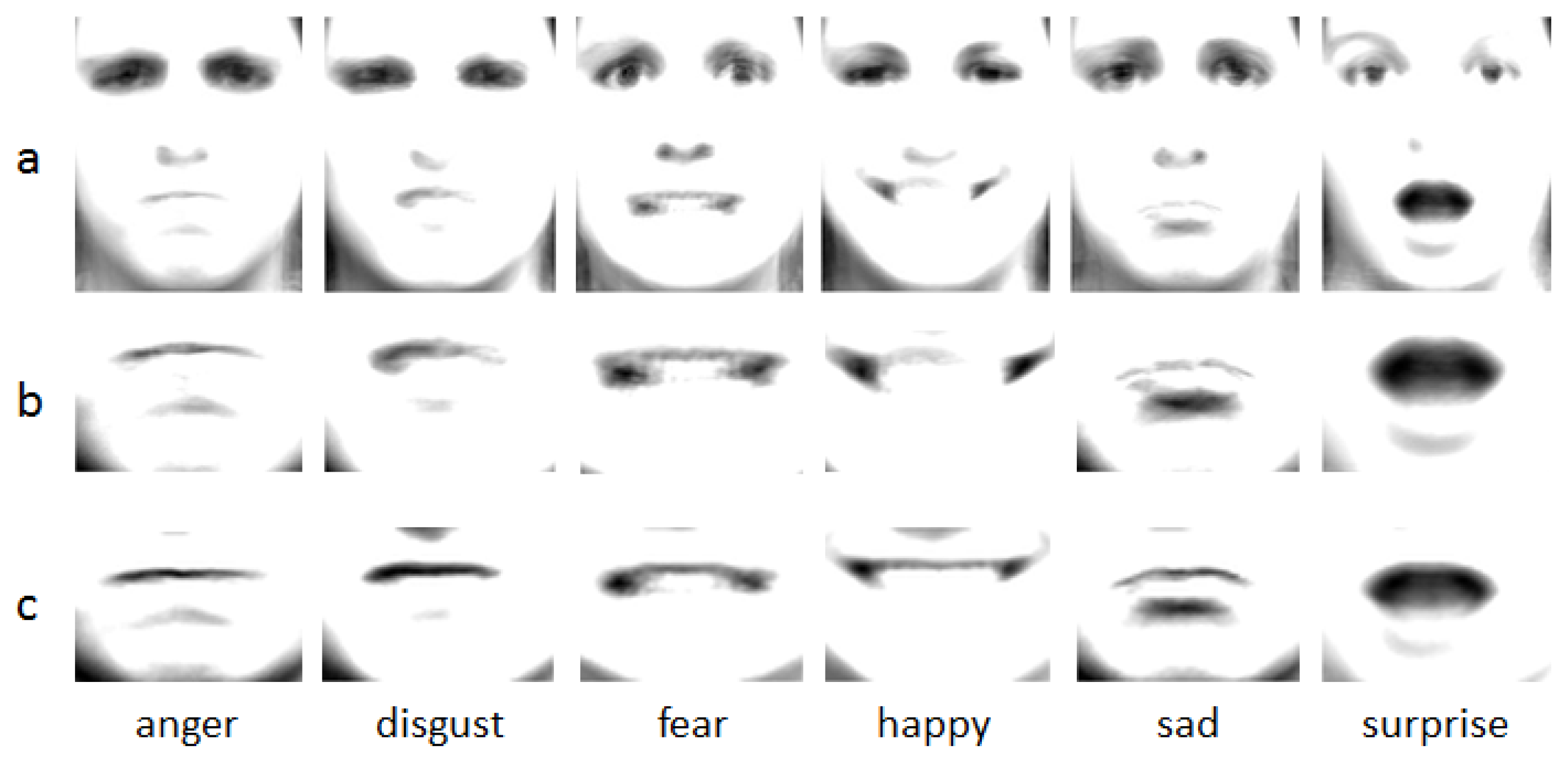
4.1. Salient Areas Definitude Method Validation
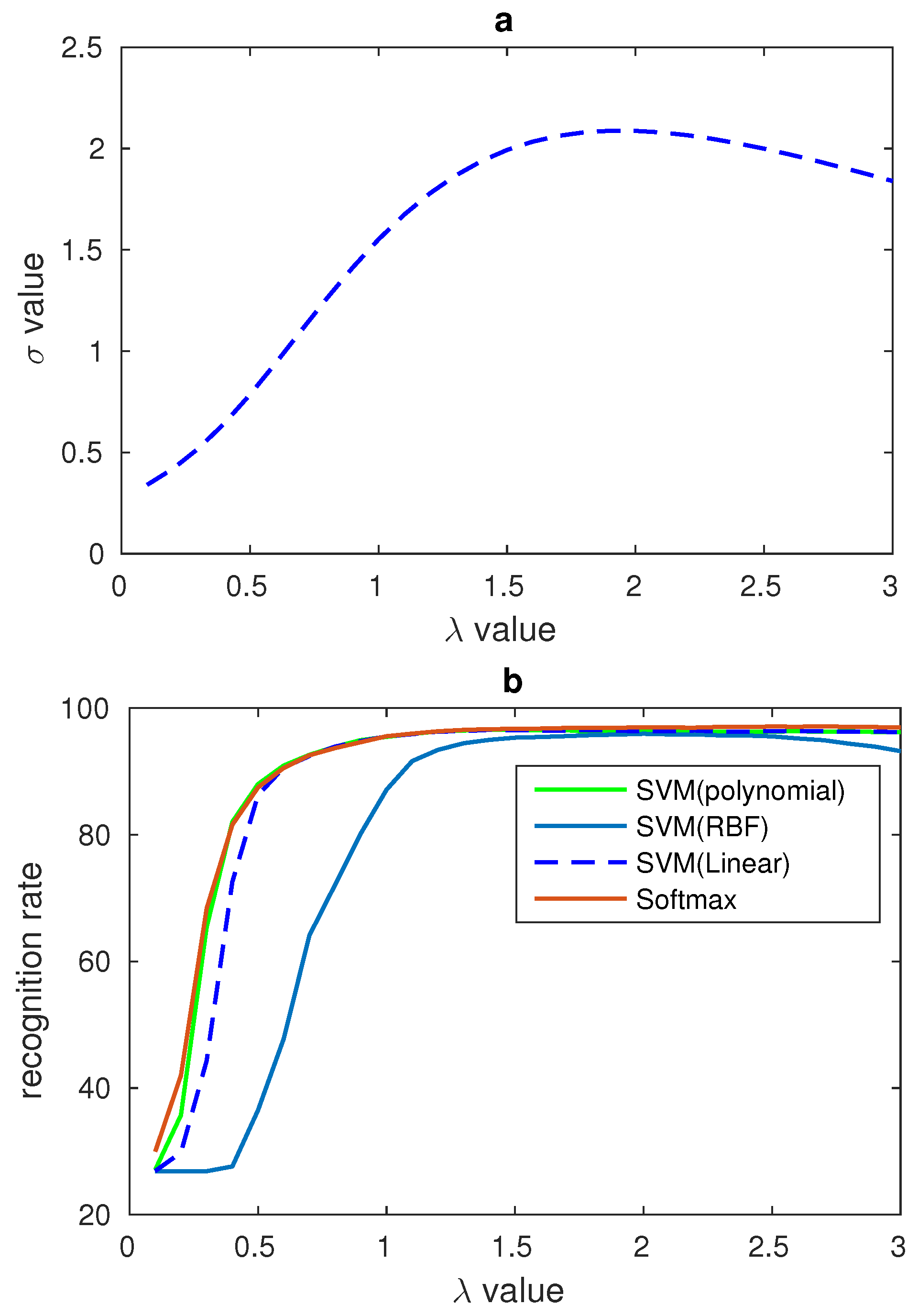
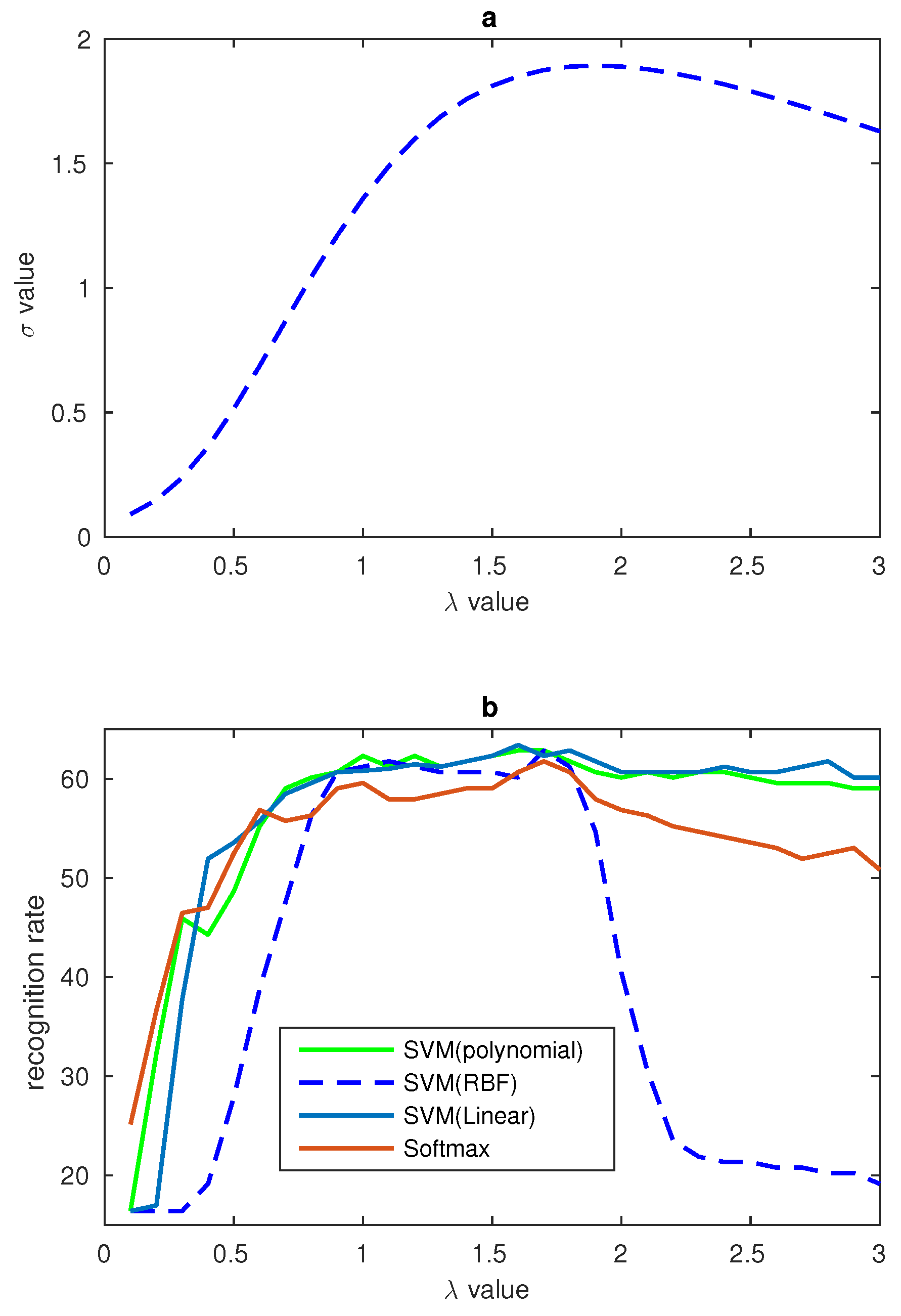
4.2. Gamma Correction of LBP Features
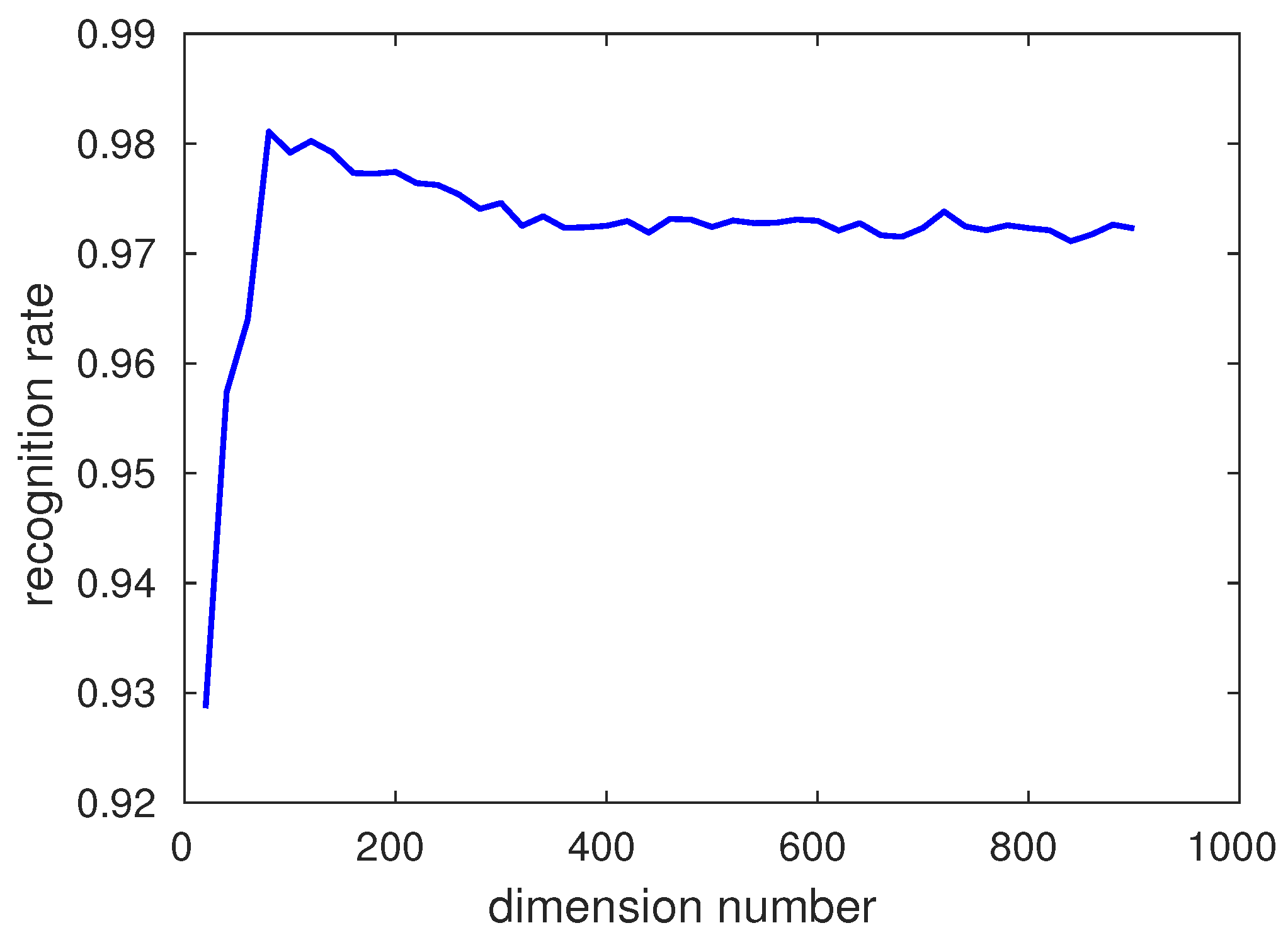
4.3. Features Fusion, PCA and Recognition Rate Comparison
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Izard, C.E. The Face of Emotion; Appleton-Century-Crofts: New York, NY, USA, 1971. [Google Scholar]
- Liu, M.; Li, S.; Shan, S.; Chen, X. Au-inspired deep networks for facial expression feature learning. Neurocomputing 2015, 159, 126–136. [Google Scholar] [CrossRef]
- Zhong, L.; Liu, Q.; Yang, P.; Liu, B.; Huang, J.; Metaxas, D.N. Learning active facial patches for expression analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2562–2569. [Google Scholar]
- Shan, C.; Gong, S.; McOwan, P.W. Facial expression recognition based on local binary patterns: A comprehensive study. Image Vis. Comput. 2009, 27, 803–816. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Wang, J.; Yin, L.; Wei, X.; Sun, Y. 3D facial expression recognition based on primitive surface feature distribution. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1399–1406. [Google Scholar]
- Lei, Y.; Bennamoun, M.; Hayat, M.; Guo, Y. An efficient 3D face recognition approach using local geometrical signatures. Pattern Recognit. 2014, 47, 509–524. [Google Scholar] [CrossRef]
- Vezzetti, E.; Marcolin, F.; Fracastoro, G. 3D face recognition: An automatic strategy based on geometrical descriptors and landmarks. Robot. Auton. Syst. 2014, 62, 1768–1776. [Google Scholar] [CrossRef]
- Vezzetti, E.; Marcolin, F. 3D Landmarking in multiexpression face analysis: A preliminary study on eyebrows and mouth. Aesthet. Plast. Surg. 2014, 38, 796–811. [Google Scholar] [CrossRef] [PubMed]
- Jung, H.; Lee, S.; Park, S.; Lee, I.; Ahn, C.; Kim, J. Deep Temporal Appearance-Geometry Network for Facial Expression Recognition. arXiv, 2015; arXiv:1503.01532. [Google Scholar]
- Zavaschi, T.H.; Britto, A.S.; Oliveira, L.E.; Koerich, A.L. Fusion of feature sets and classifiers for facial expression recognition. Expert Syst. Appl. 2013, 40, 646–655. [Google Scholar] [CrossRef]
- Hu, Y.; Zeng, Z.; Yin, L.; Wei, X.; Zhou, X.; Huang, T.S. Multi-view facial expression recognition. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition, Amsterdam, The Netherlands, 17–19 September 2008; pp. 1–6. [Google Scholar]
- Happy, S.; Routray, A. Robust facial expression classification using shape and appearance features. In Proceedings of the Eighth International Conference on Advances in Pattern Recognition (ICAPR), Kolkata, India, 4–7 January 2015; pp. 1–5. [Google Scholar]
- Liu, P.; Han, S.; Meng, Z.; Tong, Y. Facial expression recognition via a boosted deep belief network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1805–1812. [Google Scholar]
- Khorrami, P.; Paine, T.; Huang, T. Do Deep Neural Networks Learn Facial Action Units When Doing Expression Recognition? In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 19–27. [Google Scholar]
- Tian, Y. Evaluation of face resolution for expression analysis. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshop, Washington, DC, USA, 27 June–2 July 2004; p. 82. [Google Scholar]
- Tzimiropoulos, G.; Pantic, M. Optimization problems for fast aam fitting in-the-wild. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 593–600. [Google Scholar]
- Zhu, X.; Ramanan, D. Face detection, pose estimation, and landmark localization in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2879–2886. [Google Scholar]
- Lee Rodgers, J.; Nicewander, W.A. Thirteen ways to look at the correlation coefficient. Am. Stat. 1988, 42, 59–66. [Google Scholar] [CrossRef]
- Tariq, U.; Lin, K.H.; Li, Z.; Zhou, X.; Wang, Z.; Le, V.; Huang, T.S.; Lv, X.; Han, T.X. Emotion recognition from an ensemble of features. In Proceedings of the IEEE International Conference on Automatic Face & Gesture Recognition and Workshops (FG 2011), Santa Barbara, CA, USA, 21–25 March 2011; pp. 872–877. [Google Scholar]
- Evgeniou, A.; Pontil, M. Multi-task feature learning. Adv. Neural Inf. Process. Syst. 2007, 19, 41. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Harwood, D. Performance evaluation of texture measures with classification based on Kullback discrimination of distributions. In Proceedings of the 12th IAPR International Conference Pattern Recognit. Conference A: Computer Vision & Image Processing, Jerusalem, Israel, 9–13 October 1994; Volume 1, pp. 582–585. [Google Scholar]
- Ojala, T.; Pietikäinen, M.; Harwood, D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- Heikkila, M.; Pietikainen, M. A texture-based method for modeling the background and detecting moving objects. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 657–662. [Google Scholar] [CrossRef] [PubMed]
- Wikipedia. Histogram of Oriented Gradients. Available online: https://en.wikipedia.org/wiki/Histogram_of_oriented_gradients (accessed on 23 January 2017).
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Zhang, W.; Zhang, Y.; Ma, L.; Guan, J.; Gong, S. Multimodal learning for facial expression recognition. Pattern Recognit. 2015, 48, 3191–3202. [Google Scholar] [CrossRef]
- Person, K. On Lines and Planes of Closest Fit to System of Points in Space. Philiosoph. Mag. 1901, 2, 559–572. [Google Scholar] [CrossRef]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417. [Google Scholar] [CrossRef]
- Kanade, T.; Cohn, J.F.; Tian, Y. Comprehensive database for facial expression analysis. In Proceedings of the Fourth IEEE International Conference on Automatic Face and Gesture Recognition, Grenoble, France, 26–30 March 2000; pp. 46–53. [Google Scholar]
- Lyons, M.; Akamatsu, S.; Kamachi, M.; Gyoba, J. Coding facial expressions with gabor wavelets. In Proceedings of the Third IEEE International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 200–205. [Google Scholar]
- Lyons, M.J.; Budynek, J.; Akamatsu, S. Automatic classification of single facial images. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 1357–1362. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Salient Areas | Forehead | Mouth | Left Cheek | Right Cheek |
|---|---|---|---|---|
| Piexls | 20 × 90 | 40 × 60 | 60 × 30 | 60 × 30 |
| Small patches number | 12 | 16 | 12 | 12 |
| LBP dimension | 708 | 944 | 708 | 708 |
| Total | 3068 | |||
| Salient Areas | Forehead | Mouth | Left Cheek | Right Cheek |
|---|---|---|---|---|
| Piexls | 20 × 90 | 40 × 60 | 60 × 30 | 60 × 30 |
| Small patches number | 51 | 77 | 55 | 55 |
| HOG dimension | 1836 | 2772 | 1980 | 1980 |
| Total | 8568 | |||
| Salient Areas Definitude Methods | Zhong 2012 [3] (MTSL) | Liu 2015 [2] (LBP) | Liu 2015 [2] (AUDN-GSL) | Proposed Method (with Gamma) | Proposed Method (without Gamma) |
|---|---|---|---|---|---|
| Classifer | SVM | SVM | SVM | SVM | SVM |
| Recognition rate | 89.9 | 92.67 | 95.78 | 95.5 | 96.6 |
| CK+ | JAFFE | |||
|---|---|---|---|---|
| Gamma-LBP | LBP | Gamma-LBP | LBP | |
| SVM(polynomial) | 96.6 | 95.5 | 62.8 | 62.3 |
| SVM(linear) | 96.6 | 95.6 | 63.4 | 60.8 |
| SVM(RBF) | 96.0 | 87.1 | 62.8 | 61.2 |
| Softmax | 97.0 | 95.6 | 61.7 | 59.6 |
| Methods | Zhong 2012 [3] | Shan 2009 [4] | Proposed Methods |
|---|---|---|---|
| Classifier | SVM | SVM | SVM |
| Validation Setting | 10-Fold | 10-Fold | 10-Fold |
| Performance | 89.9 | 95.1 | 96.6 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Li, Y.; Ma, X.; Song, R. Facial Expression Recognition with Fusion Features Extracted from Salient Facial Areas. Sensors 2017, 17, 712. https://doi.org/10.3390/s17040712
Liu Y, Li Y, Ma X, Song R. Facial Expression Recognition with Fusion Features Extracted from Salient Facial Areas. Sensors. 2017; 17(4):712. https://doi.org/10.3390/s17040712
Chicago/Turabian StyleLiu, Yanpeng, Yibin Li, Xin Ma, and Rui Song. 2017. "Facial Expression Recognition with Fusion Features Extracted from Salient Facial Areas" Sensors 17, no. 4: 712. https://doi.org/10.3390/s17040712
APA StyleLiu, Y., Li, Y., Ma, X., & Song, R. (2017). Facial Expression Recognition with Fusion Features Extracted from Salient Facial Areas. Sensors, 17(4), 712. https://doi.org/10.3390/s17040712