1. Introduction
Indoor localization is one of the most challenging goals for mobile device application development, as evidenced by the growing interest resulting in the birth of different consortia (i.e., i-Locate [
1]) and coarse wireless devices (i.e., Apple iBeacon [
2], NexTOme [
3]) with simple software development kits (SDKs). In [
4], some achievements resulting from the worldwide Microsoft Indoor Localization Competition are outlined. Note that all the proposed systems were developed with certain constraints, including cost-effectiveness, configuration speed and transparency.
Particular attention has been given to infrastructure-free systems [
4]; that are systems used by most widespread Component-Off-The-Shelf (COTS) devices (i.e., smartphones, tablets, etc.), which only implement standard communication protocols and achieve localization services, starting from coarse and protocol estimated parameters (i.e., RSSI, LQI). In fact, localization systems compatible with typical user devices are considered the only answer to the development of friendly, cost-effective and simple localization [
5]. Therefore, improving localization accuracy is achievable by refining localization algorithms.
In terms of IEEE 802.11 and 802.15.4 compliant systems, the direct physical parameters for packet transmission are the time of arrival (ToA) and the received signal strength indicator (RSSI). Time difference of arrival (TDoA) techniques can produce interesting results [
6], and they may be the solution; however, as shown in [
6,
7] the lack of sufficient timing for resolutions at the protocola data level impose the Component-Off-The-Shelf (COTS) transceiver architecture to open up and achieve more accurate time estimations (likely using higher frequency ADCs) at a lower protocol stack layer. If such modifications could be considered, hardware adaptation would require higher frequency ADCs and DACs, comporting all related mixed-signal hardware changes and incrementing costs. With respect to the constraints of implementing COTS transceivers, the system design can take advantage of the RSSI parameter estimation available in all the IEEE 802.11 and 802.15.4 implementations. The direct RSSI evaluation appears to be an unreliable measure [
8] for achieving a sufficient accurate localization in indoor environments. By this, some RSSI-based solutions based on distributed network of routers have been proposed in the past, applying fingerprint-like methods [
4,
9,
10] or trilateration by range estimation [
11,
12]: in all of these solutions coarse errors arise due to the unpredictability of RSSI estimations in complex environments. Localization accuracy is typically improved by obtaining additional information from user devices’ inertial sensors and by applying Kalman filtering [
13,
14,
15], but information fusion requires high computational power and accuracy, both directly influencing the overall localization performance. The best localization accuracy is achieved through fingerprint methods, but a complex off-line calibration phase shall be introduced to make the system operational: such calibration strictly depends on particular environment characteristics (i.e., routers distribution, furnishings distribution, etc.), so it makes the overall localization solution very complex to be installed and managed.
This work aims to propose an IEEE 802.11/802.15.4 network compliant indoor localization system, which is capable of achieving sub-metrical accuracy without any kind of off-line calibration phases. The proposed approach is based on a network of anchor nodes (or rather, typical routers) based on a particular SBA (Switched Beam Antenna) structure [
16,
17] which is capable of SDMA (Space Division Multiplexing Access).
In
Section 2 we demonstrate that such anchor node is able to provide a more predictable radiation pattern distribution across the area, and through SDMA, exploiting more co-operative anchor nodes, the resulting constellation is able to subdivide overall area in small cells thus enabling a coarse metrical space subdivision. In this refined space domain, the proposed localization algorithm estimates effectively the target position. In force of the pattern predictability and space cell subdivision, through a RSSI-based fingerprint-like localization algorithm based on a purely ideal “reference map”, the proposed system is able to achieve the sub-metrical localization accuracy for both static and mobile target nodes. Because proposed localization algorithm is based only on RSSI estimations, no more than a typical 802.11/802.15.4 transceiver is required while RSSI values are obtained in a fully transparent way during standard packet network communication.
2. Proposed Hardware Infrastructure
In [
17,
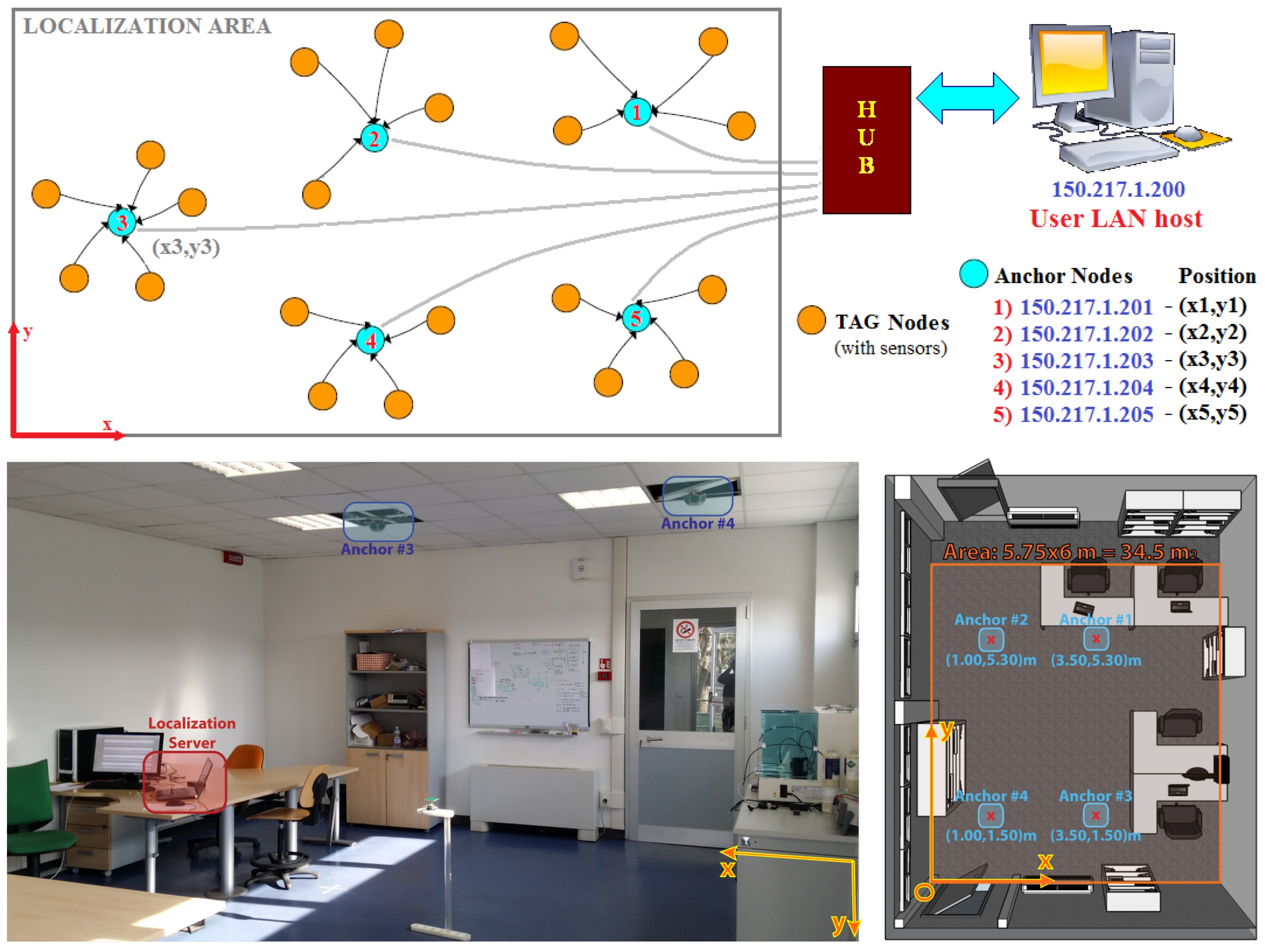
18], COTS-only hardware for transparent indoor localization was proposed for use in a distributed network of IEEE 802.15.4 anchor nodes hanging from the ceiling, which offer Ethernet-to-ZigBee connectivity. Every anchor node is capable of transferring packets between any LAN host and each ZigBee node (
Figure 1), while the LAN host collects all the localization-related data.
A reference table for complete anchor networks is built in the LAN host, containing the position of each anchor node. As shown in [
18,
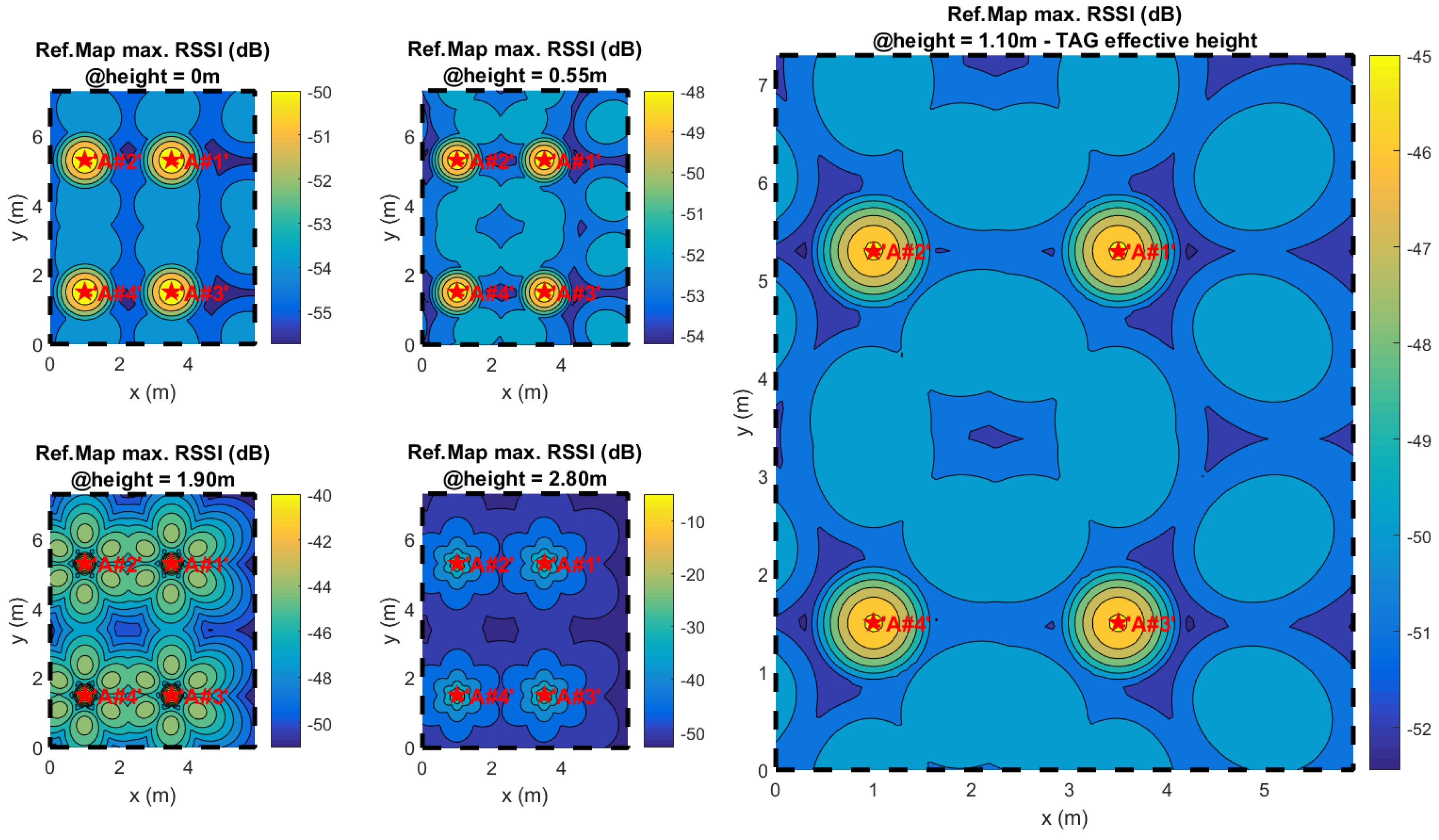
19], an ideal two-dimensional map of the expected RSSI is collected for each antenna and anchor (considering the user node as the transmitter), directly projecting each oriented polar ideal antenna pattern to the plane, with the height being the mean height of the TAG nodes (i.e., a typical height of 1.10 m from the floor is considered).
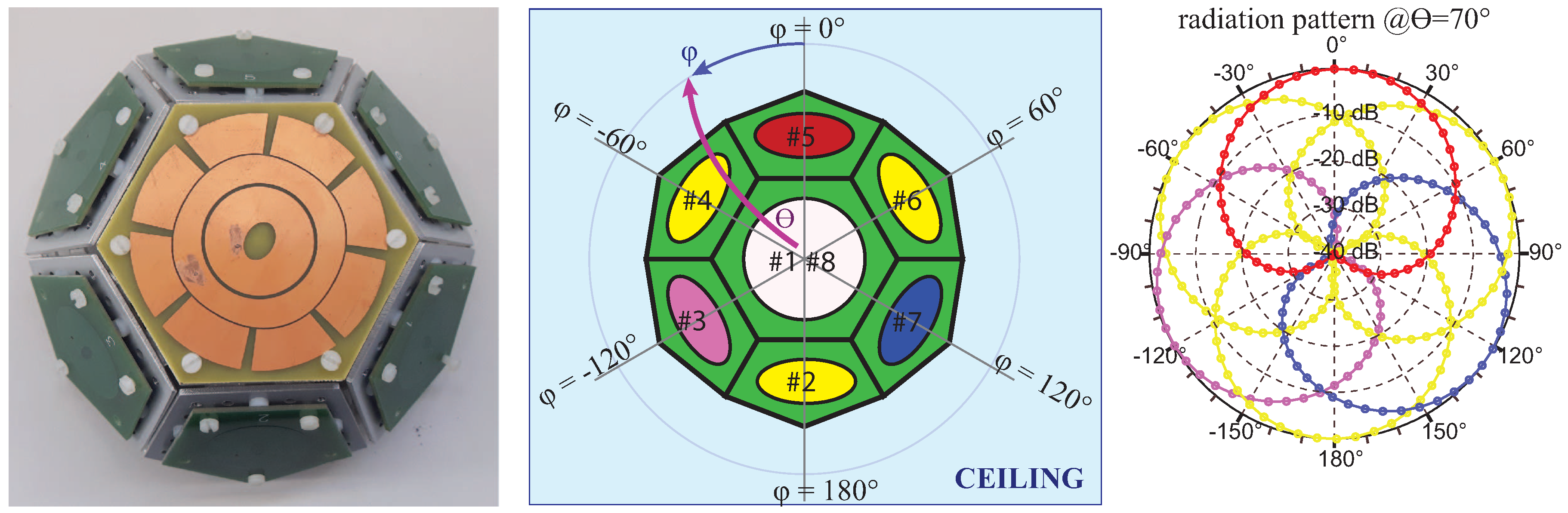
Each anchor node is built on the concept of a switched-beam array [
16,
20,
21]. In
Figure 2, a brief hardware description is shown, including both the antenna array structure and the anchor node block diagram; functionally, the concept is to place a uC-controlled RF switch on a standard ZigBee transceiver (i.e., in [
19], a COTS Texas Instruments CC2430 transceiver was used), which connects the RF channel to every antenna of the array.
The antennas are implemented as printed patch antennas, radiating a characteristic and regular far-field pattern (
Figure 3, [
22,
23,
24]). The antennas operate in circular polarization, permitting a reliable link regardless of the relative orientation of the tag [
19,
25,
26]. Furthermore, circular polarization is a strong aid in contrasting multipath impairment [
27,
28,
29]. A set of patterns is projected over different spatial areas [
19] and for each anchor tag data packet a complete RSSI vector for each antenna, called the steering vector, is given.
2.1. Proposed Localization Method
A steering vector defined through RSSI values contains information only about packet received signal power, thus phase information is totally unavailable. Despite this an accurate design of the array structure (
Figure 2, [
16,
30]) can provide an excellent pattern differentiation throughout each single anchor domain, thus lowering the expected Cramer-Rao Bound lower limit for localization accuracy [
31] and enabling the single anchor node to perform Direction-of-Arrival estimation. In [
32] a specific implementation of the DoA MuSiC algorithm [
33] has been proposed for phase-less RSSI steering vectors. Such an algorithm was successfully implemented in the 802.15.4 COTS based SBA designed in [
16] and proposed in
Figure 3, showing that a completely phaseless and RSSI-only based architecture can perform DoA localization [
17].
Different anchors DoA estimations could be used to perform a three dimensional localization overall a site, but RSSI DoA estimation is far from being accurate enough to achieve a limited dilution of precision for localization in large areas. To improve overall accuracy some enhanced triangulation algorithms exist [
34], but the actual problem is that each different DoA estimation is affected by an angle estimation error while such estimations are applied as arguments of strictly non-linear trigonometrical function to perform final
estimation [
35].
Dealing with a network of N distributed anchors, making the final localization using N different and independent DoA estimation without considering any kind of relationship between them does not exploit the entire information available. A stronger control over estimation error propagation can be achieved by applying an estimation algorithm over the entire set of RSSI data given by the entire set of installed anchors: the effective increase of information quantity available to the final localization algorithm allows to complete reciprocal anchor observations thus reducing overall estimation error.
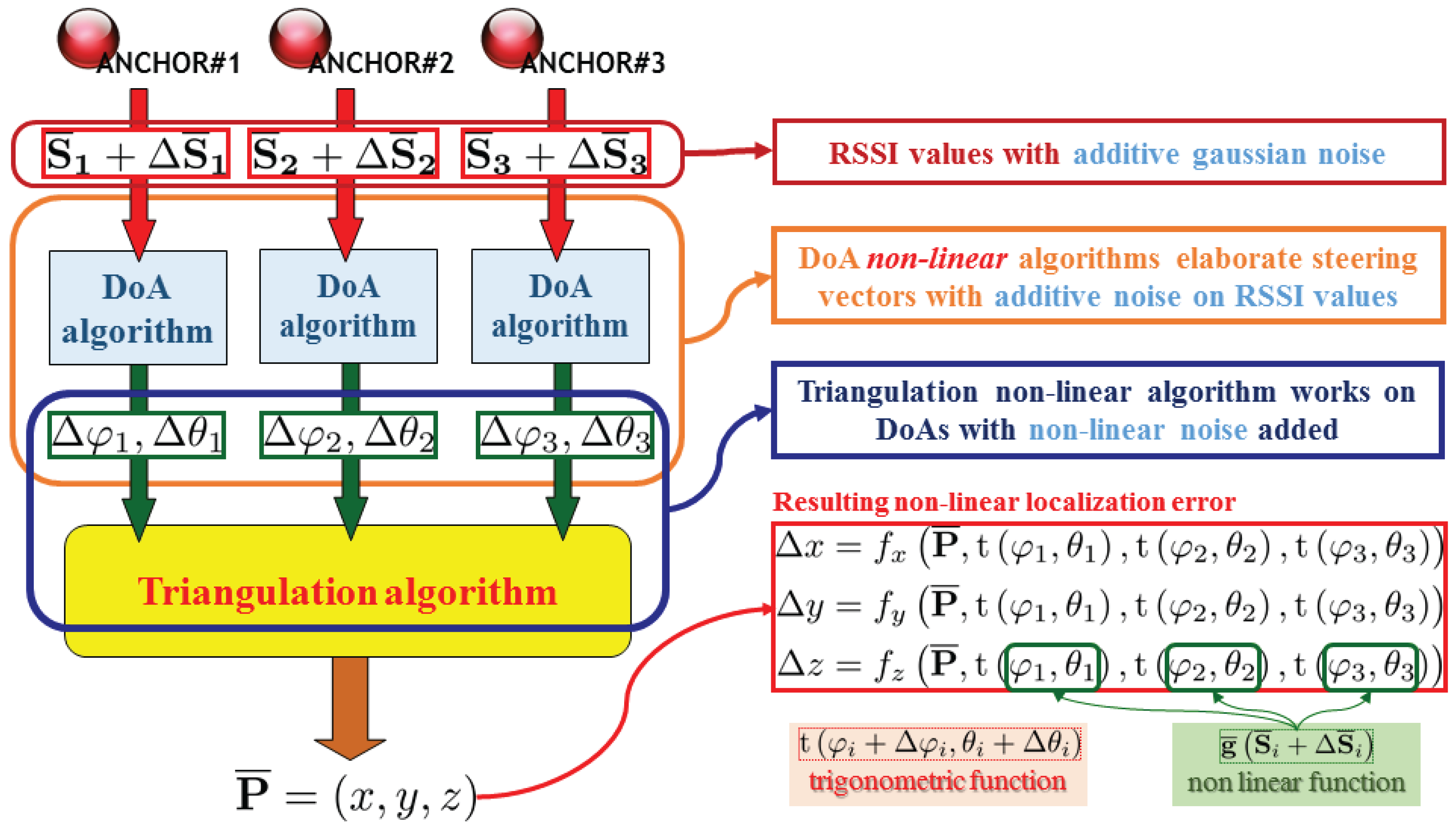
The error propagation scheme is conceptually depicted in
Figure 4 and
Figure 5. Note that while the typical triangulation approach in fact gets the different DoA estimations from each anchor node without performing any kind of reciprocity check, dealing with overall RSSI information (thus processing a “global steering vector” given by the entire network of anchors) a single conceptual block can access to the entire information batch allowing to implement smarter localization algorithms.
Note that the error propagation model of
Figure 4 is still valid for trilateration approaches [
36], as the Friis formula inversion is required to estimate the distance between the anchor and each node. In this case, the RSSI measurements error can have an even bigger impact.
Figure 4 reveals how the main source of weakness is caused by a pair of non-linear transformations applied over the collected steering vector, which is affected by RSSI measurement errors modelled as a Gaussian noise distribution [
32]. Note that the non-linear function of the localization error depends on non-linear functions
applied as trigonometric function
arguments.
To achieve an higher control over error propagation, a one-step localization algorithm is highly preferable. In
Figure 5, note that the localization error function becomes directly dependent on RSSI measurement errors, thus final localization error can be better controlled by refining the direct localization estimator function. In one-step localization, error propagation does not depend on trigonometrical functions, and the overall information comes from a distribute set of directive antennas (grouped by anchor nodes), building a more descriptive and fully exploitable data set.
The proposed approach analyses the RSSI values collected from the overall anchor-node antennas. Dealing with an highly spread antenna distribution, an extensive information about environment is given reducing the needing of information fusion with additional sensor data; the needing of an off-line calibration phase is removed thanks to predictability increase overall the observation area. Additional information given by a “global steering vector” can be exploited through different processing blocks (accurately described in
Section 3) lying within the “One-Step” localization algorithm (
Figure 5) which are able to feed each other to refine final estimation results.
In summary, the hardware architecture shown in [
17,
19] was used, the algorithmic layer is deeply different from a simple implementation of the DoA RSSI algorithm on every anchor, obtaining the final spatial localization through the simple triangulation algorithm, as shown in [
35]. In [
19], each M-dimensional steering vector collected for each of the N = 4 anchor nodes (each composed by M = 7 antenna elements) was used to compose a single MxN-dimensional global steering vector, which became the input of the direct localization algorithm placed on the server (
Figure 1).
3. One-Step Localization Algorithm
In
Section 2.1 the localization method has been introduced. As it is depicted in
Figure 5 the core of actual localization approach relies within the “One-Step algorithm” block: This paragraph will describe block implementation in depth, thus evaluating algorithm improvements respect RSSI measure noise.
In the “one-step” approach the effective steering vector is the vector containing every RSSI collected from each antenna of every anchor node, and it becomes a global steering vector. Global steering vectors correspond to a long concatenation of all the different steering vectors collected from each anchor node placed in a known order (e.g., lexicographical order based on the name associated with each anchor). For each packet transfer, the host gets a global steering vector, as shown in Equation (
1).
Next to the steering vector is a reference map of the whole set of expected global steering vectors for each different position in the localization space (Equation (
2)).
A generic Maximum-Likelihood fingerprinting algorithm is based on finding the solution to the problem in Equation (
3) [
19,
31,
37]. The
function is called the pseudospectrum function or the estimator and is defined as a
function in the localization domain.
Maximum likelihood (ML) algorithms differ depending on the estimator. Among the ML estimators, a reduced computational cost subclass can be defined; the generic form is shown in Equation (
4).
This paper will cover only reduced computational cost estimators to follow the imposed real-time constraint. In
Section 5, the localization results will be compared between the proposed estimators and the State-of-Art, computationally complex MUSIC estimator [
32,
33]. The least squares estimator is the simplest ML estimator and is the one referred to in [
19].
Following a classic fingerprinting approach [
10,
38], in [
19], the concept of predicted fingerprinting is introduced to achieve an acceptable localization accuracy in the site shown in
Figure 1. In the predicted fingerprinting reference map, which is compounded by steering vectors collected at each position in classic fingerprinting approaches, the software projects every antenna pattern of each anchor onto the observation floor space. This step was the novelty of [
19], as, at the time, there was no need for an extensive offline calibration phase prior to a system’s effective utilization by replacing it with an a posteriori tuning/optimization of antenna projection map parameters [
38] respect a small set of training observations.
Note that, as shown in [
19], antenna projections are built considering a reference height of 1.10 m, the typical height for mobile phone use when the user is standing.
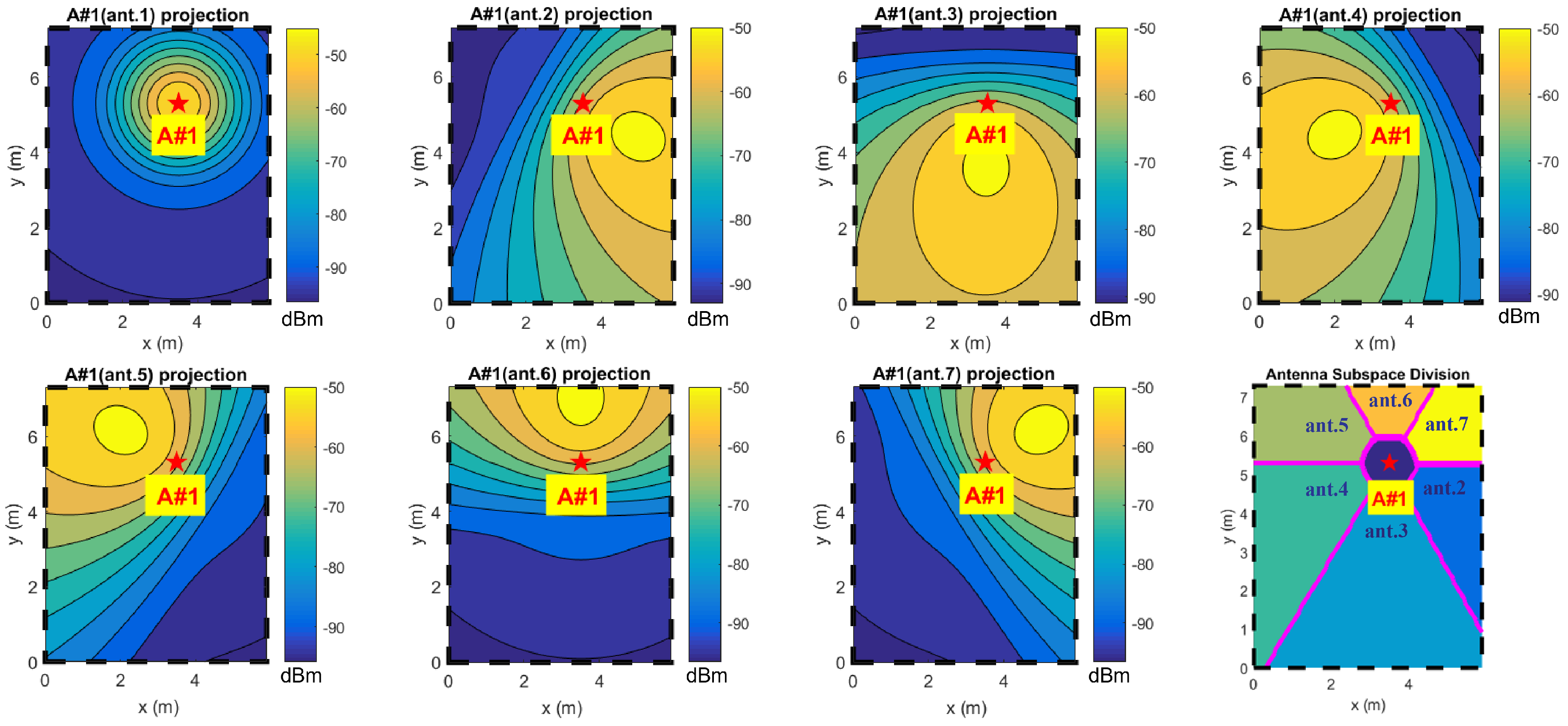
3.1. Area Preselection
The reliability of the estimator values is directly related to the reliability of reference map
and the function trends can be dramatically altered by RSSI measurement noise; arguments bias can effectively produce some wrong relative minimums, which can become new absolute minimums that alter the final localization estimation. One way of keeping this source of estimation bias under control is exploiting the capability of each anchor to make a coarse spatial subdivision for the area of competence [
19,
39] (
Figure 6).
In the subdivided localization spaces of multiple anchors in smaller sub-zones (or cells), each anchor is uniquely linked to a list of corresponding maximal antennas for each anchor plus the absolute maximal antenna (
Figure 7). Therefore, every steering vector directly links to a subselection of localization domain (or rather a sub-cell), reducing the computational cost and the maximal localization error.
Defining a preselection steering vector with related preselection steering vectors reference map as in Equation (
6), the preselection algorithm is shown in Equation (
7).
The preselection algorithm removes each point from the reference map which does not belong in the subselection condition represented by the masking function : .
The subdomain reference map equals
with the cell identifier distance function
defined in Equation (
8).
The preselection algorithm relies on unrelated sub-domain removal (i.e., unrelated to selected cells), which shows cell identifiers too different or “far” from the one extracted from the measured data.
Rough area preselection can lead to localization mistakes due to the preselection uncertainty for areas laying near cell boundaries. The feature is associated with an index called the maximum antenna distance (
), which permits the choice of the strictness of cell selection. For an example, looking at
Figure 7b, if the node position belongs near the red-coloured border, a cell selection mistake could lead to increased localization errors. An effective workaround is to incorporate the cells that belong on adjacent antennas in the domain selection. Imposing a higher
causes a reduction in domain selection selectivity, so a complete localization routine could allow for an adaptive algorithm to increment the
only when needed.
3.2. Adaptive Masking
If the localization problem is stated as in Equation (
3), the main condition for the estimator function is to be convex inside the current localization domain. By this, the presence of a possible correct estimation is identified only if an absolute minimum is present in the observed domain.
The absolute minimum is defined for a
function as the point
corresponding to the minimum value, in which the gradient and the Hessian matrix are defined in the neighborhood and the conditions in Equation (
9) is verified.
The approximate solution of the statement in Equation (
3) is given computationally by looking for the indeces matching the minimum value of the numerically computed pseudospectrum function; therefore, the direct check of the conditions in Equation (
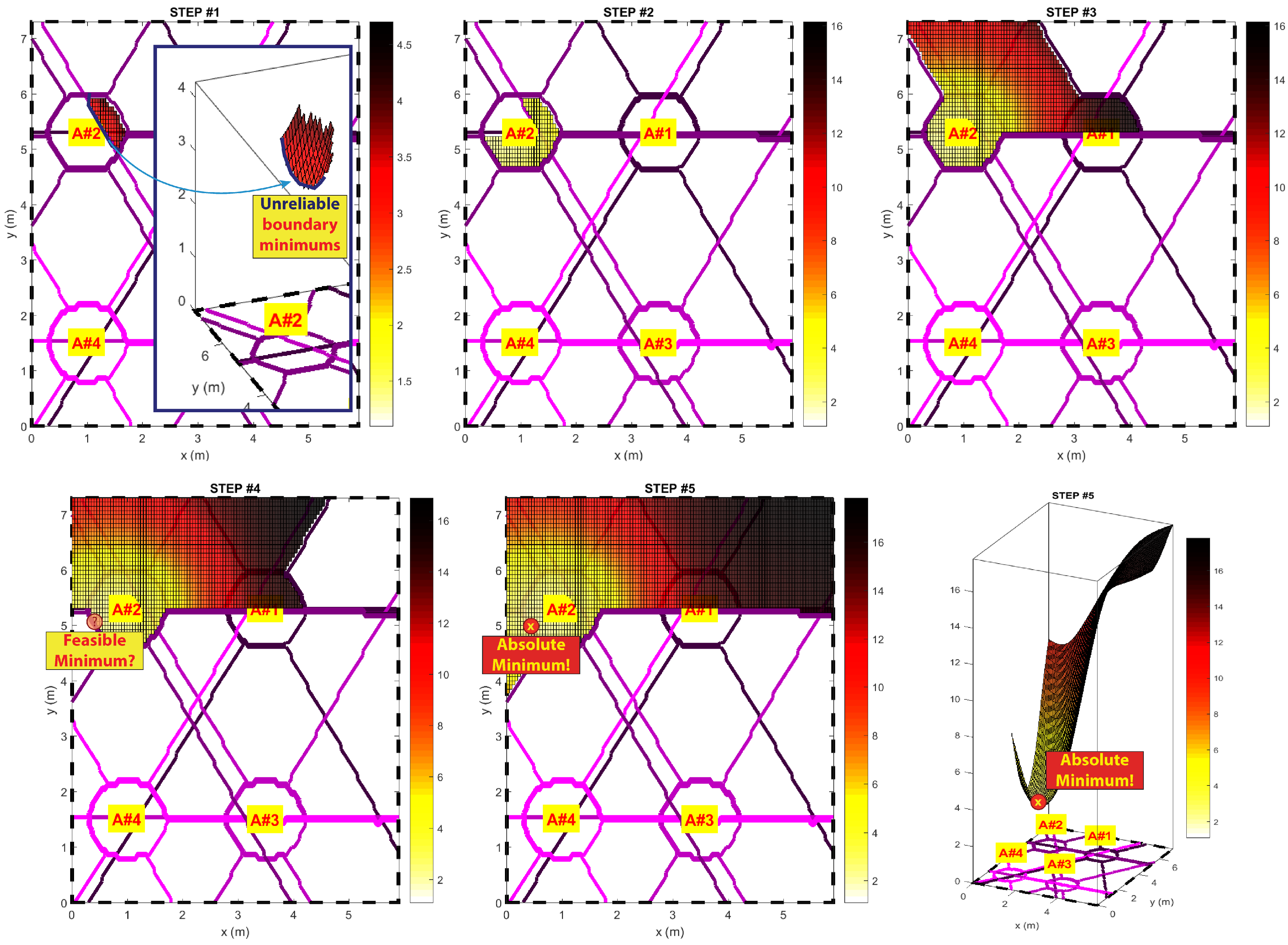
9) is unnecessary. Nevertheless, if the selected subdomain ends before the pseudospectrum value reaches its absolute minimum, the preselection feature can lead to serious estimation errors (
Figure 8).
Making the subdomain selection algorithm adaptive and dependent on each observation could be a valid workaround. Since an a priori knowledge about the maximum position does not exist, an one-step definition of the subdomain mask is unreliable. The idea is to apply an iterative algorithm that verifies whether the minimum relies on an area that is safe and far enough from any subdomain edge for each execution. If not, the subdomain boundary will be extended to enlarge the selection area, increasing the
parameter shown in Equation (
7) and reapplying the mask. An example pseudocode implementation is shown below.
Figure 8 shows the progressive building of the pseudospectrum using the adaptive masking algorithm.
In Algorithm 1, the argmin operator is numerically computed, so Equation (
9) computation is unnecessary. Thus, the “CheckReliabilityMin” function must only check that the computed minimum does not belong to the masked domain edges. If the condition is true, Equation (
9) will be implicitly verified thanks to the pseudospectrum continuity of the domain (Equation (
5)) [
19].
| Algorithm 1 Localization Algorithm with Adaptive Masking. |
- 1:
function Locate–2D - 2:
- 3:
GetFusedSVector() ▹ get data from the network (Equation ( 1)) - 4:
GenerateCellIdentifier( ) ▹ generate the preselection vector (Equation ( 6)) - 5:
GetReferenceMap() ▹ get the steering vector reference map (Equation ( 2)) - 6:
GetCellsMap() ▹ get the preselection vector reference map (Equation ( 6)) - 7:
- 8:
while do - 9:
GetCellDomain( ) ▹ apply the map masking (Equation ( 7)) - 10:
C ← Calculatepseudospectrum( ) ▹ compute the function (Equation ( 5)) - 11:
▹ = indeces of the minimum (Equation ( 3)) - 12:
CheckReliabilityMin(C, ) ▹ verify Equation ( 9) domain conditions (Algorithm 2) - 13:
if then - 14:
▹ increase the max. acceptable cell ID distance (Equation ( 8)) - 15:
end if - 16:
end while - 17:
- 18:
▹ extract the from the indexed domain - 19:
return - 20:
end function
|
To minimize the computational cost, it is best to ignore all the pseudospectrum points that belong outside of the masked domain. This marks all the points where the masking function is null (W
= 0 - Equation (
7)) as NaNs (i.e., MATLAB’s Not-a-Number marker). Marking the value of a matrix as a NaN makes it a non-existent value, so any further processing propagates the non-existence condition.
An implementation for the “CheckReliabilityMin” function is shown in Algorithm 2. The simplest way to check a condition in a point neighborhood is to write a nested cycle where, for each column of the matrix, all the rows are checked, so the neighbor zone will be square shaped.
| Algorithm 2 CheckReliabilityMin Function. |
- 1:
function CheckReliabilityMin(C,) - 2:
let - 3:
- 4:
for to do - 5:
for to do - 6:
if C=NaN then ▹ point near the domain boundary - 7:
return 0 ▹ pseudospectrum is not defined overall in the neighborhood - 8:
end if ▹ high risk of minimum identification mistakes - 9:
end for - 10:
end for - 11:
- 12:
return 1 ▹ point far enough from the domain boundary - 13:
end function
|
A square domain neighbour does not respect the mathematical definition of the neighbourhood of a point (defined as a circular area), but a workaround is to check the condition over an area that contains a typical neighborhood.
The radius of the point’s neighbour is defined through a proportionality constant number of points over the localization domain’s minor dimension (conventionally ); the process for checking for an effective domain is shown below.
An effective neighborhood domain is rectangular when the reference map is built and uses different sizes for each spatial dimension. Nevertheless, by Equation (
10), it is clear that an
neighbour with an area greater than the standard is always verified (Equation (
11)).
3.3. Antenna Weighting
RSSI measurements are non-direct physical estimations of a signal state. An RSSI value is obtained after signal decoding through different correlation processes [
40,
41].
The decoding process achieves data transfer error rate reduction by introducing a high process gain. RSSI measurements can observe high biases for lower signal powers, for which a smart decoding process can achieve a better RSSI in respect to the effectiveness of the signal power. For such cases, in particularly unlucky points, reference map projections can produce RSSI values much lower than the obtained ones.
The bias caused by demodulation process gain is expected to grow in the presence of low signal powers, so an external correction gain can be applied in estimator computing to try to remove this effect and reduce the weight of a weak antenna inside the overall estimator computation. For reduced computational cost algorithms (Equation (
4)), the function
can be modified as follows:
A direct RSSI antenna value can be used to estimate the RSSI estimation reliability, so antenna weighting is applied by placing the weights as shown in Equation (
12).
3.4. Minimum Variance (minVAR) Estimator
In the localization problem stated in Equation (
3), the effective kernel of the localization algorithm is the estimator or pseudospectrum function. An ideal estimator should give a singular minimum point (i.e., an absolute minimum) for the overall localization domain, and it must coincide with the right node position. If ideal hardware is used and localization is required in a perfect environment, in which radio propagation acts perfectly and as modelled in the reference map (Equation (
2)), a basic estimator function can be used (Equation (
5) [
19]).
In [
18,
19], the maximum accuracy limit is stated performing an analytical Cramer–Rao-bound (CRB) computation [
37], as presented in [
16], but CRB analysis places only an ideal accuracy limit given by the geometrical distributions of antenna gains over the space. CRB analysis evaluates the minimum achievable error for the localization space, supposing that the only source of idealization is the RSSI AWGN added to the obtained steering vector (modelled by the equivalent
noise parameter as in [
19]).
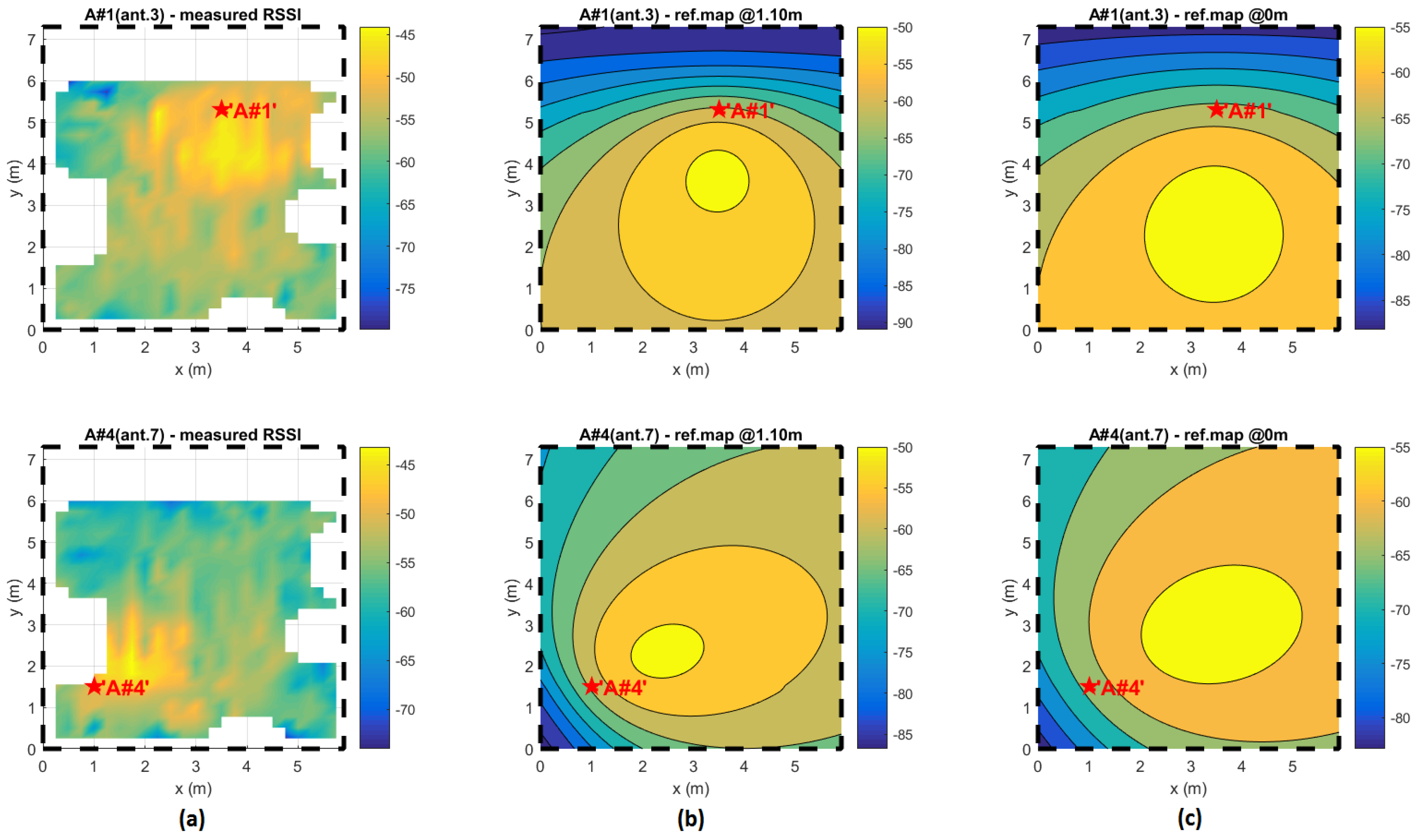
Rather than the measure AWGN, the main source of estimator bias in real applications is the effective inconsistency between the reference map and the effective RSSI distribution over the space. As an example, in
Figure 9, the measured RSSI distributions of two different antennas in the experiment site of
Figure 1 is shown; next to them, the expected ideal distributions are plotted for two different expected elevations (
= 1.1 m and
= 0 m).
Figure 9 clearly shows how much the RSSI distributions differ from the expected projections. In real environments, producing a reliable reference map as proposed in [
19,
42] is unthinkable without a scenery-related calibration session, as occurs in the fingerprinting approach. Dealing with this, reducing the reference map misalignment effects on localization estimation (causing estimator bias) is required and a new estimator function (respecting Equation (
4) definition) is proposed.
In Equation (
13), the minVAR estimator is shown; it evaluates the variance associated with the difference vector built from the measured steering vector and the reference map vector (while the standard least squares estimator calculates its norm using Equation (
5)). Assuming a perfect reference map is created, both LSE and minVAR functions act as two unbiased estimators; thus, the CRB of the localization network results, which show the expected accuracy related to typical AWG-noised measures, are the same, as shown in [
19].
3.5. Fading and Multipath Immunity
A straight evaluation of RSSI parameter intended as an estimation of physical RF received power by the anchor node leads to huge localization estimation errors due to effective RF received power fluctuations due to fading and multipath effects. Dealing with standard and crowded environments such behavior could make the proposed system unusable, but RSSI defined as in IEEE 802.11/802.15.4 network protocols is strictly related to effective data packet information and it is uniquely linked to each different data frame. Data packets are coded through Direct Sequence Spread Spectrum techniques, thus effective data retrieval shows improved immunity towards fading and multipath (representable as delayed receiving signal replies) [
43,
44,
45,
46].
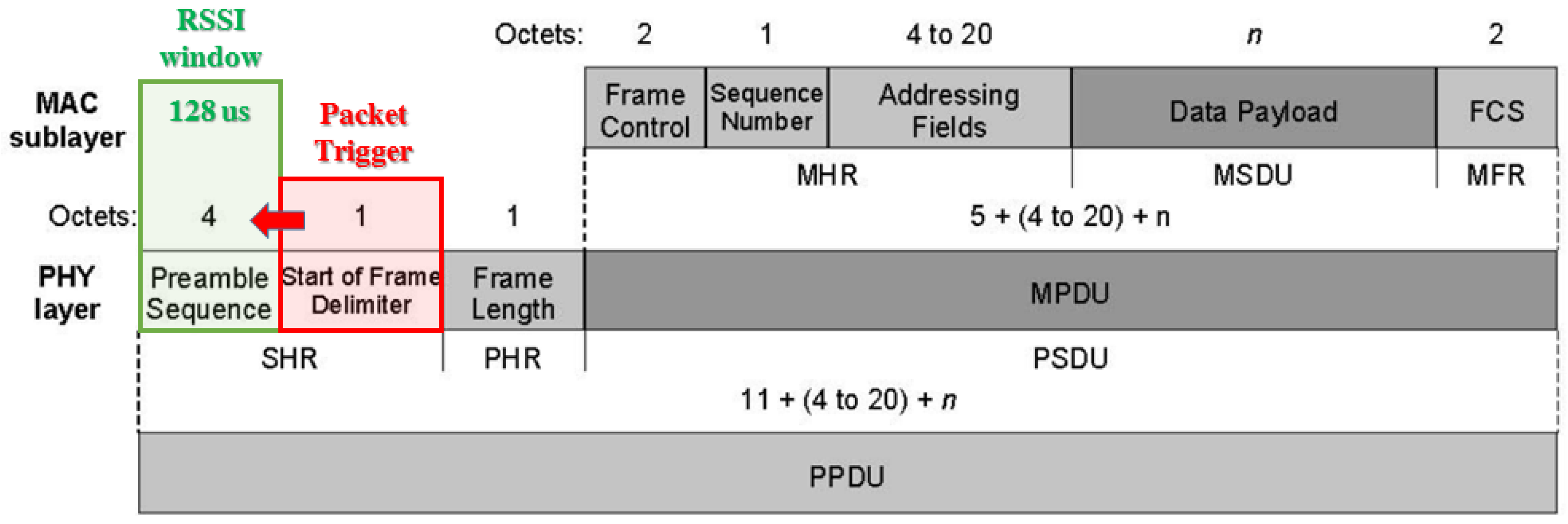
As depicted in
Figure 10 RSSI estimation is averaged overall the preamble sequence window only after recognizing the packet “Start of Frame Delimiter” through spread spectrum decoding, while spread spectrum correlation techniques ensure that only the first coming packet will be evaluated thus ignoring any delayed echo reply. Furthermore averaging RSSI over the entire preamble sequence window allows to reduce highly variable fading effects on RSSI estimations, while highly destructive effects lead to a packet loss which prevents from obtaining wrong RSSI values that can lead to wrong localization estimations.
For slow fading issues which belong to a constant and directive interference the antenna multiplicity helps to mitigate such phenomena: Two different cases can happen
omni-directional interference (or rather “diffuse scattering”): any steering vector RSSI value is uniformly altered so the steering vector mean value is altered, linearly multiplying the vector for a constant coefficient, but overall linear vector direction remains the same;
highly directional interference: some vector terms are dramatically altered, but the overall linear values steering vector direction is maintained (only few vector terms ratio are changed).
As highlighted in
Section 3 and further in
Section 4 and in [
17,
19,
32] the
steering vector maintains its DoA/positioning information into differences between single RSSI terms (or ratios between linear terms), or rather, into the effective steering vector direction in
vectorial space.
Having as reference map the ensemble of physically acceptable steering vectors for a given array structure, a good ML algorithm implementation will be able to identify the most similar reliable map vector rejecting/ignoring the extra domain vectorial components.
ML algorithms based on vectorial subspaces decomposition [
32,
33] evaluates direction match between obtained steering vector and reference vector ignoring at all any constant-term fluctuation while rejecting singular term ratio mismatches. Note that for reduced computational cost subclass algorithms (Equation (
4)) such capability depends directly on estimator function.
By this
Section 4 will describe how minVAR estimator respect LSE is more able to ignore costant-term mismatches while singular term mismatch effects are minimized increasing the number of distributed antennas, as it will be shown by estimator bias coefficients ratios in (Equations (
33)–(
35)).
4. Estimator Function Improvements Assessment
The effective core of “One-Step” algorithm block relies over the new minVAR estimator function, introduced in
Section 3.4. Having to process long vectors of RSSI values that describe a set of distributed antenna gains, Maximum-Likelihood algorithms based on vectorial subspace decomposition (like MuSiC [
32,
33] or Esprit [
47]) become unfeasible due to increase of problem complexity order and for the lack of orthogonality conditions between steering vectors collected from different
points. Consequently, the effective estimator function improvements should be evaluated respect to LSE standard estimator implementation, as proposed in Equation (
5) [
31,
35,
38], which is at the best of the author knowledge the only suitable estimator.
To achieve estimator bias immunity, a propagation error model for reference map errors in terms of both LSE and minVAR follows.
Considering the reference map bias, the localization problem statement (Equation (
3)) is as shown in Equation (
14). The equation defines the reference map bias vector object as the RSSI value difference between the ideal projected gain maps and the physically obtained ones (Equation (
15)).
Following Equation (
3), in localization estimation, a formally faultless evaluation of the estimator bias should be made to evaluate how much the reference map bias vector argument can alter the conditions in Equation (
9) and shift the position of the minimum pseudospectrum point. Despite this, it must be considered that any consideration about the unknown physical gain map projection trends is totally unfeasible; therefore, its derivatives are undefinable.
The analysis can be simplified with a comparative evaluation of the effects of the bias vector directly to the function image between the different estimators. Without evaluating the trend, if an estimator shows a reduced variability in respect to the subfunctions, it will be more robust against ideal physical reference map differences. Therefore, a qualitative comparison can be made between the estimator function differences and the terms.
The estimator function is directly definable in the
reference map vectorial space. By this, the estimator gradient can be defined as in Equation (
16).
Thus, by defining the gradient vector, each point of the estimator function can be written as in Equation (
17), which separates the influence of the reference map bias vector.
By Equation (
17), a brief evaluation of the estimator bias is given by the estimator bias gain (Equation (
18)), which is a conceptually approximate map bias to estimator bias gain.
As estimator bias gain calculated in a localization point points out how much the specific estimator is susceptible of variation on that point due to map biases, comparison between different estimators bias gains over the overall localization area could identify the more reliable estimator.
However, both LSE (Equation (
5)) and minVAR (Equation (
13)) estimators are strictly non-linear in terms of their vectorial arguments, so it is necessary to verify whether a first-grade approximation (Equation (
17)) is reliable enough.
It has already been said in
Section 3.1 that map bias can introduce new relative minimums in different
points, and this can happen in map vector domains, as well. Assuming that the map bias is restrained enough to alter the estimator function trend only in the neighborhood of the effective estimation point
, a corollary condition should be that the
term will not be able to alter the estimator function convexity so that the relative minimum condition (Equation (
9)) will still be verified.
Convexity behaviour must be verified using the Hessian matrix (as seen in Equation (
9)), but the method is absolutely unfeasible when handling a high dimensional
function. An alternative way to impose convexity is to evaluate the influence of superior grade terms. It is clear that all non-linear map bias dependency is defined by the residual term in Equation (
19).
By quantifying non-linear estimators, it becomes possible to foresee the reliability of the estimator bias prediction using the estimator bias gain in Equation (
18). To evaluate the most reliable estimator between A and B, both conditions in Equation (
20) must be verified; the first one verifies which estimator could be the more stable, while the second condition verifies how much the first condition is reliable.
Note that each condition must be verified in
, while the estimator equations directly depend on the collected steering vector
and the reference map vector
(Equation (
3)). Following the reduced computational cost estimator class definition (Equation (
4)), the correct and biased localization estimation is defined below.
The estimated localization should be equal to the real position.
Using Equations (
21) and (
22), each function can be evaluated in the
point by writing its dependency from the map bias terms directly, as shown in Equation (
23).
4.1. Algorithms Based on Vectorial Subspace Decomposition
Estimators based on vectorial subspace projections (e.g., MUSIC [
32,
33], Esprit [
47]) can give very high map bias and noise rejection relying on the property of orthogonality between the error vectors and the expected vectorial subspaces. The bias factor for vectorial subspace algorithms is ideally zero because any
vector has a null projection over the map vector subspace [
32].
Unfortunately, applying vectorial subspace decomposition algorithms on a one-step algorithm is unfeasible due to the high grade complexity of the computation. A fundamental constraint for indoor localization is real-time tracking, but high global steering vector dimensionality (Equation (
1)) prevents singular value decomposition and reference map vector projection [
32,
47] over subspaces within reasonable timeframes. The localization results of RSSI MUSIC implementation (presented in [
32]) will be reported to show the mean execution time and speed ratio of each estimator.
4.2. LSE Estimator Bias
Applying the condition in Equation (
21) to calculate the LSE estimator gradients results in the following equation:
Following Equation (
23), the estimator bias factors for the LSE estimator are given below.
4.3. minVAR Estimator Bias
By Equation (
13), the minVAR estimator is written as follows:
Each term of the minVAR estimator gradient is shown below:
Expanding on Equation (
27) results in the following equation:
Following Equation (
23), the estimator bias factors for the minVAR estimator are written as follows:
4.4. Estimator Bias Immunity Comparison
In Equation (
30), a generic bias model is described. The map bias is given as a Gaussian noise vector distributed over
steering vector terms; an eventual
term is embedded into the mean value of the Gaussian noise, because it results to be common to every steering vector component.
Applying Equation (
25), the LSE bias factor can be calculated as follows:
Applying Equation (
29), the minVAR bias factor can be calculated as follows:
To evaluate the minVAR improvement over the LSE, the following Equation (
20) ratio conditions are
Final conditions in Equation (
35) summarize all reliability comparison between minVAR and LSE estimators. When those conditions are verified, minVAR estimator reliability over LSE is proven.
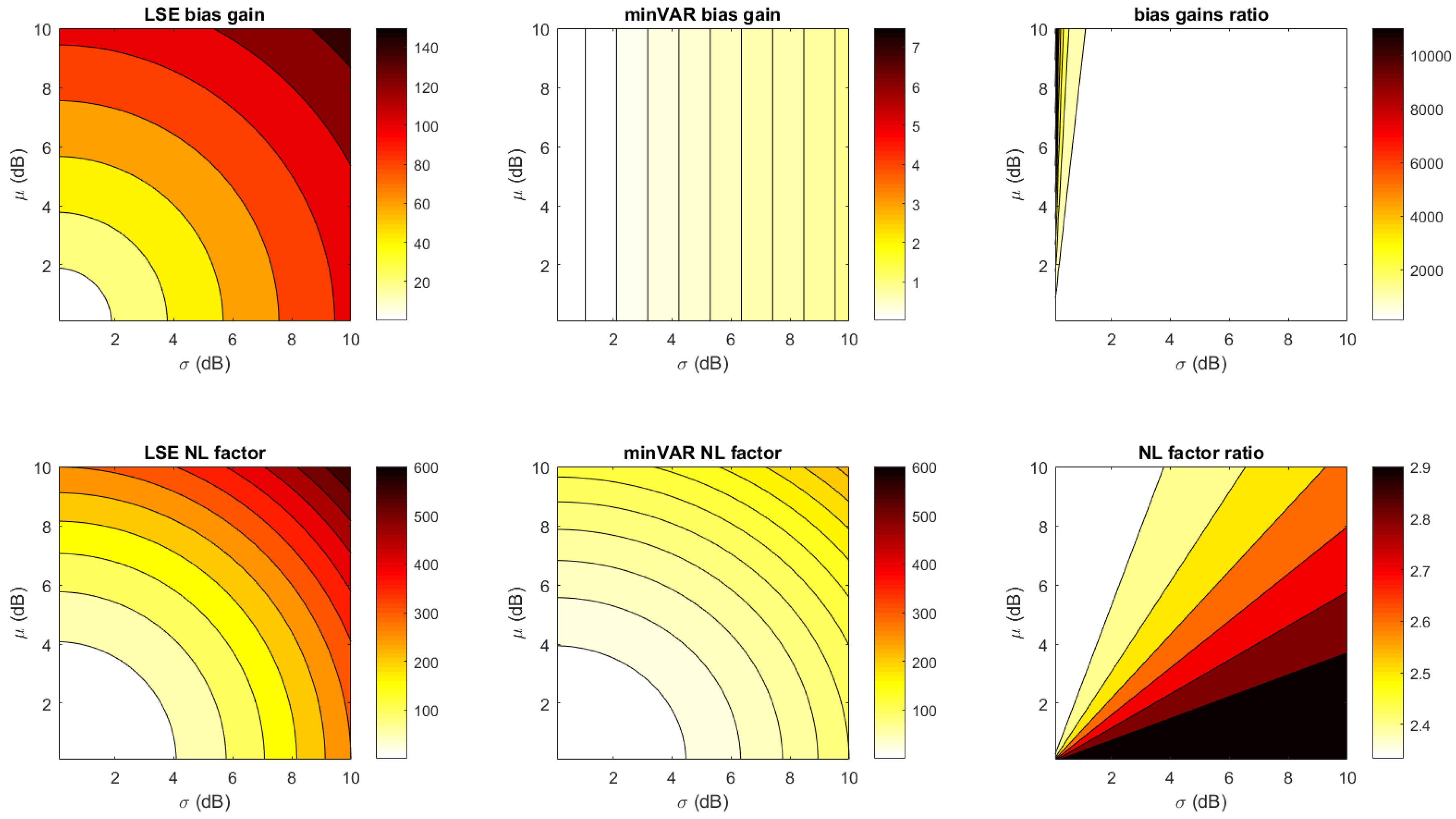
In
Figure 11, the estimator bias gain factors and estimator factor ratios are shown for the actual experiment configuration (
Figure 1 with 4 anchors, each with 7 antennas) with respect to different
parameters in the Gaussian map bias model. The estimator factor ratios are always much greater than one, making the minVAR estimator more reliable than the LSE.
By Equation (
35), a further noticeable improvement is highlighted: The minVAR estimator is fully independent or unbiased with respect to the user node’s transmitted power term
or rather from each
steady term (as it can be a
due to path loss). In particular, if the reference map deviation belongs only to the constant term, then
. The improvement is not trivial; every fingerprinting method is dependant on the overall received power value. This dependency causes localization estimation bias for transmitted and received power fluctuations, even though a complete and error-free measured data set is available [
19,
42].
Note that for minVAR estimator bias gain decreases by increasing the overall number of antennas (Equation (
33)) while the estimator non-linearity factor does not change at all (Equation (
34)). Therefore, it is proven that minVAR estimator will always enhance its reliability by increasing the number of antennas over the localization space as stated by CRB-analysis [
19,
37]; LSE estimator instead shows the reverse trend, worsening its bias if each antenna adds its RSSI measurement noise to the steering vector.
Two main cases for map bias distribution can be evaluated: the first considers an highly stable map bias
(e.g., for high
terms due to path loss), and the second considers an highly variable map bias (e.g., due to coarse unexpected map model errors).
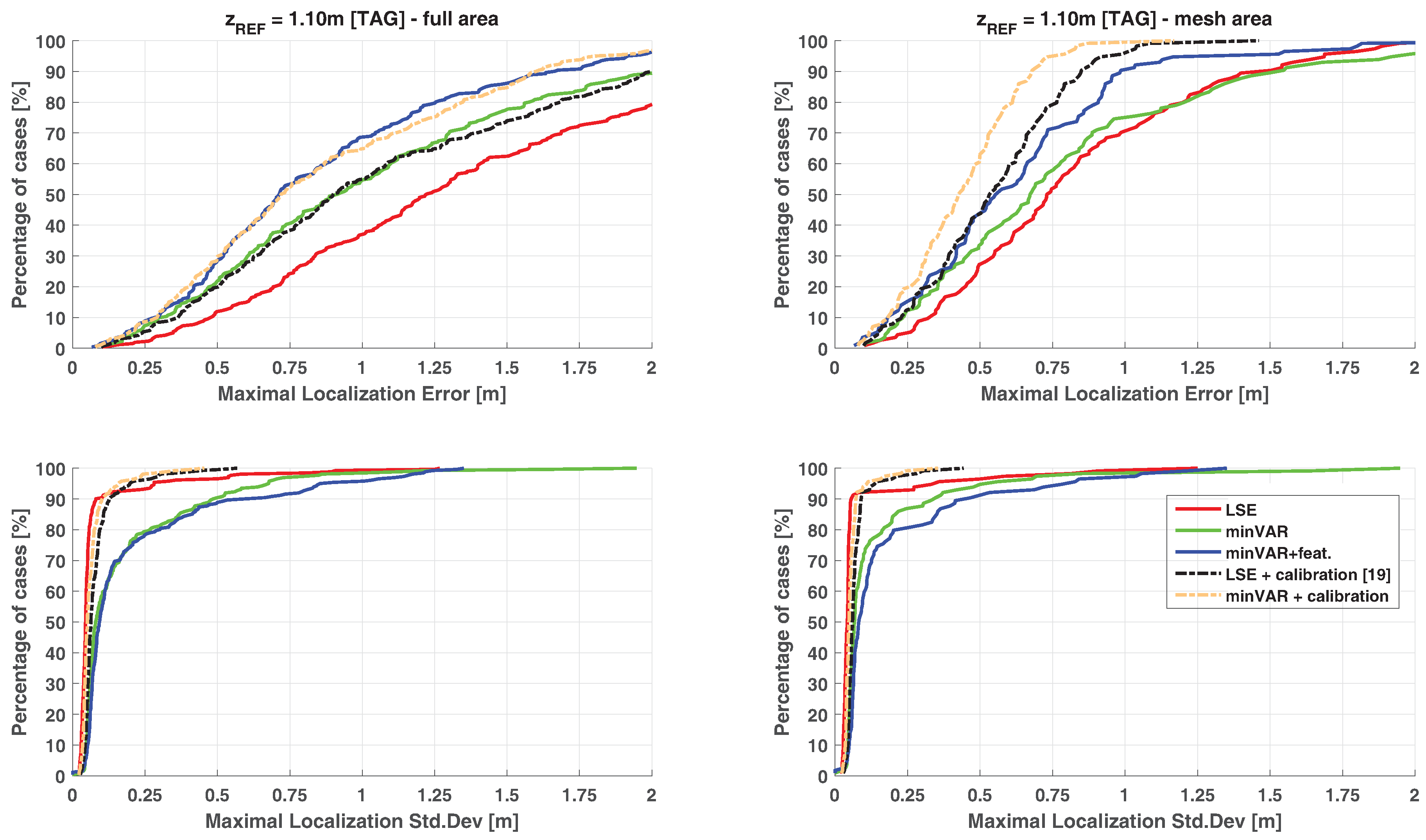
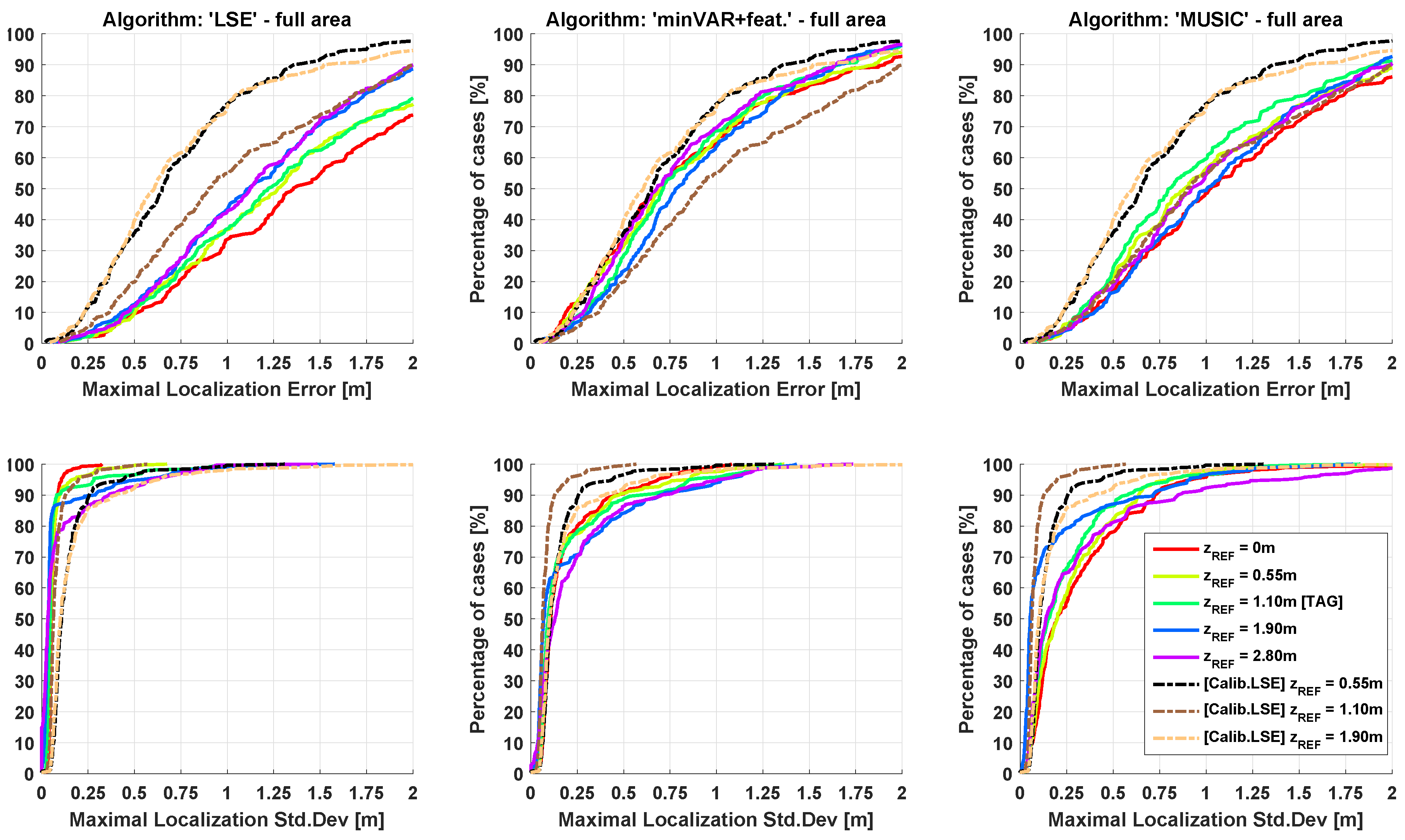
4.5. Simulated Localization Estimation Results and Comparison
To make an effective comparison, in
Figure 12 and
Figure 13, the simulated localization error results for the referenced scenery (
Figure 1) are shown, computing a set of 10 localizations in each
point. For each localization the steering vectors was the corresponding reference map vector
biased with an AWGN map bias defined as in (Equation (
30)).
It is remarkable that the plots in
Figure 12 follow the predicted trends shown in
Figure 11, further highlighting the validity of proposed model. For comparison,
Figure 12 and
Table 1 show the localization error results of the State-of-Art MUSIC localization algorithm, as shown in [
32]. For a 21× slow down in the localization execution time, better localization estimations were achieved.
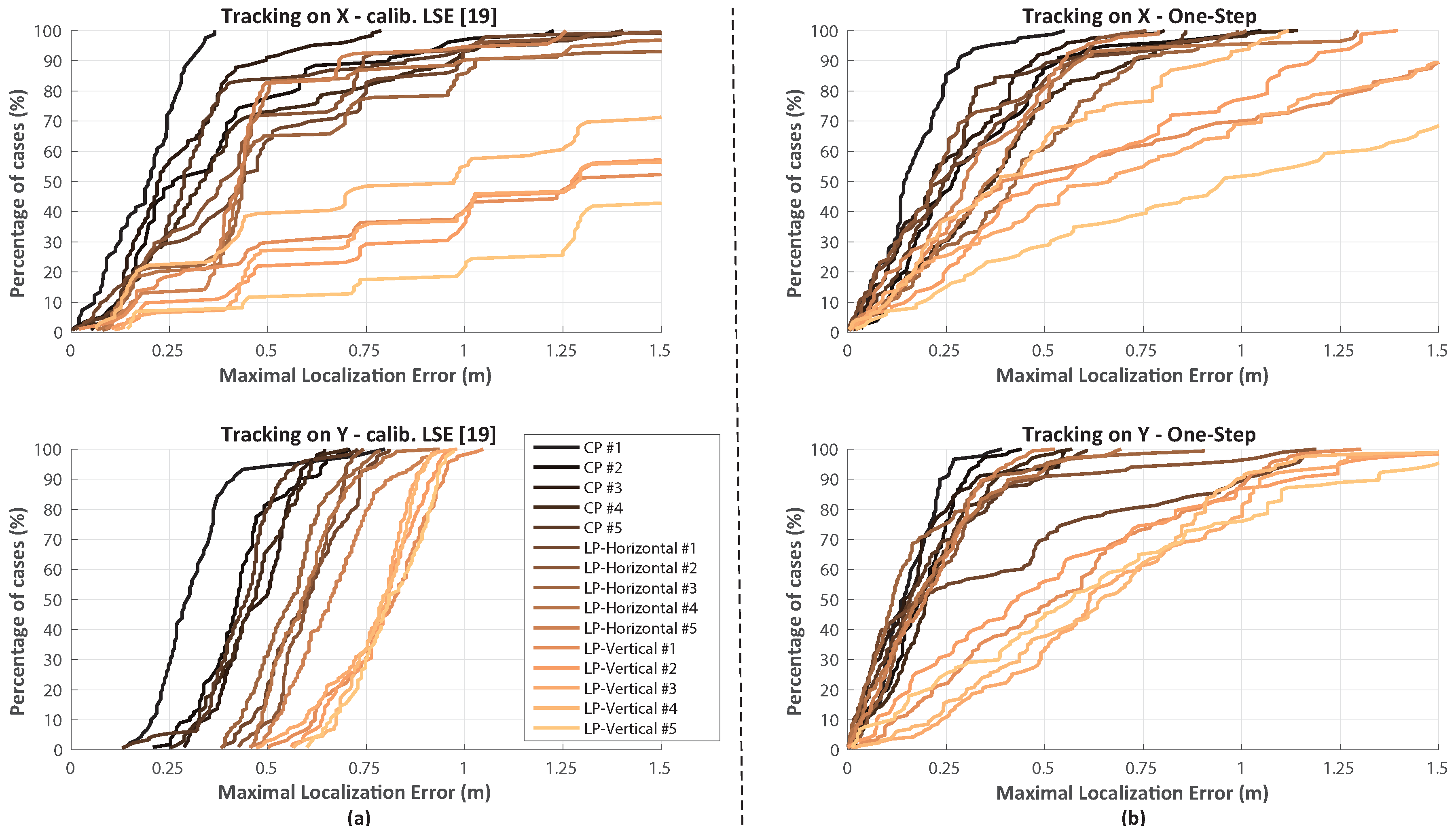
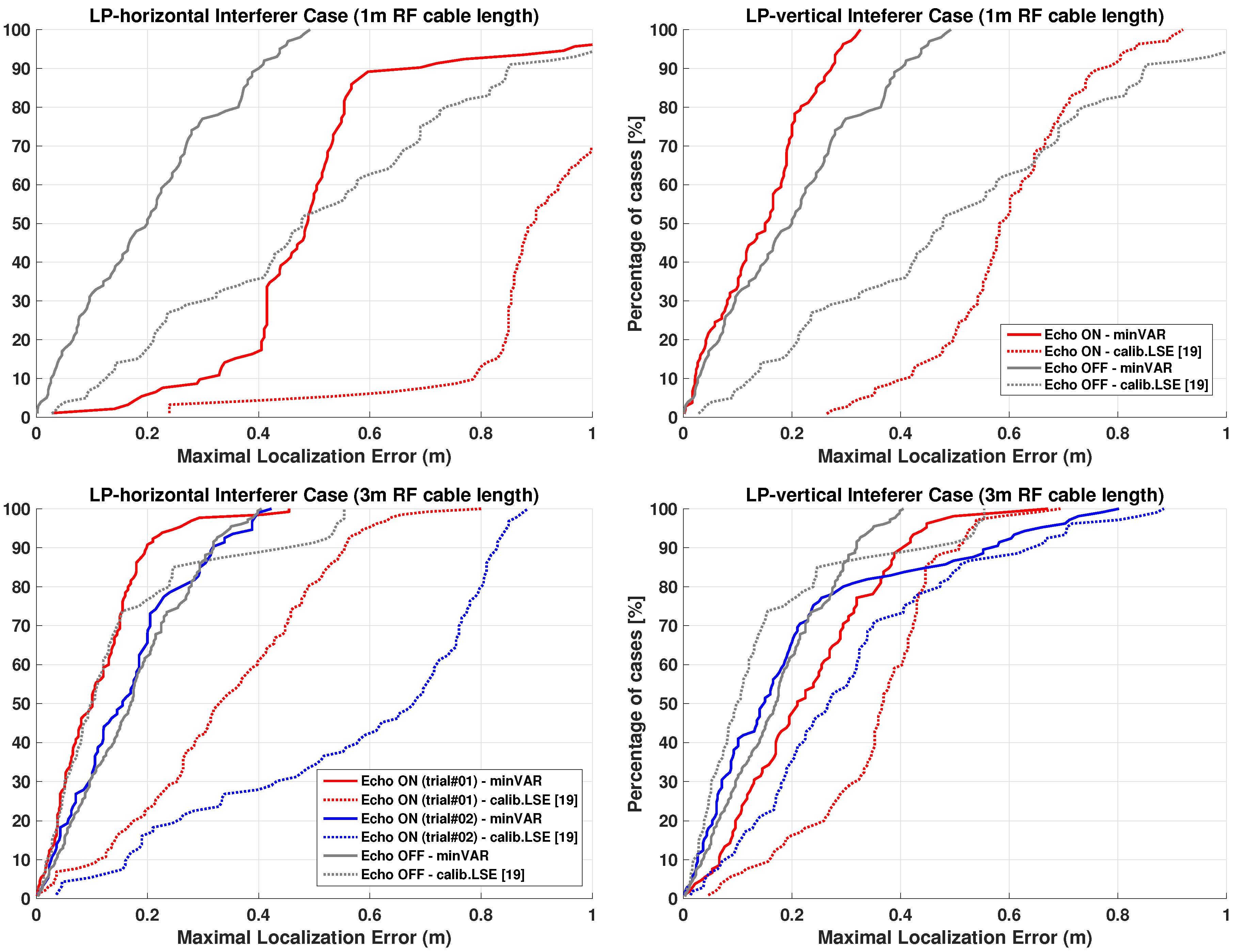
6. System Validation and “State-of-Art” comparison
The applied reference tuned map model projection seen in [
19] gives a first-grade approximation of RSSI environment distribution without evaluating any advanced effects, such as fading or scattering [
50] or measurement device deviation [
51,
52], which dramatically alters the effective power distribution [
8]. Due to the unpredictability of such phenomena, minimizing the effects of non-idealities will be much more reliable than making any kind of calibration, giving the unknown dependency and environment variables. Some solutions are proposed to reduce fingerprint map errors [
53], but the given improvement is far from achieving acceptable accuracy results. The depicted analysis and experimental results show an improved robustness of the proposed system to allow for the implementation of host-side software based solutions.
Table 9 lists a comparison of the State-of-Art equivalent indoor localization systems in the literature, considering standard COTS systems based on IEEE 802.11- and 802.15.4-compliant networks only, as the main goal is to produce a new direct-to-use submetrical localization system that can be considered transparent and cost-free in terms of a standard WiFi network configuration [
5]. To provide a comparison with systems based on more refined CSI (Channel State Indicator) evaluations ignoring the loss of portability due to unavailability of CSI detection (available only for OFDM WiFi modulation schemes [
54]) on wide-spread IEEE WiFi protocols, also results given by the state-of-art CSI-based localization system presented in [
54] are cited.
In literature some accurate indoor localization systems based on TDoA method over 802.11 IEEE networks are presented [
6,
7] but such method is currently unfeasible using COTS due to high accuracy measurement devices required or the needing of low-level communication stack access.
Explicitly smartphone-related algorithms (i.e., all odometry-based algorithms of
Table 9) improve localization accuracy by accomplishing RSSI fingerprint localization with odometric information provided by smartphone sensors. Some papers [
15] present approaches not based on fingerprinting techniques; nevertheless, all of them rely on an offline training phase. Although the accuracy can be good, the training phase always requires an uncomfortable calibration session.































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}