1. Introduction
Search strategies for finding an emitting source of hazardous substance based on sporadic sensory cues are a topic of great importance. In the context of national security, for example, the search could be for the source of an accidental or deliberate biochemical agent release into the atmosphere [
1], which would require urgent attention. Similar techniques are also used in search and rescue missions and to explain the foraging behaviour of animals. In many studies of these search techniques, the searching agent is assumed to be mobile and capable of sensing the emitted substance from the source. The sensing cues are often sporadic, fluctuating and discontinuous, due to turbulent transport through the medium over a large search domain [
2]. The objective of the search is to find the emitting source in the shortest possible time.
Recent advances in biochemical sensing technologies [
3,
4] have made the deployment of robots to search for such emitting sources very attractive [
5]. Developing autonomous robots equipped with appropriate sensing capability to explore and search in harsh and dangerous environments, such as toxic or flammable ones, is the ultimate goal of this research. Due to its importance, the topic has attracted a great deal of interest from the scientific community. A survey including a taxonomy of pre-2008 search algorithms can be found in [
6]. The dominant class of methods are bio-inspired strategies [
7,
8,
9], which mimic the use of olfactory senses by bacteria, insects and other animals to localise food sources, detect predators, or find mates. Typically, the search actions depend on sensory cues. For example, upon sensing an odor signal, male moths surge upwind in the direction of the flow. When odor information vanishes, they exhibit random cross-wind casting or zigzagging to perform a local search until the plume is reacquired. Chemotaxis algorithms are a bio-inspired class of algorithms, in which the search is carried out by climbing the concentration gradient [
10]. These strategies are effective close to the source where the odor plume can be considered as a continuous cloud. In the absence of positive detections, the robot may stay in one position, move linearly, or carry out a random walk. Once the chemical is detected, motion is directed towards higher gradients of concentration. These bio-inspired techniques are simple, as they require only limited spatial perception [
11], however they are mostly ad hoc. Another popular class of algorithms, not mentioned in [
6], are stochastic source-seeking algorithms [
12,
13,
14]. While these algorithms are theoretically sound, they rely on smooth gradients of concentration. In the presence of turbulence, however, where the plume of the tracer randomly breaks up into time-varying disconnected patches resulting in intermittent measurements, these stochastic source-seeking algorithms are not practical.
Recently, a class of algorithms referred to as
infotaxis [
15] was developed specifically for searching in turbulent flows. In the absence of a smooth distribution of concentration, caused by turbulence, this strategy directs the robot towards the highest information gain. As a theoretically principled approach, with the source-term estimation being carried out in the Bayesian framework and the robot motion control being based on information-theoretic principles, the infotaxic strategy has been adopted by a number of research groups [
16,
17,
18,
19,
20,
21,
22,
23,
24].
The goal of Bayesian estimation is to construct the posterior probability density function (PDF) of the source parameter vector, which typically includes its location, release rate and size. In [
15] the estimation was carried out using an approximate grid-based nonlinear filtering technique [
25] on a two-dimensional parameter space consisting of the
x and
y Cartesian coordinates of the source location. The source-release rate was assumed known, as well as the environmental parameters. The search was carried out using a single robotic platform. Grid-based nonlinear filtering was subsequently replaced with the sequential Monte Carlo method (also known as the particle filter) in [
21,
22,
23,
26]. The particle filter is more efficient than grid-based methods and is therefore capable of estimating the source-release rate jointly with the source location. Multi-robot infotaxis were investigated in [
16,
22,
24].
Sequential estimation of the source posterior PDF using the particle filter is problematic when the state (the source parameter vector) is random, but
stationary [
27]. The absence of dynamics in the state implies that the exploration of the parameter space is limited to the first time index only. Even by artificially introducing dynamics to the state (e.g. a random walk-like dynamic with a small variance), the depletion of particles is inevitable over time and causes the collapse of the PF for long-duration searches [
23]. In this paper we apply a Rao–Blackwell dimension reduction method to estimate the posterior PDF of the source parameter vector. This method computes the source release-rate, conditioned on the source location, analytically and uses the Monte Carlo method only in the space of
x and
y coordinates of the source. As a batch method, it does not suffer from depletion of particles over time. This paper studies the multi-robot search assuming a replicated centralised fusion with all-to-all communication. The robots move in a scalable formation, where the maximum size of the formation is determined by the specified communication range. Control actions are made autonomously by all robots using entropy reduction as the information theoretic measure. In computing the reward, however, we also introduce a cost of motion. The paper analyses the statistical patterns of the search, in particular the formation displacements and its scale.
The organisation of the paper is as follows. Mathematical models are presented in
Section 2. The method of source parameter estimation is described in
Section 3. Robotic platform motion control is explained in
Section 4.
Section 5 presents the numerical results, through simulations and using an experimental dataset characterised by a turbulent flow. Finally, the conclusions are drawn in
Section 6.
3. Source Parameter Estimation
3.1. Problem Specification
Let denote the sensor measurement recorded by the ith robot platform at time . The sequence of such measurements from platform i, starting from the beginning of the search until is a vector , . Similarly, the measurements from all platforms up to time is a vector . Accordingly we can define the vector of sensor measurement locations corresponding to as . This vector is assumed to be known. Whenever in the text we refer to the measurement vector , we implicitly assume that it is in pair with .
Assuming all-to-all communication between the platforms for exchanging mutually their latest measurements and positions (ignoring the time-delays and bandwidth limitations), and are available at every platform at time for processing. Thus, every platform can independently carry out centralised fusion in order to estimate the source parameter vector . This type of fusion architecture is known as replicated centralised.
Assuming the sensor measurements, conditioned on , are independent, the likelihood function of the measurement vector can be written as a double product .
We adopt the Bayesian estimation framework with the goal of computing the posterior PDF
. In this framework, in addition to
, one needs to specify the prior distribution of the parameter vector
. Then, using the Bayes’ rule, the posterior PDF is:
For the described problem, (
7) cannot be solved analytically and we need to apply a numeric approximation. However, it will be shown that, assuming the prior of the source strength
is a gamma distribution, the posterior
can be solved analytically. Because the posterior
, using the chain rule, can be expressed as:
x
we will only need to apply a numeric approximation to estimate the posterior
.
3.2. Solution
It is reasonable to assume that the source strength is independent of its location, and hence
. Let us adopt for
a gamma distribution, with the shape parameter
and the scale parameter
:
Note that for suitably chosen hyperparameters and , the support of this prior can cover a large span of possible values of .
The conjugate prior of the Poisson distribution is the gamma distribution [
28]. Therefore, the posterior
is also a gamma distribution,
, with parameters
and
expressed analytically as a function of
and
as follows (see
Appendix A):
where
, that is:
It remains to compute the posterior PDF
:
Compared to (
7), which is a three-dimensional PDF, the posterior in (
13) is two-dimensional. This dimension reduction improves the accuracy of the numerical solution. After a few lines of mathematical derivations one can show that the analytic expression for the likelihood function
, which features in (
13), is given by (see
Appendix A):
A plethora of techniques is available for the numerical computation of (
13), from grid-based numerical integration methods to Monte Carlo methods (e.g. the Markov Chain Monte Carlo, importance sampling and population Monte Carlo). We choose a Monte Carlo method which, for a given
and
, approximates the posterior PDF
by a random sample
as follows:
Here
denotes the delta-Dirac mass located at
. As the size of the sample
, the moments of
converge almost surely to the moments of
. An advantage of the Monte Carlo method over the grid-based (deterministic) integration is that the former positions its integration points (i.e., samples) in the regions of high probability [
29].
The basic steps in estimation of
expressed by (
8) are summarised in Algorithm 1. The expected
a posteriori point estimates of the source location and its strength can be computed from the output
as follows:
| Algorithm 1 Estimation of |
- 1:
Input: , , , , M - 2:
Estimate by a random sample - 3:
Compute , Equation ( 10) - 4:
Compute using , Equation (11); - 5:
Output:
|
Finally, the Monte Carlo method which estimates
in line 2 of Algorithm 1, was implemented using iterated importance sampling with progressive correction (IIS-PC) [
30]. Full details of the implementation are given in [
31]. A desirable property of importance sampling is to draw samples from an importance density that result in sample weights with a minimal variance. The question is how to design this importance density. The key idea behind IIS-PC is to achieve the goal of drawing samples with a minimal variance in a sequential manner, by constructing a sequence of target distributions from which to draw samples. The first target distribution is the prior, while every subsequent target distribution should increasingly resemble the posterior. A target distribution which can be used in this context at iteration
of the IIS-PC is:
where
is given by (
14),
with
and
. Note that
is an increasing function of
s, upper bounded by one. As a consequence, the intermediate likelihood is broader than the true likelihood, particularly in the early stages (for small
s). Thus, the sequence of target distributions in (
17) gradually introduces the correction imposed by the measurement
on the prior
. To derive any benefits from IIS-PC, it is required after each stage to remove the lowly weighted members of the sample and diversify the remaining ones. Lowly weighted members are removed by resampling [
27], while diversification of the remaining samples is performed by Markov transitions whose stationary distribution is the target distribution
. The outcome is a diverse sample located in the region of the parameter space where the intermediate likelihood has non-zero values. The choice of correction factors
, as well as the number of iterations
H are design parameters. Further details can be found in [
31].
4. Robot Formation Control
Suppose at time
the robotic platforms have processed all available measurements included in the vector
and estimated the posterior PDF
using the method described in
Section 3. Let
denote a designated search area, which includes the source location
. The key aspect of search is, for each robotic platform of the formation, to decide autonomously where to move next within
in order to acquire a new concentration measurement at
, denoted
.
An autonomous multi-robot search can be formulated as a partially-observed Markov decision process (POMDP) [
32]. The elements of a POMDP include an information state, the space of admissible actions (controls) and a reward function. The information state, adopting the Bayesian framework for estimation of source parameters, is the posterior PDF
. Current knowledge about the source position and strength is fully specified by this density. A decision in the context of search is the selection of a control vector
, where
is the space of admissible actions. Finally, the reward function maps each admissible action into a non-negative real number, which represents a measure of the action’s expected information gain. An optimal strategy selects, at each time, the action with the highest reward. Admissible actions can be formed with one or multiple steps ahead. According to the motion model introduced in
Section 2.1, the space of admissible actions
is continuous with four dimensions:
,
,
and
. In order to reduce the computational complexity of the numerical optimisation, we discretise
and consider only myopic (one step ahead) control.
If
,
,
and
denote the sets of possible discrete-values of
,
,
and
, respectively, then
is the Cartesian product
. The myopic selection of the control vector at time
is expressed as:
where
is the reward function. Note that the reward function depends on the future measurement
, assuming the control vector
has been applied. In reality, this future measurement is not available (the decision has to be made at time
), and therefore the expectation operator
with respect to the prior measurement PDF features in (
18). Previous studies of search strategies [
16,
23] found that the reward function measuring the information gain as the
entropy reduction, results in the most efficient search. However, the earlier work neglected that, while traveling, robots incur certain cost. Assuming
is the cost of travel per unit distance, we adopt the following specification for the expected reward function:
where
is the travelled distance under action
,
is the current entropy (based on
), i.e.,
is the future entropy (after applying the control
):
and
is its expected value, with respect to the probability mass function
:
The exponential term,
, in (
19) incorporates the cost of travel, penalising longer travel distances.
The computation of entropy
in (
20) is carried out as follows. Recall that
is approximated by a random sample
. From this representation, one can compute a random sample
, with uniform weights
, where
and
, for
. Then
, which leads to the approximation
.
The computational expense of exact computation of
grows exponentially with
N because the sum in (
22) is
N-dimensional: it requires consideration of all possible combinations of measurement outcomes from
N platforms. Hence we resort to a Monte Carlo approximation. For a command vector
, first we draw a random sample
from
using the following procedure. We randomly select a sample
from
, and then draw
N times from the likelihood
. By repeating this procedure
S times,
samples of the measurement outcomes from
N platforms
are created. Then (
22) is simply approximated as:
.
The search algorithm needs to decide when to stop the search and report its final estimates of source parameters, denoted and . The termination criterion is based on the spatial spread of the random sample , computed as the trace of its sample covariance matrix. When this spread is below a certain threshold, denoted , the search is terminated.
The key assumption of the replicated centralised fusion architecture is that the same input data (measurements
and the corresponding locations
) are available to all robotic platforms for data fusion (parameter estimation and robot motion control). However, this assumption is not sufficient. As the Monte Carlo method plays a role in the data fusion, we must also ensure that the same pseudo-random generators, using the same seed, are running on each individual platform. In this way all platforms reach the same decision on the motion control vector
and subsequently apply the motion model described in
Section 2.1, knowing their own identification number
i in the formation.
6. Summary
The paper proposed an algorithm for autonomous search for an emitting source of hazardous material transported through the environment by a turbulent flow. The search was designed for a group of robots connected in a network with all-to-all communication.
The source parameter estimation was carried out in the Bayesian framework: the posterior density of source strength, conditioned on the source location, was carried out analytically. The posterior density of source location, on the other hand, was computed numerically, using a Monte Carlo method. The source parameter estimation, carried out in this manner, overcomes the problems encountered in previous implementations, such as the assumption that the source strength is known in using the grid-based estimation, or the depletion of particles, when the particle filter is applied.
The robots are moving in a controllable formation, with control parameters including the linear and angular velocity, the travel time and the scale of formation. The reward function for choosing the robot formation control vector was selected as the entropy reduction, with the built-in travel cost.
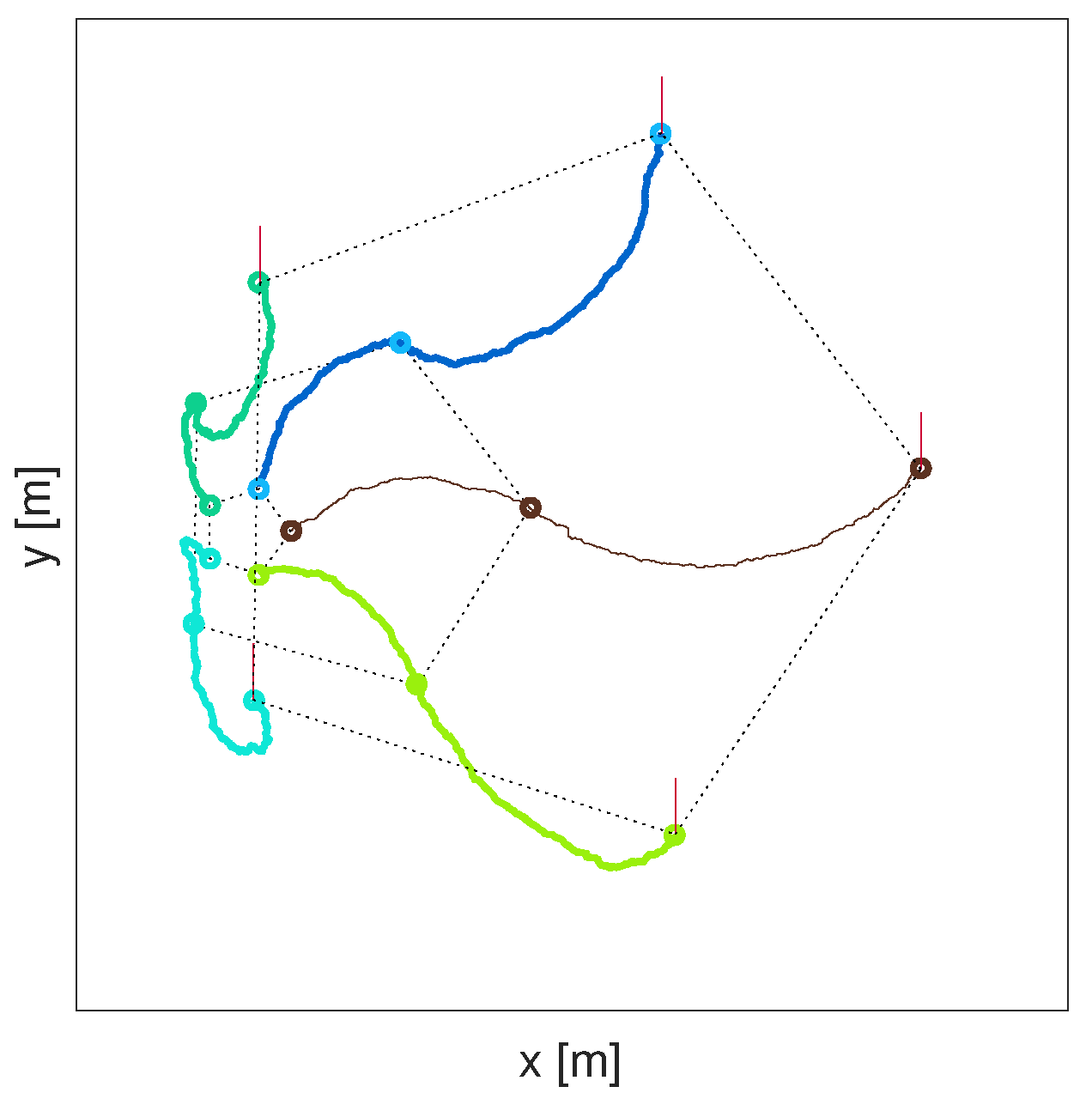
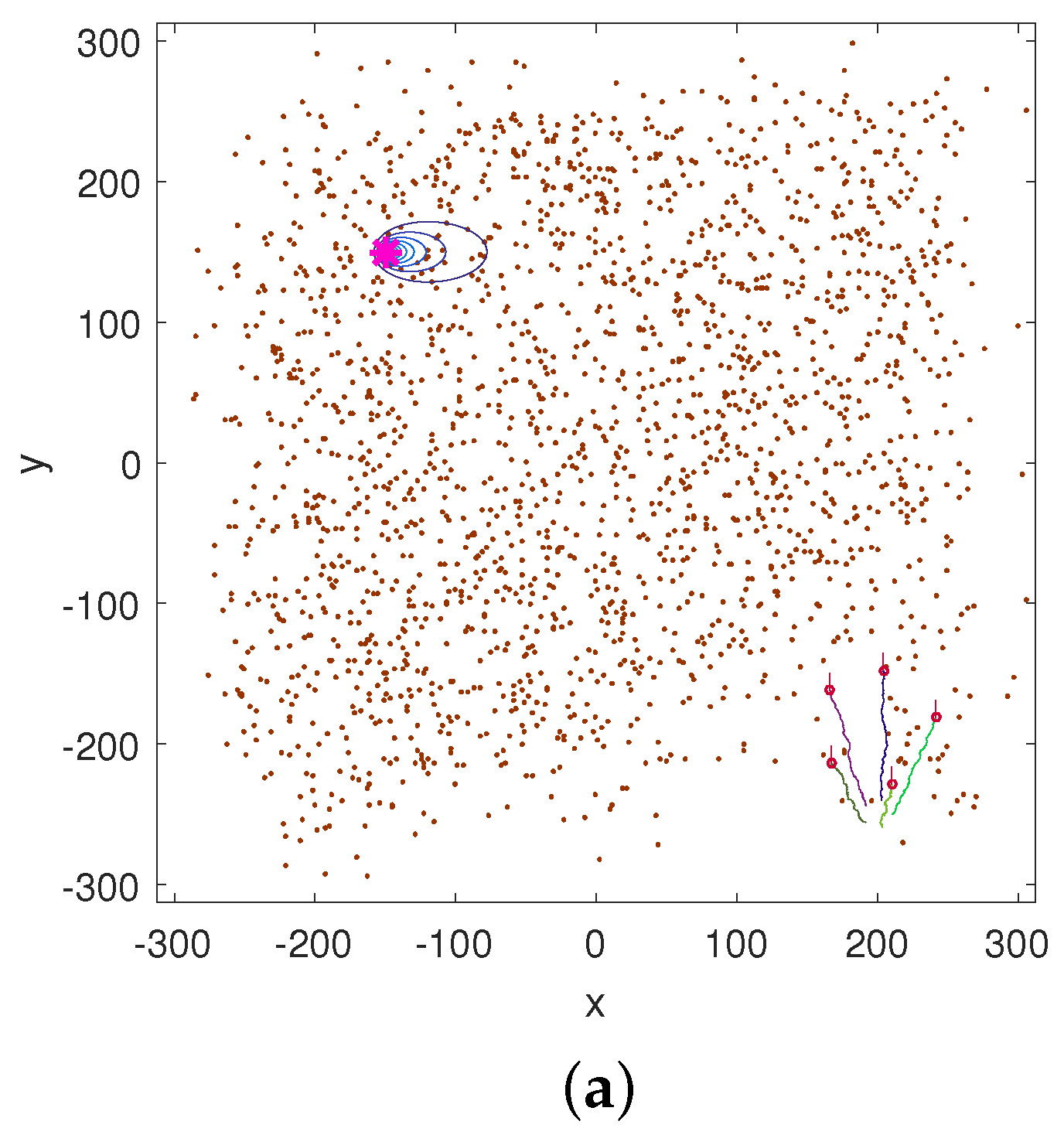
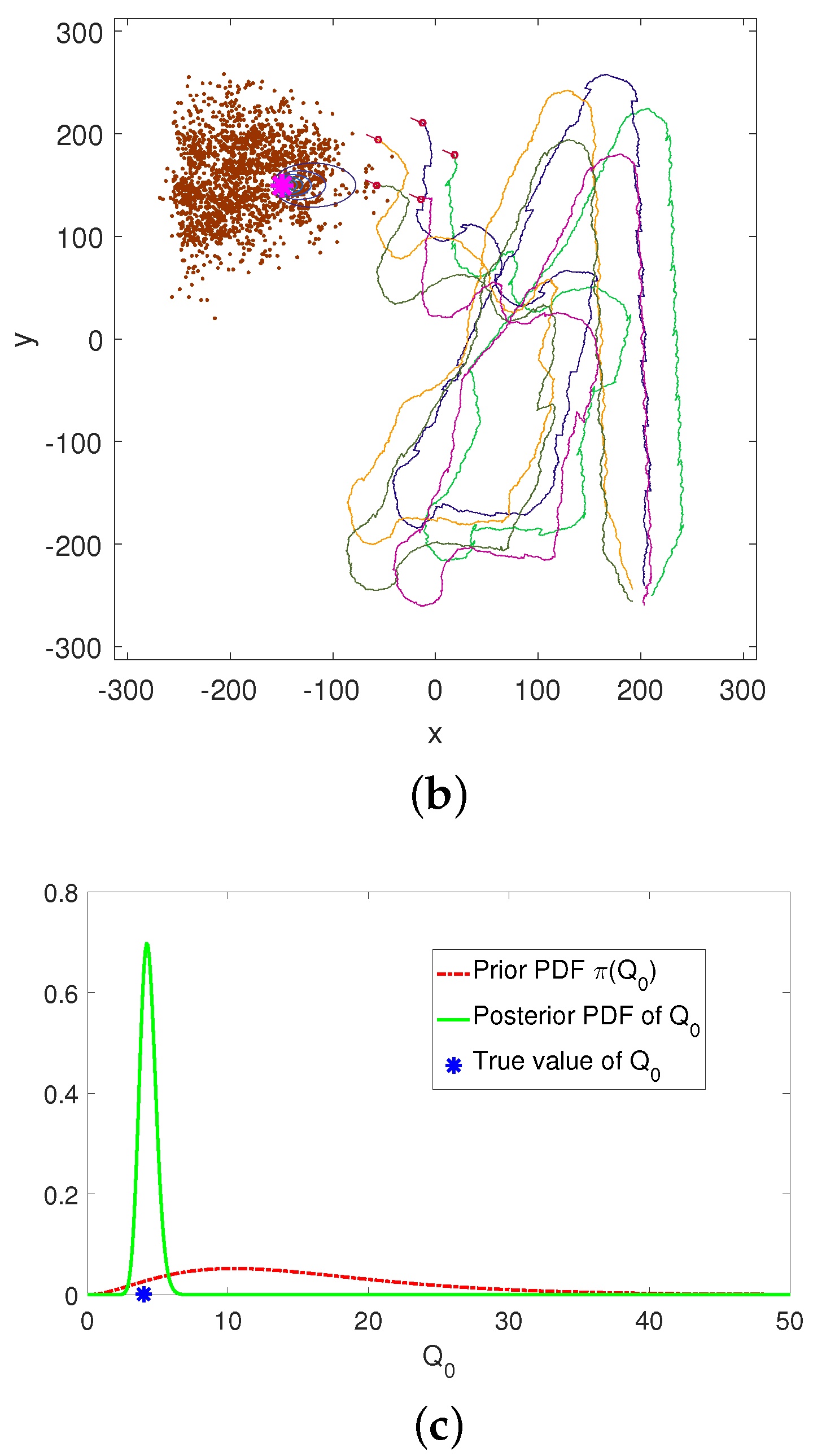
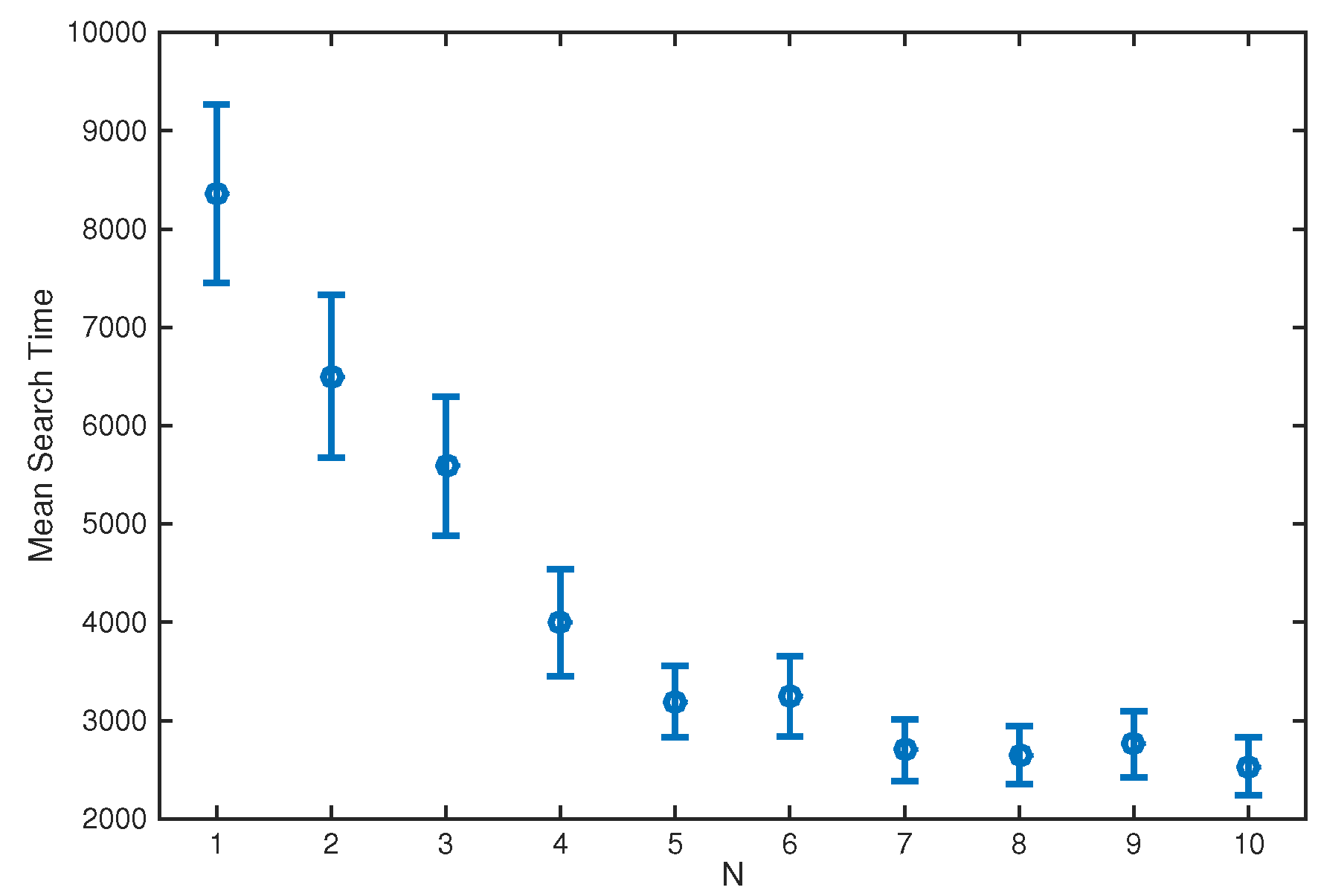
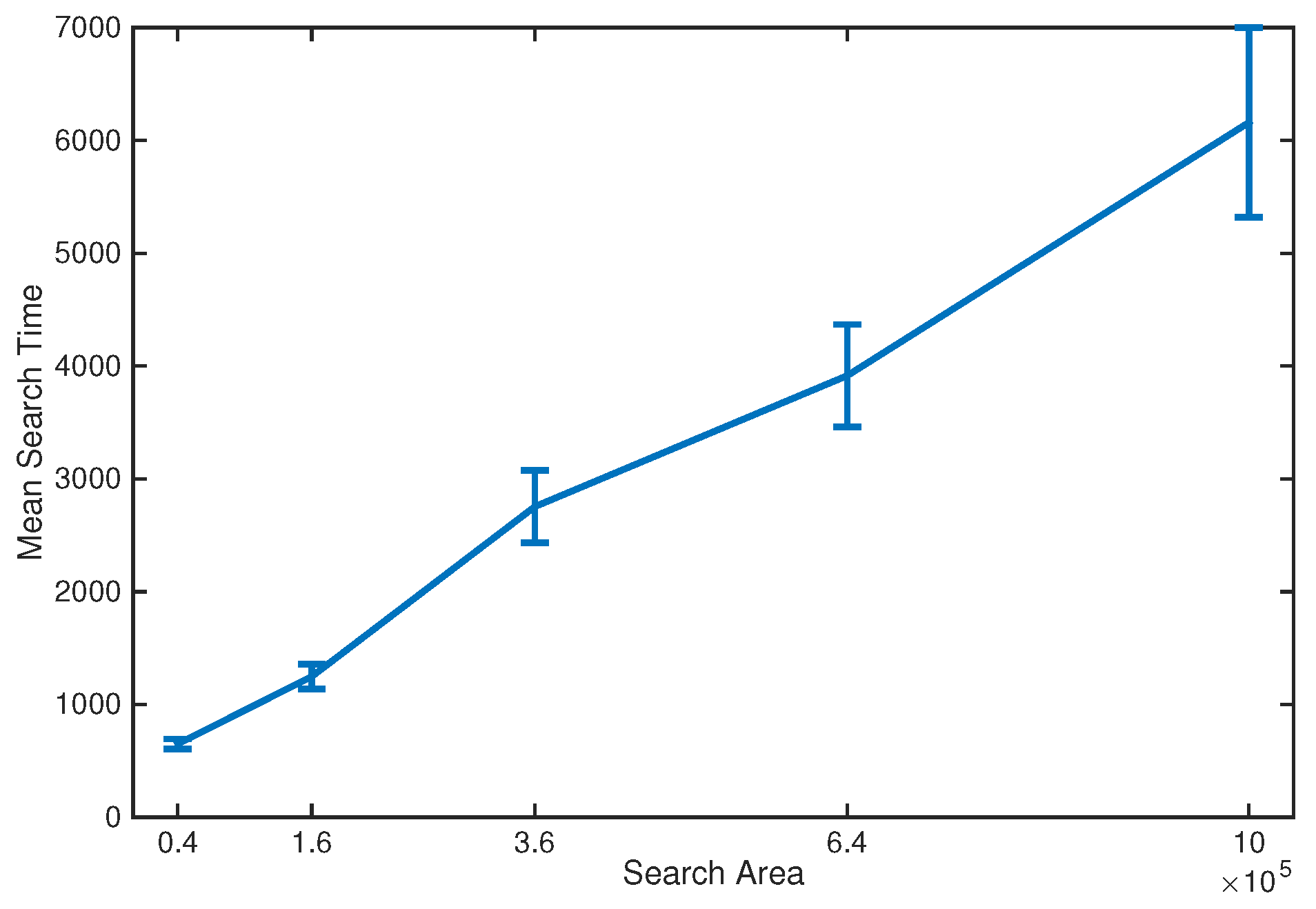
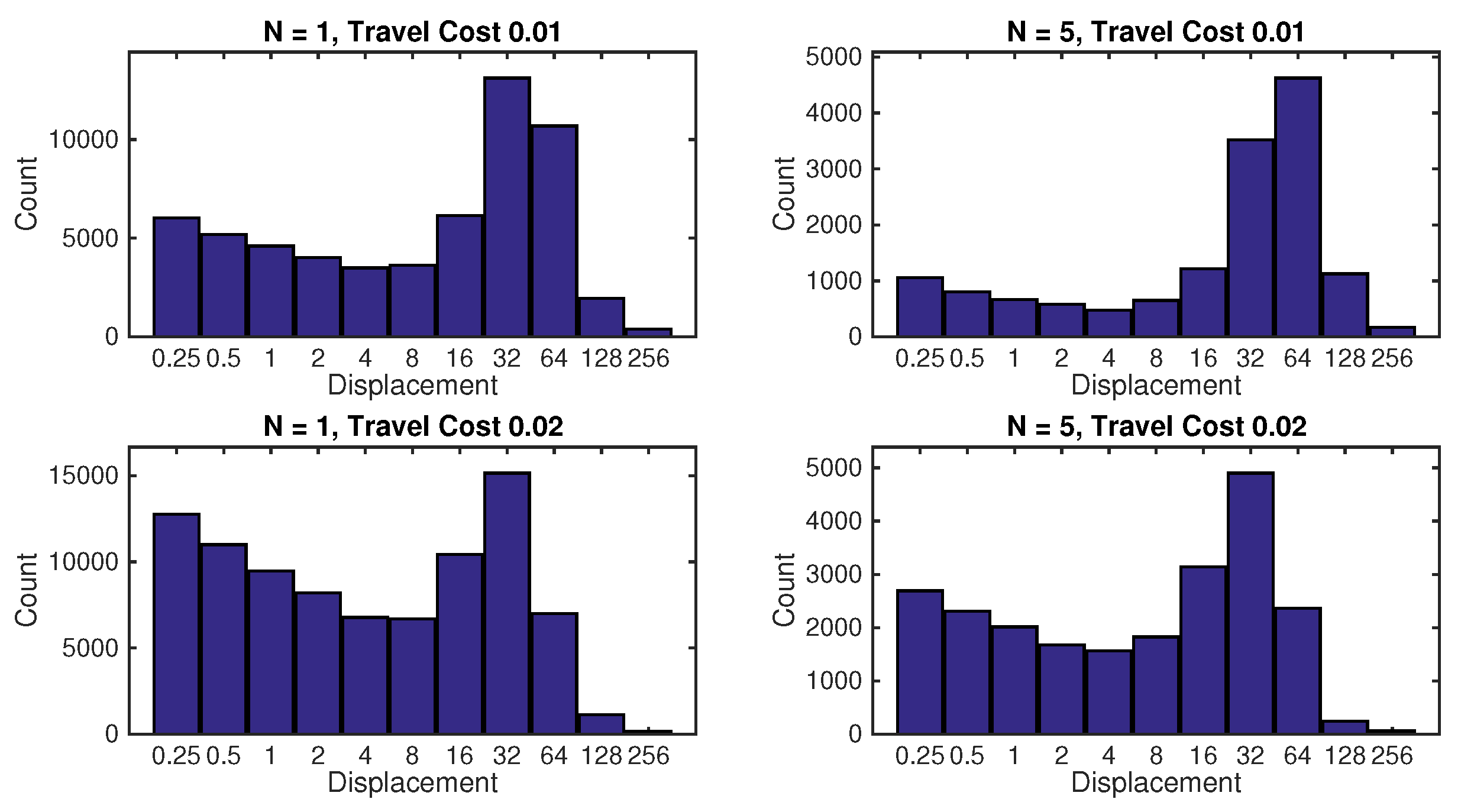
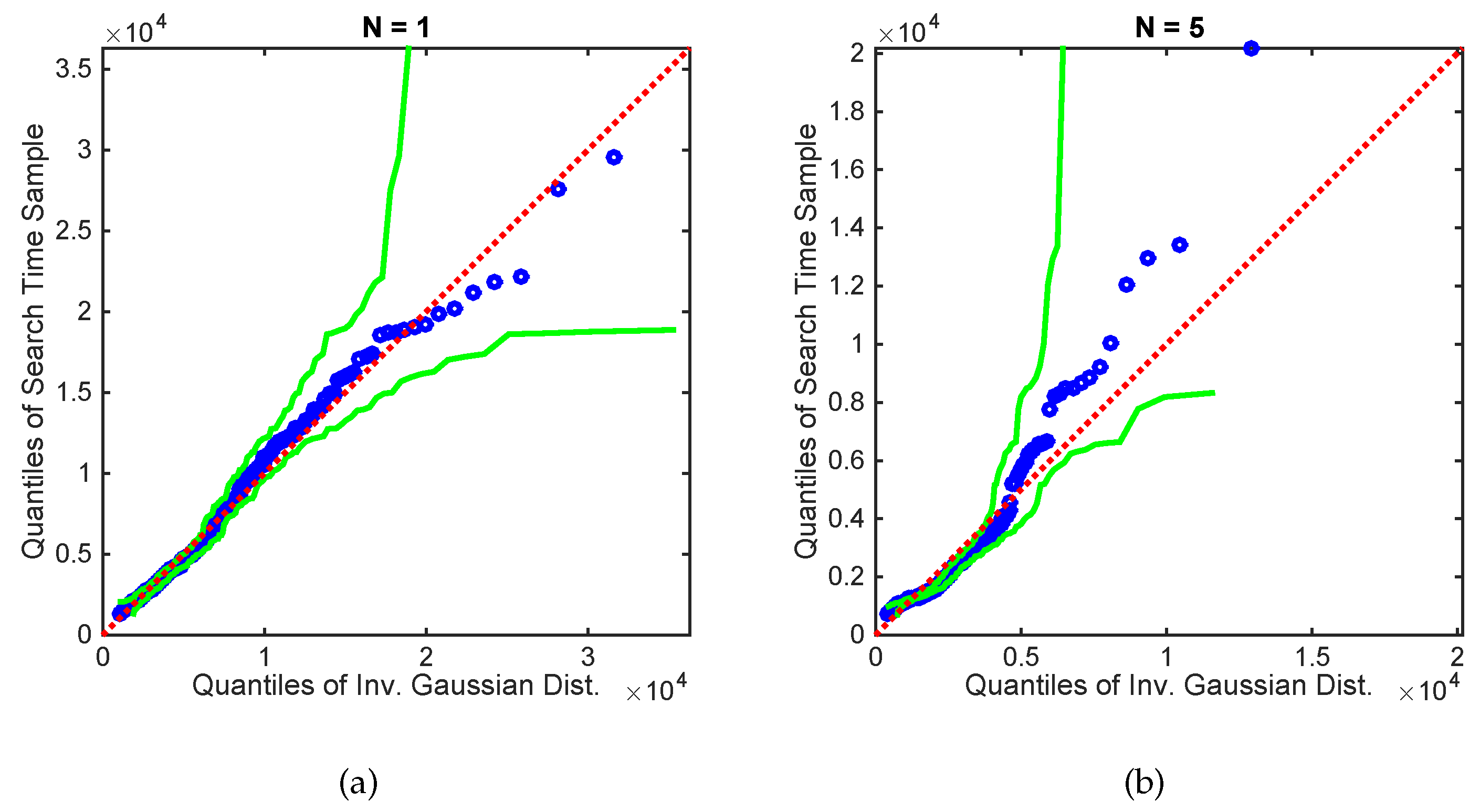
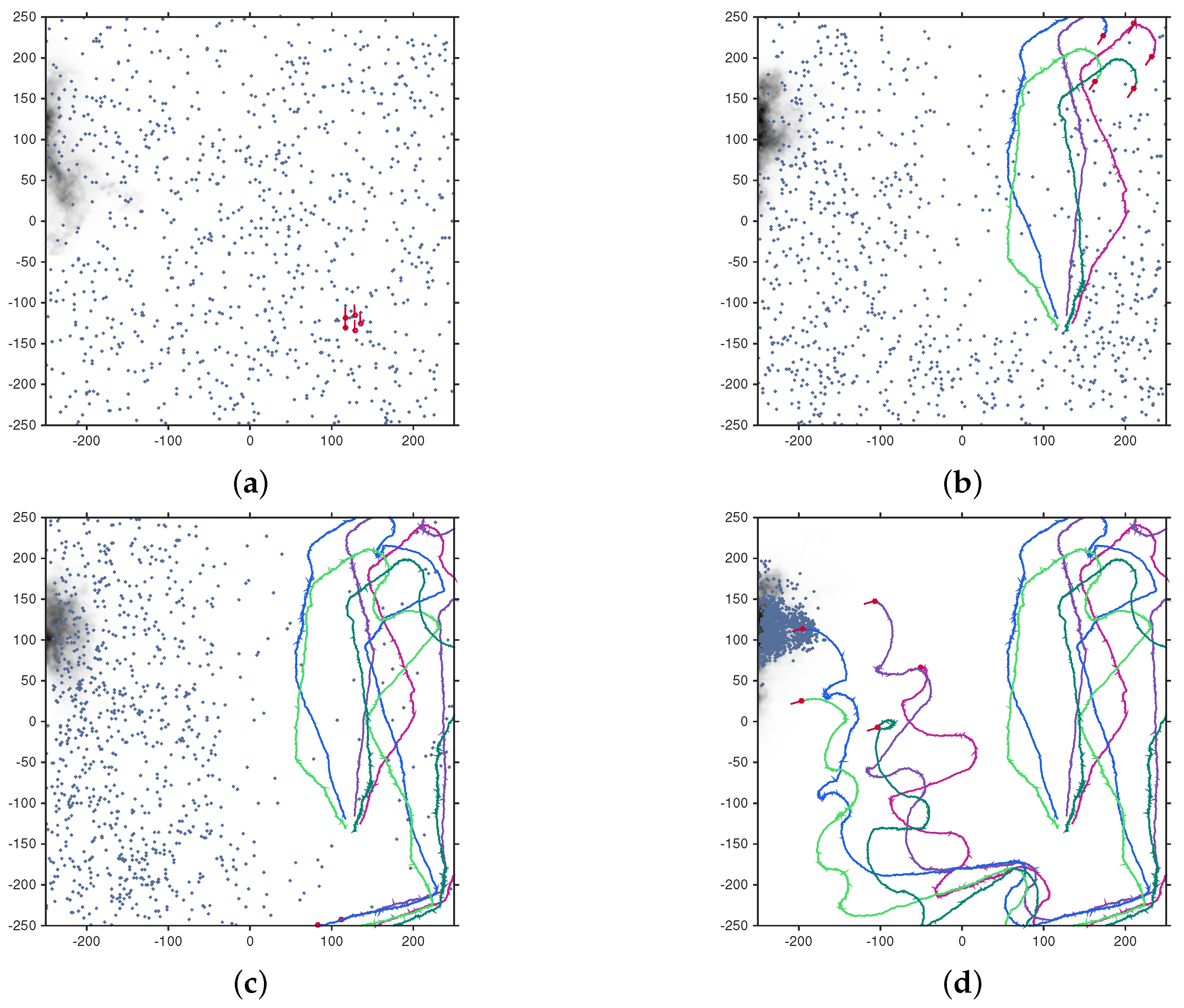
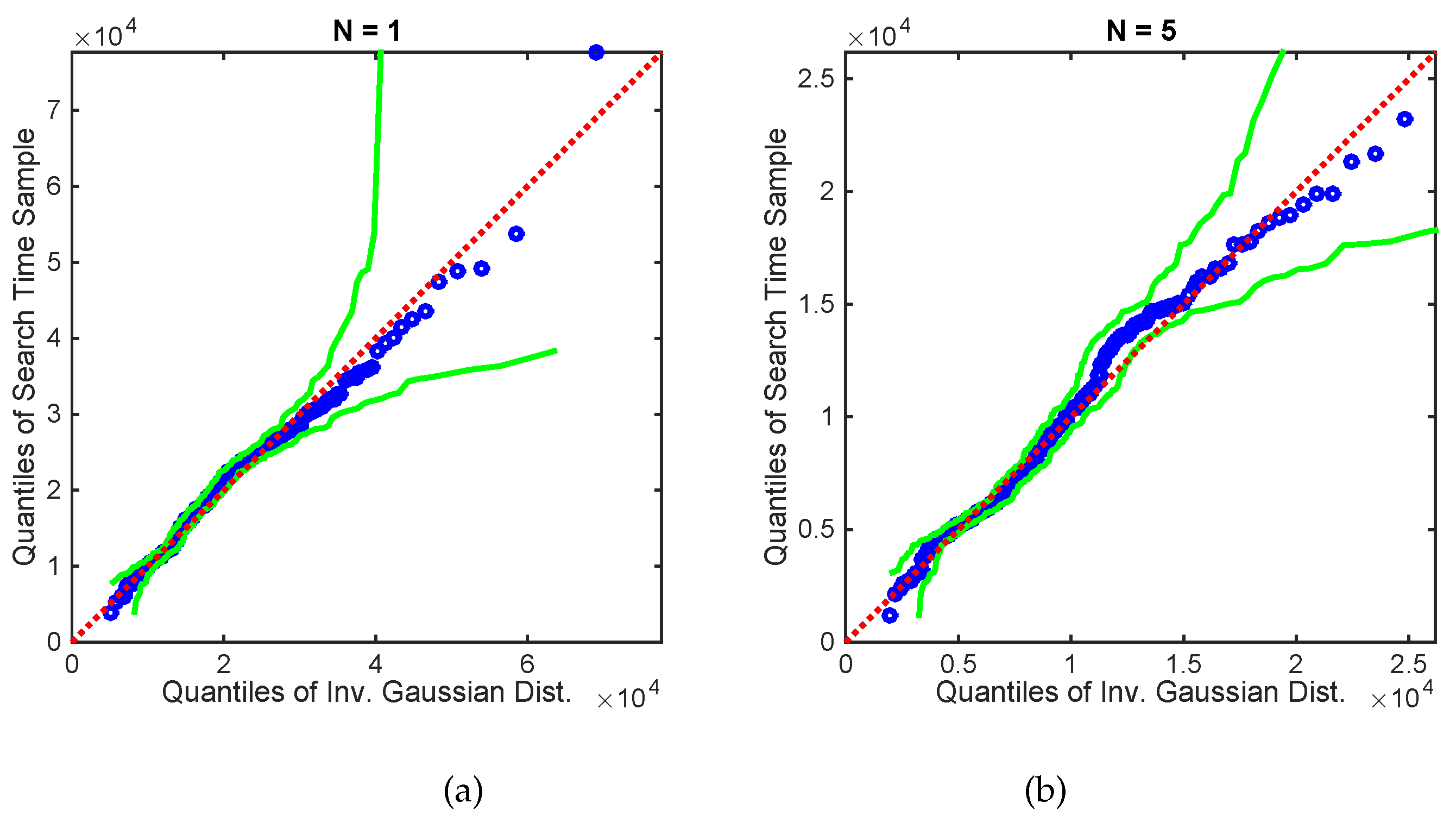
Numerical results, using both simulated and real data, demonstrate reliable performance: the success rate in finding the source is , with localisation accuracy determined by the termination criterion. Furthermore, the analysis of the algorithm reveals: (1) a diminishing return on increasing the number of platforms in formation; (2) a linear growth of the mean search time with the search area; (3) an increase in the cost of travel resulting in shorter formation displacements; (4) the search displacements are in accordance with the intermittent search strategy; and (5) the PDF of search time for a single searcher is well-modelled by the inverse Gaussian distribution.
There are many avenues for future work. For example, one could explore distributed, rather than centralised, source parameter estimation and robot control. This could take into account a more realistic communication network with limited bandwidth and time delays. The implicit assumption in the presented work was that the search area is an open field. The search in an area with obstacles and known map would be another complementary future research direction: it would require a different dispersion model, and modifications of the parameter estimation and robot control algorithms. Finally, the search in an area with obstacles and an unknown map would require robots to be equipped with appropriate ranging sensors for localisation and mapping. Carrying out autonomously and simultaneously three functions: search, localisation and mapping, is the ultimate goal of this research.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








