Block-Diagonal Constrained Low-Rank and Sparse Graph for Discriminant Analysis of Image Data


Abstract
:1. Introduction
- (1)
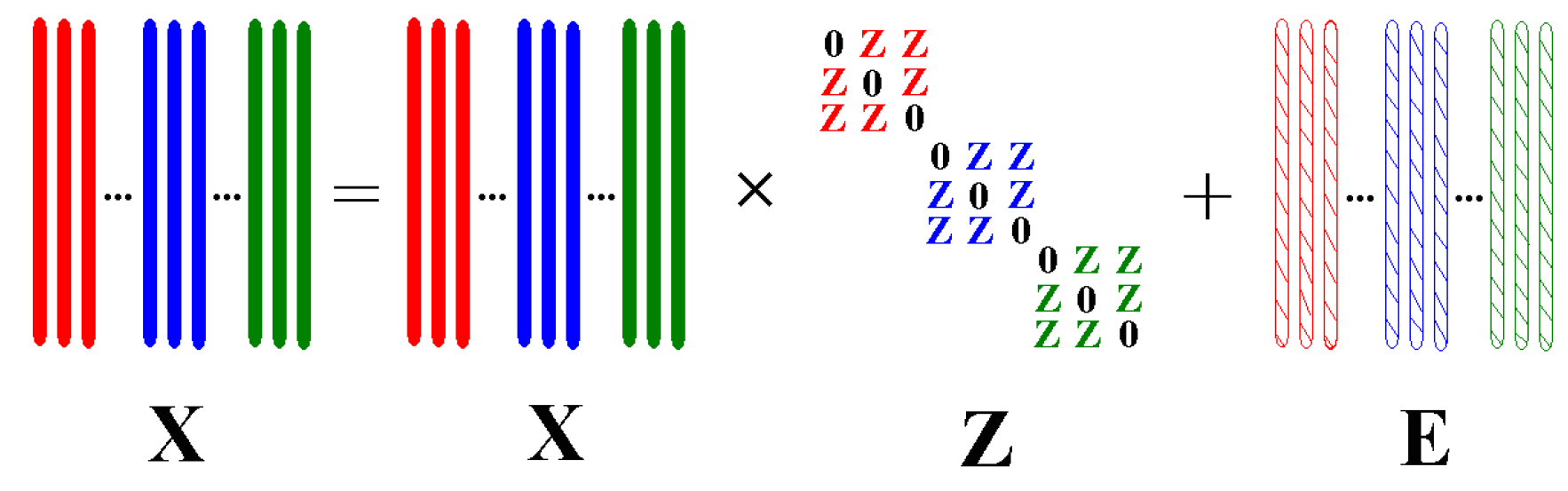
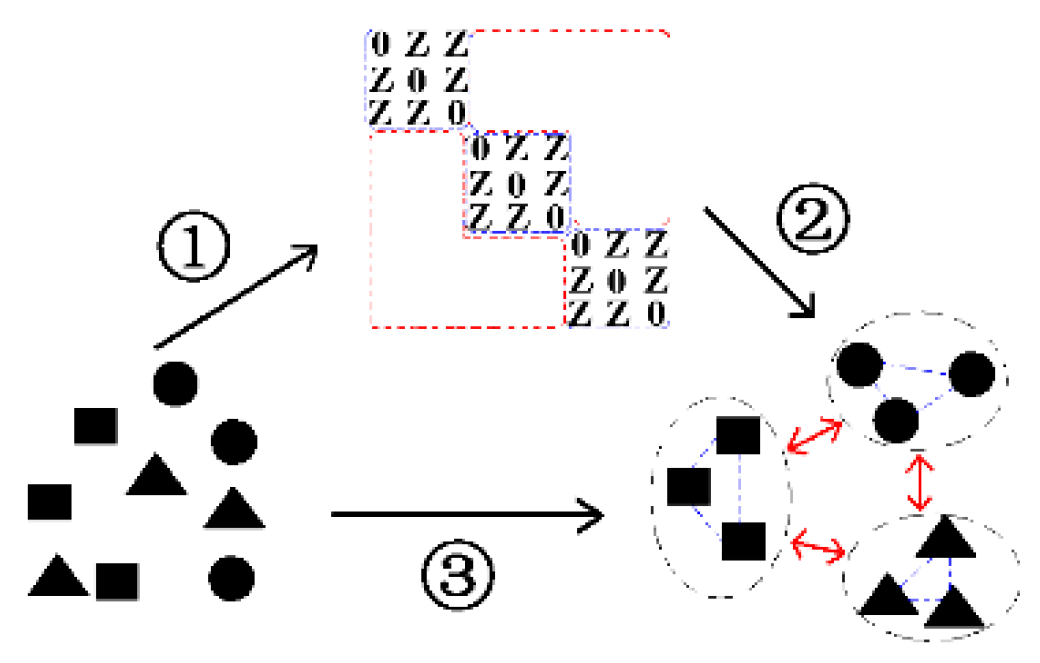
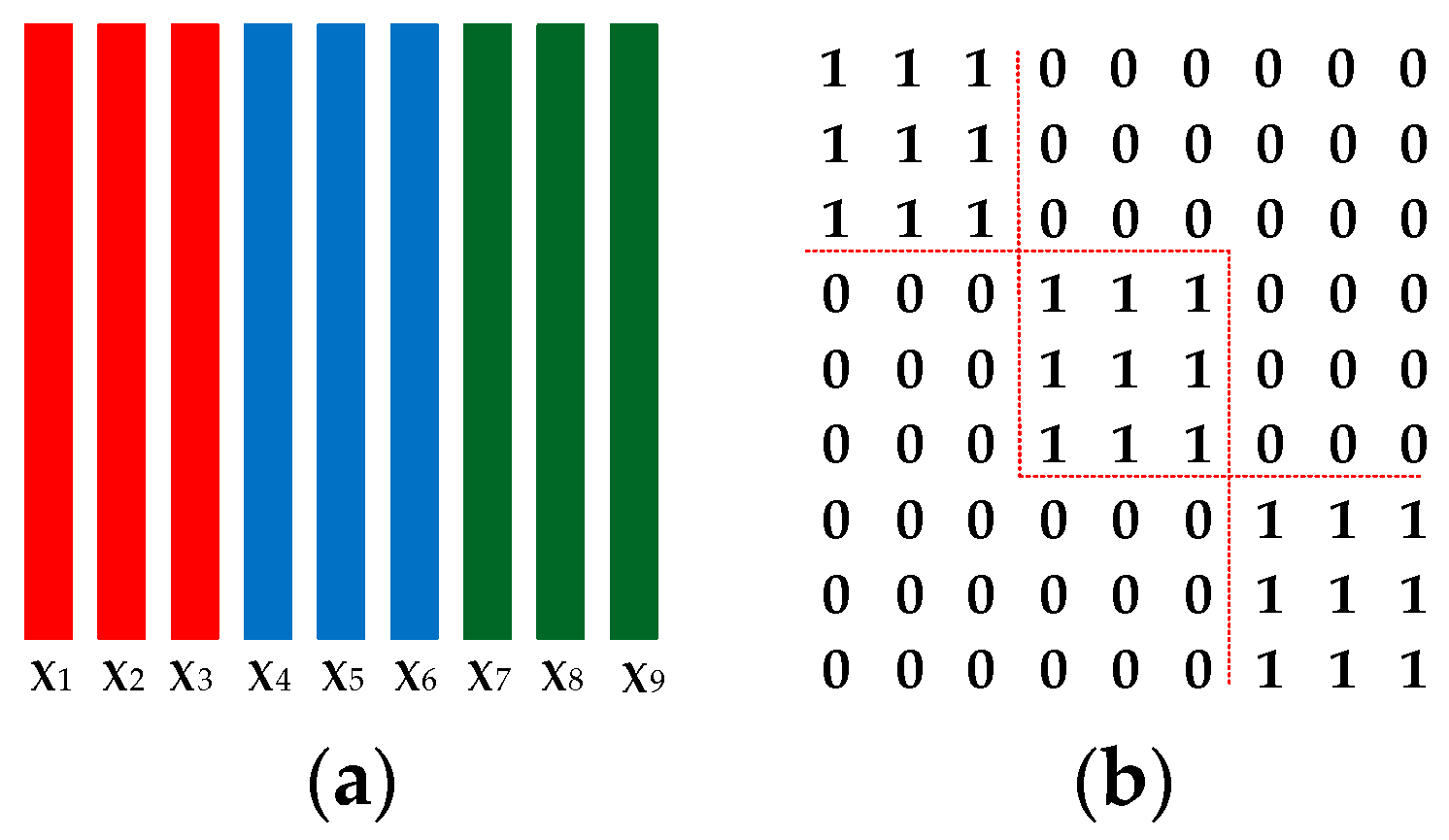
- A self-expressive model, i.e., BLSR is devised by incorporating sparsity, low rankness as well as a novel block-diagonal constraint. BLSR can not only simultaneously capture the local and global structures, but also highlight both the intra-class similarities and inter-class differences of samples.
- (2)
- With the intra-class and inter-class graphs derived from BLSR, BLSGE seeks an optimal feature space by simultaneously minimizing the intra-class scatter and maximizing the inter-class scatter. Generally, a novel supervised dimensionality reduction method namely BLSE is developed by taking the advantages of BLSR and GE framework.
- (3)
- BLSE is applied for the dimensionality reduction and classification of visual data. Extensive experiments on the public face and object datasets verify the effective of proposed method.
2. Related Works
2.1. Low Rank and Sparse Representation
2.2. Graph Embedding
3. Proposed Method
3.1. Block-Diagonal Constrained Low-Rank and Sparse Based Embedding (BLSE)
3.1.1. Block-Diagonal Constrained Low–Rank and Sparse Representation (BLSR)
3.1.2. Block-Diagonal Constrained Low–Rank and Sparse Graph Embedding (BLSGE)
3.2. Optimizations for BLSR and BLSGE
3.2.1. Optimization for BLSR
| Algorithm 1. Solving BLSR by Inexact ALM |
| Input: Training data . Parameters , and . |
| Initialization: , , |
| , , , . |
| 1: While not converged do |
| 2: Fix other variables and optimize via (14). |
| 3: Fix other variables and optimize via (15). |
| 4: Fix other variables and optimize via (16). |
| 5: Fix other variables and optimize via (18). |
| 6: Update the multipliers and via (19). |
| 7: Check the convergence conditions: |
| , |
| 8: End while |
| Output: |
3.2.2. Optimization for BLSGE
| Algorithm 2. BLSGE |
| Input: Affinity weights matrix , reduced dimension . |
| 1: Compute the weights of inter-class graph (6) and intra-class graph (7) through affinity matrix. |
| 2: Solve the generalized eigenvalue problem (21), and get the eigenvectors corresponding to the minimum eigenvalues. |
| Output: Projection matrix . |
| Algorithm 3. BLSE |
| Input: labeled training data . Reduced dimension . |
| Tradeoff parameters , and . |
| 1: Run Algorithm 1 to get the affinity weights matrix of . |
| 2: Run Algorithm 2 to obtain the optimal projection matrix . |
| Output: Projection matrix. |
3.3. Classification
4. Experimental Results
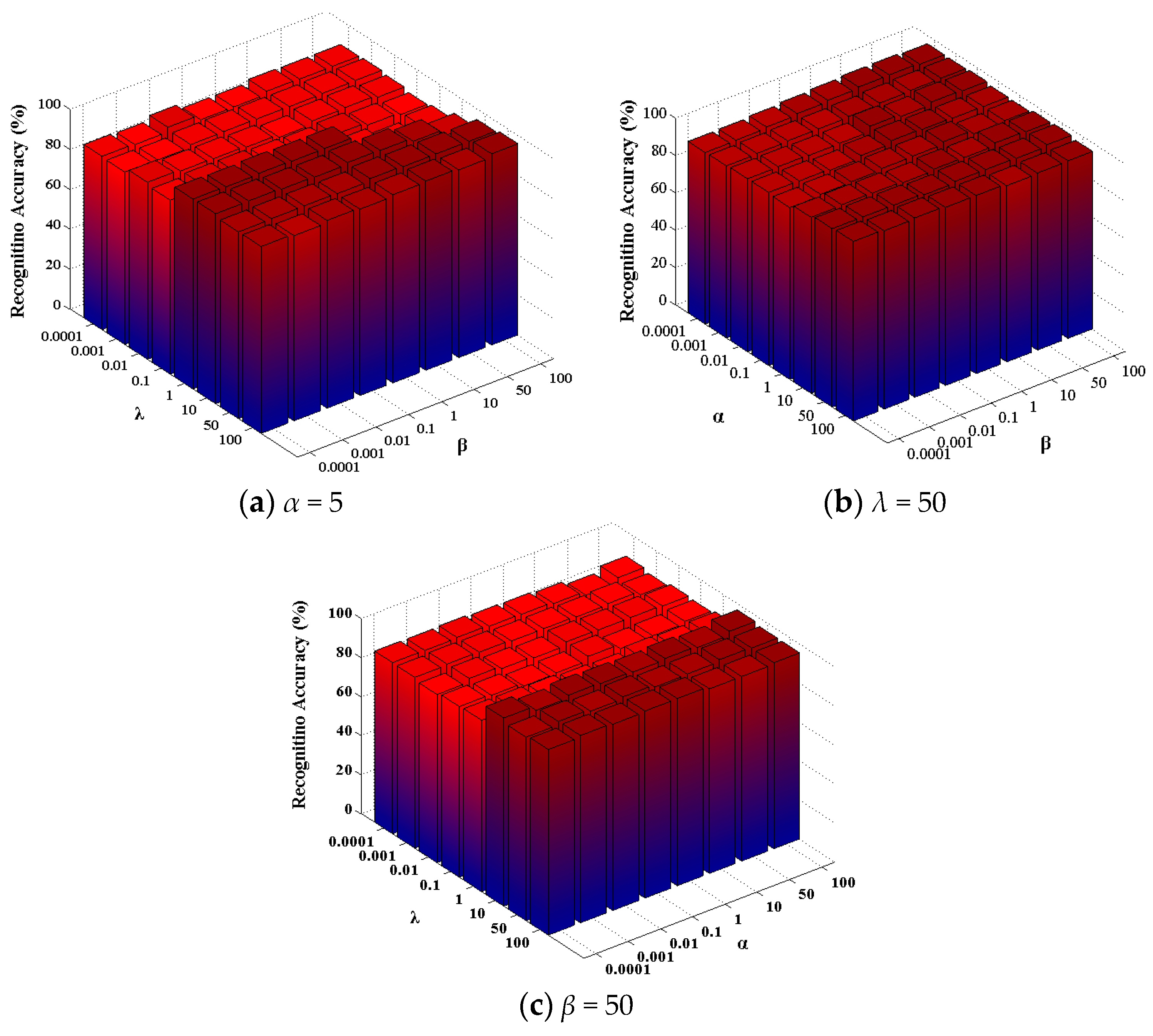
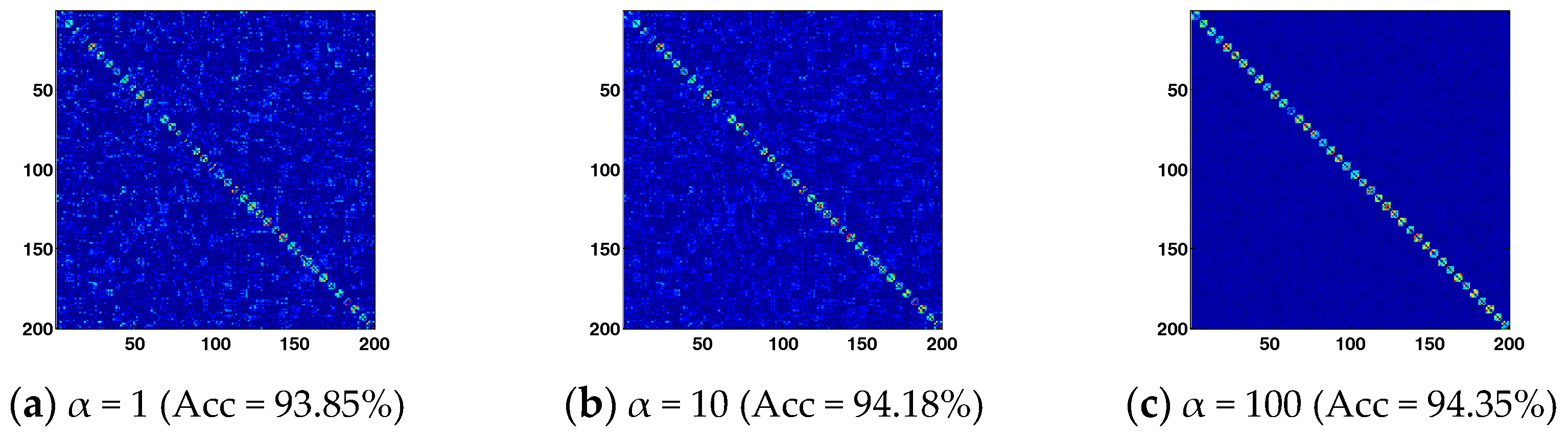
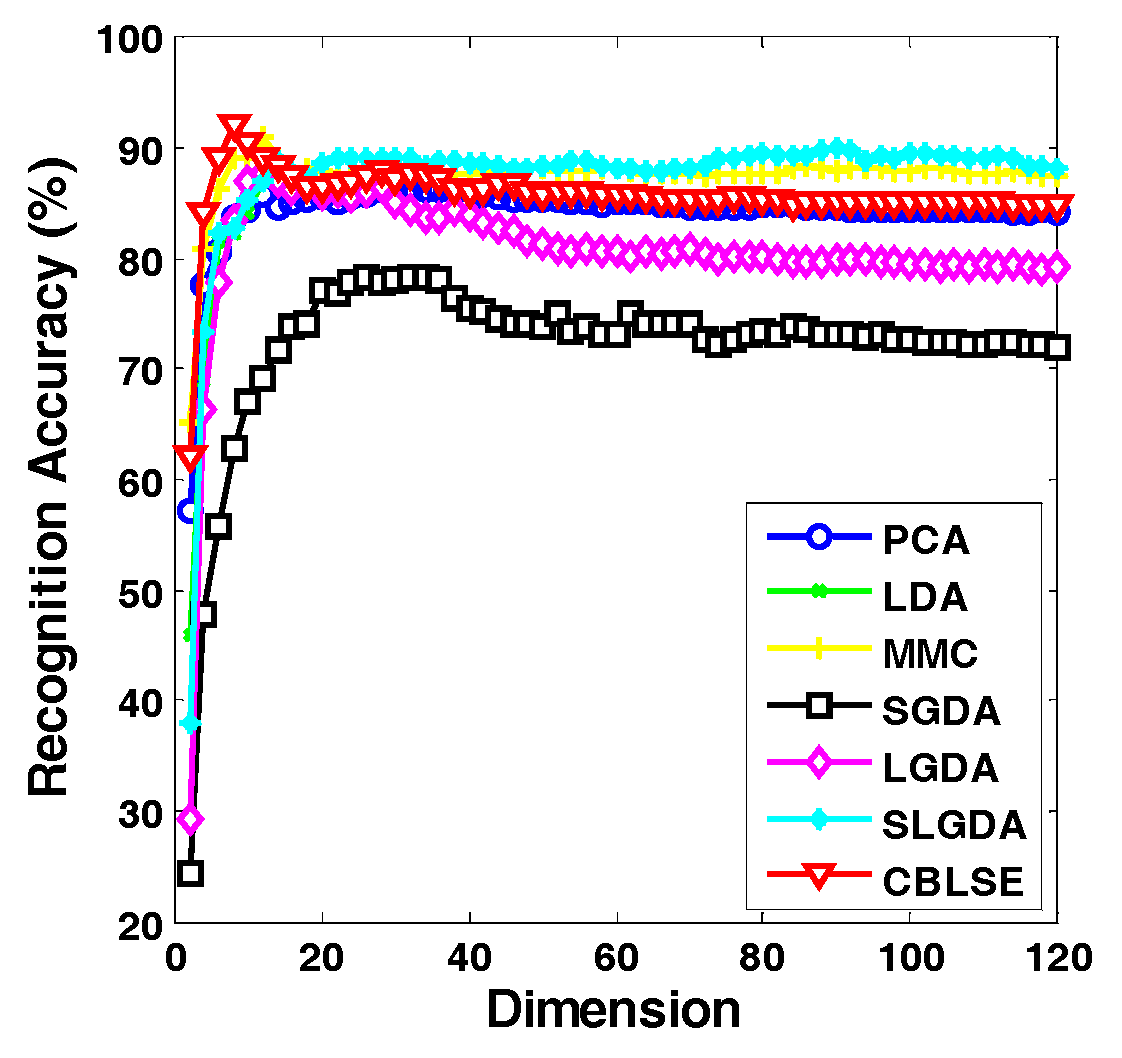
4.1. Analysis of BLSE
4.2. 2-D Visualization Experiment on CMU PIE Dataset
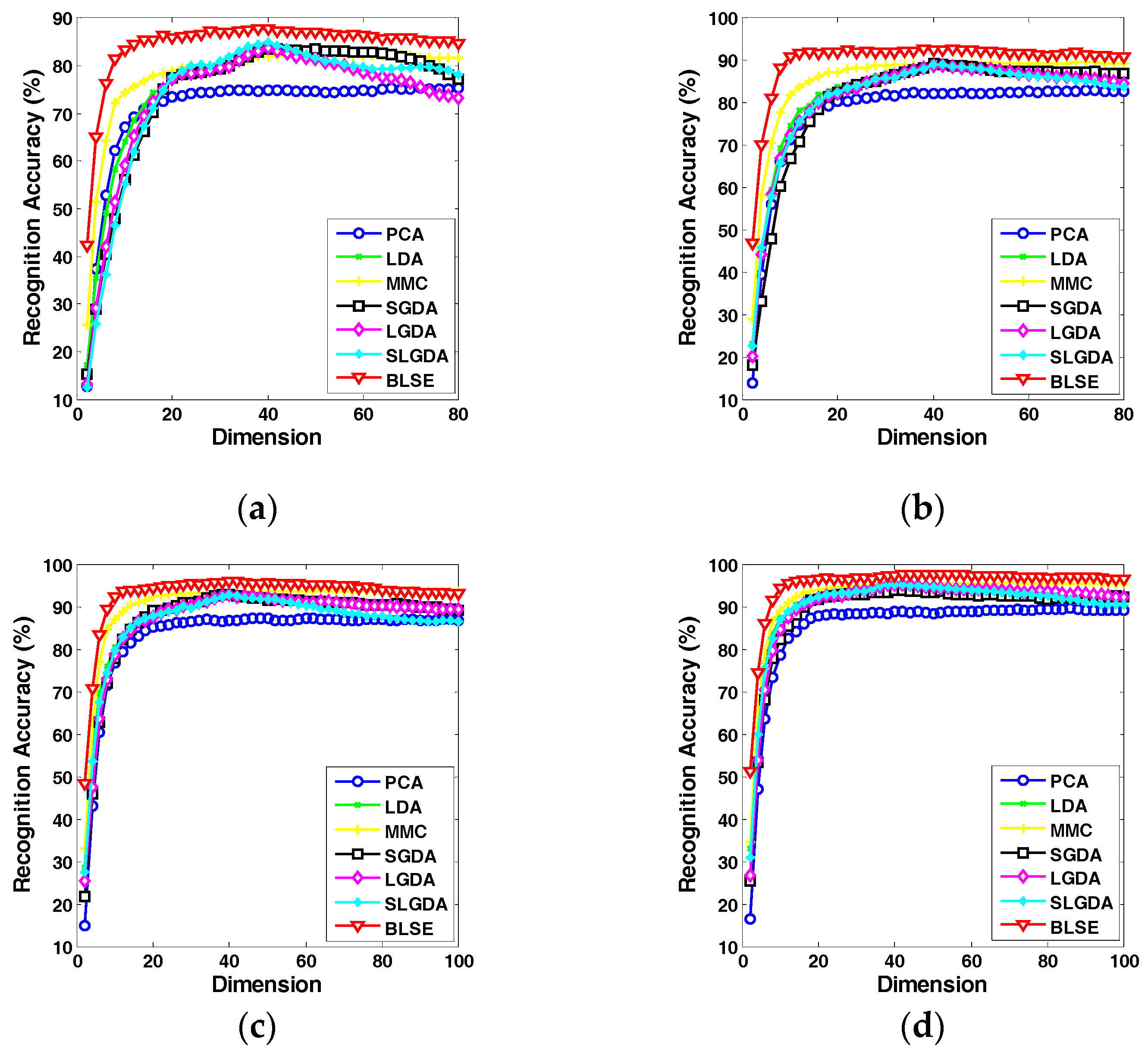
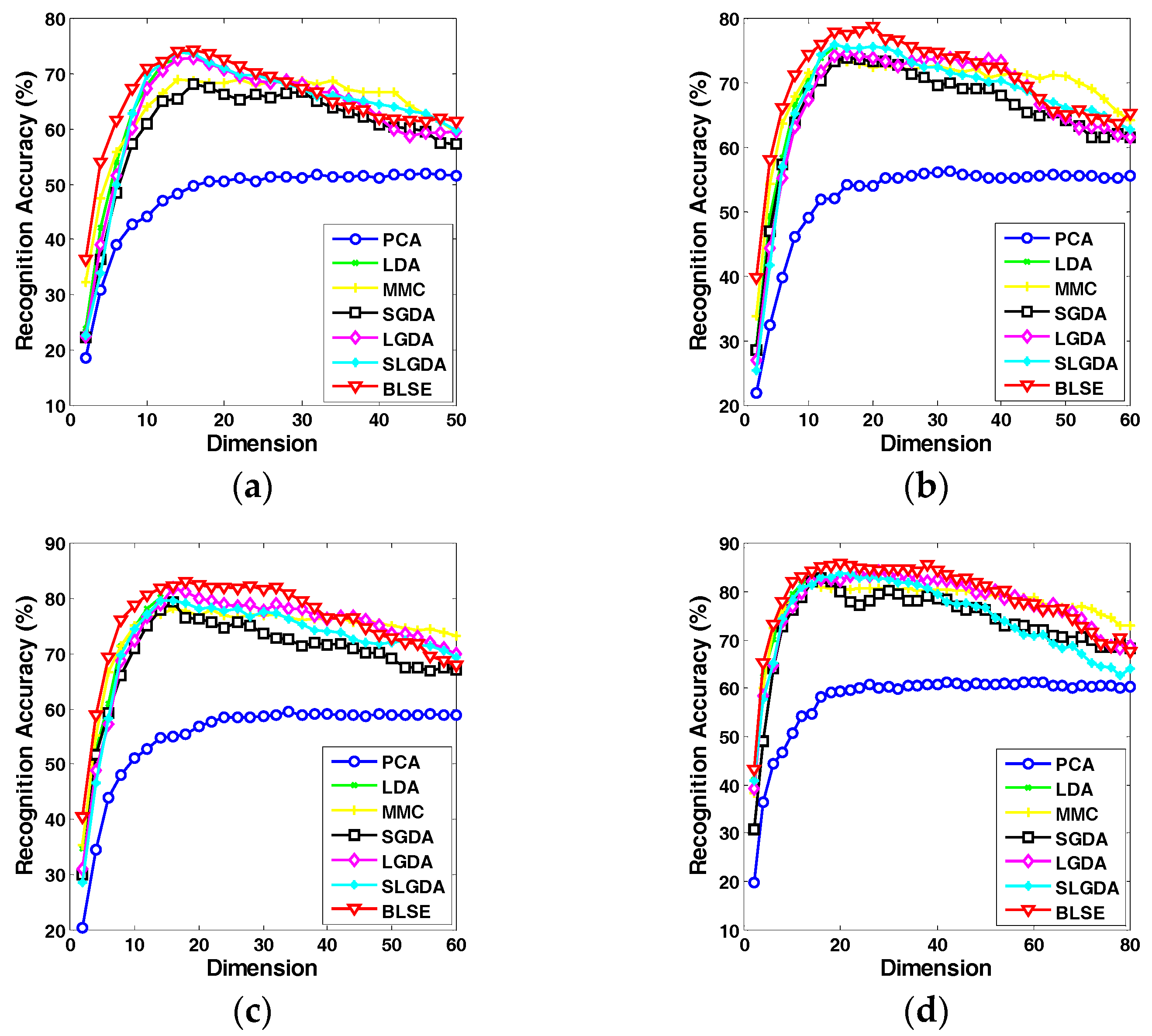
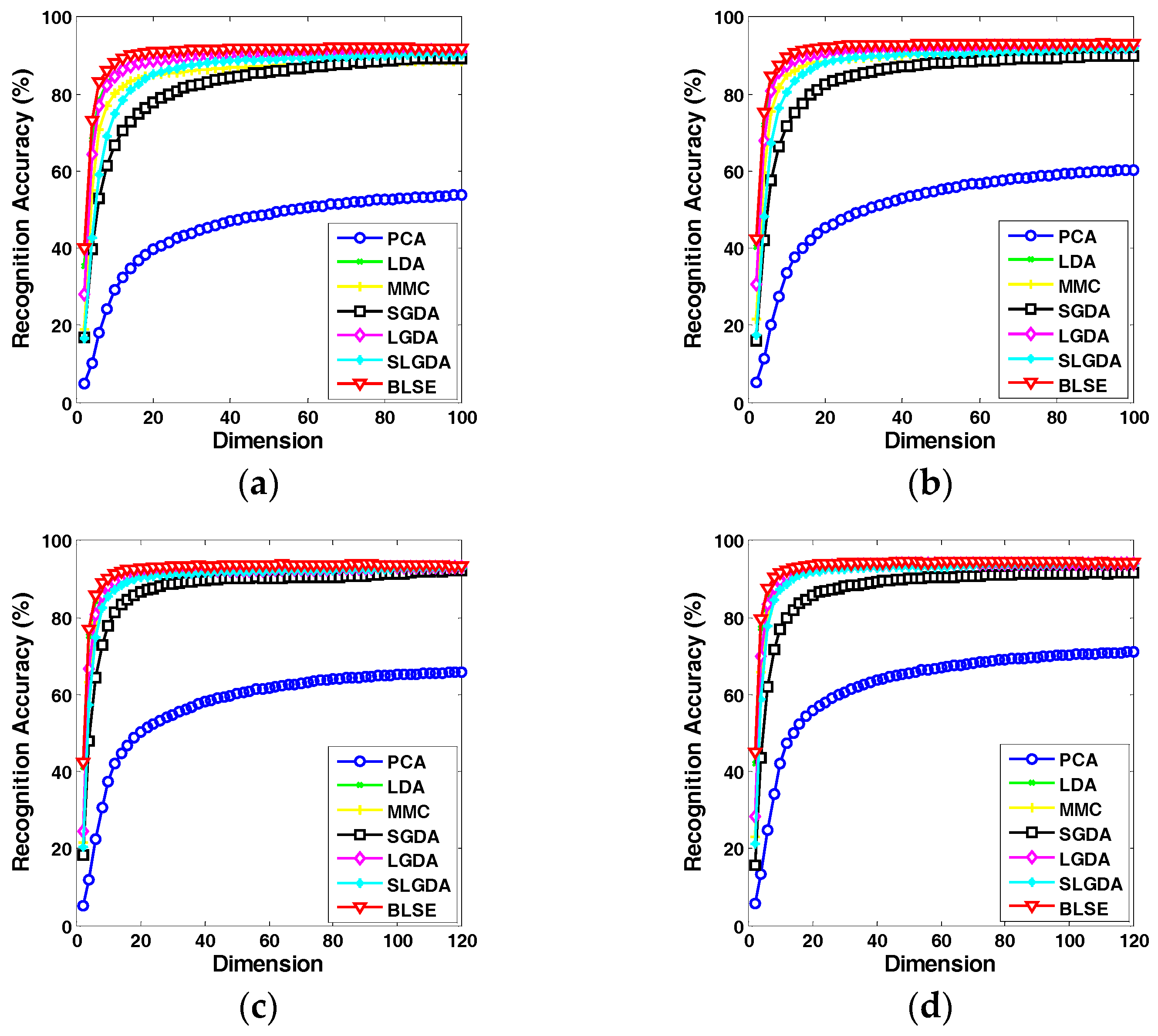
4.3. Experimental Results on Image Datasets
5. Discussion and Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Jain, A.; Duin, R.; Mao, J. Statistical pattern recognition: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 4–37. [Google Scholar] [CrossRef]
- Wang, X.; Zheng, Y.; Zhao, Z.; Wang, J. Bearing fault diagnosis based on statistical locally linear embedding. Sensors 2015, 15, 16225–16247. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Zhang, S. Facial expression recognition based on local binary patterns and kernel discriminant Isomap. Sensors 2011, 11, 9573–9588. [Google Scholar] [CrossRef] [PubMed]
- Jolliffe, I.T. Principal Component Analysis; Springer: New York, NY, USA, 1986. [Google Scholar]
- Webb, A.R.; Copsey, K.D. Introduction to Statistical Pattern Recognition, 3nd ed.; John Wiley & Sons. Ltd.: Hoboken, NJ, USA, 1990. [Google Scholar]
- Li, H.; Jiang, T.; Zhang, K. Efficient and robust feature extraction by maximum margin criterion. IEEE Trans. Neural Netw. 2006, 17, 1157–1165. [Google Scholar] [CrossRef] [PubMed]
- Schölkopf, B.; Smola, A.; Müller, K.R. Nonlinear component analysis as a kernel eigenvalue problem. Neural Comput. 1998, 10, 1299–1319. [Google Scholar] [CrossRef]
- Mika, S.; Ratsch, G.; Weston, J.; Scholkopf, B.; Smola, A.; Muller, K.R. Constructing descriptive and discriminative nonlinear features: Rayleigh coefficients in kernel feature spaces. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 623–628. [Google Scholar] [CrossRef]
- Roweis, S.T.; Saul, L.K. Nonlinear dimension reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [PubMed]
- Tenenbaum, J.B.; De Silva, V.; Langford, J.C. A global geometric framework for nonlinear dimensionality reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef] [PubMed]
- Belkin, M.; Niyogi, P. Laplacian eigenmaps for dimensionality reduction and data representation. Neural Comput. 2003, 15, 1373–1396. [Google Scholar] [CrossRef]
- Yan, S.; Xu, D.; Zhang, B.; Zhang, H.J.; Yang, Q.; Lin, S. Graph embedding and extensions: A general framework for dimensionality reduction. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 40–51. [Google Scholar] [CrossRef] [PubMed]
- Han, Y.; Jin, A.T.B.; Abas, F.S. Neighborhood preserving discriminant embedding in face recognition. J. Visual Commun. Image Represent. 2009, 20, 532–542. [Google Scholar] [CrossRef]
- Huang, H.; Luo, F.; Liu, J.; Yang, Y. Dimensionality reduction of hyperspectral images based on sparse discriminant manifold embedding. ISPRS J. Photogramm. Remote Sens. 2015, 106, 42–54. [Google Scholar] [CrossRef]
- Qiao, L.; Chen, S.; Tan, X. Sparsity preserving projections with applications to face recognition. Pattern Recognit. 2010, 43, 331–341. [Google Scholar] [CrossRef]
- Elhamifar, E.; Vidal, R. Sparse subspace clustering: algorithm, theory, and applications. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2765–2781. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Lin, Z.; Yan, S.; Sun, J.; Yu, Y.; Ma, Y. Robust recovery of subspace structures by low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 171–184. [Google Scholar] [CrossRef] [PubMed]
- Cheng, B.; Yang, J.; Yan, S.; Fu, Y.; Huang, T.S. Learning with l1-graph for image analysis. IEEE Trans. Image Process. 2010, 19, 858–866. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Liu, Q.; Li, P. Blessing of dimensionality: recovering mixture data via dictionary pursuit. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 47–60. [Google Scholar] [CrossRef] [PubMed]
- Lu, C.Y.; Min, H.; Zhao, Z.Q.; Zhu, L.; Huang, D.S.; Yan, S. Robust and efficient subspace segmentation via least squares regression. In Proceedings of the European Conference on Computer Vision (ECCV), Firenze, Italy, 7–13 October 2012. [Google Scholar]
- Zhao, H.; Ding, Z.; Fu, Y. Block-wise constrained sparse graph for face image representation. In Proceedings of the International Conference on Automatic Face and Gesture Recognition, Ljubljana, Slovenia, 4–8 May 2015. [Google Scholar]
- Zhao, H.; Ding, Z.; Fu, Y. Ensemble subspace segmentation under sparse and block-wise constraints. IEEE Trans. Circuits Syst. Video Tech. 2017. [Google Scholar] [CrossRef]
- Tang, K.; Liu, R.; Su, Z.; Zhang, J. Structure-constrained low-rank representation. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 2167–2179. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Jiang, Z.; Davis, L.S. Learning structured low-rank representations for image classification. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (IEEE CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Li, Y.; Liu, J.; Lu, H.; Ma, S. Learning robust face representation with classwise block-diagonal structure. IEEE Trans. Inf. Forensics Secur. 2014, 9, 2051–2062. [Google Scholar] [CrossRef]
- Feng, J.; Lin, Z.; Xu, H.; Yan, S. Robust subspace segmentation with block-diagonal prior. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (IEEE CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Ly, N.H.; Du, Q.; Fowler, J.E. Sparse graph-based discriminant analysis for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3872–3884. [Google Scholar]
- Li, W.; Liu, J.; Du, Q. Sparse and low-rank graph for discriminant analysis of hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4094–4105. [Google Scholar] [CrossRef]
- Zhuang, L.; Gao, H.; Lin, Z.; Ma, Y.; Zhang, X.; Yu, N. Non-negative low rank and sparse graph for semi-supervised learning, In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (IEEE CVPR), Providence, RI, USA, 16–21 June 2012.
- Zhao, M.; Jiao, L.; Feng, J.; Liu, T. A simplified low rank and sparse graph for semi-supervised learning. Neurocomputing 2014, 140, 84–96. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Cai, J.; Chen, J.; Liang, X. Single-sample face recognition based on intra-class differences in a variation model. Sensors 2015, 15, 1071–1087. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Ding, Z.; Fu, Y. Pose-dependent low-rank embedding for head pose estimation. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Zhang, L.; Zhang, D. Robust visual knowledge transfer via extreme learning machine based domain adaptation. IEEE Trans. Image Process. 2016, 25, 4959–4973. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Zhang, D. Evolutionary cost-sensitive extreme learning machine. IEEE Trans. Neural Netw. Learn. Syst. 2017. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Zhang, D. Visual understanding via multi-feature shared learning with global consistency. IEEE Trans. Multimed. 2016, 18, 247–259. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, Y.; Wang, F.; Meng, G.; Salman, W.; Saleem, L. A novel multi-sensor environmental perception method using low-rank representation and a particle filter for vehicle reversing safety. Sensors 2016, 16, 848. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Fang, X.; Wu, J.; Li, X.; Zhang, D. Discriminative transfer subspace learning via low-rank and sparse representation. IEEE Trans. Image Process. 2015, 25, 850–863. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Zuo, W.; Zhang, D. LSDT: Latent sparse domain transfer learning for visual adaptation. IEEE Trans. Image Process. 2016, 25, 1179–1191. [Google Scholar] [CrossRef] [PubMed]
- Guo, T.; Zhang, L.; Tan, X. Neuron pruning-based discriminative extreme learning machine for pattern classification. Cogn. Comput. 2017. [Google Scholar] [CrossRef]
- Lin, Z.; Liu, R.; Su, Z. Linearized alternating direction method with adaptive penalty for low rank representation, In Proceedings of the 2011 Advances in Neural Information Processing Systems (NIPS), Granada, Spain, 12–17 December 2011.
- He, X.; Yan, S.; Hu, Y.; Niyogi, P.; Zhang, H. Face recognition using Laplacian faces. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 328–340. [Google Scholar] [PubMed]
- Sim, T.; Baker, S.; Bsat, M. The CMU pose, illumination and expression database. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1615–1618. [Google Scholar]
- Laurens, V.D.M.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Cai, D.; He, X.; Han, J.; Zhang, H.-J. Orthogonal Laplacian faces for face recognition. IEEE Trans. Image Process. 2006, 15, 3608–3614. [Google Scholar] [CrossRef] [PubMed]
- Cai, D.; He, X.; Han, J.; Huang, T. Graph regularized nonnegative matrix factorization for data representation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1548–1560. [Google Scholar] [PubMed]
- Miao, S.; Wang, J.; Gao, Q.; Chen, F.; Wang, Y. Discriminant structure embedding for image recognition. Neurocomputing 2016, 174, 850–857. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | t | Compared Methods | Ours | |||||
|---|---|---|---|---|---|---|---|---|
| PCA | LDA | MMC | SGDA | LGDA | SLGDA | BLSE | ||
| ORL | 3 | 75.32 ± 2.58 (80) | 83.63 ± 2.38 (38) | 82.39 ± 2.73 (56) | 83.61 ± 2.72 (40) | 83.79 ± 2.15 (40) | 84.96 ± 1.78 (40) | 87.68 ± 2.36 (38) |
| 4 | 82.92 ± 1.79 (72) | 88.71 ± 2.26 (38) | 89.58 ± 2.44 (72) | 89.42 ± 2.08 (40) | 88.83 ± 2.36 (40) | 89.08 ± 2.63 (40) | 92.63 ± 2.28 (40) | |
| 5 | 87.45 ± 1.70 (48) | 93.15 ± 1.13 (38) | 93.95 ± 1.55 (64) | 93.10 ± 1.94 (40) | 93.00 ± 0.91 (40) | 92.95 ± 1.41 (40) | 96.05 ± 0.96 (42) | |
| 6 | 89.75 ± 1.65 (86) | 95.75 ± 1.31 (38) | 95.81 ± 1.22 (70) | 94.06 ± 1.48 (40) | 95.50 ± 1.09 (40) | 95.44 ± 1.22 (40) | 97.88 ± 0.67 (44) | |
| Yale | 4 | 52.00 ± 2.34 (46) | 72.76 ± 2.30 (14) | 69.05 ± 3.51 (14) | 68.29 ± 3.81 (16) | 72.86 ± 2.16 (16) | 73.90 ± 2.92 (14) | 74.38 ± 2.48 (16) |
| 5 | 56.33 ± 5.57 (32) | 75.67 ± 2.31 (14) | 73.44 ± 4.52 (14) | 74.00 ± 3.52 (16) | 74.56 ± 3.33 (16) | 76.11 ± 2.83 (14) | 78.89 ± 3.10 (20) | |
| 6 | 59.60 ± 5.76 (34) | 80.27 ± 3.81 (14) | 78.13 ± 5.56 (16) | 79.47 ± 3.51 (16) | 81.87 ± 3.51 (16) | 79.60 ± 5.34 (14) | 83.20 ± 4.71 (18) | |
| 7 | 61.33 ± 5.02 (42) | 83.00 ± 2.70 (14) | 81.67 ± 4.30 (14) | 82.83 ± 3.34 (16) | 84.17 ± 4.10 (28) | 83.83 ± 4.45 (22) | 85.83 ± 3.17 (20) | |
| CMU PIE | 4 | 53.72 ± 1.28 (100) | 91.14 ± 1.25 (64) | 88.61 ± 1.50 (96) | 89.44 ± 1.35 (100) | 91.33 ± 0.81 (86) | 90.40 ± 1.03 (94) | 92.28 ± 1.07 (80) |
| 5 | 60.31 ± 1.78 (100) | 92.60 ± 0.83 (66) | 91.27 ± 0.85 (98) | 89.95 ± 1.84 (98) | 92.60 ± 0.83 (66) | 91.82 ± 0.99 (100) | 93.26 ± 1.03 (92) | |
| 6 | 65.88 ± 1.92 (120) | 93.56 ± 0.88 (66) | 93.17 ± 1.03 (106) | 92.15 ± 0.95 (112) | 93.24 ± 1.04 (104) | 92.84 ± 0.92 (118) | 93.93 ± 1.01 (92) | |
| 7 | 71.12 ± 1.61 (120) | 94.34 ± 0.83 (66) | 94.09 ± 0.66 (110) | 93.54 ± 0.58 (120) | 94.09 ± 0.72 (104) | 93.88 ± 0.59 (102) | 94.64 ± 0.59 (70) | |
| COIL20 | 36 | 86.39 (28) | 88.75 (14) | 90.97 (12) | 78.33 (26) | 87.78 (12) | 90.00 (90) | 92.22 (8) |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, T.; Tan, X.; Zhang, L.; Xie, C.; Deng, L. Block-Diagonal Constrained Low-Rank and Sparse Graph for Discriminant Analysis of Image Data. Sensors 2017, 17, 1475. https://doi.org/10.3390/s17071475
Guo T, Tan X, Zhang L, Xie C, Deng L. Block-Diagonal Constrained Low-Rank and Sparse Graph for Discriminant Analysis of Image Data. Sensors. 2017; 17(7):1475. https://doi.org/10.3390/s17071475
Chicago/Turabian StyleGuo, Tan, Xiaoheng Tan, Lei Zhang, Chaochen Xie, and Lu Deng. 2017. "Block-Diagonal Constrained Low-Rank and Sparse Graph for Discriminant Analysis of Image Data" Sensors 17, no. 7: 1475. https://doi.org/10.3390/s17071475
APA StyleGuo, T., Tan, X., Zhang, L., Xie, C., & Deng, L. (2017). Block-Diagonal Constrained Low-Rank and Sparse Graph for Discriminant Analysis of Image Data. Sensors, 17(7), 1475. https://doi.org/10.3390/s17071475