
Low-Latency and Energy-Efficient Data Preservation Mechanism in Low-Duty-Cycle Sensor Networks

{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
2.1. Feature Projection Based Mechanisms
2.2. Network Coding Based Mechanisms
2.2.1. Random Linear Codes Based Mechanisms
2.2.2. Fountain Codes Based Mechanisms
3. System Model and Problem Statement
3.1. System Model
- (1)
- Data production phase. In this phase, all of the nodes monitor the field, and k ≤ n nodes sensed the data, i.e., there are k source nodes and k source data. The source nodes will disseminate a short message that contains its ID to the network to let other nodes know of its existence. After all source nodes disseminate their short messages, all of the nodes in the network know the number k of source nodes (or source data).
- (2)
- Data dissemination and storage phase. In this phase, the k source nodes will disseminate their data to the network for storage. Since each node can only store one piece of data, the node will encode the data received before storing it.
- (3)
- Data collection phase. In this phase, the nodes wait for the coming of the mobile sink. Some nodes may die due to being broken by outer force. A mobile sink can enter the network from any place in the network and at any time in this phase. It should visit some survival nodes to collect their encoded data. The collected encoded data is expected to recover all of the source data. On the other hand, if a node senses new data, it can continue to disseminate its data to the network for storage. However, since this dissemination cannot be guaranteed to be completed before the coming of the sink, these data cannot be guaranteed to be recovered. The problem of how to store the new data or update the old data is outside the scope of our research, so we will research it in the future and not discuss it in this paper.
3.2. Problem Statement
4. Algorithm Description
4.1. Basic Idea
4.2. Data Dissemination Mechanism
| Algorithm 1. Function Transmission (packet(vj)) |
|
1 if (packet(vj) is the first time received by vi) 2 temp = rand(1); 3 If (temp ≤ pi) or (vi == vj) 4 T(vi) = N(vi); // N(vi) is the set of vi’s neighbours 5 While T(vi)! = {} 6 Wake up for one time slot when a node vk in T(vi) wakes up; 7 Send the message packet(vj) to vk; 8 If receives a message ACK(vk) from vk 9 Remove vk from T(vi); 10 End 11 End 12 End 13 End |
4.3. Data Storage Algorithm
4.3.1. LT Codes
4.3.2. Algorithm Description
| Algorithm 2. Data Storage Algorithm Ran on Each Node vi: |
| 1 Upon vi generates a source data xi: 2 yi = xi; 3 Put xi into a message packet(vi); // the message packet(vi) is generated by vi, and vi takes the message as a new message that is received by it for the first time. 4 Transmission(packet(vi)); 5 6 Upon vi receives a message packet(vj) that contains a data xj: 7 If packet(vj) is received by vi for the first time 8 temp = rand(1); 9 If (temp ≤ di/k) 10 yi = yi XOR xj; 11 End 12 Transmission(packet(vj)); 13 End |
4.4. Performance Analyses
4.4.1. Time Complexity
4.4.2. Energy Consumption
4.4.3. Latency of Data Dissemination
4.4.4. Decoding Performance in a Small-Scale Network
5. Simulations
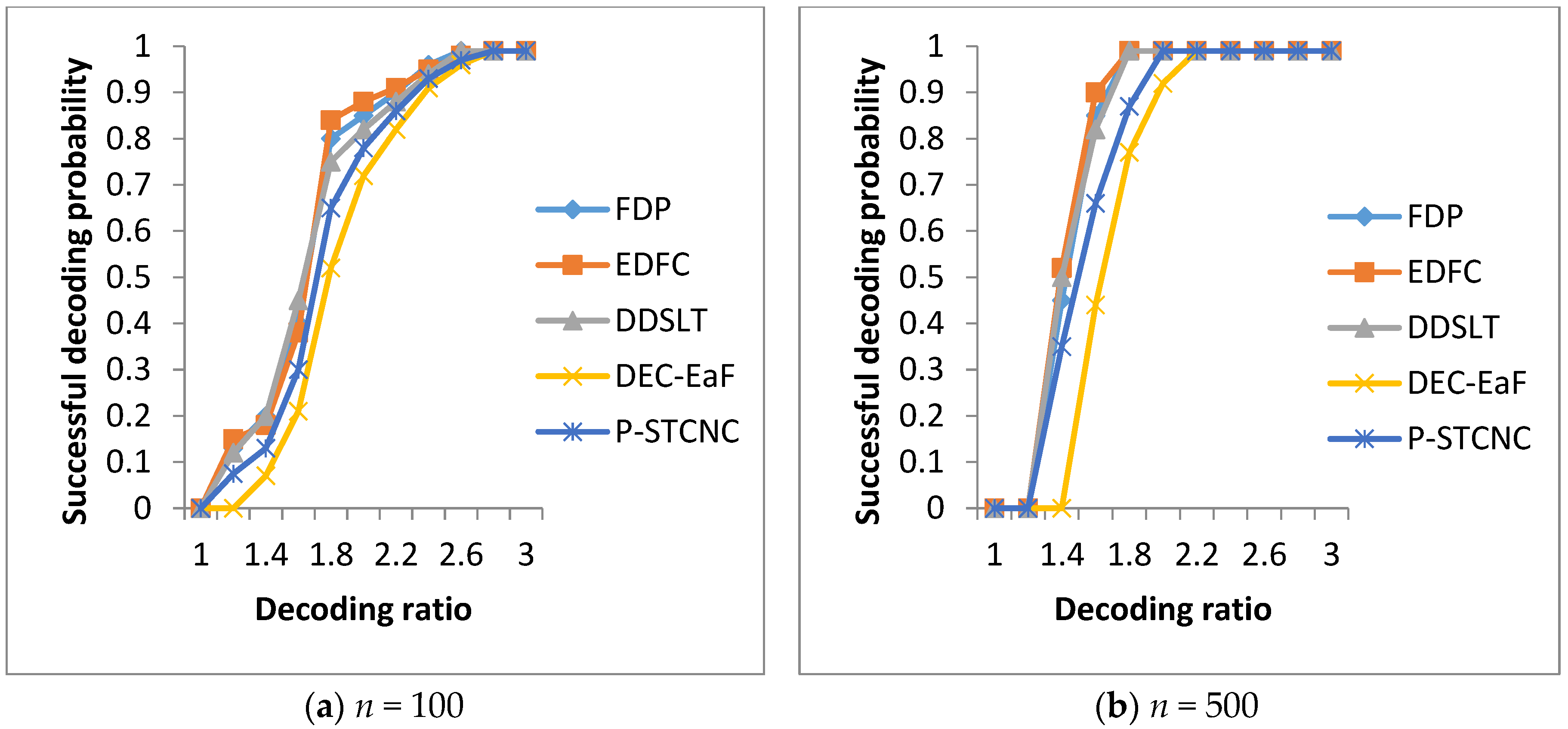
5.1. Comparison of Decoding Performance
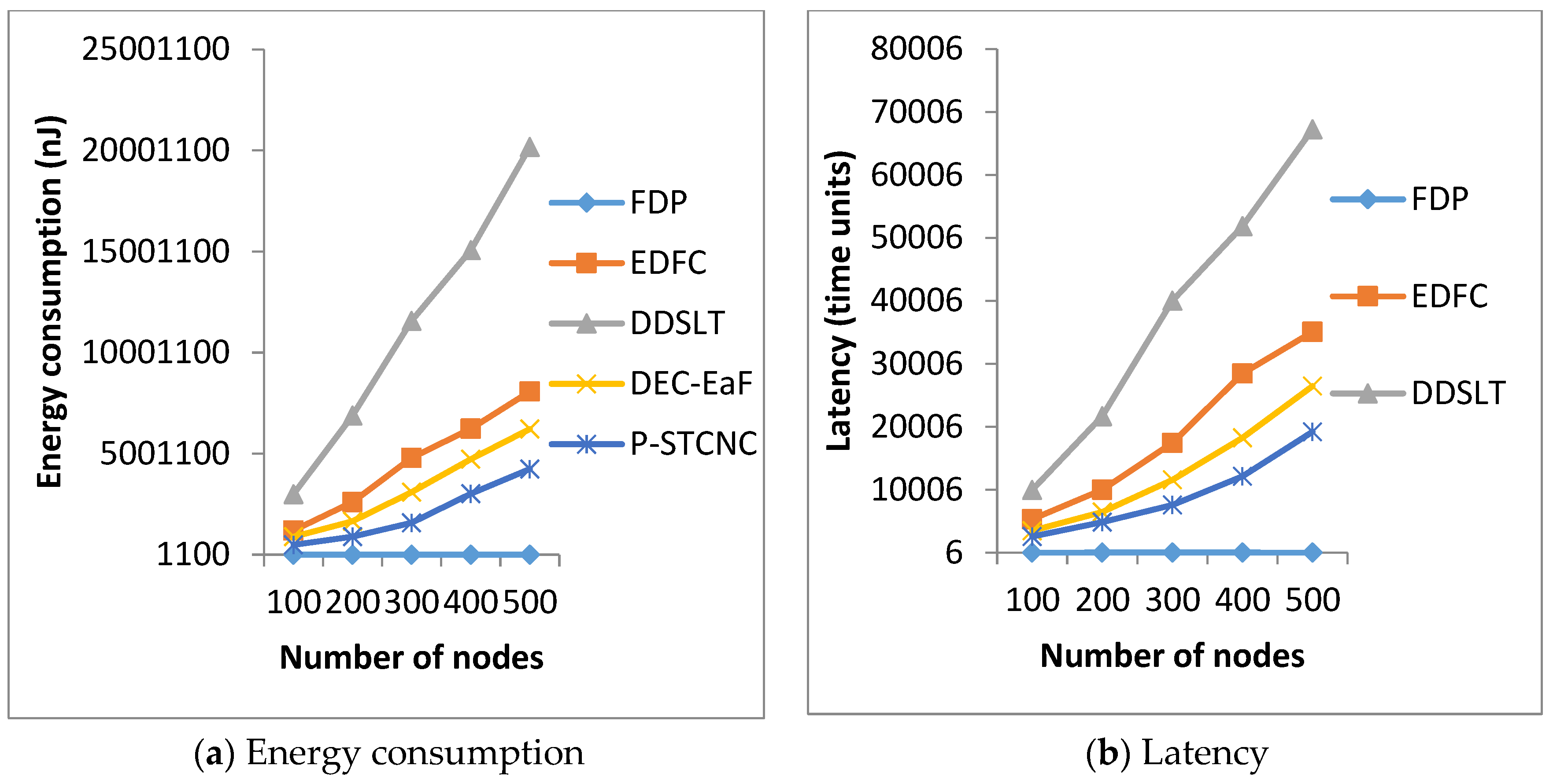
5.2. Comparison of Energy Consumption and Latency
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Kim, T.; Min, H.; Jung, J. A Mobility-Aware Adaptive Duty Cycling Mechanism for Tracking Objects during Tunnel Excavation. Sensors 2017, 17, 435–450. [Google Scholar] [CrossRef] [PubMed]
- Gu, Y.; He, T. Dynamic Switching-Based Data Forwarding for Low-Duty-Cycle Wireless Sensor Networks. IEEE Trans. Mob. Comput. 2011, 10, 1741–1754. [Google Scholar] [CrossRef]
- Liu, F.; Lin, M.; Hu, Y.; Luo, C.; Wu, F. Design and Analysis of Compressive Data Persistence in Large-Scale Wireless Sensor Networks. IEEE Trans. Parallel Distrib. Syst. 2015, 26, 2685–2698. [Google Scholar] [CrossRef]
- Li, K. Performance analysis and evaluation of random walk algorithms on wireless networks. In Proceedings of the 2010 IEEE International Symposium on Parallel & Distributed Processing (IPDPS), Atlanta, GA, USA, 19–23 April 2010; pp. 1–8. [Google Scholar]
- Li, L.; Garcia-Frias, J. Hybrid analog-digital coding scheme based on parallel concatenation of linear random projections and LDGM codes. In Proceedings of the 2014 48th Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 19–21 March 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Yang, X.; Tao, X.; Dutkiewicz, E.; Huang, X.; Jay Guo, Y.; Cui, Q. Energy—Efficient Distributed Data Storage for Wireless Sensor Networks Based on Compressed Sensing and Network Coding. IEEE Trans. Wirel. Commun. 2013, 12, 5087–5099. [Google Scholar] [CrossRef]
- Gong, B.; Cheng, P.; Chen, Z.; Liu, N.; Gui, L.; de Hoog, F. Spatiotemporal Compressive Network Coding for Energy-Efficient Distributed Data Storage in Wireless Sensor Networks. IEEE Commum. Lett. 2015, 19, 803–806. [Google Scholar] [CrossRef]
- Wang, C.; Cheng, P.; Chen, Z.; Liu, N.; Gui, L. Practical Spatiotemporal Compressive Network Coding for Energy-Efficient Distributed Data Storage in Wireless Sensor Networks. In Proceedings of the 2015 IEEE 81st Vehicular Technology Conference (VTC Spring), Glasgow, UK, 11–14 May 2015; pp. 1–6. [Google Scholar]
- Kaufman, T.; Sudan, M. Sparse Random Linear Codes are Locally Decodable and Testable. In Proceedings of the 48th Annual IEEE Symposium on Foundations of Computer Science (FOCS), Providence, RI, USA, 20–23 October 2007; pp. 590–600. [Google Scholar] [CrossRef]
- James, A.; Madhukumar, A.S.; Kurniawan, E.; Adachi, F. Performance Analysis of Fountain Codes in Multihop Relay Networks. IEEE Trans. Veh. Technol. 2013, 62, 4379–4391. [Google Scholar] [CrossRef]
- Lin, Y.; Li, B.; Liang, B. Differentiated Data Persistence with Priority Random Linear Codes. In Proceedings of the 27th International Conference on Distributed Computing Systems (ICDCS), Toronto, ON, Canada, 25–29 June 2007; pp. 47–55. [Google Scholar]
- Stefanovic, C.; Vukobratovic, D.; Crnojevic, V.; Stankovic, V. A random linear coding scheme with perimeter data gathering for wireless sensor networks. In Proceedings of the 2011 Eighth International Conference on Wireless On-Demand Network Systems and Services (WONS 2011), Bardonecchia, Italy, 26–28 January 2011; pp. 142–145. [Google Scholar] [CrossRef]
- Al-Awami, L.; Hassanein, H. Energy efficient data survivability for WSNs via Decentralized Erasure Codes. In Proceedings of the 2012 IEEE 37th Conference on Local Computer Networks (LCN), Clearwater, FL, USA, 22–25 October 2012; pp. 577–584. [Google Scholar] [CrossRef]
- Tian, J.; Yan, T.; Wang, G. A Network Coding Based Energy Efficient Data Backup in Survivability- Heterogeneous Sensor Networks. IEEE Trans. Mob. Comput. 2015, 14, 1992–2006. [Google Scholar] [CrossRef]
- Lin, Y.; Liang, B.; Li, B. Data Persistence in Large-Scale Sensor Networks with Decentralized Fountain Codes. In Proceedings of the 26th IEEE International Conference on Computer Communications (INFOCOM), Anchorage, AK, USA, 6–12 May 2007; pp. 1658–1666. [Google Scholar]
- Xu, M.; Song, W.; Heo, D.; Kim, J.; Kim, B. ECPC: Preserve Downtime Data Persistence in Disruptive Sensor Networks. In Proceedings of the 2013 IEEE 10th International Conference on Mobile Ad-Hoc and Sensor Systems (MASS), Beijing, China, 24–26 September 2013; pp. 281–289. [Google Scholar]
- Ye, X.; Li, J.; Chen, W.; Tang, F. LT codes based distributed coding for efficient distributed storage in Wireless Sensor Networks. In Proceedings of the 2015 IFIP Networking Conference (IFIP Networking), Toulouse, France, 20–22 May 2015; pp. 1–9. [Google Scholar]
- Jafarizadeh, S.; Jamalipour, A. Data Persistency in Wireless Sensor Networks Using Distributed Luby Transform Codes. IEEE Sens. J. 2013, 13, 4880–4890. [Google Scholar] [CrossRef]
- Liang, J.; Wang, J.; Zhang, X.; Chen, J. An Adaptive Probability Broadcast-based Data Preservation Protocol in Wireless Sensor Networks. In Proceedings of the 2011 IEEE International Conference on Communications (ICC), Kyoto, Japan, 5–9 June 2011; pp. 523–528. [Google Scholar]
- Cardoso, J.S.; Baquero, C.; Almeida, P.S. Probabilistic Estimation of Network Size and Diameter. In Proceedings of the Fourth Latin-American Symposium on Dependable Computing (LADC), Joao Pessoa, Brazil, 1–4 September 2009; pp. 33–40. [Google Scholar]
- Haas, Z.; Halpern, J.; Li, L. Gossip-based ad hoc routing. IEEE/ACM Trans. Netw. 2006, 14, 479–491. [Google Scholar] [CrossRef]
- Vakulya, G.; Simony, G. Energy efficient percolation-driven flood routing for large-scale sensor networks. In Proceedings of the International Multi-Conference on Computer Science and Information Technology (IMCSIT), Wisla, Poland, 20–22 October 2008; pp. 877–883. [Google Scholar]
- Zhu, J.; Papavassiliou, S. On the connectivity modeling and the tradeoffs between reliability and energy efficiency in large scale wireless sensor networks. In Proceedings of the 2003 IEEE Wireless Communications and Networking (WCNC), New Orleans, LA, USA, 16–20 March 2003; pp. 1260–1265. [Google Scholar] [CrossRef]
- Chung, F.; Lu, L. The Average Distance in a Random Graph with Given Expected Degrees. Internet Math. 2003, 1, 91–114. [Google Scholar] [CrossRef]
- Luby, M. LT codes. In Proceedings of the 43rd Annual IEEE Symposium on Foundations of Computer Science (FOCS), Vancouver, BC, Canada, 16–19 November 2002; pp. 271–280. [Google Scholar]
- Subramanian, S.; Shakkottai, S.; Arapostathis, A. Broadcasting in sensor networks: The role of Local Information. IEEE/ACM Trans. Netw. 2008, 16, 1133–1146. [Google Scholar] [CrossRef]
- Feng, D.; Xiao, M.; Liu, Y.; Song, H.; Yang, Z.; Hu, Z. Finite-sensor fault-diagnosis simulation study of gas turbine engine using information entropy and deep belief networks. Front. Inf. Technol. Electron. Eng. 2016, 17, 1287–1304. [Google Scholar] [CrossRef]
- Huang, T.; Teng, Y.; Liu, M.; Liu, J. Capacity analysis for cognitive heterogeneous networks with ideal/non-ideal sensing. Front. Inf. Technol. Electron. Eng. 2015, 16, 1–11. [Google Scholar]
- Liang, J.; Cao, J.; Liu, R.; Li, T. Distributed Intelligent MEMS: A Survey and a Real-time Programming Framework. ACM Comput. Surv. 2016, 49, 1–29. [Google Scholar] [CrossRef]


© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, C.; Li, T.-S.; Liang, J.-B.; Wu, H. Low-Latency and Energy-Efficient Data Preservation Mechanism in Low-Duty-Cycle Sensor Networks. Sensors 2017, 17, 1051. https://doi.org/10.3390/s17051051
Jiang C, Li T-S, Liang J-B, Wu H. Low-Latency and Energy-Efficient Data Preservation Mechanism in Low-Duty-Cycle Sensor Networks. Sensors. 2017; 17(5):1051. https://doi.org/10.3390/s17051051
Chicago/Turabian StyleJiang, Chan, Tao-Shen Li, Jun-Bin Liang, and Heng Wu. 2017. "Low-Latency and Energy-Efficient Data Preservation Mechanism in Low-Duty-Cycle Sensor Networks" Sensors 17, no. 5: 1051. https://doi.org/10.3390/s17051051
APA StyleJiang, C., Li, T. -S., Liang, J. -B., & Wu, H. (2017). Low-Latency and Energy-Efficient Data Preservation Mechanism in Low-Duty-Cycle Sensor Networks. Sensors, 17(5), 1051. https://doi.org/10.3390/s17051051