1. Introduction
Most organizations collect relevant customer data to improve service quality. The excessive amount of collected data often contains information on customer demographics, finances, interests, activities, and medical status. Research has shown that access to this data can aid organizations in many ways. For instance, it allows them to provide customer analyses, achieve strategic goals, create effective marketing strategies, and improve overall business performance. However, organizations are not willing to publish person-specific data because personally identifiable information (PII) often leads to unique individual identification. A survey [
1] reported that:
About of the population in the United States is likely to be identified based only on 5-digit zip code, gender, date of birth. About of the U.S. population are likely to be uniquely identified by only place, gender, date of birth. Moreover, even at the county level, county, gender, date of birth are likely to identify about of the U.S. population.
User PII such as age, gender, place, zip code, and race are called quasi-identifiers (QIs). Each QI affects user privacy differently, and some QIs, like zip codes and places, are highly identity vulnerable. QIs with high identity vulnerability enable easier unique identification. The presence of identity-vulnerable QIs in published data increases privacy risks for sensitive attributes (SAs) such as diseases or salary information disclosure. Therefore, it is necessary to anonymize user data in a fine-grained manner before publishing it, and in many cases, this is achieved by employing anonymization. This is a practical approach to achieve privacy-preserving data publishing (PPDP) [
2]. The strategy mainly uses generalization and suppression techniques to anonymize the person-specific data.
Mostly the existing anonymization schemes do not provide thorough insights into privacy, particularly regarding the identity vulnerability of QIs and the diversity of SA-based adaptive data generalization. Current privacy schemes mainly focus on hiding individual QIs in the crowd of other users and treat all QIs equally from an identity revelation point of view. However, in many real-world cases, each QI reveals identity differently (e.g., a zip code represents a local region more accurately than a country or place). Therefore, it is mandatory to consider the identity vulnerability of each QI and the diversity of SAs to effectively protect user privacy. Recently, information surges and advances in machine learning tools have created unexpected privacy concerns. These tools are very good at finding the private information of individuals from large datasets using relevant QIs with high probabilities [
3,
4,
5], which cannot be eliminated by applying the privacy models discussed so far. The power of machine learning tools is increasing aggressively, and it is expected to double in the next few years [
6]. Therefore, considering the limitations of the existing work, and the continually growing power of machine learning tools, PPDP has received global attention over the past few decades. There is an emerging need to develop methods that use the capabilities of these tools to protect user privacy.
Generally, there are two settings for privacy preserving data publishing: interactive and non-interactive. In non-interactive settings, the data owner (e.g., hospitals, insurance companies and/or service providers), a trusted party, publishes the complete dataset in perturbed form after applying some operation to original data and removing directly identifiable information (e.g., name). However, in interactive settings the data owner, a trusted party, does not publish the whole dataset in perturbed form like in the non-interactive setting. It provides an interface to the users through which they may pose different queries about the data and get (possibly noisy) answers. Each of the privacy settings introduces various privacy concerns pertaining to the users sensitive and demographics data in question. Hence, one approach cannot replace the other, and they each have a place alongside the other.
Differential privacy (DP) [
7] has emerged as a state-of-the-art method and one of the most promising privacy models for releasing person-specific data in interactive settings. DP offers strong privacy guarantees and it has been developed in the sequence of papers [
8,
9,
10,
11]. It provides the desired level of privacy and based on the fact that presence or absence of any individuals in the database does not significantly influence the results of the analyses on the dataset. However, enforcement of these strict guarantees in real-world applications may not fulfill either strong privacy guarantees or desired data utility requirements. The users can execute different statistical queries and can get the noisy and aggregate answers from the differentially private systems. Currently, various approaches have been proposed to extend the DP concept for data mining. In this regard, a comprehensive study was given by the authors of [
12], and they verified the fact that DP is typically applicable for privacy preserving data mining. The authors of [
13] study, discuss, and formalize an alternative to the standard DP model as individual differential privacy model that introduces less amount of noise to the query results for improving utility/accuracy. Sarathy et al. [
14] reported a method for adding noise in response to user queries to protect privacy. After the query function is computed from the original data set, Laplace-distributed random noise is added to the query result. Generally, the magnitude of the noise depends on the sensitivity of the query function and desired privacy budget for that specific query. The authors concluded that noise variance should vary with the subsequent queries to deliver promised level of privacy at the expense of utility. There are many differentially private systems, such as privacy-integrated queries (PINQ) [
15], Airavat [
16] and Gupt [
17]. These systems maintain each query budget and mediate accesses to the underlying data in a differentially-private manner. These systems maintain various levels of privacy for different user’s applications while ensuring the desired level of privacy and utility.
In this work, we focus on the non-interactive setting of person-specific data publishing, and extend the
k-anonymity [
18] concept and its ramifications as a very popular privacy model within the research community. The
k-anonymity [
18] is a well-known PPDP technique that protects user privacy by introducing
k-users with the same QIs in each equivalence class. Thus, the probability of re-identifying someone in anonymized data becomes at least
. This helps to protect against a linking attack with external data sources by ensuring
k or more identical tuples in each equivalence class. However, user privacy is not guaranteed when an adversary has strong background knowledge or when the SAs in an equivalence class are not diverse. Many attempts have been made to enhance the protection level of
k-anonymity. Three different PPDP models—
ℓ-diversity [
19], (
)-anonymity [
20], and
t-closeness [
21]—have been proposed to address
k-anonymity limitations. They impose more protective requirements, consider diversity, and ensure the equal proportion of SAs in each class to overcome private information disclosure. However, creating a feasible
ℓ-diverse dataset is very challenging when the data is highly imbalanced (e.g., if the SA distribution is uneven). In such datasets, maintaining user privacy through
ℓ-diversity or
t-closeness is not possible in practice, and the current schemes do not guarantee individual privacy. To overcome the aforementioned limitations, this study proposes a new anonymization scheme that reduces the privacy risks while improving the anonymous data utility in person-specific data publishing. When the data is anonymized, data generalization is performed adaptively based on the identity vulnerability of the QIs as well as the diversity of SAs in each class.
The remainder of this paper is organized as follows:
Section 2 explains the background and related work regarding well-known PPDP models.
Section 3 presents the conceptual overview of proposed anonymization scheme and outlines its principal steps.
Section 4 provides a brief overview about determining the identity vulnerability of the QIs using random forest, and
Section 5 describes the adaptive generalization algorithm.
Section 6 discusses the simulation and results. Finally, conclusions are offered in
Section 7.
2. Background and Related Work
Privacy protection has remained a concern for researchers and experts because recent advances in information technology have threatened user privacy. Information surges have made the retrieval of QIs along with the SAs of individuals a part of day-to-day life. PPDP provides promising methods for publishing useful information while preserving data privacy [
22]. In PPDP, explicit identifiers (e.g., name) are removed, and QIs are generalized or suppressed to protect the SAs of individuals from disclosure. Researchers require sensitive attributes, so they are mostly retained unchanged. In many circumstances,
k-anonymity [
18] provides sufficient protection because of its conceptual simplicity. It is a well-known PPDP model, and due to algorithmic advances in creating
k-anonymous datasets [
23,
24,
25,
26], it has become a benchmark.
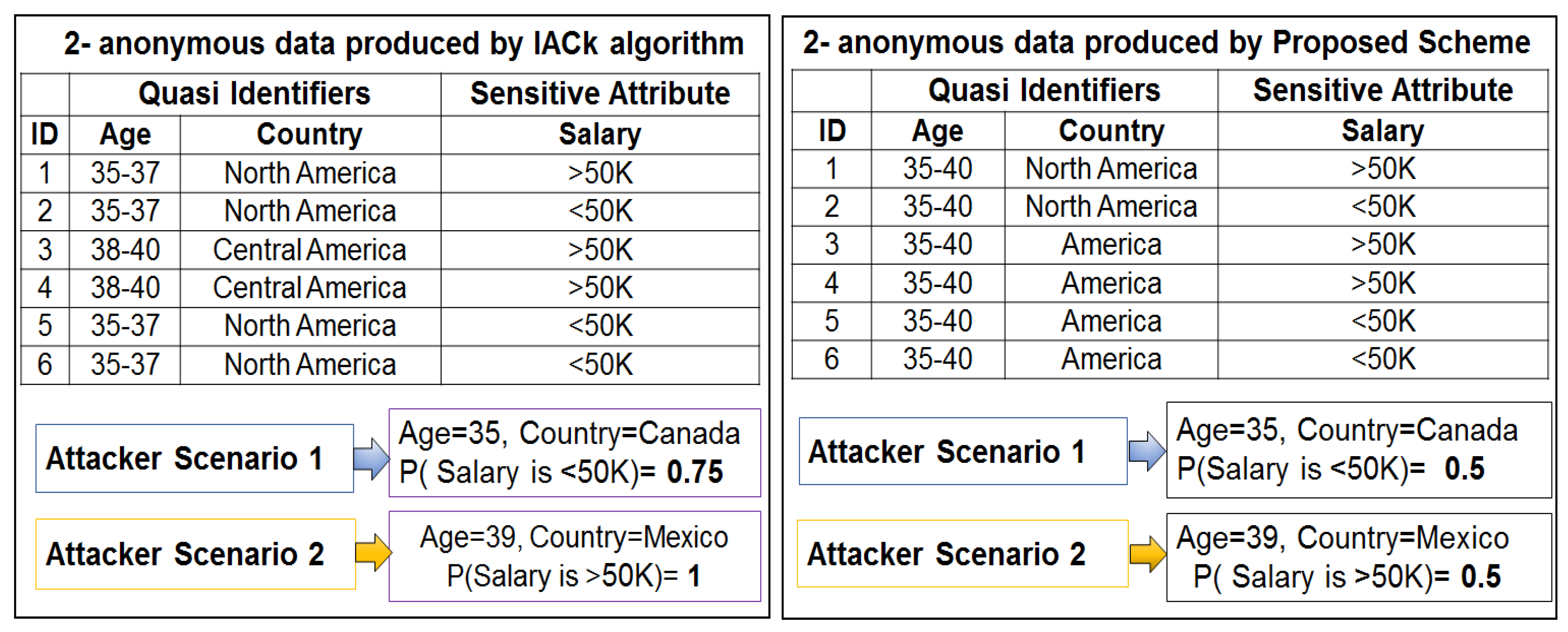
Figure 1a shows selected census information for a group individuals. In this example, attributes are divided into two groups: QIs and SA.
Figure 1b shows a 2-anonymous table derived from the table in
Figure 1a.
Each class has two tuples with identical QIs. However, two simple attacks—homogeneity and background knowledge on
k-anonymous datasets—allow an adversary to infer the SA of an individual with ease. Consider the two simplest attacks on anonymous data in
Figure 1b produced by the
k-anonymity model. Juan and Tana are two Belizean friends, and one day they have dinner together. Juan tells his friend, Tana, that he took part in a census conducted by the National Institute of Statistics (NIS) last week. After knowing this information, Tana sets out to discover Juan’s salary. She discovers the 2-anonymous table of current census participants published by the NIS (
Figure 1b). She knows that one of the records in this table must contain Juan’s salary information. Juan is Tana’s neighbor also, so she knows that Juan is a 40-year-old resident of Belize. She discovers that Juan must be either 3 or 4 in
Figure 1b. Now, all participants have the same finance information (e.g., salary is greater than 50,000 dollars). Therefore, Tana concludes that Juan’s salary is greater than 50,000 dollars.Tana has a friend named Albert from Canada, who also participated in the same census, and whose financial status also appears in the table shown in
Figure 1b. Tana knows that Albert is a 35-year old who lives in Canada permanently. Based on this information, Tana determines that Albert is represented by either the first, second, fifth, or sixth row in
Figure 1b. Without any other information, she is not sure whether Albert has a salary higher or lower than 50,000 dollars. However, it is well known that majority of Canadian adults have salaries less than 50,000 dollars. Therefore, Tana concludes with near certainty (e.g.,
) that Albert’s salary is 50 K. Thus, it is evident that
k-anonymity can create groups that are prone to leaking private information.
A stronger definition of privacy that resolves the aforementioned limitations of
k-anonymity is
ℓ- diversity [
19]. The main idea behind a
ℓ-diverse dataset is that the values of the SAs in each class should be well represented (e.g., the same as
ℓ). Class
A in
Figure 1b has a diversity of 2, while classes
B and
C have no diversity at all. Achieving
ℓ-diversity becomes very challenging when the SA distribution is uneven, such as with these two values: salary > 50 K (1%) and < 50 K (99%). In many other cases as well,
ℓ-diversity is hard to achieve, such as for classes
B and
C in
Figure 1b, which contain only salary values higher or lower than 50 K. To overcome these issues,
t-closeness [
21] was proposed. In the
t-closeness model, the distribution of SAs in any QI group and the overall table should be no more than a certain threshold. However,
t-closeness does not protect from attribute disclosure and is complex in nature. Another significant contribution regarding the implications from the QIs to SAs made by using a local recording-based algorithm to enhance the protection level of
k-anonymity is (
)-anonymity [
20]. The advantage of the (
)-anonymity model is that it can be extended to more general cases (e.g., two or more SAs).
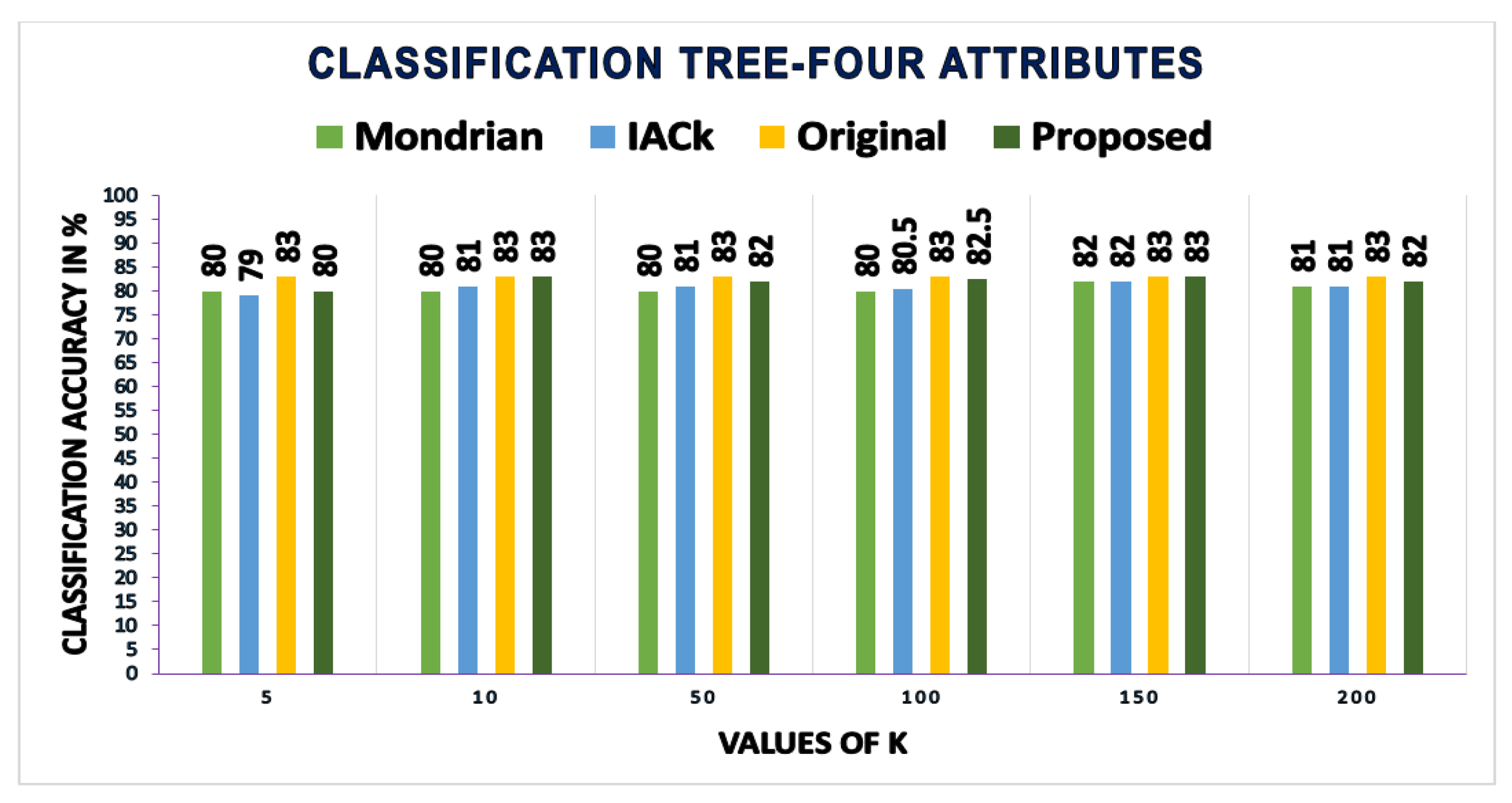
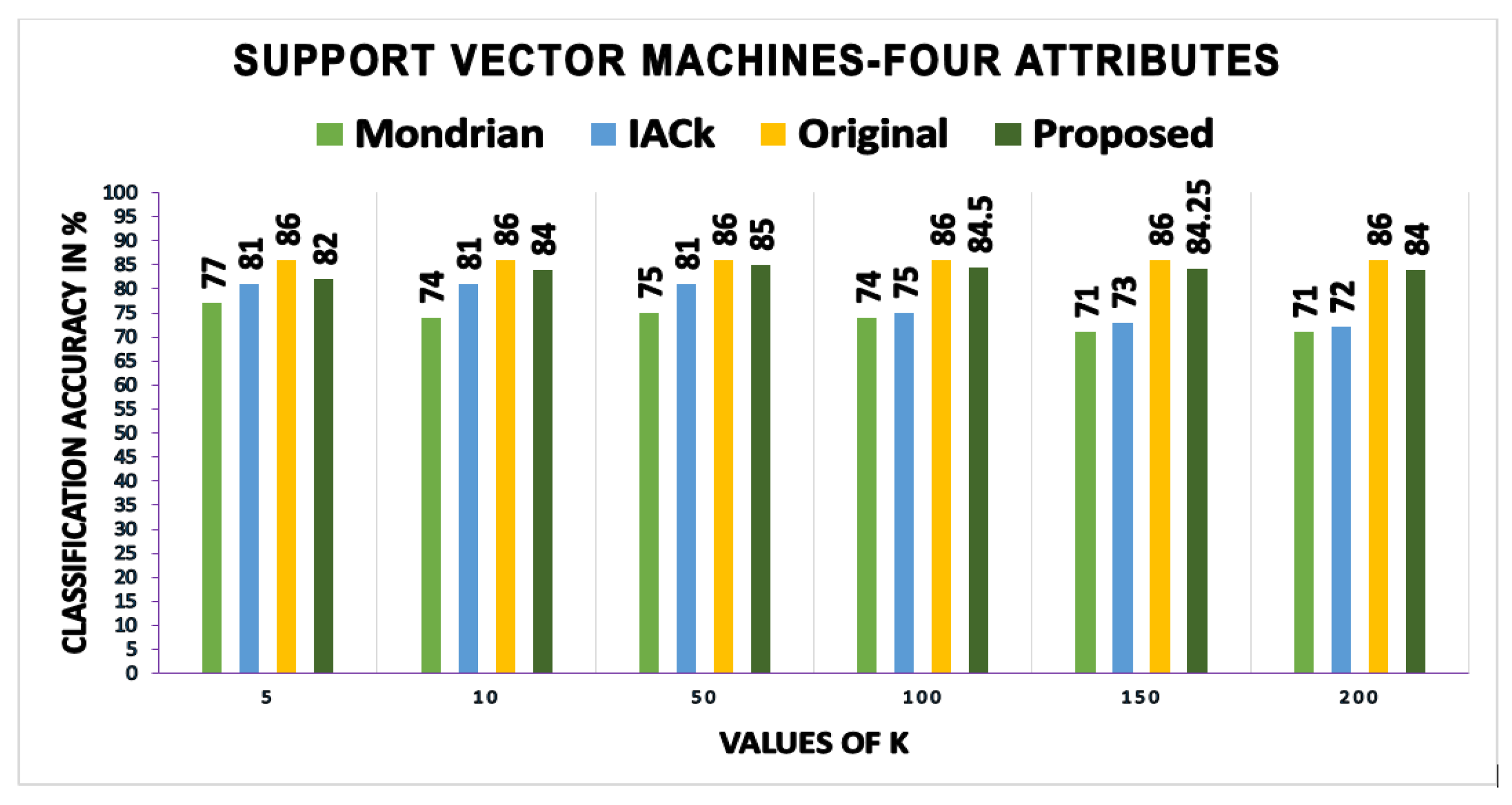
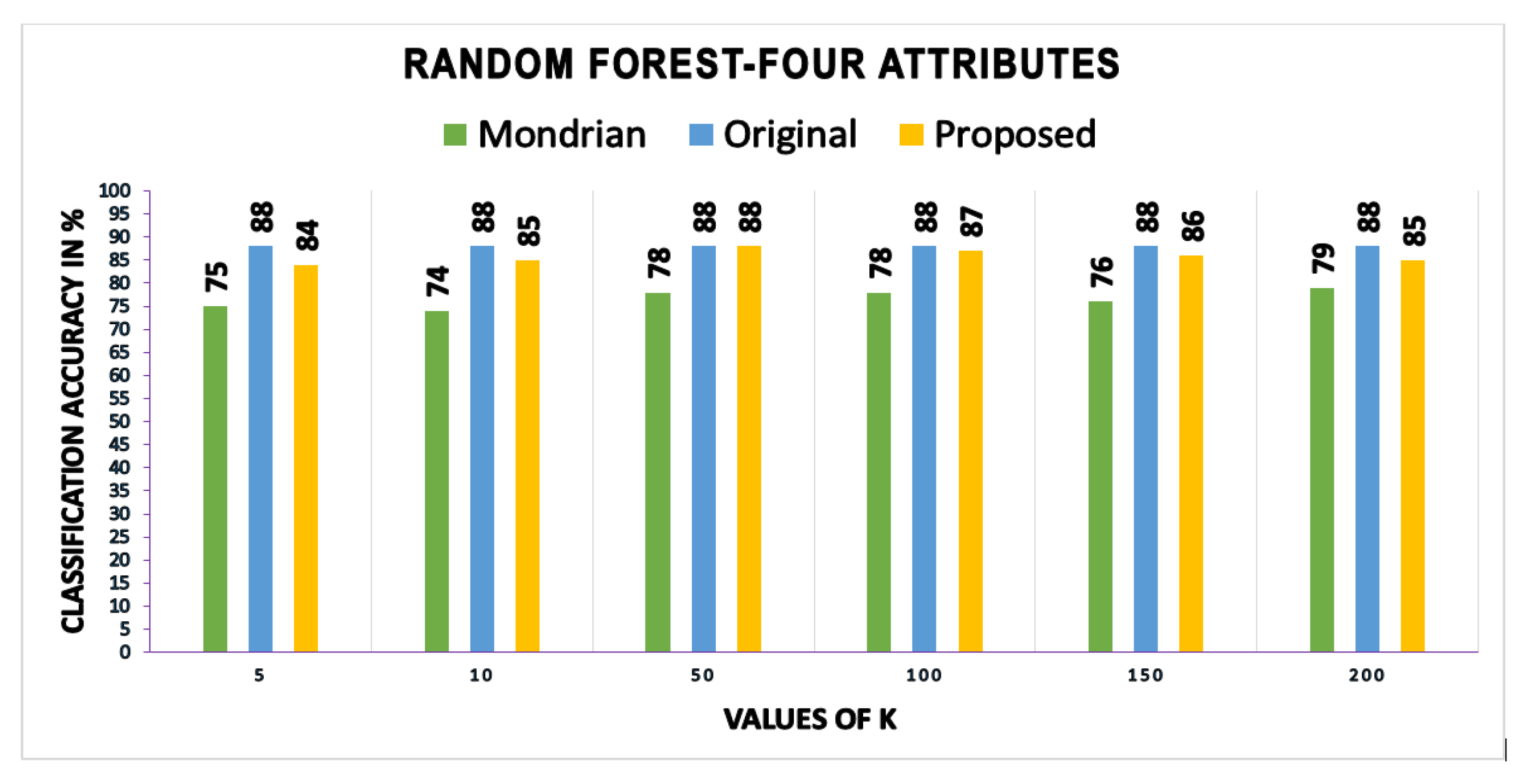
A growing body of literature has examined the anonymous data utility in terms of classification models and their accuracy. A most recent review of the literature on retaining maximum utility in anonymous data from classification accuracy perspective was offered by [
27]. They make use of DP for anonymizing and publishing data that shows considerable improvements in accuracy using decision trees. Apart from this aspect, currently much work on the potentials of data mining has been carried out to mine different perspectives and summaries from data and convert them into useful information. In this regard, a comprehensive study was given by the authors of [
28]; the proposed technique has shown considerable improvements in privacy and utility based on the relations among different attributes in the dataset. The authors make use of the of entropy and information gain to find the distributions of data to protect privacy. The proposed study offers the potential for finding several relations based on data background and area of application. Another independent study to publish useful dataset to satisfy certain research needs, e.g., classification was proposed by the authors of [
29] after adding some noise in the released data. The authors of [
30] study proposed a comprehensive solution for protecting individual privacy using a rule-based privacy model that protects against explicit identity and private information disclosures while releasing person-specific data. It has been suggested that the proposed model recursively generalizes data with low information loss, and ensures promising scalability using sampling and a combination of top-down and bottom-up generalization heuristics. A general-purpose strategy to improve structured data classification accuracy by enriching data with semantics-based knowledge obtained by a multiple-taxonomy built over data items was provided by the authors of [
31], and this seems to be a reliable solution for producing more useful datasets for analysis or building classification models.
A related review of the literature on utility-aware anonymization was offered by [
32,
33]. They draw attention to attribute-level anonymization via retaining the original values of some useful QIs to the greatest extent possible to enhance the utility of the anonymous data. The main weakness of their studies is that they make no attempt to consider the identity vulnerability of the QIs in terms of privacy. Recently, classification models for anonymous data have gained popularity. However, this requires the identification and modeling of privacy threats when releasing data [
34]. Likewise, knowledge of the dependencies between QIs and SAs (e.g., male patients are less likely to have breast cancer) [
35,
36], the underlying anonymization methods [
37], and the combination of QI values [
38], may affect privacy. However, such types of threats have been overlooked in previous work. Data mining reveals knowledge patterns that apply to many people in the data [
39], and the existing privacy models often ignore these receptive patterns. An independent study in 2008 [
40] discussed
k-anonymity in data mining and seemed to be reliable. Anonymity is achieved by extending the general
k-anonymity model with the data mining model, and the proposed algorithm provides reasonable privacy in data mining.
A number of studies have explored a closely-related method used in data publishing for improved classification utility and privacy, such as InfoGain Mondrian [
41], top down refinement (TDR) [
42], information-based anonymization for classification given
k (IACk) [
43] and
k-anonymity of classification trees using suppression (kACTUS) [
44]. Interestingly they produced the same 2-anonymous table as the one shown in
Figure 1a with partial or full suppression of age or country attributes. Mondrian [
41] is a multidimensional method that partitions the data into disjointed rectangular regions according to QI values. Each rectangular region contains at least
k-data points to facilitate value generalization. A serious weakness of the Mondrian method is its unnecessary suppression, which fully hides the QI values. kACTUS [
44] and TDR [
42] will produce the same results by employing the information gain versus anonymity and classification trees, respectively, during anonymization. These approaches are not well suited to privacy because consideration is not given to the probability that each attribute will reveal an individual’s identity. The IACk [
43] algorithm reasonably improves the classification accuracy by considering mutual information when selecting the generalization level. However, SA diversity is not considered, which makes private information disclosure obvious. An even greater source of concern is the need to control the suppression of QIs having less identity vulnerability as much as possible to facilitate utility [
45]. Suppression is a convenient solution to preserve privacy, and most of the machine learning tools can handle suppressed values as missing values. However, in large datasets, full column suppression of less vulnerable QI values potentially hurts utility. Apart from this utility aspect, most of the existing privacy algorithms over-fit anonymized data to QIs, and this over-generalization results in high information losses [
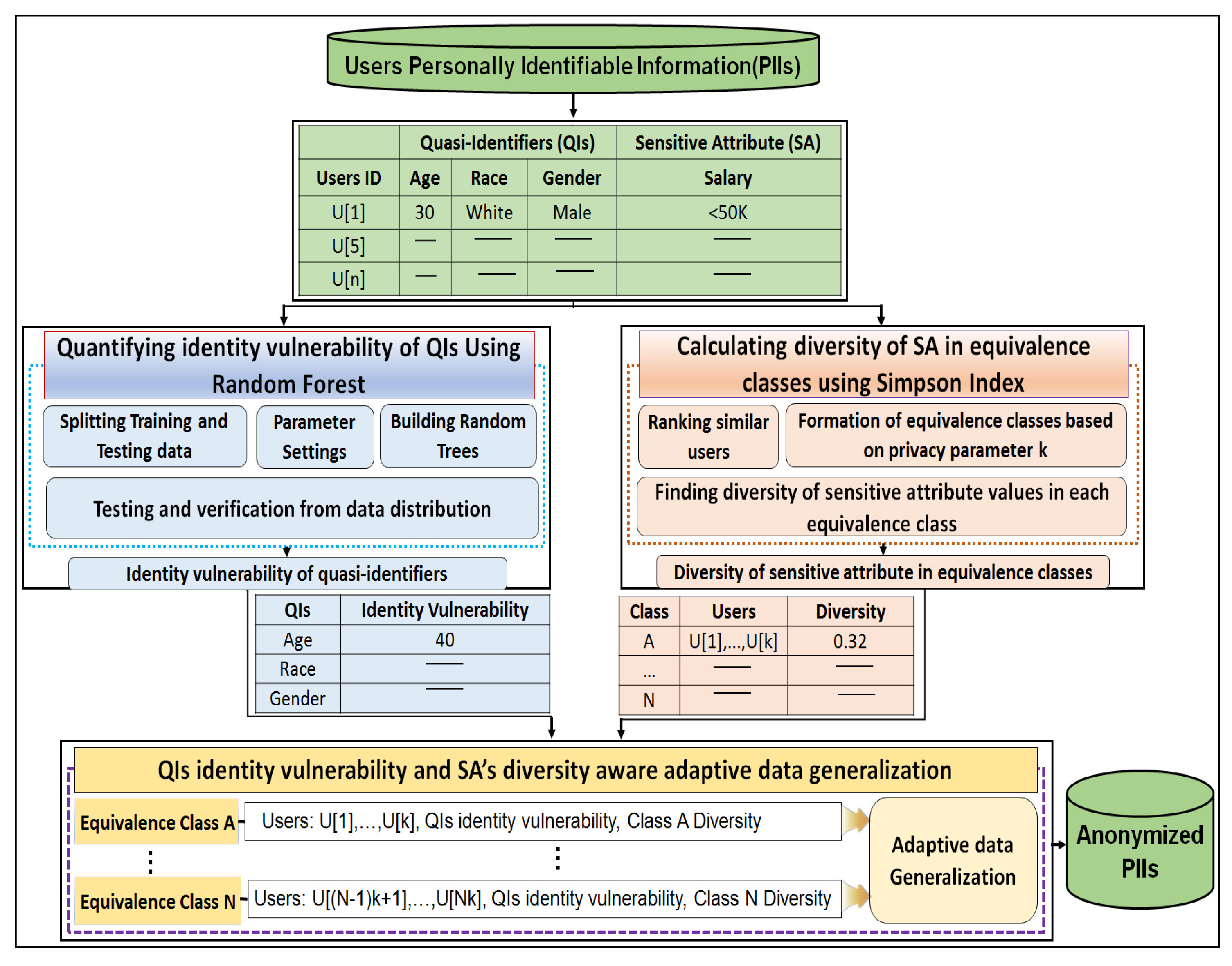
46]. Therefore, anonymous data produced by the existing schemes have less utility. Accordingly, identity cannot be effectively protected and private information disclosure cannot be adequately prevented in a fine-grained manner. The contributions of this research in the field of PPDP can be summarized as follows: (1) it can be used for the anonymization of any dataset, balanced or imbalanced; (2) it uses random forest, a machine learning method, to determine the identity vulnerability values of QIs to reduce the unique identifications caused by the highly identity vulnerable QIs; (3) the Simpson index is used to determine the diversity of classes. A threshold value for the comparison of each class diversity is provided, and considerable attention is paid to low diverse classes to overcome privacy breaches; and (4) we proposed an adaptive generalization scheme for anonymizing data considering the identity vulnerability of QIs as well as the diversity of SAs in equivalence classes to improve both user privacy and utility as compared to existing PPDP algorithms.
4. Finding the Identity Vulnerability of Quasi Identifiers
This section presents the proposed mechanism by which the identity vulnerability of the QIs is determined using RF [
47]. RF is a machine learning method, and we used it to quantify the identity vulnerability values of each QI and to identify vulnerable QIs that explicitly reveal users identities. Determining the identity vulnerability of QIs enables a formal solution to be derived that can effectively protect individual privacy in a fine-grained manner. Without considering the identity vulnerability of the QIs, it is not clear whether the anonymous tuple (e.g., full attribute set representing an individual) produced by any anonymization scheme to tackle user privacy is suitable for use in many real-world cases or not. Knowledge of the identity vulnerability of each QI to a fine level of granularity leads to better privacy preservation and fewer private information disclosures. It is worth looking at RF in greater detail, as well as at the procedure of determining the identity vulnerability of QIs.
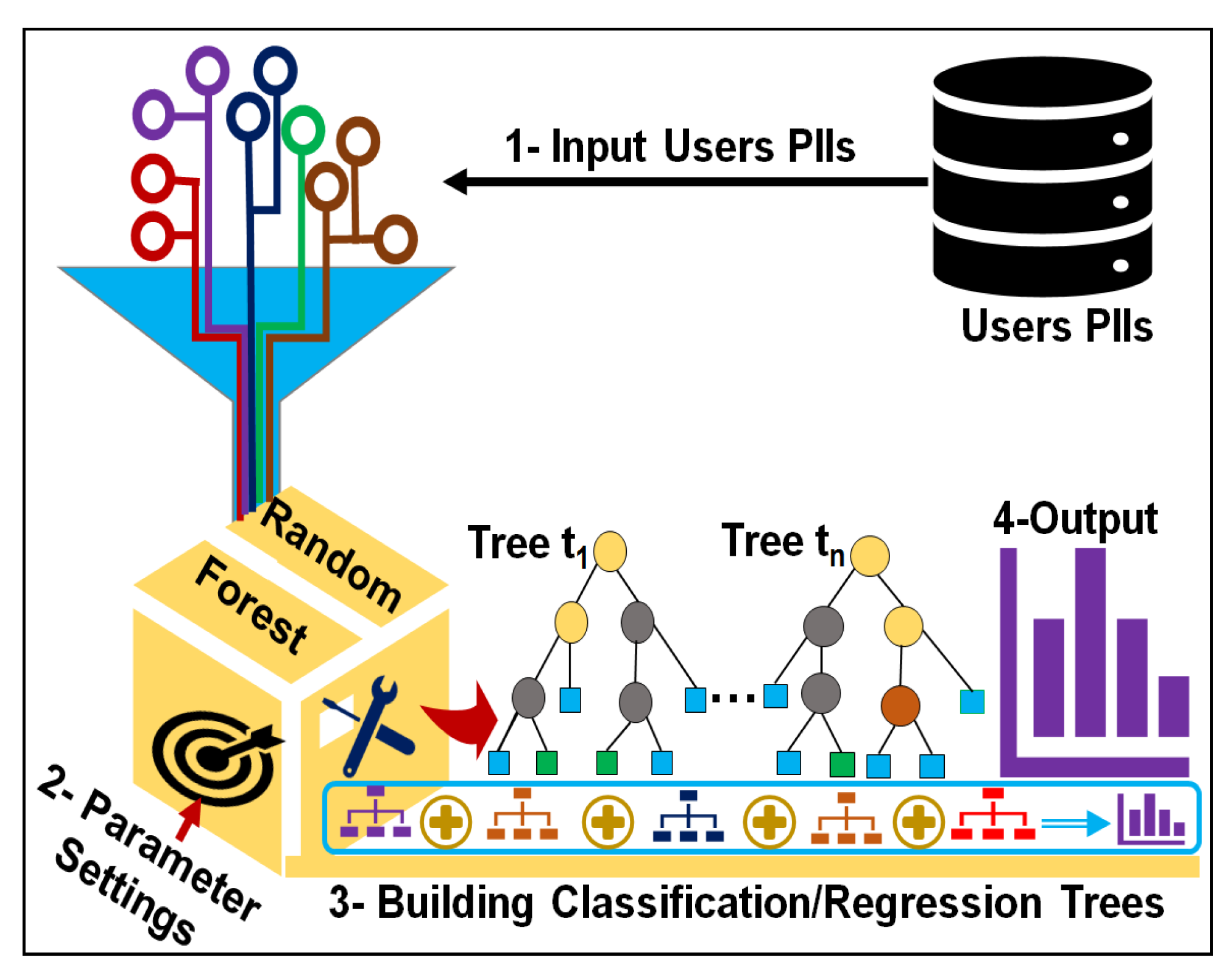
RF is a versatile machine learning method and a special type of ensemble learning technique. It was selected because among currently available algorithms, it is highly accurate. It considers the interaction between attributes and gives high accuracy values. It has been used extensively to build classification and regression models. It produces an ensemble of classification and regression trees (CARTs) using bagged samples of training data [
49] as shown in
Figure 3. By employing the bagging concept, each tree selects only a small set of QIs to split the tree node, which enables the algorithm to quickly build classifiers for highly dimensional data. RF is potentially attractive for handling large amounts of data and variables. It is the best among existing methods in dealing with missing values and outliers that exist in the training data, and gives better accuracy values [
50]. It provides more than six different numerical measures regarding the observations (number of records used as input), including classification accuracy, misclassification rate, precision, recall, F-statistic, and variable importance. However, the most important measure among them is variable importance because it assists in categorizing QIs according to their identity revelation ability. A QI having high importance reveals an identity more easily than other QIs. RF has only two parameters—the number of trees (
) and the number of QIs required at the node split (
)—so it is very easy to tune them. In standard terms, these are called parameter settings, which allow data practitioners to modify these two parameter values subject to their data and purpose. A general procedure to quantify the identity vulnerability of QIs using RF is presented visually in
Figure 3, and the corresponding algorithm pseudo code is provided in Algorithm 1. There are three major steps used to obtain the desired values of the identity vulnerability of the QIs—the data input, parameter settings, and building of the CARTs. The complete pseudo-code used to quantify the identity vulnerability of the QIs using RF is presented in Algorithm 1.
In Algorithm 1, a user dataset containing N number of records, and a set of QIs (P), a number of trees (B), and a small subset of QIs (m) used to split the tree node is provided as input. The identity vulnerability () values of the QIs are obtained as output. RF builds an ensemble of CARTs and calculates the out-of-bag () error (Lines 1–5). We partition the original dataset into two parts during experiments, training data and testing data. So, two-thirds in Line 4 is the amount of training data (e.g., the data on which the algorithms were tested) containing tuples out of tuples and the remaining one-third of the data in Line 5 containing was used for validation and testing purposes.
| Algorithm 1: Finding identity vulnerability values of the QIs |
![Sensors 17 01059 i001]() |
Integer 10 in line 6 represents the desired value of error called misclassification produced by the random forest while building random trees. The desired values of accuracy should be higher than to correctly measure the vulnerability values of quasi-identifiers. Therefore, we rigorously compare error with integer 10 to keep the accuracy values higher. However, accuracy values can be adjusted according to the protection level and objectives of data publishing. If the is high, then a parameter setting is performed to achieve the appropriate accuracy (Lines 6 and 7). In contrast, if the falls within the acceptable range, then the values of each QI are shuffled in a column, and its impact on the is observed (Lines 9–12). The same process is repeated for all QIs in a dataset. After getting the values for all of the QIs, the mean (), variance () and standard deviation (s) are calculated using Equations (7)–(9). Subsequently, the identity vulnerability () of each QI is calculated using Equation (10).
5. Determining the Best Generalization Level
Apart from the full suppression of all QIs in a tuple, complete safeguarding against the background knowledge and linking attacks as explained in
Section 2, is very difficult. However, adaptive data generalization can play a significant role in guarding against these attacks to an acceptable level. This section presents the proposed adaptive generalization scheme appropriate generalization level selection from taxonomies based on the identity vulnerability of QIs and diversity of SA to effectively protect user privacy. After determining the identity vulnerability of the QIs, ranking highly similar users, and forming equivalence classes using
k, it is now possible to calculate and compare the diversity of classes and determine the generalization level to anonymize QIs. When anonymizing the data, data generalization is performed adaptively based on the identity vulnerability of the QIs as well as the diversity. Apart from class diversity (
D), evenness (
E) is also calculated to determine the relative abundance of the SA values. Both of these measures are calculated using the Simpson index. The
D and
E values are calculated using Equations (
3)–(
6) (this procedure is explained in
Section 3). Values with defined thresholds (
and
) are subsequently compared. Because certain data statistics such as the identity vulnerability of the QIs and the diversity of classes are determined in advance, adaptive generalization (i.e., taxonomy positions are established) can be performed. For less diverse user classes, great care is taken in the corresponding QI group. The proposed adaptive generalization method, which couples the identity vulnerability of the QIs with the diversity of the SAs, ultimately provides considerable protection against various attacks. The adaptive generalization facilitates superior data anonymity, thereby protecting identities and preventing private information disclosures. At the same time, the data utility is also preserved. The technique shows clear improvements over existing methods of privacy protection that determine the generalization level based on mutual information or heuristics.
5.1. Higher and Lower Level Generalization
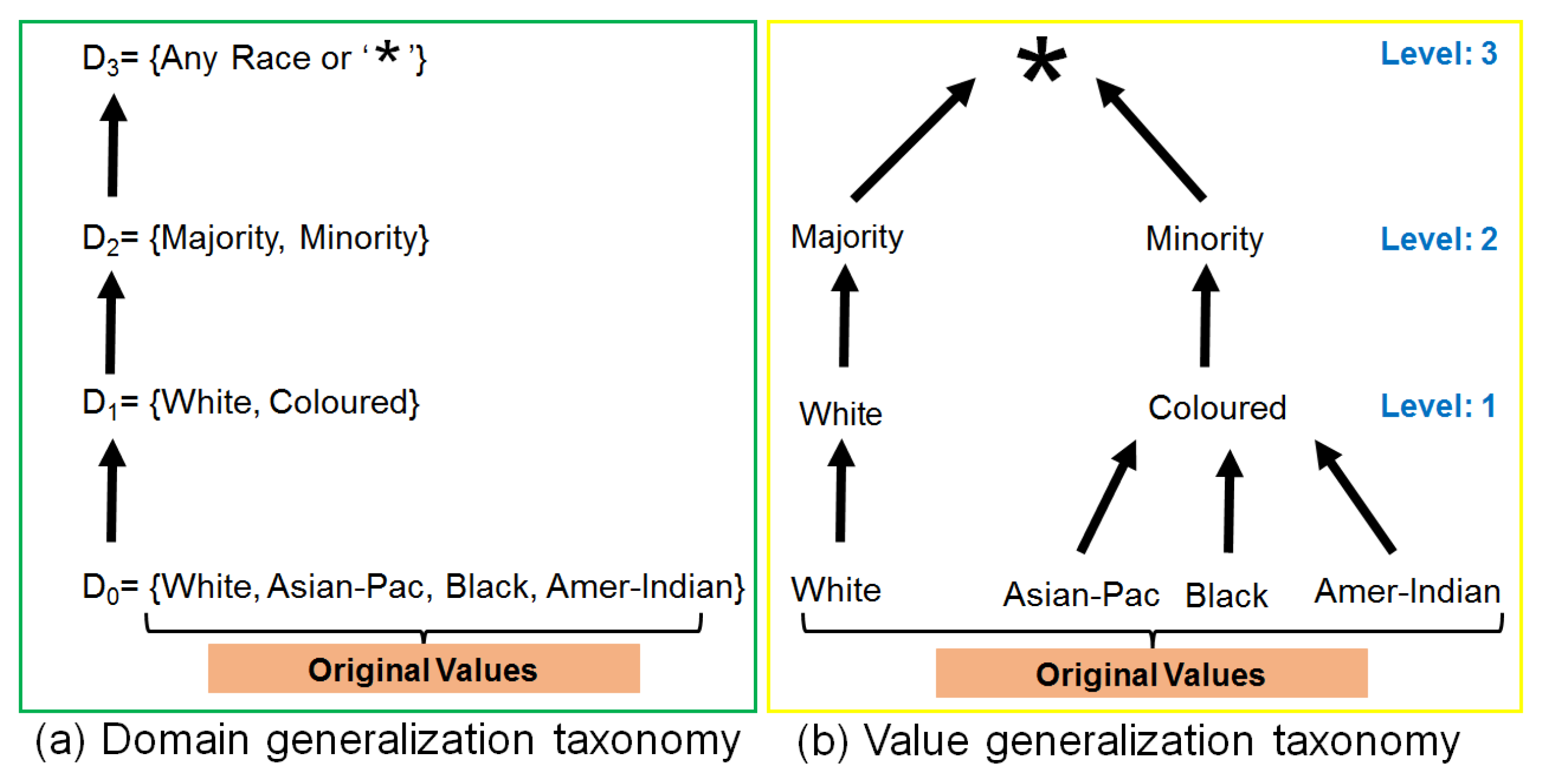
Data generalization to anonymize QI values is based on either domain generalization hierarchy/taxonomy or value generalization hierarchy/taxonomy. A domain generalization taxonomy is defined to be a set of domains that is totally ordered by the relationship from lower limit to higher limit in numeric data, and all possible values ordered semantically or logically in case of alphabetic data. We can consider the taxonomy as a chain of nodes, and if there is an edge from node
(bottom node) to another node
(top node) of the same branch in generalization taxonomy, it means that
is the direct generalization of
. Similarly, if
is a set of domains in a domain generalization taxonomy of a QI from QIs set,
. For every
and
belonging to
if
and
, then
. In this case, domain
is an implied generalization of
.
Figure 4 shows an example of generalization taxonomies of race attribute. Domain generalization taxonomy of race is given in
Figure 4a. Meanwhile, the value generalization functions associated with the domain generalization taxonomy induces a corresponding value-level taxonomy based on the actual QI values. In value generalization taxonomy, edges are denoted by
r, i.e., direct value generalization, and paths are denoted by
, i.e., implied value generalization.
Figure 4b shows a value generalization taxonomy with each value in the race, e.g., colored =
r (black) and * belongs
(black). For all QIs,
consisting of multiple values, each with its own domain. The domain generalization hierarchies of the individual attributes can be combined to form generalization lattices and combine taxonomies to be used for anonymizing QIs values. In Algorithm 2, we mainly refer to direct generalization (generalization at lower levels close to original values, e.g., level 1 or 2 in
Figure 4) as lower level generalization, and implied generalization (generalization at higher levels close to the root node, e.g., level 2 or 3 in
Figure 4) as higher level generalization. When the diversity of sensitive attributes is less than desired threshold then higher level generalization is preferred to limit privacy breaches. Meanwhile, lower level generalization is performed to preserve anonymous data utility for performing analysis or building different classification models.
5.2. Adaptive Data Generalization Algorithm
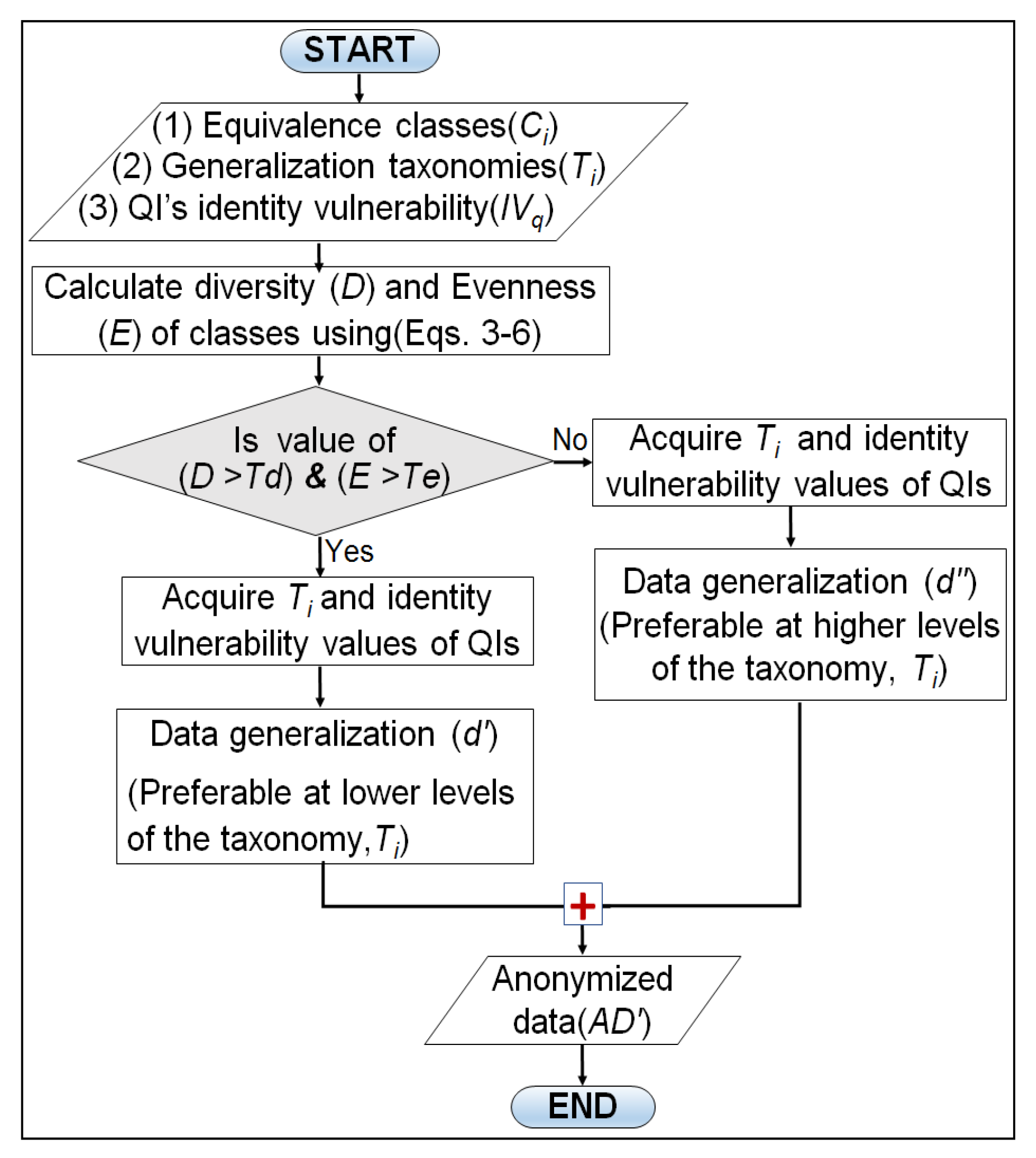
In this section, we present proposed adaptive generalization algorithm and its working with the help of flowchart and pseudo-code. The proposed algorithm performs two major steps to produce anonymous data from the original data: finding
D and
E values and their analyses, and adaptive data generalization. The
D and
E analyses steps involve comparing each class diversity and evenness with their defined thresholds (
and
). However, the adaptive data generalization step selects the most appropriate generalization level to anonymize QI values.
Figure 4 shows three different levels to anonymize race values given in the dataset. As we climb up in the taxonomy tree, the distance from the original values increase and information becomes less specific. Data generalization near the root of the tree offers strong privacy guarantees but utility will be very low. In either case, data generalization at lower levels of the taxonomy tree gives promising utility but privacy will be low. This results in a trade-off between privacy and utility which can be exploited by designing an adaptive data generalization mechanism where the identity vulnerability of each QI and diversity of sensitive attributes are integrated to reduce the privacy issues while improving the anonymous data utility. We obtain vulnerability and diversity values and use them in generalizing each QI values. A comprehensive overview of the proposed algorithm working in the form of the flow chart is presented in
Figure 5.
Apart from the visual flow chart, a complete pseudo-code of the adaptive generalization is listed in Algorithm 2. Lines 1–3 implement the D and E calculations as well as the comparison with the relevant thresholds ( and ). Lines 5–11 perform the lower level generalization for the highly diverse classes, and Lines 13–19 implement the higher-level generalization for low diverse classes. Lines 5–11 and 13–19 are the two blocks of –. The initial three steps in both blocks are identical, the main difference lies in Line number 8 and Line number 16, where higher level and lower level generalizations are performed respectively. Finally, anonymous data () is returned by combining both classes of anonymity (Lines 22,23). The complete pseudo-code used to determine the generalization level adaptively for QI anonymization is presented in Algorithm 2.
| Algorithm 2: Adaptive data generalization algorithm |
![Sensors 17 01059 i002]() |















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}