A Hybrid Scheme for Fine-Grained Search and Access Authorization in Fog Computing Environment

Abstract
:1. Introduction
- On the promise of ensuring the security of cryptography scheme, the index encryption and data encryption components are integrated under the same access policy and key pair to achieve higher efficiency at a lower cost.
- In ABE scheme, the computational costs of the encryption and decryption scale with the complexity of the access policy or number of attributes and are primarily incurred by complex exponentiations and pairing operations. Although Ambrosin et al. [20] declared the feasibility of ABE for IoT devices, they also advised the migration of complex arithmetic operations to more powerful parties in order to enhance energy efficiency and total execution time. Therefore, how to alleviate the burden on resource-constrained end users and solve the possible performance bottleneck caused by resource limitation is still a problem that needs to be considered in scheme design.
- In the fog computing environment, many copies of encrypted data can be generated and distributed to many fog nodes, but the ciphertexts of the basic ABE scheme need to be re-encrypted when a user revocation occurs, and consequently, directly applying the basic ABE scheme to fog computing environment will be inefficient due to huge revocation cost.
1.1. Related Works
1.1.1. Fine-grained Access Control Based on ABE
1.1.2. Searchable Encryption
1.2. Contributions
- For the new cloud computing architecture with fog computing layer, we design a hybrid authorization model spanning user-fog-cloud, by which the authorized users can securely delegate search task over encrypted data to cloud server/fog nodes and decrypt the search results with the help of fog nodes.
- To improve access efficiency, reduce key management cost and resist swapping attack, the data ciphertext and index ciphertext are constructed based on the same access policy and key pair.
- To meet resource constraints of end IoT devices, we incorporate decryption outsourcing technique of ABE to outsource most of decryption computation task to fog node, and meanwhile, we also adopt online/offline ABE technique to calculate in advance most of ciphertext components during device’s idle time and then the device can rapidly assemble ABE ciphertexts online. Thus, energy efficiency and total execution time on end devices are enhanced and the possible performance bottleneck is avoided.
- Considering that many copies of encrypted data are distributed to many fog nodes, we incorporate mediated ABE technique to achieve instantaneous user revocation and avoid huge revocation cost incurred by re-encryption of ciphertexts.
- We prove the proposed scheme is selectively secure against chosen keyword attack (CKA) and chosen plaintext attack (CPA) under standard model. Performance evaluation shows that the proposed scheme can effectively protect data confidentiality and achieve secure data sharing in fog environment.
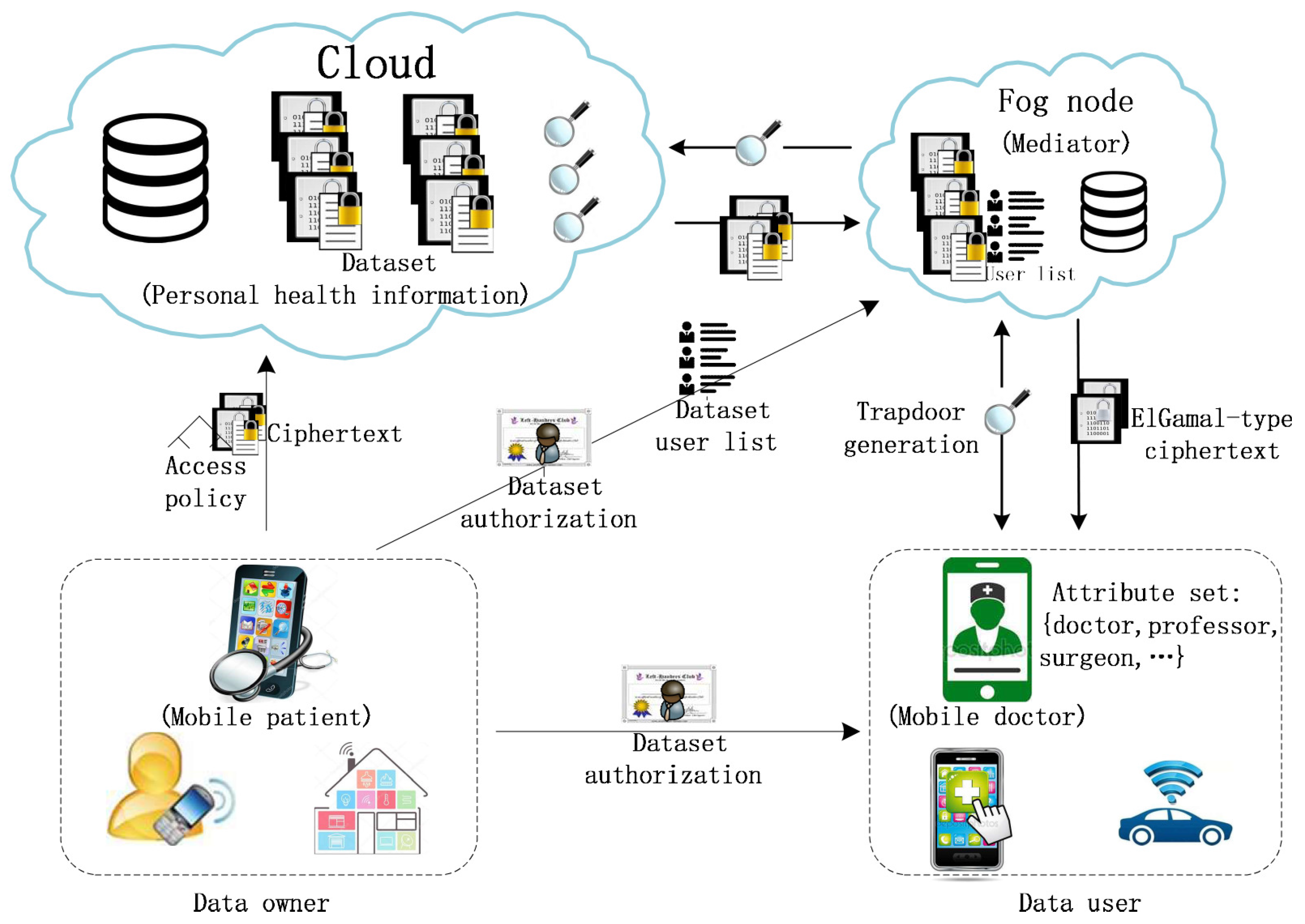
2. System Overview
2.1. System Model
2.2. An Application Scenario
2.3. Threat Model and Security Goals
- Keyword privacy: The proposed hybrid scheme can achieve selectively secure against chosen-keyword attack (CKA). We will prove it under standard model in Appendix A.
- Data confidentiality: The proposed hybrid scheme can achieve selectively secure against chosen-plaintext attack (CPA). We will prove it under standard model in Appendix A.
- Trapdoor unlinkability: This security property makes the cloud server or fog nodes unable to visually distinguish two or more trapdoors even containing the same keyword.
- Swapping attack resistance: This security property requires that the alteration of relationship between index ciphertext and data ciphertex can be detected immediately.
3. Proposed Hybrid Scheme
3.1. System Initialization
3.1.1. System Setup
3.1.2. Mediator Register
3.1.3. User Register
3.2. Sensitive Data Outsourcing Storage
3.2.1. Offline Computation
- Main Module Generation: The data owner picks a random number and computes . The tuple is a main module. The data owner can generate an arbitrary number of main modules.
- Attribute Module Generation: For each , the data owner selects a random and computes and each tuple is called as an attribute module. The data owner can generate an arbitrary number of attribute modules for each k.
3.2.2. Online Computation
3.3. Search and Access of Outsourced Sensitive Data
3.3.1. Trapdoor Generation
3.3.2. Search over Ciphertext
- if and ,
- If and ,
3.3.3. Data Decryption
- if and
- if and
3.4. User Revocation
4. Security and Performance Analysis
4.1. Security Analysis
4.2. Performance Analysis
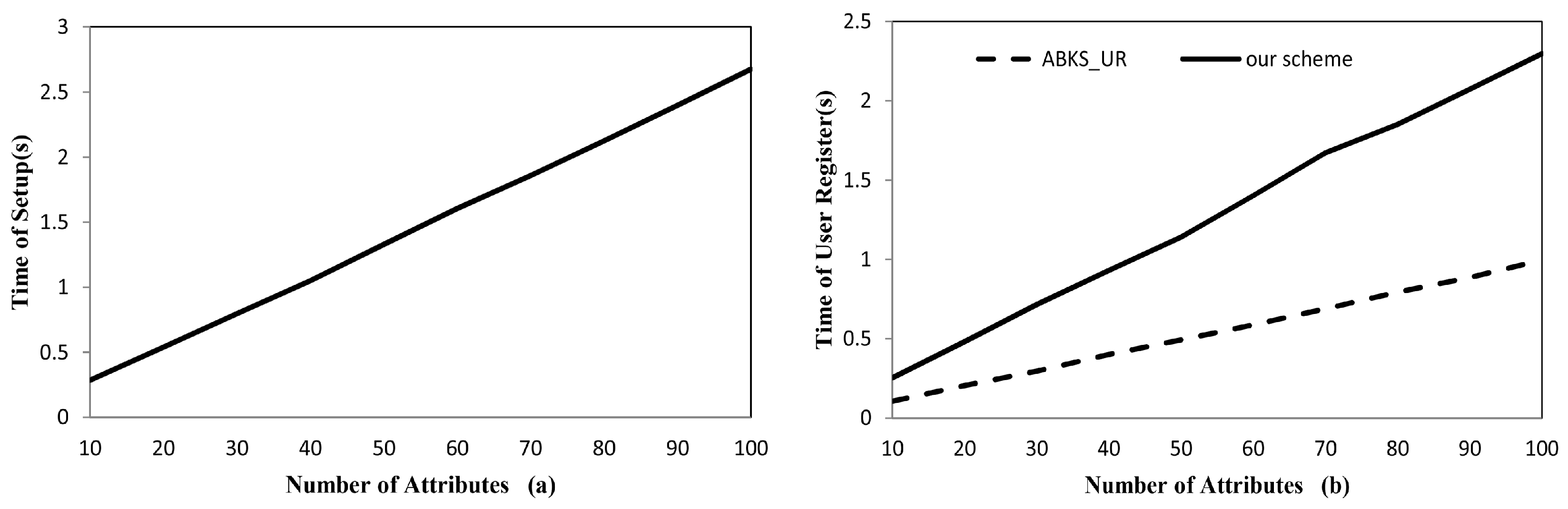
4.2.1. The Efficiency of System Initialization
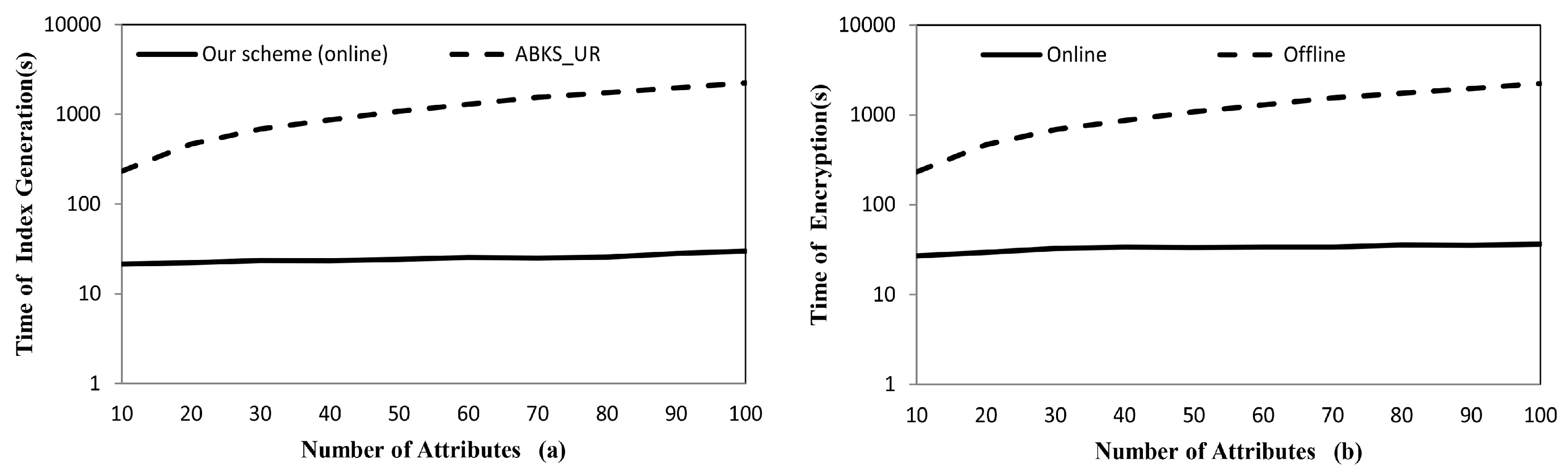
4.2.2. The Efficiency of Data Outsourcing
4.2.3. The Efficiency of Data Search and Access
4.2.4. User Revocation
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Security Proof
Appendix A.1. Security of mABKS
Appendix A.1.1. Scheme Description
- System Initialization. This phase in mABKS is the exact same as that in the proposed scheme in Section 3.
- Secure Index Generation. Data owner generates the secure index of some keyword for his each outsourced file. Like the proposed scheme, mABKS scheme also adopts a two-layer authorization structure for accelerating search. For a dataset, the data owner first selects a secret value randomly and computes and . Let w denote the keyword from a file in the dataset and be a designated access structure for the file, for each , the data owner computesThe keyword w is encrypted in the following way. For some attribute , the data owner calculates . Finally, the secure index is sent to cloud server along with the encrypted file (the file encryption isn’t considered in this scheme).
- Trapdoor Generation. Trapdoor generation process in mABKS is exactly the same as that in the proposed scheme in Section 3.
- Search. Substituting for in Section 3.3.2, search process in mABKS can be implemented using Step 2 and Step 3 of the search process in the proposed scheme.
Appendix A.1.2. Security Definition for mABKS
- : asks for a mediator share of trapdoor for a chosen attribute set S and receives .
- : asks for a user share of trapdoor for a chosen attribute set S and keyword w, then receives .
- : asks for a complete value of trapdoor for a chosen attribute set S and keyword w, then receives the whole trapdoor T.
Appendix A.1.3. Security Proof for mABKS
- For all , randomly chooses and sets , and if . Then, computes and chooses from as a random secret value of the mediator. Consequently, can compute , and for the witness attribute such that and , compute and .For , has: 1) . if , and if , .2) . if , and if , .Meanwhile, also computes components similarly for , if and if , . Finally, response is
- chooses from as a random secret value of the user and gets , , and for all except for , . For the witness attribute , and , denotes and .Except for , for , the components can be computed as follows:
- (1)
- . If ; if .
- (2)
- . If , ; if , .
Similarly, except for , for , also computes if and if . Without loss of generality, consider and . Thus, sets . - sets and computes . For all , computes . Finally, response is .
Appendix A.2. Security of the Proposed Scheme
Appendix A.2.1. Security Definition for the Proposed Scheme
Appendix A.2.2. Security Proof for the Proposed Scheme
References
- Bonomi, F.; Milito, R.; Zhu, J.; Addepalli, S. Fog Computing and its Role in the Internet of Things. In Proceedings of the first edition of the MCC workshop on Mobile cloud computing, Helsinki, Finland, 17 August 2012; pp. 13–16. [Google Scholar]
- Stojmenovic, I.; Wen, S. The Fog computing paradigm: Scenarios and security issues. In Proceedings of the Federated Conference on Computer Science and Information Systems, Warsaw, Poland, 7–10 September 2014; pp. 1–8. [Google Scholar]
- Yi, S.; Li, C.; Li, Q. A Survey of Fog Computing: Concepts, Applications and Issues. In Proceedings of the 2015 Workshop on Mobile Big Data, Hangzhou, China, 21 June 2015; pp. 37–42. [Google Scholar] [CrossRef]
- Goyal, V.; Pandey, O.; Sahai, A.; Waters, B. Attribute-based encryption for fine-grained access control of encrypted data. In Proceedings of the ACM Conference on Computer and Communications Security, CCS 2006, Alexandria, VA, USA, 30 October–3 November 2006; pp. 89–98. [Google Scholar]
- Bethencourt, J.; Sahai, A.; Waters, B. Ciphertext-Policy Attribute-Based Encryption. Procededings of the IEEE Symposium on Security and Privacy, 2007, Berkeley, CA, USA, 20–23 May 2007; pp. 321–334. [Google Scholar]
- Li, M.; Yu, S.; Zheng, Y.; Ren, K.; Lou, W. Scalable and secure sharing of personal health records in cloud computing using attribute-based encryption. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 131–143. [Google Scholar] [CrossRef]
- Zuo, C.; Shao, J.; Wei, G.; Xie, M.; Ji, M. CCA-secure ABE with outsourced decryption for fog computing. Future Gener. Comput. Syst. 2016. [Google Scholar] [CrossRef]
- Jiang, Y.; Susilo, W.; Mu, Y.; Guo, F. Ciphertext-policy attribute-based encryption against key-delegation abuse in fog computing. Future Gener. Comput. Syst. 2017. [Google Scholar] [CrossRef]
- Yu, Z.; Man, H.A.; Xu, Q.; Yang, R.; Han, J. Towards leakage-resilient fine-grained access control in fog computing. Future Gener. Comput. Syst. 2017. [Google Scholar] [CrossRef]
- Zhang, P.; Chen, Z.; Liu, J.K.; Liang, K.; Liu, H. An efficient access control scheme with outsourcing capability and attribute update for fog computing. Future Gener. Comput. Syst. 2016. [Google Scholar] [CrossRef]
- Song, D.X.; Wagner, D.; Perrig, A. Practical techniques for searches on encrypted data. In Proceedings of the IEEE Symposium on Security & Privacy, Berkeley, CA, USA, 14–17 May 2000; pp. 44–55. [Google Scholar]
- Bosch, C.; Hartel, P.; Jonker, W.; Peter, A. A Survey of Provably Secure Searchable Encryption. ACM Comput. Surv. (CSUR) 2015, 47, 1–51. [Google Scholar] [CrossRef]
- Chang, Y.C.; Mitzenmacher, M. Privacy Preserving Keyword Searches on Remote Encrypted Data. In Proceedings of the Applied Cryptography and Network Security, ANCS 2005, LNCS, Cambridge, MA, USA, 7–10 June 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 442–455. [Google Scholar]
- Curtmola, R.; Garay, J.; Kamara, S.; Ostrovsky, R. Searchable symmetric encryption: Improved definitions and efficient constructions. J. Comput. Secur. 2011, 19, 79–88. [Google Scholar] [CrossRef]
- Yang, Y.; Lu, H.; Weng, J. Multi-user private keyword search for cloud computing. In Proceedings of the 2011 IEEE Third International Conference on Cloud Computing Technology and Science (CloudCom), Athens, Greece, 29 November–1 December 2011; pp. 264–271. [Google Scholar]
- Sun, W.H.; Yu, S.C.; Lou, W.J.; Hou, Y.T.; Li, H. Protecting your right: Attribute-based keyword search with fine-grained owner-enforced search authorization in the cloud. In Proceedings of the INFOCOM, Toronto, ON, Canada, 27 April–2 May 2014; Volume 27, pp. 226–234. [Google Scholar]
- Dan, B.; Crescenzo, G.D.; Ostrovsky, R.; Persiano, G. Public Key Encryption with Keyword Search. In Advances in Cryptology-EUROCRYPT 2004; Springer: Heidelberg, Germany, 2003; pp. 506–522. [Google Scholar]
- Baek, J.; Safavi-Naini, R.; Susilo, W. On the Integration of Public Key Data Encryption and Public Key Encryption with Keyword Search. In Information Security; Springer: Heidelberg, Germany, 2006; Volume 4176, pp. 217–232. [Google Scholar]
- Liang, K.; Susilo, W. Searchable Attribute-Based Mechanism With Efficient Data Sharing for Secure Cloud Storage. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1981–1992. [Google Scholar] [CrossRef]
- Ambrosin, M.; Anzanpour, A.; Conti, M.; Dargahi, T.; Moosavi, S.R.; Rahmani, A.M.; Liljeberg, P. On the Feasibility of Attribute-Based Encryption on Internet of Things Devices. IEEE Micro 2016, 36, 25–35. [Google Scholar] [CrossRef]
- Green, M.; Hohenberger, S.; Waters, B. Outsourcing the decryption of ABE ciphertexts. In Usenix Conference on Security; USENIX Association: Berkeley, CA, USA, 2011; Volume 49, p. 34. [Google Scholar]
- Li, J.; Chen, X.; Li, J.; Jia, C.; Ma, J.; Lou, W. Fine-Grained Access Control System Based on Outsourced Attribute-Based Encryption. Comput. Secur. Esorics 2013, 8134, 592–609. [Google Scholar]
- Hohenberger, S.; Waters, B. Online/offline attribute-based encryption. In Public-Key Cryptography, PKC; Springer: Heidelberg, Germany, 2014; Volume 8383, pp. 293–310. [Google Scholar]
- Luan, I.; Petkovic, M.; Nikova, S.; Hartel, P.; Jonker, W. Mediated Ciphertext-Policy Attribute-Based Encryption and Its Application. In Information Security Applications; Springer: Heidelberg, Germany, 2009; Volume 5932, pp. 309–323. [Google Scholar]
- Sahai, A.; Waters, B. Fuzzy Identity-Based Encryption. Lect. Notes Comput. Sci. 2004, 3494, 457–473. [Google Scholar]
- Cheung, L.; Newport, C. Provably secure ciphertext policy ABE. In Proceedings of the ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 29 October–2 November 2007; Volume 2007, pp. 456–465. [Google Scholar]
- Pirretti, M.; Traynor, P.; Mcdaniel, P.; Waters, B. Secure attribute-based systems. In Proceedings of the ACM Conference on Computer and Communications Security, CCS 2006, Alexandria, VA, USA, 30 October–3 November 2006; Volume 18, pp. 99–112. [Google Scholar]
- Yang, K.; Jia, X.; Ren, K. Attribute-based fine-grained access control with efficient revocation in cloud storage systems. In Proceedings of the ACM Sigsac Symposium on Information, Computer and Communications Security, Hangzhou, China, 8–10 May 2013; pp. 523–528. [Google Scholar]
- Tysowski, P.K.; Hasan, M.A. Hybrid attribute- and re-encryption-based key management for secure and scalable mobile applications in clouds. IEEE Trans. Cloud Comput. 2013, 1, 172–186. [Google Scholar] [CrossRef]
- Zhang, R.; Imai, H. Generic Combination of Public Key Encryption with Keyword Search and Public Key Encryption. In Cryptology and Network Security; Springer: Heidelberg, Germany, 2007; pp. 159–174. [Google Scholar]
- Chen, Y.; Zhang, J.; Lin, D.; Zhang, Z. Generic constructions of integrated PKE and PEKS. Des. Codes Cryptogr. 2016, 78, 493–526. [Google Scholar] [CrossRef]
- Wang, P.; Wang, H.; Pieprzyk, J. Threshold privacy preserving keyword searches. In Proceedings of the International Conference on Current Trends in Theory and Practice of Informatics, Novy Smokovec, Slovakia, 19–25 January 2008; Volume 4910, pp. 646–658. [Google Scholar]
- Wang, P.; Wang, H.; Pieprzyk, J. An Efficient Scheme of Common Secure Indices for Conjunctive Keyword-Based Retrieval on Encrypted Data. In Proceedings of the International Workshop on Information Security Applications, Jeju Island, Korea, 23–25 September 2008; Volume 5379, pp. 145–159. [Google Scholar]
- Sun, W.; Yu, S.; Lou, W.; Hou, Y.T.; Li, H. Protecting Your Right: Verifiable attribute-based keyword search with fine-grained owner-enforced search authorization in the cloud. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 1187–1198. [Google Scholar] [CrossRef]
- Cohen, W.W. Enron Email Dataset. Available online: https://www.cs.cmu.edu/enron/ (accessed on 26 July 2016).
- Pairing-Based Cryptography Libray. Available online: http://crypto.stanford.edu/pbc/ (accessed on 12 May 2017).
- JPBC: The Java Pairing Based Cryptography Library. Available online: http://gas.dia.unisa.it/projects/jpbc/ (accessed on 12 May 2017).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Single User | Multiple Users | Index Encryption | Data Encryption | Instantaneous User |
|---|---|---|---|---|---|
| Revocation | |||||
| [11] | √ | √ | |||
| [13] | √ | √ | |||
| [17] | √ | √ | |||
| [15,33] | √ | √ | √ | ||
| [16,34] | √ | √ | |||
| [19] | √ | √ | √ |
| Schemes | System Setup | User Register | Mediator Register |
|---|---|---|---|
| our scheme | |||
| ABKS_UR |
| Schemes | Secure Index Generation | Ciphertext Generation | ||
|---|---|---|---|---|
| Online | Offline | Online | Offline | |
| our scheme | ||||
| ABKS_UR | ||||
| Schemes | Trapdoor Generation | Per-Index Search | Data Decryption | ||
|---|---|---|---|---|---|
| User | Fog Node | User | Fog Node | ||
| our scheme | |||||
| ABKS_UR | |||||
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, M.; Zhou, J.; Liu, X.; Jiang, M. A Hybrid Scheme for Fine-Grained Search and Access Authorization in Fog Computing Environment. Sensors 2017, 17, 1423. https://doi.org/10.3390/s17061423
Xiao M, Zhou J, Liu X, Jiang M. A Hybrid Scheme for Fine-Grained Search and Access Authorization in Fog Computing Environment. Sensors. 2017; 17(6):1423. https://doi.org/10.3390/s17061423
Chicago/Turabian StyleXiao, Min, Jing Zhou, Xuejiao Liu, and Mingda Jiang. 2017. "A Hybrid Scheme for Fine-Grained Search and Access Authorization in Fog Computing Environment" Sensors 17, no. 6: 1423. https://doi.org/10.3390/s17061423
APA StyleXiao, M., Zhou, J., Liu, X., & Jiang, M. (2017). A Hybrid Scheme for Fine-Grained Search and Access Authorization in Fog Computing Environment. Sensors, 17(6), 1423. https://doi.org/10.3390/s17061423