
PHROG: A Multimodal Feature for Place Recognition

 ,
,  , and
, and
Abstract
:1. Introduction
2. Related Work
2.1. Images and Intermediates Representations
2.2. Features and Multimodality
2.3. Visual Place Recognition Supervision
3. Methodology
3.1. Features Extraction: Detection and Description
3.2. Preliminary Tests on Feature Point Detectors Repeatability
3.3. Multiscale Description Pattern
3.4. Gradient Direction Invariant HoG Features
3.5. Hellinger Kernel on Descriptors
3.6. Bag-of-Words Retrieval
- (Term Frequency) is defined as follows (Equation (6)):where is the number of occurrences of the word having index i in the dictionary, in the image having index j in the memory database, and is the total number of images in the corpus.
- (Inverse Document Frequency) is defined as follows (Equation (7)):where is the total number of images in the corpus and is the number of images where the word occurs.
4. PHROG Applied to the Visual Place Recognition Problem
4.1. Experimental Setup
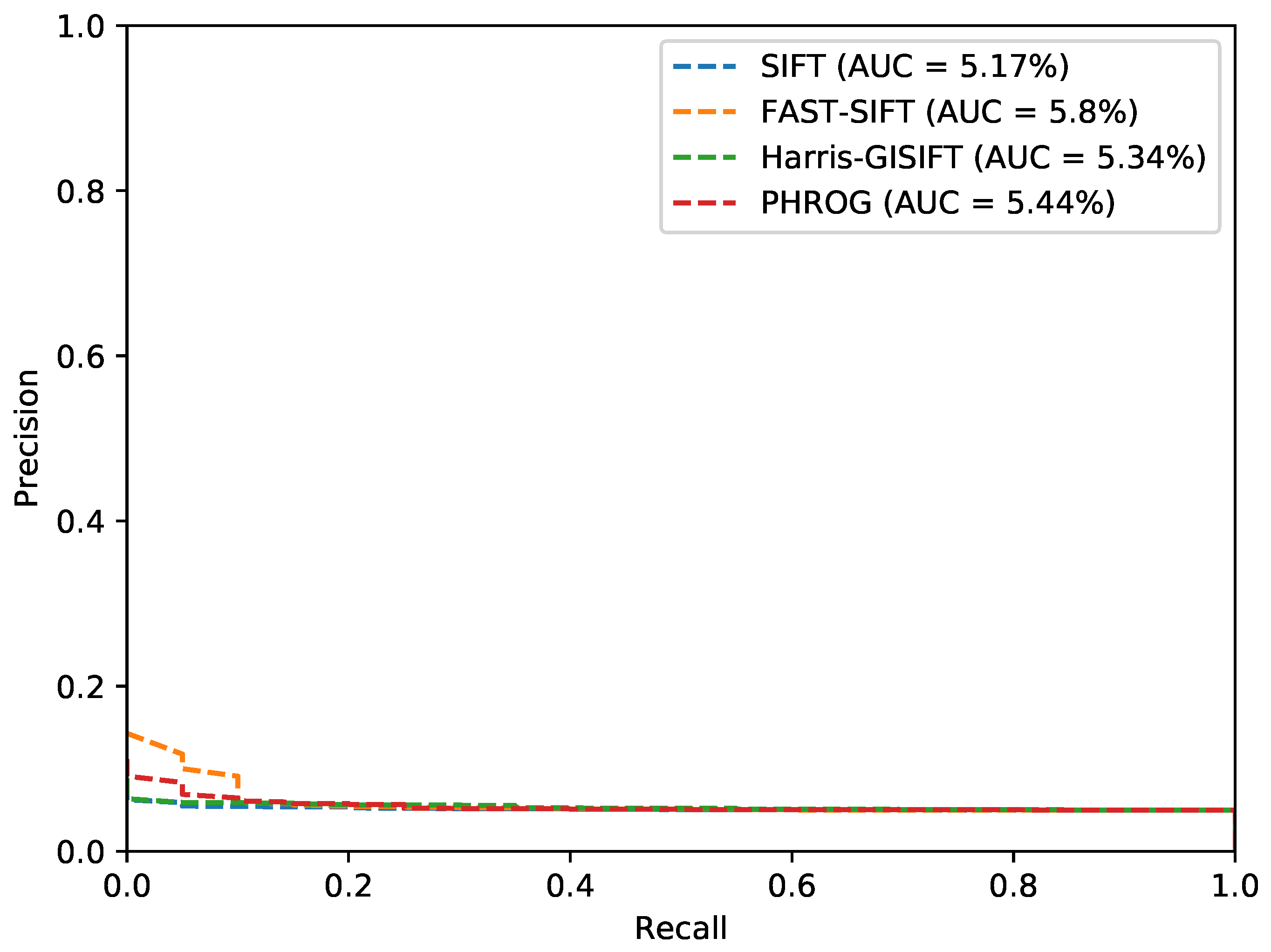
4.2. Experimentations on Visible and Near-InfraRed Images
4.3. Experimentations on Visible and Long-Wavelength InfraRed Images
4.4. Experimentations on VPrice Dataset
4.5. Experimentations on our Visible-SWIR Dataset
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Fox, D.; Ko, J.; Konolige, K.; Limketkai, B.; Schulz, D.; Stewart, B. Distributed multirobot exploration and mapping. Proc. IEEE 2006, 94, 1325–1339. [Google Scholar] [CrossRef]
- Lowry, S.; Sünderhauf, N.; Newman, P.; Leonard, J.J.; Cox, D.; Corke, P.; Milford, M.J. Visual place recognition: A survey. IEEE Trans. Robot. 2016, 32, 1–19. [Google Scholar] [CrossRef]
- Cummins, M.; Newman, P. Appearance-only SLAM at large scale with FAB-MAP 2.0. Int. J. Robot. Res. 2011, 30, 1100–1123. [Google Scholar] [CrossRef]
- Brubaker, M.A.; Geiger, A.; Urtasun, R. Lost! Leveraging the crowd for probabilistic visual self-localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 25–27 June 2013; pp. 3057–3064. [Google Scholar]
- Chapoulie, A.; Rives, P.; Filliat, D. A spherical representation for efficient visual loop closing. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Barcelona, Spain, 6–13 November 2011; pp. 335–342. [Google Scholar]
- Milford, M.J.; Wyeth, G.F. SeqSLAM: Visual route-based navigation for sunny summer days and stormy winter nights. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), St. Paul, MN, USA, 14–18 May 2012; pp. 1643–1649. [Google Scholar]
- Neubert, P.; Sunderhauf, N.; Protzel, P. Appearance change prediction for long-term navigation across seasons. In Proceedings of the European Conference on Mobile Robots (ECMR), Barcelona, Spain, 25–27 September 2013; pp. 198–203. [Google Scholar]
- Naseer, T.; Spinello, L.; Burgard, W.; Stachniss, C. Robust Visual Robot Localization Across Seasons using Network Flows. In Proceedings of the 28th AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- McManus, C.; Churchill, W.; Maddern, W.; Stewart, A.; Newman, P. Shady Dealings: Robust, Long- Term Visual Localisation using Illumination Invariance. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–5 June 2014. [Google Scholar]
- Mikolajczyk, K.; Schmid, C. A performance evaluation of local descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1615–1630. [Google Scholar] [CrossRef] [PubMed]
- Heinly, J.; Dunn, E.; Frahm, J.M. Comparative evaluation of binary features. In Proceedings of the European Conference on Computer Vision (ECCV), Firenze, Italy, 7–13 October 2012; pp. 759–773. [Google Scholar]
- Fraundorfer, F.; Scaramuzza, D. Visual odometry: Part II: Matching, robustness, optimization, and applications. IEEE Robot. Autom. Mag. 2012, 19, 78–90. [Google Scholar] [CrossRef]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Fuentes-Pacheco, J.; Ruiz-Ascencio, J.; Rendón-Mancha, J.M. Visual simultaneous localization and mapping: A survey. Artif. Intell. Rev. 2015, 43, 55–81. [Google Scholar] [CrossRef]
- Garcia-Fidalgo, E.; Ortiz, A. Vision-based topological mapping and localization methods: A survey. Robot. Autonom. Syst. 2015, 64, 1–20. [Google Scholar] [CrossRef]
- Sivic, J.; Zisserman, A. Video Google: A text retrieval approach to object matching in videos. In Proceedings of the 9th IEEE International Conference on Computer Vision (ICCV), Nice, France, 11–17 October 2003; pp. 1470–1477. [Google Scholar]
- Mishkin, D.; Perdoch, M.; Matas, J. Place recognition with WxBS retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Workshop on Visual Place Recognition in Changing Environments, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Koniusz, P.; Yan, F.; Mikolajczyk, K. Comparison of mid-level feature coding approaches and pooling strategies in visual concept detection. Comput. Visi. Image Underst. 2013, 117, 479–492. [Google Scholar] [CrossRef]
- Sünderhauf, N.; Shirazi, S.; Dayoub, F.; Upcroft, B.; Milford, M. On the performance of convnet features for place recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 4297–4304. [Google Scholar]
- Sunderhauf, N.; Shirazi, S.; Jacobson, A.; Dayoub, F.; Pepperell, E.; Upcroft, B.; Milford, M. Place recognition with ConvNet landmarks: Viewpoint-robust, condition-robust, training-free. In Proceedings of the Robotics: Science and Systems Conference (RSS), Rome, Italy, 13–17 July 2015. [Google Scholar]
- Weyand, T.; Kostrikov, I.; Philbin, J. Planet-photo geolocation with convolutional neural networks. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, Netherlands, 8–16 October 2016; pp. 37–55. [Google Scholar]
- Aguilera, C.A.; Aguilera, F.J.; Sappa, A.D.; Aguilera, C.; Toledo, R. Learning Cross-Spectral Similarity Measures with Deep Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–9. [Google Scholar]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [PubMed]
- Abrate, F.; Bona, B.; Indri, M. Experimental EKF-based SLAM for Mini-rovers with IR Sensors Only. In Proceedings of the 3rd European Conference on Mobile Robots (ECMR), Freiburg, Germany, 19–21 September 2007. [Google Scholar]
- Caron, G.; Dame, A.; Marchand, E. Direct model based visual tracking and pose estimation using mutual information. Image Vis. Comput. 2014, 32, 54–63. [Google Scholar] [CrossRef]
- Magnabosco, M.; Breckon, T.P. Cross-spectral visual Simultaneous Localization And Mapping (SLAM) with sensor handover. Robot. Autonom. Syst. 2013, 61, 195–208. [Google Scholar] [CrossRef]
- Maddern, W.; Vidas, S. Towards robust night and day place recognition using visible and thermal imaging. In Proceedings of the Robotics: Science and Systems Conference (RSS), Sydney, Australia, 9–13 July 2012. [Google Scholar]
- Ricaurte, P.; Chilán, C.; Aguilera-Carrasco, C.A.; Vintimilla, B.X.; Sappa, A.D. Feature Point Descriptors: Infrared and Visible Spectra. Sensors 2014, 14, 3690–3701. [Google Scholar] [CrossRef] [PubMed]
- Firmenichy, D.; Brown, M.; Susstrunk, S. Multispectral interest points for RGB-NIR image registration. In Proceedings of the 18th IEEE International Conference on Image Processing (ICIP), Brussels, Belgium, 11–14 September 2011; pp. 181–184. [Google Scholar]
- Mouats, T.; Aouf, N. Multimodal stereo correspondence based on phase congruency and edge histogram descriptor. In Proceedings of the 16th International Conference on Information Fusion (FUSION), Istanbul, Turkey, 9–13 July 2013; pp. 1981–1987. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In Proceedings of the European Conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006; pp. 430–443. [Google Scholar]
- Mikolajczyk, K.; Tuytelaars, T.; Schmid, C.; Zisserman, A.; Matas, J.; Schaffalitzky, F.; Kadir, T.; Van Gool, L. A comparison of affine region detectors. Int. J. Comput. Vis. 2005, 65, 43–72. [Google Scholar] [CrossRef]
- Tuytelaars, T.; Mikolajczyk, K. Local invariant feature detectors: A survey. Found. Trends® Comput. Graph. Vis. 2008, 3, 177–280. [Google Scholar] [CrossRef]
- Harris, C.; Stephens, M. A combined corner and edge detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; p. 147. [Google Scholar]
- Shi, J.; Tomasi, C. Good features to track. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 21–23 June 1994; pp. 593–600. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Aguilera, C.A.; Sappa, A.D.; Toledo, R. LGHD: A feature descriptor for matching across non-linear intensity variations. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Québec City, QC, Canada, 27–30 September 2015; pp. 178–181. [Google Scholar]
- Arandjelović, R.; Zisserman, A. Three things everyone should know to improve object retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2911–2918. [Google Scholar]
- Brown, M.; Susstrunk, S. Multi-spectral SIFT for scene category recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 20–25 June 2011; pp. 177–184. [Google Scholar]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modality as Memory | Dataset | |||||
|---|---|---|---|---|---|---|
| Urban | Street | Country | ||||
| Visible | NIR | Visible | NIR | Visible | NIR | |
| SIFT-SIFT | 96% | 94% | 78% | 66% | 40% | 34% |
| SIFT-GISIFT | 98% | 94% | 70% | 64% | 34% | 32% |
| FAST-SIFT | 100% | 100% | 96% | 96% | 75% | 76% |
| Harris-SIFT | 100% | 98% | 88% | 92% | 73% | 61% |
| Harris-GISIFT | 100% | 100% | 90% | 90% | 69% | 67% |
| Our Method | 100% | 100% | 96% | 94% | 73% | 80% |
| Method | Modality Used as Memory Set | |
|---|---|---|
| LWIR | Visible | |
| SIFT-SIFT | 9% | 9% |
| SIFT-GISIFT | 11% | 9% |
| FAST-SIFT | 22% | 9% |
| Harris-SIFT | 18% | 20% |
| Harris-GISIFT | 52% | 38% |
| Our method | 61% | 56% |
| Method | Efficiency |
|---|---|
| SIFT-SIFT | 36% |
| SIFT-GISIFT | 42% |
| FAST-SIFT | 68% |
| Harris-SIFT | 52% |
| Harris-GISIFT | 47% |
| Our method | 73% |
| Method | Modality Used as Memory Set | |
|---|---|---|
| SWIR | Visible | |
| SIFT-SIFT | 15% | 5% |
| SIFT-GISIFT | 20% | 10% |
| FAST-SIFT | 15% | 20% |
| Harris-SIFT | 15% | 10% |
| Harris-GISIFT | 25% | 15% |
| Our method | 35% | 15% |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bonardi, F.; Ainouz, S.; Boutteau, R.; Dupuis, Y.; Savatier, X.; Vasseur, P. PHROG: A Multimodal Feature for Place Recognition. Sensors 2017, 17, 1167. https://doi.org/10.3390/s17051167
Bonardi F, Ainouz S, Boutteau R, Dupuis Y, Savatier X, Vasseur P. PHROG: A Multimodal Feature for Place Recognition. Sensors. 2017; 17(5):1167. https://doi.org/10.3390/s17051167
Chicago/Turabian StyleBonardi, Fabien, Samia Ainouz, Rémi Boutteau, Yohan Dupuis, Xavier Savatier, and Pascal Vasseur. 2017. "PHROG: A Multimodal Feature for Place Recognition" Sensors 17, no. 5: 1167. https://doi.org/10.3390/s17051167
APA StyleBonardi, F., Ainouz, S., Boutteau, R., Dupuis, Y., Savatier, X., & Vasseur, P. (2017). PHROG: A Multimodal Feature for Place Recognition. Sensors, 17(5), 1167. https://doi.org/10.3390/s17051167