1. Introduction
In recent years, enormous amounts of data on human or animal behavior have been collected using 2D and 3D cameras, and automated methods for detecting and tracking individuals or animals have begun to play an important role in studies of experimental biology, behavioral science, and related disciplines. Tracking target is prone to being lost due to managing appearance changes, fast motion, and other factors. This results in the problem of detecting the tracking target again. Traditional detection methods (such as the detector in TLD (Tracking-Learning-Detection) [
1]) treat every frame independently and perform full scanning of an input frame to localize all appearances that have been observed and learned in the past. It is inefficient and time consuming, especially for real-time tracking. However, foreground segmentation requires a detector to scan only the foreground region of an input frame using a scanning window, which greatly reduces the scanning time of the detector and also improves the classification accuracy. At present, a variety of foreground extraction methods have been proposed, such as the frame difference method [
2], the background subtraction method [
3], the optical flow method [
4] and the block matching method [
5]. The core of a background subtraction algorithm is the modeling of the background. Zones that show notable differences between the current frame and the background model are deemed to correspond to moving objects. Generally, background subtraction algorithms include the Average Background Model (AVG) algorithm, the Gaussian Mixture Model (GMM) algorithm [
6], the Codebook algorithm [
7] and the Visual Background Extractor (ViBe) algorithm [
8,
9,
10]. The ViBe algorithm is a fast motion detection algorithm proposed by Olivier Barnich et al. [
8]. It is characterized by a high processing efficiency and a good detection effect.
Most of the conventional methods mentioned above were designed for application to color images. However, depth is another interesting cue for segmentation that is less strongly affected by the adverse effects encountered in classical color segmentation, such as shadow and highlight regions. Depth cameras, such as the Microsoft Kinect and the ASUS Xtion Pro (ASUS, Taiwan), are able to record real-time depth video together with color video. Because of their beneficial depth imaging features and moderate price, such depth cameras are broadly applied in intelligent surveillance, medical diagnostics, and human–computer interaction applications [
11,
12,
13]. The Kinect sensor is not sensitive to light conditions; it works well either in a bright room or in a pitch black one. This makes depth images more reliable and easier for a computer program to understand.
Most studies using the Kinect sensor have focused on human body detection and tracking [
14,
15,
16]. The Histogram of Oriented Depths (HOD) detection algorithm, proposed in [
14], can be used to match human body contour information in an image. In [
15], a model was presented for detecting humans using a 2D head contour model and a 3D head surface model. In these studies, the computational complexity of the feature generation and matching process was relatively high.
Crabb et al. [
17] and Schiller et al. [
18] focused on combining the depth and color information obtained by low-resolution ToF (Time of Flight) cameras, but their methods are not well suited for video surveillance. For example, the method of Crabb et al. [
17] requires the definition of a distance plane where no foreground object is located behind any part of the background. Fernandez-Sanchez et al. [
19] proposed an adaptation of the Codebook background subtraction algorithm that focuses on different sensor channels. In [
20], the method presented combines a mixture of Gaussian-based background subtraction algorithms with a new Bayesian network. The Bayesian network exploits the characteristics of the depth data using two dynamic models that estimate the spatial and depth evolution of the foreground/background regions. Camplani et al. [
21] proposed a foreground/background segmentation method that combines two statistical classifiers using color and depth features. The combination of depth and color cues makes it possible to solve color segmentation issues such as shadows, reflections and camouflage. However, the computations required are too complicated. The fundamental idea of the combination strategy in [
22] is that when depth measurement is reliable, the background subtraction from depth takes top priority. Otherwise, RGB (Red-Green-Blue) is used as an alternative. Noise is removed from the depth data using a noise model. They define the background as the stationary part of a scene. The Gaussian mixture model is observed for each pixel over a sequence of frames. These existing RGB-D (RGB and Depth) segmentation algorithms either suffer from ghosts, such as Depth-Extended Codebook ( DECB) [
19] and 4D version of Mixture of Gaussians (MOG4D) [
18], or fail to achieve real-time performance [
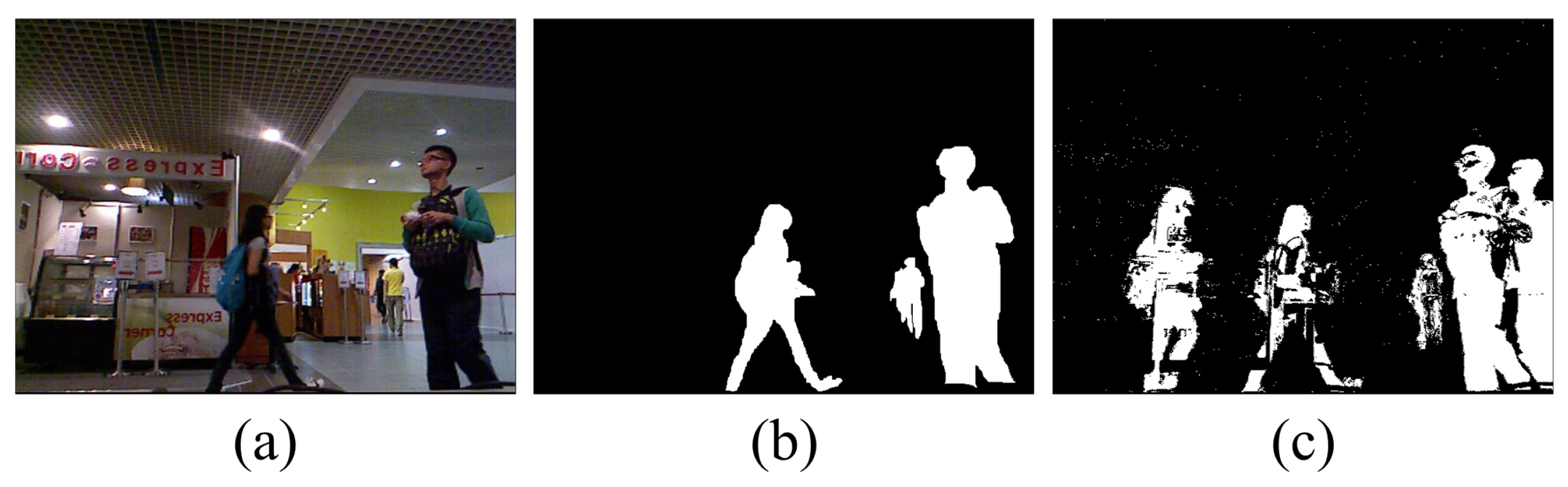
21]. A ghost is a set of interconnected points that is detected as a moving object but does not correspond to any real object (see
Figure 1c). Ghosting greatly reduces the effectiveness of motion detection.
In this paper, we propose an adaptive ViBe background subtraction algorithm that fuses the depth and color information obtained by the Kinect sensor to segment foreground regions. First, a background model and a depth model are established. Then, based on these models, we develop a new updating strategy that can efficiently eliminate ghosting and black shadows. The improved algorithm is evaluated using an RGB-D benchmark dataset [
23] in addition to our own test RGB-D video and achieves good results that provide a perfect basis for subsequent feature extraction and behavior recognition.
The remainder of the paper is organized as follows. In
Section 2, we briefly describe the original ViBe algorithm. Then, the improved algorithm is developed in
Section 3. In
Section 4, experimental results and discussions are presented. Finally, we conclude the paper in
Section 5.
2. ViBe Background Subtraction Algorithm
In this section, we first review the basic ViBe algorithm. Then, we identify its disadvantages. This technique involves modeling the background based on a set of samples for each pixel. New frames are compared with the background model, pixel by pixel, to determine whether each pixel belongs to the background or the foreground.
2.1. Pixel Model
Background model construction begins from the first frame. Formally, let denote the value in a given Euclidean color space associated with the pixel located at x in the image, and let be the background sample value with index i. Each background pixel x is modeled based on a collection of N background sample values .
2.2. Classification Process
If the Euclidean distance from a sample in to is below a threshold R, then is regarded as a neighbor of . We define the number of neighbors of the pixel located at x as . When is greater than a threshold , x is a background pixel. Otherwise, it is a foreground pixel.
2.3. Updating the Background Model over Time
It is necessary to continuously update the background model with each new frame. This is a crucial step for achieving accurate results over time. When a pixel
x is classified as background, the background model updating strategy is triggered. A sample is chosen randomly. Mathematically, the probability that a sample present in the model at time
t will be preserved is given by
. Under the assumption of time continuity, for any later time
, this probability is equal to:
which can be rewritten as:
This expression shows that the expected remaining lifespan of any sample value in the model decays exponentially according to a random subsampling strategy. As in [
8], we adopt a time subsampling factor of
, meaning that a background pixel value has one chance in
of being selected to update its pixel model.
Reduced pseudo-code for the ViBe construction phase is given in Algorithm 1.
The classical ViBe algorithm has the advantages of simple processing and outstanding performance. Its main drawback is the occurrence of ghosting. A moving object in the first frame often causes ghosting. To resolve this problem, we can take advantage of depth information. The Kinect sensor records the distance to any object that is placed in front of it. This feature can be utilized to determine whether a foreground pixel is a ghost.
| Algorithm 1 Algorithm for ViBe construction |
- 1:
procedure ViBe(image, N, R, , ) - 2:
for do - 3:
while and do - 4:
Calculate Euclidean distance between and - 5:
if then - 6:
- 7:
end if - 8:
- 9:
end while - 10:
if then - 11:
Store that pixel ∈ background - 12:
Update current pixel background model with probability - 13:
Update neighboring pixel background model with probability - 14:
else - 15:
Store that pixel ∈ foreground - 16:
end if - 17:
end for - 18:
end procedure
|
4. Experiments and Results
The program development environment consisted of VC++2010, OpenCV SDK2.4.3 and OpenNI1.5.2.7. The PC was equipped with a Core Duo 2 CPU E7500 with 2.00 GB of RAM. The video frame rate was 30 fps, and the size of both the color and depth images was 640 × 480. We compared the results of our method with those obtained using two state-of-the-art RGB-D fusion-based background subtraction algorithms, namely, MOG4D [
18] and DECB [
19], as well as the ViBe algorithm on the color images [
8] (ViBe) and the ViBe based only on depth (ViBe1D). To evaluate these algorithms objectively through a quantitative analysis, we required a benchmark that would provide information on both color and depth images. The chosen benchmark sequences are publicly available at [
23]. However, the depth image sequences provided by this source could not be utilized directly. The depth images are in the 16-bit png format, with the first three bits swapped with the last. We needed to swap them back after reading each image to obtain values for each pixel corresponding to the distance from the Kinect sensor to the object in mm. The sequences
,
,
and
from [
23] and our own
were chosen for testing.
Many metrics can be used to assess the output of a background subtraction algorithm given a series of ground truths for several frames in each sequence. Various relative metrics can be calculated based on the numbers of true and false positives and negatives (
,
,
, and
). These metrics are most widely used in computer vision to assess the performance of a binary classifier, as in [
24].
is the percentage of wrong classifications in the entire image. This measure represents a trade-off between the abilities of an algorithm to detect foreground and background pixels. In general, a lower value of this estimator indicates better performance.
The proposed approach relies on several parameters originating from the ViBe algorithm:
N,
R,
, and
in [
8]. Considering our aim of evaluating the overall performance of the algorithms, we chose a unique set of parameters that yielded sufficiently good results on the complete dataset. According to [
8], and in our experience, the use of a radius
and a time subsampling factor
leads to excellent results in every situation. To determine optimal values for
, we computed the evolution of the
of DEVB on the
sequence for
ranging from 1 to 20. The other parameters were fixed to
, and
. Based on joint consideration of the value of
in [
8] and in
Figure 2, we set the optimal value of
to
. As
rises, the computational cost increases. Once the value of 2 has been selected for
, we study the influence of the parameter
N on the performance of DEVB.
Figure 3 shows the percentages obtained using the
sequence for
N ranging from 2 to 50. We observe that higher values of
N provide better performance. However, they tend to saturate for values higher than 20. We select N at the beginning of the basin, that is,
. To ensure a fair comparison of the performances of the various algorithms, all algorithms were applied without morphological filtering.
The first sequence,
, shows a child and two adults playing in a living room. The main difficulties in this sequence are light reflections and subjects that sometimes remain still or move only slowly.
Figure 4 shows the segmentations produced by the four methods as well as the original color and depth frames and the hand-generated segmentations (ground truths). Ghosts appear in some frames for MOG4D, DECB, ViBe and ViBe1D, greatly reducing the effectiveness of foreground detection. The ViBe algorithm yields worse results than the other algorithms in frame 160 because of the reflection in the color image. In general, the DEVB algorithm achieves improvement over ViBe by virtue of the additional depth model, which allows the ghosts and black shadows to be effectively removed.
Table 1 shows the quantitative
results obtained by the four approaches on the evaluation frames from the
sequence. All RGB-D approaches achieve improvements with respect to ViBe, obtaining lower
values. A lower
value indicates better performance. The proposed DEVB algorithm achieves the lowest average error rate of 7.023% in
Table 1, which indicates that our method performs better than the other algorithms.
The second sequence,
, shows two individuals walking in front of a coffee shop. The main difficulties presented by this sequence are flickering lights and areas where depth information cannot be obtained by the active infrared sensor.
Figure 5 shows the segmentations produced by the four approaches. Our DEVB algorithm achieves good results, whereas ghosting greatly reduces the effectiveness of the other algorithms in foreground extraction.
Table 2 shows the quantitative
results obtained by the four approaches on the evaluation frames from the
sequence. The proposed DEVB algorithm achieves the lowest
of
, which indicates that our method performs better than the other algorithms. ViBe yields the worst result of
on this sequence.
The third sequence,
, shows a few people walking in and out of the camera field. In addition, there are flickering lights on the ceiling and sudden illumination changes.
Figure 6 shows the segmentations produced by the four approaches. DECB and ViBe1D are less affected by the sudden illumination changes. In addition to ghosting, ViBe1D results in black shadows in frames 35 and 62. The reason for the generation of black shadows is that a new moving object reaches the previous position of an old target. Because the pixel values are similar, the foreground is misclassified as background.
Table 3 shows the quantitative
results obtained by the four approaches on the evaluation frames from the
sequence. The DEVB algorithm achieves
in frame 8, whereas the
values obtained by the other algorithms are higher by more than a factor of three. Moreover, despite being affected by illumination changes in the RGB space, DEVB achieves an average
of
(
Table 3), indicating that our method is fairly robust to difficult situations.
The fourth sequence,
, shows a lady walking in front of a coffee shop. The scenario is similar to the
sequence discussed above.
Figure 7 shows the segmentations produced by the four approaches. A large amount of noise is generated by the ViBe1D algorithm because of the holes in the original depth image.
Table 4 shows the quantitative
results obtained by the four approaches on the evaluation frames from the
sequence. The proposed DEVB algorithm achieves
. This value is the lowest in
Table 4, which indicates that our method performs better than the other algorithms. ViBe1D obtains the worst result in this sequence, with
.
The fifth sequence,
, is from our own test RGB-D video. The pigeon has a wide range of activities in the scene as shown in
Figure 8. It can jump onto a high platform and walk beside a water bottle and a feeder, which serve as the background. Because of the fast and abrupt pose changes of the pigeon, most of the tracking algorithms fail to track in most of the frames. We focus on detection technology and on utilizing the corresponding depth images, which extracts foregrounds more effectively and more efficiently. In addition to ghosting, ViBe1D results in much noise because of the holes in the original depth image. DECB suffers from ghosting in all test frames.
Table 5 shows the quantitative
results obtained by the four approaches on the evaluation frames from the
sequence. The proposed DEVB algorithm achieves
. This value is the smallest in
Table 5, which indicates that our method performs better than the other algorithms. ViBe1D obtains the worst result on this sequence, with
.
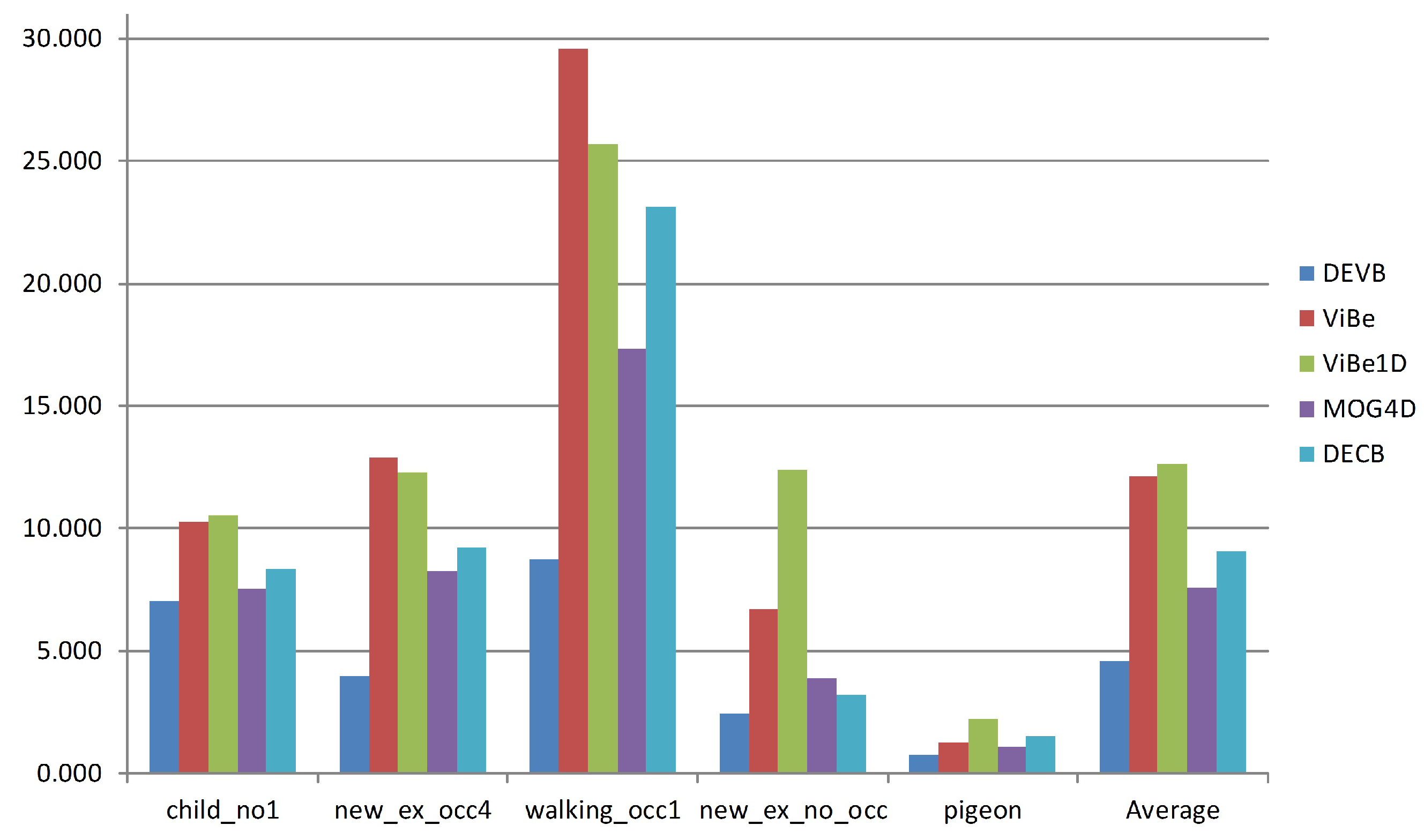
Finally,
Figure 9 shows the average
value obtained by each approach on each sequence. According to this figure, DEVB yields the best results on every sequence. The
sequence is particularly complicated because of the high pedestrian flow; consequently, for each algorithm, the error rate is considerably increased.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}