
Time Series Data Analysis of Wireless Sensor Network Measurements of Temperature


Abstract
:1. Introduction
2. Previous Work
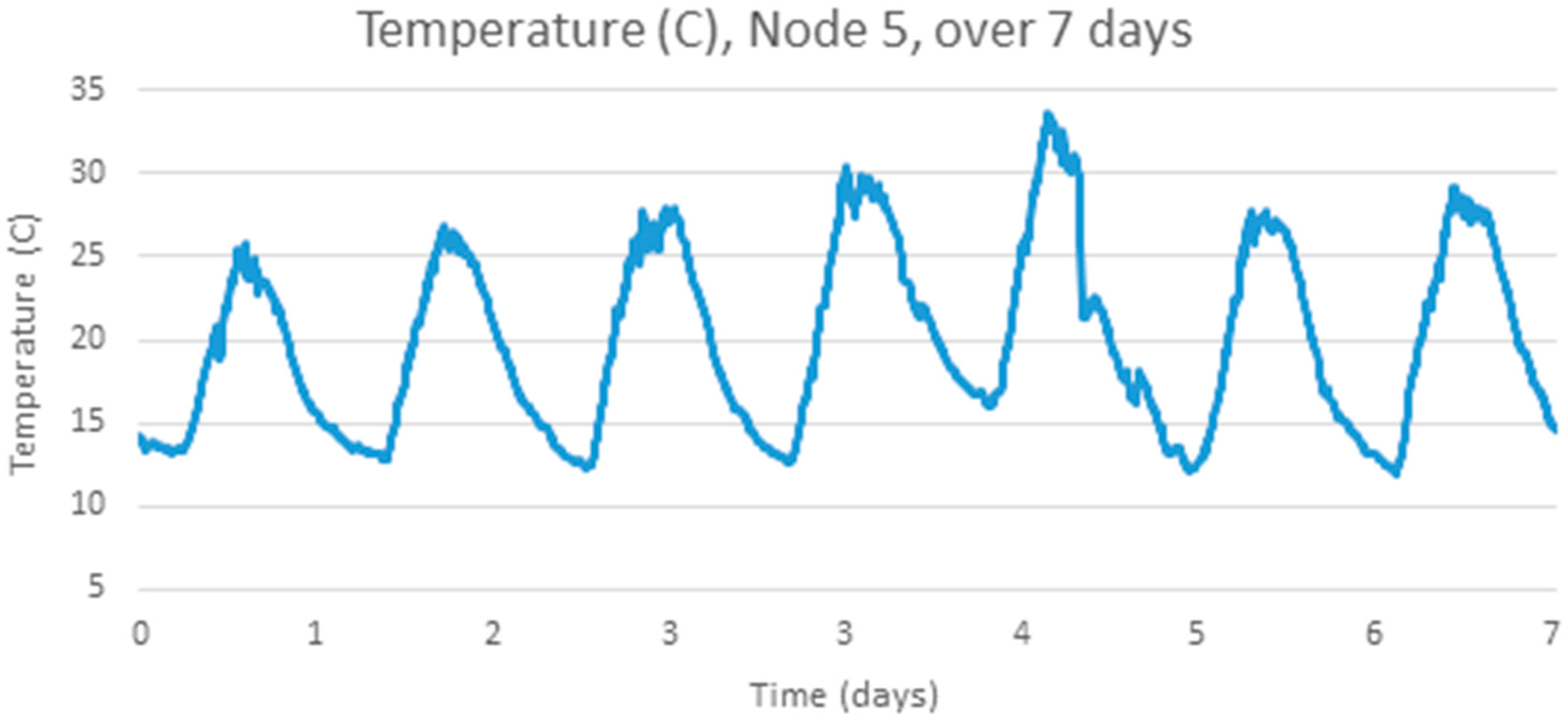
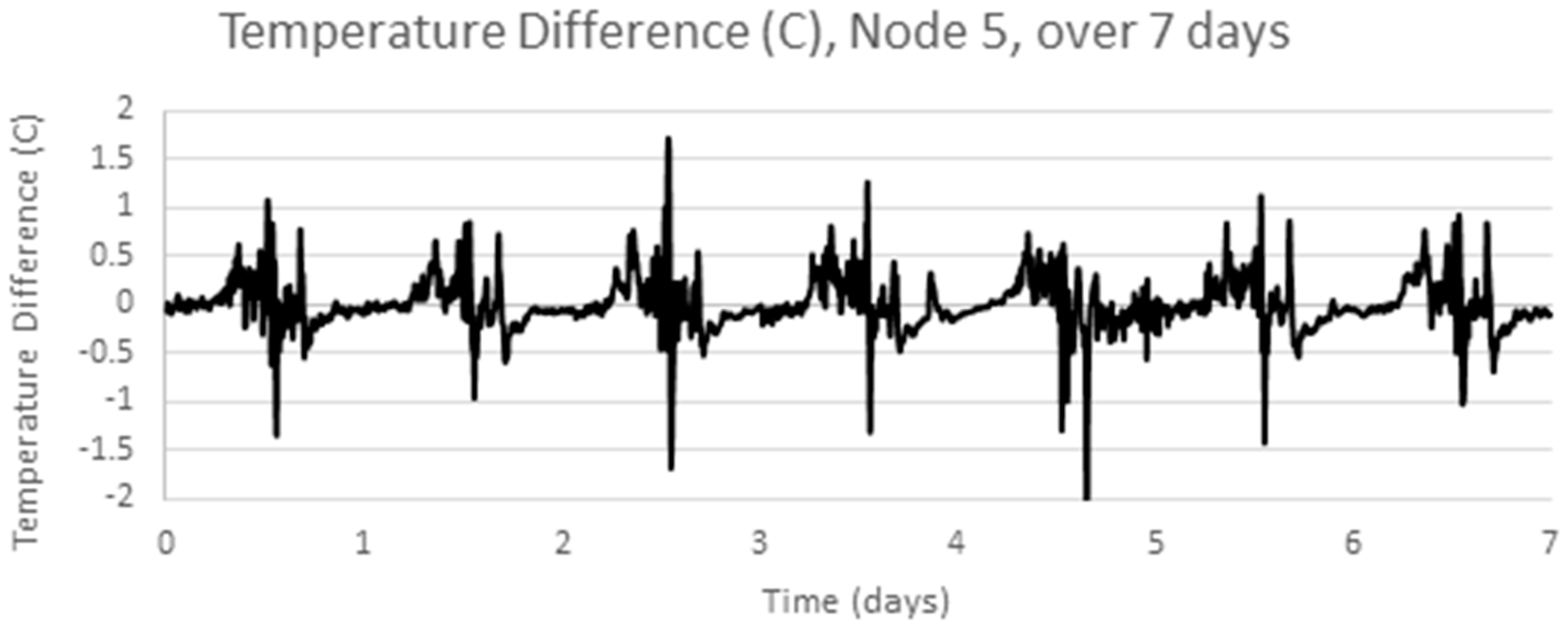
3. Temperature Data from Springbrook WSN Deployment
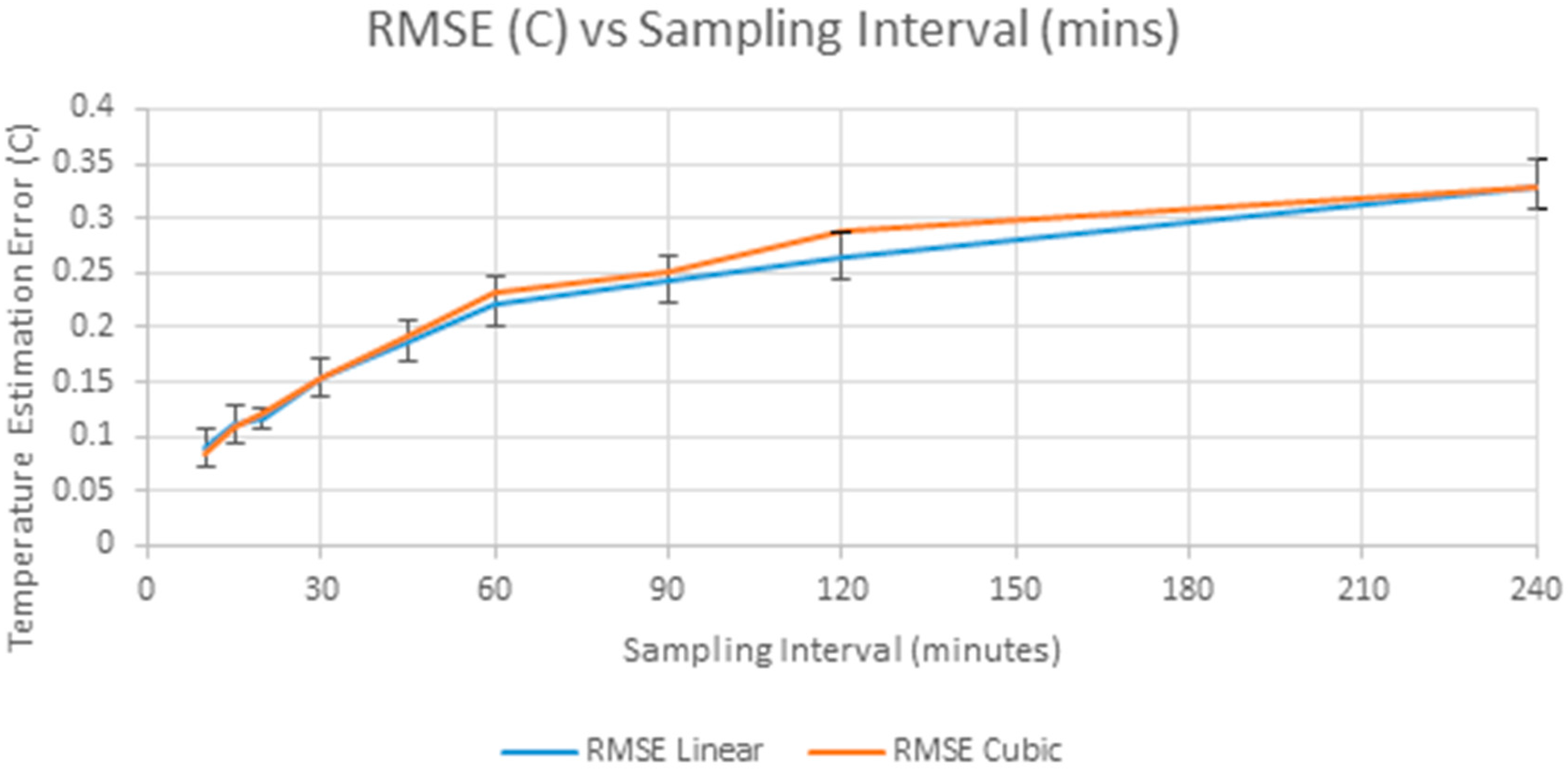
4. Accuracy versus Sampling Interval
5. Repeating for Another Data Series
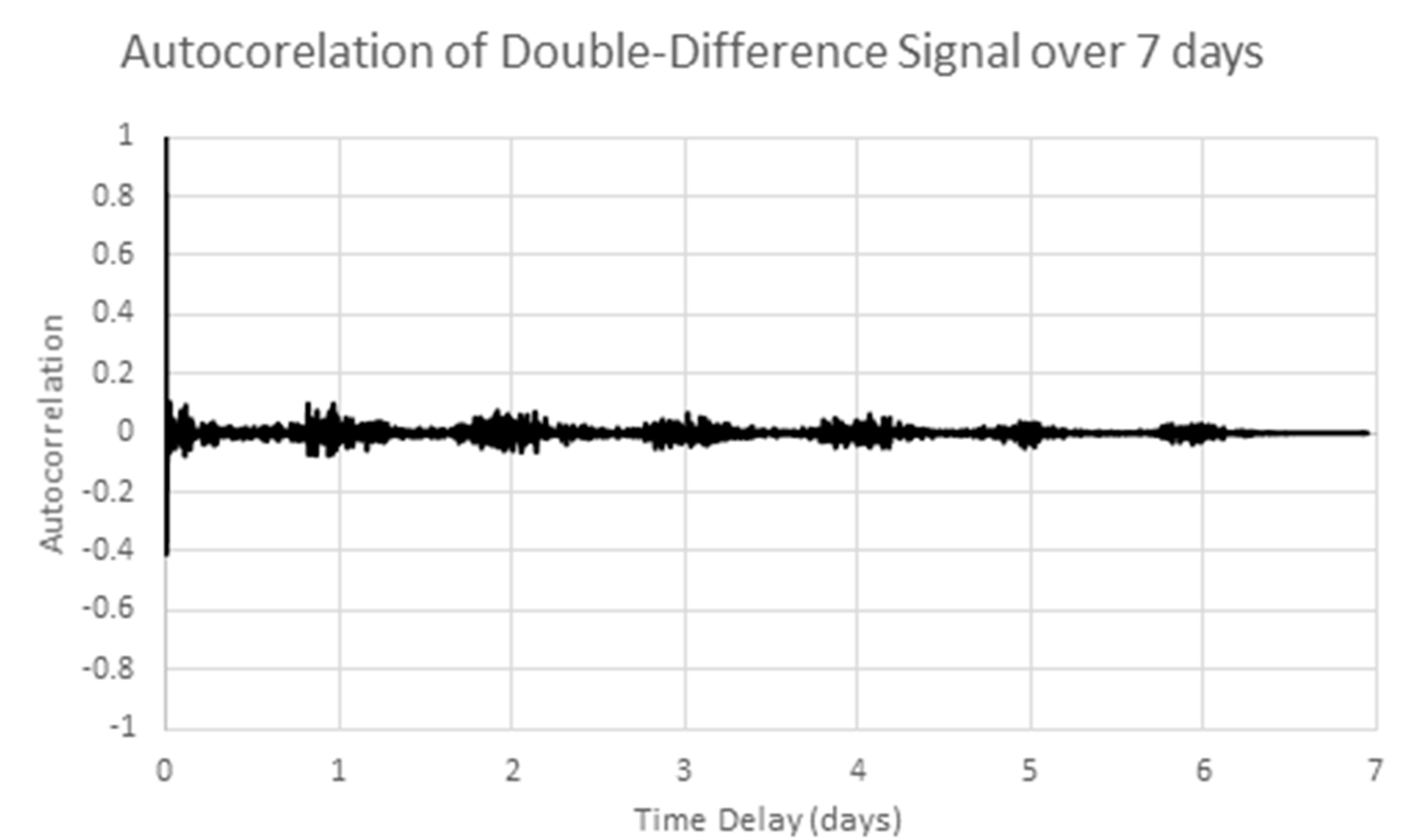
6. Time Series Analysis of Random Processes
6.1. Time Series and Stochastic Process
6.2. Time Series Model Development Strategy
6.2.1. Model Specification
6.2.2. Parameter Estimation
6.2.3. Model Diagnostics
6.2.4. Time Series Forecasting
7. Forecasting Experiments
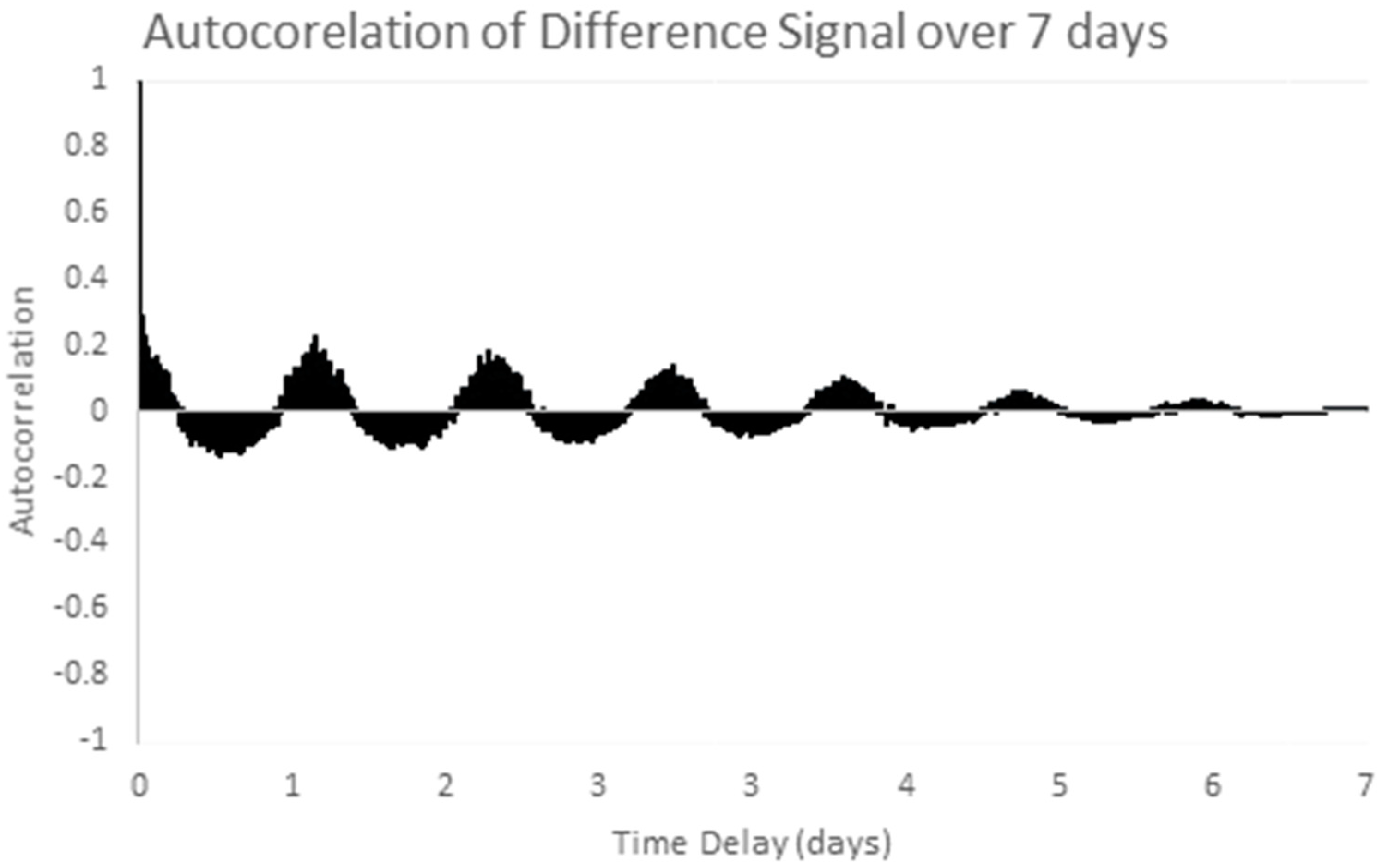
7.1. Structural Analysis of Time Series
7.2. Model Order Selection
7.3. Forecasting
8. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Corke, P.; Wark, T.; Jurdak, R.; Hu, W.; Valencia, P.; Moore, D. Environmental wireless sensor networks. Proc. IEEE 2010, 98, 1903–1917. [Google Scholar] [CrossRef]
- Wark, T.; Hu, W.; Corke, P.; Hodge, J.; Keto, A.; Mackey, B.; Foley, G.; Sikka, P.; Brunig, M. Springbrook: Challenges in developing a long-term, rainforest wireless sensor network. In Proceedings of the ISSNIP 2008 International Conference on Intelligent Sensors, Sensor Networks and Information Processing, Sydney, Australia, 15–18 December 2008. [Google Scholar]
- Pollock, D.S.G.; Green, R.C.; Nguyen, T. Handbook of Time Series Analysis, Signal Processing, and Dynamics; Academic Press: San Diego, CA, USA, 1999. [Google Scholar]
- Hart, J.K.; Martinez, K. Environmental sensor networks: A revolution in the earth system science? Earth Sci. Rev. 2006, 78, 177–191. [Google Scholar] [CrossRef]
- Dutta, P.; Aoki, P.M.; Kumar, N.; Mainwaring, A.; Myers, C.; Willett, W.; Woodruff, A. Common sense: Participatory urban sensing using a network of handheld air quality monitors. In Proceedings of the 7th ACM conference on embedded networked sensor systems, Berkeley, CA, USA, 4–6 November 2009; pp. 349–350. [Google Scholar]
- Thepvilojanapong, N.; Ono, T.; Tobe, Y. A deployment of fine-grained sensor network and empirical analysis of urban temperature. Sensors 2010, 10, 2217–2241. [Google Scholar] [CrossRef] [PubMed]
- Cao, X.; Chen, J.; Xiao, Y.; Sun, Y. Building-environment control with wireless sensor and actuator networks: Centralized versus distributed. IEEE Trans. Ind. Electron. 2010, 57, 3596–3605. [Google Scholar]
- Leonard, N.E.; Paley, D.A.; Lekien, F.; Sepulchre, R.; Fratantoni, D.M.; Davis, R.E. Collective motion, sensor networks, and ocean sampling. Proc. IEEE 2007, 95, 48–74. [Google Scholar] [CrossRef]
- De Vito, S.; Fattoruso, G. Wireless chemical sensor networks for air quality monitoring. In Proceedings of the 14th International Meeting on Chemical Sensors (IMCS 2012), Nuremberg, Germany, 20–23 May 2012; pp. 641–644. [Google Scholar]
- Lengfeld, K.; Ament, F. Observing local-scale variability of near-surface temperature and humidity using a wireless sensor network. J. Appl. Meteorol. Climatol. 2012, 51, 30–41. [Google Scholar] [CrossRef]
- Cardell-Oliver, R.; Smettem, K.; Kranz, M.; Mayer, K. Field testing a wireless sensor network for reactive environmental monitoring [soil moisture measurement]. In Proceedings of the Intelligent Sensors, Sensor Networks and Information Processing Conference (ISSNIP 2004), Melbourne, Australia, 14–17 December 2004; pp. 7–12. [Google Scholar]
- Umer, M.; Kulik, L.; Tanin, E. Spatial interpolation in wireless sensor networks: Localized algorithms for variogram modeling and kriging. Geoinformatica 2010, 14, 101. [Google Scholar] [CrossRef]
- Shinomiya, J.; Teranishi, Y.; Harumoto, K.; Takeuchi, S.; Nishio, S. An examination of sensor data collection method for spatial interpolation on hierarchical delaunay overlay network. In Proceedings of the 11th International Conference on Mobile Data Management (MDM 2010), Kansas City, MO, USA, 23–26 May 2010; pp. 407–412. [Google Scholar]
- Guo, D.; Qu, X.; Huang, L.; Yao, Y. Sparsity-based spatial interpolation in wireless sensor networks. Sensors 2011, 11, 2385–2407. [Google Scholar] [CrossRef] [PubMed]
- Cortés, J. Distributed kriged kalman filter for spatial estimation. IEEE Trans. Autom. Control 2009, 54, 2816–2827. [Google Scholar] [CrossRef]
- Liu, C.; Wu, K.; Pei, J. An energy-efficient data collection framework for wireless sensor networks by exploiting spatiotemporal correlation. IEEE Trans. Parallel Distrib. Syst. 2007, 18, 1010–1023. [Google Scholar] [CrossRef]
- Law, Y.W.; Chatterjea, S.; Jin, J.; Hanselmann, T.; Palaniswami, M. Energy-efficient data acquisition by adaptive sampling for wireless sensor networks. In Proceedings of the 2009 International Conference on Wireless Communications and Mobile Computing: Connecting the World Wirelessly, Leipzig, Germany, 21–24 June 2009; pp. 1146–1151. [Google Scholar]
- Le Borgne, Y.-A.; Santini, S.; Bontempi, G. Adaptive model selection for time series prediction in wireless sensor networks. Signal Process. 2007, 87, 3010–3020. [Google Scholar] [CrossRef]
- Miranda, K.; Razafindralambo, T. Using efficiently autoregressive estimation in wireless sensor networks. In Proceedings of the International Conference onComputer, Information and Telecommunication Systems (CITS 2013), Athens, Greece, 7–8 May 2013; pp. 1–5. [Google Scholar]
- Liu, C.; Wu, K.; Tsao, M. Energy efficient information collection with the ARIMA model in wireless sensor networks. In Proceedings of the IEEE Global Telecommunications Conference (GLOBECOM ’05.), St. Louis, MO, USA, 28 November–2 December 2005; Volume 5, pp. 2470–2474. [Google Scholar]
- Aderohunmu, F.A.; Paci, G.; Brunelli, D.; Deng, J.D.; Benini, L.; Purvis, M. An application-specific forecasting algorithm for extending wsn lifetime. In Proceedings of the IEEE International Conference on Distributed Computing in Sensor Systems (DCOSS 2013), Cambridge, MA, USA, 20–23 May 2013; pp. 374–381. [Google Scholar]
- Amidi, A. Arima based value estimation in wireless sensor networks. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, 40, 41. [Google Scholar] [CrossRef]
- Pardo, J.; Zamora-Martínez, F.; Botella-Rocamora, P. Online learning algorithm for time series forecasting suitable for low cost wireless sensor networks nodes. Sensors 2015, 15, 9277–9304. [Google Scholar] [CrossRef] [PubMed]
- Tulone, D.; Madden, S. PAQ: Time series forecasting for approximate query answering in sensor networks. In European Workshop on Wireless Sensor Networks; Springer: Zurich, Switzerland, 2006; pp. 21–37. [Google Scholar]
- Kusy, B.; Richter, C.; Bhandari, S.; Jurdak, R.; Neldner, V.J.; Ngugi, M.R. Evidence-based landscape rehabilitation through microclimate sensing. In Proceedings of the 12th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON 2015), Seattle, WA, USA, 22–25 June 2015; pp. 372–380. [Google Scholar]
- Kyriakidis, P.C.; Journel, A.G. Geostatistical space–time models: A review. Math. Geol. 1999, 31, 651–684. [Google Scholar] [CrossRef]
- Cryer, J.; Chen, K. Time Series Analysis with Applications in R, 2nd ed.; Springer: Berlin, Germany, 2008. [Google Scholar]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- De Gooijer, J.G.; Hyndman, R.J. 25 years of time series forecasting. Int. J. Forecast. 2006, 22, 443–473. [Google Scholar] [CrossRef]
- Ihaka, R.; Gentleman, R. R: A language for data analysis and graphics. J. Comput. Graph. Stat. 1996, 5, 299–314. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Khandakar, Y. Automatic Time Series for Forecasting: The Forecast Package for R; Monash University, Department of Econometrics and Business Statistics: Melbourne, Australia, 2007. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sampling Interval (Mins) | RMSE Linear | MAE Linear | RMSE Cubic | MAE Cubic | 99% Linear | 99% Cubic |
|---|---|---|---|---|---|---|
| 10 | 0.0884 | 0.0528 | 0.0852 | 0.0519 | 0.3250 | 0.2893 |
| 15 | 0.1097 | 0.0664 | 0.1088 | 0.0669 | 0.4000 | 0.4037 |
| 20 | 0.1166 | 0.0755 | 0.1228 | 0.0793 | 0.4200 | 0.4496 |
| 30 | 0.1527 | 0.0937 | 0.1531 | 0.0962 | 0.5800 | 0.5709 |
| 45 | 0.1865 | 0.1152 | 0.1921 | 0.1190 | 0.6867 | 0.7410 |
| 60 | 0.2224 | 0.1335 | 0.2330 | 0.1430 | 0.8425 | 0.8753 |
| 90 | 0.2439 | 0.1566 | 0.2507 | 0.1629 | 0.9133 | 0.8774 |
| 120 | 0.2646 | 0.1720 | 0.2893 | 0.1882 | 0.9425 | 1.0206 |
| 240 | 0.3297 | 0.2161 | 0.3290 | 0.2215 | 1.2758 | 1.2189 |
| Sampling Interval (Mins) | RMSE Linear | MAE Linear | RMSE Cubic | MAE Cubic | 99% Linear | 99% Cubic |
|---|---|---|---|---|---|---|
| 10 | 0.1746 | 0.0941 | 0.1751 | 0.0960 | 0.6740 | 0.6366 |
| 15 | 0.2085 | 0.1164 | 0.2185 | 0.1211 | 0.7554 | 0.8286 |
| 20 | 0.2342 | 0.1360 | 0.2487 | 0.1459 | 0.8862 | 0.9436 |
| 30 | 0.2723 | 0.1588 | 0.2846 | 0.1693 | 1.0099 | 1.0027 |
| 45 | 0.3664 | 0.2029 | 0.3694 | 0.2087 | 1.2578 | 1.3131 |
| 60 | 0.4655 | 0.2498 | 0.4635 | 0.2493 | 1.5781 | 1.5309 |
| 90 | 0.5837 | 0.3093 | 0.5762 | 0.3033 | 1.9658 | 1.8047 |
| 120 | 0.6057 | 0.3836 | 0.5840 | 0.3663 | 2.1344 | 2.0859 |
| 240 | 0.9780 | 0.6687 | 0.8121 | 0.5515 | 3.0073 | 2.7782 |
| Sampling Rate (Minutes) | Fitted Models |
|---|---|
| 5 | ARIMA(3,1,1) |
| 10 | ARIMA(2,1,2) |
| 15 | ARIMA(1,1,3) |
| 20 | ARIMA(1,1,3) |
| 30 | ARIMA(2,1,1) |
| 60 | ARIMA(1,1,0) |
| 120 | ARIMA(3,1,1) |
| Forecast | Simple Models | ARIMA Models Sampling Intervals (Minutes) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Time (Mins) | Zero Diff | Same Diff | 5 | 10 | 15 | 20 | 30 | 60 | 120 |
| 5 | 0.33 | 0.49 | 0.33 | 0.17 | 0.13 | 0.13 | 0.11 | 0.12 | 0.12 |
| 10 | 0.48 | 0.78 | 0.45 | 0.45 | 0.38 | 0.39 | 0.35 | 0.34 | 0.34 |
| 15 | 0.59 | 1.07 | 0.51 | 0.51 | 0.51 | 0.51 | 0.45 | 0.44 | 0.46 |
| 20 | 0.62 | 1.36 | 0.53 | 0.54 | 0.54 | 0.63 | 0.54 | 0.54 | 0.57 |
| 30 | 0.91 | 2.02 | 0.75 | 0.76 | 0.77 | 0.90 | 0.86 | 0.84 | 0.85 |
| 60 | 1.56 | 4.05 | 1.07 | 1.07 | 1.06 | 1.29 | 1.17 | 1.39 | 1.33 |
| 120 | 3.32 | 8.47 | 2.50 | 2.52 | 2.52 | 2.71 | 2.58 | 2.80 | 2.48 |
| Forecast | Simple Models | ARIMA Models Sampling Intervals (Minutes) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Time (Mins) | Zero Diff | Same Diff | 5 | 10 | 15 | 20 | 30 | 60 | 120 |
| 5 | 0.24 | 0.27 | 0.21 | 0.11 | 0.08 | 0.08 | 0.07 | 0.08 | 0.09 |
| 10 | 0.35 | 0.49 | 0.32 | 0.32 | 0.26 | 0.26 | 0.23 | 0.21 | 0.22 |
| 15 | 0.45 | 0.65 | 0.38 | 0.38 | 0.38 | 0.36 | 0.31 | 0.29 | 0.31 |
| 20 | 0.52 | 0.87 | 0.42 | 0.42 | 0.42 | 0.46 | 0.40 | 0.37 | 0.43 |
| 30 | 0.73 | 1.31 | 0.58 | 0.58 | 0.59 | 0.63 | 0.63 | 0.55 | 0.62 |
| 60 | 1.27 | 2.60 | 0.82 | 0.82 | 0.81 | 0.85 | 0.82 | 0.90 | 0.96 |
| 120 | 2.71 | 5.71 | 1.91 | 1.94 | 1.98 | 2.03 | 1.97 | 2.03 | 1.74 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bhandari, S.; Bergmann, N.; Jurdak, R.; Kusy, B. Time Series Data Analysis of Wireless Sensor Network Measurements of Temperature. Sensors 2017, 17, 1221. https://doi.org/10.3390/s17061221
Bhandari S, Bergmann N, Jurdak R, Kusy B. Time Series Data Analysis of Wireless Sensor Network Measurements of Temperature. Sensors. 2017; 17(6):1221. https://doi.org/10.3390/s17061221
Chicago/Turabian StyleBhandari, Siddhartha, Neil Bergmann, Raja Jurdak, and Branislav Kusy. 2017. "Time Series Data Analysis of Wireless Sensor Network Measurements of Temperature" Sensors 17, no. 6: 1221. https://doi.org/10.3390/s17061221
APA StyleBhandari, S., Bergmann, N., Jurdak, R., & Kusy, B. (2017). Time Series Data Analysis of Wireless Sensor Network Measurements of Temperature. Sensors, 17(6), 1221. https://doi.org/10.3390/s17061221