Spatial Indexing for Data Searching in Mobile Sensing Environments





Abstract
:1. Introduction
2. Related Work
Comparison Table and Requirements for Mobile Sensing Environments
3. Data Retrieval Framework
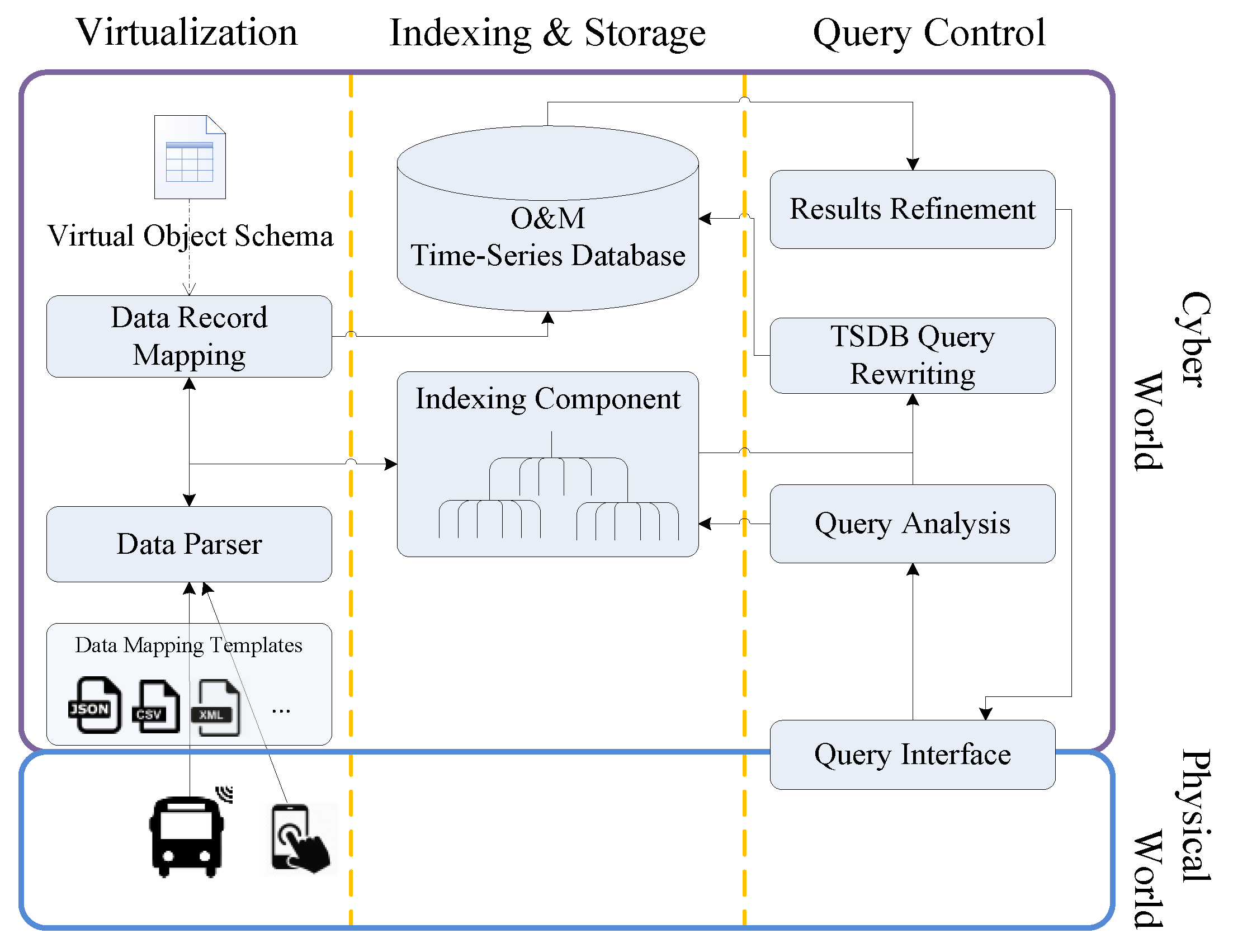
3.1. System Overview
3.2. Data Repository Mapping
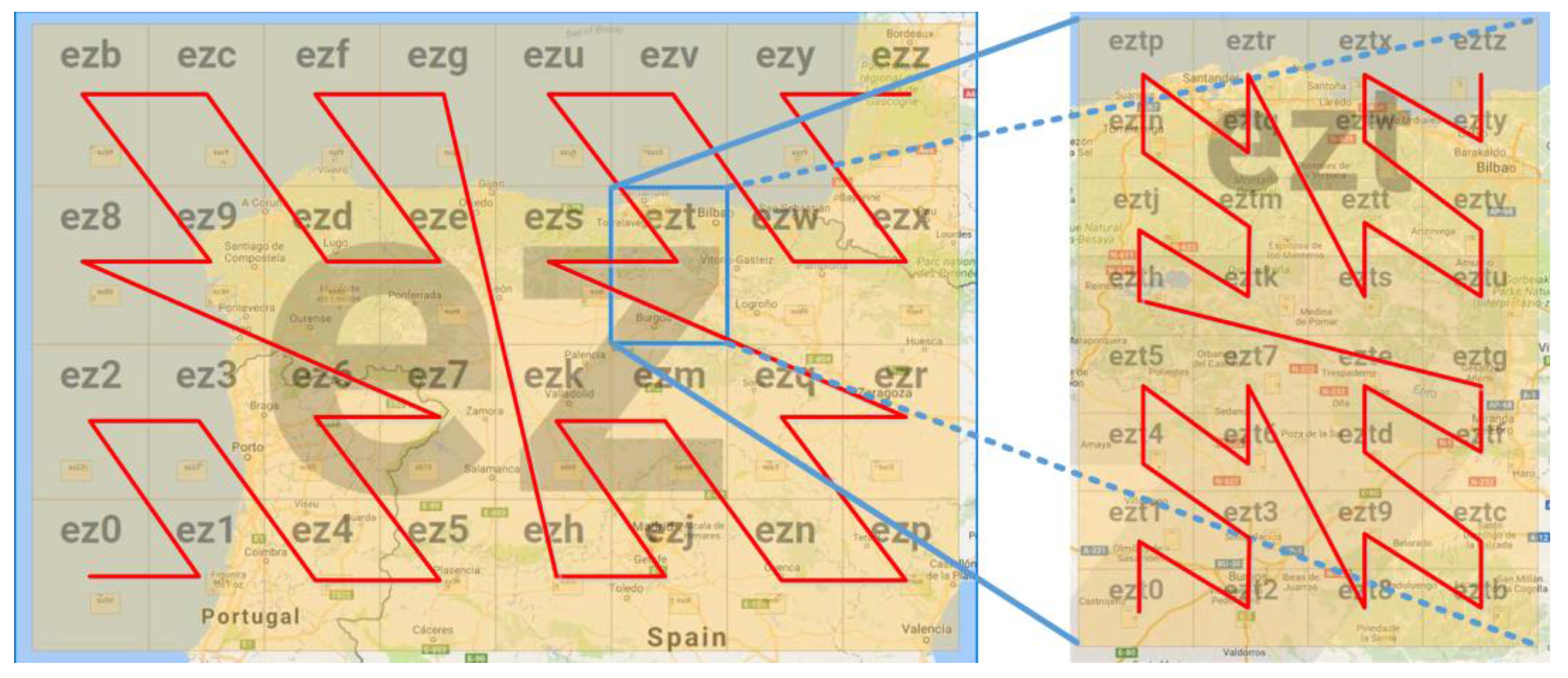
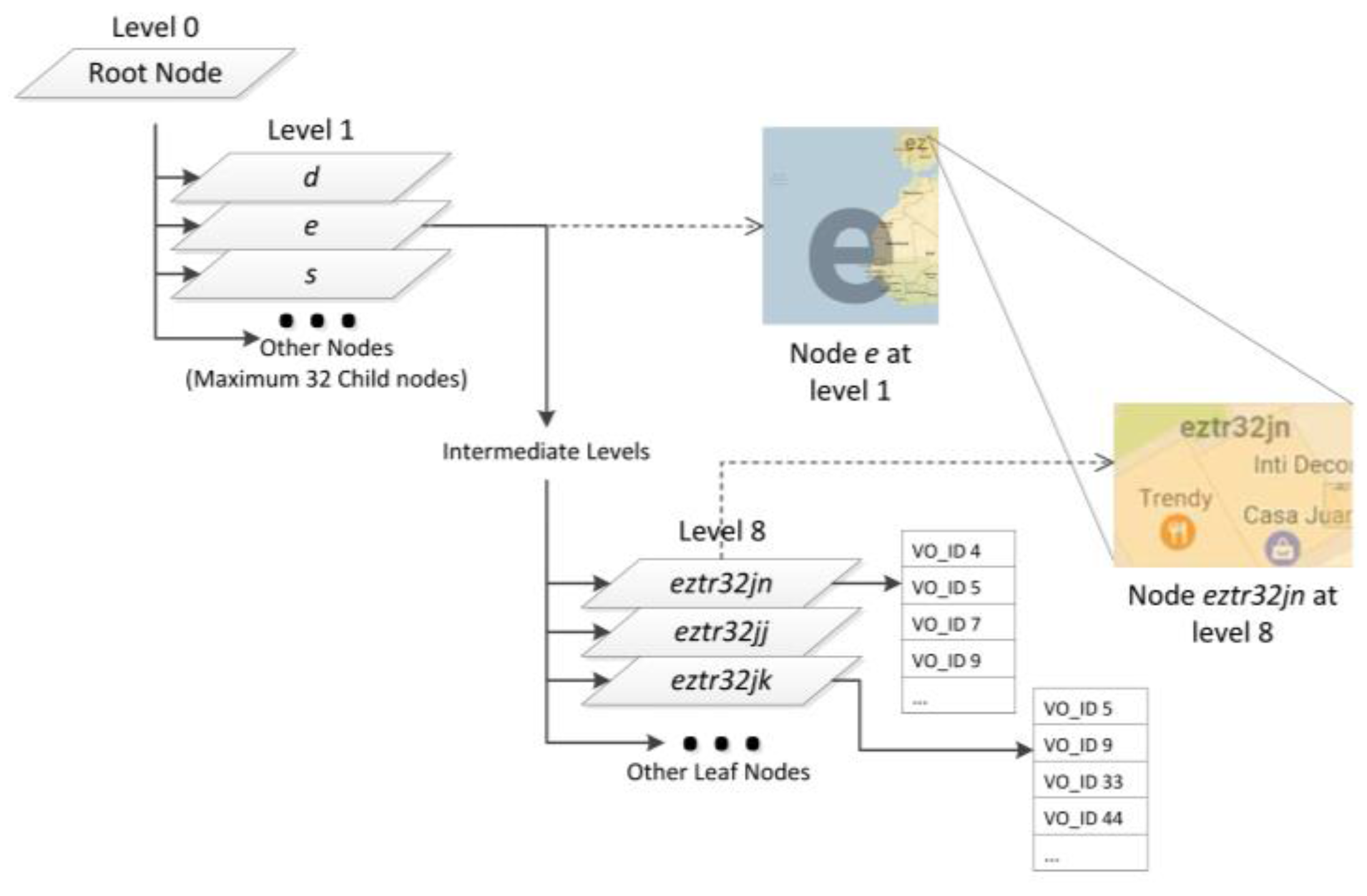
3.2.1. Geospatial Indexing for FUTS data from Mobile Sources
- Step 1:
- The VO_ID is inserted to the root node (Line 5). Upon receiving a VO, the node performs several checks: (1) the node checks whether the spatial information of the VO is contained in the range of the node (Line 7). If the VO is outside of the range of the node, the node ignores the insertion and the VO is discarded (Line 8); (2) the node is initialized if it is null (Line 10–12); and (3) if the node is a leaf node, VO_ID is added to the tree (Line 13–16).
- Step 2:
- After Step 1, the location of the VO is confirmed to be within the range of the node. Then the node computes in which smaller range (the child node) the VO should be inserted. The smaller range, subrange, is computed by the node (Line 18).
- Step 3:
- The node computes the index of a child node that matches the subrange (Line 20).
- Step 4:
- At the end, the VO is inserted to the child node iteratively till the leaf node (Line 22). The node with the indexed VO will be returned (Line 13–16).
| Algorithm 1: Insertion in the Geohash-Grid Tree |
|
3.3. Query Processing
- Range queries—a rectangular area specified on a map, along with the desired time window.
- Distance queries—a circular area of interest specified as a point and a radius on the map within which observations are sought. Time window is also supported.
- Time window and aggregation—several temporal aggregation functions: minimum, maximum or mean of the stored O&M values within a given time window.
| Algorithm 2: Query Mechanism of Geohash-Grid Tree and InfluxDB |
|
4. Experiments and Evaluation
4.1. Dataset Description
4.2. Experimental Settings
4.3. Evaluation Results
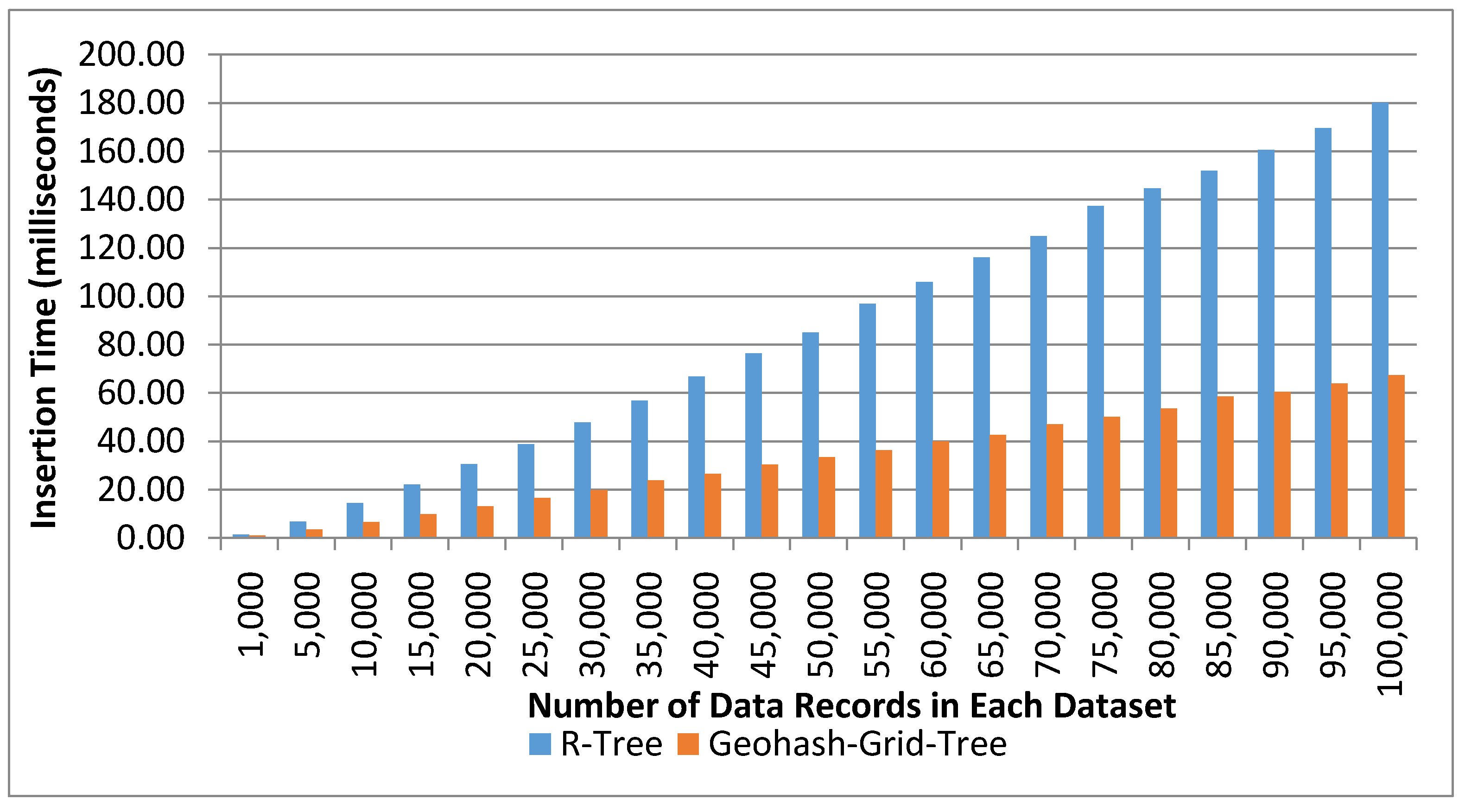
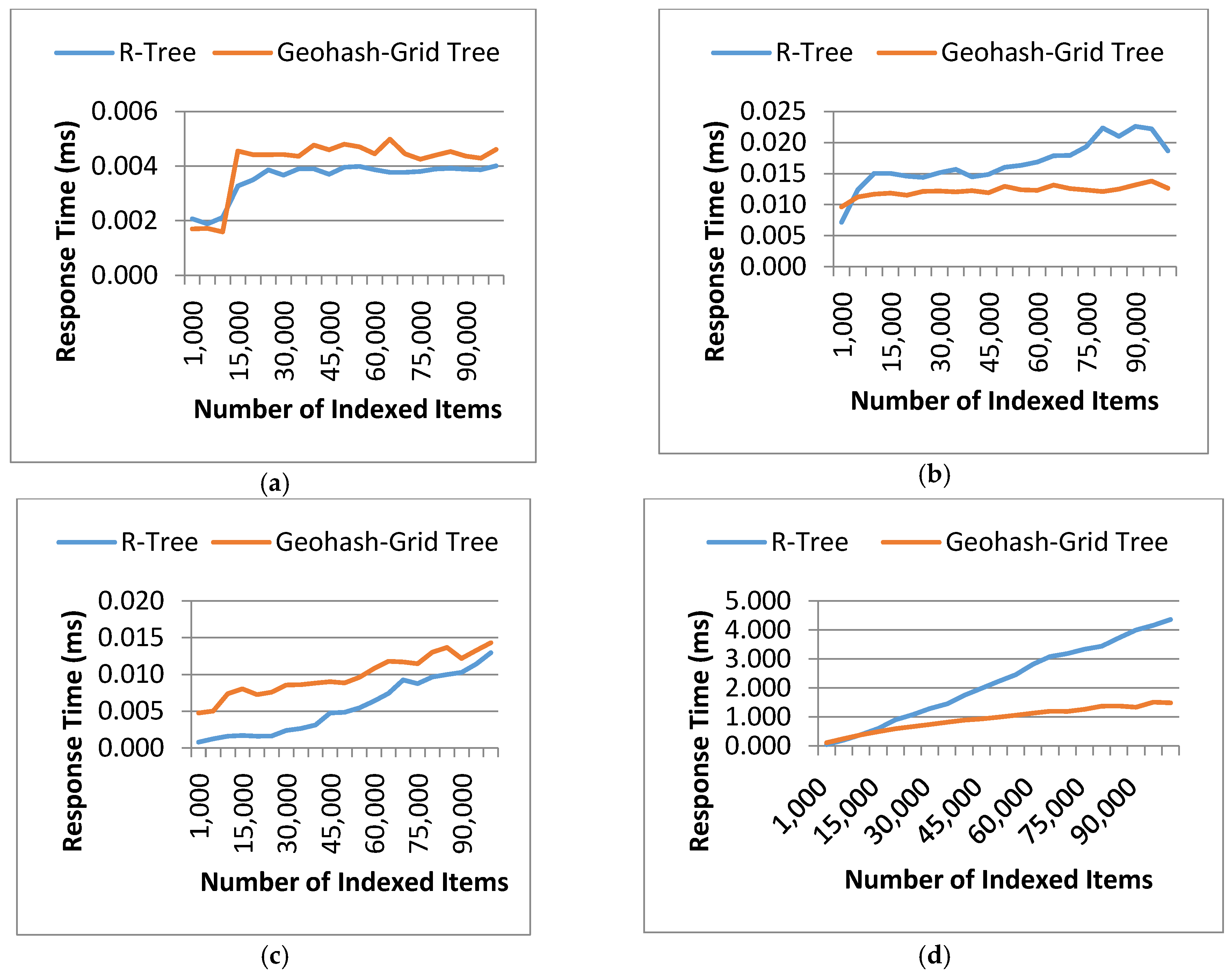
4.3.1. Index Creation Time
4.3.2. Tree Query Response Time
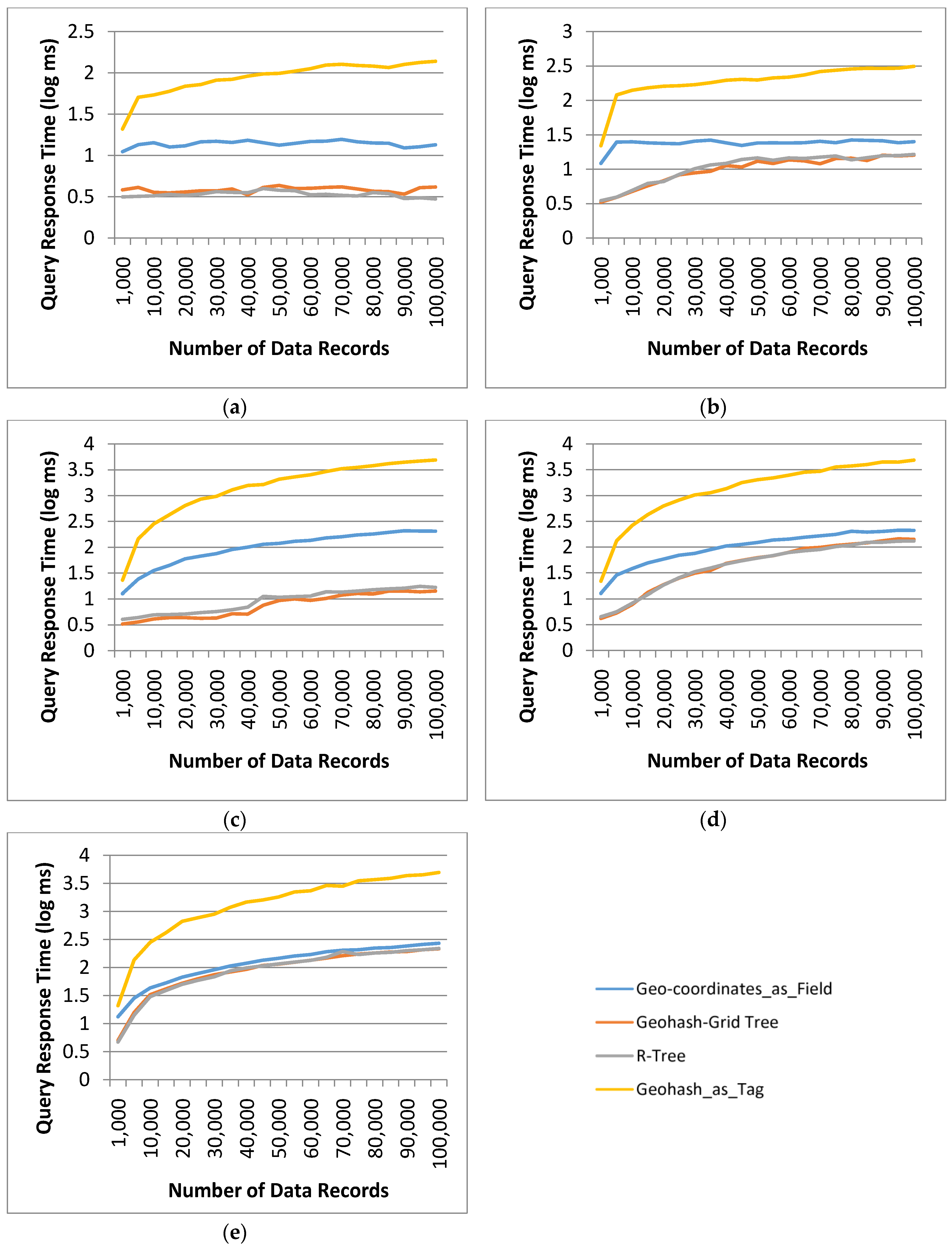
4.3.3. Query Response Time
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Ericsson Mobility Report. Available online: https://www.ericsson.com/assets/local/mobility-report/documents/2015/ericsson-mobility-report-nov-2015.pdf (accessed on 12 February 2017).
- Manta-Caro, C.; Fernández-Luna, J.M. Advances in Real-Time Indexing Models and Techniques for the Web of Things. In Proceedings of the 2016 8th IEEE Latin-American Conference on Communications (LATINCOM), Medellín, Colombia, 15–17 November 2016; pp. 1–6. [Google Scholar]
- Liu, C.H.; Zhang, Z.; Huang, Y.; Leung, K.K. Distributed and Real-Time Query Framework for Processing Participatory Sensing Data Streams. In Proceedings of the 2015 IEEE 17th International Conference on High Performance Computing and Communications, 2015 IEEE 7th International Symposium on Cyberspace Safety and Security, and 2015 IEEE 12th International Conference on Embedded Software and Systems, New York, NY, USA, 24–26 Augest 2015; pp. 248–253. [Google Scholar]
- Zhou, Y.; De, S.; Wang, W.; Moessner, K. Enabling Query of Frequently Updated Data from Mobile Sensing Sources. Proceedings of 13th IEEE International Conference on Ubiquitous Computing and Communications (IUCC 2014), Chengdu, China, 19–21 December 2014. [Google Scholar]
- Zhou, Y.; De, S.; Wang, W.; Moessner, K. Search techniques for the web of things: A taxonomy and survey. Sensors 2016, 16, 600. [Google Scholar] [CrossRef] [PubMed]
- Qin, Y.; Sheng, Q.Z.; Falkner, N.J.G.; Dustdar, S.; Wang, H.; Vasilakos, A.V. When things matter: A survey on data-centric internet of things. J. Netw. Comput. Appl. 2016, 64, 137–153. [Google Scholar] [CrossRef]
- Nath, S.; Liu, J.; Zhao, F. Sensormap for wide-area sensor webs. Computer 2007, 40, 0090–0093. [Google Scholar] [CrossRef]
- Yang, X.; Song, W.; De, D. Liveweb: A sensorweb portal for sensing the world in real-time. Tsinghua Sci. Technol. 2011, 16, 491–504. [Google Scholar] [CrossRef]
- Liang, S.H.; Huang, C.-Y. Geocens: A geospatial cyberinfrastructure for the world-wide sensor web. Sensors 2013, 13, 13402–13424. [Google Scholar] [CrossRef] [PubMed]
- Qi, S.Y.; Bouros, P.; Sacharidis, D.; Mamoulis, N. Efficient point-based trajectory search. Lect. Notes Comput. Sci. 2015, 9239, 179–196. [Google Scholar]
- Zhu, Y.; Gong, J. A Real-Time Trajectory Indexing Method Based on Mongodb. In Proceedings of the 2014 11th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Xiamen, China, 19–21 August 2014; pp. 548–553. [Google Scholar]
- Chen, Z.; Shen, H.T.; Zhou, X.; Zheng, Y.; Xie, X. Searching Trajectories by Locations: An Efficiency Study. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data, Indianapolis, Indiana, 6–11 June 2010; pp. 255–266. [Google Scholar]
- John, A.; Sugumaran, M.; Rajesh, R. Indexing and query processing techniques in spatio-temporal data. ICTACT J. Soft Comput. 2016, 6, 1198–1217. [Google Scholar]
- Bauer, M.; Longo, S. Geographic Service Discovery for the Internet of Things. In International Conference on Ubiquitous Computing and Ambient Intelligence; Springer: Cham, ZG, Switzerland, 2014; pp. 424–431. [Google Scholar]
- De, S. D4.3: Concepts and Solutions for Entity-Based Discovery of Iot Resources and Managing Their Dynamic Associations; IoT-A public deliverable, 2012. Available online: http://www.meet-iot.eu/deliverables-IOTA/D4_3.pdf (accessed on 17 June 2017).
- Wang, W.; De, S.; Cassar, G.; Moessner, K. An experimental study on geospatial indexing for sensor service discovery. Expert Syst. Appl. 2015, 42, 3528–3538. [Google Scholar] [CrossRef]
- De, S.; Christophe, B.; Moessner, K. Semantic enablers for dynamic digital-physical object associations in a federated node architecture for the internet of things. Ad Hoc Netw. 2014, 18, 102–120. [Google Scholar] [CrossRef]
- Jirka, S.; Bröring, A.; Stasch, C. Discovery mechanisms for the sensor web. Sensors 2009, 9, 2661–2681. [Google Scholar] [CrossRef] [PubMed]
- Ding, Z.; Chen, Z.; Yang, Q. Iot-svksearch: A real-time multimodal search engine mechanism for the internet of things. Int. J. Commun. Syst. 2014, 27, 871–897. [Google Scholar] [CrossRef]
- Le-Phuoc, D.; Nguyen-Mau, H.Q.; Parreira, J.X.; Hauswirth, M. A middleware framework for scalable management of linked streams. Web Semant. Sci. Serv. Agents World Wide Web 2012, 16, 42–51. [Google Scholar] [CrossRef]
- Huang, C.-Y.; Liang, S.H. Lost-tree: A spatio-temporal structure for efficient sensor data loading in a sensor web browser. Int. J. Geogr. Inf. Sci. 2013, 27, 1190–1209. [Google Scholar] [CrossRef]
- Huang, C.-Y.; Liang, S. Ahs model: Efficient topological operators for a sensor web publish/subscribe system. ISPRS Int. J. Geo-Inf. 2017, 6, 54. [Google Scholar] [CrossRef]
- Chan, K.P.; Fu, A.W.C. Efficient Time Series Matching by Wavelets. In ICDE ‘99 Proceedings of the 15th International Conference on Data Engineering, Sydney, NSW, Australia, 23–26 March 1999; IEEE Computer Society: Washington, DC, USA, 1999; pp. 126–133. [Google Scholar]
- Cai, Y.; Ng, R. Indexing spatio-temporal trajectories with chebyshev polynomials. In Proceedings of the 2004 ACM SIGMOD International Conference on Management of Data, Paris, France, 13–18 June 2004; ACM: New York, NY, USA, 2004; pp. 599–610. [Google Scholar]
- Cox, S. Observations and measurements-xml implementation. OGC Document 2011, 10-025r, 1–76. [Google Scholar]
- Swe Terms: Semantic Sensor Network Incubator Group Wiki. Available online: https://www.w3.org/2005/Incubator/ssn/wiki/SWE_terms (accessed on 22 April 2017).
- Pas 212:2016 Automatic Resource Discovery for the Internet of Things. Specification, bsi Standard. Available online: http://shop.bsigroup.com/forms/PASs/PAS-212-2016-download/ (accessed on 25 April 2017).
- London Air Quality Network—King’s College London. Available online: https://www.londonair.org.uk/ (accessed on 6 June 2017).
- Boyle, D.E.; Yates, D.C.; Yeatman, E.M. Urban sensor data streams: London 2013. IEEE Internet Comput. 2013, 17, 12–20. [Google Scholar] [CrossRef]
- Chun-Wei, T.; Chin-Feng, L.; Ming-Chao, C.; Yang, L.T. Data mining for internet of things: A survey. IEEE Commun. Surv. Tutor. 2014, 16, 77–97. [Google Scholar]
- Geohashexplorer. Available online: http://geohash.gofreerange.com/ (accessed on 28 April 2017).
- Guttman, A. R-trees: A Dynamic Index Structure for Spatial Searching. In Proceedings of the 1984 ACM SIGMOD International Conference on Management of Data—SIGMOD ’84, Boston, MA, USA, 18–21 June 1984; ACM: New York, NY, USA, 1984; pp. 47–57. [Google Scholar]
- Pan, B.; Zheng, Y.; Wilkie, D.; Shahabi, C. Crowd Sensing of Traffic Anomalies Based on Human Mobility and Social Media. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Orlando, FL, USA, 5–8 November 2013; pp. 344–353. [Google Scholar]
- Kang, L.; Poslad, S.; Wang, W.; Li, X.; Zhang, Y.; Wang, C. A Public Transport Bus as a Flexible Mobile Smart Environment Sensing Platform for IoT. In Proceedings of the 2016 12th International Conference on Intelligent Environments (IE), London, UK, 14–16 September 2016; pp. 1–8. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Descriptions |
|---|---|
| Data Items | Indicates the items managed by the reviewed system. They are the objects used for the indexed domains and corresponding query functionalities. |
| Indexed Domain | Spatial, temporal, or thematic domains indexed by the system. |
| Supported Query | Query functionalities supported by the system. |
| Metadata Update Frequency | Frequency of update for the metadata of sensor data, especially spatial information. Frequently changing spatial information is one of the key characteristics in mobile sensing environments and a good system should support high metadata update frequency. |
| Query for Historical Data | Whether the reviewed system supports queries for historical data. Historical data is important for data analysis. |
| Search Method | Data Items | Indexed Domain | Supported Query | Metadata Update Frequency | Query for Historical Data |
|---|---|---|---|---|---|
| IoT service resolution framework [14,15] (R-tree) | IoT Service metadata | Spatial | Point or area-based spatial query | Slow | - |
| Wei et al. [16] (R-tree) | Sensor metadata | Spatial | Point-based spatial query | Very fast | Not supported |
| OSIRIS [18] | Sensor metadata | A spatial Index for spatial domain, a temporal index for temporal domain, a full-text index for thematic domain | Sensor instance discovery and sensor service discovery based on search criteria of metadata, including spatial, temporal, and thematic metadata | Medium | Yes |
| SensorMap [7] | Sensor metadata | Spatial | Spatial search for latest values generated by sensors | Medium | No |
| Liveweb [8] | Sensor data | Keywords indexing for thematic domain, binary search tree for values | Search for real-time content based on keywords, category, and value range | Slow | Yes |
| GeoCENS [9] | Sensor Web Service | Spatial filling curve for spatial domain | Geospatial search based on key-value pair queries | Slow | Yes |
| IoT-SVK [19] | Sensors, devices, objects | Spatial-Temporal R-Tree for spatial and temporal domain, B+-Tree for keywords and values | Keyword-based search Spatial-temporal search Value-based search | Fast | Yes |
| Linked Stream Middleware (LSM) [20] | Sensor streams as RDF triples | - | SPARQL-based continuous query with semantic constraints (including spatial and temporal domain constraints) | Slow | Yes |
| LOST-Tree [21] | Sensor data and geometries | Spatial, Temporal | Spatial and temporal queries | - | - |
| AHS model [22] | Sensor observation data | Spatial | Spatial query with complex geometry | Very fast | Not supported |
| Bouros et al. [10] | Trajectories | Spatial and temporal | Retrieval of the top-k trajectories that pass as close as possible to all query points. | Fast | Yes |
| Chan et al. [23] | Haar Wavelets transformed trajectories | Spatial and temporal | Range query and nearest neighbour query for trajectories | Fast | Yes |
| Cai and Ng [24] | Chebyshev approximation of trajectories | Spatial and temporal | K nearest neighbours query for trajectories | Fast | Yes |
| Chen et al. [12] | Trajectories | Spatial and temporal | K nearest neighbours query for trajectories | Fast | Yes |
| Zhu and Gong [11] | Trajectories | Spatio-temporal R-tree for spatial and time domain, | real-time access to latest trajectories, trajectory-based queries | Fast | Yes |
| Proposed Approach | Virtualized objects and sensor data | Geohash-Grid Tree for spatial domain, TSDB for time domain | Query with spatio-temporal ranges and phenomenon, Aggregations on time-series data | Very fast | Yes |
| ID | 3021 | Name | bus3021 |
| Type | http://dbpedia.org/page/Bus | Mobile | Yes |
| Location {Latitude, Longitude, Geohash} | |||
| {43.430007, −3.949993, eztpn45wn} | |||
| Information {Name, Value, Unit of Measurement, Time, Description} | |||
| {Particles, 0.89, mg/m3, 02 January 2015 17:33:19, density of particles with a diameter between 2.5 and 10 micrometres} | |||
| {Humidity, 0.64, percentage, 02 January 2015 17:33:19, Humidity} | |||
| Database | Measurement | Tag-key | Tag-value | Field-key | Field-value |
|---|---|---|---|---|---|
| mydb | vo_3021 | geohash | eztpn45wn | humidity | 0.64 |
| Dimension | Total | From | To | Distribution |
|---|---|---|---|---|
| VO | 84 | |||
| Environmental Phenomenon | 5 | CO, Humidity, Ozone + NO2, Particles (PM10), and Temperature | ||
| Latitude | 827 | 42.9855 | 43.6636 | Largely distributed between 43.4 to 43.5 |
| Longitude | 9978 | −4.13309 | −3.53594 | Largely distributed between −3.9 to −3.78 |
| Date | 223 distinct days | Friday, 02 January 2015 17:33:19 GMT | Thursday, 13 August 2015 11:59:09 GMT | Almost a uniform distribution |
| Query constraint | Query 1 | Query 2 | Query 3 | Query 4 |
|---|---|---|---|---|
| Point | (43.1702, −3.89954) | (43.4632, −3.80883) | ||
| Location range | (43.4, −3.6) to (43.5, −3.5) | (43.4, −3.9) to (43.5, −3.8) | ||
| Indexed items density in nearby area | sparse | dense | sparse | dense |
| Number of distinct VO_IDs of returned indexed items | 1 | 1 | 1 | 84 |
| Phenomenon | Query 1 | Query 2 | Query 3 | Query 4 | Query 5 |
|---|---|---|---|---|---|
| Temperature | |||||
| Time_from | 21 January 2015 10:00 a.m. | 21 January 2015 10:00 a.m. | 21 January 2015 10:00 a.m. | 21 January 2015 10:00 a.m. | 21 January 2015 10:00 a.m. |
| Time_to | 22 January 2015 10:00 a.m. | 26 January 2015 10:00 a.m. | 22 July 2015 10:00 a.m. | 26 July 2015 10:00 a.m. | 22 July 2015 10:00 a.m. |
| Time range | 1 day | 5 days | ~6 months | ~6 months | ~6 months |
| Location range | (43.4, −3.94) to (43.42, −3.93) | (43.47, −3.79) to (43.473, −3.785) | (43.4, −3.94) to (43.42, −3.93) | (43.47, −3.79) to (43.473, −3.785) | (43.467, −3.79) to (43.47, −3.787) |
| Data records density of nearby area | sparse | dense | sparse | dense | dense |
| VOs in indexed trees | 2 | 46 | 2 | 46 | 58 |
| Number of Returned Data Records | |||||
| Geo-coordinates_as_Field | 1 | 4 | 7 | 107 | 1004 |
| Geohash-Grid Tree | 1 | 4 | 7 | 107 | 1004 |
| R-Tree | 1 | 4 | 7 | 107 | 1004 |
| Geohash_as_Tag | 616 | 2774 | 88,864 | 85,459 | 93,404 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; De, S.; Wang, W.; Moessner, K.; Palaniswami, M.S. Spatial Indexing for Data Searching in Mobile Sensing Environments. Sensors 2017, 17, 1427. https://doi.org/10.3390/s17061427
Zhou Y, De S, Wang W, Moessner K, Palaniswami MS. Spatial Indexing for Data Searching in Mobile Sensing Environments. Sensors. 2017; 17(6):1427. https://doi.org/10.3390/s17061427
Chicago/Turabian StyleZhou, Yuchao, Suparna De, Wei Wang, Klaus Moessner, and Marimuthu S. Palaniswami. 2017. "Spatial Indexing for Data Searching in Mobile Sensing Environments" Sensors 17, no. 6: 1427. https://doi.org/10.3390/s17061427
APA StyleZhou, Y., De, S., Wang, W., Moessner, K., & Palaniswami, M. S. (2017). Spatial Indexing for Data Searching in Mobile Sensing Environments. Sensors, 17(6), 1427. https://doi.org/10.3390/s17061427