Dual-Channel Cosine Function Based ITD Estimation for Robust Speech Separation


Abstract
:1. Introduction
- (1)
- we novelly upgrade delay-and-sum beamforming (DSB) [15] for estimating the ITD; and
- (2)
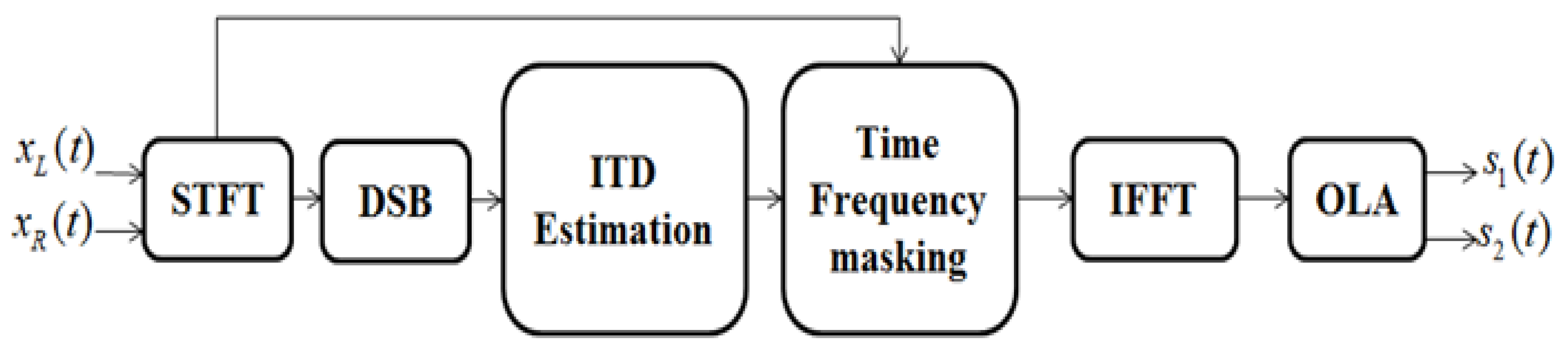
- for the first time, we clarify the connections between ideal binary mask and DSB amplitude ratio. The framework of our approach is illustrated in Figure 1. Moreover, our proposed algorithm can handle the problem of phase wrap-around.
2. Time Difference Model
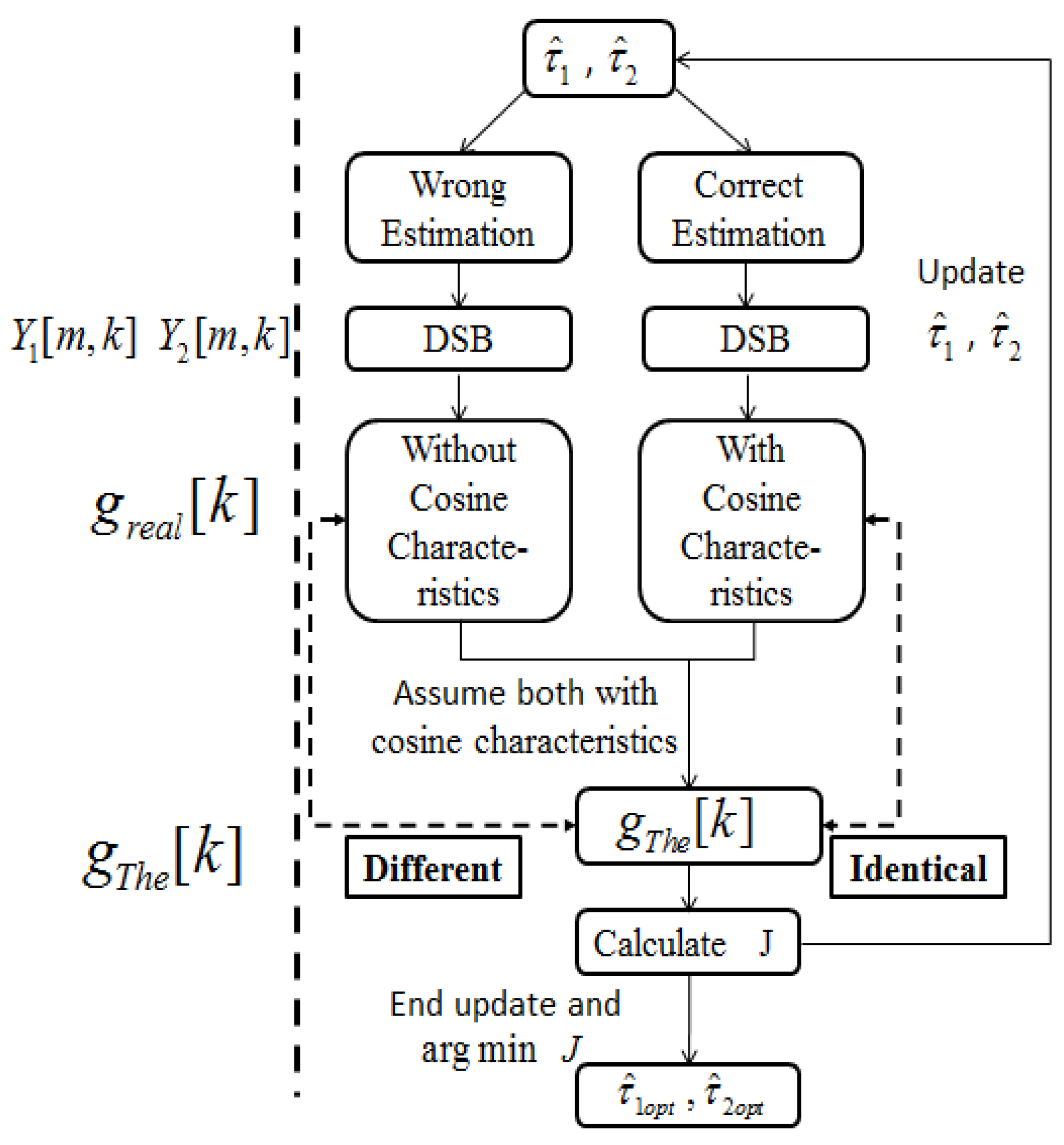
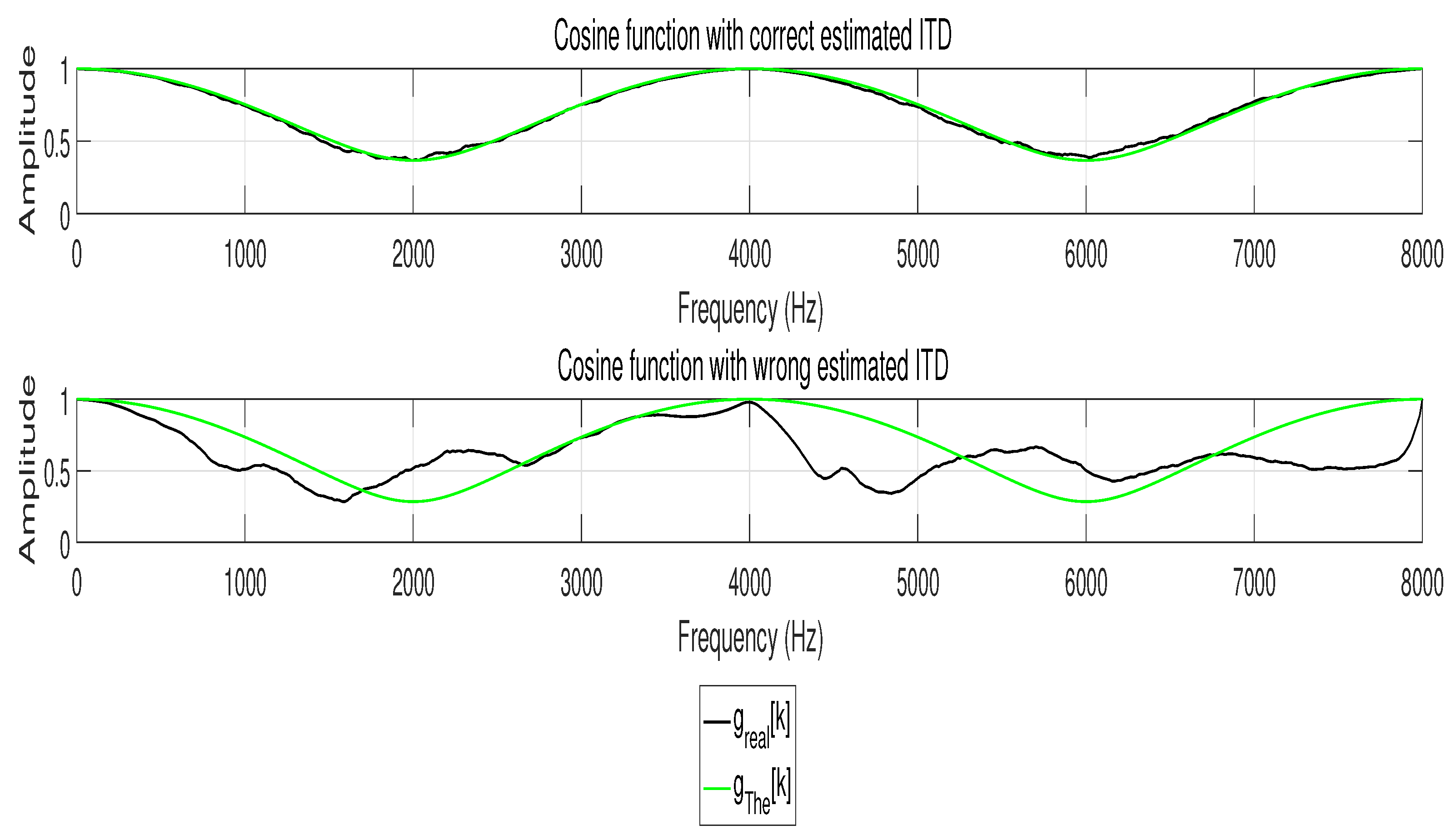
3. Proposed Approach
4. Source Separation
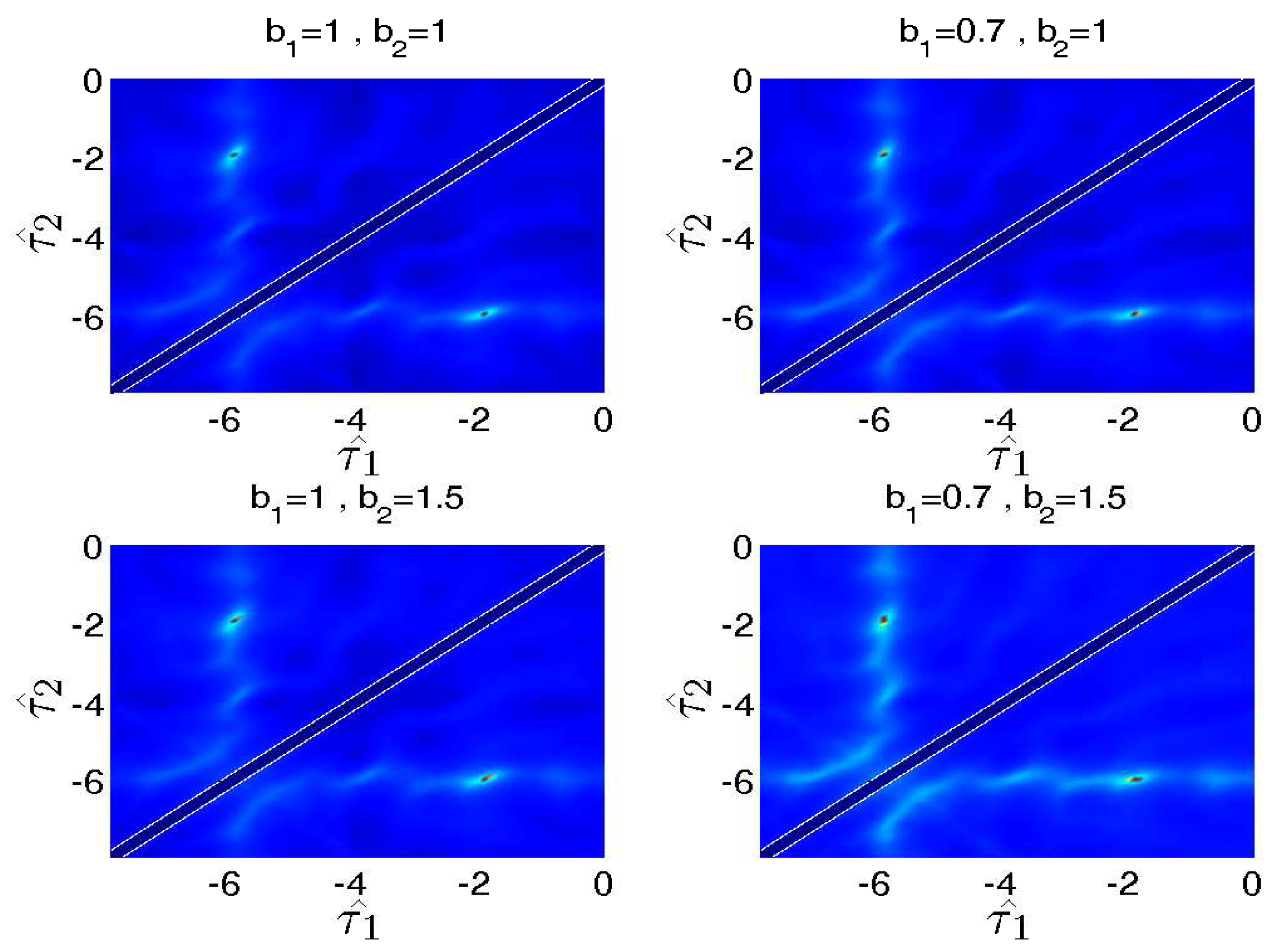
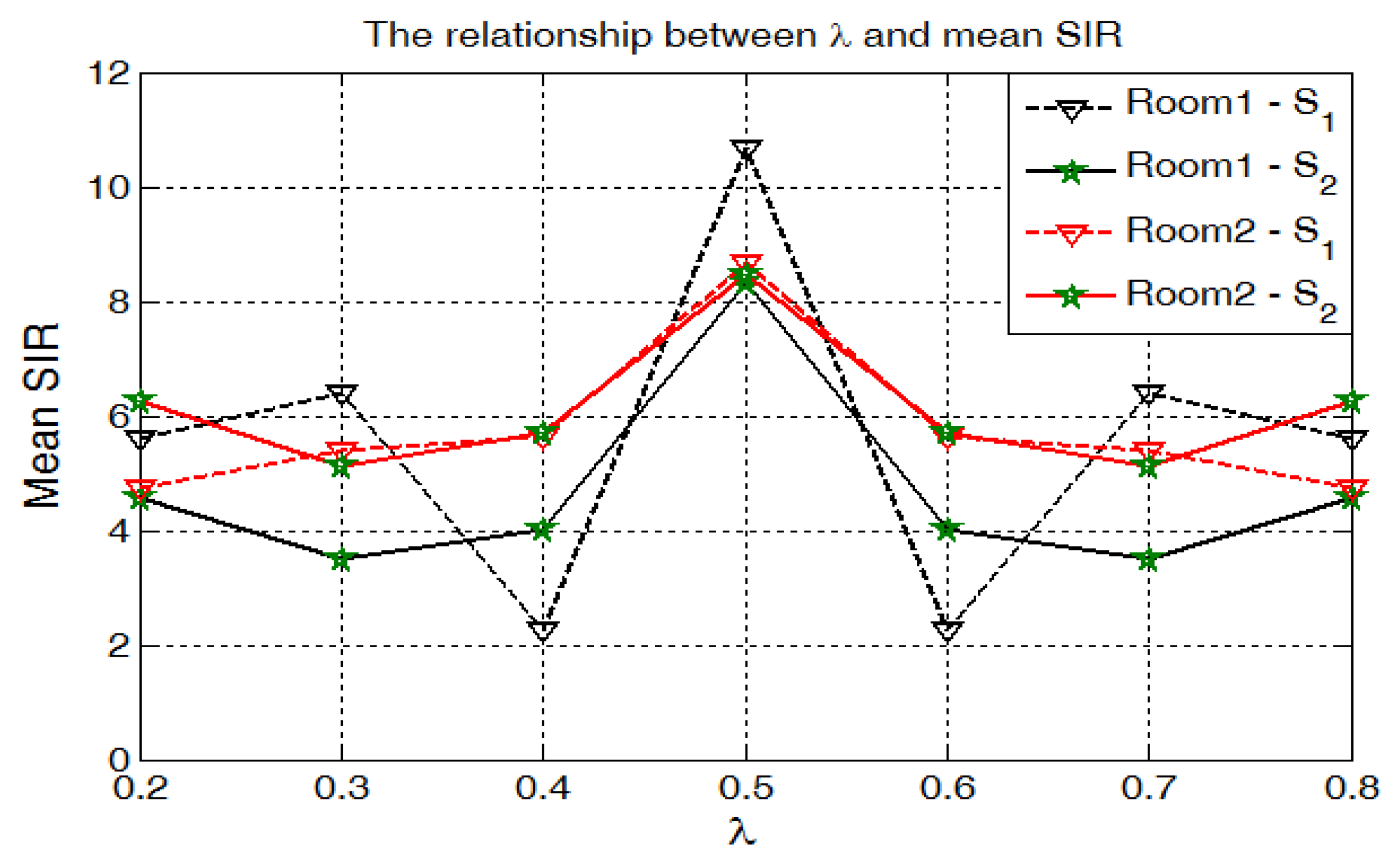
4.1. The Effects of Weighted Coefficients
4.2. Mask Based on DSB Ratio
5. Experimental Evaluations
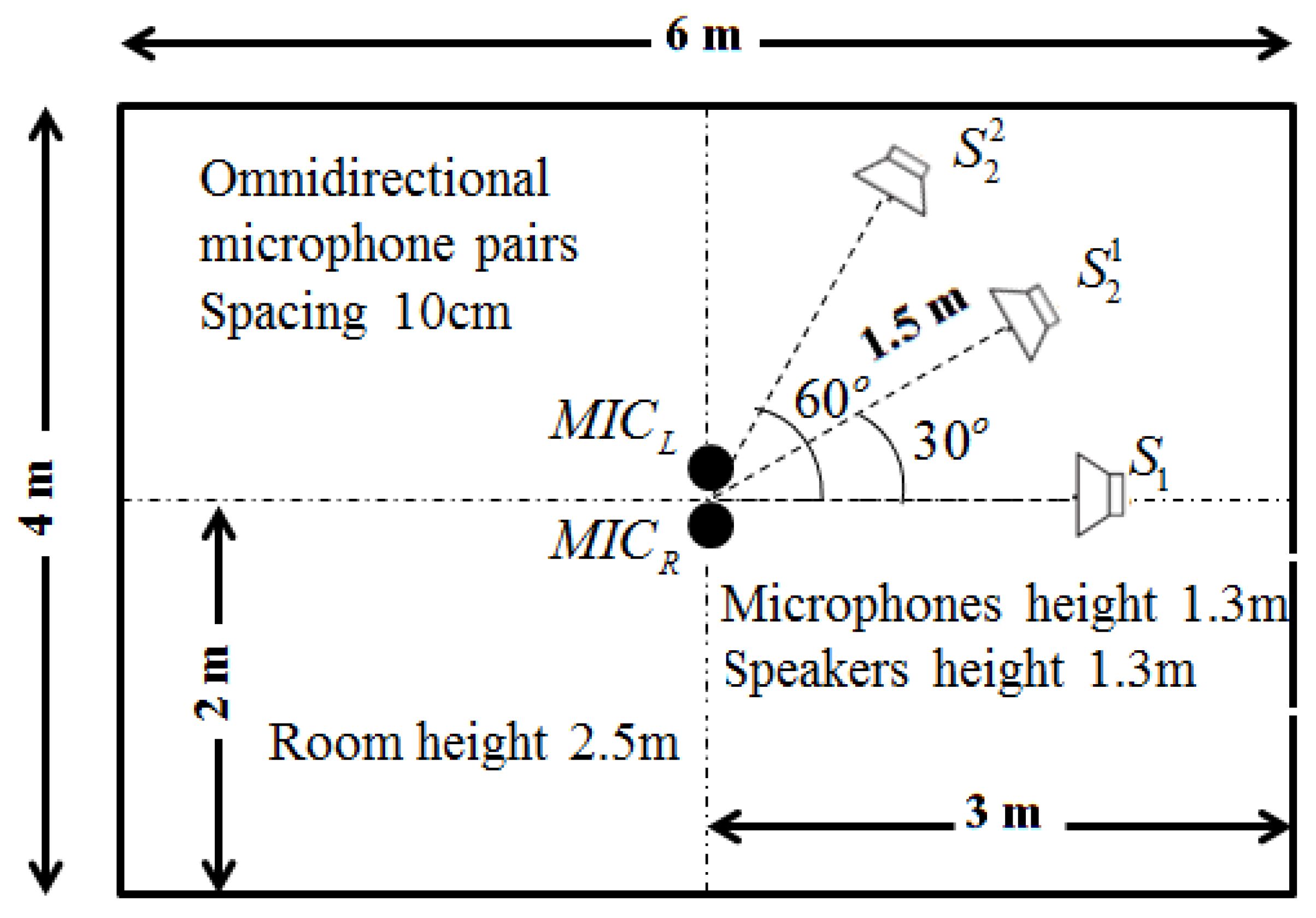
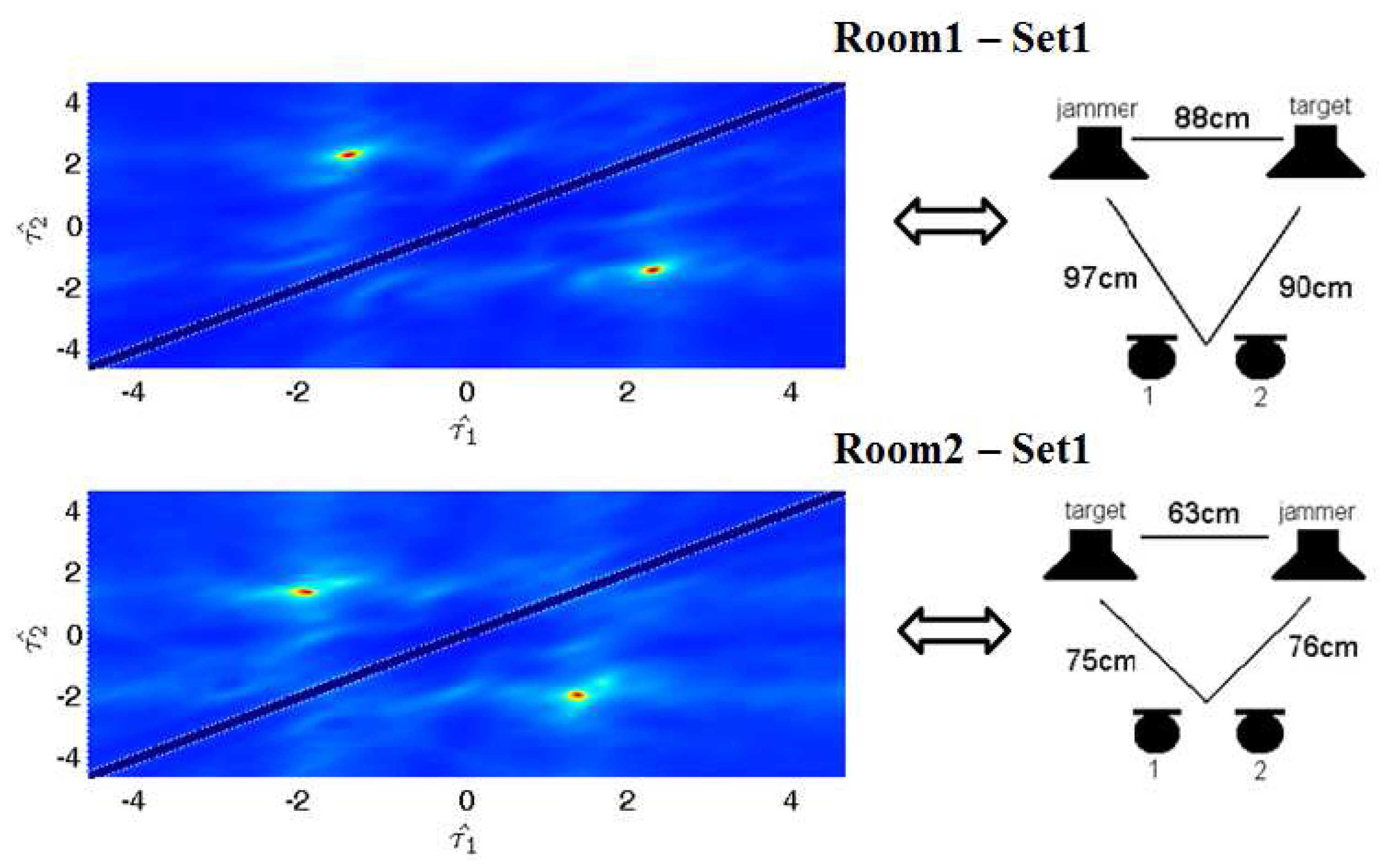
5.1. Experimental Setup
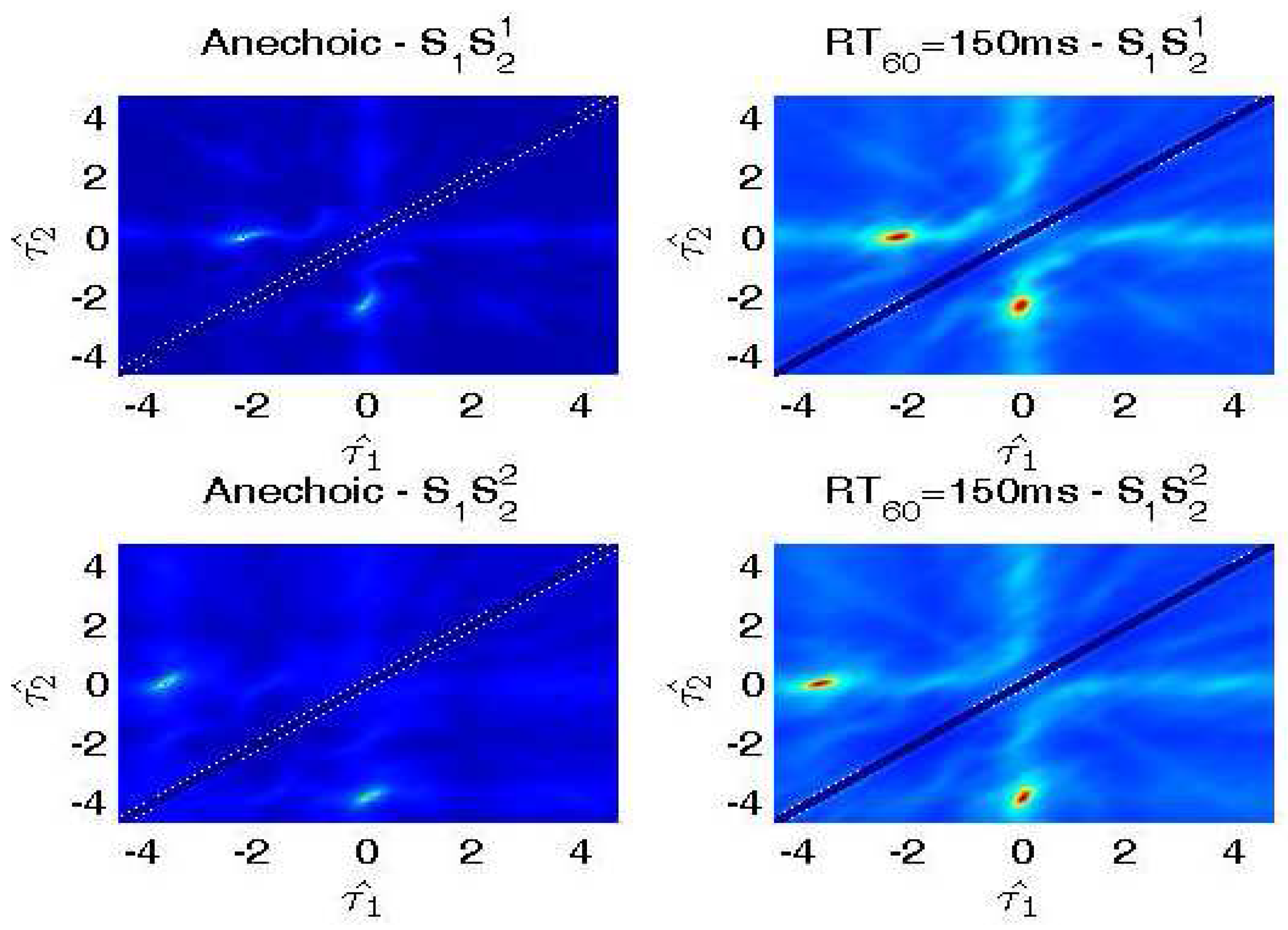
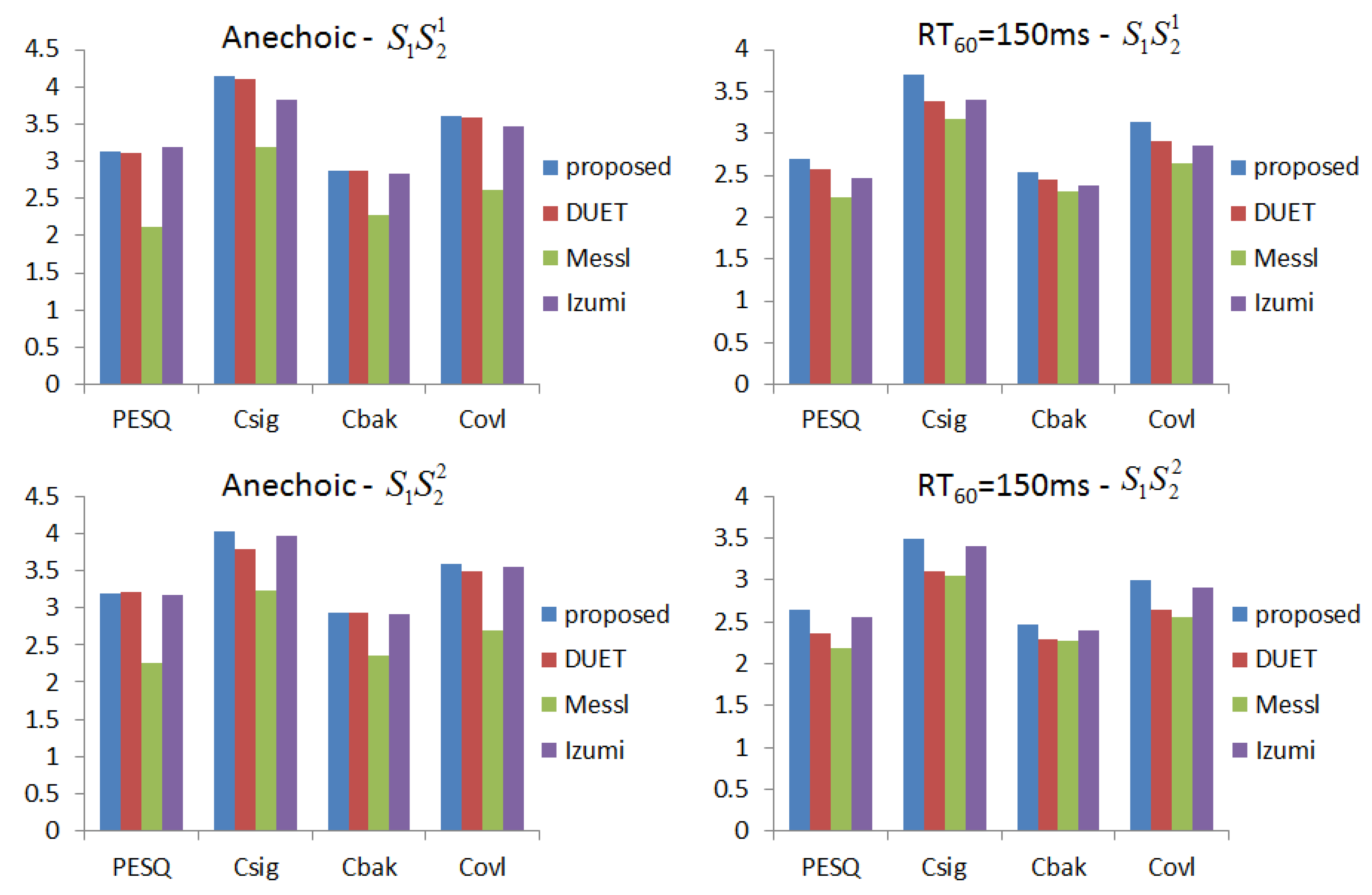
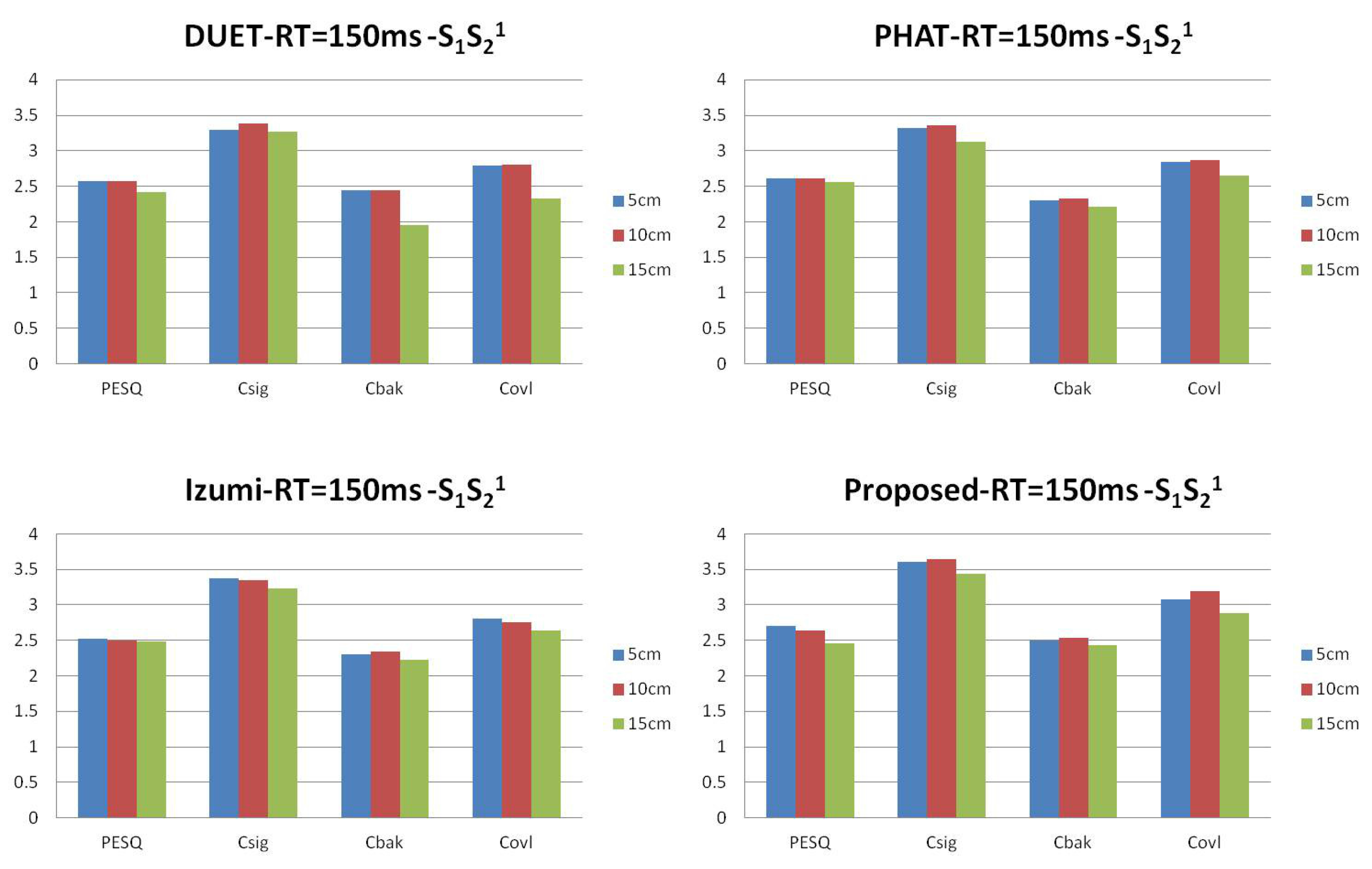
5.2. Simulated Data
5.3. SiSEC 2010 Test Data
6. Conclusions
Author Contributions
Conflicts of Interest
References
- Kouchaki, S.; Sanei, S. Supervised single channel source separation of EEG signals. In Proceedings of the 2013 IEEE International Workshop on Machine Learning for Signal Processing (MLSP), Southampton, UK, 22–25 September 2003; pp. 1–5. [Google Scholar]
- Gao, B.; Woo, W.; Dlay, S. Single-channel source separation using EMD-subband variable regularized sparse features. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 961–976. [Google Scholar] [CrossRef]
- Tengtrairat, N.; Woo, W.L.; Dlay, S.S.; Gao, B. Online noisy single-channel source separation using adaptive spectrum amplitude estimator and masking. IEEE Trans. Signal Process. 2016, 64, 1881–1895. [Google Scholar] [CrossRef]
- Tengtrairat, N.; Gao, B.; Woo, W.L.; Dlay, S.S. Single-channel blind separation using pseudo-stereo mixture and complex 2D histogram. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1722–1735. [Google Scholar] [CrossRef] [PubMed]
- Clark, B.; Flint, J.A. Acoustical direction finding with time-modulated arrays. Sensors 2016, 16, 2107. [Google Scholar] [CrossRef] [PubMed]
- Velasco, J.; Pizarro, D.; Macias-Guarasa, J. Source localization with acoustic sensor arrays using generative model based fitting with sparse constraints. Sensors 2012, 12, 13781–13812. [Google Scholar] [CrossRef] [PubMed]
- Aarabi, P.; Shi, G. Phase-based dual-microphone robust speech enhancement. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2004, 34, 1763–1773. [Google Scholar] [CrossRef]
- Kim, C.; Stern, R.M.; Eom, K.; Lee, J. Automatic selection of thresholds for signal separation algorithms based on interaural delay. Proccedings of the INTERSPEECH 2010, Chiba, Japan, 26–30 September 2010; pp. 729–732. [Google Scholar]
- Kim, C.; Khawand, C.; Stern, R.M. Two-microphone source separation algorithm based on statistical modeling of angle distributions. Proccedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 4629–4632. [Google Scholar]
- Yousefian, N.; Loizou, P.C. A dual-microphone algorithm that can cope with competing-talker scenarios. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 145–155. [Google Scholar] [CrossRef]
- Pedersen, M.S.; Wang, D.; Larsen, J.; Kjems, U. Two-microphone separation of speech mixtures. IEEE Trans. Neural Netw. 2008, 19, 475–492. [Google Scholar] [CrossRef] [PubMed]
- Nishiguchi, M.; Morikawa, A.; Watanabe, K.; Abe, K.; Takane, S. Sound source separation and synthesis for audio enhancement based on spectral amplitudes of two-channel stereo signals. J. Acoust. Soc. Am. 2016, 140, 3428. [Google Scholar] [CrossRef]
- Wood, S.; Rouat, J. Blind speech separation with GCC-NMF. In Proceedings of the INTERSPEECH 2016, San Francisco, CA, USA, 8–12 September 2016. [Google Scholar]
- Al-Tmeme, A.; Woo, W.L.; Dlay, S.S.; Gao, B.; Al-Tmeme, A.; Woo, W.L.; Dlay, S.S.; Gao, B.; Woo, W.L.; Dlay, S.S.; et al. Underdetermined Convolutive Source Separation Using GEM-MU With Variational Approximated Optimum Model Order NMF2D. IEEE/ACM Trans. Audio Speech Lang. Process. (TASLP) 2017, 25, 35–49. [Google Scholar] [CrossRef]
- Brandstein, M.; Ward, D. Microphone Arrays: Signal Processing Techniques and Applications; Springer: Berlin, Germany, 2001. [Google Scholar]
- Yilmaz, O.; Rickard, S. Blind separation of speech mixtures via time-frequency masking. IEEE Trans. Signal Process. 2004, 52, 1830–1847. [Google Scholar] [CrossRef]
- Srinivasan, S.; Roman, N.; Wang, D. Binary and ratio time-frequency masks for robust speech recognition. Speech Commun. 2006, 48, 1486–1501. [Google Scholar] [CrossRef]
- Zue, V.; Seneff, S.; Glass, J. Speech database development at MIT: TIMIT and beyond. Speech Commun. 1990, 9, 351–356. [Google Scholar] [CrossRef]
- Hu, Y.; Loizou, P.C. Evaluation of objective quality measures for speech enhancement. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 229–238. [Google Scholar] [CrossRef]
- Vincent, E.; Sawada, H.; Bofill, P.; Makino, S.; Rosca, J.P. First stereo audio source separation evaluation campaign: Data, algorithms and results. In Independent Component Analysis and Signal Separation; Springer: Heidelberg, Germany, 2007; pp. 552–559. [Google Scholar]
- Cho, Y.D.; Kondoz, A. Analysis and improvement of a statistical model-based voice activity detector. IEEE Signal Process. Lett. 2001, 8, 276–278. [Google Scholar]
- Allen, J.B.; Berkley, D.A. Image method for efficiently simulating small-room acoustics. J. Acoust. Soc. Am. 1979, 65, 943–950. [Google Scholar] [CrossRef]
- Wang, Y.; Yılmaz, Ö.; Zhou, Z. Phase aliasing correction for robust blind source separation using DUET. Appl. Comput. Harmonic Anal. 2013, 35, 341–349. [Google Scholar] [CrossRef]
- Mandel, M.; Weiss, R.J.; Ellis, D.P. Model-based expectation-maximization source separation and localization. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 382–394. [Google Scholar] [CrossRef]
- Izumi, Y.; Ono, N.; Sagayama, S. Sparseness-based 2ch BSS using the EM algorithm in reverberant environment. In Proceedings of the 2007 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, NY, USA, 21–24 October 2007; pp. 147–150. [Google Scholar]
- Araki, S.; Theis, F.; Nolte, G.; Lutter, D.; Ozerov, A.; Gowreesunker, V.; Sawada, H.; Duong, N.Q.K. The 2010 Signal Separation Evaluation Campaign (SiSEC2010): Audio Source Separation. Lect. Notes Comput. Sci. 2010, 6365, 414–422. [Google Scholar]
- Koldovsky, Z.; Tichavsky, P.; Oja, E. Efficient Variant of Algorithm FastICA for Independent Component Analysis Attaining the Cram—Rao Lower Bound. IEEE Trans. Neural Netw. 2006, 17, 1265–1277. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Anechoic | = 150 ms | ||||
|---|---|---|---|---|---|
| Method | Method | ||||
| Real ITD | 0.000 | 2.373 | Real ITD | 0.000 | 2.373 |
| DUET | 0.058 | 2.370 | DUET | 0.520 | 2.560 |
| Phat | 0.017 | 2.502 | Phat | 0.217 | 2.500 |
| Izumi | 0.093 | 2.502 | Izumi | 0.337 | 2.946 |
| Proposed | 0.024 | 2.402 | Proposed | 0.179 | 2.428 |
| Anechoic | = 150 ms | ||||
|---|---|---|---|---|---|
| Method | Method | ||||
| Real ITD | 0.000 | 4.060 | Real ITD | 0.000 | 4.060 |
| DUET | 0.020 | 3.963 | DUET | 1.844 | 3.448 |
| Phat | 0.055 | 4.009 | Phat | 0.117 | 4.122 |
| Izumi | 0.045 | 4.018 | Izumi | 0.043 | 4.067 |
| Proposed | 0.012 | 4.039 | Proposed | 0.042 | 4.045 |
| Mic-Distance | 5 cm | 10 cm | 15 cm | |||
|---|---|---|---|---|---|---|
| Method | ||||||
| Real ITD | 0.000 | 1.187 | 0.000 | 2.373 | 0.000 | 3.560 |
| DUET | 0.271 | 1.069 | 0.520 | 2.560 | 1.678 | 3.135 |
| PHAT | 0.163 | 1.296 | 0.217 | 2.500 | 0.126 | 3.652 |
| Izumi | 0.234 | 1.334 | 0.337 | 2.946 | 0.031 | 3.891 |
| Proposed | 0.112 | 1.125 | 0.179 | 2.428 | 0.041 | 3.527 |
| Room1 | x1 | x2 | x3 | x4 | x5 | x6 | |
| Proposed | 11.8 | 7.8 | 14.7 | 26.4 | 4.9 | ||
| 10.5 | 12.2 | 2.7 | 14.0 | 21.2 | |||
| ICA | 0.3 | 10.2 | 18.6 | ||||
| 3.3 | 4.8 | 10.0 | 18.3 | ||||
| Room2 | x1 | x2 | x3 | x4 | x5 | x6 | |
| Proposed | 3.3 | 6.2 | 12.3 | 27.5 | 3.2 | 1.0 | |
| 12.8 | 11.1 | 15.8 | 22.5 | ||||
| ICA | 6.6 | 19.6 | |||||
| 6.2 | 4.8 | 12.0 | 19.4 | ||||
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Ding, Z.; Li, W.; Liao, Q. Dual-Channel Cosine Function Based ITD Estimation for Robust Speech Separation. Sensors 2017, 17, 1447. https://doi.org/10.3390/s17061447
Li X, Ding Z, Li W, Liao Q. Dual-Channel Cosine Function Based ITD Estimation for Robust Speech Separation. Sensors. 2017; 17(6):1447. https://doi.org/10.3390/s17061447
Chicago/Turabian StyleLi, Xuliang, Zhaogui Ding, Weifeng Li, and Qingmin Liao. 2017. "Dual-Channel Cosine Function Based ITD Estimation for Robust Speech Separation" Sensors 17, no. 6: 1447. https://doi.org/10.3390/s17061447
APA StyleLi, X., Ding, Z., Li, W., & Liao, Q. (2017). Dual-Channel Cosine Function Based ITD Estimation for Robust Speech Separation. Sensors, 17(6), 1447. https://doi.org/10.3390/s17061447