1. Introduction
High dimensionality research for data mining is an essential topic in modern imaging applications, such as social networks and the Internet of Things (IoT). It is worth noting that data of high dimension is often supposed to reside in several subspaces of lower dimension. For instance, facial images with various lightning conditions and expressions lie in a union of a nine-dimensional linear subspace [
1]. Moreover, moving motions in videos [
2] and hand-written digits [
3] can also be approximated by multiple low-dimensional subspaces. Inspiringly, these characteristics enable effective segmentation, recognition, and classification to be carried out. The problem of subspace segmentation [
4] is formulated as determining the number of subspaces and partitions the data according to the intrinsic structure.
Many subspace segmentation algorithms have emerged in the past decades. Some of these methods are algebraic or statistical. Among the algebraic methods, generalized principal component analysis (GPCA) [
5] is mostly widely used. GPCA characterizes the data subspace with the gradient of a polynomial, and segmentation is obtained by fitting the data with polynomials. However, the performance drops quickly in the presences of noise, and polynomial fitting computation is time consuming. As to the statistical algorithms, including random sample consensus (RANSAC) [
6], factorization-based methods [
7,
8], and probabilistic principal component analysis (PPCA) [
9], the estimation of exact subspace models exquisitely changed the performance of this type of methods. Recently, spectral-type methods [
10] like sparse representation (SR) [
7,
11,
12], low-rank representation (LRR) [
13,
14,
15], and the extensions base on SR or LRR [
16,
17,
18,
19,
20,
21,
22] have attracted much attention, as they are robust to noise [
11,
12,
13,
14], with strong theoretical backgrounds [
16] and are easy to implement. Once an affinity graph is learned from SR or LRR, segmentation results can be obtained by means of spectral clustering. Therefore, building an affinity graph that accurately captures relevant data structures is a key point for SR- and LRR-based spectral-type models.
A good affinity graph should preserve the local geometrical structure, as well as the global information [
11]. Recently, Elhamifar et al. [
23] presented the sparse subspace clustering (SSC) based on an
l1-graph. The
l1-graph is constructed by using SR coefficients deduced in the
l1-norm minimization to represent the relationships among samples. Attributed to SR, the
l1-graph is sparse, capable of finding neighborhood according to the data and robust to noisy data. Inspired by
l1-graph, various SR-graphs have been proposed [
24]. Wang et al. [
25] provided
l2-Graph based subspace clustering to eliminate errors from various types of projection spaces. Peng et al. [
26] proposed a unified framework for representation-based subspace clustering methods to cluster both the out-of-sample and the large-scale data. Peng et al. [
27] introduced principal coefficients embedding to automatically identify the number of features, as well as learn the underlying subspace in the presence of Gaussian noise. Wang et al. [
28] proposed a race lasso-based regularizer for multi-view data while keeping individual views well encapsulated. However, SR-based methods seek the sparsest representation coefficients of each data point individually, without a global structure regularizer. This drawback alters the robustness of these methods in the presence of outliers [
15], when the data is not “clean” enough. To account for the underlying global information, Liu et al. [
15] presented a two-step algorithm which firstly computes low-rank representation coefficients for data and then uses the coefficient matrix to build an affinity graph (LRR-graph). The LRR-graph jointly represents all the data by solving a nuclear norm optimization problem and, thus, becomes a better option at capturing global information. Numerous LRR-graph-based methods have also been proposed for spectral clustering. For example, Wang et al. [
28] proposed a multi-graph Laplacian-regularized LRR to characterize the non-linear spectral graph structure from each view. Both SSC and LRR are based on convex relaxations of the initial problems, SSC uses
l1-norm to approximate the number of non-zero elements, while LRR applies nuclear norm to compute the number of non-vanishing singular values. These convex relaxations yield solutions that deviate far from solutions to the original problems. Hence, it is desirable to rather use non-convex surrogates, without causing any significant increase in computational complexity.
A large number of studies on non-convex surrogates for
l0-norm problem have been addressed recently. Xu et al. [
29] introduced the
l1/2-norm in noisy signal recovery with an efficient iterative half-thresholding algorithm. Similarly, Zhang et al. [
30] proposed the
lp-norm minimization with a generalized iterative shrinkage and thresholding method (GIST). Their study shows
lp-norm based model is more effective on image denoising and image deburring. Numerous researchers also considered the other non-convex surrogate functions, such as homotopic
L0-minimization [
31], smoothly clipped absolute deviation (SCAD) [
32], multi-stage convex relaxation [
17], logarithm [
33], half-quadratic regularization (HQR) [
34], exponential-type penalty (ETP) [
35], and minimax concave penalty (MCP) [
36]. Recent years have also witnessed the progress in non-convex rank minimization functions. Mohan et al. [
37] developed an efficient IRLS-
p to minimize rank function, and improved the recovery performance for matrix completion. Xu et al. [
18] introduced the
S1/2-norm with an efficient ADMM solver for video background modeling. Kong et al. [
38] proposed a Schatten
p-norm constrained model to recover noisy data. Another popular non-convex rank minimization is the truncated nuclear norm [
39]. They all compete with the state-of-the-art algorithms to some extent.
Combining the non-convex
lp-norm regularizer with the Schatten
p-norm (0 <
p ≤ 1), in this study, we propose a robust method named non-convex sparse and low-rank-based robust subspace segmentation (
lpS
pSS). Our
lp-norm error function can better predict errors, which further improves the robustness of subspace segmentation. Meanwhile, the Schatten
p-norm-regularized objective function shows a better ability to approximate the rank of coefficient matrix compared with the nuclear norm. Our method can provide a more accurate description of the global information and better measurement of data redundancy. Thus, our new objective is to solve joint the
lp-norm and Schatten
p-norm (0 <
p ≤ 1) minimization together. When
p→0, our proposed
lpS
pSS turns to be more robust and effective than SR- and LRR-based subspace segmentation algorithms. In addition, we enforce non-negative constraint to the reconstruction coefficients, which aids interpretability and allows better solutions in numerous application areas such as text mining, computer vision, and bioinformatics. Traditionally, an alternating direction method (ADM) [
40] can solve this optimization problem efficiently. However, to increase the speed and scalability of the algorithm, we choose an efficient solver commonly named the linearized alternating direction method with adaptive penalty (LADMAP) [
19]. As it is based on fewer auxiliary parameters and without an inverse of its matrix, it is more efficient than ADM. Numerical experimental results verify our proposed method, which consistently obtains better segmentation results.
The rest of this paper is structured as follows: In
Section 2, the notations, as well as the overview of SSC and LRR, will be presented.
Section 3 is dedicated to introducing our novel non-convex sparse and low-rank based robust subspace segmentation.
Section 4 conducts multiple numerical experiments to examine the effectiveness and robustness of
lpS
pSS.
Section 5 concludes this work.
3. Non-Convex Sparse and Low-Rank Based Robust Subspace Segmentation
In this section, we first propose the non-convex sparse and low-rank-ased robust subspace segmentation model, in which we combine the lp-norm with the Schatten p-norm together for clustering, and then use LADMAP to solve lpSpSS. Finally, we analyze of the time complexity of lpSpSS.
3.1. Model of lpSpSS
We consider the non-convex sparse and low-rank-based subspace segmentation for data contaminated by noise and corruption. Notice that the nuclear norm is replaced by the Schatten
p-norm, when
p is smaller than 1, the underlying global information can be captured more effectively. Additionally, the
lp norm (0 <
p ≤ 1) of the coefficient matrix is also introduced as an error function, in order to harvest stronger robustness to noise [
42]. It has been demonstrated in some recent research [
43] that the Schatten
p-norm is more powerful than the nuclear norm in matrix completion, and the recovery performance of the
lp-norm is also superior to the convex
l1-norm [
36]. Our
lpS
pSS will surely be more effective than the convex methods.
We begin by considering the relaxed low-rank subspace segmentation problem, which is equivalent to:
In which, the first term is the lp-norm, which improves the integration of the local geometrical structure. Meanwhile, the second term is the Schatten p-norm, which can better approximate the rank of Z. Moreover, the third term reconstruction error is the l2,1 norm, which can better characterize errors like corruption and outliers. β and λ are trade-off parameters. Regarding the widely-used non-negative constraint (Z ≥ 0), which is to ensure direct use of the reconstruction coefficients in the affinity graph construction.
3.2. Solution to lpSpSS
3.2.1. Brief Description of LADMAP
We adopt LADMAP [
19] to solve the objective function (Equation (8)) constrained by the
lp-norm norm and Schatten-
p regularizers. An auxiliary variable
W is introduced and the optimization problem becomes separable. Thus, Equation (8) is rewritten as:
To remove two linear constraints in Equation (9), we introduce two Lagrange multipliers
Y1 and
Y2, hence, the optimization problem is defined using the following Lagrangian function:
where
,
Y1 and
Y2 are the Lagrange multipliers, and
μ ≥ 0 is a trade-off parameter. We solve Equation (10) by minimizing
L to update each variable with the other variables fixed. The updating schemes at each iteration can be designed as follows:
In Equation (12),
is the partial differential of
q with respect to
Z,
. In particular, the detailed procedures of LADMAP are shown in Algorithm 1. The first, Equation (11), and the second, Equation (12), are solved using the following subsections. The last convex problem (Equation (13)) can solved by the
l2,1-norm minimization operator [
15].
| Algorithm 1. LADMAP for solving Equation (9). |
| Input: Data X, tradeoff variables β > 0, λ > 0 |
| Initialize: Z(0) = W(0) = E(0), Y1(0) = Y1 (0) = 0, µ(0) = 0.1, µmax = 107, ρ0 = 1.1, ε1 = 10−7, ε2 = 10−6, k = 0,, and the number of maximum iteration MaxIter = 1000. |
While not converged and k ≤ MaxIter do- (1)
Compute W(k+1) by solving Equation (11) with Z(k+1), E(k+1) are fixed; - (2)
Compute Z(k+1) by solving Equation (12) with W(k+1), E(k+1) are fixed; - (3)
Compute E(k+1) by solving Equation (13) with W(k+1), Z(k+1) are fixed; - (4)
Compute the multipliers Y1 (k + 1)and Y2 (k + 1) as follows: - (5)
Compute µ(k + 1) as follows: , in which - (6)
Converges when In which - (7)
Increment of iteration: k = k + 1.
|
| End while |
| Output: The optimal solution W, Z and E. |
3.2.2. Solving the Non-Convex lp-Norm Minimization Subproblem (Equation (11))
For each element in
, we can decouple Equation (11) into a simplified formula:
Recently, Zhang et al. solved this
lp-norm optimization problem via the proposed GIST [
30]. For
lp-norm minimization, the thresholding function is:
Meanwhile, the generalized soft-thresholding function is:
The corresponding thresholding rule in the generalized soft-thresholding function is when , and corresponding shrinkage rule is when .
3.2.3. Solving the Non-Convex Schatten p-Norm Minimization Subproblem (Equation (12))
We can reformulate Equation (12) as the following simplified notation:
After applying SVD on
X,
X is decomposed into summation of
r rank-
p matrices
X = UΔVT. Here,
U is the left singular vector,
Δ is the non-zero singular diagonal matrix, and
V is the right singular vector. The
i-th singular value
δi is solved by:
Equation (16) can be used to solve Equation (18) again. For
p = 1, we can obtain the same solution with nuclear norm minimization [
44].
3.3. Convergence and Computational Complexity Analysis
Although Algorithm 1 is described in three major alternative steps for solving
W,
Z, and
E, we can actually combine steps for
Z and
E easily into one larger block step by simultaneously solving for (
Z, E). Thus, the convergence conclusion of two variables LADMAP in [
45] can be applied to our case. Finally, the convergence of the algorithm is ensured.
Suppose the size of X are d × n, k is number of total iterations, and r is the lowest rank for X. The major time consumption of Algorithm 1 is mainly determined by Step 2, as it involves time-consuming SVDs. In Step 1, each component of can be computed in O(rn2) by using the skinny SVD to update W. In Step 2, the complexity of the SVD to update Z is approximately O(d2n). In Step 3, the computation complexity of l2,1 minimization operator is about O(dn). The total complexity is, thus, O(krn2 + kd2n). Since r ≤ min(d, n), the time cost is, at most, O(krn2).
3.4. Affinity Graph for Subspace Segmentation
Once Equation (9) was solved by LADMAP, we can obtain the optimal coefficient matrix Z*. Since every sample is reconstructed by its neighbors, Z* naturally characterizes the relationships among samples. Such information is a good indicator of similarity among samples, we use the reconstruction coefficients to build the affinity graph. The non-convex lp-norm ensures that each sample only connects to few samples. As a result, the weights of the graph tend to be sparse. While the non-convex Schatten p-norm ensures samples lying in the same subspace are highly correlated and tend to be assigned into the same cluster, Z* is theoretically able to capture the global information, and the graph weights are constrained with non-negativity, as they reflect similarities between data points.
After obtaining the coefficient matrix Z*, the reconstruction coefficients of each sample are normalized and thresholded to zero. Therefore, the obtained normalized sparse can be used to compute the affinity graph . Finally, W carries out spectral clustering to obtain the segmentation results. Our proposed non-convex sparse and low-rank based subspace segmentation is outlined in Algorithm 2.
| Algorithm 2. lpSpSS. |
Input: Matrix , tradeoff parameters β, λNormalize each sample xi to obtain . Solve the non-convex sparse and low-rank constrained program by Algorithm 1: and get (Z*, E*). Normalize coefficient matrix, and threshold small values by θ to obtain . Set weights for affinity graph by . The data is segmented by spectral clustering.
Output: The segmentation results. |
4. Experimental Evaluation and Discussion
In the following, we will discuss the performance of our proposed
lpS
pSS model. Firstly, the experimental setting is detailed in
Section 4.1. From
Section 4.2,
Section 4.3,
Section 4.4, we will test the segmentation performance of
lpS
pSS on CMU-PIE, COIL20, and USPS. In
Section 4.5, we will examine the robustness of
lpS
pSS to block occlusions and pixel corruptions. Finally, the discussion of experimental results will be given in
Section 4.6.
4.1. Experimental Settings
The proposed
lpS
pSS approach will be evaluated on realistic images and compared with five related works. We use four publicly-available datasets, including CMU-PIE [
46], COIL20 [
47], USPS [
48], and Extended Yale B [
49]. Among them, datasets [
46] and [
49] contain face images with various poses/illuminations/facial expressions, COIL20 consists of different general objects, and USPS includes handwritten digit images. Our proposed
lpS
pSS will be compared with five segmentation methods, including PCA, SSC [
16], LRR [
15], and NNLRS [
50], while K-means serves as a baseline for comparison.
We adopt the same experimental settings as Zhuang’s work [
50]. For the compared methods, a grid search strategy is used for selecting model parameters, and the optimal segmentation is achieved by tuning the parameters carefully. As to our
lpS
pSS, there are two regularized parameters,
β and
λ, affecting its performance. We take a stepwise selection strategy to search the best parameters. For example, we search the possible candidate interval
λ may exit, with
β fixed, and alternatively search
λ’s most possible candidate interval, with
β fixed. Finally, the best values are found in a two-dimensional candidate space of (
β, λ).
To quantitatively and effectively measure the segmentation performance, two quantity metrics, namely accuracy (AC) and normalized mutual information (NMI) [
51], are used in our experiments. All the experiments are implemented by MATLAB, on a MacBook Pro with a 2.6 GHz Intel Core i7 CPU and 16 GB memory.
4.2. Segmentation Results on CMU-PIE Database
In this experiment, we compare
lpS
pSS with the other five methods on the CMU-PIE facial images dataset. It includes 41,368 pictures of 68 persons, acquired with various postures and lighting scenarios. The resolution of each image is 32 × 32 = 1024 pixels. Typical examples of CMU-PIE are shown in
Figure 1. For each given cluster number
K = 4
,..., 68 in the whole dataset, the segmentation results with different
K were averaged on the twenty tests. The averaged segmentation performance of proposed and existing algorithms on the CMU-PIE dataset [
46] are reported in
Table 1.
We can see that our proposed lpSpSS achieves the best segmentation AC and NMI on CMU-PIE dataset, which proves the effectiveness of our lpSpSS. For example, the average segmentation accuracy of NNLRS and lpSpSS are 84.1% and 89.8%, respectively. lpSpSS improves the segmentation accuracy by 5.7% compared with NNLRS (the second best algorithm). The improvement of lpSpSS indicates the importance of the non-convex SR and LRR affinity graph.
4.3. Segmentation Results on COIL20 Database
When it comes to the evaluation using second dataset COIL20 [
49], the proposed
lpS
pSS is compared with five existing algorithms. This dataset contains 1440 images of 20 objects, with 72 different views. The resolution of each picture is 32 × 32 = 1024 pixels. Typical examples of COIL20 are shown in
Figure 2. For each given cluster number
K = 2
,...,20 in the whole dataset, the segmentation results with different
K were averaged on the twenty tests. The averaged segmentation performances of the proposed and existing algorithms on the COIL20 dataset [
47] are reported in
Table 2.
Experimental results on COIL20 indicates that our lpSpSS outperforms the other five existing algorithms. For example, the average AC and NMI of lpSpSS are 90.2% and 91.0%, which are higher than for NNLRS (the second best algorithm) by 2.0% and 1.5%, respectively. Especially, when the cluster number is large, the superiority of lpSpSS is very obvious.
4.4. Segmentation Results on USPS Handwritten Digit Dataset
In this experiment, we compare
lpS
pSS with the other five methods on the USPS handwritten digit dataset. It contains 9298 images of 10 classes, with a variety of orientations. The resolution of each picture is 16 × 16 = 256 pixels.
Figure 3 shows typical sample images in the USPS dataset. For each given cluster number
K = 2,
...,10, the segmentation results with different
K were averaged on the twenty tests. The averaged segmentation performances of proposed and existing algorithms on the USPS handwritten digit dataset are reported in
Table 3.
Table 3 shows that our proposed
lpS
pSS still obtains the best segmentation performance. This result demonstrates that a non-convex sparse and low-rank graph is better to model complex related data than traditional SR and LRR based graphs. Experimental results have demonstrated that our proposed
lpS
pSS model can not only represent the global information, but also preserves the local geometrical structures in the data by incorporating the non-convex
lp-norm regularizer.
4.5. Segmentation Results on Dataset with Block Occlusions and Pixel Corruptions
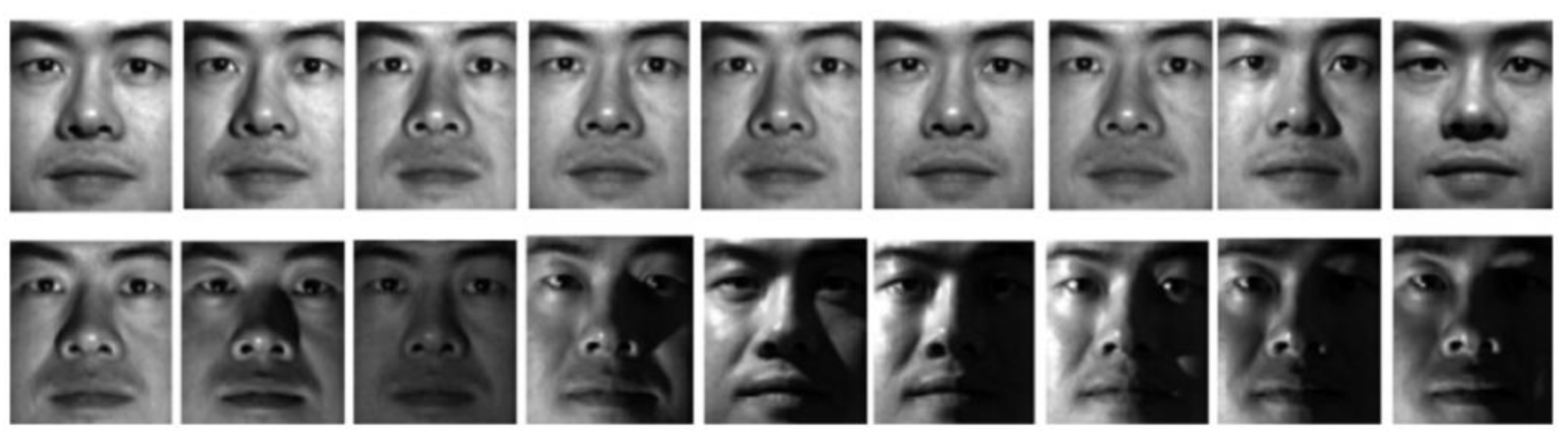
Finally, we evaluate the robustness of each model on the more challenging Extended Yale B face dataset. It has 38 × 64 facial images, with various lighting scenarios. To reduce the resources and budget, the resolution of each picture is downsized to 96 × 84. This dataset more challenging for subspace segmentation, as 50% of the samples with hard shadows or specularities.
Figure 4 shows typical sample images of Extended Yale B.
We select 1134 images from first 18 individuals to evaluate the different methods. Two types of corruptions are introduced into this experiment. For Type I block occlusions, different block sizes (from 5 × 5 to 20 × 20) are added to randomly selected locations of the images. For Type II random pixel corruption, randomly-chosen pixels on each images are substituted with equally-distributed random values. The proportion of corrupted pixels per image is from 0 to 20%. Some examples from corrupted Extended Yale B face images are shown in
Figure 5. The averaged segmentation AC of proposed and existing algorithms with multiple block occlusions and pixel corruptions are tabulated in
Table 4 as well as
Table 5.
Both experimental results show that our lpSpSS achieves the best segmentation results again. Segmentation results suggest that proposed lpSpSS is more robust than compared methods, especially when a significant portion of the realistic samples are corrupted.
4.6. Discussions
Our lpSpSS outperforms five existing subspace segmentation algorithms. Especially, in the case of CMU-PIE face dataset, the improvement by lpSpSS is largest. Our affinity graph can capture the local geometrical structure, as well as the global information of the data, hence, is both generative and discriminative.
lpSpSS is more robust than the other compared methods, which can properly deal with multiple noises. Images in Extended Yale B dataset contain different errors, including block occlusions, pixel corruptions, illuminations, partition them is challenging. However, lp-norm and Schatten p-norm are introduced for lpSpSS affinity graph construction. Therefore, our model can better predict errors and is a better measurement for data redundancy.
The segmentation performance of SSC and LRR are almost the same. For example, the segmentation accuracy of SSC on CMU-PIE is 0.9% better than LRR, while the performance of LRR on USPS is 0.7% higher than SSC. The segmentation results heavily depends on the intrinsic structure of the testing dataset, it is difficult to determine which one is better.
The LRR-based algorithm is robust in handling noisy data. It aims at obtaining the low rankness of coefficient matrix, thus, the LRR-based methods can better model the global information. Furthermore, LRR can find similar clusters which measure the data redundancy, ensuring high quality and stability of the segmentation results. For data heavily contaminated with corruptions or outliers, the model can find lower ranks that will be more robust to noise.
However, SVD computation for Schatten p-norm minimization is performed in each iteration, which is very time consuming, and the best segmentation results are not achieved at the lowest value of p. Hence, we will be focused on the study of speeding up the Schatten p-norm solver and the selection of best p values in our future work.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}