Constrained Active Learning for Anchor Link Prediction Across Multiple Heterogeneous Social Networks

Abstract
:1. Introduction
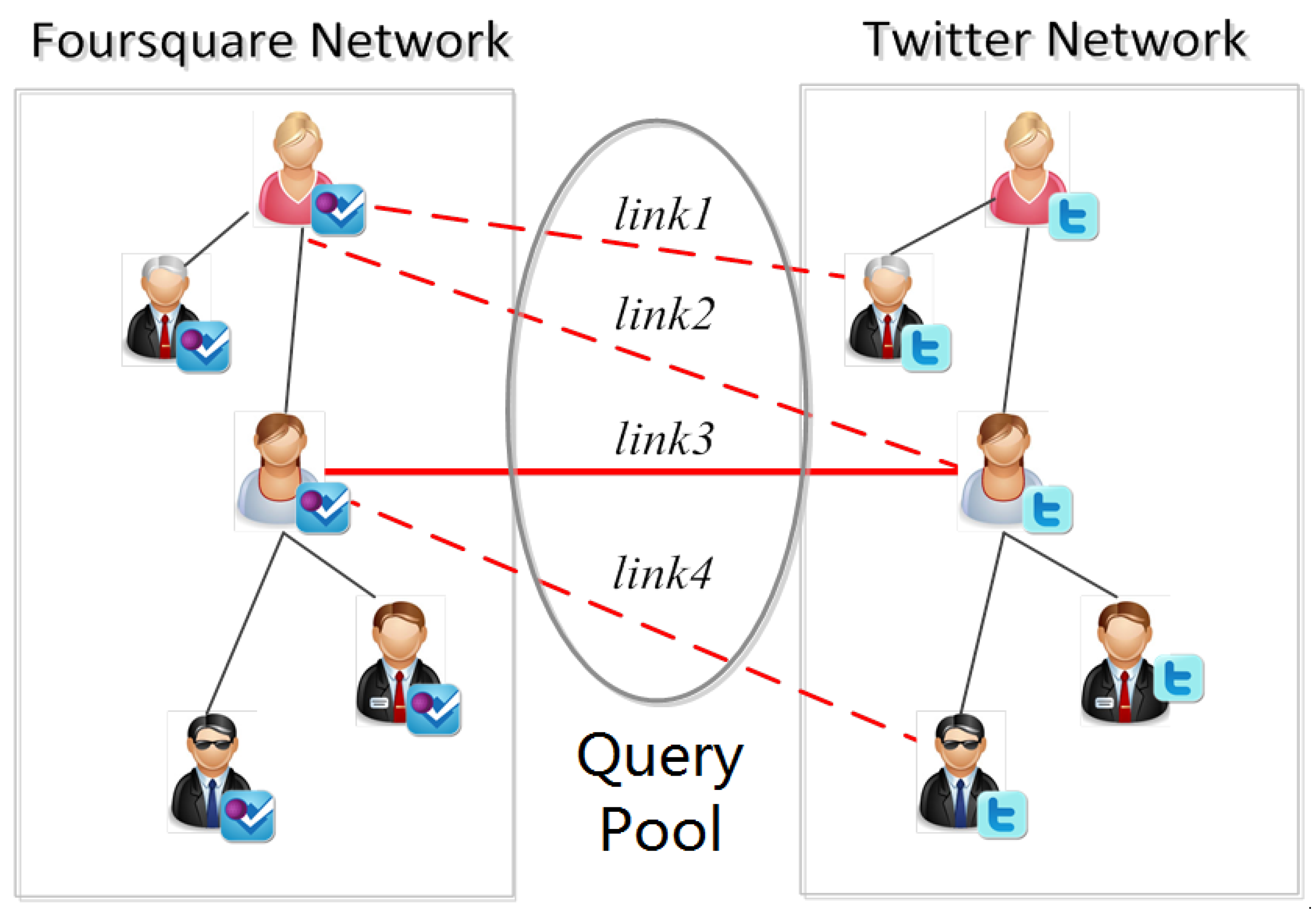
- one-to-one constraint on anchor links: anchor links have an inherent one-to-one constraint [1], which has never been considered in traditional active learning methods at all. Via the one-to-one constraint, when identifying one positive anchor link, a group of negative anchor links incident to its nodes can be discovered from the networks. Viewed in such a perspective, identifying positive anchor links and using the one-to-one constraint to infer their related negative links will be very important for the active anchor link prediction problem.
- sparsity of anchor links: unlike other kinds of social network link, due to the one-to-one constraint, the positive anchor links between two given networks are extremely sparse, and only account for a small proportion among all the potential inter-network user pairs. As a result, when collecting the training set, acquiring enough positive anchor links under a limited cost is very challenging.
- heterogeneity of social networks: anchor links in online social networks can be associated with heterogeneous information, like various types of attributes and complex connections [1]. How to properly apply such heterogeneous information to the active learning for anchor link prediction is quite different from traditional active learning and link prediction problems.
2. Related Works
3. Problem Formulation
4. The Constrained Active Learning for Anchor Link Prediction
4.1. The Basic Anchor Link Prediction Method
- Multi-Network Social Features: extracted by evaluating the similar social links of two user accounts from different social networks, to represent the social similarity between two user accounts.
- Spatial Distribution Features: extracted by comparing the location information of two user accounts in different ways, to represent people’s location similarities.
- Temporal Distribution Features: extracted by using different ways to compare the distribution of different users’ activities in the given time slots, to represent people’s temporal similarities.
- Text Content Features: extracted by evaluating the similarity of words used by two user accounts from different social networks, to represent the similarity of text contents posted by two user accounts.
4.2. The Constrained Active Learning Methods
4.2.1. The Normal Constrained Active Learning Methods
- The Basic-entropy-based Constrained Active Learning (BC): Using this method, the active learner calculates of an unlabeled link a by its basic entropy . Here, the basic entropy can also be viewed as the amount of information contained in the link. To a given unlabeled anchor link a, the basic entropy of it is as follows:Here, is the posterior probability of link a’s value to be y under the prediction model .
- The Mean-entropy-based Constrained Active Learning (MC): different from BC, MC calculates for an unlabeled anchor link a not only by its own entropy, but also by the mean entropy of all the links in a’s related link set .
| Algorithm 1 The framework of Normal Constrained Active Learning |
| Input: Two heterogeneous social networks: and . Two sets of labeled anchor link: The training set and the validation set . The query pool . The max number of queries . The potential entropy computation method . |
Output: The new training set and the new query pool
|
4.2.2. The Biased Constrained Active Learning Methods
| Algorithm 2 The framework of Biased Constrained Active Learning |
| Input: Two heterogeneous social networks: and . Two sets of labeled anchor link: The training set and the validation set . The query pool . The max number of queries . The potential entropy computation method . The threshold adjusting pace |
Output: The new training set and the new query pool
|
5. Experimental Section
5.1. Data Preparation
5.2. Experiment Setups
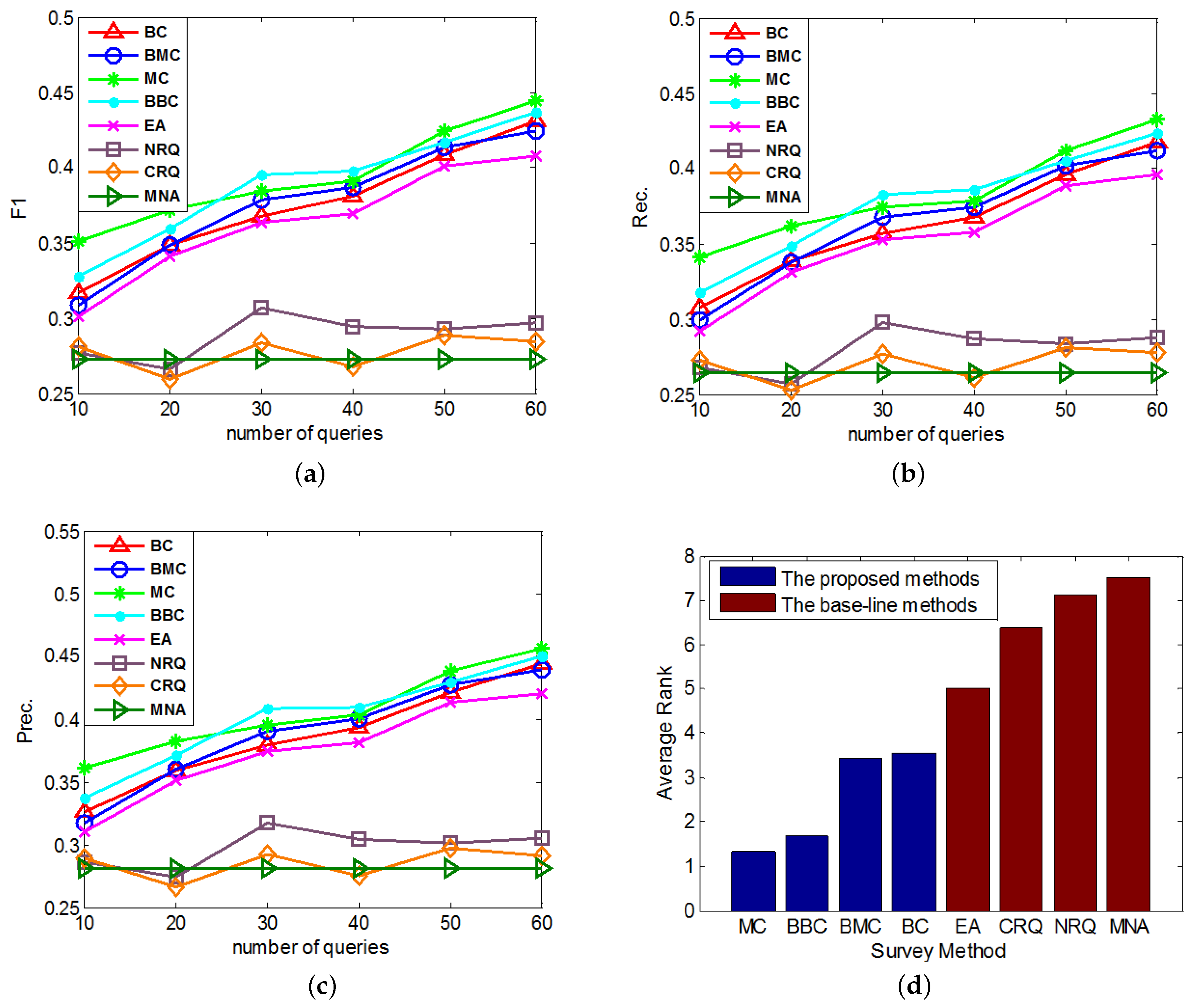
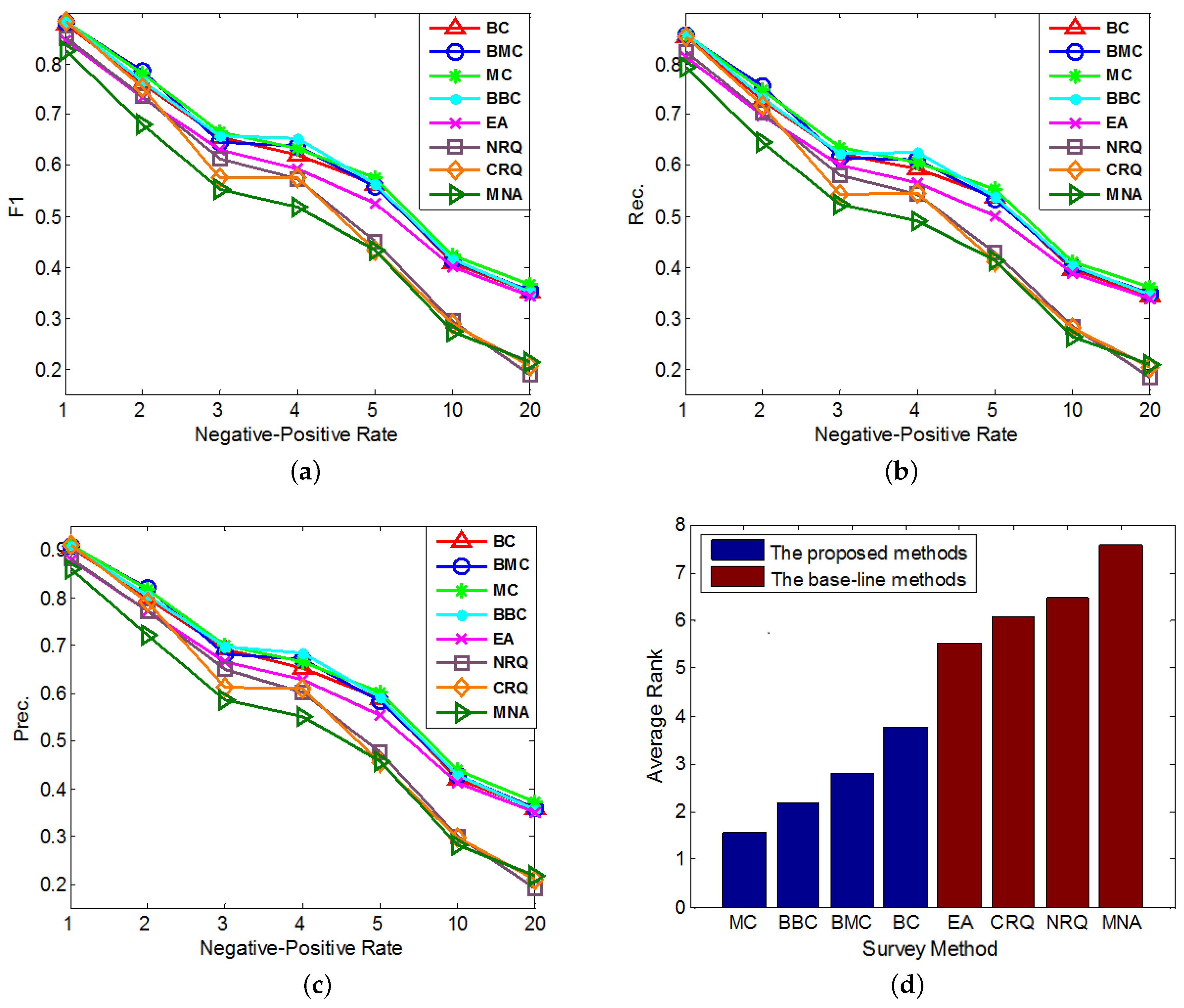
5.3. Effectiveness Experiments
- The Normal Constrained Active Learning methods: The first kind of proposed methods in this paper, including the Basic-entropy-based Constrained Active Learning (BC) and Mean-entropy-based Constrained Active Learning (MC).
- The Biased Constrained Active Learning methods: The second kind of proposed methods in this paper, including the Biased Basic-entropy-based Constrained Active Learning (BBC) and Biased Mean-entropy-based Constrained Active Learning (BMC).
- MNA: A state-of-art supervised anchor link prediction method based on heterogeneous features and outperforms [1], which doesn’t do any query to enlarge its original training set.
- The Random Query Methods: Two base-line query methods integrated to MNA for better comparison. One is the Normal Random Query (NRQ) which only adds the randomly queried links to ; the other is the Constrained Random Query (CRQ), which adds not only the randomly queried links, but also the related link set of each queried positive link to .
- Overall, MC outperforms other methods on the anchor link prediction. However, the listed performances of BBC are not much worse than MC. In addition, compared with BBC, MC needs a reasonable validation set to do anchor link prediction. So to the anchor link prediction problem, MC would be the best choice if we have enough labeled anchor links to form a reasonable validation set. However, when the labeled anchor links in the validation set are not sufficient, the sample distribution of the validation set can be very different from the sample distribution of the overall experimental data. In addition, thus according to what we analyzed in the definition of Equation (5), the computed potential entropies of MC in the query pool are not precise, which can result in the bad performances of MC. So in this circumstance, BBC would be a better choice.
- According to the average rank of each compared method, BBC performs better than BC. However, BMC cannot perform better than MC. To understand this, we can suppose that there exist two anchor links in , whose basic entropies are the same, and related link sets contain the same amount of information. In addition, thus from these two links, the MC prefers to identify the one with bigger (See Equation (5)). Furthermore, according to the definition of , the bigger is, the more likely a is to be a positive anchor link. So we can see MC already has a reasonable mechanism to prefer the potentially positive links. As a result, adding a new mechanism of preferring potential positive links is not easy to make MC perform better. Because this new mechanism may make MC focus on identifying the links that are easy to be correctly predicted as positive, but neglect some informative links whose labels are hard to be correctly predicted. And this may also be the reason why BMC cannot outperform BBC in these experiments.
- All of our proposed Constrained Active Learning methods perform better than EA, it proves the value of applying the one-to-one constraint to the active learning in anchor link prediction problem.
- In the same experiment, the performance ranks of each method on metrics F1, Prec. and Rec. are almost the same.
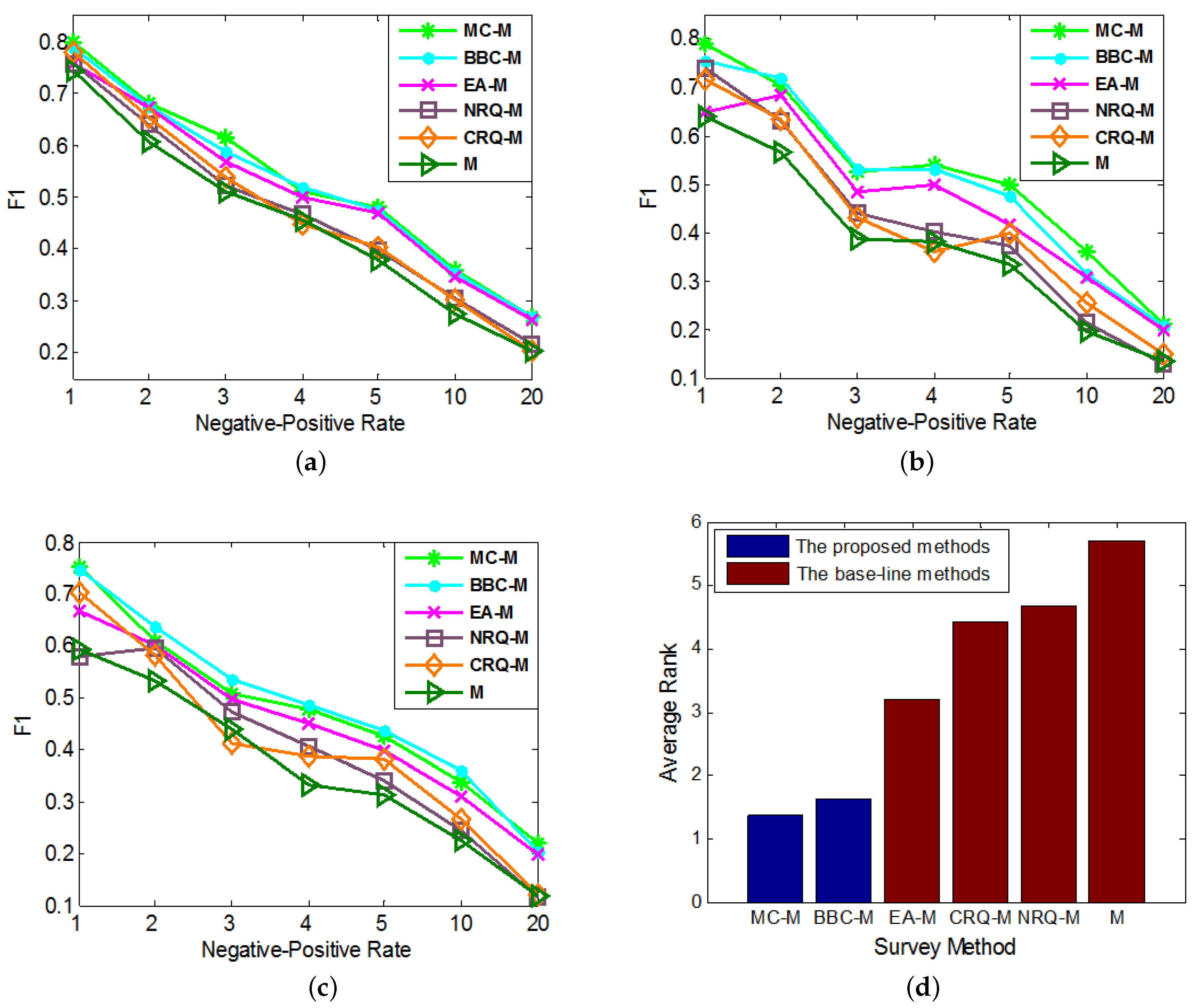
5.4. Portability Experiments
- M: The basic anchor link prediction method (which can be set as , or ). It will be directly used as a base-line method.
- MC-M: Integrating the proposed Mean-entropy-based Cons- trained Active Learning (MC) method to M.
- BBC-M: Integrating the proposed Biased Basic-entropy-based Constrained Active Learning (BBC) method to M.
- EA-M: Integrating the Entropy-based Active Learning (EA) method to M. It will be used as a base-line method.
- NRQ-M and CRQ-M: Two base-line query methods integrated to method M for better comparison. One is the Normal Random Query (NRQ); the other is the Constrained Random Query (CRQ).
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Kong, X.; Zhang, J.; Yu, P.S. Inferring anchor links across multiple heterogeneous social networks. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 179–188. [Google Scholar]
- Zhang, J.; Philip, S.Y. Multiple anonymized social networks alignment. In Proceedings of the 2015 IEEE 15th International Conference on Data Mining, Atlantic City, NJ, USA, 14–17 November 2015; pp. 599–608. [Google Scholar]
- Pu, J.; Teng, Z.; Gong, R.; Wen, C.; Xu, Y. Sci-Fin: Visual Mining Spatial and Temporal Behavior Features from Social Media. Sensors 2016, 16, 2194. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Kong, X.; Philip, S.Y. Predicting social links for new users across aligned heterogeneous social networks. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining, Dallas, TX, USA, 7–10 December 2013; pp. 1289–1294. [Google Scholar]
- Liu, D.; Wu, Q.Y. Cross-Platform User Profile Matching in Online Social Networks. Appl. Mech. Mater. 2013, 380, 1955–1958. [Google Scholar] [CrossRef]
- Nie, Y.; Huang, J.; Li, A.; Zhou, B. Identifying users based on behavioral-modeling across social media sites. In Proceedings of the 16th Asia-Pacific Web Conference, Changsha, China, 23–25 September 2014; pp. 48–55. [Google Scholar]
- Zhang, Y.; Tang, J.; Yang, Z.; Pei, J.; Yu, P.S. Cosnet: Connecting heterogeneous social networks with local and global consistency. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 1485–1494. [Google Scholar]
- Lu, C.T.; Shuai, H.H.; Yu, P.S. Identifying your customers in social networks. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 391–400. [Google Scholar]
- Zafarani, R.; Liu, H. Connecting users across social media sites: a behavioral-modeling approach. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 41–49. [Google Scholar]
- Malhotra, A.; Totti, L.; Meira, W., Jr.; Kumaraguru, P.; Almeida, V. Studying user footprints in different online social networks. In Proceedings of the 2012 International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2012), Istanbul, Turkey, 26–29 August 2012; pp. 1065–1070. [Google Scholar]
- Liu, S.; Wang, S.; Zhu, F.; Zhang, J.; Krishnan, R. Hydra: Large-scale social identity linkage via heterogeneous behavior modeling. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; pp. 51–62. [Google Scholar]
- Vosecky, J.; Hong, D.; Shen, V.Y. User identification across multiple social networks. In Proceedings of the 2009 First International Conference on Networked Digital Technologies, Ostrava, Czech Republic, 28–31 July 2009; pp. 360–365. [Google Scholar]
- Backstrom, L.; Dwork, C.; Kleinberg, J. Wherefore art thou r3579x? Anonymized social networks, hidden patterns, and structural steganography. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; ACM: New York, NY, USA, 2007; pp. 181–190. [Google Scholar]
- Settles, B.; Craven, M. An analysis of active learning strategies for sequence labeling tasks. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Honolulu, HI, USA, 25–27 October 2008; pp. 1070–1079. [Google Scholar]
- Settles, B. Active Learning Literature Survey; Technical Report; University of Wisconsin: Madison, WI, USA, 2010. [Google Scholar]
- Roy, N.; McCallum, A. Toward optimal active learning through monte carlo estimation of error reduction. In Proceedings of the 18th International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001; pp. 441–448. [Google Scholar]
- Tong, S.; Koller, D. Support vector machine active learning with applications to text classification. J. Mach. Learn. Res. 2001, 2, 45–66. [Google Scholar]
- Chattopadhyay, R.; Wang, Z.; Fan, W.; Davidson, I.; Panchanathan, S.; Ye, J. Batch mode active sampling based on marginal probability distribution matching. ACM Trans. Knowl. Discov. Data (TKDD) 2013, 7, 13. [Google Scholar] [CrossRef]
- Wang, Z.; Ye, J. Querying discriminative and representative samples for batch mode active learning. ACM Trans. Knowl. Discov. Data (TKDD) 2015, 9, 17. [Google Scholar] [CrossRef]
- Bilgic, M.; Getoor, L. Link-based active learning. In Proceedings of the NIPS Workshop on Analyzing Networks and Learning with Graphs, Whistler, BC, Canada, 11 December 2009. [Google Scholar]
- Bilgic, M.; Mihalkova, L.; Getoor, L. Active learning for networked data. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 79–86. [Google Scholar]
- Xu, Z.; Kersting, K.; Joachims, T. Fast active exploration for link-based preference learning using gaussian processes. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Barcelona, Spain, 20–24 September 2010; pp. 499–514. [Google Scholar]
- Bhattacharya, I.; Getoor, L. Collective entity resolution in relational data. ACM Trans. Knowl. Discov. Data (TKDD) 2007, 1, 5. [Google Scholar] [CrossRef]
- Tsikerdekis, M.; Zeadally, S. Multiple account identity deception detection in social media using nonverbal behavior. IEEE Trans. Inf. Forensics Secur. 2014, 9, 1311–1321. [Google Scholar] [CrossRef]
- Liben-Nowell, D.; Kleinberg, J. The link-prediction problem for social networks. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 1019–1031. [Google Scholar] [CrossRef]
- Wang, C.; Satuluri, V.; Parthasarathy, S. Local probabilistic models for link prediction. In Proceedings of the 7th IEEE International Conference on Data Mining, Omaha, NE, USA, 28–31 October 2007; pp. 322–331. [Google Scholar]
- Al Hasan, M.; Chaoji, V.; Salem, S.; Zaki, M. Link prediction using supervised learning. In Proceedings of the SDM06: Workshop on Link Analysis, Counter-terrorism and Security, Bethesda, MD, USA, 2006. [Google Scholar]
- Wang, D.; Pedreschi, D.; Song, C.; Giannotti, F.; Barabasi, A.L. Human mobility, social ties, and link prediction. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; ACM: New York, NY, USA, 2011; pp. 1100–1108. [Google Scholar]
- Benchettara, N.; Kanawati, R.; Rouveirol, C. Supervised machine learning applied to link prediction in bipartite social networks. In Proceedings of the 2010 International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Odense, Denmark, 9–11 August 2010; pp. 326–330. [Google Scholar]
- Goga, O.; Loiseau, P.; Sommer, R.; Teixeira, R.; Gummadi, K.P. On the Reliability of Profile Matching Across Large Online Social Networks. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Hilton, Sydney, 10–13 August 2015; ACM: New York, NY, USA, 2015; pp. 1799–1808. [Google Scholar]
- Zhang, J.; Philip, S.Y. Integrated Anchor and Social Link Predictions across Social Networks. In Proceedings of the 24th International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 2125–2132. [Google Scholar]
- Pan, W.; Xiang, E.W.; Liu, N.N.; Yang, Q. Transfer Learning in Collaborative Filtering for Sparsity Reduction. In Proceedings of the 24th AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 2010; Volume 10, pp. 230–235. [Google Scholar]
- Yan, M.; Sang, J.; Xu, C.; Hossain, M.S. A Unified Video Recommendation by Cross-Network User Modeling. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2016, 12, 53. [Google Scholar] [CrossRef]
- Yan, M.; Sang, J.; Xu, C. Unified youtube video recommendation via cross-network collaboration. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, Shanghai, China, 23–26 June 2015; ACM: New York, NY, USA, 2015; pp. 19–26. [Google Scholar]
- Bordes, A.; Ertekin, S.; Weston, J.; Bottou, L. Fast Kernel Classifiers With Online And Active Learning. J. Mach. Learn. Res. 2005, 6, 1579–1619. [Google Scholar]
- Tuia, D.; Pasolli, E.; Emery, W.J. Using active learning to adapt remote sensing image classifiers. Remote Sens. Environ. 2011, 115, 2232–2242. [Google Scholar] [CrossRef]
- Rahhal, M.M.A.; Bazi, Y.; Alhichri, H.; Alajlan, N.; Melgani, F.; Yager, R.R. Deep learning approach for active classification of electrocardiogram signals. Inf. Sci. 2016, 345, 340–354. [Google Scholar] [CrossRef]
- Bellala, G.; Stanley, J.; Bhavnani, S.K.; Scott, C. A Rank-Based Approach to Active Diagnosis. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2078–2090. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Li, M.; Xu, J.; Song, G. An effective procedure exploiting unlabeled data to build monitoring system. Expert Syst. Appl. Int. J. 2011, 38, 10199–10204. [Google Scholar] [CrossRef]
- Jiang, P.; Hu, Z.; Liu, J.; Yu, S.; Wu, F. Fault Diagnosis Based on Chemical Sensor Data with an Active Deep Neural Network. Sensors 2016, 16, 1695. [Google Scholar] [CrossRef] [PubMed]
- Isele, R.; Bizer, C. Active learning of expressive linkage rules using genetic programming. Web Semant. Sci. Serv. Agents World Wide Web 2013, 23, 2–15. [Google Scholar] [CrossRef]
- Xiong, S.; Azimi, J.; Fern, X.Z. Active learning of constraints for semi-supervised clustering. IEEE Trans. Knowl. Data Eng. 2014, 26, 43–54. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Property | Network | ||
|---|---|---|---|
| Foursquare | |||
| # node | user | 600 | 600 |
| user/tip | 889,925 | 9012 | |
| location | 41,196 | 7578 | |
| # link | friend/follow | 6640 | 3611 |
| write | 889,925 | 9012 | |
| locate | 48,268 | 9012 | |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, J.; Zhang, J.; Wu, Q.; Jia, Y.; Zhou, B.; Wei, X.; Yu, P.S. Constrained Active Learning for Anchor Link Prediction Across Multiple Heterogeneous Social Networks. Sensors 2017, 17, 1786. https://doi.org/10.3390/s17081786
Zhu J, Zhang J, Wu Q, Jia Y, Zhou B, Wei X, Yu PS. Constrained Active Learning for Anchor Link Prediction Across Multiple Heterogeneous Social Networks. Sensors. 2017; 17(8):1786. https://doi.org/10.3390/s17081786
Chicago/Turabian StyleZhu, Junxing, Jiawei Zhang, Quanyuan Wu, Yan Jia, Bin Zhou, Xiaokai Wei, and Philip S. Yu. 2017. "Constrained Active Learning for Anchor Link Prediction Across Multiple Heterogeneous Social Networks" Sensors 17, no. 8: 1786. https://doi.org/10.3390/s17081786
APA StyleZhu, J., Zhang, J., Wu, Q., Jia, Y., Zhou, B., Wei, X., & Yu, P. S. (2017). Constrained Active Learning for Anchor Link Prediction Across Multiple Heterogeneous Social Networks. Sensors, 17(8), 1786. https://doi.org/10.3390/s17081786