1. Introduction
Marine oil slicks occur during the extraction and transportation of crude oil. The development of marine transportation and ocean development technologies has increased the possibility of oil accidents. The high frequency of oil slicks at sea has not only caused a serious waste of energy but also seriously damaged the marine ecology and environment. In order to prevent oil slick disasters, it is essential to detect the location of oil slicks. Synthetic Aperture Radar (SAR) sensors can be operated day and night under all weather conditions and produce high-resolution images [
1].
In recent years, the application of SAR in oil slicks monitoring has been improved thanks to the use of launched polarimetric SAR missions, such as Radarsat-2, ALOS-2 and so on [
2]. Damping the Bragg scattering from the ocean surface is the basic underlying principle of SAR oil slick detection, and they produce dark spots on SAR images [
3]. However, several phenomena (e.g., plant oil, oil emulsion, etc.) also produce dark regions in SAR images. These are called lookalikes and appear quite similar to oil slicks. These lookalikes often become false positives in oil slick detection. Many studies into discriminating oil slicks from lookalikes have been conducted with a wide variety of methods. These can be mainly divided into the following two categories. The first is methods that use specific classification features. Zheng Honglei et al. used polarimetric characteristic Single-bounce Eigenvalue Relative Difference (SERD) for oil slick detection and found that SERD can distinguish plant oil from crude oil relatively well [
1,
4,
5,
6,
7,
8]. Bing Duan et al. proposed a method based on cross-polarization ratio of multi-polarimetric SAR images to distinguish mineral oil from plant oil [
9,
10]. Yongsheng Yang et al. have used texture features to detect and classify oil slicks in SAR images [
11,
12,
13,
14]. Reliance on a single feature to distinguish oil slicks from and lookalikes limits the accuracy of conventional oil slick services based on single polarimetric SAR imagery [
15]. The texture features of single polarimetric SAR images cannot fully describe the physical characteristics of the sea surface targets, which may cause misjudgment during the oil slick detection [
1]. In consideration of the complementarity among features to the classification performance, multi-feature fusion would be more suitable for discrimination oil slicks from lookalikes. Multi-feature fusion is known as early fusion, and it captures all the underlying statistical information about the problem [
16]. It may be possible to use multiple features simultaneously to reduce the false positive rate in quad-polarimetric SAR images.
The next goal is to improve the classification algorithm. Suman Singha et al. have presented a new oil slick classification system using Artificial Neural Networks (ANN) in sequence for image segmentation and feature classification [
17,
18,
19]. Kruti Vyas et al. used hysteresis algorithms to segment the dark spots and decision trees to classify oil spills from lookalikes [
19,
20,
21,
22,
23,
24]. ANN has many advantages, such as high accuracy, strong ability of parallel distributed processing and good descriptiveness of nonlinear relationship between input and output [
17]. However, the number of parameters in the input and hidden layers grows with the number of features used for classification (multiple input parameters), hence making the network training a very challenging task [
25]. Sometimes the increase in the number of parameters can draw out the ANN’s learning time, and it may fail to achieve the purpose of learning [
25]. In the decision tree, information gain tends to be biased towards features which have greater values. The decision tree method can lead to the emergence of overfitting problems, and it disregards the correlation between attributes of data sets [
25]. Convolutional Neural Network (CNN) is a deep learning method specially designed for image classification and recognition [
26,
27,
28,
29,
30,
31]. It is designed to resemble multilayer neural networks. CNN is good at recognizing two-dimensional shapes and learning structural features and it provides a way to discern features from pixels automatically [
32]. The short training time makes it easier to use multilayer neural networks and improves the recognition accuracy. Its successful use in image classification and recognition has shown that CNN produces satisfactory results in hand-written recognition [
32]. CNN is also used in image segmentation [
33,
34,
35,
36,
37]. Adhish Prasoon et al. have used CNN to perform the segmentation of knee joint cartilage in Magnetic Resonance Imaging (MRI). Its accuracy is much greater than that of the traditional method, and the training time was shorter [
38].
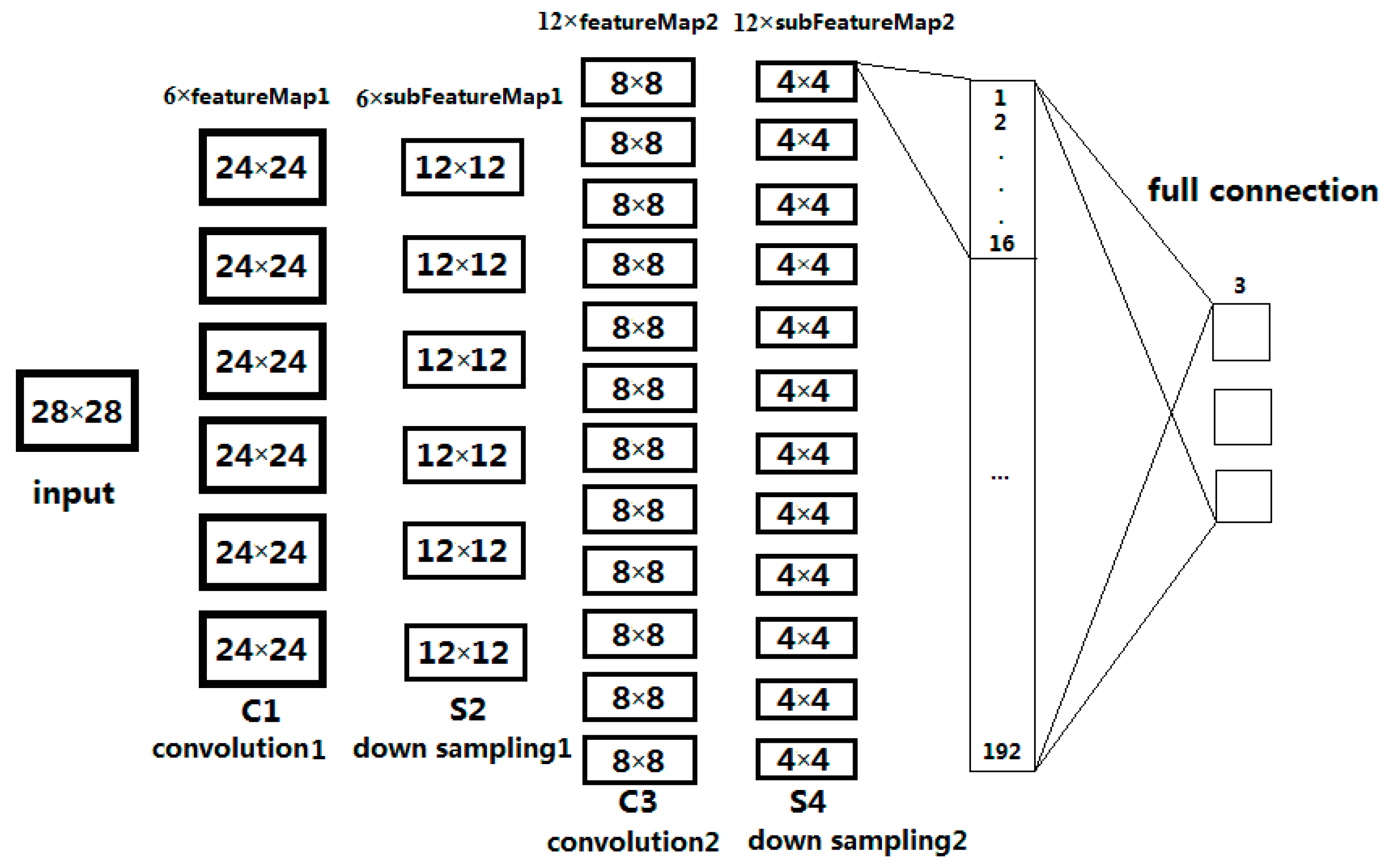
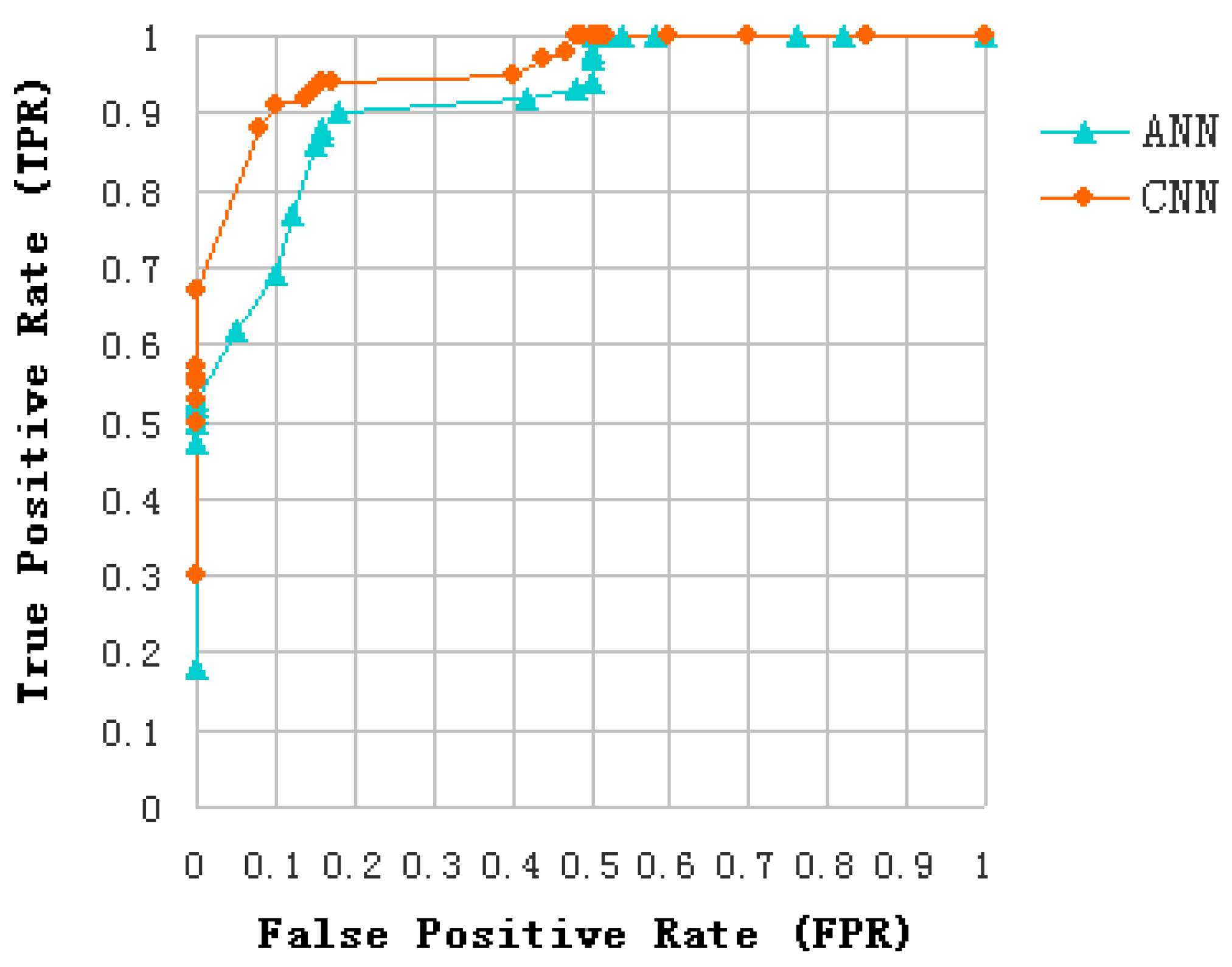
In this paper, an algorithm is presented for discriminating oil slicks from lookalikes in SAR images. This algorithm is based on CNN and multi-feature fusion. The proposed algorithm is run in the following steps: detection of dark spots in SAR images, extraction of features, analysis and selection of features, selection of Regions Of Interest (ROI) in feature images, and classification of dark spots into oil slicks or lookalikes. During feature extraction, 12 different kinds of features consisting of 4 polarimetric features and 8 texture features are extracted. During feature analysis and selection, three features are used to produce the desired feature subset, which has good distinction. In the classification step, CNN model was built and verified through three data. Training data set of 5400 samples serves as the input to train the CNN, and the classification accuracy obtained using 900 samples of test data is 91.33%. The ANN classification accuracy was only 80.33% for the same test data. In addition, dark spots of all five experimental data were predicted by the established model of CNN to confirm our result. The proposed algorithm can effectively apply CNN to the classification of oil slicks and lookalikes in SAR images. The learning sample of CNN is the ROI selected on dark spots of the feature images, which does not have any characteristic shape. The experiment verified that the proposed algorithm is also good at learning non-structural features.
The rest of this paper is organized as follows. In
Section 2, five quad-polarimetric SAR oil slick scenes acquired by C-band Radarsat-2 polarimetric mode are introduced. In the third section, the features of the dark spots are extracted and analyzed, and then an optimal feature subset based on feature fusion is constructed to identify the oil slicks and lookalikes. In the fourth section, we describe the classification based on CNN, in which the learning process is based on the feature values. The effectiveness of the algorithm is demonstrated through the analysis of some experimental results and the results are compared to those produced using ANN. The conclusion and outlook are discussed in the final section.
5. Conclusions and Outlooks
The current study is to discriminate oil slicks from lookalikes in polarimetric SAR images based on the use of multi-feature fusion and a proposed CNN approach. It allows exploiting the information content of polarimetric features obtained from the decomposition of quad-polarimetric SAR images, ensuring a high classification rate to distinguish oil from lookalike slicks. Effectively compared with respect to a classical ANN approach, the proposed method is able to identify accurately the dark spots on SAR images and hence to classify unstructured features related to different oil classes.
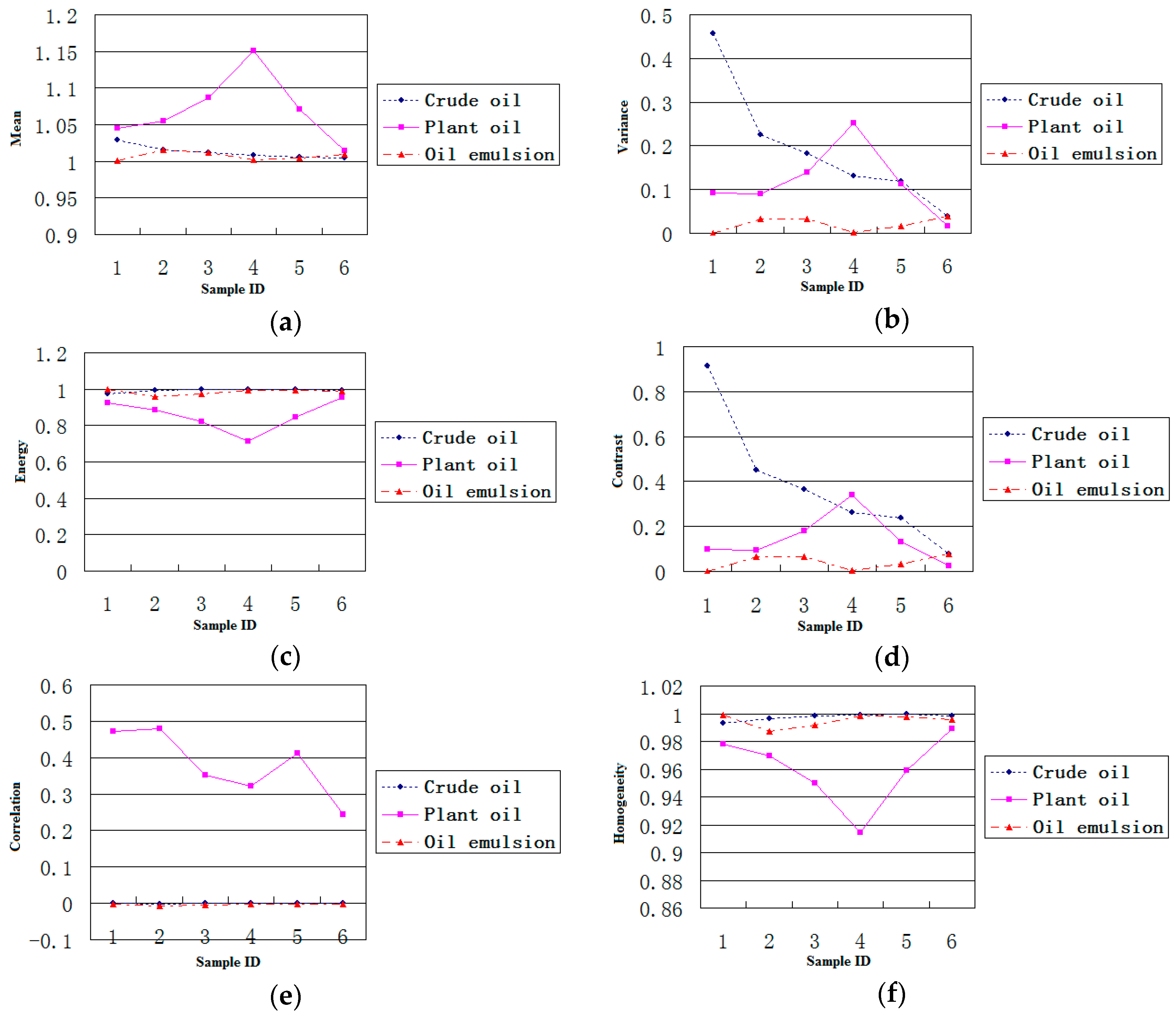
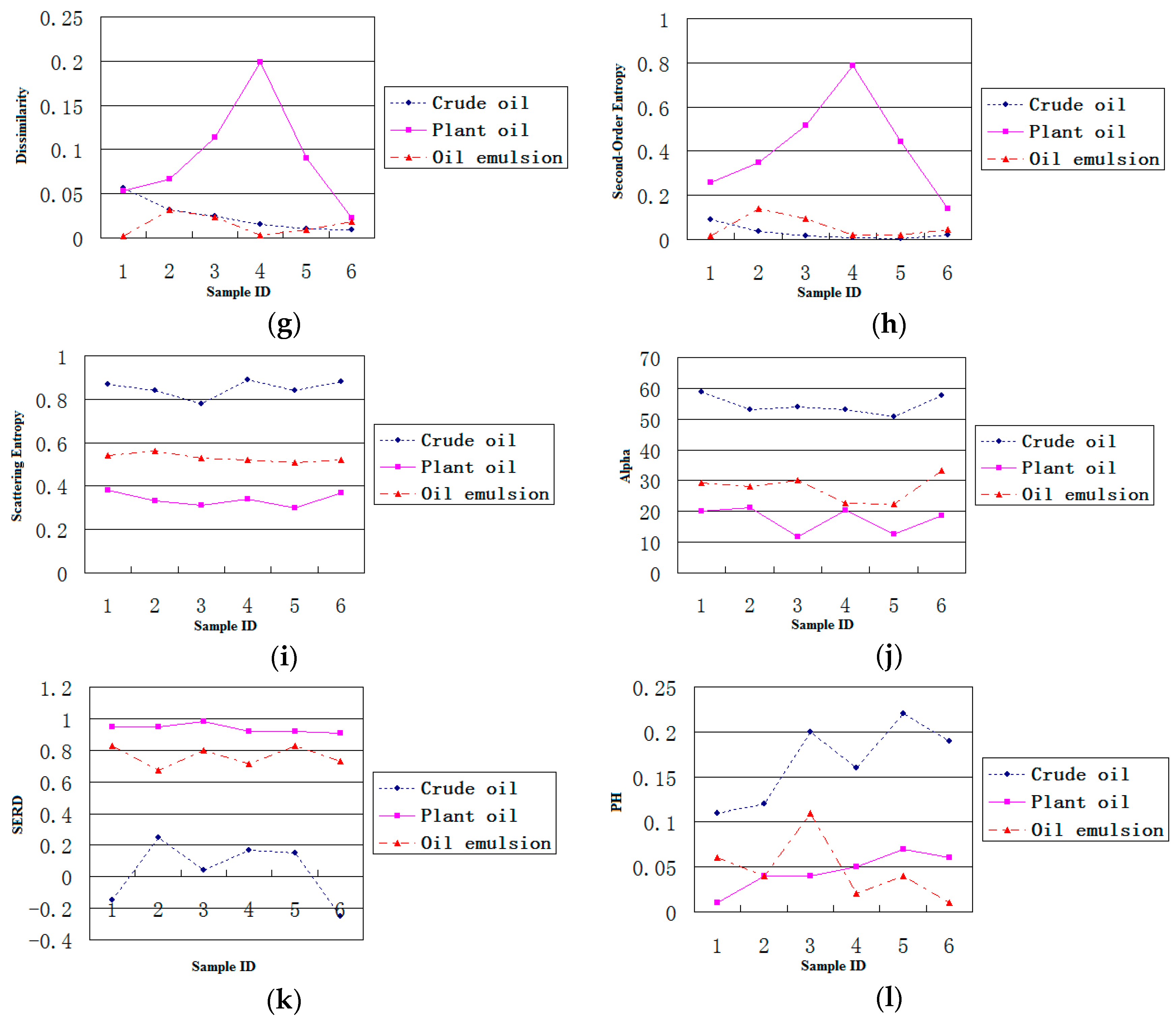
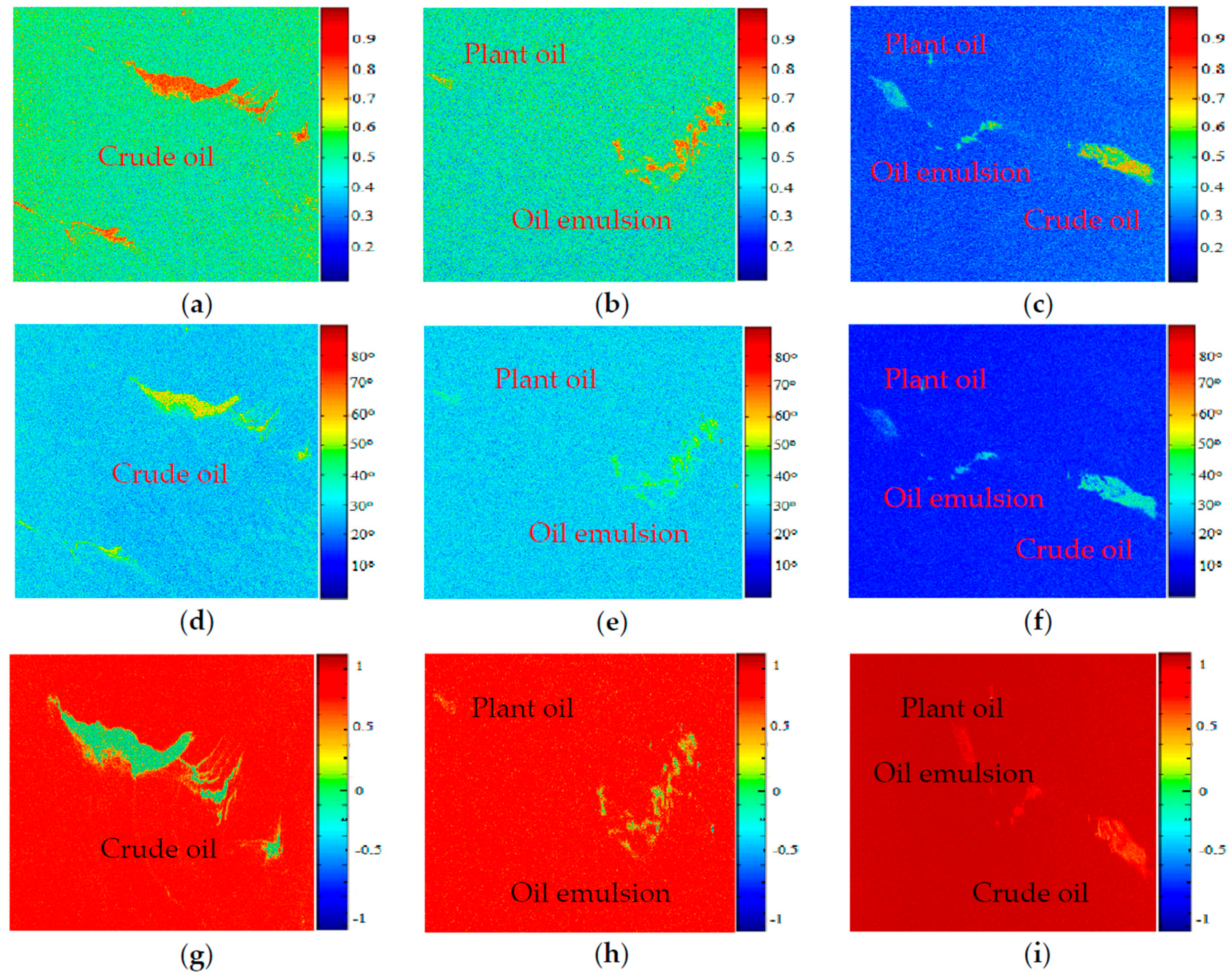
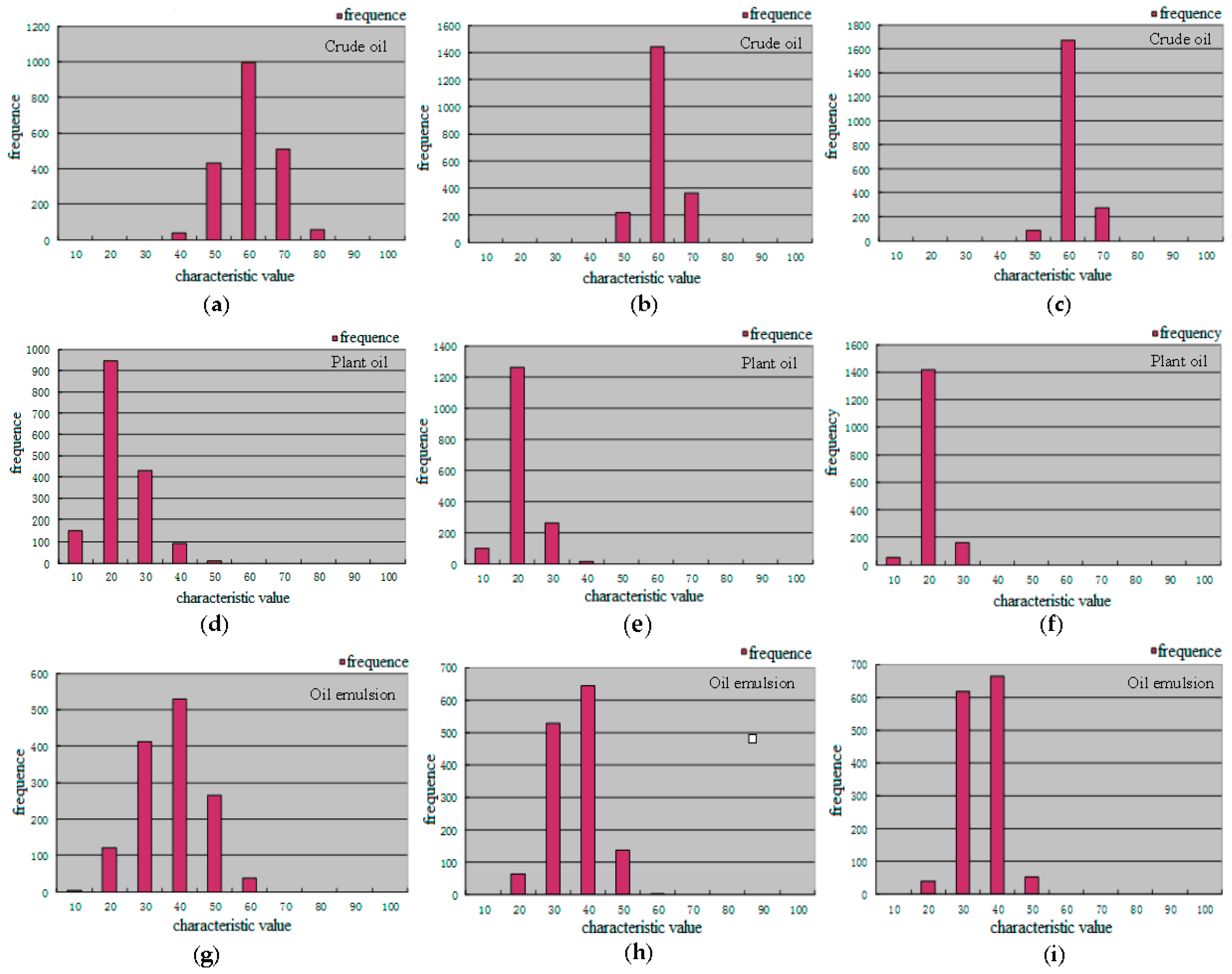
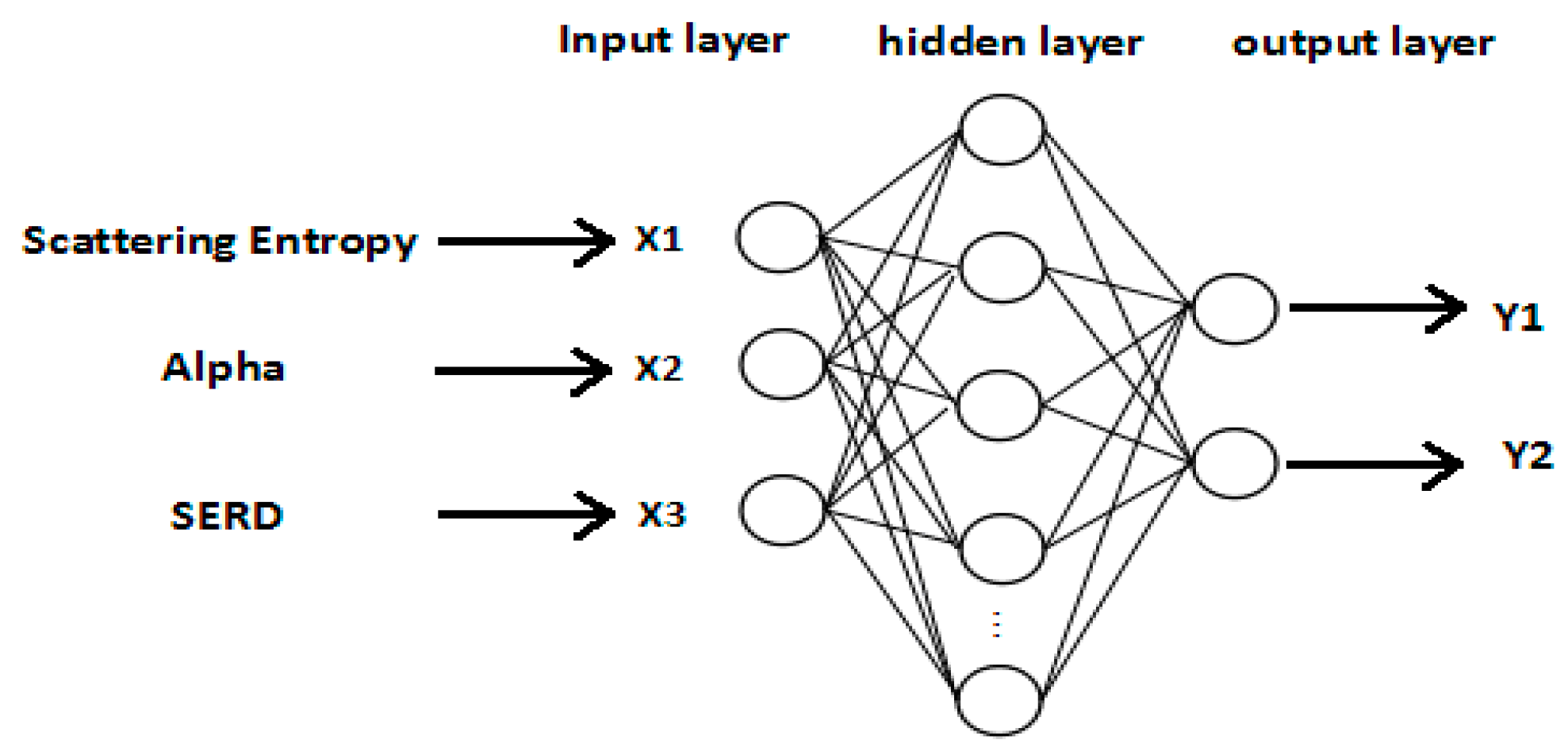
In consideration of the different contributions of each polarimetric feature to the classification performance, a simple discrimination analysis was conducted to assess discrimination ability of each feature. We have explored 12 features of oil slicks and lookalikes for the purpose of oil slick discrimination, and find a preferred features subset includes entropy, alpha, and SERD in the C-band polarimetric mode.
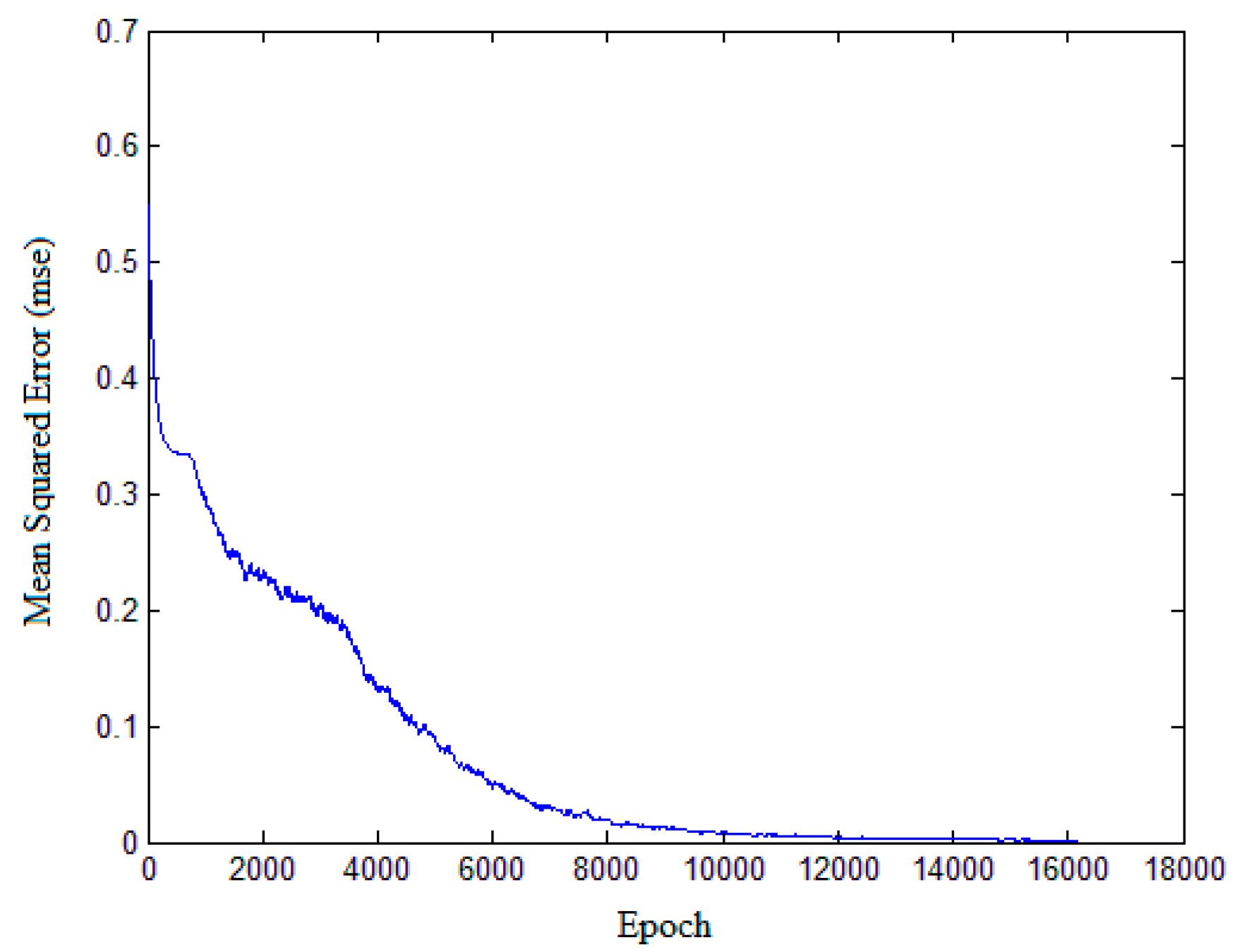
A solution for multi-feature fusion of the three polarimetric features is provided with the proposed CNN model. In order to avoid overfitting and obtain more reliable results statistically, we extend the training data set and a K-CV was be implemented. In the process of CNN model establishment, a training data set consists of 5400 samples, and the classification accuracy was 91.33% with a test data set of 900 samples.
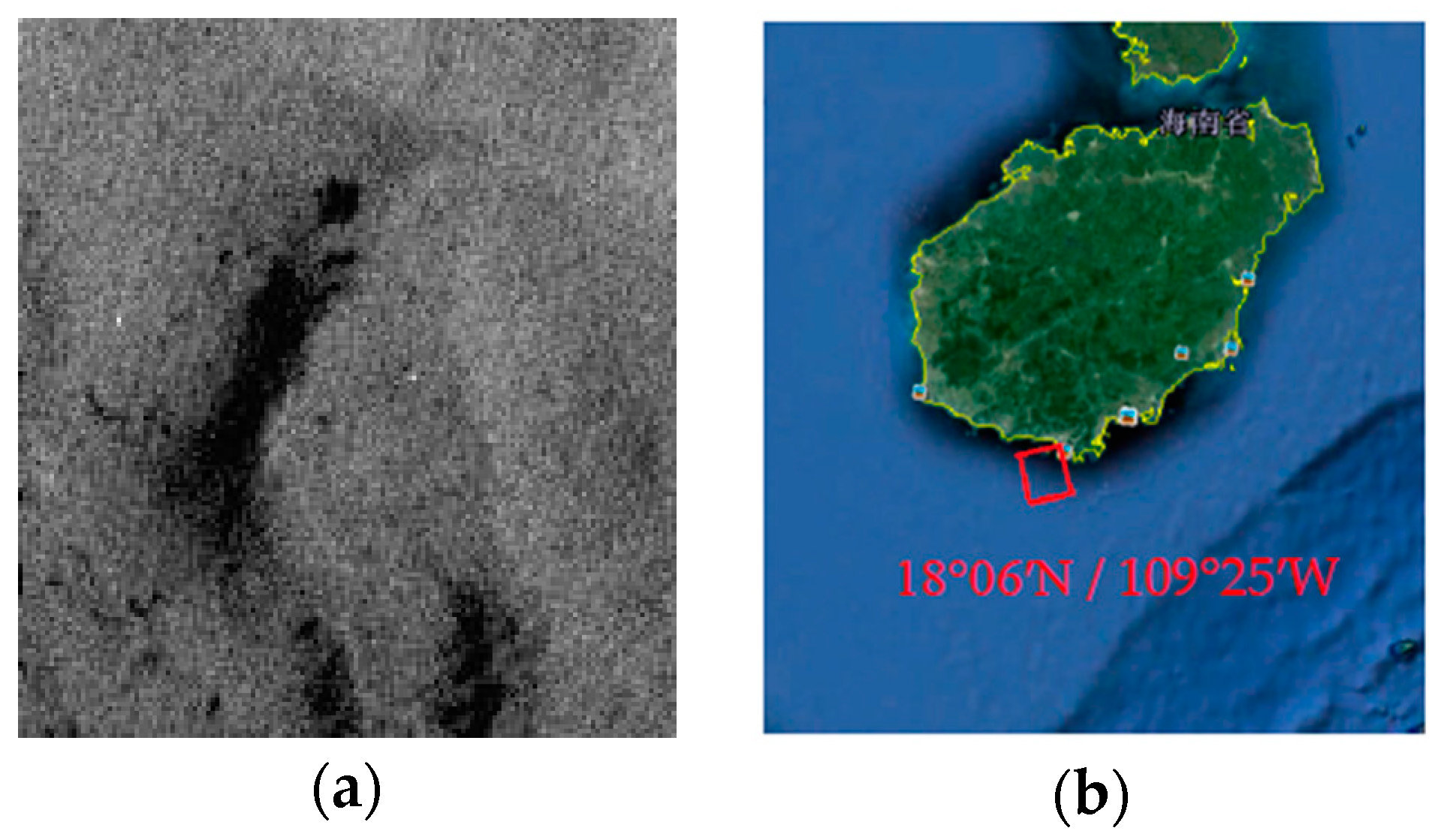
The effectiveness of the algorithm is demonstrated through the analysis of the five experimental data. These data contain multi-temporal quad-polarimetric Radarsat-2 SAR information of oil slicks and lookalikes (oil emulsion and plant oil). The plant oil in data set is used to simulate a natural monomolecular biogenic slick. The results of the discrimination process on real SAR images demonstrated that the proposed method is not only accurately identify dark spots on SAR images but also classify unstructured features.
This study gives an important method to distinguish oil slicks from lookalikes, and it is effective for oil slicks classification task. The result also shows if the difference of sea condition (such as climatic, geographical, sea temperature and environmental conditions) between test and training data is too large, classification accuracy would be a big decline. In order to reduce the effects of these factors on future experiments, we will apply more oil slick data from different sea areas to build the CNN model, and enhance the robustness of training structure of the proposed method. If the prior probabilities of oil slicks and lookalikes are taken into account for classification decision, the classification accuracy would be improved undoubtedly. However, there are many types of lookalikes, and only plant oil and oil emulsion are discussed in this study. The five images used do not contain typical lookalikes caused by low wind or biogenic materials, which are also regarded as major challenges in oil slicks detection. It is very difficult to obtain the priori probabilities of all oil slicks and lookalikes accurately. Therefore, the method of equal probability sampling is adopted in this paper. With the abundance of data sets, prior probability should be used to estimate classification results.
In our study multi-feature fusion, which is also known as early fusion, is implemented and a single complex classifier (CNN) is used. Fusion at different stages of classification procedures is a booming research field that has shown capabilities for improvement of classification results. Late fusion of scores of several classifiers will also be adapted to the proposed problem as a future research work.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}