1. Introduction
One of the most important social phenomena of the last decades has been the endless transference of population from rural areas to urban ones. As a matter of fact, it is foreseen that 9% of the worldwide population will reside in 41 megacities in the short term [
1]. As a result, metropolises are now much more complex and dynamic than ever before. This never-ending growth imposes new challenges on administrators and planners in order to provide city dwellers with an acceptable welfare state, such as air quality control, intelligent public transportation services or efficient allocation of energy resources.
When it comes to tackling all these challenges, a comprehensive understanding of the human dynamics within cities plays a paramount role [
2]. In this frame, several works have already put forward the impact of human mobility on understanding or even predicting the economic development and social conditions of a city [
3,
4]. For that reason, the study of mobility patterns that define such dynamics have been addressed in many different forms. They can be split into three different trends depending on the source of data under consideration, namely, (1) travel survey, (2) wireless sensor mechanisms [
5] and (3) mobile-phone network [
6] methods. Despite the fact that these sources of mobility data have given rise to suitable and useful results, all of them suffer from serious drawbacks in terms of costs associated with their gathering and availability because of privacy, security or proprietary reasons.
Due to these drawbacks, a novel trend in the mobility research domain has started to consider Online Social Networks (OSNs) as a suitable source of data [
7]. OSNs now constitute virtual worlds where users share their activities or interest with their online friendships. These worlds intersect with the real one by means of locations that act as connectors. This is mainly because most mainstream OSN platforms, such as Twitter [
8], Facebook [
9] or Flickr [
10], now include location-based capabilities into their web or smartphone’s applications that have enabled the geo-tagging of most of their documents. Hence, when a user submits, for example, a tweet on Twitter or a post on Facebook, the textual content that he or she personally writes is automatically enriched with the spatial coordinates of his current location.
This way, the combination of the popularity of these platforms (the number of active users of social media reached 2.031 billion in 2015 [
11] along with the widespread existence of personal handheld devices, generates an unprecedented wealth of location data. What is more important, unlike previous sources, is that this data is highly accessible by using the Application Programming Interfaces (APIs) provided by their own OSN platforms. However, it is also true that OSN data tends to be more sparse than traditional mobility feeds due to the slow pace that most users exhibit when it comes to posting geo-tagged documents [
12]. This makes it quite difficult to compose high-resolution mobility logs from such data. In addition to that, only a low percentage of OSN documents is actually geo-tagged. As a matter of fact, only 1.6 percent of Twitter users actually have the automatic geo-tagging functionality turned on [
13]
An important line of work within the OSN-based mobility mining intends to uncover the usage of different social areas of a city by applying several clustering algorithms to geo-tagged OSN data. In these works, each identified cluster is regarded as a different area of interest of the target city [
14,
15,
16]. Nevertheless, we have observed that existing solutions in this domain do not generally take into account all the characteristics that OSNs have in terms of mobility. This is substantiated in the following common limitations which present solutions that usually incur.
First of all, most OSN-based clustering algorithms frequently only use the spatial meta-data of documents to generate the clusters. However, the textual content of the documents, what users have actually created by themselves, is not considered for the clusters’ generation. As a result, current solutions do not actually take full advantage of the underlying knowledge contained in OSN data sources.
Secondly, the user-generated nature of OSN data makes it inherently noisy and imprecise. For example, Flickr photographs are usually geo-tagged with the place where they were taken that might not be exactly the same place where the true landmark is located. Existing solutions generally do not take into account such inner characteristics during the clustering process. It will have an impact on the generation of mobility patterns though.
Finally, current mechanisms focus on extracting general mobility information related to a particular urban area without distinguishing the time of the day in which the information was generated. Hence, they do not study the relationship between the moment of the day at which social-media documents are posted and its associated spatial place. This missing information could provide a global vision of the movement of a population along a day. Therefore, these works are not taking full advance of social-media datasets.
In this context, the present work introduces a novel mechanism for human mobility characterization that exploits all the benefits that OSN data can bring in terms of its spatial, temporal and textual aspects. In order to enable this full characterization, the proposal follows a fuzzy-modelling approach that considers the inherent uncertainty associated with OSN data in a formal manner. This is instantiated in an OSN-based mobility framework that provides a complete solution to the limitations listed before. In that sense, the usage of the spatial and textual content of OSN data makes the resulting model provide not only the location of the social areas of the city but also a set of labels associated with each cluster describing its predominant activity or landmark giving rise to the most valuable information.
Finally, in order to study the feasibility of the proposal, a lightweight location predictor has been developed on top of the proposed framework. This service profits from people displacement between clusters in different time slots so as to forecast the location where an OSN user is going to submit his next document. These types of location predictors are instrumental for many mobility operators [
17]. In order to be consistent with the mobility framework, this predictor also follows a fuzzy-rule approach in order to infer the predicted outcome. Furthermore, it has been designed by considering the widespread nature of OSN data mentioned before, as it does not rely on long mobility records to make a prediction. Both the framework and the predictor have been evaluated with a large dataset containing documents from Twitter and Flickr platforms.
The paper is structured as follows:
Section 2 provides a brief overview of the proposal. Then,
Section 3 looks into the framework, including its architecture and functional modules.
Section 4 describes the predictor service built on top of the framework.
Section 5 provides an evaluation of some of the features of the platform.
Section 6 provides a comparative of our work with the existing state of the art; and
Section 7 concludes the paper with some final remarks and conclusions.
2. System Overview
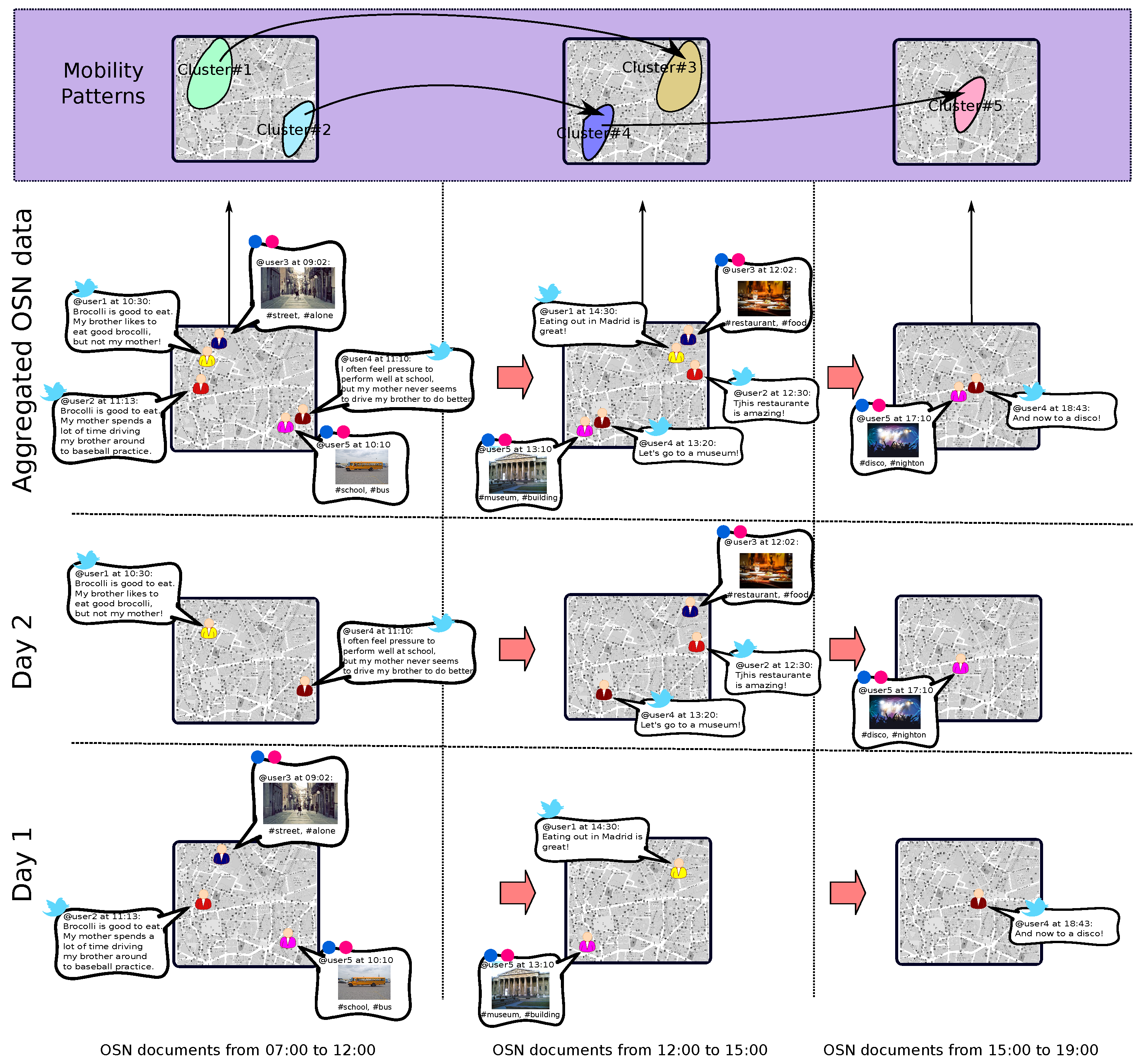
Figure 1 depicts a general overview of the proposal. From the raw OSN documents published at different time periods and days depicted at the bottom of the figure, the present solution’s outcome is shown on top of it. As we can see, the proposal is able to identify the spatial areas of a city with a high level of OSN activity at different time periods (e.g., clusters 1 and 2 during the morning or cluster 5 during the afternoon). For this task, we have integrated the Gustafson–Kessel (GK) clustering algorithm [
18] and the Hierarchical Dirichlet Process (HDP) [
19].
Furthermore, this fuzzy-clustering process is not monolithic, but it is launched for different time slots. In order to keep on with the fuzzy approach, these slots are defined by fuzzy sets. This temporal aspect of the solution makes it possible to detect how the active social areas move across the city’s throughout time.
On the basis of these clusters, the human movement between time periods can be established. For instance, according to the figure, most of the people at cluster 1 in the morning moves to cluster 3 in the afternoon.
3. The Fuzzy Modelling Process
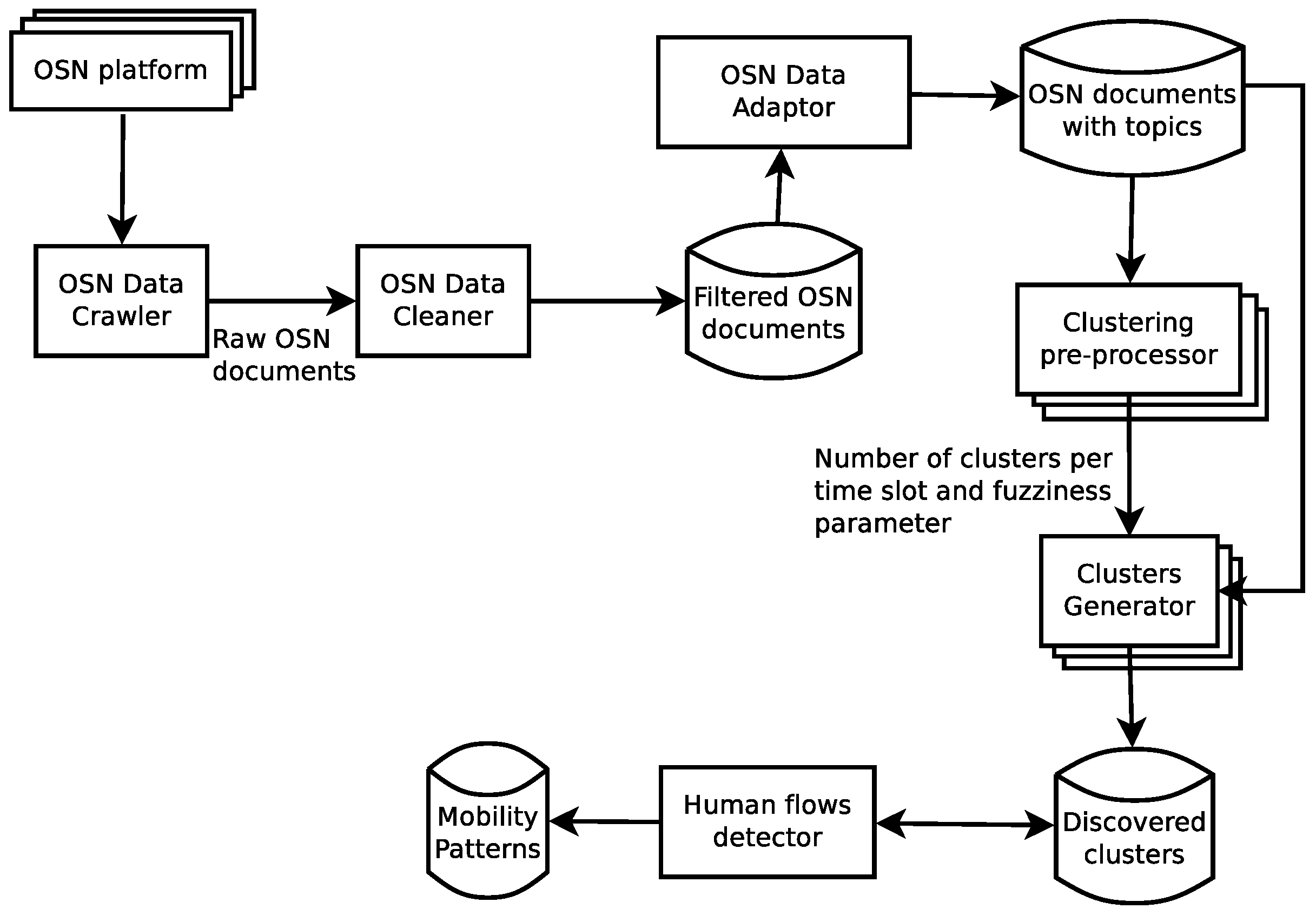
In this section, the fuzzy modelling solution to extract the mobility patterns of a city is put forward. In brief, the proposed solution follows a four-step processing pipeline:
Firstly, collect and filter the OSN documents from the target OSN platforms.
Secondly, transform the clean documents into a format able to define a similarity distance between OSN documents integrating both their spatio-temporal and their textual features.
Next, perform the fuzzy clustering over the product space of input features generated on the basis of the transformed documents to discover regions with high human activity.
Finally, compute the movement of people between the discovered clusters defining the mobility patterns of the area under study.
Figure 2 shows different modules that realize the aforementioned process, each one representing a different step in the analysis of OSN documents. The following sections state each of these steps in detail.
For the sake of clarity,
Table 1 summarizes the key acronyms used in the following sections.
3.1. OSN Data Collection and Cleaning
The first step in the processing loop is to gather the needed documents from the target OSN platforms for their further analysis related to the urban area under study . Many of these platforms already provide open Application Programming Interfaces (APIs) that can be used in order to gather their publicly visible documents. Depending on the platform under consideration, these documents will take the form of tweets in the case of Twitter, posts on Facebook or labelled photographs on Flickr.
Despite this variety, the present work relies on a uniform view of the gathered documents. Hence, a raw OSN document is a tuple where u is the OSN user who actually posted the document, p the host OSN platform, l the spatial spatial coordinates at which d was posted, t the timestamp of the submission and c the textual content of the document directly written by u.
This way, the OSN data crawler (see
Figure 2)) focuses on keeping only geo-tagged OSN documents, discarding the ones that do not include a location
l among their meta-data. Moreover, the current work only considers the textual content of a document discarding other types like images, sounds or videos.
Once the extraction of the OSN documents has been completed, it is necessary to clean the collected dataset so that it eventually contains accurate human mobility information. In that sense, OSNs usually comprise a significant proportion of redundant and useless (spam) content that might disturb the obtained results. For example, it is reported that about 10% of Twitter content is spam [
20].
For this reason, documents from OSN accounts representing companies, institutions and so forth or having an unusually high posting frequency are removed from the collected dataset. In addition to that, consecutive documents posted by the same user u close in time and space are merged into a single document. Next, the textual content c of each document d is cleaned by removing its stop words and performing word stemming.
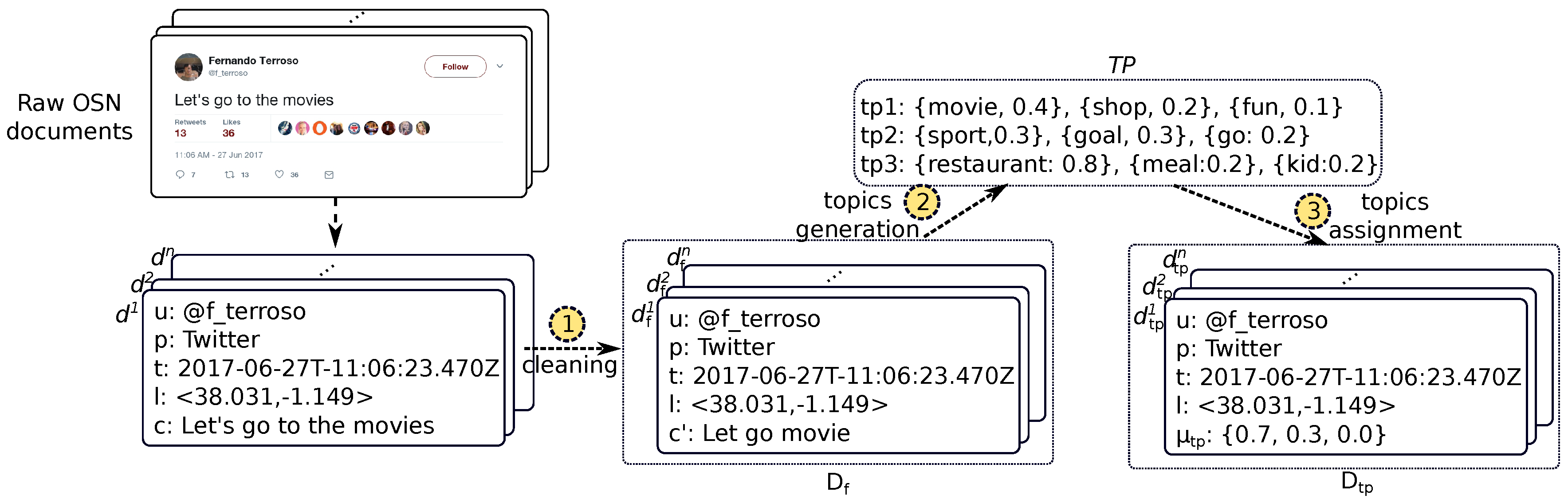
As
Figure 3 depicts, this initial stage results in a database
of filtered OSN documents
where
means the textual content of the document without stop words and the rest of words in their root form. This repository solely contains documents from actual citizens, and each document represents a meaningful displacement of such citizens either in the space or the time dimension.
3.2. OSN Data Transformation
Once the OSN documents have been collected and cleaned, the next step is to transform such documents to make them compatible with a distance metric that allows for measuring the similarity between documents. The definition of this measurement is paramount for our approach to properly process OSN data by means of a clustering algorithm. In that sense, the OSN Data Adaptor module (see
Figure 2) transforms the textual content
from the filtered documents in
into a vector-based format.
For this goal, we have made use of the Hierarchical Dirichlet Process (HDP) [
19]. HDP is a non-parametric Bayesian mechanism that has been widely used in the information retrieval field in order to uncover the latent topics of sets of documents. Unlike the well-known Latent Dirichlet Allocation (LDA) model [
21], HDP does not need to know in advance the number of topics to be generated. On that contrary, it is able to automatically learn the number of topics to be detected over the document corpus.
This way, a HDP instance is fed with a corpus
comprising the textual content
of all the documents in
. This instance returns a distribution of
m topics
of such a corpus defined as follows (see arrow 2 in
Figure 3),
As we can see, each generated topic is represented as a probability distribution over a word subset in .
Once the topics have been uncovered, the HDP model also allows to know the membership of a particular document to each of these topics. We leverage this feature so as to re-format the textual content of the documents in
. This way, each document
is replaced with a new document with topics
where
and where
represents the membership of the document to the i-th topic and
(see arrow 3 in
Figure 3).
At this point, the original textual content of an OSN document
c has been transformed to a numeric vector
over which we can easily define a distance metric. Finally, the resulting dataset
is stored in a repository as
Figure 2 depicts.
3.3. Fuzzy Cluster Generation
The next step in the mobility patterns discovery focuses on executing the fuzzy clustering algorithm to detect the areas of social activity of a city. In more detail, we have applied the Gustafson–Kessel (GK) clustering algorithm [
18]. GK is one of the most commonly used solutions to extract fuzzy clusters from a set of data. Unlike other well-known algorithms like Fuzzy C-Means [
22], GK is able to detect elliptical clusters instead of spherical ones. Therefore, if the data is distributed in different clusters, and they are of different shapes and orientations, the GK is more likely to discover the real underlying structure of data than using an algorithm that imposes, for example, spherical shapes that could not be present in the data. This is quite convenient in the present domain due to the fact that OSN documents do not usually follow a homogeneous distribution in urban environments [
23]. How this algorithm has been adopted in this work is stated in the following sub-sections.
3.3.1. Input Selection
This work relies on the assumption that active areas of a city are not the same during the whole day, but they change through time. This has been already pointed out by existing literature in human pattern mining [
24,
25]. For example, business parks or university campus attract a lot of activity during the morning and afternoon, whereas residential areas or shopping malls have a high level of human activity at later hours.
For that reason, we manually split the 24-hour period of a day into five different time slots. Such a time division is consistent with previous ones proposed in the mobility mining field [
26,
27,
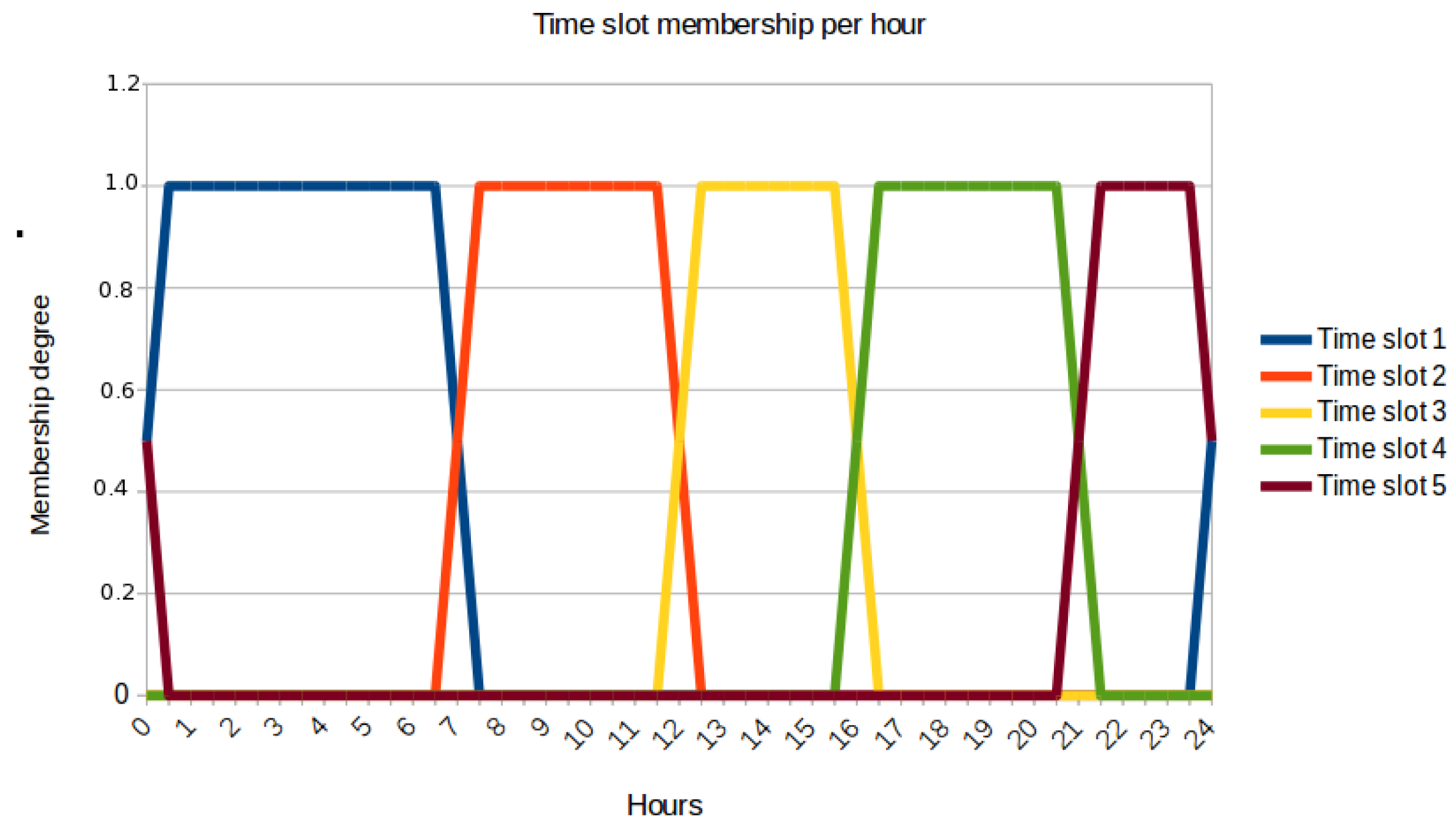
28]. In order to be compliant with the fuzzy modelling approach of the solution, these time slots were defined as trapezoidal fuzzy sets as
Figure 4 depicts. As a result, each document
will have a particular membership degree to each of these slots depending on its timestamp field
t.
Then, we launch a different GK instance for each slot. Hence, the generated clusters in each of these individual processes will uncover the social areas related to its target time period. For example, the GK instance for time slot 2 will detect the active social areas for the time period between 6:00 a.m. and 1:00 p.m. approximately according to
Figure 4, whereas the GK instance for time slot 3 will cover from 11:00 a.m. to 5:00 p.m. This composes a fuzzy time period between 11:00 a.m. and 1:00 p.m. that is properly handled by the current approach.
Concerning the product space of input features of each GK instance, in our case, this will be where is the space comprising the location coordinates of OSN documents and the membership degree of OSN documents to the uncovered topics. Other fields of an OSN document like the user u or the host OSN platform p are not considered by the clustering algorithm.
3.3.2. Algorithm Adaptation
Given the dataset , the pseudo-code of the GK algorithm to generate the clusters for a time slot s is described in Algorithm 1.
From such a code snippet, we can see that the general structure of the algorithm is very similar to its standard version. However, we have incorporated a few but meaningful modifications to adapt the algorithm to the particularities of our work.
Firstly, the computation of the clusters’ prototypes and covariance matrices (Equations (2) and (3)) considers not only the membership of the k-th document to the i-th cluster, but also the membership degree of such a document to the target time slot s, . This way, the contribution of each OSN document to the clusters generated for a time slot is proportional to its closeness in time.
Secondly, the computation of the distance between a document
and a cluster prototype
(
) (Equations (3) and (4)) needs to consider both the spatial and textual aspects of the documents. For this reason, such distance is calculated as a combination of two different metrics:
| Algorithm 1: Gustafson–Kessel Algorithm |
![Sensors 17 01949 i001]() |
As we can see, the distance between a document and a centroid is composed of two aspects. For the location feature, we use the haversine formula [
29] that determines the spherical distance between the coordinates in
l. As for the textual features, we compute the coisine similarity [
30] between the vectors comprising the membership of each element to the topics previously generated by the HDP model (see
Section 3.2).
Moreover, the weighting parameter () allows for controlling the actual contribution of both features to the similarity computation. This way, we are able to generate just spatio-temporal patterns () or just patterns reporting semantic features (). In that sense, the haversine distance is normalized with respect to a maximum distance between two locations in so that both the spatial and textual features can contribute equally to the similarity computation.
All in all, by means of the membership degrees for the time slots and the multi-variate distance formula of Equation (1), we are able to smoothly integrate the temporal, spatial and textual features of the OSN documents in the clustering process.
Finally, since the cluster prototypes from the aforementioned process are generated on the basis of the l and fields, they represent the location center of areas with a high level of human activity and the relevant topics from associated with such areas. In that sense, five sets of these clusters are composed , one for each time slot.
3.3.3. Initial Number of Centroids and Weighting Exponent Specification
One of the most important limitations of most clustering algorithms is that is not easy to determine its parameters, the number of clusters to be generated (
c) and the weighting exponent (
m). This last parameter determines the fuzziness of the clusters. The larger the value of
m is, the more overlapped the clusters are. In the current work, instead of establishing both parameters a priori, a suitable value of
m and
c is automatically obtained from the data as it is done in [
31].
The mechanism is based on a cluster validity measure that takes into account the compactness of and the separation between clusters (see
Appendix A). Basically, for every number of clusters
c,
m is incremented in
until the cluster validity criterion is fulfilled (see
Appendix B).
3.4. Human Mobility Detection
The clusters generated in the previous step are the basis to finally compose the flows that define the human movement of the area of interest. Basically, this composition is done by following a bottom-up approach, we firstly categorize the mobility of each unique user u and then aggregate such individual data to compose a crowd-based information representing the whole mobility of the target area. This process is summed up in Algorithm 2.
To start with, the algorithm detects the most representative cluster for each in each of the five pre-defined timeslots (lines 2–10). This is done by obtaining the cluster in each set where the ’s documents have the highest membership degree on average. For this computation, we need the set of partition matrices per time slot generated by the GK instances comprising the membership of the documents in to each of the clusters.
At the end of this process,
contains the mobility pattern of the target user in terms of his movement in between time slots. It should be noted that this approach aggregates the different documents published by the user during the entire period under study (see
Figure 1). This is particularly useful in the OSN domain where data scarcity makes it rather challenging to compose users’ paths covering different time slots in a single day.
Table 2 shows some examples of this variable. This way, we can see that
usually stays close to cluster
during time slot 1 and moves to cluster
at time slot 2. Similarly,
moves from cluster
to
at time slot 3. It might happen that there is no information for a user given a particular time slot (like
for time slot 1). This is because a user does not publish documents during that time slot and, thus, the algorithm is not able to extract any representative cluster.
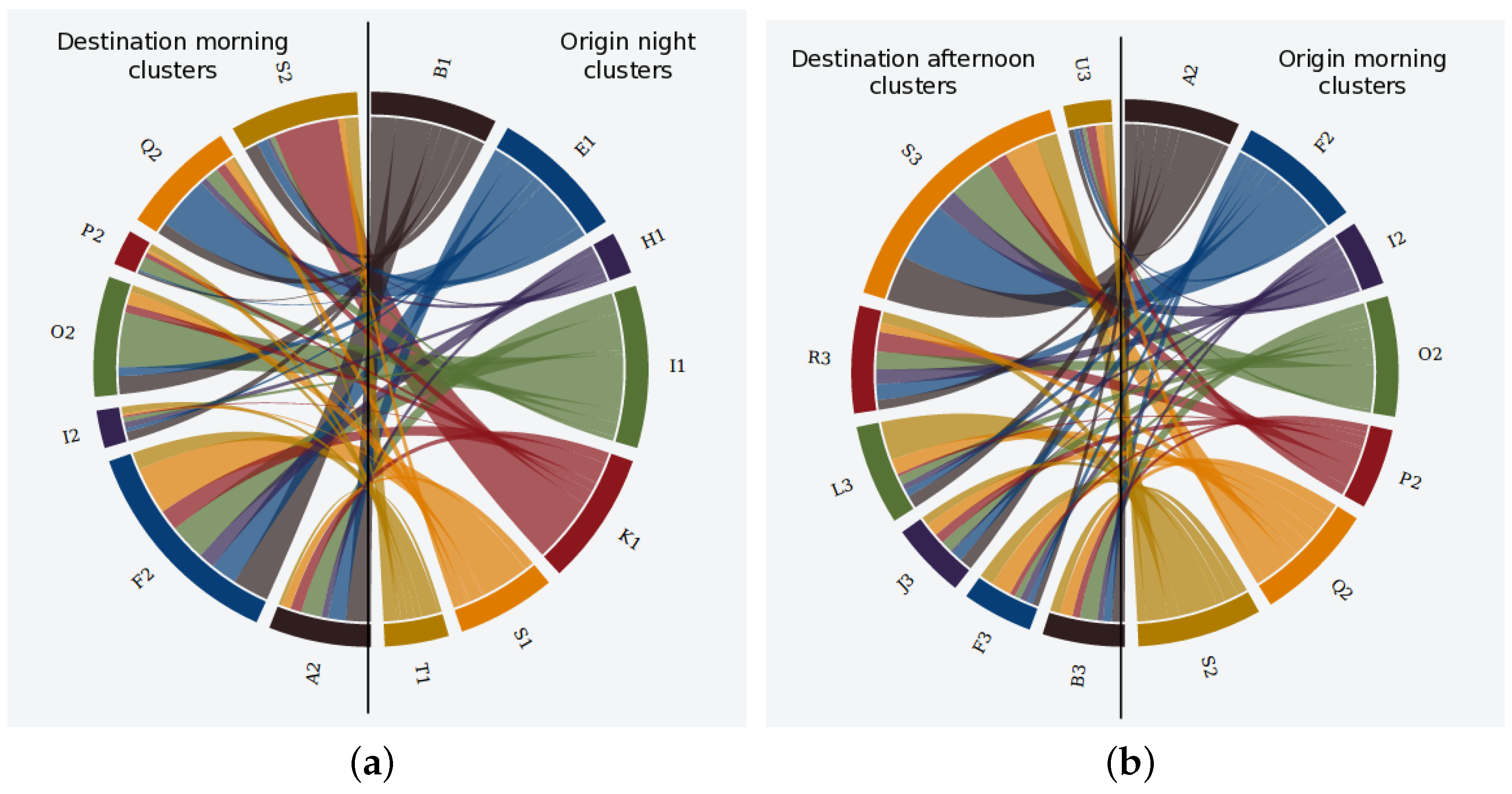
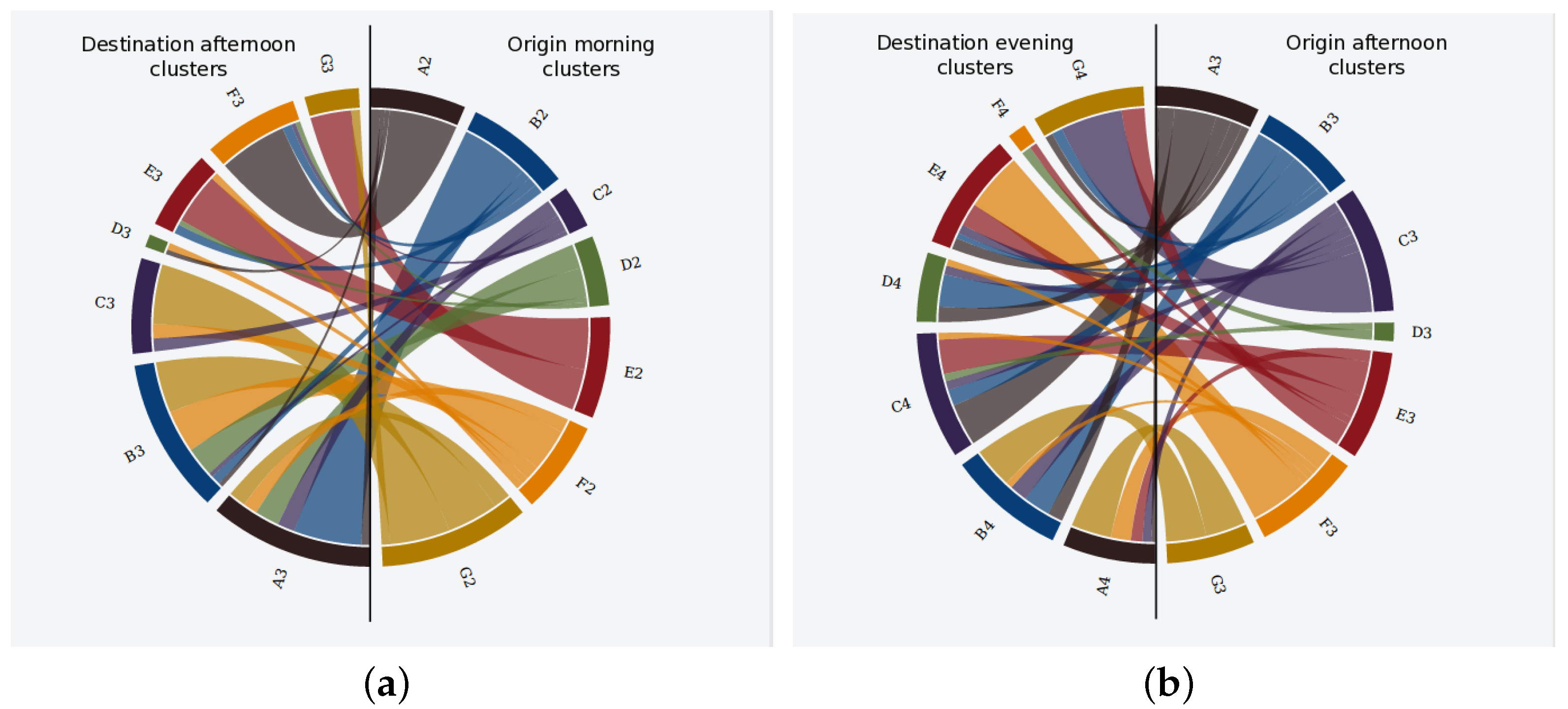
Given such individual patterns, the second part of the algorithm focuses on composing the aggregated patterns describing the movement of the whole urban area under study (lines 11–63). To do so, we firstly compute the number of occurrences of each cluster and the number of transitions between clusters at different time slots (not necessarily consecutive) in the individual patterns (lines 11–20). Then, we normalize transitions’ counting with the number of occurrences of the origin cluster (lines 21–26). As a result, we obtain the rates of users that move from one cluster to another at a different time slot. Such rates are represented as a multi-dimensional table in Algorithm 2. This way, comprises the transition rates from clusters in time slot 2 to clusters in time slot 3.
| Algorithm 2: Pattern discovery algorithm |
![Sensors 17 01949 i002]() |
Going back to our illustrative example of
Table 2, if we stick to time slots 1 and 2 (night and morning periods according to
Figure 4), the aforementioned process will detect that 66% of users who spend the night near cluster
then move to
during the morning (
).
Although this approach focuses on extracting patterns between consecutive time slots, we can easily use them to compose longer patterns by just linking the rows and columns of table
. Such multi-timeslot patterns take the form of a sequence
where
are clusters in consecutive timeslots with a certain percentage of movement. This approach is different than well-known solutions for trajectory pattern extraction [
32] based on the Frequent Sequential Pattern (FSP) problem [
33]. This type of algorithm is designed to operate with high-resolution spatio-temporal trajectories, where the target moving object frequently reports their current location. As a result, each individual trajectory may comprise hundreds or thousands of different locations. On the contrary, OSN data tends to provide more spread and coarse-grained routes that might not be dense enough to extract accurate patterns. Furthermore, FSP-based solutions provide information about the overall frequency (support) of the extracted pattern. However, our solution allows for knowing the particular percentage of users moving between each pair of clusters providing more detailed mobility information.
All in all, we follow a memory-based approach to represent the mobility patterns by table
. In that sense, the dimensions of such a table corresponds to the total number of clusters generated by the clustering process. Such a number is calculated by the data-driven approach described in
Section 3.3.3. As a side effect of this process, we optimize
dimensions avoiding their underestimation or overestimation, which will, in turn, affect the optimal representation of the global patterns due to data-scarcity issues and the cost-effective allocation of resources for its storage.
Finally, bearing in mind the known limitations of existing OSN-based mobility mining solutions pointed out in
Section 1, our approach proposes several mechanisms to deal with them:
Firstly, regarding the underestimation of the textual content of OSN data, such a content is smoothly fused in the clustering process as topic-based features of the OSN documents as described in
Section 3.2.
Secondly, as far as the noisy nature of human-generated data is concerned, the combination of fuzzy clustering and HDP avoids defining hard boundaries indicating whether a document belongs or not to a certain cluster (see
Section 3.3.2). On the contrary, the adopted approach defines fuzzy boundaries that makes it suitable for OSN documents where either its textual or location content is noisy or imprecise, which makes it difficult to assign it to only one cluster.
Lastly, as for the monolithic mobility patterns in terms of time evolution, the split of the mobility mining in different time slots within a day allows for extracting more time-aware, and thus more dynamic, mobility patterns.
4. Location-Based Predictor Service
In order to test the feasibility of our approach, we have developed a prediction service able to estimate where an OSN user is going to post his or her next document making use of the learned mobility patterns.
Since these patterns have been defined on the basis of a palette of fuzzy clusters, the present prediction service leverages such fuzzy approach and its design takes the form of a fuzzy IF-THEN classifier. Fuzzy classifiers have been successfully applied to pattern classification tasks [
34,
35]. Concretely, the model for the current problem has the form:
where
is the fuzzy set for the
i-th rule,
is the partial output of the
i-th rule, and being
,
r being the number of rules.
As regards the fuzzy reasoning mechanism, it is such that the firing strength
for the
i-th rule given an input OSN document
is obtained by the expression:
where
denotes the membership degree to the associated fuzzy cluster. Then, the partial output
is given by:
and the partial outputs are combined to generate the final prediction
of the system according to:
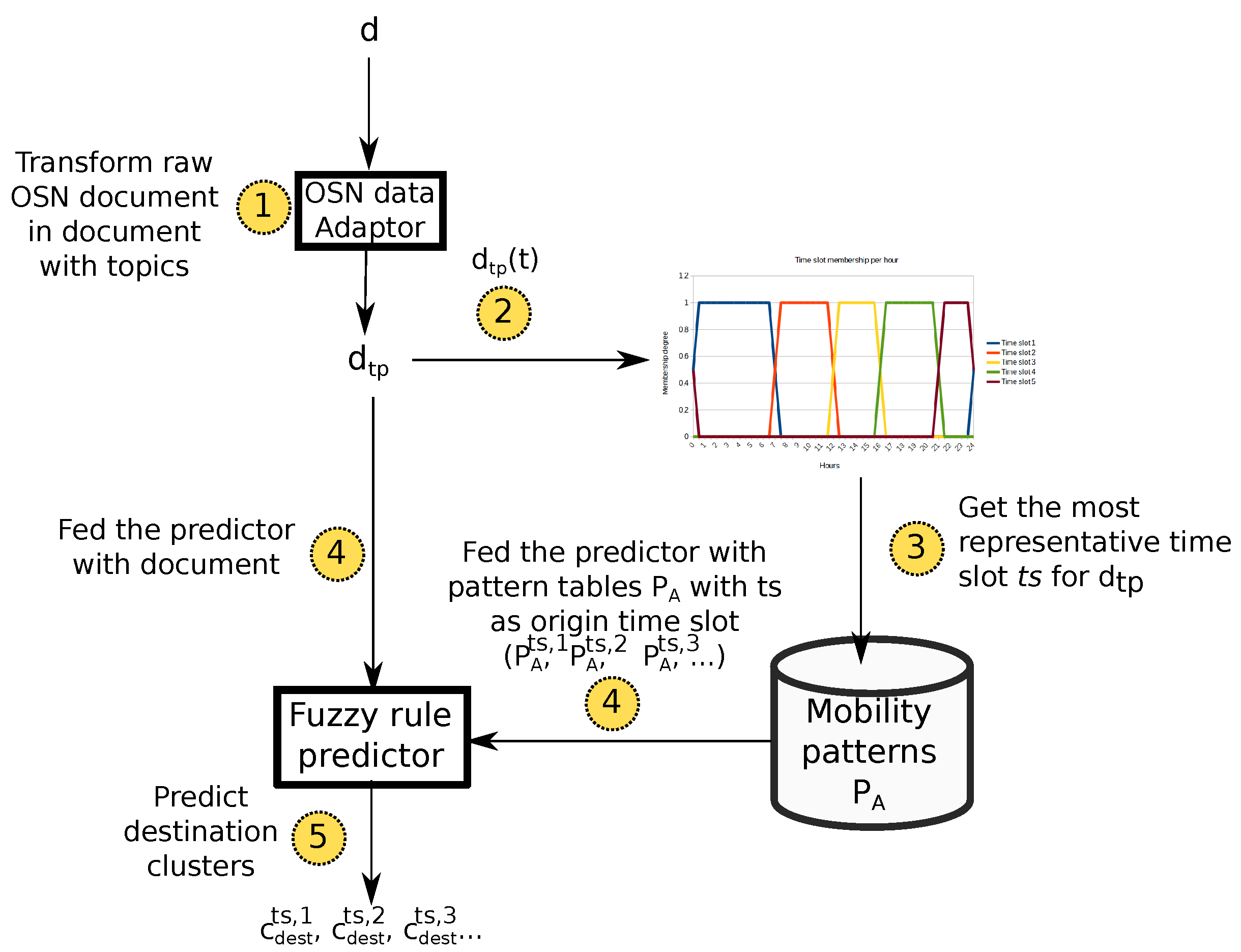
For the sake of clarity,
Figure 5 summarizes the whole prediction loop. This way, this system takes the last raw OSN document
d published by a user and transforms it to a document with topic
(see
Figure 3) (arrow 1 in
Figure 5). Next, the mechanism infers the most representative time slot
that such a document belongs to (arrows 2 and 3). This allows for selecting the sub-tables of
with such a time slot as origin (
).
The fuzzy classifier is fed at different times with the selected sub-tables in order to generate predictions for different time slots (arrows 4). This way, the system is able to provide the potential destination of the target user for several time horizons. Due to the spatial and topic-related information contained in each cluster, predicted clusters will not only indicate the potential future location of the user but also semantic information about such a location.
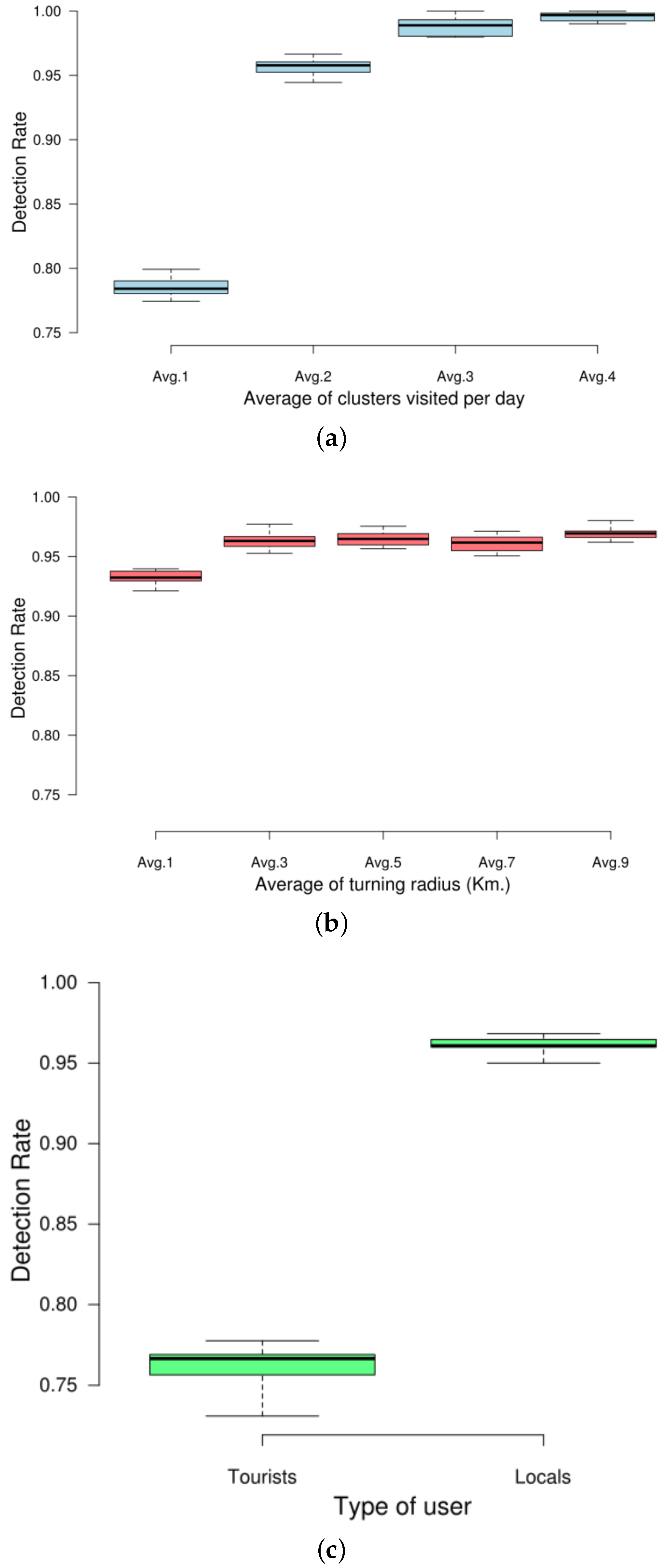
Finally, as we can see, the predictor takes under consideration the data-sparsity problem of OSN platforms. In that sense, several works already state that most users tend to post roughly one or two OSN documents per day [
12]. As we have seen, the present solution does not rely on a long sequence of previously-visited clusters by a user in order to infer a potential destination. On the contrary, it only makes use of the most recently-visited cluster. Hence, the rationale of this approach is to provide a solution suitable for a wide range of users.
6. Related Work
The study of human mobility on a large scale started in the 1950s with the creation of household travel surveys based on face-to-face, telephone or mail interaction. The limitations in terms of coverage of these surveys were overcome with the emergence of the Information and Communication Technologies (ICTs) [
2]. This way, the usage of wireless sensors or traffic cameras giving insight into urban user dynamics defined a second era of large-scale mobility studies [
44]. More recently, mobile phone networks have been adopted as another meaningful data source to come up with human mobility modelling [
45]. In this context, OSNs have been studied for the last few years as a suitable source to extract mobility-related knowledge. From a utility perspective, the core of OSN-based works in the mobility mining discipline can be divided into three different lines of work (see
Table 11).
Firstly, several works use OSNs as real-time data streams to detect certain events or incidents with respect the traffic of a city [
46,
60,
61,
62]. For this task, different classification algorithms, like Support Vector Machines or Random Forest, along with Natural Language Processing (NLP) techniques are combined. In brief, these works focus on detecting meaningful changes in the frequency and content of OSN documents submitted within a geographic area that might report a serious traffic situation.
A second line of work investigates the usage of heterogeneous OSN data to automatically detect regions within a city [
47,
48,
49,
63,
64]. In this case, works explore OSN data as an enabler to discover how humans name places in order to assist attempts aimed at imitating this behaviour by computer systems. From the point of view of the applied data-mining techniques, these works can be generalized into two types: spatial clustering approaches that determines regions based on the intensity of human activity [
14,
47,
48,
49] and network-based approaches [
64], where areas are determined with the intensity of human relations between regions.
Finally, a third line of work makes use of OSN data to compose mobility patterns that define the human movement in a geographic area. In this scope, several works follow a model-based approach able to classify or assign geo-tagged OSN documents to a particular mobility category or pattern [
24,
52,
54]. In that sense, Latent Dirichlet Allocation (LDA) [
24], Bayesian networks [
52] or Origin–Destination (OD) matrices [
54] are some examples of adopted models.
Our work can be enclosed in an alternative course of action for OSN-based mobility pattern discovery following a clustering-based approach. Basically, these works cluster the locations or paths followed by OSN users and then, on top of these clusters, make up the eventual mobility patterns [
48,
50,
51,
55]. In that sense, several clustering solutions have been proposed. In more detail, Ref. [
48] makes use of the density-based clustering algorithm DBSCAN to firstly detect areas with high OSN activity using the spatial features of photos shared in Flickr. Then, a temporal clustering allows for uncovering the movement across these areas. Finally, the textual labels tagging the photos feed a semantic layer to make up a clouds of tags labelling each cluster. Similarly, Ref. [
51] adapts the OPTICS algorithm, a density-based clustering for trajectories, to detect mobility patterns using the spatio-temporal features of documents from two different OSN platforms, Gowalla and Brightkite. Next, the Kullback–Leibler (KL) divergence is used as the similarity measurement to mine the evolution of these patterns through time. Ref. [
50] envisions a non-negative matrix factorization to cluster profiling information of OSN users related to their activity score within the platform to capture the spatio-temporal features of their consecutive movements across a city.
Despite this variety, the usage of fuzzy clustering techniques with OSN data has not been fully exploited. For instance, Ref. [
55] actually proposes a fuzzy modelling approach for human mobility mining. Nonetheless, several dissimilarities exist between that work and ours. Firstly, it uses the Fuzzy C-Means (FCM) clustering algorithm to uncover the OSN-active areas. In that sense, FCM is only able to generate spherical-shape clusters, whereas the GK algorithm, used in the present work, allows for generating clusters with different geometrical shapes. This is more convenient due to the heterogeneous distribution of OSN documents in urban areas. Secondly, whilst our approach fuses the spatio-temporal features and the textual content of OSN documents for the clusters’ identification, Ref. [
55] only takes into account the spatial and temporal attributes of the documents. Finally, this work goes beyond the pattern discovery proposed in [
55] by also developing a location predictor on top of the patterns. For the sake of completeness, we also mention the work in [
59], which proposes a fuzzy version of a Multinominal Mixture Model (MMM) to detect the gender of the Twitter users on the basis of the textual content of their tweets.
Regarding location prediction, the anticipation of the future movement of a target individual is based on the idea that human mobility exhibits a high regularity, and, thus, predictability [
6]. In this frame, our work also includes some innovative features with respect to existing literature related to OSN-based location predictors [
16,
56,
57,
58]. In this frame, most works make use of the spatio-temporal features of the documents in order to perform the prediction [
56,
57]. For example, like in [
57], our approach also uses the spatio-temporal features of the documents of a user to make a prediction. However, the present work also takes under consideration the textual features of the documents in order to provide a prediction. In addition to that, whilst [
57] proposes a real-time system orchestrated by means of event-based rules, our work combines two steps: (i) an offline one to generate the clusters and the underlying mobility patterns and (ii) an online step where the patterns are used to generate a prediction in real time. This way, we avoid the convergence period problem that the mechanism in [
57] suffers from. Another difference exists regarding the particular prediction algorithm, while the work in [
57] makes use of a Fallback Markov Model, we rely on fuzzy rules. In that sense, these rules provide more flexible capabilities to deal with uncertainty than the aforementioned Markov model.
A different approach is put forward in [
16] that considers the spatial distribution of words of OSN documents to predict the next location of an OSN users. Like our proposal, Ref. [
58] considers the three dimensions of an OSN document: temporal, location and textual features. By following a Bayesian-network approach, the proposed system is able to forecast the next location and activity of a user by also taking into account temporal factors. However, in our case, we follow a fuzzy-rule system, which is able to deal with the uncertainty inherent to OSN data.
7. Conclusions
The study of human dynamics is paramount for the development of innovative services in the context of large cities. In that sense, OSN platforms have arisen as a cost-effective data source to extract human-generated mobility data. For that reason, the research community has provided several solutions to mine mobility patterns by using such OSN data. However, the proper management of their inherent uncertainty and the full analysis of all their characteristics is still an open issue.
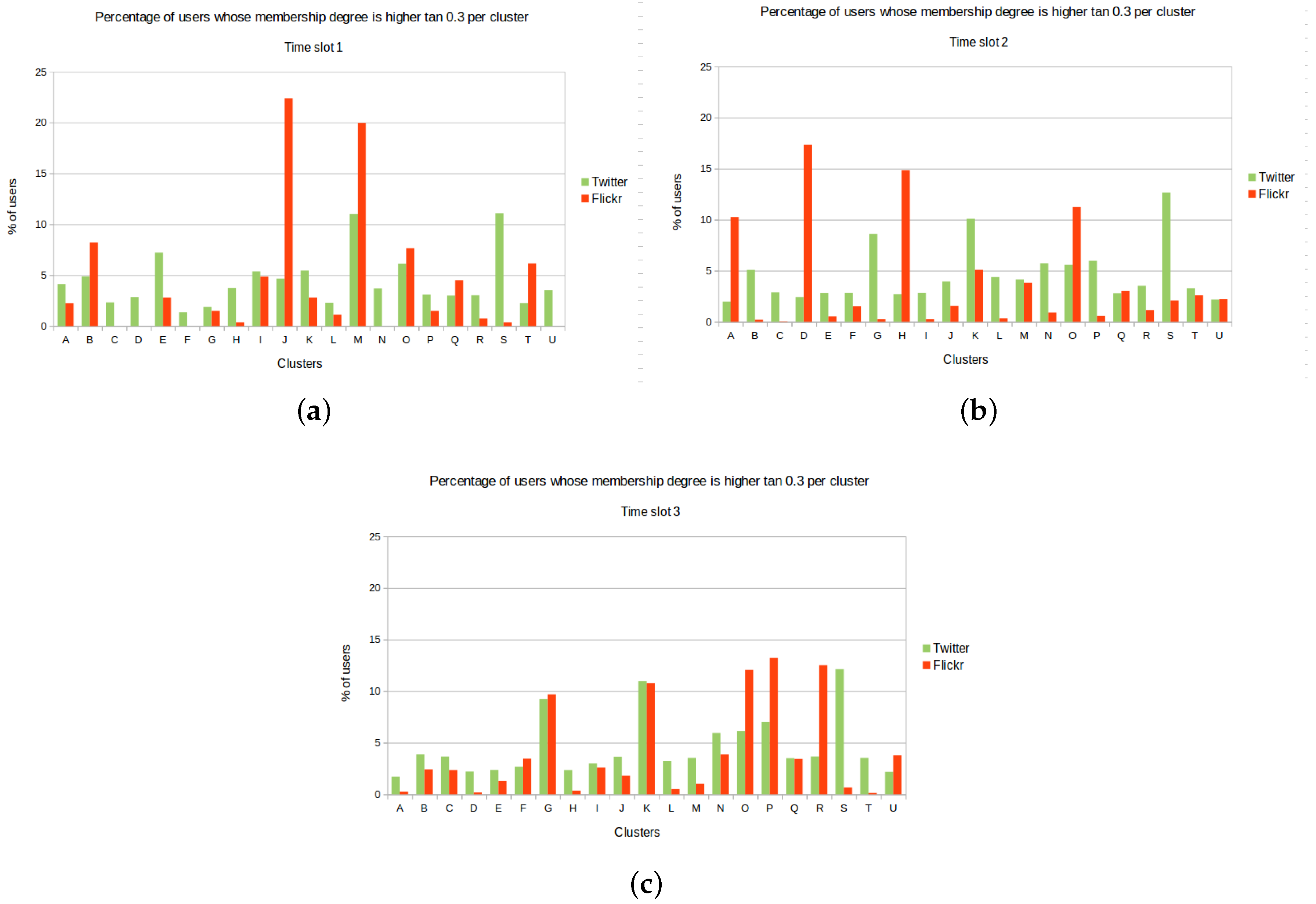
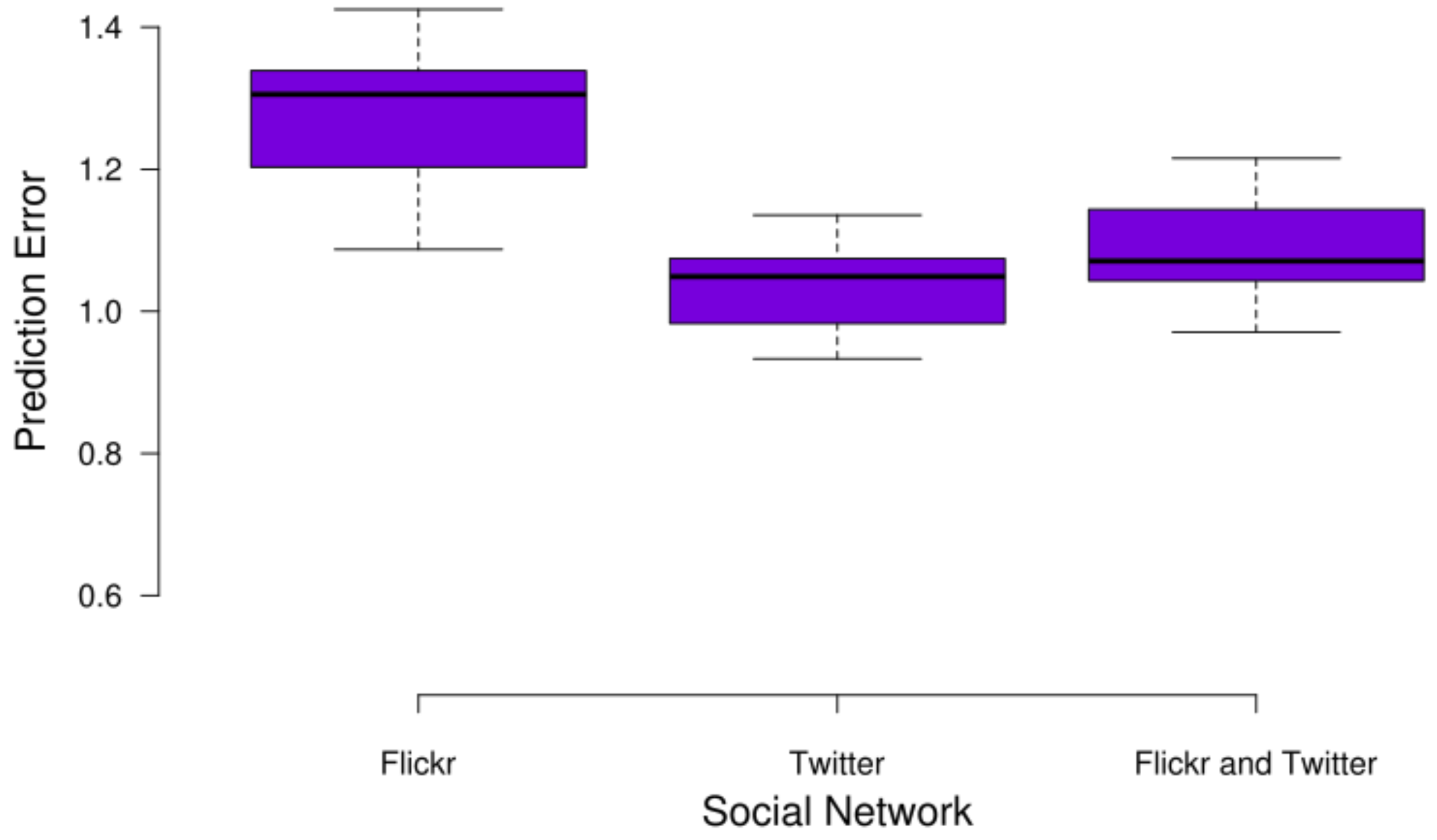
For that reason, the present work puts forward an innovative fuzzy model for human dynamics that solely relies on OSN data. By means of well-established fuzzy algorithms and classifiers, we have developed a mechanism able to extract the social areas of a city and the mobility flows among them. Furthermore, we made use of the textual content of OSN documents in order to semantically enrich the discovered areas. On top of such a solution, a prediction service has been implemented in order to anticipate future movements of city dwellers. The evaluation study has shown the feasibility of the proposal by detecting the mobility patterns in two different cities and the convenience of the semantic enrichment of the clusters.
Finally, future work will focus on including metrics to asses the accuracy of the semantic labelling of the clusters. In that sense, the usage of well-known ontologies like Wordnet is foreseen. Moreover, other repositories reporting land-use data will be studied in order to allow the static and dynamic labelling of the uncovered clusters.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}