Capturing Complex 3D Human Motions with Kernelized Low-Rank Representation from Monocular RGB Camera

Abstract
:1. Introduction
2. Motivations
2.1. NRSfM with Low-Rank Priors
2.2. Low-Rank Representation
3. Formulations
4. Optimization
| Algorithm 1: Solving problem (12) by ALM. |
| Input: Output: initialization ; while not converged do  end |
4.1. The Solution of and
4.2. The Solution of
4.3. The Solution of
4.4. The Solution of and
5. Experiments
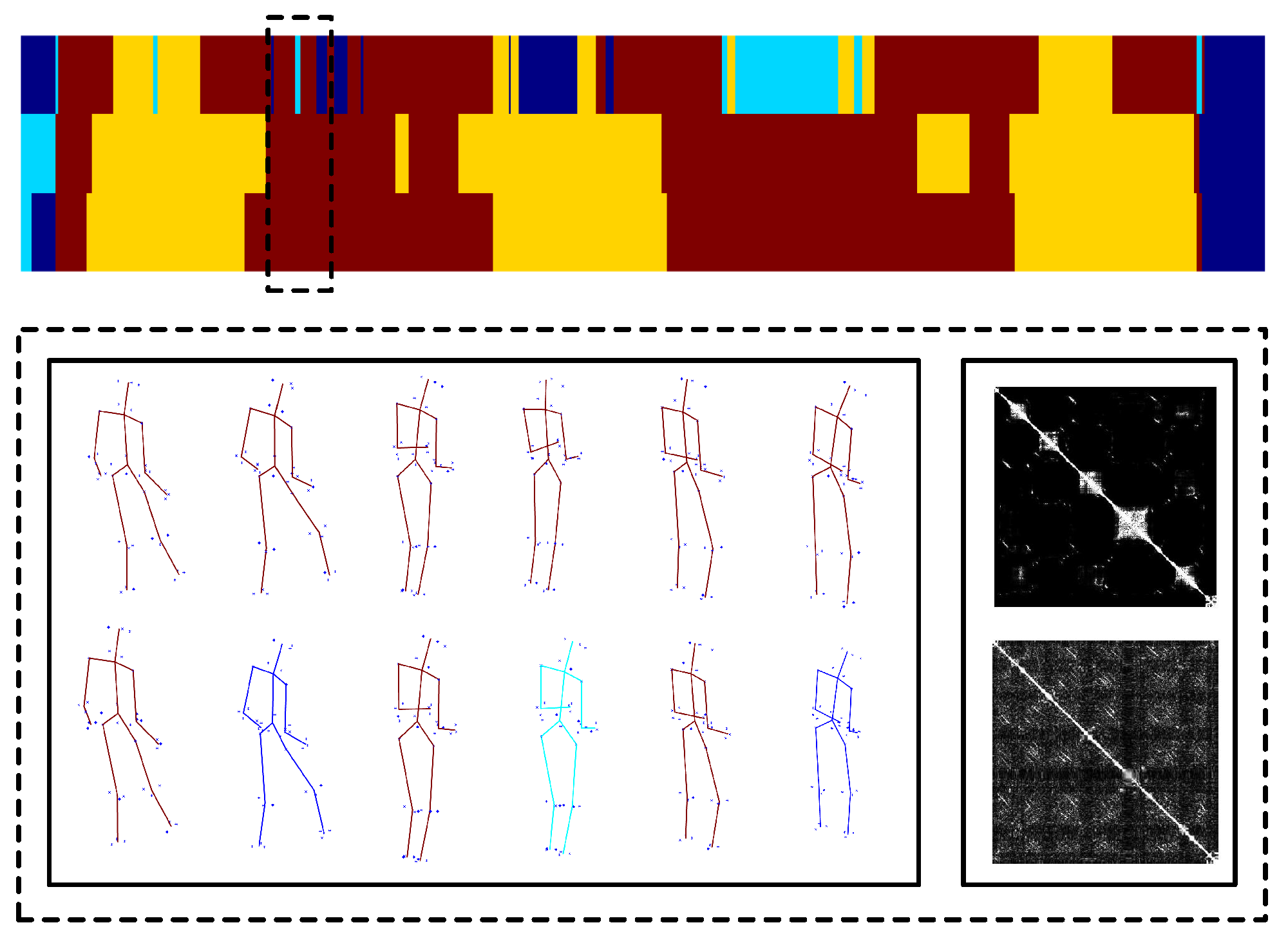
5.1. Subspaces Analysis
5.2. Quantitative Evaluation
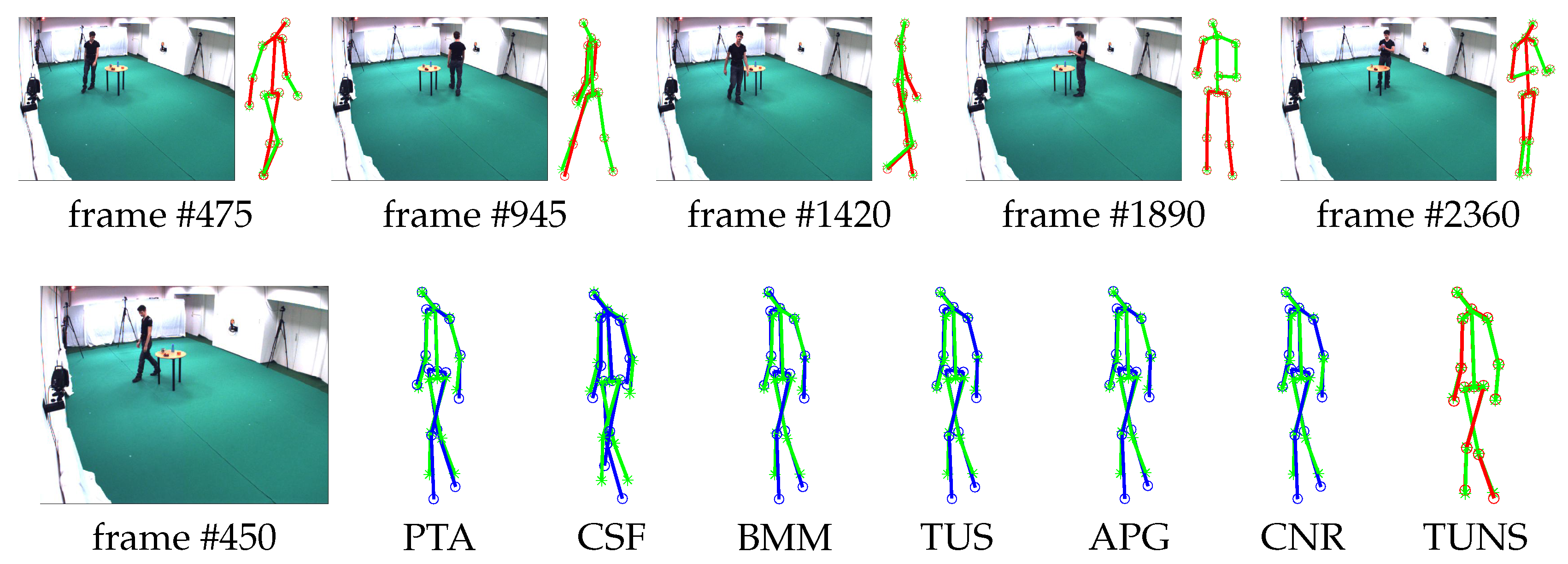
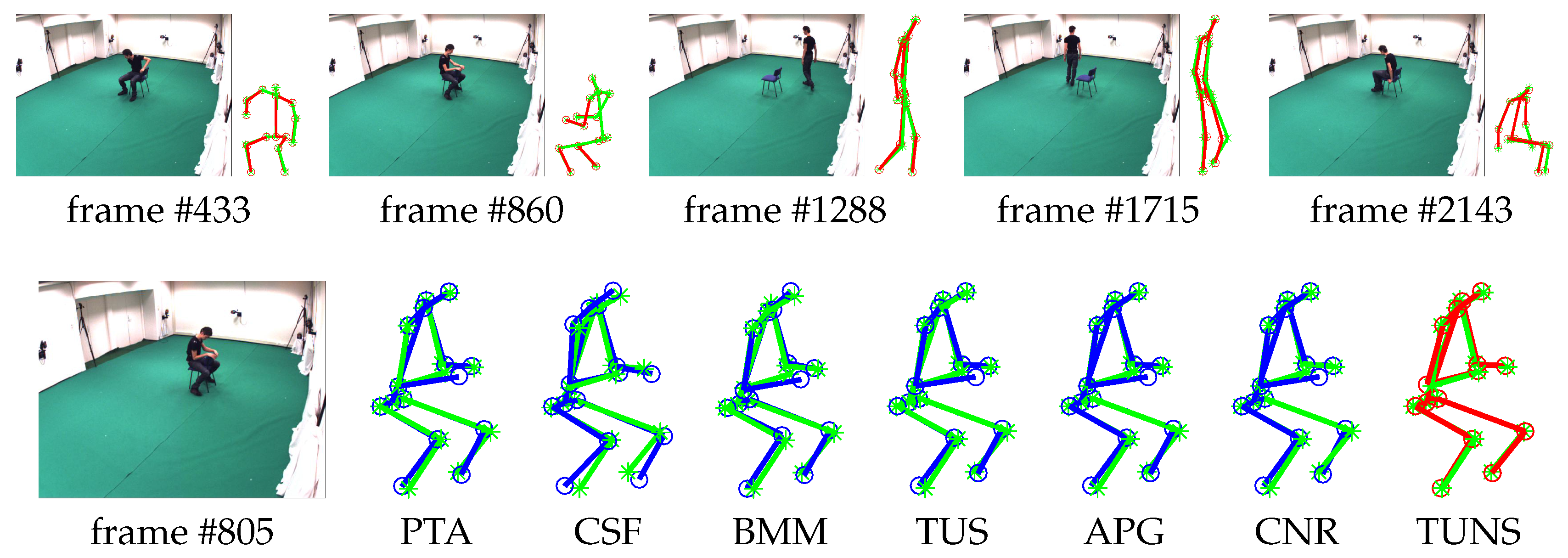
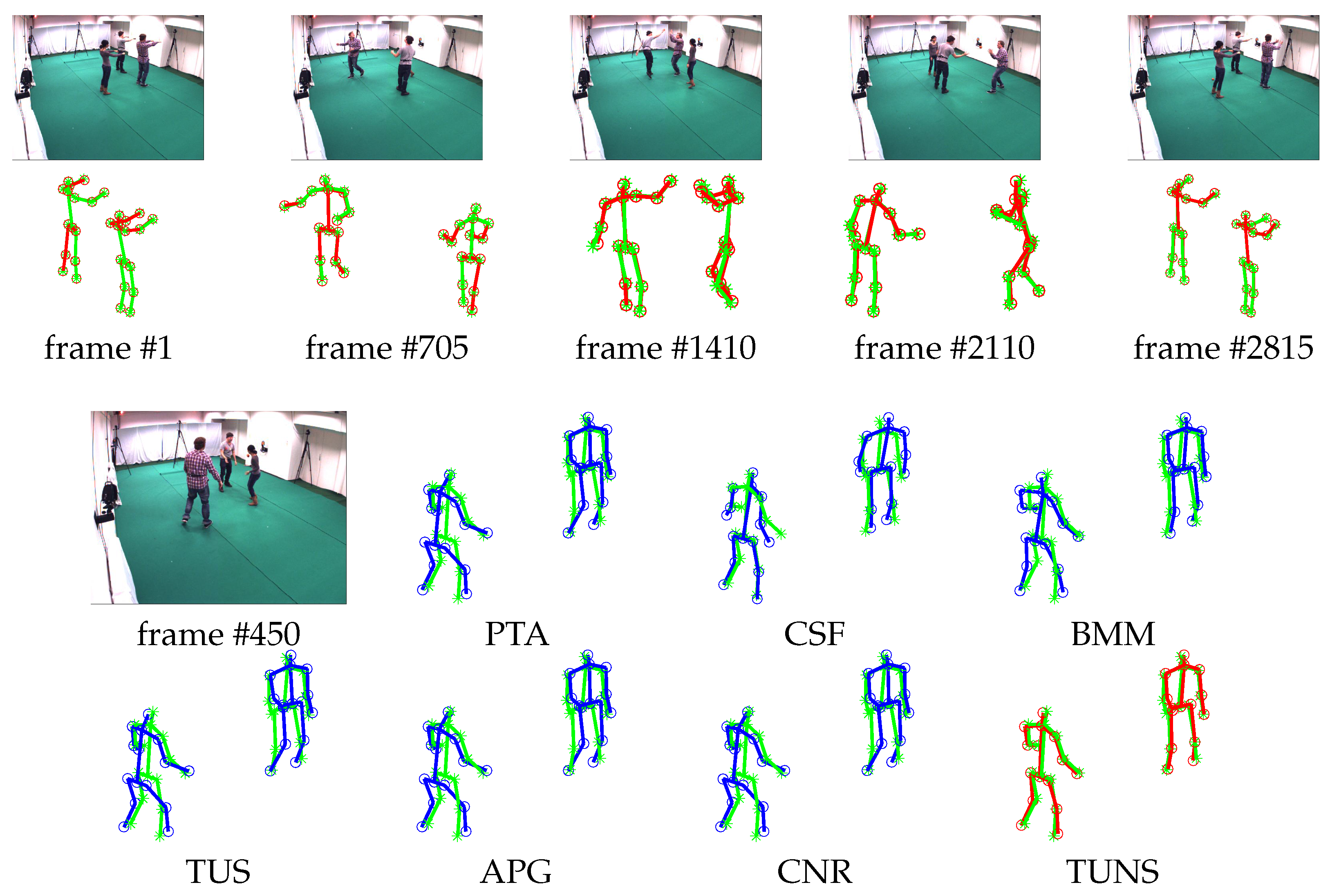
5.3. Qualitative Evaluation of Marker-Less Method
5.4. Discussion
6. Conclusions
Author Contributions
Conflicts of Interest
References
- Bregler, C.; Hertzmann, A.; Biermann, H. Recovering non-rigid 3D shape from image streams. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hilton Head Island, SC, USA, 15 June 2000; pp. 690–696. [Google Scholar]
- Tomasi, C.; Kanade, T. Shape and motion from image streams under orthography: A factorization method. Int. J. Comput. Vis. 1992, 9, 137–154. [Google Scholar] [CrossRef]
- Xiao, J.; Chai, J.; Kanade, T. A closed-form solution to non-rigid shape and motion recovery. Int. J. Comput. Vis. 2006, 67, 233–246. [Google Scholar] [CrossRef]
- Akhter, I.; Sheikh, Y.; Khan, S.; Kanade, T. Nonrigid structure from motion in trajectory space. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 41–48. [Google Scholar]
- Ahkter, I.; Sheikh, Y.; Khan, S.; Kanade, T. Trajectory Space: A Dual Representation for Nonrigid Structure from Motion. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1442–1456. [Google Scholar]
- Gotardo, P.F.U.; Martinez, A.M. Computing smooth time-trajectories for camera and deformable shape in structure from motion with occlusion. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2051–2065. [Google Scholar] [CrossRef] [PubMed]
- Akhter, I.; Sheikh, Y.; Khan, S. In defense of orthonormality constraints for nonrigid structure from motion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1534–1541. [Google Scholar]
- Dai, Y.; Li, H.; He, M. A simple prior-free method for non-rigid structure-from-motion factorization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2018–2025. [Google Scholar]
- Wang, Y.; Tong, L.; Jiang, M.; Zheng, J. Non-Rigid Structure Estimation in Trajectory Space from Monocular Vision. Sensors 2015, 15, 25730–25745. [Google Scholar] [CrossRef] [PubMed]
- Gotardo, P.F.U.; Martinez, A.M. Non-rigid structure from motion with complementary rank-3 spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3065–3072. [Google Scholar]
- Lee, M.; Cho, J.; Choi, C.; Oh, S. Procrustean normal distribution for non-rigid structure from motion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 Jun 2013; pp. 1280–1287. [Google Scholar]
- Simon, T.; Valmadre, J.; Matthews, I.; Sheikh, Y. Separable spatiotemporal priors for convex reconstruction of time-varying 3D point clouds. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 204–219. [Google Scholar]
- Zhu, Y.; Lucey, S. Convolutional sparse coding for trajectory reconstruction. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 529–540. [Google Scholar] [CrossRef] [PubMed]
- Lee, M.; Cho, J.; Oh, S. Consensus of non-rigid reconstructions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Burenius, M.; Sullivan, J.; Carlsson, S. 3D pictorial structures for multiple view articulated pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3618–3625. [Google Scholar]
- Oh, H.; Cha, G.; Oh, S. Samba: A Real-Time Motion Capture System Using Wireless Camera Sensor Networks. Sensors 2014, 14, 5516–5535. [Google Scholar] [CrossRef] [PubMed]
- Tsai, M.H.; Chen, K.H.; l-Chen, L. Real-time Upper Body Pose Estimation from Depth Images. In Proceedings of the IEEE International Conference on Image Processing, Quebec City, QC, Canada, 27–30 September 2015. [Google Scholar]
- Michel, D.; Panagiotakis, C.; Argyros, A.A. Tracking the articulated motion of the human body with two RGBD cameras. Mach. Vis. Appl. 2015, 26, 41–54. [Google Scholar] [CrossRef]
- Rádlová, R.; Bouwmans, T.; Vachon, B. Models Used by vision—Based motion capture. In Proceedings of the Computer Graphics and Artificial Intelligence (3IA), Limoges, France, 23–24 May 2006. [Google Scholar]
- Sigal, L. Human pose estimation. In Computer Vision: A Reference Guide; Springer US: New York, NY, USA, 2014; pp. 362–370. [Google Scholar]
- Andriluka, M.; Sigal, L. Human context: Modeling human-human interactions for monocular 3D pose estimation. In Proceedings of the Articulated Motion and Deformable Objects, Mallorca, Spain, 11–13 July 2012. [Google Scholar]
- Andriluka, M.; Roth, S.; Schiele, B. Monocular 3D pose estimation and tracking by detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 623–630. [Google Scholar]
- Yao, A.; Gall, J.; Gool, L.V.; Urtasun, R. Learning probabilistic non-linear latent variable models for tracking complex activities. In Proceedings of the Advances in Neural Information Processing System, Granada, Spain, 12–17 December 2011; pp. 1359–1367. [Google Scholar]
- Taylor, G.W.; Sigal, L.; Fleet, D.J.; Hinton, G.E. Dynamical binary latent variable models for 3D human pose tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 631–638. [Google Scholar]
- Tian, Y.; Sigal, L.; De la Torre, F.; Jia, Y. Canonical locality preserving latent variable model for discriminative pose inference. Image Vis. Comput. 2013, 31, 223–230. [Google Scholar] [CrossRef]
- Zhu, H.; Yu, Y.; Zhou, Y.; Du, S. Dynamic Human Body Modeling Using a Single RGB Camera. Sensors 2016, 16, 402. [Google Scholar] [CrossRef] [PubMed]
- Ek, C.H.; Torr, P.H.; Lawrence, N.D. Gaussian process latent variable models for human pose estimation. In Proceedings of the Machine Learning for Multimodal Interaction, Utrecht, The Netherlands, 8–10 September 2008; pp. 132–143. [Google Scholar]
- Tekin, B.; Rozantsev, A.; Lepetit, V.; Fua, P. Direct prediction of 3D body poses from motion compensated sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Elhayek, A.; de Aguiar, E.; Jain, A.; Tompson, J.; Pishchulin, L.; Andriluka, M.; Bregler, C.; Shiele, B.; Theobalt, C. Efficient ConvNet-based marker-less motion capture in general scenes with a low number of cameras. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 3810–3818. [Google Scholar]
- Gong, W.; Zhang, X.; Gonzàlez, J.; Sobral, A.; Bouwmans, T.; Tu, C.; Zahzah, E.-H. Human Pose Estimation from Monocular Images: A Comprehensive Survey. Sensors 2016, 16, 1966. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Huang, D.; De La Torre, F.; Lucey, S. Complex non-rigid motion 3D reconstruction by union of subspaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 Jun 2014; pp. 1542–1549. [Google Scholar]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional Pose Machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4724–4732. [Google Scholar]
- Liu, G.; Lin, Z.; Yan, S.; Sun, J.; Yu, Y.; Ma, Y. Robust recovery of subspace structures by low-rank representation. IEEE Trans Pattern Anal. Mach. Intell. 2013, 35, 171–184. [Google Scholar]
- Xiao, S.; Tan, M.; Xu, D.; Dong, Z.Y. Robust kernel low-rank representation. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 2268–2281. [Google Scholar] [CrossRef] [PubMed]
- Cai, J.; Candès, E.J.; Shen, Z. A singular value thresholding algorithm for matrix completion. SIAM J. Optim. 2010, 20, 1956–1982. [Google Scholar] [CrossRef]
- Moré, J.J. The Levenberg-Marquardt Algorithm: Implementation and Theory. Numerical Analysis, Lecture Notes in Mathematics 1977, 630, 105–116. [Google Scholar]
- Lin, Z.; Chen, M.; Wu, L.; Ma, Y. The augmented Lagrange multiplier method for exact recovery of corrupted low-rank matrices. arXiv, 2009; arXiv:1009.5055. [Google Scholar]
- Aa, N.; Luo, X.; Giezeman, G.; Tan, R.; Veltkamp, R. Utrecht multi-person motion (umpm) benchmark: A multiperson dataset with synchronized video and motion capture data for evaluation of articulated human motion and interaction. In Proceedings of the International Conference on Computer Vision Workshop HICV, Barcelona, Spain, 6–13 November 2011. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PTA [5] | CSF [6] | BMM [8] | TUS [31] | APG [9] | CNR [14] | TUNS (Ours) | |
|---|---|---|---|---|---|---|---|---|
| Data | ||||||||
| 56_02 | 0.0227/0.0113 | 0.0500/0.0252 | 0.0235/0.0147 | 0.0204/0.0112 | 0.0215/0.0102 | 0.0341/0.0240 | 0.0205/0.0118 | |
| 56_03 | 0.0655/0.0301 | 0.1309/0.0792 | 0.0748/0.0446 | 0.0557/0.0254 | 0.0739/0.0460 | 0.0605/0.0316 | 0.0448/0.0219 | |
| 56_04 | 0.0720/0.0325 | 0.1819/0.1199 | 0.0843/0.0516 | 0.0637/0.0287 | 0.0792/0.0487 | 0.0661/0.0329 | 0.0538/0.0278 | |
| 56_05 | 0.0697/0.0354 | 0.2056/0.1269 | 0.0857/0.0596 | 0.0613/0.0312 | 0.0741/0.0479 | 0.0629/0.0341 | 0.0506/0.0287 | |
| 56_06 | 0.0951/0.0483 | 0.2412/0.1616 | 0.1085/0.0696 | 0.0827/0.0402 | 0.0975/0.0582 | 0.0829/0.0413 | 0.0667/0.0321 | |
| 56_07 | 0.1259/0.0542 | 0.3446/0.2144 | 0.1453/0.0889 | 0.0959/0.0424 | 0.1262/0.0789 | 0.2066/0.0982 | 0.0790/0.0385 | |
| 56_08 | 0.0807/0.0386 | 0.2015/0.1236 | 0.1158/0.0822 | 0.0717/0.0427 | 0.1415/0.1160 | 0.1910/0.1041 | 0.0583/0.0303 | |
| 86_01 | 0.0700/0.0321 | 0.1591/0.0942 | 0.0832/0.0516 | 0.0619/0.0267 | 0.0642/0.0271 | 0.0607/0.0278 | 0.0582/0.0237 | |
| 86_02 | 0.1817/0.0930 | 0.3170/0.2125 | 0.1716/0.0927 | 0.1521/0.0710 | 0.1586/0.0750 | 0.1463/0.0683 | 0.1449/0.0646 | |
| 86_03 | 0.1861/0.1057 | 0.3696/0.2751 | 0.1766/0.1018 | 0.1554/0.0799 | 0.1578/0.0832 | 0.1541/0.0795 | 0.1433/0.0733 | |
| 86_04 | 0.0934/0.0464 | 0.2384/0.1601 | 0.0975/0.0559 | 0.0826/0.0391 | 0.0854/0.0402 | 0.0783/0.0363 | 0.0774/0.0351 | |
| 86_05 | 0.2267/0.1394 | 0.3387/0.2595 | 0.1975/0.1131 | 0.1821/0.0972 | 0.1872/0.1008 | 0.1738/0.0938 | 0.1784/0.0949 | |
| 86_06 | 0.1765/0.0949 | 0.3724/0.2780 | 0.1745/0.0995 | 0.1570/0.0781 | 0.1617/0.0815 | 0.1516/0.0761 | 0.1501/0.0734 | |
| 86_07 | 0.1457/0.0854 | 0.4838/0.3634 | 0.1447/0.0878 | 0.1293/0.0702 | 0.1331/0.0724 | 0.1254/0.0677 | 0.1253/0.0688 | |
| 86_08 | 0.1333/0.0746 | 0.3672/0.2562 | 0.1366/0.0836 | 0.1191/0.0631 | 0.1227/0.0657 | 0.1152/0.0608 | 0.1157/0.0609 | |
| 86_09 | 0.0302/0.0135 | 0.0728/0.0498 | 0.0412/0.0237 | 0.0306/0.0118 | 0.0310/0.0112 | 0.0291/0.0107 | 0.0270/0.0096 | |
| 86_10 | 0.0636/0.0334 | 0.2489/0.1609 | 0.0681/0.0431 | 0.0534/0.0257 | 0.0552/0.0261 | 0.0516/0.0245 | 0.0505/0.0232 | |
| 86_11 | 0.0727/0.0416 | 0.4362/0.3212 | 0.0729/0.0465 | 0.0605/0.0319 | 0.0630/0.0329 | 0.0586/0.0306 | 0.0569/0.0304 | |
| 86_12 | 0.1190/0.0667 | 0.2714/0.2062 | 0.1225/0.0735 | 0.1102/0.0596 | 0.1131/0.0616 | 0.1096/0.0597 | 0.1078/0.0584 | |
| 86_13 | 0.0676/0.0420 | 0.1261/0.0931 | 0.0777/0.0566 | 0.0586/0.0361 | 0.0684/0.0462 | 0.0584/0.0348 | 0.0515/0.0276 | |
| Average Err. | 0.1049/0.0560 | 0.2579/0.1790 | 0.1101/0.0670 | 0.0902/0.0456 | 0.1008/0.0565 | 0.1008/0.0518 | 0.0830/0.0417 | |
| Relative Err. | 1.2639/1.3429 | 3.1072/4.2926 | 1.3265/1.6067 | 1.0867/1.0935 | 1.2145/1.3549 | 1.2145/1.2422 | 1/1 | |
| Method | PTA [5] | CSF [6] | BMM [8] | TUS [31] | APG [9] | CNR [14] | TUNS (Ours) | |
|---|---|---|---|---|---|---|---|---|
| Data | ||||||||
| p1_grab_3 | 0.1036/0.0639 | 0.1619/0.1127 | 0.0976/0.0673 | 0.0882/0.0539 | 0.0908/0.0558 | 0.0805/0.0492 | 0.0781/0.0560 | |
| p1_chair_2 | 0.0763/0.0461 | 0.1889/0.1281 | 0.0892/0.0664 | 0.0736/0.0429 | 0.0736/0.0433 | 0.0678/0.0404 | 0.0628/0.0441 | |
| p3_ball_12 | 0.0431/0.0244 | 0.0930/0.0682 | 0.0709/0.0591 | 0.0423/0.0245 | 0.0414/0.0225 | 0.0407/0.0226 | 0.0286/0.0168 | |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Wang, F.; Chen, Y. Capturing Complex 3D Human Motions with Kernelized Low-Rank Representation from Monocular RGB Camera. Sensors 2017, 17, 2019. https://doi.org/10.3390/s17092019
Wang X, Wang F, Chen Y. Capturing Complex 3D Human Motions with Kernelized Low-Rank Representation from Monocular RGB Camera. Sensors. 2017; 17(9):2019. https://doi.org/10.3390/s17092019
Chicago/Turabian StyleWang, Xuan, Fei Wang, and Yanan Chen. 2017. "Capturing Complex 3D Human Motions with Kernelized Low-Rank Representation from Monocular RGB Camera" Sensors 17, no. 9: 2019. https://doi.org/10.3390/s17092019
APA StyleWang, X., Wang, F., & Chen, Y. (2017). Capturing Complex 3D Human Motions with Kernelized Low-Rank Representation from Monocular RGB Camera. Sensors, 17(9), 2019. https://doi.org/10.3390/s17092019