1. Introduction
Cardiovascular disease is a class of dangerous and troublesome diseases that involve the development of myocardial infarction coronaries, peripheral arterial disease, cerebrovascular disease, cardiomyopathy, heart failure, and endocarditis, etc. It has been the leading cause of death globally [
1,
2,
3]. According to the statistics by the World Health Organization (WHO) [
4], 17.5 million people die each year from cardiovascular diseases, an estimated 31% of all deaths worldwide. More than 75% of cardiovascular diseases deaths occur in low-income and middle-income countries. In particular, approximately 3 million Chinese people die from cardiovascular diseases every year, accounting for 40% of all causes of death [
5]. Cardiovascular disease deaths resulted in a 4.79 year loss of life expectancy in the Chinese population [
5].
The number of patients suffering from cardiovascular disease is increasing dramatically. This leads to a sharp contradiction between the ever-increasing number of patients and limited medical resources. Computer-aided diagnosis (CAD) is a potential solution to alleviate such a contradiction, and it has constantly attracted more and more attention since being proposed [
6,
7,
8,
9].
In their technical details, these CAD approaches belong to the sensor data fusion community [
10], as the approaches make diagnoses based on fusing the data that is acquired by medical sensors from people. Nowadays, sensor-based e-healthcare systems are attracting increasing attention from both academic and industrial communities. They provides the interpretation of medical images or the reference diagnosis results for clinical staff based on the sensor data from patients. Taking advantage of the considerable development in machine learning algorithms, sensor data fusion has witnessed a widening and deepening of applications in various cardiovascular disease diagnoses [
11,
12,
13]. However, it is a pity that among the numerous diagnosis approaches based on sensor data fusion, those able to effectively address atrial hypertrophy diagnosis are missing. The underlying reason for this is that labelled atrial hypertrophy data are lacking. This causes a serious problem for most learning algorithms because their good performance depends heavily on sufficient training data. For example, supervised learning algorithms based on statistics can derive information concerned with data distribution and density with a large amount of training data.
From the literature, neural networks (NNs) [
14,
15,
16] and support vector machine (SVM) [
17,
18,
19] can solve atrial hypertrophy disease detection. NNs are powerful tools in nonlinear classification and regression, but the formulation of a concrete NN imposes huge and unexpected computational costs in defining the number of layers, the number of neurons in each layer, and the activation functions, etc. Therefore, between these two approaches, SVM is preferred. SVM computes the support vectors based on which a hyperplane is defined to maximize the separation between two classes. Recently, SVM has played an important role in computer-aided diagnosis for cardiovascular diseases including atrial hypertrophy [
20,
21,
22,
23,
24,
25], because it has good generalization performance, a compact structure and a solid theoretical basis. A number of SVM-based works have been proposed in recent years. However, as the practical data to be processed gets confusing, SVM encounters bottlenecks.
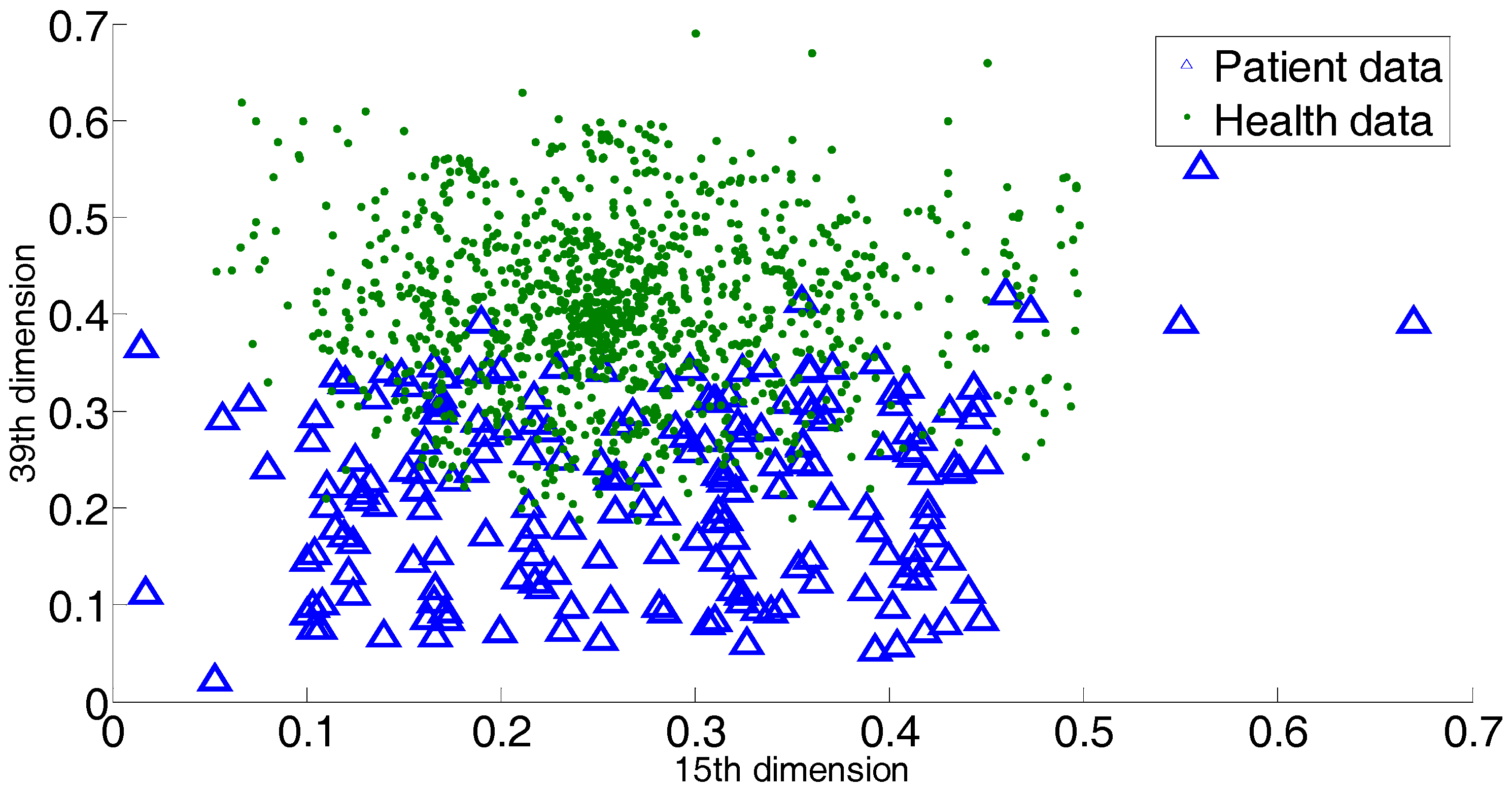
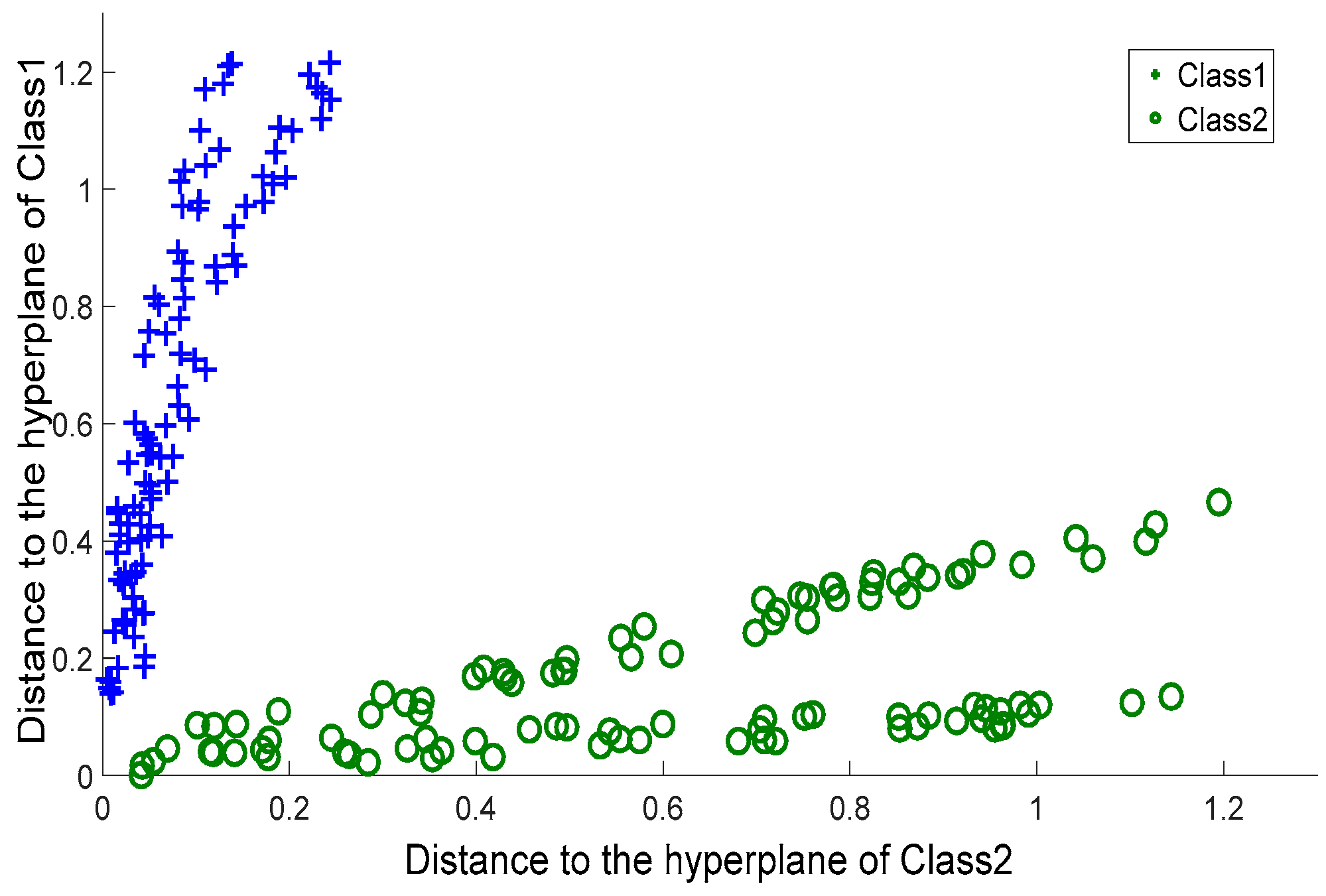
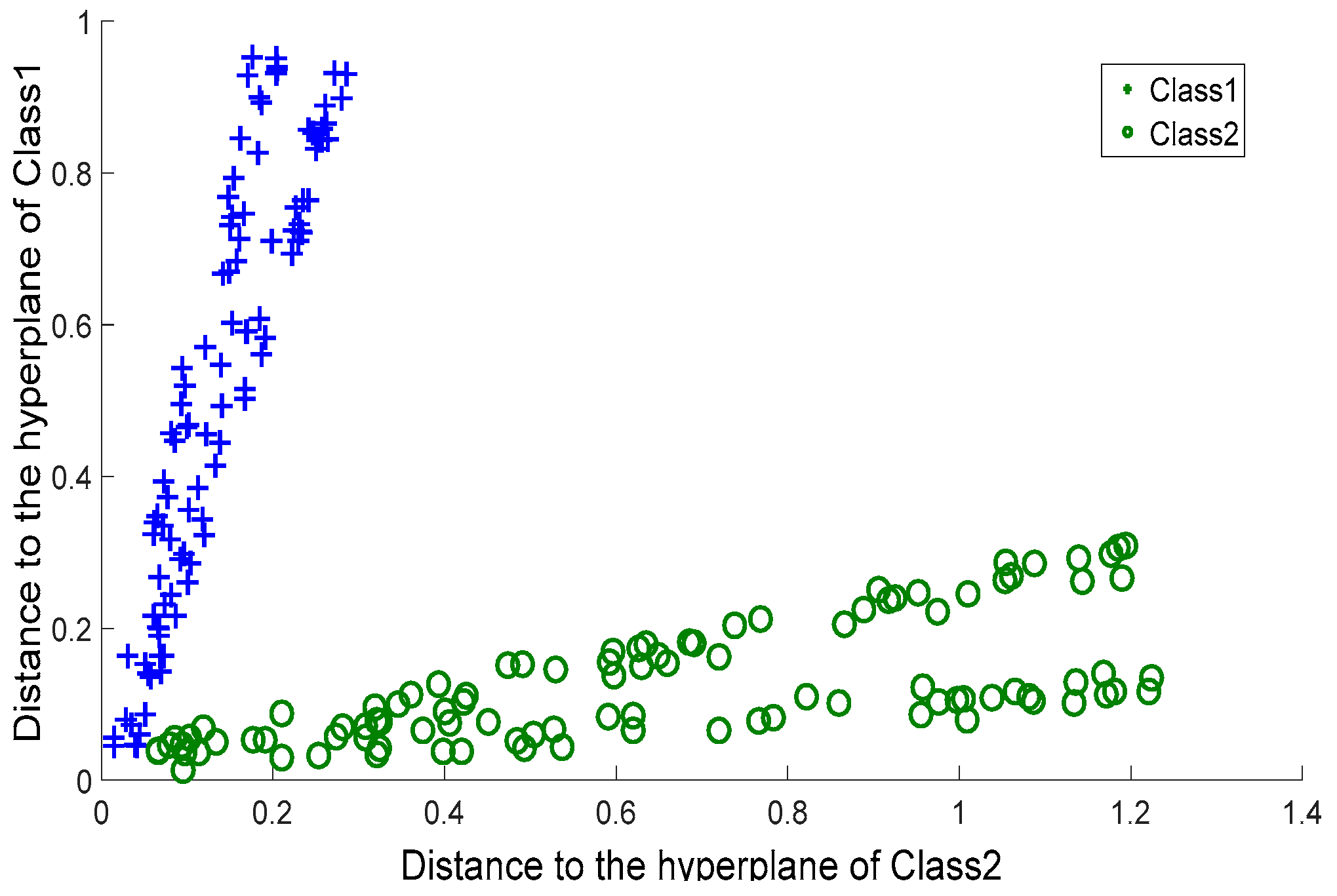
The first bottleneck lies in SVM’s hardship in labelling the data within the overlapping margin. SVM is a binary classifier, and it generates the separating hyperplane within the margin between two classes. This means SVM depends completely on the margin between two classes. To the overlapping classes, the margin is covered by data in a mess. It is difficult for SVM to construct a cutting hyperplane that can hold the maximum classification margin. However, it is notable that current medical data may not follow a given distribution, and the difference between patient information and healthy people’s information is getting more and more ambiguous. That is to say, the margin between the patient class and health class is blurred. Consequently, the behavior of SVM is affected by such a data environment. Another bottleneck of SVM is the negligence in handling outliers or novelties. In other words, SVM is not equipped with customized steps to process outliers. In the atrial data, this is a conspicuous issue, because as time goes by the physiological data of patients definitely become ever more complex. Even if two patients suffer from the same disease, there would be a sharp gap between their medical records. It is normal that a patient would exhibit an individual medical record that does not follow the typical characteristics. All these cases correspond to outliers or overlapping-region data, and special steps are required to derive discriminative information from them.
Recently, a diagnosis approach based on sensor data fusion was presented in [
25], a locally discriminant SVM (LDSVM) for atrial hypertrophy diagnosis. As an assembling approach, LDSVM consists of SVM and k-Nearest Neighbors (kNN). The former is trained in advance and the latter is started when the confidence of the decision of the SVM is below a threshold. The underlying idea of LDSVM is to append a classifier to modify the unpleasant initial decision. However, there are some problems encoded with LDSVM. Firstly, as [
25] indicated, the scenarios when the initial SVM decision fails usually involve datasets with overlapping classes. In such cases, kNN works in the overlapping regions based on a metric derived from the SVM hyperplane function. However, it should be noted that SVM is not good at addressing the overlapping classes, which implies that the hyperplane function produced by SVM would be biased. This leads to a distorted metric on which kNN works, and consequently, poor modification decisions. Secondly, the confidence threshold brings an increase in computational cost, and there is no heuristic for specifying such a parameter. Thirdly, LDSVM ignores the existence of outliers. It is known that medical data are often of high diversity, which means that on the one hand, the margin between the patient group and health group becomes more and more blurred; on the other hand, there exist outliers that are far away from the main occupied regions. If a diagnosis approach ignores the above two aspects, the diagnosis decision will be undesired.
Focused on above issues, in this paper we propose a novel approach for atrial hypertrophy diagnosis, and the approach is named characterized support vector hyperspheres (CSVH). CSVH takes the characters of atrial data (acquired from medical sensors) into consideration and develops two individual hyperspheres for the health class (consisting of the medical records of healthy people) and the patient class (consisting of the medical records of patients), respectively. The hypersphere of the patient class is formulated by a weighted schema, with the aim to identify outliers and overlapping-region data, and consequently, to collect well-defined class information. The hypersphere of the health class keeps furthest away from the patient class hypersphere, with the aim of obtaining the maximum separation between the two groups. When a query arrives, it is labelled according to membership functions defined based on the two hyperspheres. If the query is rejected by the two classes, the angle information between the query and outliers as well as the overlapping-region data is investigated to provide the further decision. To upgrade efficiency, CSVH is equipped with data-adaptive parameterization heuristics.
Instead of constructing a hyperplane as SVM does, CSVH generates hyperspheres to collect the discriminative information, because it is believed that a hypersphere is more powerful for data description than a hyperplane. Moreover, CSVH upgrades the common hypersphere model to the weighted version and the furthest-away version. That assists CSVH in revealing more inner-class information, learning more inter-class difference, and simultaneously allows it to be less affected by outliers and unpleasant data around blurring margins.
The remainder of this paper is organized as follows.
Section 2 introduces the experimental data for this study. The idea, procedure and the implementation details of the proposed CSVH are proposed in
Section 3.
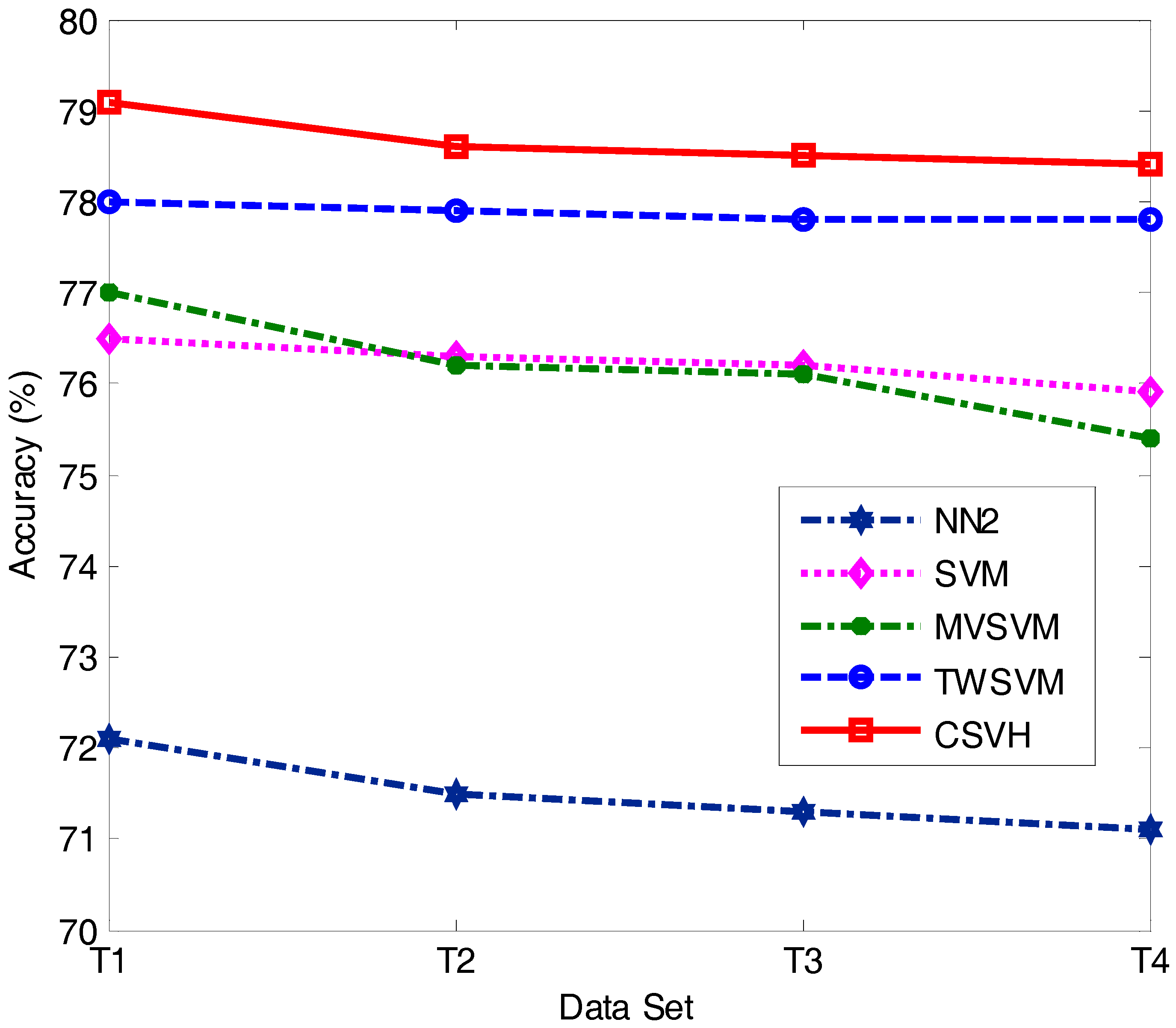
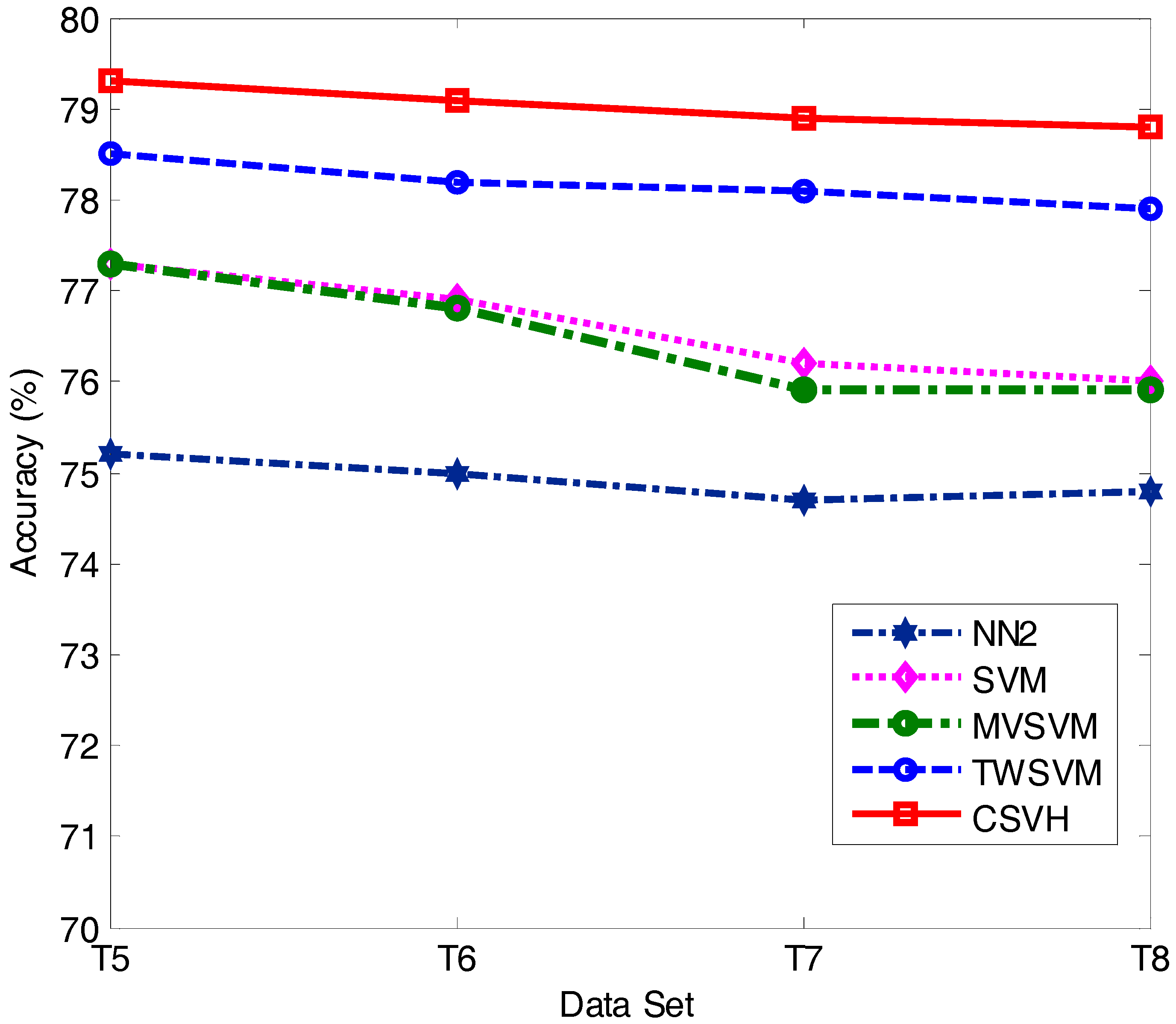
Section 4 discusses the experimental results on benchmark datasets and atrial data. Finally, conclusions and ongoing work are summarized in
Section 5.
3. Methods
3.1. The Outline of the Proposed CSVH Approach
The CSVH approach consists of two phases: the training phase and the labeling phase.
In the training phase, two characterized hyperspheres for two classes are constructed. Motivated by the observation that the distribution of patient class data for atrial hypertrophy is diverse, the hypersphere of the patient class is equipped with a data-adaptive weighted schema, with the aim to strengthen the presence of outliers and overlapping-region data. Simultaneously, based on the fact that the health group data are relatively denser than the patient data, the hypersphere of the health group keeps furthest away from the patient class, with the aim of obtaining the maximum separation between the two groups.
In the labeling phase, two membership functions are defined based on the two hyperspheres, and they provide the degree of belonging query to the two classes. When a query arrives, its belonging degree to the two classes is first computed. If the two degrees are close enough, the angle information between the query and outliers as well as the overlapping-region data are investigated to refine the membership decision.
The CSVH steps are outlined as follows.
Training phase:
- (1)
Preprocess training of the atrial sensor data.
- (2)
Construct the weighted hypersphere for the patient class, and obtain a, R2, and OsetP.
- (3)
Construct the furthest hypersphere for the health class, and obtain b, Z2, and OsetH.
where a is the hypersphere center of the patient class, and b is the hypersphere center of the health class; R and Z are the two hypersphere radii; OsetH is the set including outliers and the overlapping-region data of the health class, and OsetP is the set including outliers in the patient class.
Labeling phase:
- (4)
For query Q, compute its hypersphere-wise membership degrees to two hyperspheres, Gp(Q) and Gh(Q).
- (5)
If | Gh(Q) − Gp(Q)| > εQ, label Q as the class with higher membership.
- (6)
If | Gh(Q) − Gp(Q)| ≤ εQ, label Q based on the information of the outlier and overlapping-region data.
where Gp(Q) and Gh(Q) are two membership functions; εQ is the threshold to determine whether Q is rejected by the two classes.
3.2. Characterized Hypersphere of the Patient Class
The diversity in a distribution of patient data requires CSVH to construct a weighted hypersphere to identify the unpleasant data (including outliers and overlapping-region data). For this reason, the formulation of the hypersphere and inner-class data are equipped with large penalty coefficients. This ensures that the hypersphere can cover this data and can develop a well-defined data description of the patient class. Other unpleasant data are equipped with small penalty coefficients, to highlight their presence.
The weighted hypersphere of the patient class is modeled based on the containing hypersphere [
9,
29] and constructed through optimizing the following objective:
where
Np is the size of the patient class;
ϕ is the nonlinear map from the input space to the feature space;
ξi is a slack variable;
a is the hypersphere center;
R is the hypersphere radius; and
C is a penalty coefficient of the slack variable. Introducing a Gaussian kernel
k(
xi,
xj), the final objective is thus:
where
βi is a Lagrange multiplier.
The hypersphere center
a is computed as:
The hypersphere radius is computed by adopting a support vector in the following distance formula:
The data with βi = Ci and ξi > 0 are outliers and overlapping-region data. They constitute the set OsetP.
Then, consider the parameterization of the penalty coefficient
Ci. For outliers, they are of large distance to their nearest neighbors. Based on that fact, we consider the distance between
x and its nearest neighbor, and let that distance serve as the penalty factor:
where
xinear is the nearest neighbor of
xi. The further
xinear is from
xi, the more probable
xi is to be an outlier, and a relatively small penalty coefficient is required. Notice that the distance is computed in the feature space. Introduce a Gaussian kernel, and we have:
For overlapping-region data, some of the neighbors would come from the other class. Therefore, we investigate the ratio of neighbors of the own class to those of the other class. Such a ratio works as another penalty factor, defined as:
where
OTHERi and
OWNi are the sets of neighbors of
xi belonging to the other class and own class of
xi, respectively. |∙| computes the cardinality of the set. The higher the ratio of |
OTHER| to |
OWN|, the more probable that
xi is in the overlapping-region data, and consequently, a relatively small penalty factor is required.
Combine the above two factors to form the penalty coefficient customized to
xi as:
3.3. Characterized Hypersphere of the Class of Healthy Subjects
The hypersphere of the health class is characterized by the maximum separation from the hypersphere of the patient class. To keep the furthest distance between the two hyperspheres, the distance between the two hypersphere centers is investigated. Inspired by [
30], CSVH constructs the hypersphere of the health class that keeps furthest away from the origin of the feature space, and then maps the hypersphere center of the patient class to the origin to realize the maximum separation between the two hyperspheres.
3.3.1. Rough Model of the Furthest Hypersphere
To keep the hypersphere furthest away from the origin of the feature space, an appendix term is added to the original objective:
The meanings of
ϕ,
ξi and
C are the same as above.
b and
Z are the center and radius of the furthest hypersphere, respectively.
Nh is the size of the health class. The parameter
η determines the importance of ||
b||
2 (the distance from
b to the origin of the feature space) to the model formulation. Denote
γi as a Lagrange multiplier, and then the final objective is:
3.3.2. Refined Model of the Furthest Hypersphere
We mapped the hypersphere center of patient class,
a, to the origin of the feature space. If
a is viewed as the origin, then the new axes can be formed. The problem then turns to constructing the common hypersphere for the health class in the space spanned by the new axes. In that new space, there exists a new nonlinear map that is used in the formulation of the hypersphere. The nonlinear map under the new axes is denoted as
ϕ’. We considered modifying the original Kernel function
k to a new version
k’:
where
ϕ’ is the nonlinear map. As mentioned before,
a = ∑
βiφ(
xi), (
i = 1 …
Np). Therefore,
k’ is given by:
Replace k with k’ in (10), and the furthest hypersphere is obtained.
3.3.3. Parameterization of Balance Coefficient
η is the balance coefficient to tradeoff “
Z2” and “−||
b||
2” in Formula (9). These two terms essentially determine the volume and separation of the hypersphere for the health class. In this paper, it is derived from the approximate distribution information of the health class in the feature space:
where
.
The motivation for the above parameterization is as follows. s computes the average distance among health class members in the feature space, basically indicating the compactness of the health class. If s is high, it implies that the members of health class are scattered within a large area. In that case, the term “Z2” should be strengthened to ensure the tight volume of the health class hypersphere and consequently foster the separation between the two hyperspheres. Thus, a small η is required. Alternatively, if s is low, it implies that the distribution of the health class is relatively dense. In other words, in that scenario, the separation should be emphasized rather than the hypersphere volume. That is, term “−||b||2” should be highlighted, and a large η is required.
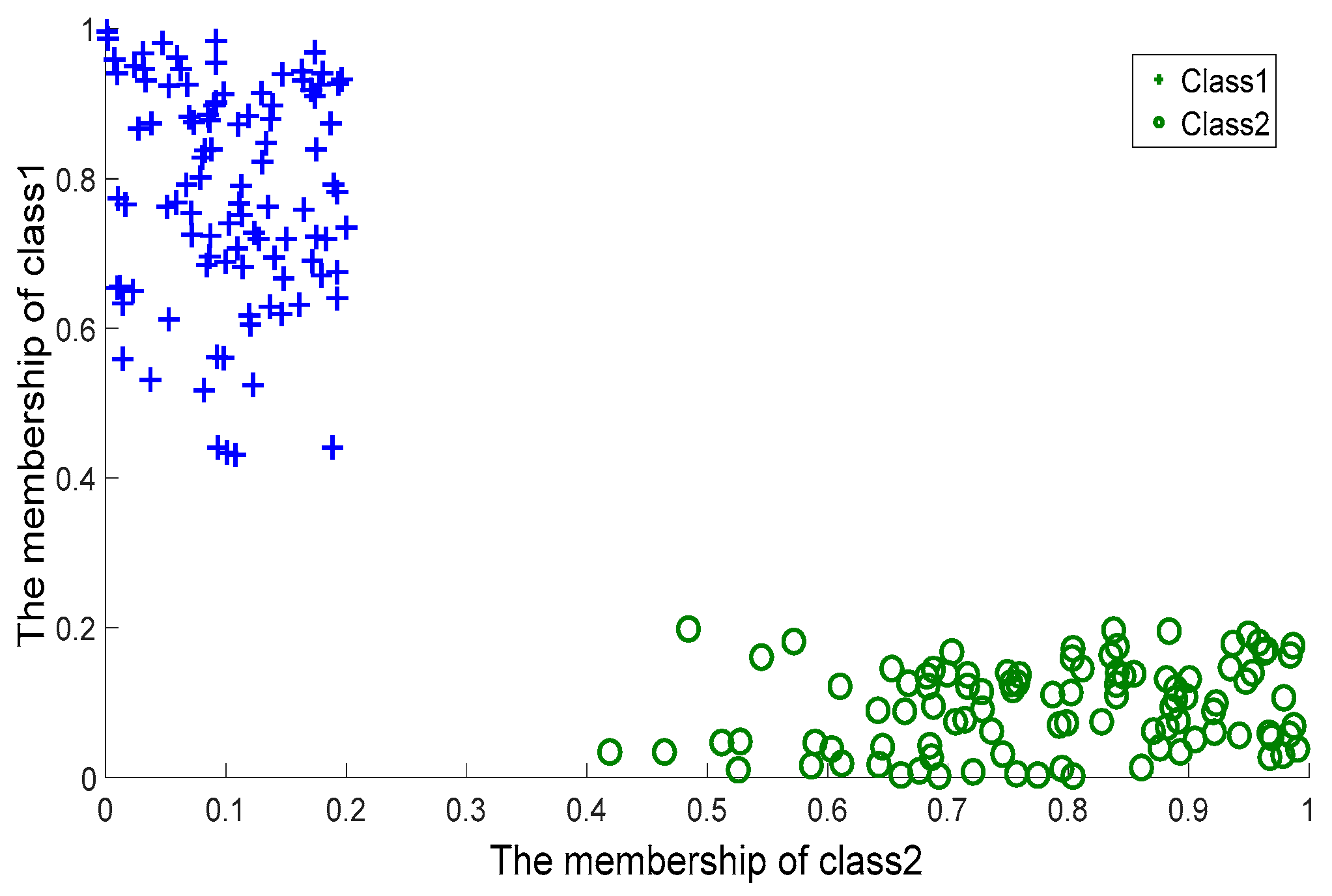
3.4. Labeling Phase
With the two hyperspheres in hand, we labelled the query according to its position with respect to two the hyperspheres. Here, CSVH takes the presence of outliers and overlapping-region data into consideration, and develops the membership functions in the below versions:
where
,
.
If |
Gh(
Q) −
Gp(
Q)| >
εQ,
Q is labelled as the class member with higher membership values. The threshold
εQ is specified adaptively as some percentage of the larger membership values:
If it is typical that |
Gh(
Q) −
Gp(
Q)| ≤
εQ, that fact corresponds to two cases. The one is that the query is far away from two classes, which implies that the query is relatively near to the outliers. In this case, labelling the query according to the information of the outliers is reasonable. The second case is that query is located within the margin between the two classes. That means the query is close to the overlapping-region data. In that case, the local information of the overlapping-region data is of discrimination ability to label the query. Therefore, CSVH searches for the most analogous one from
OsetP and
OsetH that is of the smallest angle with
Q. Denote the most analogous one as
QA, which is defined as:
Then,
Q is labelled as the same class as
QA. Therein, the inner product <
φ(
Q)·
φ(
x)> computes the
Cosine values of the angle between
Q and
x in the feature space. With the different kernel functions in the patient and health classes,
QA is computed by:










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}