A Robust Sparse Representation Model for Hyperspectral Image Classification †


Abstract
:1. Introduction
- (1)
- A robust sparsity-based classification model for HSIs is proposed when the data is corrupted by Gaussian noise and sparse noise, by incorporating the appropriate priors for noise-free data and degradations into an optimization framework.
- (2)
- An efficient algorithm is developed to solve the optimization problem by using an alternating minimization strategy.
- (3)
- The robust model is extended to efficiently incorporate spatial information. By jointly processing super-pixels, we strongly improve the performance both in terms of the classification accuracy and processing speed.
2. Sparsity-Based Models in HSI Classification
2.1. Sparse Representation Classification
2.2. Joint Sparse Representation Classification
3. Proposed Method
3.1. Robust SRC Model
3.2. Robust JSRC Model
3.3. Robust Super-Pixel Level JSRC
3.4. Optimization Algorithm
| Algorithm 1 Generic pseudo-code of the proposed approach |
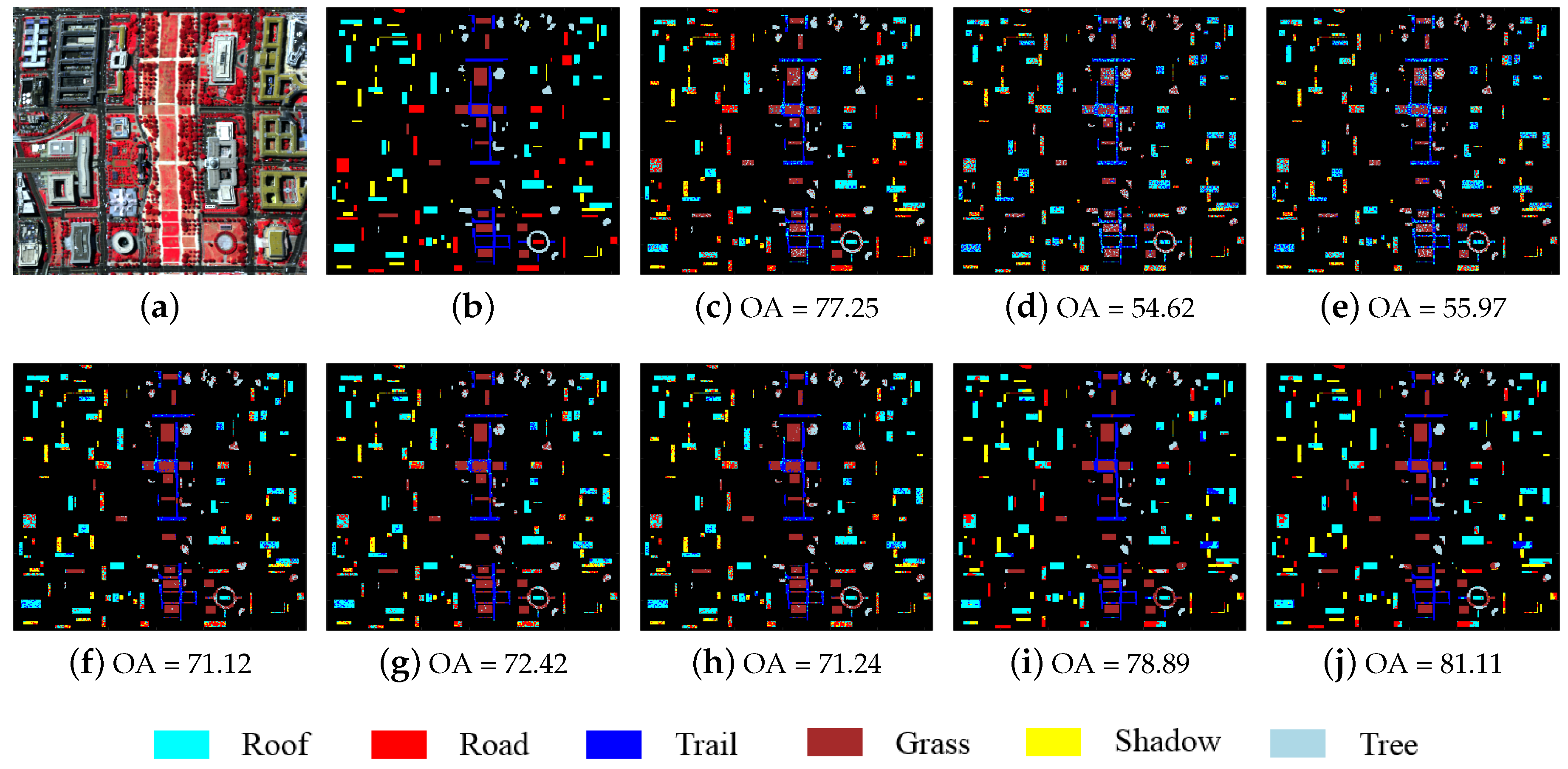
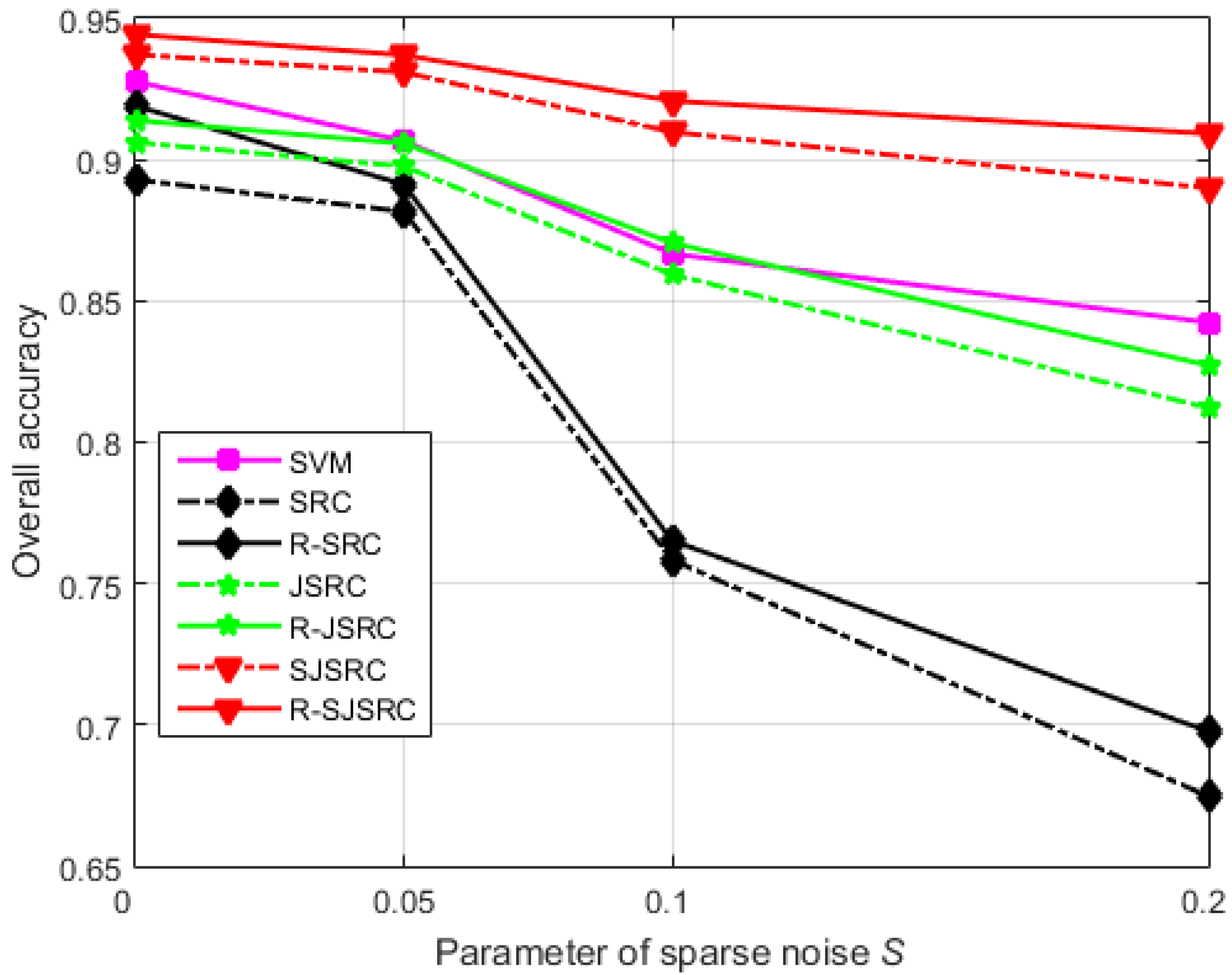
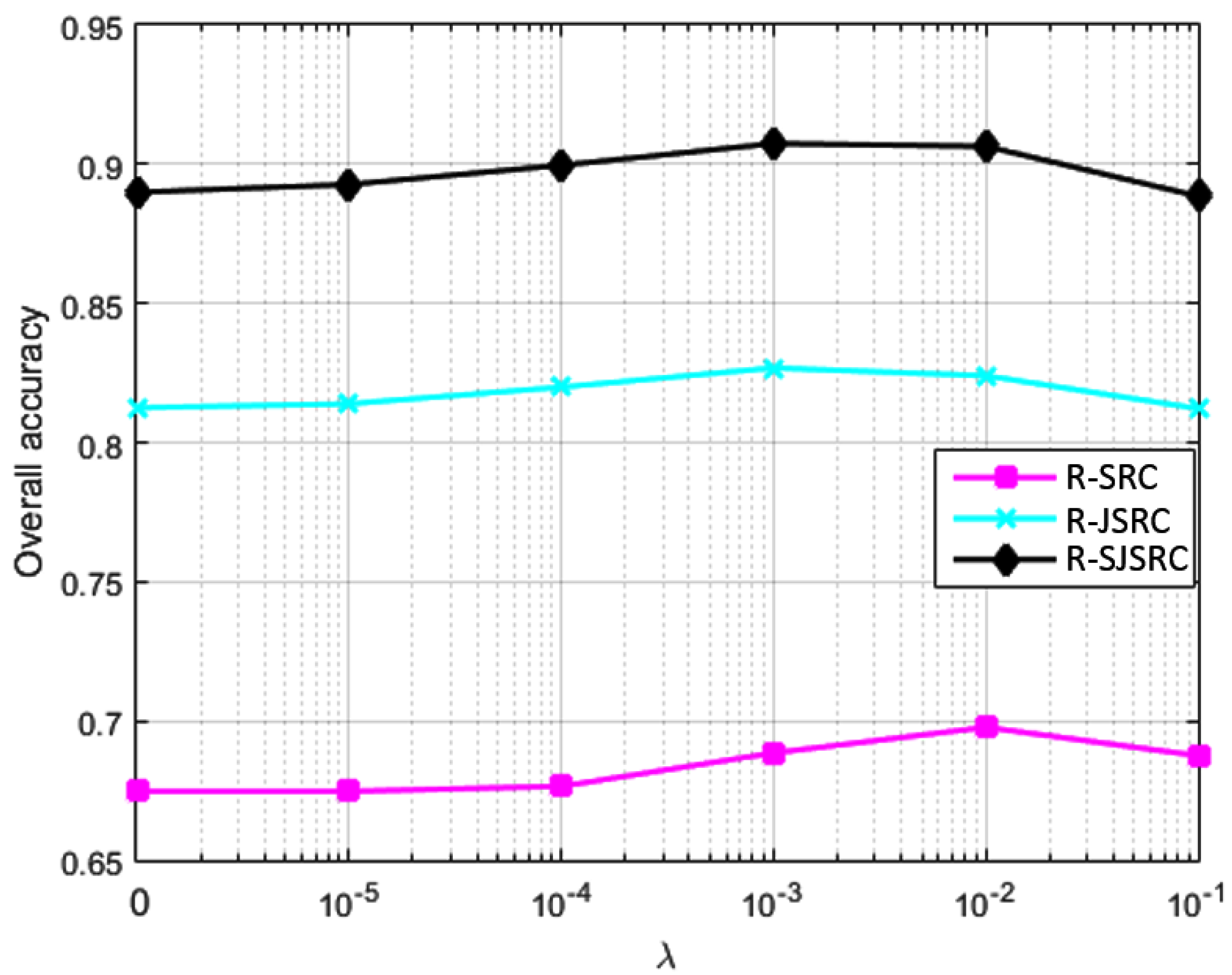
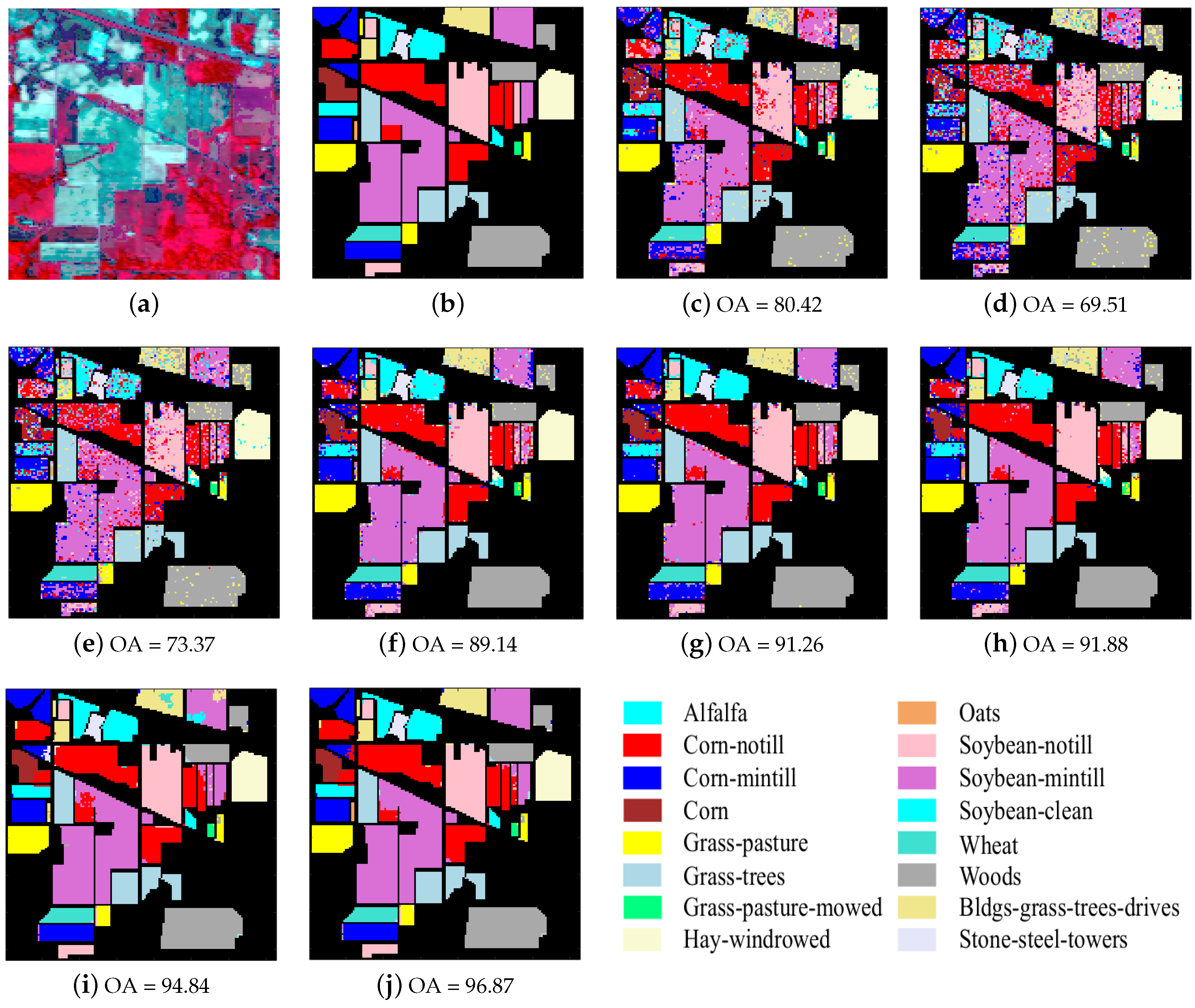
4. Experiments
4.1. Results for the Simulated HSI Experiment
- Zero-mean Gaussian noise in all bands with SNR value for each band varying from 10 to 20 dB.
- Impulse noise with 20% of corrupted pixels in bands 30–40.
- Dead lines in bands 70–73 with width ranging from one line to three lines.
- Strips in bands 101–104 with width ranging from one line to three lines.
4.2. Results for Real HSI Experiment
4.2.1. Classification Results on the Real Datasets
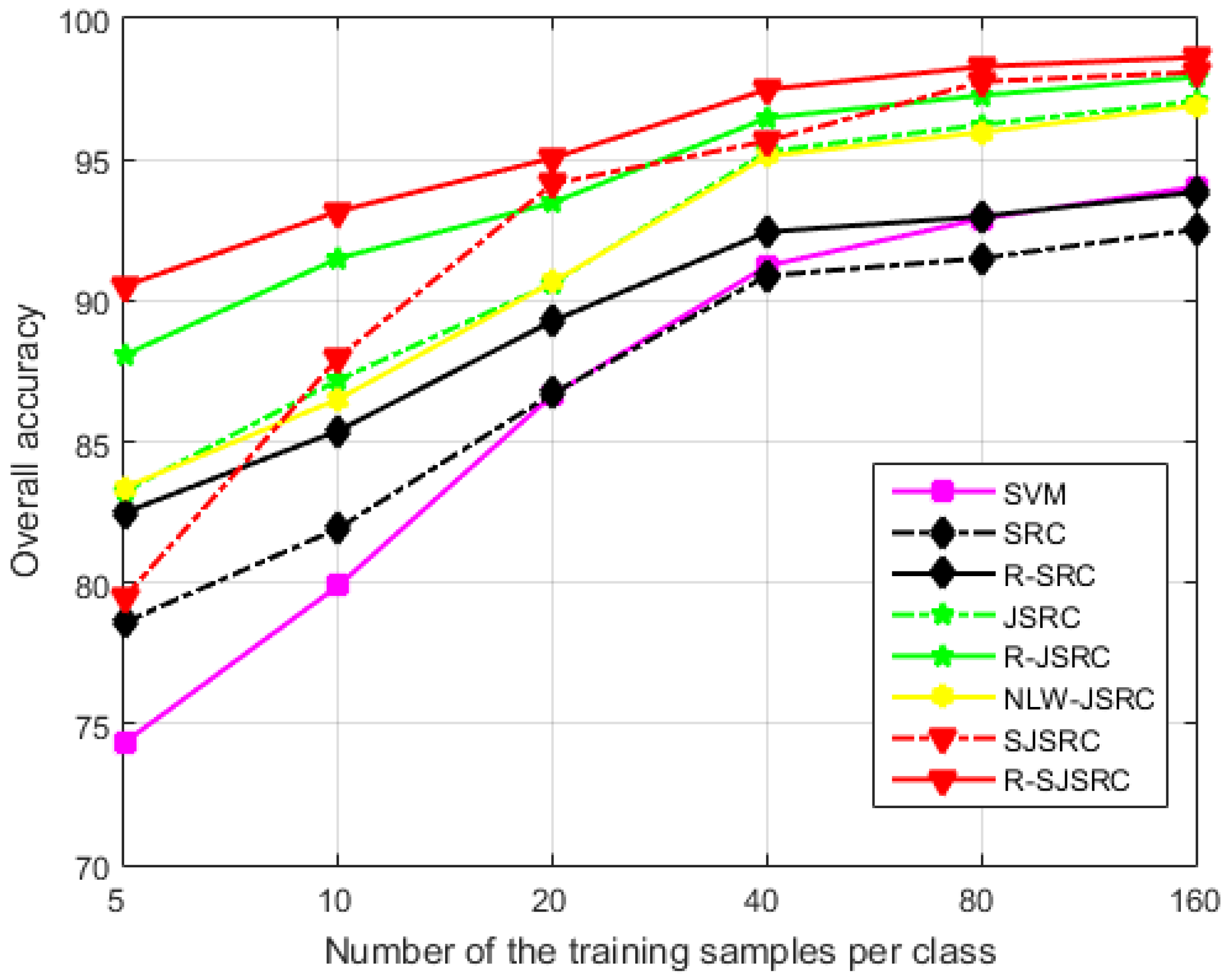
4.2.2. The Effect of the Training Sample Size
4.2.3. The Influence of the Segmentation Granularity
4.3. Practical Specification of the Parameters
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Datt, B.; McVicar, T.R.; Van Niel, T.G.; Jupp, D.L.; Pearlman, J.S. Preprocessing EO-1 Hyperion hyperspectral data to support the application of agricultural indexes. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1246–1259. [Google Scholar] [CrossRef]
- Lee, M.A.; Huang, Y.; Yao, H.; Thomson, S.J.; Bruce, L.M. Determining the effects of storage on cotton and soybean leaf samples for hyperspectral analysis. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2562–2570. [Google Scholar] [CrossRef]
- Eismann, M.T.; Stocker, A.D.; Nasrabadi, N.M. Automated hyperspectral cueing for civilian search and rescue. IEEE Proc. 2009, 97, 1031–1055. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Tuia, D.; Bruzzone, L.; Benediktsson, J.A. Advances in hyperspectral image classification: Earth monitoring with statistical learning methods. IEEE Signal Process. Mag. 2014, 31, 45–54. [Google Scholar] [CrossRef]
- Zhang, B.; Wu, D.; Zhang, L.; Jiao, Q.; Li, Q. Application of hyperspectral remote sensing for environment monitoring in mining areas. Environ. Earth Sci. 2012, 65, 649–658. [Google Scholar] [CrossRef]
- Ratle, F.; Camps-Valls, G.; Weston, J. Semisupervised neural networks for efficient hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2271–2282. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Semisupervised hyperspectral image segmentation using multinomial logistic regression with active learning. IEEE Trans. Geosci. Remote Sens. 2010, 48, 4085–4098. [Google Scholar] [CrossRef]
- Roscher, R.; Waske, B.; Forstner, W. Incremental import vector machines for classifying hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3463–3473. [Google Scholar] [CrossRef]
- Chen, C.; Li, W.; Tramel, E.W.; Cui, M.; Prasad, S.; Fowler, J.E. Spectral–spatial preprocessing using multihypothesis prediction for noise-robust hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1047–1059. [Google Scholar] [CrossRef]
- Prasad, S.; Li, W.; Fowler, J.E.; Bruce, L.M. Information fusion in the redundant-wavelet-transform domain for noise-robust hyperspectral classification. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3474–3486. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Tuia, D.; Ratle, F.; Pozdnoukhov, A.; Camps-Valls, G. Multisource composite kernels for urban-image classification. IEEE Geosci. Remote Sens. Lett. 2010, 7, 88–92. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Palmason, J.A.; Sveinsson, J.R. Classification of hyperspectral data from urban areas based on extended morphological profiles. IEEE Trans. Geosci. Remote Sens. 2005, 43, 480–491. [Google Scholar] [CrossRef]
- Dalla Mura, M.; Benediktsson, J.A.; Waske, B.; Bruzzone, L. Morphological attribute profiles for the analysis of very high resolution images. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3747–3762. [Google Scholar] [CrossRef]
- Liao, W.; Bellens, R.; Pizurica, A.; Philips, W.; Pi, Y. Classification of hyperspectral data over urban areas using directional morphological profiles and semi-supervised feature extraction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1177–1190. [Google Scholar] [CrossRef]
- Liao, W.; Pizurica, A.; Bellens, R.; Gautama, S.; Philips, W. Generalized graph-based fusion of hyperspectral and LiDAR data using morphological features. IEEE Geosci. Remote Sens. Lett. 2015, 12, 552–556. [Google Scholar] [CrossRef]
- Liao, W.; Dalla Mura, M.; Chanussot, J.; Bellens, R.; Philips, W. Morphological Attribute Profiles With Partial Reconstruction. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1738–1756. [Google Scholar] [CrossRef]
- Prasad, S.; Cui, M.; Li, W.; Fowler, J.E. Segmented mixture-of-Gaussian classification for hyperspectral image analysis. IEEE Geosci. Remote Sens. Lett. 2014, 11, 138–142. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.; Ganesh, A.; Sastry, S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Hyperspectral image classification using dictionary-based sparse representation. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3973–3985. [Google Scholar] [CrossRef]
- Zhang, H.; Li, J.; Huang, Y.; Zhang, L. A nonlocal weighted joint sparse representation classification method for hyperspectral imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2056–2065. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Hyperspectral image classification via kernel sparse representation. IEEE Trans. Geosci. Remote Sens. 2013, 51, 217–231. [Google Scholar] [CrossRef]
- Fang, L.; Li, S.; Kang, X.; Benediktsson, J.A. Spectral–spatial hyperspectral image classification via multiscale adaptive sparse representation. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7738–7749. [Google Scholar] [CrossRef]
- Wang, J.; Jiao, L.; Liu, H.; Yang, S.; Liu, F. Hyperspectral Image Classification by Spatial–spectral Derivative-Aided Kernel Joint Sparse Representation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2485–2500. [Google Scholar] [CrossRef]
- Li, J.; Zhang, H.; Zhang, L. Efficient superpixel-level multitask joint sparse representation for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5338–5351. [Google Scholar]
- Fu, W.; Li, S.; Fang, L.; Kang, X.; Benediktsson, J.A. Hyperspectral Image Classification Via Shape-Adaptive Joint Sparse Representation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 556–567. [Google Scholar] [CrossRef]
- Bian, X.; Chen, C.; Xu, Y.; Du, Q. Robust Hyperspectral Image Classification by Multi-Layer Spatial–Spectral Sparse Representations. Remote Sens. 2016, 8, 985. [Google Scholar] [CrossRef]
- Chen, C.; Chen, N.; Peng, J. Nearest Regularized Joint Sparse Representation for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2016, 13, 424–428. [Google Scholar] [CrossRef]
- Wang, Z.; Nasrabadi, N.M.; Huang, T.S. Spatial–spectral classification of hyperspectral images using discriminative dictionary designed by learning vector quantization. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4808–4822. [Google Scholar] [CrossRef]
- Wang, Z.; Nasrabadi, N.M.; Huang, T.S. Semisupervised hyperspectral classification using task-driven dictionary learning with Laplacian regularization. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1161–1173. [Google Scholar] [CrossRef]
- Fang, L.; Li, S.; Kang, X.; Benediktsson, J.A. Spectral–spatial classification of hyperspectral images with a superpixel-based discriminative sparse model. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4186–4201. [Google Scholar] [CrossRef]
- Soltani-Farani, A.; Rabiee, H.R.; Hosseini, S.A. Spatial-aware dictionary learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 527–541. [Google Scholar] [CrossRef]
- Sun, X.; Nasrabadi, N.M.; Tran, T.D. Task-driven dictionary learning for hyperspectral image classification with structured sparsity constraints. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4457–4471. [Google Scholar] [CrossRef]
- Zhang, H.; Zhai, H.; Zhang, L.; Li, P. Spectral-Spatial Sparse Subspace Clustering for Hyperspectral Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3672–3684. [Google Scholar] [CrossRef]
- He, W.; Zhang, H.; Zhang, L. Sparsity-regularized robust non-negative matrix factorization for hyperspectral unmixing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4267–4279. [Google Scholar] [CrossRef]
- He, W.; Zhang, H.; Zhang, L.; Shen, H. Total-variation-regularized low-rank matrix factorization for hyperspectral image restoration. IEEE Trans. Geosci. Remote Sens. 2016, 54, 178–188. [Google Scholar] [CrossRef]
- Zhang, H.; He, W.; Zhang, L.; Shen, H.; Yuan, Q. Hyperspectral image restoration using low-rank matrix recovery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4729–4743. [Google Scholar] [CrossRef]
- Aggarwal, H.; Majumdar, A. Hyperspectral unmixing in the presence of mixed noise using joint-sparsity and total variation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4257–4266. [Google Scholar] [CrossRef]
- Giannakis, G.B.; Mateos, G.; Farahmand, S.; Kekatos, V.; Zhu, H. USPACOR: Universal sparsity-controlling outlier rejection. In Proceedings of the IEEE Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 1952–1955. [Google Scholar]
- Huang, S.; Zhang, H.; Liao, W.; Pizurica, A. Robust joint sparsity model for hyperspectral image classification. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar]
- Tropp, J.A.; Gilbert, A.C. Signal recovery from random measurements via orthogonal matching pursuit. IEEE Trans. Inf. Theory 2007, 53, 4655–4666. [Google Scholar] [CrossRef]
- Tropp, J.A.; Gilbert, A.C.; Strauss, M.J. Algorithms for simultaneous sparse approximation. Part I: Greedy pursuit. Signal Process. 2006, 86, 572–588. [Google Scholar] [CrossRef]
- Liu, M.; Tuzel, O.; Ramalingam, S.; Chellappa, R. Entropy rate superpixel segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 2097–2104. [Google Scholar]
- Pham, D.; Venkatesh, S. Joint learning and dictionary construction for pattern recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Bruzzone, L.; Chi, M.; Marconcini, M. A novel transductive SVM for semisupervised classification of remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2006, 44, 3363–3373. [Google Scholar] [CrossRef]
- Yuan, Q.; Zhang, L.; Shen, H. Hyperspectral image denoising employing a spectral–spatial adaptive total variation model. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3660–3677. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Class Name | Train | Test | SVM | SRC | R-SRC | JSRC | R-JSRC | NLW-JSRC | SJSRC | R-SJSRC |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Roof | 146 | 2770 | 0.7466 | 0.5842 | 0.5873 | 0.7727 | 0.7918 | 0.7790 | 0.7897 | 0.7962 |
| 2 | Road | 91 | 1728 | 0.6742 | 0.4100 | 0.4197 | 0.5219 | 0.5374 | 0.5204 | 0.5122 | 0.5425 |
| 3 | Trail | 64 | 1200 | 0.7585 | 0.6900 | 0.7070 | 0.7417 | 0.7540 | 0.7543 | 0.9110 | 0.9099 |
| 4 | Grass | 90 | 1700 | 0.8726 | 0.7536 | 0.7712 | 0.9463 | 0.9496 | 0.9468 | 0.9801 | 0.9834 |
| 5 | Shadow | 56 | 1064 | 0.7087 | 0.4234 | 0.4487 | 0.5778 | 0.5738 | 0.5617 | 0.8237 | 0.8273 |
| 6 | Tree | 65 | 1216 | 0.7970 | 0.4792 | 0.5042 | 0.5954 | 0.6038 | 0.5881 | 0.6846 | 0.7160 |
| OA | |||||||||||
| AA | |||||||||||
| No. | Class Name | Train | Test |
|---|---|---|---|
| 1 | Alfalfa | 6 | 40 |
| 2 | Corn-notill | 129 | 1299 |
| 3 | Corn-mintill | 83 | 747 |
| 4 | Corn | 24 | 213 |
| 5 | Grass-pasture | 48 | 435 |
| 6 | Grass-trees | 73 | 657 |
| 7 | Grass-pasture-mowed | 5 | 23 |
| 8 | Hay-windrowed | 48 | 430 |
| 9 | Oats | 4 | 16 |
| 10 | Soybean-notill | 97 | 875 |
| 11 | Soybean-mintill | 196 | 2259 |
| 12 | Soybean-clean | 59 | 534 |
| 13 | Wheat | 21 | 184 |
| 14 | Woods | 114 | 1151 |
| 15 | Bldgs-grass-trees-drives | 39 | 347 |
| 16 | Stone-steel-towers | 12 | 81 |
| Total | 958 | 9291 |
| Class | SVM | SRC | R-SRC | JSRC [20] | R-JSRC | NLW-JSRC [21] | SJSRC | R-SJSRC |
|---|---|---|---|---|---|---|---|---|
| 1 | 0.6275 | 0.4125 | 0.5075 | 0.5625 | 0.6350 | 0.5950 | 0.9800 | 0.9800 |
| 2 | 0.7807 | 0.6122 | 0.6546 | 0.8570 | 0.8780 | 0,8917 | 0.9799 | 0.9427 |
| 3 | 0.7106 | 0.5396 | 0.5750 | 0.8371 | 0.8541 | 0,8617 | 0.9601 | 0.9426 |
| 4 | 0.5362 | 0.3286 | 0.3770 | 0.6892 | 0.7469 | 0,7113 | 0.9920 | 0.8441 |
| 5 | 0.8968 | 0.8478 | 0.8678 | 0.9159 | 0.9292 | 0,9366 | 0.9172 | 0.9163 |
| 6 | 0.9534 | 0.9307 | 0.9470 | 0.9962 | 0.9970 | 0,9976 | 1.0000 | 0.9976 |
| 7 | 0.8130 | 0.7565 | 0.8261 | 0.6304 | 0.6652 | 0,6783 | 0.9696 | 0.9696 |
| 8 | 0.9584 | 0.9170 | 0.9598 | 0.9988 | 0.9993 | 0,9995 | 0.9977 | 0.9977 |
| 9 | 0.5813 | 0.5125 | 0.5813 | 0.4125 | 0.4750 | 0,6625 | 1.0000 | 0.8000 |
| 10 | 0.7506 | 0.6103 | 0.6466 | 0.8312 | 0.8519 | 0,8665 | 0.8574 | 0.9271 |
| 11 | 0.8053 | 0.7000 | 0.7291 | 0.8726 | 0.8977 | 0,9137 | 0.9099 | 0.9508 |
| 12 | 0.7315 | 0.5075 | 0.5772 | 0.8384 | 0.8936 | 0,9026 | 0.9296 | 0.9700 |
| 13 | 0.9544 | 0.9538 | 0.9668 | 0.9967 | 0.9967 | 0,9967 | 0.9951 | 0.9951 |
| 14 | 0.9308 | 0.9056 | 0.9145 | 0.9791 | 0.9815 | 0,9856 | 0.9569 | 0.9818 |
| 15 | 0.5545 | 0.4596 | 0.4937 | 0.7960 | 0.8499 | 0,8369 | 0.8939 | 0.9677 |
| 16 | 0.9346 | 0.8531 | 0.8605 | 0.9840 | 0.9852 | 0,9938 | 0.9790 | 0.9679 |
| OA | ||||||||
| AA | ||||||||
| Class | Class Name | Train | Test | SVM | SRC | R-SRC | JSRC | R-JSRC | NLW-JSRC | SJSRC | R-SJSRC |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Trees | 30 | 3093 | 0.9251 | 0.9230 | 0.9269 | 0.9817 | 0.9856 | 0.9812 | 0.9691 | 0.9737 |
| 2 | Concrete | 30 | 1380 | 0.9696 | 0.9787 | 0.9874 | 0.9978 | 0.9990 | 0.9977 | 1 | 0.9999 |
| 3 | Soil | 30 | 607 | 0.8638 | 0.8359 | 0.8624 | 0.7685 | 0.8891 | 0.7802 | 0.8611 | 0.9432 |
| 4 | Grass | 30 | 4014 | 0.9055 | 0.8984 | 0.9208 | 0.9421 | 0.9590 | 0.9426 | 0.9915 | 0.9863 |
| 5 | Asphalt | 30 | 882 | 0.7832 | 0.7953 | 0.8194 | 0.9117 | 0.9179 | 0.9027 | 0.9621 | 0.9711 |
| OA | |||||||||||
| AA | |||||||||||
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, S.; Zhang, H.; Pižurica, A. A Robust Sparse Representation Model for Hyperspectral Image Classification. Sensors 2017, 17, 2087. https://doi.org/10.3390/s17092087
Huang S, Zhang H, Pižurica A. A Robust Sparse Representation Model for Hyperspectral Image Classification. Sensors. 2017; 17(9):2087. https://doi.org/10.3390/s17092087
Chicago/Turabian StyleHuang, Shaoguang, Hongyan Zhang, and Aleksandra Pižurica. 2017. "A Robust Sparse Representation Model for Hyperspectral Image Classification" Sensors 17, no. 9: 2087. https://doi.org/10.3390/s17092087
APA StyleHuang, S., Zhang, H., & Pižurica, A. (2017). A Robust Sparse Representation Model for Hyperspectral Image Classification. Sensors, 17(9), 2087. https://doi.org/10.3390/s17092087