A Sparse Dictionary Learning-Based Adaptive Patch Inpainting Method for Thick Clouds Removal from High-Spatial Resolution Remote Sensing Imagery




Abstract
:1. Introduction
2. Preliminaries
2.1. Exemplar-Based Image Inpainting
2.2. Sparse Dictionary Learning
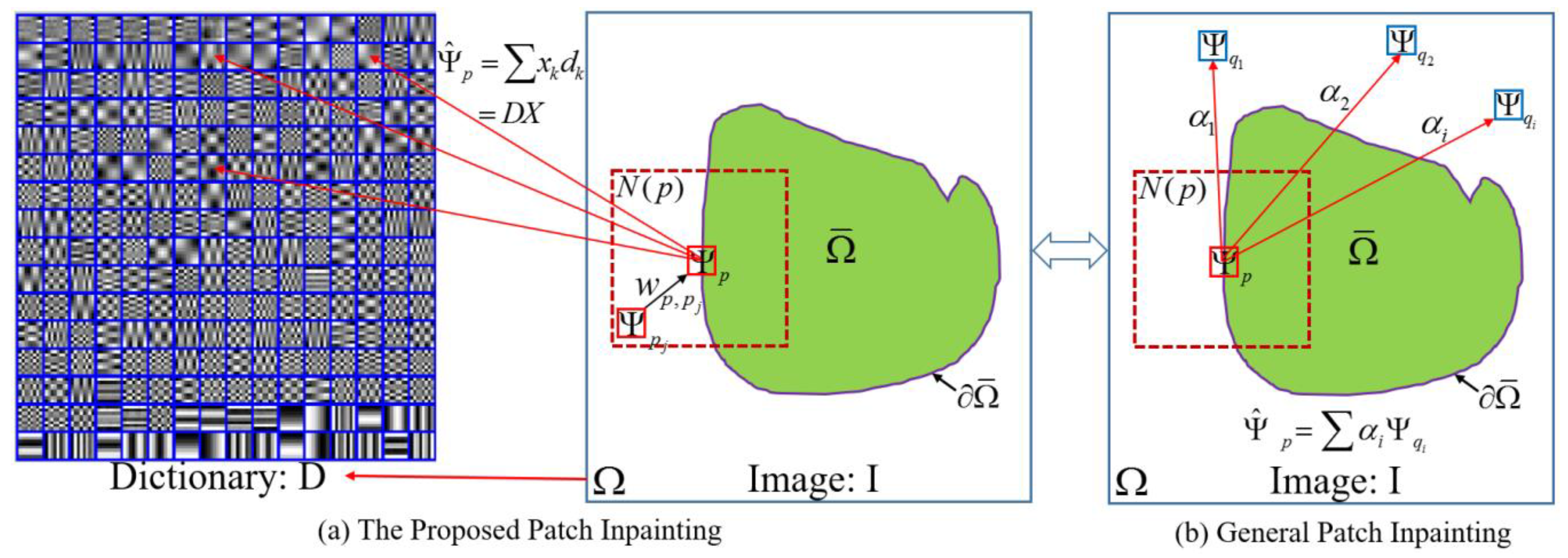
3. Methodology
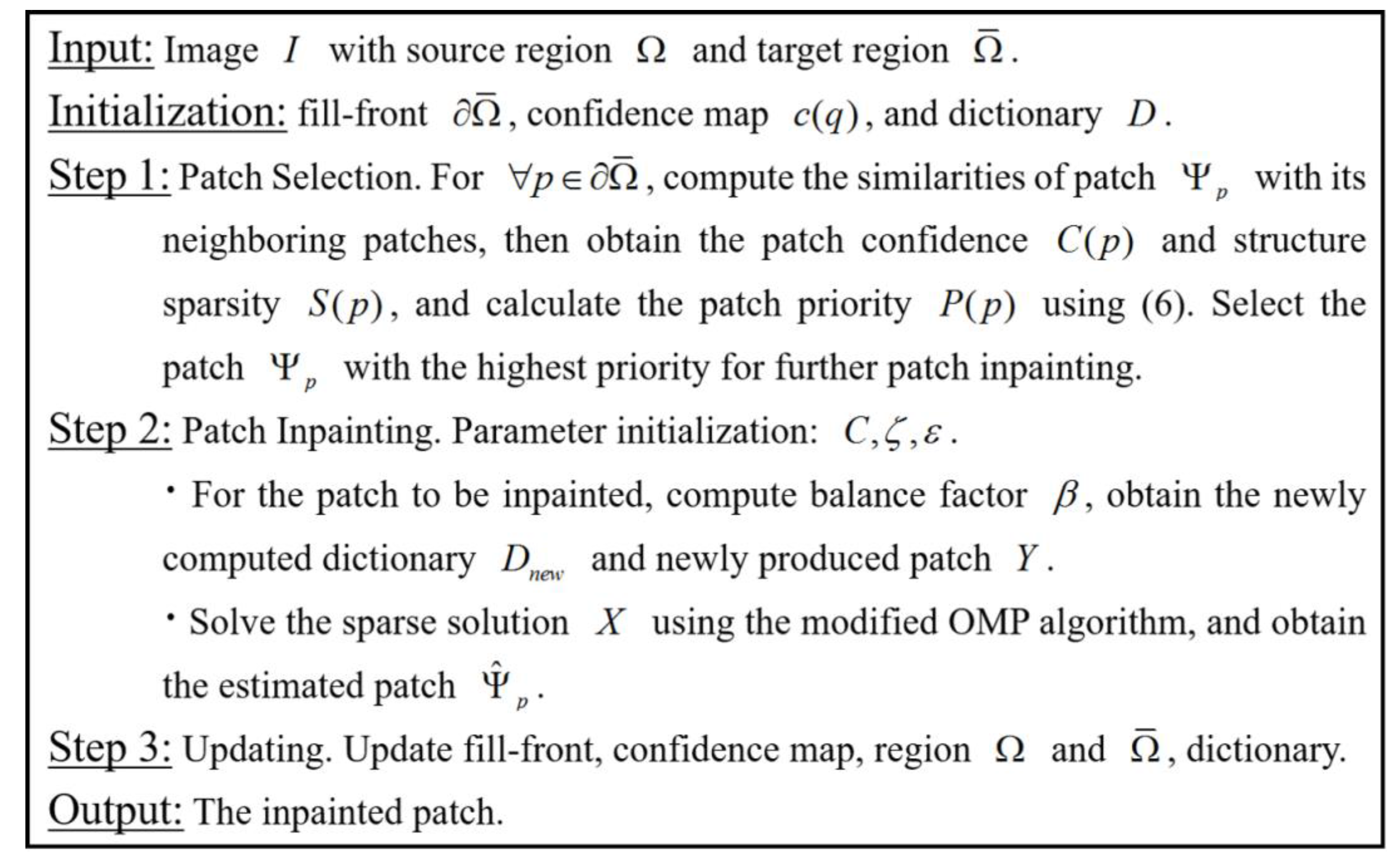
3.1. Adaptive Patch Inpainting Model and Algorithm
3.1.1. Patch Priority
3.1.2. The Optimization Model for Patch Inpainting
3.1.3. Modified OMP and the Inpainting Algorithm
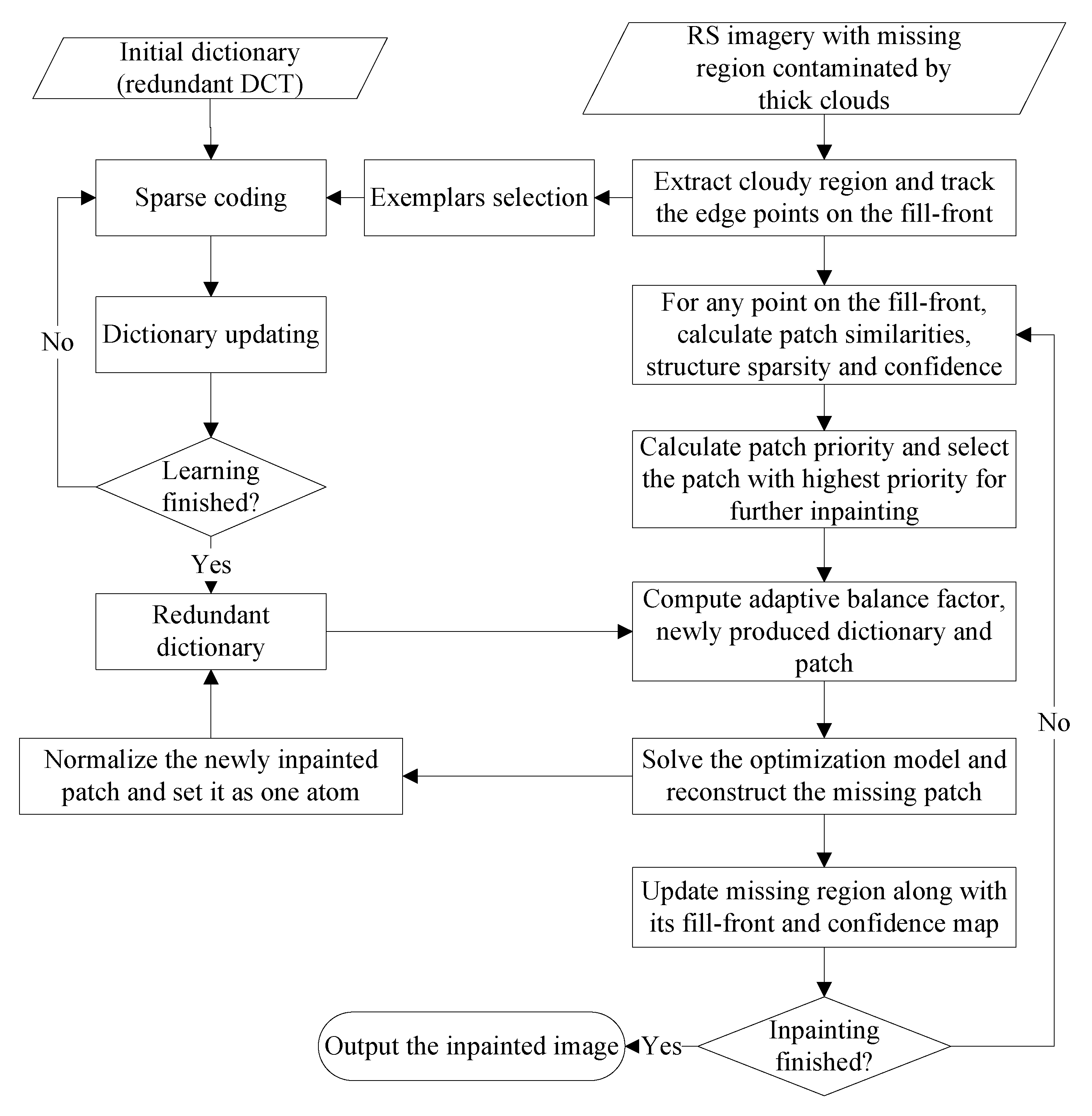
3.2. Thick Clouds Removal Scheme for RS Imagery
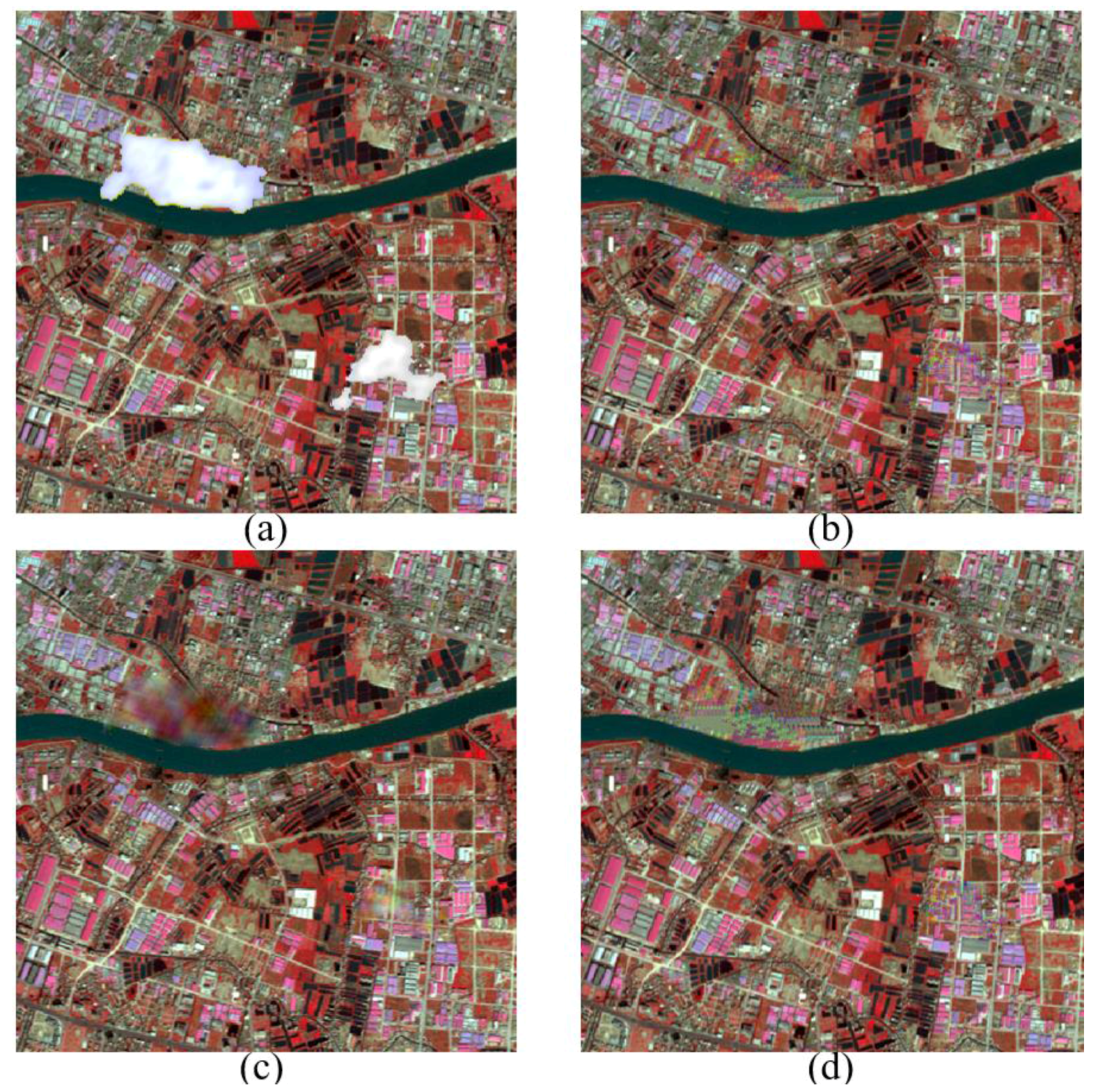
4. Experiments and Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bertalmio, M.; Sapiro, G.; Caselles, V.; Ballester, C. Image inpainting. In Proceedings of the 27th International Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 23–28 July 2000; pp. 417–424. [Google Scholar]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Han, Y.; Kim, B.; Kim, Y.; Lee, W.H. Automatic cloud detection for high spatial resolution multi-temporal images. Remote Sens. Lett. 2014, 5, 601–608. [Google Scholar] [CrossRef]
- Li, Z.; Shen, H.; Li, H.; Xia, G.; Gamba, P.; Zhang, L. Multi-feature combined cloud and cloud shadow detection in GaoFen-1 wide field of view imagery. Remote Sens. Environ. 2017, 191, 342–358. [Google Scholar] [CrossRef]
- Shao, Z.; Deng, J.; Wang, L.; Fan, Y.; Sumari, N.S.; Cheng, Q. Fuzzy autoencode based cloud detection for remote sensing imagery. Remote Sens. 2017, 9, 311. [Google Scholar] [CrossRef]
- Lin, C.-H.; Tsai, P.-H.; Lai, K.-H.; Chen, J.-Y. Cloud removal from multitemporal satellite images using information cloning. IEEE Trans. Geosci. Remote Sens. 2013, 51, 232–241. [Google Scholar] [CrossRef]
- Lin, C.-H.; Lai, K.-H.; Chen, Z.-B.; Chen, J.-Y. Patch-based information reconstruction of cloud-contaminated multitemporal images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 163–174. [Google Scholar] [CrossRef]
- Li, X.; Shen, H.; Zhang, L.; Li, H. Sparse-based reconstruction of missing information in remote sensing images from spectral/temporal complementary information. ISPRS J. Photogramm. Remote Sens. 2015, 106, 1–15. [Google Scholar] [CrossRef]
- Shen, H.; Zeng, C.; Zhang, L. Recovering reflectance of AQUA MODIS band 6 based on with-in class local fitting. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 185–192. [Google Scholar] [CrossRef]
- Gladkova, I.; Grossberg, M.D.; Shahriar, F.; Bonev, G.; Romanov, P. Quantitative restoration for MODIS band 6 on Aqua. IEEE Trans. Geosci. Remote Sens. 2012, 50, 2409–2416. [Google Scholar] [CrossRef]
- Li, H.; Zhang, L.; Shen, H.; Li, P. A variational gradient-based fusion method for visible and SWIR imagery. Photogramm. Eng. Remote Sens. 2012, 78, 947–958. [Google Scholar] [CrossRef]
- Shen, H.; Li, X.; Zhang, L.; Tao, D.; Zeng, C. Compressed sensing-based inpainting of Aqua moderate resolution imaging spectroradiometer band 6 using adaptive spectrum-weighted sparse Bayesian dictionary learning. IEEE Trans. Geosci. Remote Sens. 2014, 52, 894–906. [Google Scholar] [CrossRef]
- Tseng, D.-C.; Tseng, H.-T.; Chien, C.-H. Automatic cloud removal from multi-temporal SPOT images. Appl. Math. Comput. 2008, 205, 584–600. [Google Scholar] [CrossRef]
- Cheng, Q.; Shen, H.; Zhang, L.; Yuan, Q.; Zeng, C. Cloud removal for remotely sensed images by similar pixel replacement guided with a spatio-temporal MRF model. ISPRS J. Photogramm. Remote Sens. 2014, 92, 54–68. [Google Scholar] [CrossRef]
- Zeng, C.; Shen, H.; Zhong, M.; Zhang, L.; Wu, P. Reconstructing MODIS LST based on multitemporal classification and robust regression. IEEE Geosci. Remote Sens. Lett. 2015, 12, 512–516. [Google Scholar] [CrossRef]
- Zhu, X.; Gao, F.; Liu, D.; Chen, J. A modified neighborhood similar pixel interpolator approach for removing thick clouds in Landsat images. IEEE Geosci. Remote Sens. Lett. 2012, 9, 521–525. [Google Scholar] [CrossRef]
- Li, X.; Shen, H.; Zhang, L.; Zhang, H.; Yuan, Q.; Yang, G. Recovering quantitative remote sensing products contaminated by thick clouds and shadows using multitemporal dictionary learning. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7086–7098. [Google Scholar]
- Lorenzi, L.; Melgani, F.; Mercier, G. Missing-area reconstruction in multispectral images under a compressive sensing perspective. IEEE Trans. Geosci. Remote Sens. 2013, 51, 3998–4008. [Google Scholar] [CrossRef]
- Huang, B.; Li, Y.; Han, X.; Cui, Y.; Li, W.; Li, R. Cloud removal from optical satellite imagery with SAR imagery using sparse representation. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1046–1050. [Google Scholar] [CrossRef]
- Xu, M.; Jia, X.; Pickering, M.; Plaza, A.J. Cloud removal based on sparse representation via multitemporal dictionary learning. IEEE Trans. Geosci. Remote Sens. 2016, 54, 2998–3006. [Google Scholar] [CrossRef]
- Maalouf, A.; Carré, P.; Augereau, B.; Fernandez-Maloigne, C. A bandelet-based inpainting technique for clouds removal from remotely sensed images. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2363–2371. [Google Scholar] [CrossRef]
- Bertalmio, M. Strong-continuation, contrast-invariant inpainting with a third-order optimal PDE. IEEE Trans. Image Process. 2006, 15, 1934–1938. [Google Scholar] [CrossRef] [PubMed]
- Chan, T.F.; Yip, A.M.; Park, F.E. Simultaneous total variation image inpainting and blind deconvolution. Int. J. Imaging Syst. Technol. 2005, 15, 92–102. [Google Scholar] [CrossRef]
- Criminisi, A.; Perez, P.; Toyama, K. Region filling and object removal by exemplar-based image inpainting. IEEE Trans. Image Process. 2004, 13, 1200–1212. [Google Scholar] [CrossRef] [PubMed]
- Wong, A.; Orchard, J. A nonlocal-means approach to exemplar-based inpainting. In Proceedings of the 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 2600–2603. [Google Scholar]
- Xu, Z.; Sun, J. Image inpainting by patch propagation using patch sparsity. IEEE Trans. Image Process. 2010, 19, 1153–1165. [Google Scholar] [PubMed]
- Elad, M.; Starck, J.L.; Querre, P.; Donoho, D.L. Simultaneous cartoon and texture image inpainting using morphological component analysis (MCA). Appl. Comput. Harmon. Anal. 2005, 19, 340–358. [Google Scholar] [CrossRef]
- Fadili, M.J.; Starck, J.L.; Murtagh, F. Inpainting and zooming using sparse representations. Comput. J. 2009, 52, 64–79. [Google Scholar] [CrossRef]
- Hu, H.; Wohlberg, B.; Chartrand, R. Task-driven dictionary learning for inpainting. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 3543–3547. [Google Scholar]
- Mairal, J.; Elad, M.; Sapiro, G. Sparse representation for color image restoration. IEEE Trans. Image Process. 2008, 17, 53–69. [Google Scholar] [CrossRef] [PubMed]
- Mairal, J.; Sapiro, G.; Elad, M. Learning multiscale sparse representations for image and video restoration. Multiscale Model. Simul. 2008, 7, 214–241. [Google Scholar] [CrossRef]
- Shen, H.; Zhang, L. A MAP-based algorithm for destriping and inpainting of remotely sensed images. IEEE Trans. Geosci. Remote Sens. 2009, 47, 1492–1502. [Google Scholar] [CrossRef]
- Lorenzi, L.; Melgani, F.; Mercier, G. Inpainting strategies for reconstruction of missing data in VHR images. IEEE Geosci. Remote Sens. Lett. 2011, 8, 914–918. [Google Scholar] [CrossRef]
- Cheng, Q.; Shen, H.; Zhang, L.; Li, P. Inpainting for remotely sensed images with a multichannel nonlocal total variation model. IEEE Trans. Geosci. Remote Sens. 2014, 52, 175–187. [Google Scholar] [CrossRef]
- Schmidt, U.; Gao, Q.; Roth, S. A generative perspective on mrfs in low-level vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 1751–1758. [Google Scholar]
- Gandy, S.; Recht, B.; Yamada, I. Tensor completion and low-n-rank tensor recovery via convex optimization. Inverse Probl. 2011, 27, 025010. [Google Scholar] [CrossRef]
- Liu, J.; Musialski, P.; Wonka, P.; Ye, J. Tensor completion for estimating missing values in visual data. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 208–220. [Google Scholar] [CrossRef] [PubMed]
- Guillemot, C.; Le Meur, O. Image inpainting: Overview and recent advances. IEEE Signal Process. Mag. 2014, 31, 127–144. [Google Scholar] [CrossRef]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, B. Discriminative K-SVD for dictionary learning in face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2691–2698. [Google Scholar]
- Lu, C.; Shi, J.; Jia, J. Online robust dictionary learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 415–422. [Google Scholar]
- Lu, C.; Shi, J.; Jia, J. Scale adaptive dictionary learning. IEEE Trans. Image Process. 2014, 23, 837–847. [Google Scholar] [CrossRef] [PubMed]
- Tropp, J.A. Greed is good: Algorithmic results for sparse approximation. IEEE Trans. Inf. Theory 2004, 50, 2231–2242. [Google Scholar] [CrossRef]
- Chen, S.S.; Donoho, D.L.; Saunders, M.A. Atomic decomposition by basis pursuit. SIAM Rev. 2001, 43, 129–159. [Google Scholar] [CrossRef]
- Gorodnitsky, I.F.; Rao, B.D. Sparse signal reconstruction from limited data using FOCUSS: A re-weighted norm minimization algorithm. IEEE Trans. Signal Process. 1997, 45, 600–616. [Google Scholar] [CrossRef]
- Fadili, J.M.; Starck, J.L.; Elad, M.; Donoho, D. MCALab: Reproducible research in signal and image decomposition and inpainting. IEEE Comput. Sci. Eng. 2010, 12, 44–63. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Barbara Image | Texture Synthesis | Result of [24] | Result of MRF | Result of MCA | Result of Ours |
|---|---|---|---|---|---|
| PSNR(DB) | 16.836 | 19.942 | 19.887 | 23.348 | 24.408 |
| SSIM | 0.805 | 0.898 | 0.897 | 0.954 | 0.966 |
| Images | Statistical Indices | Texture Synthesis | [24] | MRF | MCA | [26] | 8 × 8 pixels Patch | 16 × 16 pixels Patch |
|---|---|---|---|---|---|---|---|---|
| Aerial | PSNR(dB) | 13.663 | - | 10.488 | 13.599 | 13.082 | 13.833 | 15.281 |
| SSIM | 0.632 | - | 0.325 | 0.682 | 0.546 | 0.657 | 0.752 | |
| SPOT5 | PSNR(dB) | - | 17.576 | 17.792 | 18.092 | - | - | 18.883 |
| SSIM | - | 0.814 | 0.801 | 0.818 | - | - | 0.868 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, F.; Yang, X.; Zhou, C.; Li, Z. A Sparse Dictionary Learning-Based Adaptive Patch Inpainting Method for Thick Clouds Removal from High-Spatial Resolution Remote Sensing Imagery. Sensors 2017, 17, 2130. https://doi.org/10.3390/s17092130
Meng F, Yang X, Zhou C, Li Z. A Sparse Dictionary Learning-Based Adaptive Patch Inpainting Method for Thick Clouds Removal from High-Spatial Resolution Remote Sensing Imagery. Sensors. 2017; 17(9):2130. https://doi.org/10.3390/s17092130
Chicago/Turabian StyleMeng, Fan, Xiaomei Yang, Chenghu Zhou, and Zhi Li. 2017. "A Sparse Dictionary Learning-Based Adaptive Patch Inpainting Method for Thick Clouds Removal from High-Spatial Resolution Remote Sensing Imagery" Sensors 17, no. 9: 2130. https://doi.org/10.3390/s17092130
APA StyleMeng, F., Yang, X., Zhou, C., & Li, Z. (2017). A Sparse Dictionary Learning-Based Adaptive Patch Inpainting Method for Thick Clouds Removal from High-Spatial Resolution Remote Sensing Imagery. Sensors, 17(9), 2130. https://doi.org/10.3390/s17092130