Organ Segmentation in Poultry Viscera Using RGB-D

 and
and 
Abstract
:1. Introduction
Contributions
2. Related Work
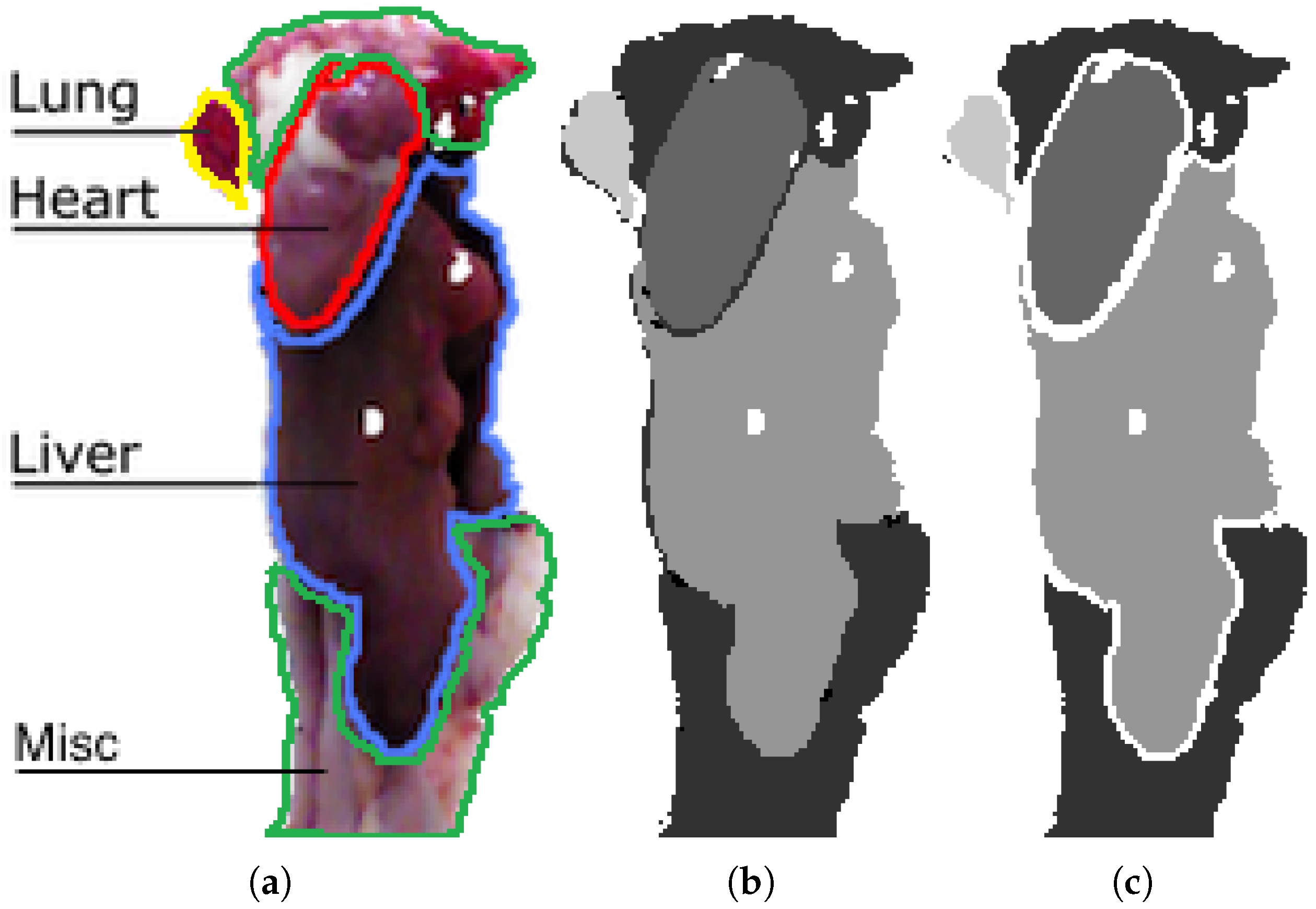
3. Chicken Viscera Dataset
Ground-Truth Annotations
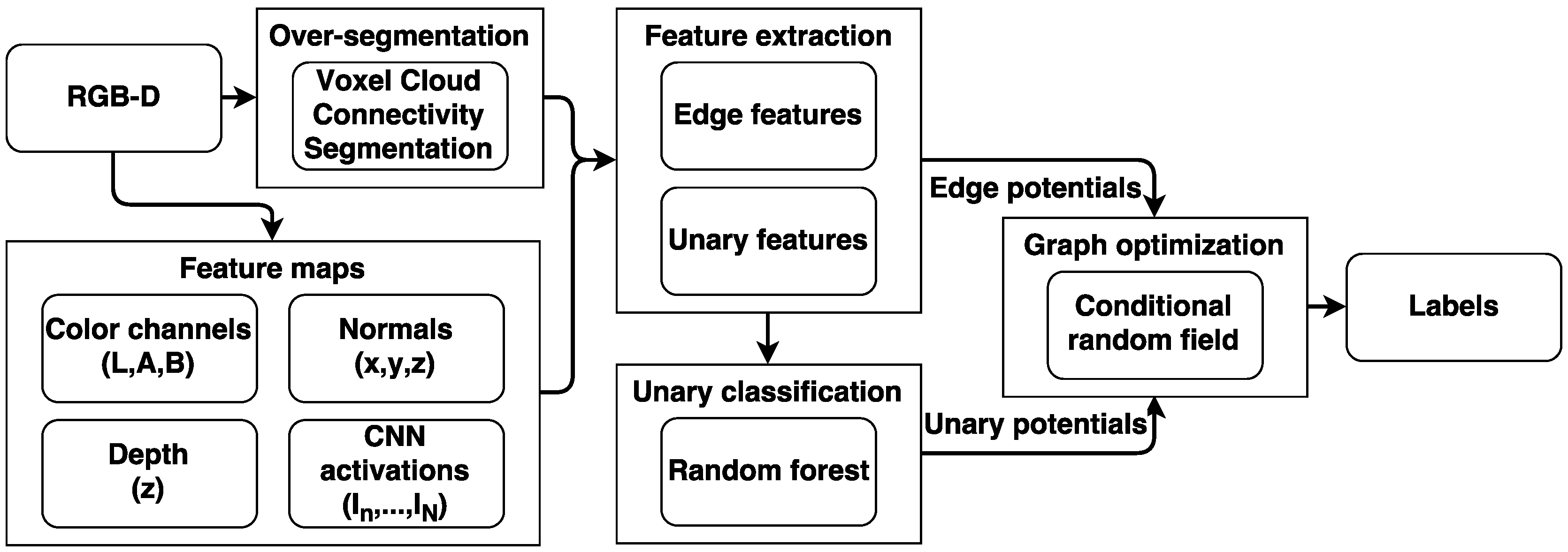
4. Segmentation Approach
4.1. Oversegmentation
4.2. Feature Maps
4.3. Feature Extraction
4.4. Unary Classification
4.5. Graph Optimization
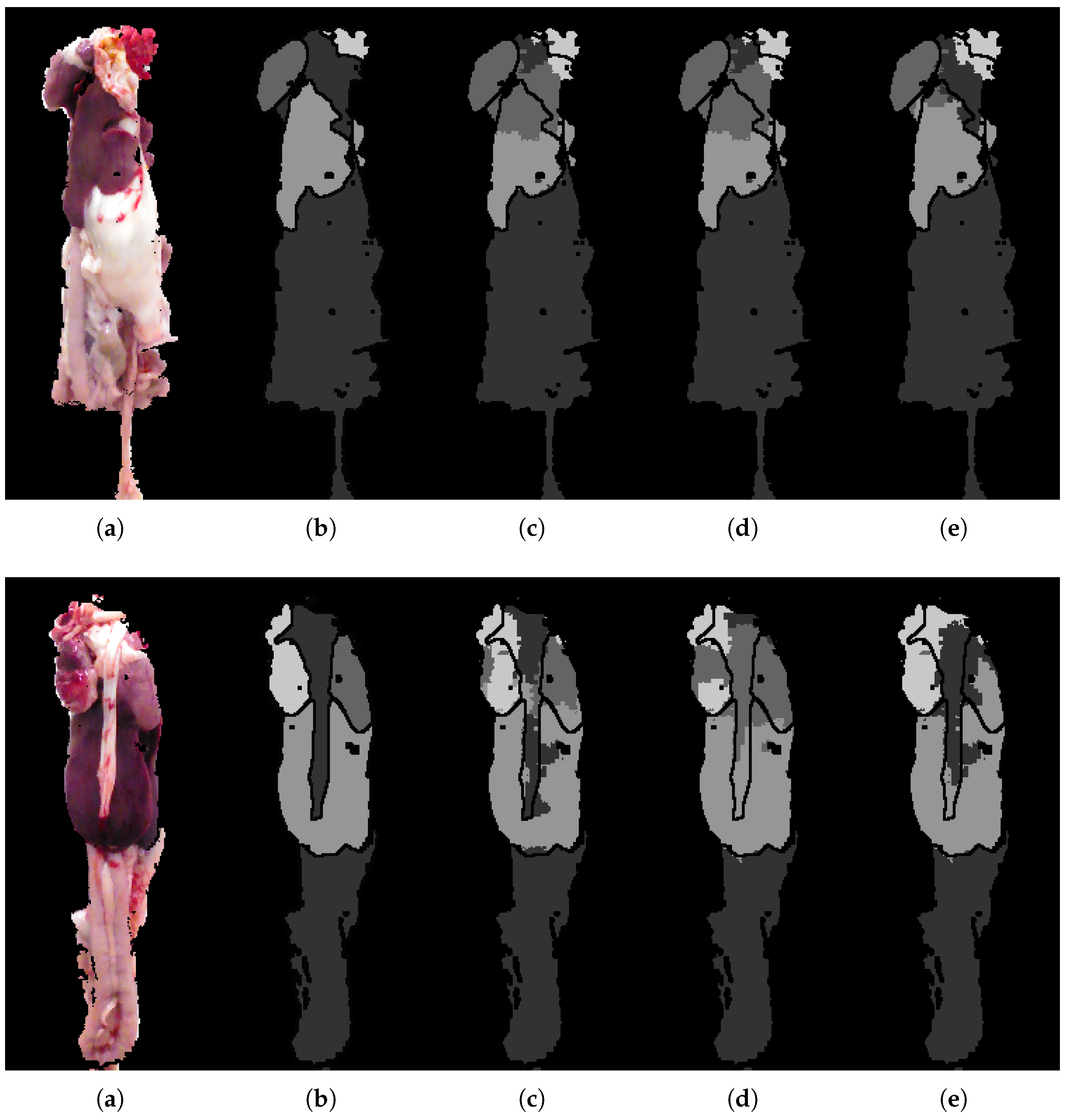
5. Evaluation
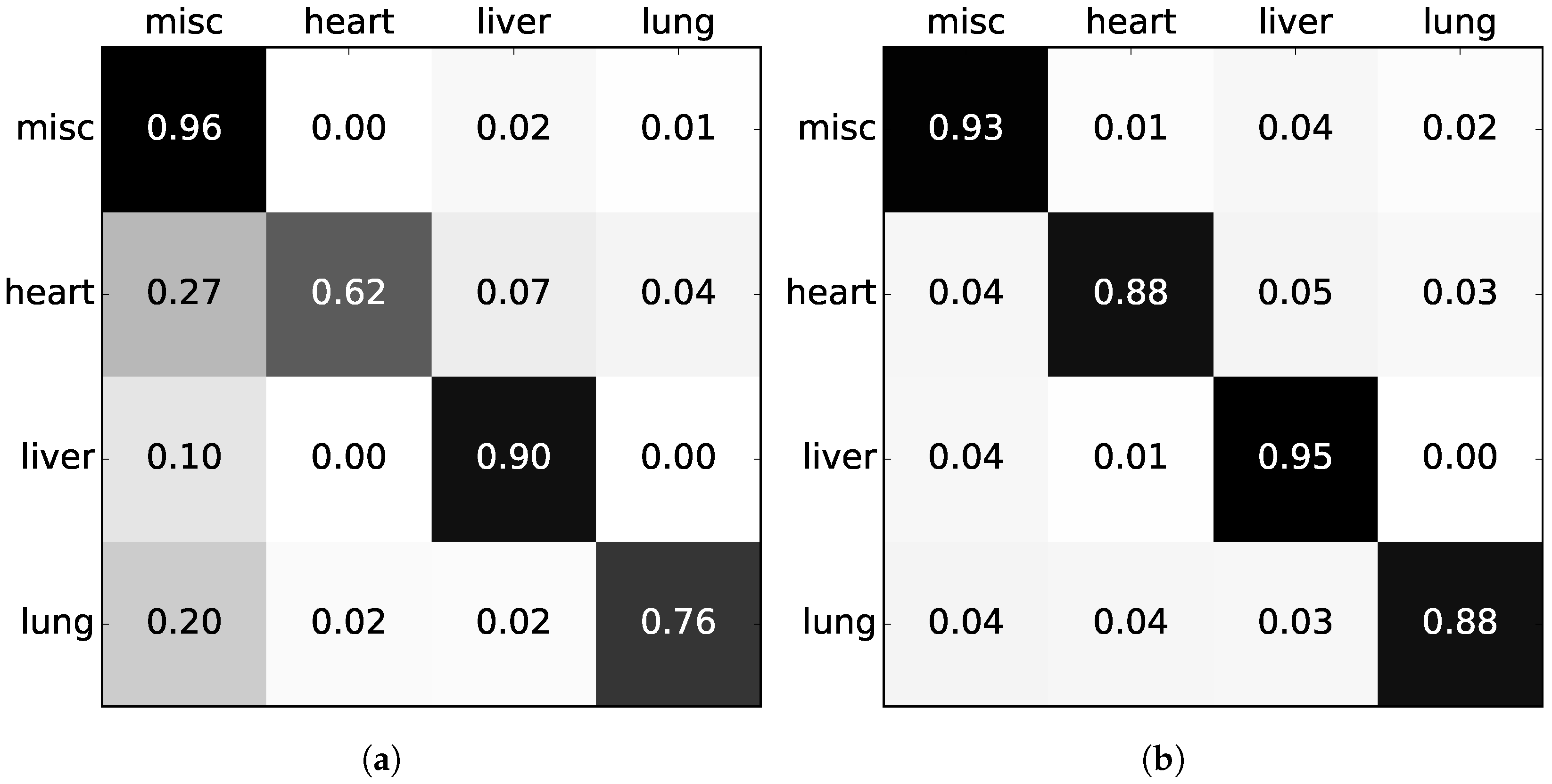
5.1. Quantitative Analysis
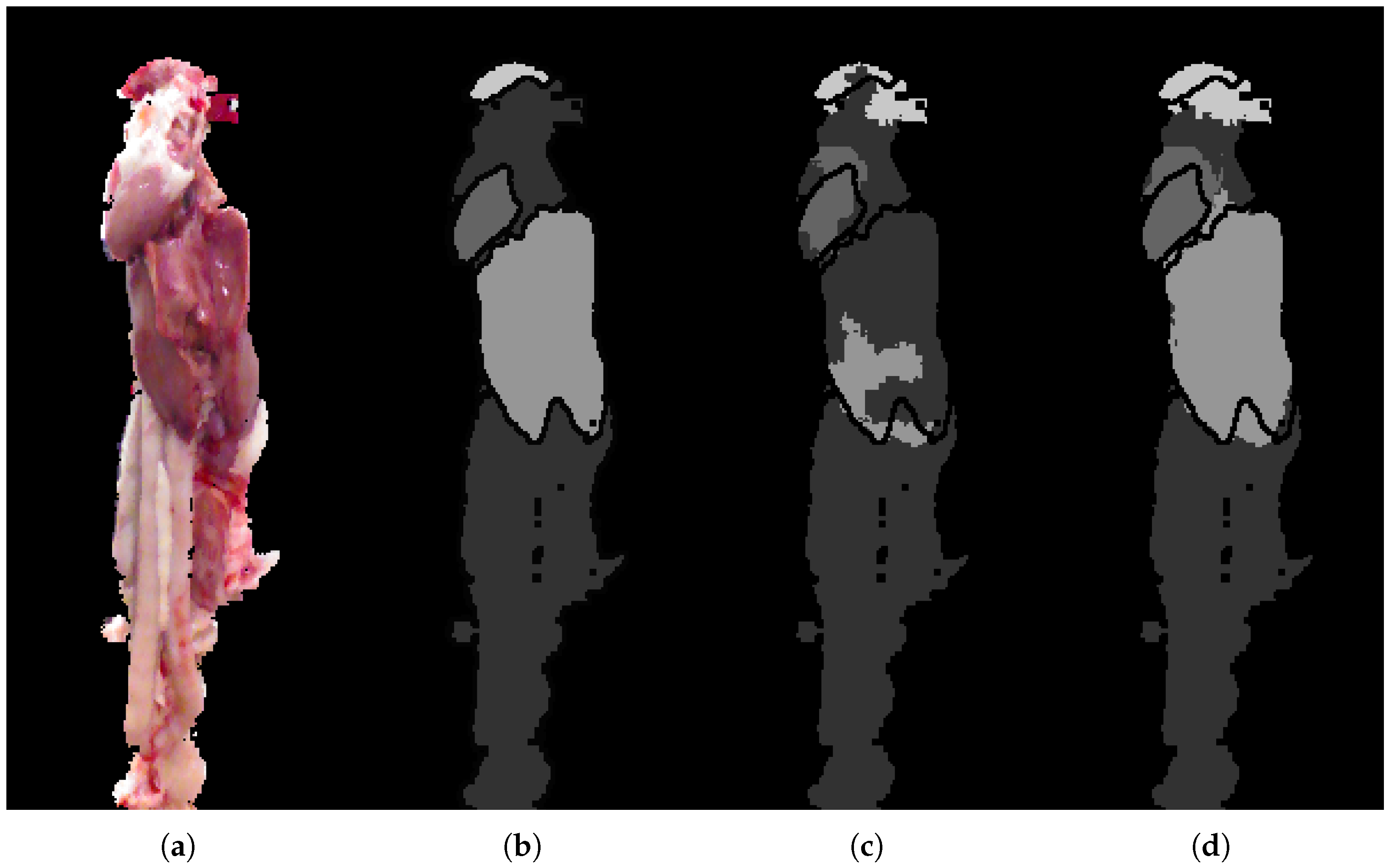
5.2. Analytic Results
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Sun, D.W. Computer Vision Technology for Food Quality Evaluation; Academic Press: Cambridge, MA, USA, 2016. [Google Scholar]
- United States Department of Agriculture (USDA). Poultry Statistics. Available online: https://www.ers.usda.gov/topics/animal-products/poultry-eggs/statistics-information.aspx (accessed on 30 November 2016).
- Chao, K.; Yang, C.; Chen, Y.; Kim, M.; Chan, D. Hyperspectral-multispectral line-scan imaging system for automated poultry carcass inspection applications for food safety. Poult. Sci. 2007, 86, 2450–2460. [Google Scholar] [CrossRef] [PubMed]
- Park, B.; Lawrence, K.C.; Windham, W.R.; Smith, D.P. Multispectral imaging system for fecal and ingesta detection on poultry carcasses. J. Food Process Eng. 2004, 27, 311–327. [Google Scholar] [CrossRef]
- Food, I. ClassifEYE-Inspection, Grading and Quality Assurance. Available online: http://www.ihfood.dk/poultry2111 (accessed on 2 December 2016).
- Chao, K.; Chen, Y.R.; Early, H.; Park, B. Color image classification systems for poultry viscera inspection. Appl. Eng. Agric. 1999, 15, 363–369. [Google Scholar] [CrossRef]
- Jørgensen, A.; Fagertun, J.; Moeslund, T.B. Diagnosis of Broiler Livers by Classifying Image Patches. In Proceedings of the Scandinavian Conference on Image Analysis, Tromsø, Norway, 12–14 June 2017; Springer: Berlin, Germany, 2017; pp. 374–385. [Google Scholar]
- Philipsen, M.P.; Jørgensen, A.; Escalera, S.; Moeslund, T.B. RGB-D Segmentation of Poultry Entrails. In Proceedings of the 9th International Conference on Articulated Motion and Deformable Objects, Palma de Mallorca, Spain, 13–15 July 2016; Volume 9756, pp. 168–174. [Google Scholar]
- Chao, K.; Yang, C.C.; Kim, M.S.; Chan, D.E. High throughput spectral imaging system for wholesomeness inspection of chicken. Appl. Eng. Agric. 2008, 24, 475–485. [Google Scholar] [CrossRef]
- Dey, B.P.; Chen, Y.R.; Hsieh, C.; Chan, D.E. Detection of septicemia in chicken livers by spectroscopy. Poult. Sci. 2003, 82, 199–206. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.; Liu, L.; Ngadi, M.O. Recent developments in hyperspectral imaging for assessment of food quality and safety. Sensors 2014, 14, 7248–7276. [Google Scholar] [CrossRef] [PubMed]
- Panagou, E.Z.; Papadopoulou, O.; Carstensen, J.M.; Nychas, G.J.E. Potential of multispectral imaging technology for rapid and non-destructive determination of the microbiological quality of beef filets during aerobic storage. Int. J. Food Microbiol. 2014, 174, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Trinderup, C.H.; Dahl, A.L.; Carstensen, J.M.; Jensen, K.; Conradsen, K. Utilization of multispectral images for meat color measurements. Workshop Farm Anim. Food Qual. Imaging 2013, 2013, 42–48. [Google Scholar]
- Tao, Y.; Shao, J.; Skeeles, K.; Chen, Y.R. Detection of splenomegaly in poultry carcasses by UV and color imaging. Trans. ASAE 2000, 43, 469–474. [Google Scholar] [CrossRef]
- Elmasry, G.; Sun, D.W.; Allen, P. Near-infrared hyperspectral imaging for predicting colour, pH and tenderness of fresh beef. J. Food Eng. 2012, 110, 127–140. [Google Scholar] [CrossRef]
- Jørgensen, A.; Jensen, E.M.; Moeslund, T.B. Detecting Gallbladders in Chicken Livers using Spectral Imaging. In Proceedings of the Machine Vision of Animals and their Behaviour (MVAB), Swansea, UK, 10 September 2015; Amaral, T., Matthews, S., Ploetz, T., McKenna, S., Fisher, R., Eds.; BMVA Press: Durham, UK, 2015. [Google Scholar]
- Amaral, T.; Kyriazakis, I.; Mckenna, S.J.; Ploetz, T. Weighted atlas auto-context with application to multiple organ segmentation. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–9 March 2016. [Google Scholar]
- Lötjönen, J.M.; Wolz, R.; Koikkalainen, J.R.; Thurfjell, L.; Waldemar, G.; Soininen, H.; Rueckert, D.; Alzheimer’s Disease Neuroimaging Initiative. Fast and robust multi-atlas segmentation of brain magnetic resonance images. Neuroimage 2010, 49, 2352–2365. [Google Scholar]
- Wang, H.; Suh, J.W.; Das, S.R.; Pluta, J.B.; Craige, C.; Yushkevich, P.A. Multi-Atlas Segmentation with Joint Label Fusion. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 611–623. [Google Scholar] [CrossRef] [PubMed]
- Criminisi, A.; Robertson, D.; Pauly, O.; Glocker, B.; Konukoglu, E.; Shotton, J.; Mateus, D.; Martinez Möller, A.; Nekolla, S.G.; Navab, N. Anatomy Detection and Localization in 3D Medical Images. In Decision Forests for Computer Vision and Medical Image Analysis; Springer: London, UK, 2013; pp. 193–209. [Google Scholar]
- Sampedro, F.; Escalera, S.; Puig, A. Iterative multi-class multi-scale stacked sequential learning: Definition and application to medical volume segmentation. Pattern Recogn. Lett. 2014, 46, 1–10. [Google Scholar] [CrossRef]
- Silberman, N.; Fergus, R. Indoor Scene Segmentation using a Structured Light Sensor. In Proceedings of the International Conference on Computer Vision, Workshop on 3D Representation and Recognition, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from RGBD images. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 746–760. [Google Scholar]
- Müller, A.C.; Behnke, S. Learning depth-sensitive conditional random fields for semantic segmentation of RGB-D images. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 6232–6237. [Google Scholar]
- Wolf, D.; Prankl, J.; Vincze, M. Fast semantic segmentation of 3D point clouds using a dense CRF with learned parameters. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Washington, DC, USA, 26–30 May 2015; pp. 4867–4873. [Google Scholar]
- Thøgersen, M.; Escalera, S.; Gonzàlez, J.; Moeslund, T.B. Segmentation of RGB-D indoor scenes by stacking random forests and conditional random fields. Pattern Recogn. Lett. 2016, 80, 208–215. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Granada, Spain, 12–15 December 2011; pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. arXiv, 2015; arXiv:1511.00561. [Google Scholar]
- Patterson, G.; Hays, J. SUN attribute database: Discovering, annotating, and recognizing scene attributes. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2751–2758. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. arXiv, 2016; arXiv:1606.00915. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Hypercolumns for object segmentation and fine-grained localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 447–456. [Google Scholar]
- Intel. Intel® RealSense SDK for Windows. Available online: https://software.intel.com/en-us/realsense-sdk-windows-eol (accessed on 30 December 2017).
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2281. [Google Scholar] [CrossRef] [PubMed]
- Papon, J.; Abramov, A.; Schoeler, M.; Wörgötter, F. Voxel Cloud Connectivity Segmentation-Supervoxels for Point Clouds. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2027–2034. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the 18th International Conference on Machine Learning, ICML, Williamstown, MA, USA, 28 June–1 July 2001; Volume 1, pp. 282–289. [Google Scholar]
- Müller, A.C.; Behnke, S. PyStruct-Learning Structured Prediction in Python. J. Mach. Learn. Res. 2014, 15, 2055–2060. [Google Scholar]
- Liu, M.Y.; Tuzel, O.; Ramalingam, S.; Chellappa, R. Entropy Rate Superpixel Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 2097–2104. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Unary Features | Type | 2D | 3D | 3D + CNN |
|---|---|---|---|---|
| LAB | Color | 3 | 3 | 3 |
| Center point | Spatial | 2 | 3 | 3 |
| CNN activation | Texture etc. | 0 | 0 | 4224 |
| Edge Features | Type | 2D | 3D | 3D + CNN |
| LAB | Color | 3 | 3 | 3 |
| Center point | Spatial | 2 | 3 | 3 |
| Normal vector | Geometric | 0 | 3 | 3 |
| Method | Features | Misc. | Heart | Liver | Lung | Class Avg. |
|---|---|---|---|---|---|---|
| RF + CRF | 2D | 90.66 | 57.69 | 80.59 | 68.18 | 74.28 |
| RF + CRF | 3D | 91.28 | 63.02 | 82.38 | 67.43 | 76.03 |
| RF + CRF | 3D + CNN | 91.58 | 70.17 | 83.64 | 67.05 | 78.11 |
| ASA | 96.32 | 88.65 | 88.63 | 82.49 | 89.63 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Philipsen, M.P.; Dueholm, J.V.; Jørgensen, A.; Escalera, S.; Moeslund, T.B. Organ Segmentation in Poultry Viscera Using RGB-D. Sensors 2018, 18, 117. https://doi.org/10.3390/s18010117
Philipsen MP, Dueholm JV, Jørgensen A, Escalera S, Moeslund TB. Organ Segmentation in Poultry Viscera Using RGB-D. Sensors. 2018; 18(1):117. https://doi.org/10.3390/s18010117
Chicago/Turabian StylePhilipsen, Mark Philip, Jacob Velling Dueholm, Anders Jørgensen, Sergio Escalera, and Thomas Baltzer Moeslund. 2018. "Organ Segmentation in Poultry Viscera Using RGB-D" Sensors 18, no. 1: 117. https://doi.org/10.3390/s18010117
APA StylePhilipsen, M. P., Dueholm, J. V., Jørgensen, A., Escalera, S., & Moeslund, T. B. (2018). Organ Segmentation in Poultry Viscera Using RGB-D. Sensors, 18(1), 117. https://doi.org/10.3390/s18010117