Gas Classification Using Deep Convolutional Neural Networks


Abstract
:1. Introduction
- (1)
- We propose a very deep convolutional neural network called GasNet for gas classification. To the best of our knowledge, our work is the first one to exploit a real “deep” learning-based model to recognize gas types.
- (2)
- The proposed CNN contains up to 38 layers. This offers huge advantages over conventional machine learning algorithms (e.g., SVM, KNN, and GMM) and other recently proposed more shallow networks (e.g., RBM and SAE).
- (3)
- Experimental results confirm that GasNet achieves higher classification accuracy than other previous approaches.
2. The Proposed GasNet Tailored for the Gas Classification
2.1. GasNet Overview
2.2. Network Architecture
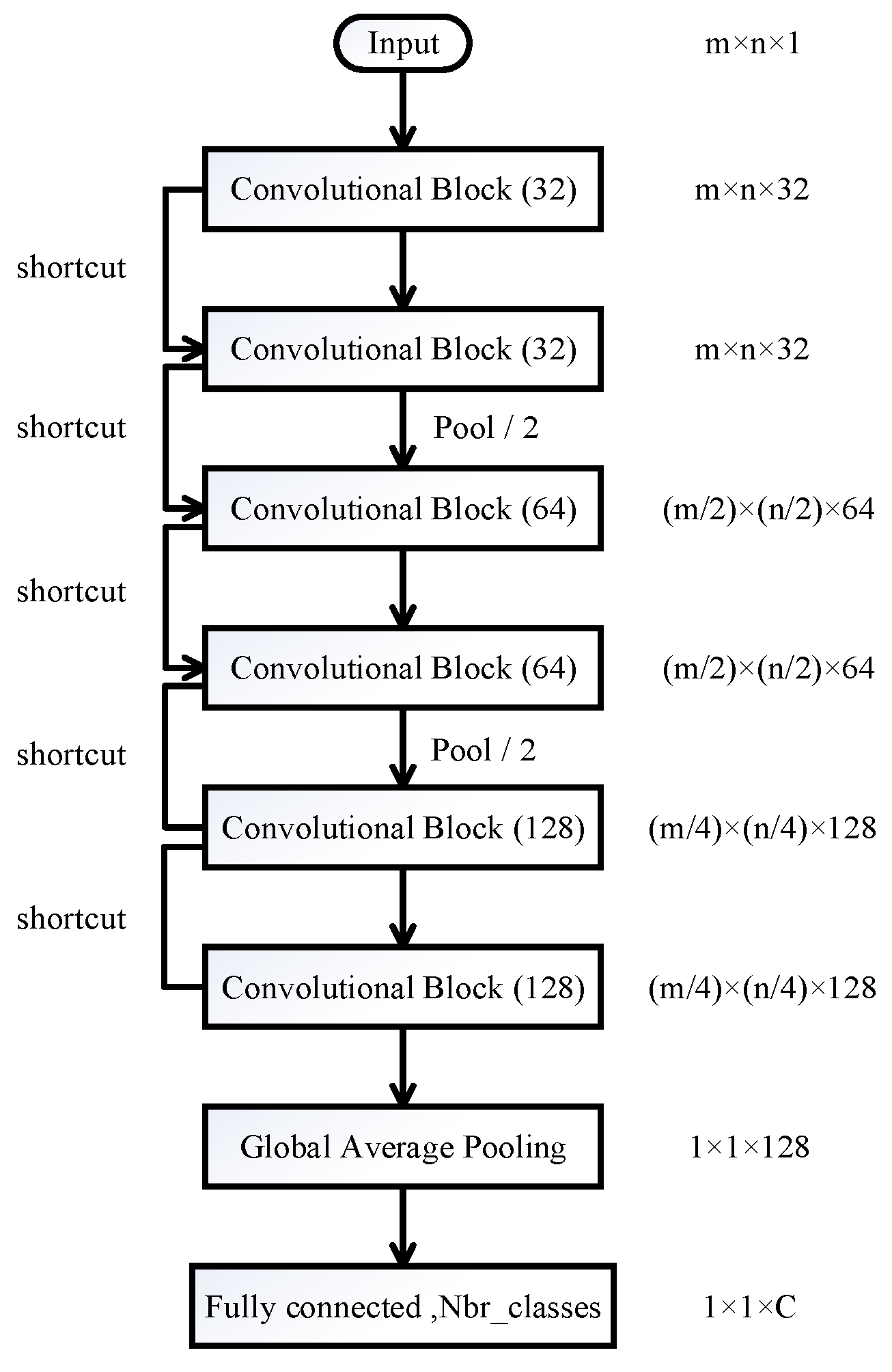
2.2.1. Overall Architecture
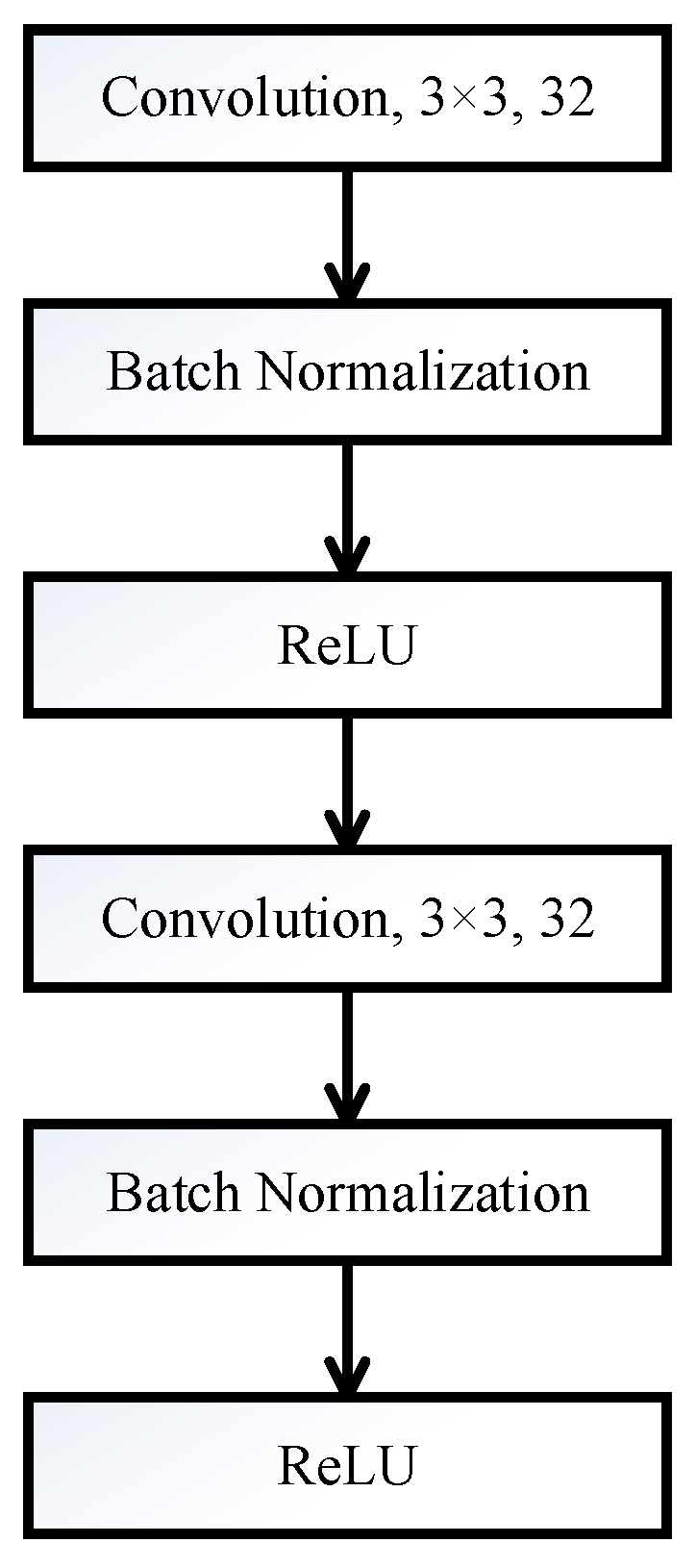
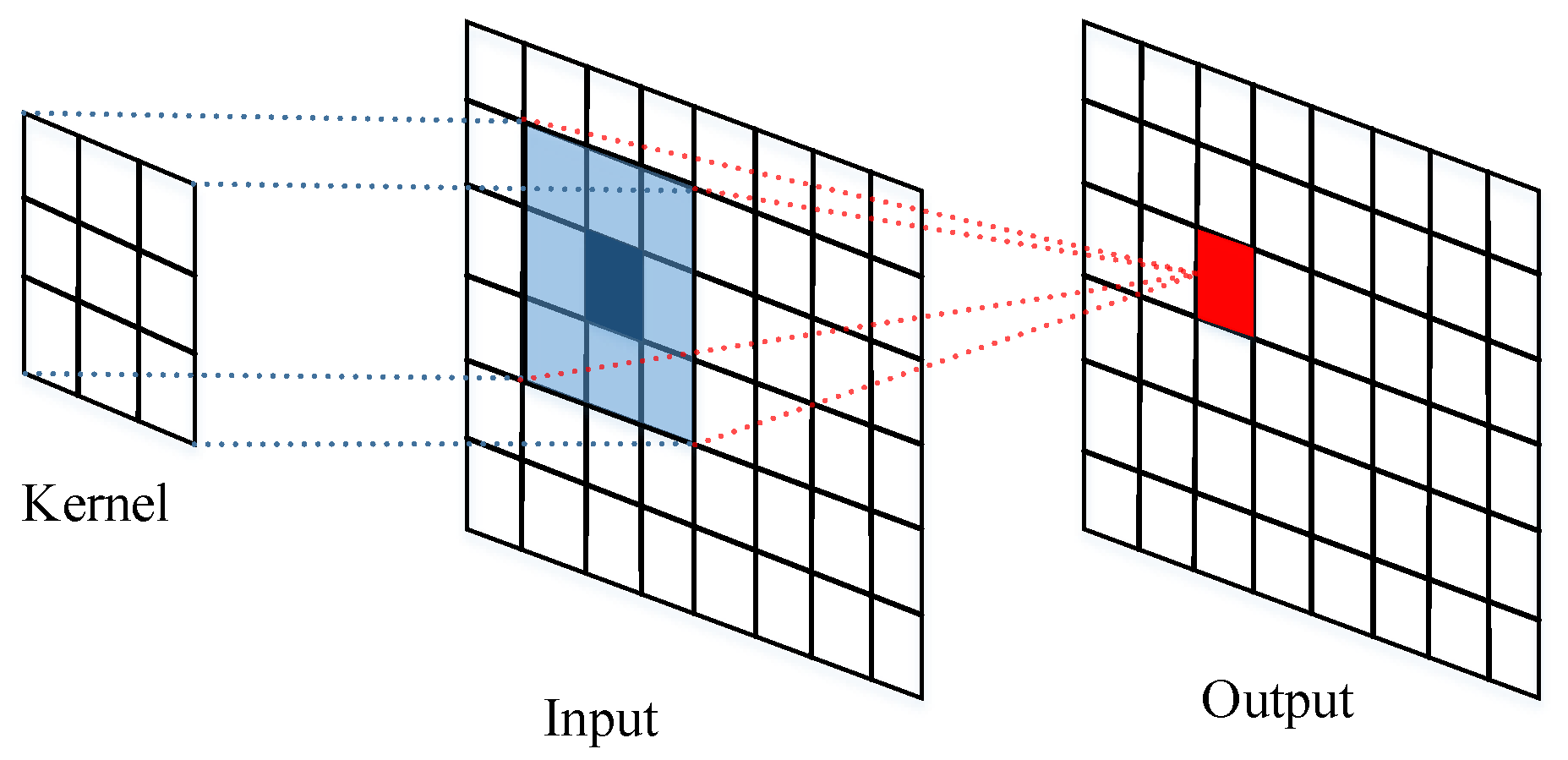
2.2.2. Convolutional Block
2.3. Network Training
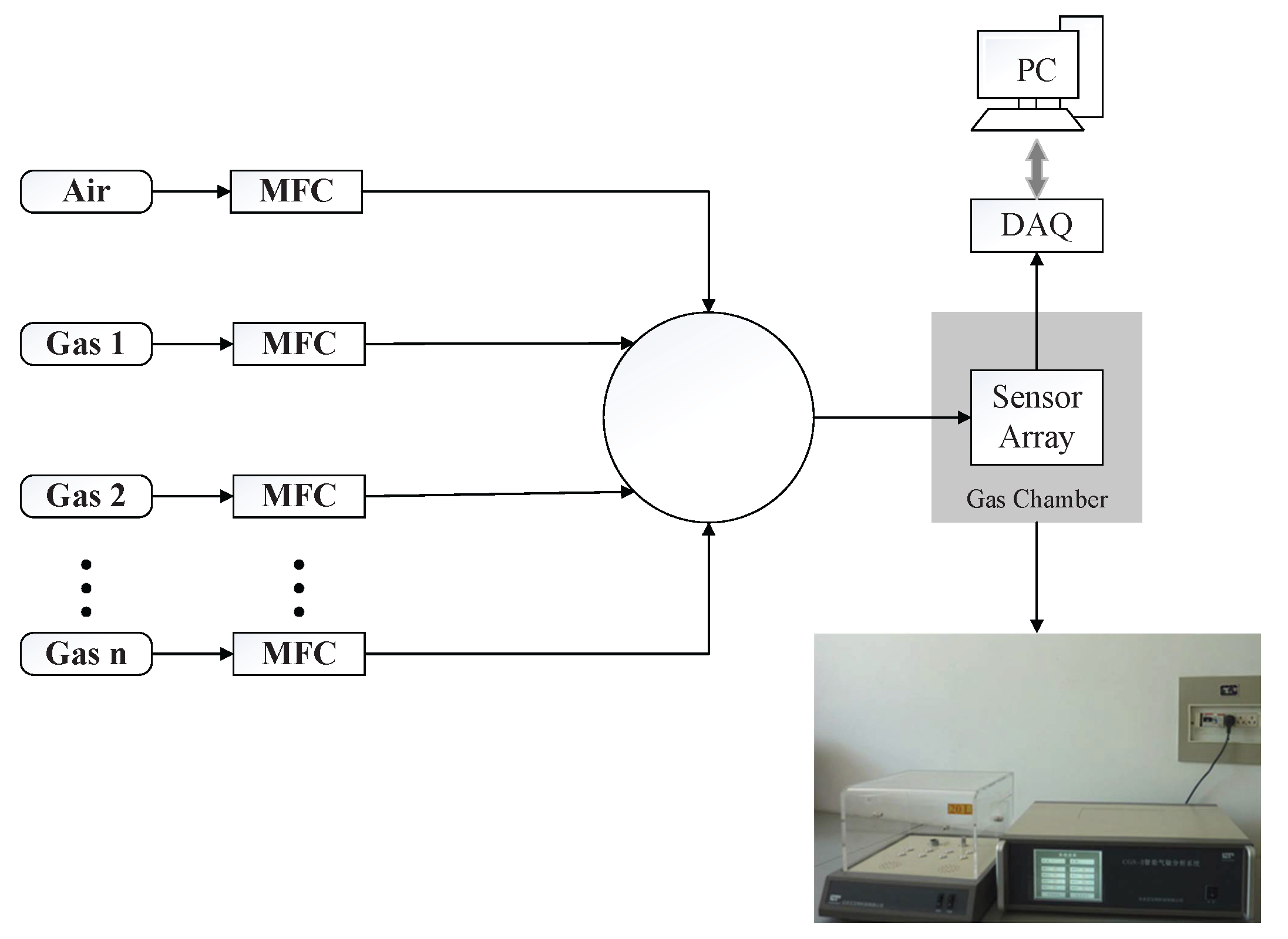
3. Experimental Results
3.1. Baseline Approach
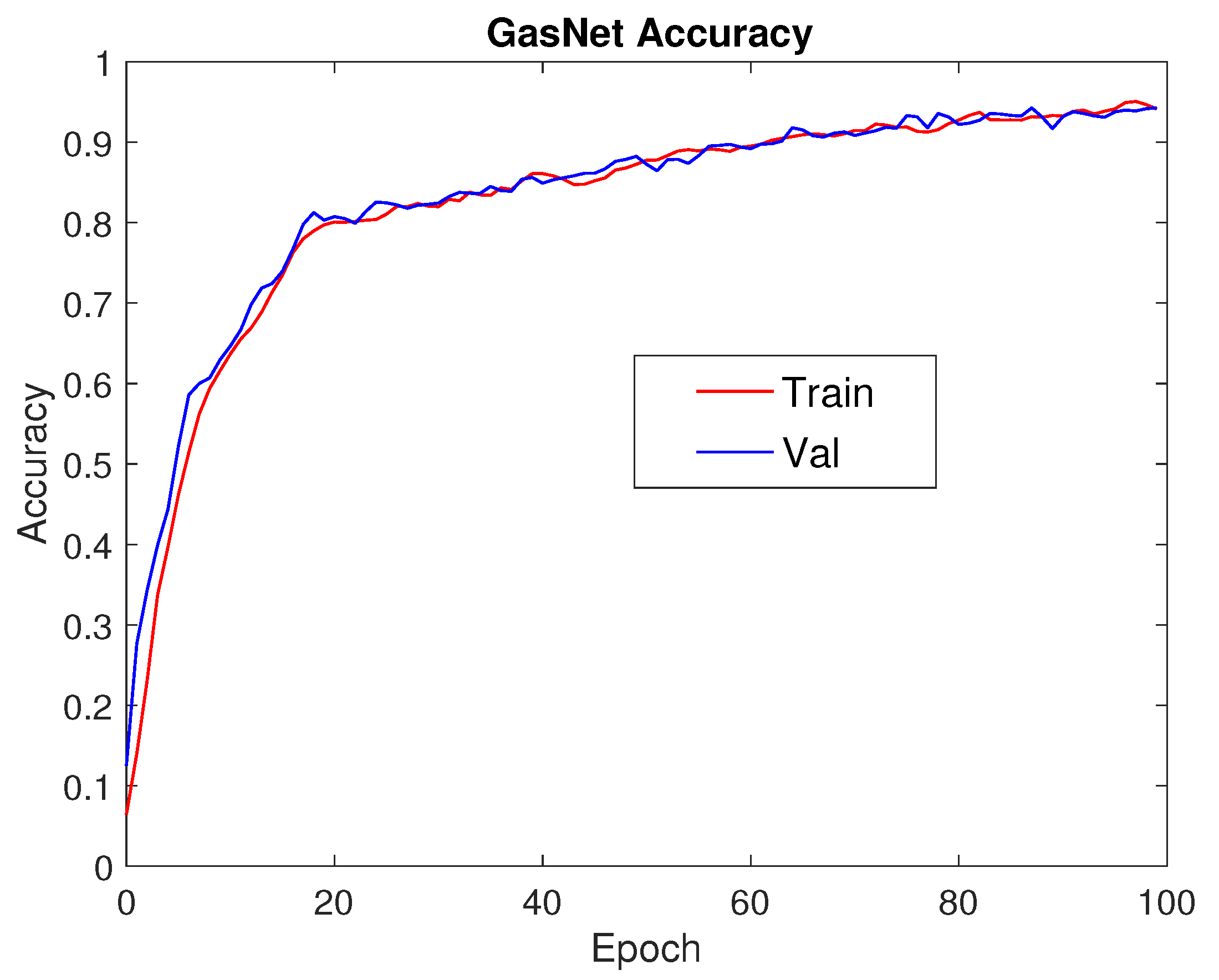
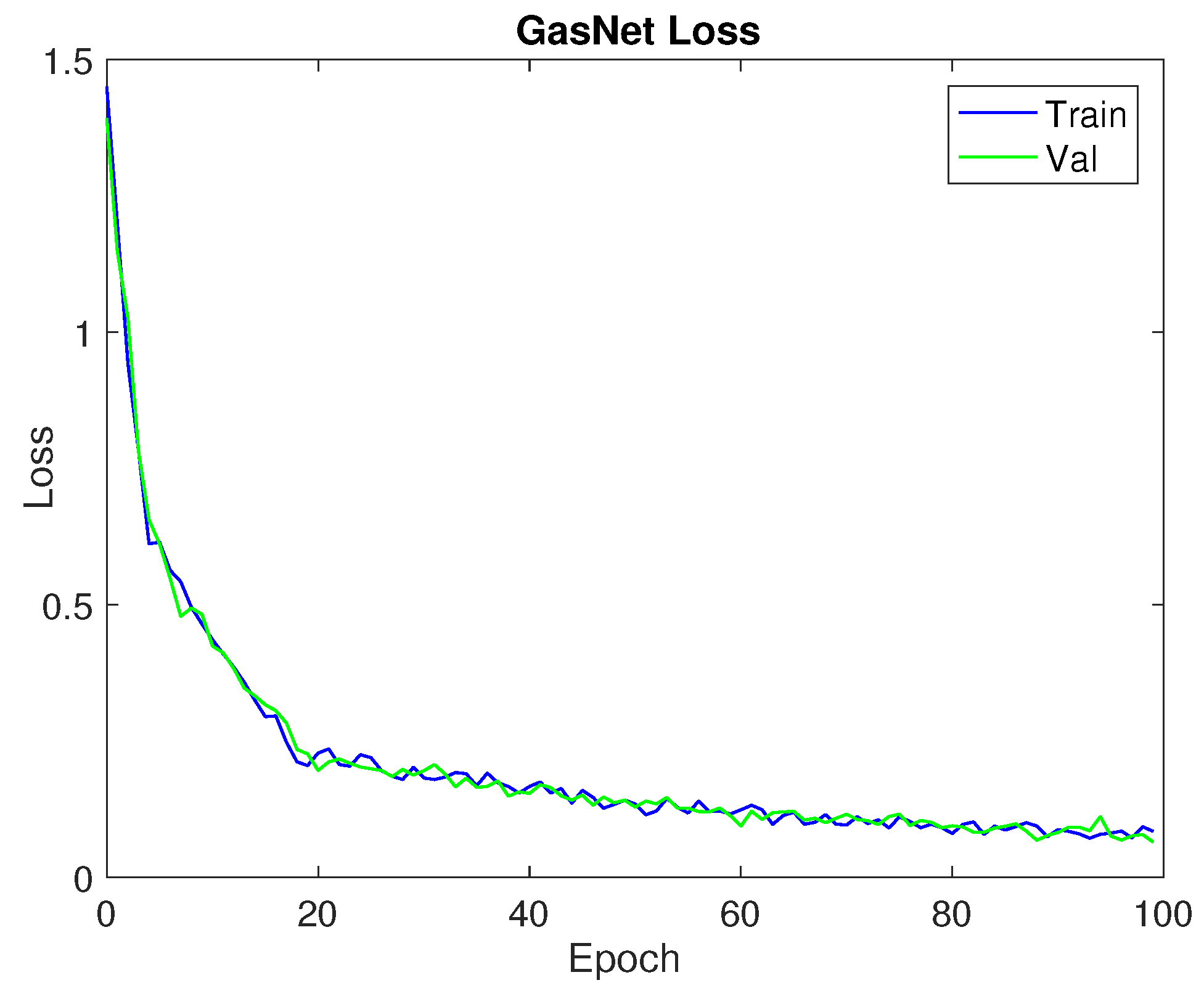
3.2. Learning Curves
3.3. Performance of Recognition
3.4. The Computational Complexity of the DCNN
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Kiani, S.; Minaei, S.; Ghasemi-Varnamkhasti, M. Application of electronic nose systems for assessing quality of medicinal and aromatic plant products: A review. J. Appl. Res. Med. Aromat. Plants 2016, 3, 1–9. [Google Scholar] [CrossRef]
- Loutfi, A.; Coradeschi, S.; Mani, G.K.; Shankar, P.; Rayappan, J.B.B. Electronic noses for food quality: A review. J. Food Eng. 2015, 144, 103–111. [Google Scholar] [CrossRef]
- Romain, A.C.; Nicolas, J. Long term stability of metal oxide-based gas sensors for e-nose environmental applications: An overview. Sens. Actuators B Chem. 2010, 146, 502–506. [Google Scholar] [CrossRef]
- Capelli, L.; Sironi, S.; Del Rosso, R. Electronic noses for environmental monitoring applications. Sensors 2014, 14, 19979–20007. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gutierrez-Osuna, R.; Gutierrez-Galvez, A.; Powar, N. Transient response analysis for temperature-modulated chemoresistors. Sens. Actuators B Chem. 2003, 93, 57–66. [Google Scholar] [CrossRef]
- Yang, J.; Sun, Z.; Chen, Y. Fault detection using the clustering-kNN rule for gas sensor arrays. Sensors 2016, 28, 2069. [Google Scholar] [CrossRef] [PubMed]
- Belhouari, S.B.; Bermak, A.; Shi, M.; Chan, P.C. Fast and robust gas identification system using an integrated gas sensor technology and Gaussian mixture models. IEEE Sens. J. 2005, 5, 1433–1444. [Google Scholar] [CrossRef]
- Brezmes, J.; Ferreras, B.; Llobet, E.; Vilanova, X.; Correig, X. Neural network based electronic nose for the classification of aromatic species. Anal. Chim. Acta 1997, 348, 503–509. [Google Scholar] [CrossRef]
- Omatul, S.; Yano, M. Mixed Odors Classification by Neural Networks. In Proceedings of the 2015 IEEE 8th International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS), Warsaw, Poland, 24–26 September 2015; pp. 171–176. [Google Scholar]
- Zhai, X.; Ali, A.A.S.; Amira, A.; Bensaali, F. MLP neural network based gas classification system on Zynq SoC. IEEE Access 2016, 4, 8138–8146. [Google Scholar] [CrossRef]
- Acevedo, F.; Maldonado, S.; Dominguez, E.; Narvaez, A.; Lopez, F. Probabilistic support vector machines for multi-class alcohol identification. Sens. Actuators B Chem. 2007, 122, 227–235. [Google Scholar] [CrossRef]
- Lentka, Ł.; Smulko, J.M.; Ionescu, R.; Granqvist, C.G.; Kish, L.B. Determination of gas mixture components using fluctuation enhanced sensing and the LS-SVM regression algorithm. Metrol. Meas. Syst. 2015, 3, 341–350. [Google Scholar]
- Wang, X.; Ye, M.; Duanmua, C. Classification of data from electronic nose using relevance vector machines. Sens. Actuators B Chem. 2009, 140, 143–148. [Google Scholar] [CrossRef]
- Langkvist, M.; Loutfi, A. Unsupervised feature learning for electronic nose data applied to Bacteria Identification in Blood. In Proceedings of the NIPS 2011 Workshop on Deep Learning and Unsupervised Feature Learning, Granada, Spain, 12–17 December 2011; pp. 1–7. [Google Scholar]
- Liu, Q.; Hu, X.; Ye, M.; Cheng, X.; Li, F. Gas recognition under sensor drift by using deep learning. Int. J. Intell. Syst. 2015, 30, 907–922. [Google Scholar] [CrossRef]
- Available online: http://www.image-net.org/ (accessed on 13 September 2017).
- Krizhevsky, A.; Ilya, S.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. NIPS 2012, 1, 1097–1105. [Google Scholar] [CrossRef]
- Zeiler, D.; Fergus, R. Visualizing and understanding convolutional networks, in: Computer Vision. In Proceedings of the 13th European Conference in Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Rethinking the inception architecture for computer vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, ICML, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Vergara, A.; Vembu, S.; Ayhan, T.; Ryan, M.; Homer, M.L.; Huerta, R. Chemical gas sensor drift compensation using classifier ensembles. Sens. Actuators B Chem. 2012, 9, 320–329. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Channel | Sensor Part Number |
|---|---|
| 0 | TGS821 |
| 1 | TGS812 |
| 2 | TGS2610 |
| 3 | TGS2612 |
| 4 | TGS3870 |
| 5 | TGS2611 |
| 6 | TGS816 |
| 7 | TGS2602 |
| Model | Validation Accuracy | Training Time(s) |
|---|---|---|
| SVM | 79.9% | 2 |
| MLP | 82.3% | 17 |
| GasNet | 95.2% | 154 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, P.; Zhao, X.; Pan, X.; Ye, W. Gas Classification Using Deep Convolutional Neural Networks. Sensors 2018, 18, 157. https://doi.org/10.3390/s18010157
Peng P, Zhao X, Pan X, Ye W. Gas Classification Using Deep Convolutional Neural Networks. Sensors. 2018; 18(1):157. https://doi.org/10.3390/s18010157
Chicago/Turabian StylePeng, Pai, Xiaojin Zhao, Xiaofang Pan, and Wenbin Ye. 2018. "Gas Classification Using Deep Convolutional Neural Networks" Sensors 18, no. 1: 157. https://doi.org/10.3390/s18010157
APA StylePeng, P., Zhao, X., Pan, X., & Ye, W. (2018). Gas Classification Using Deep Convolutional Neural Networks. Sensors, 18(1), 157. https://doi.org/10.3390/s18010157