Characterization of System Status Signals for Multivariate Time Series Discretization Based on Frequency and Amplitude Variation


Abstract
:1. Introduction
2. Methodology
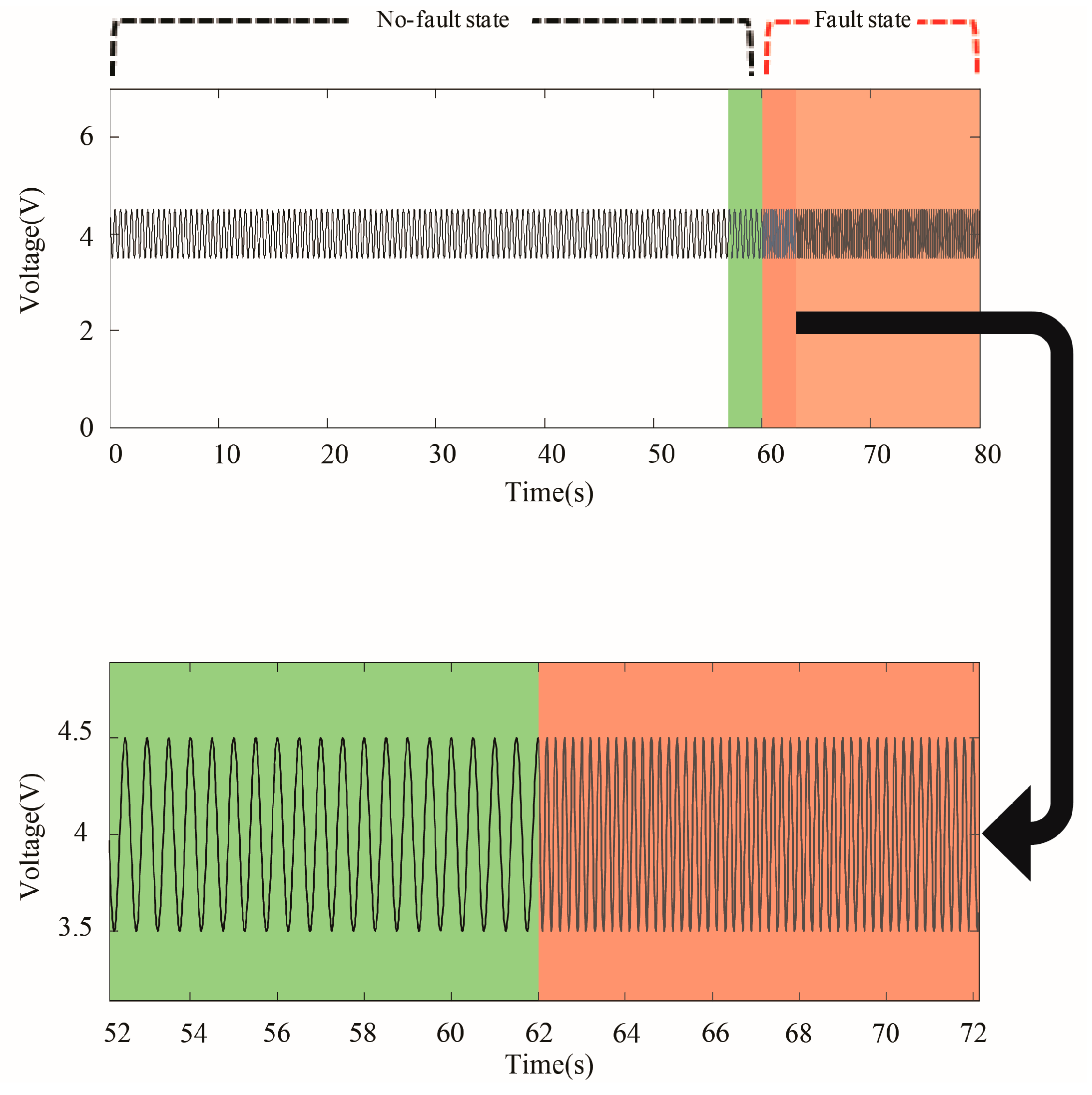
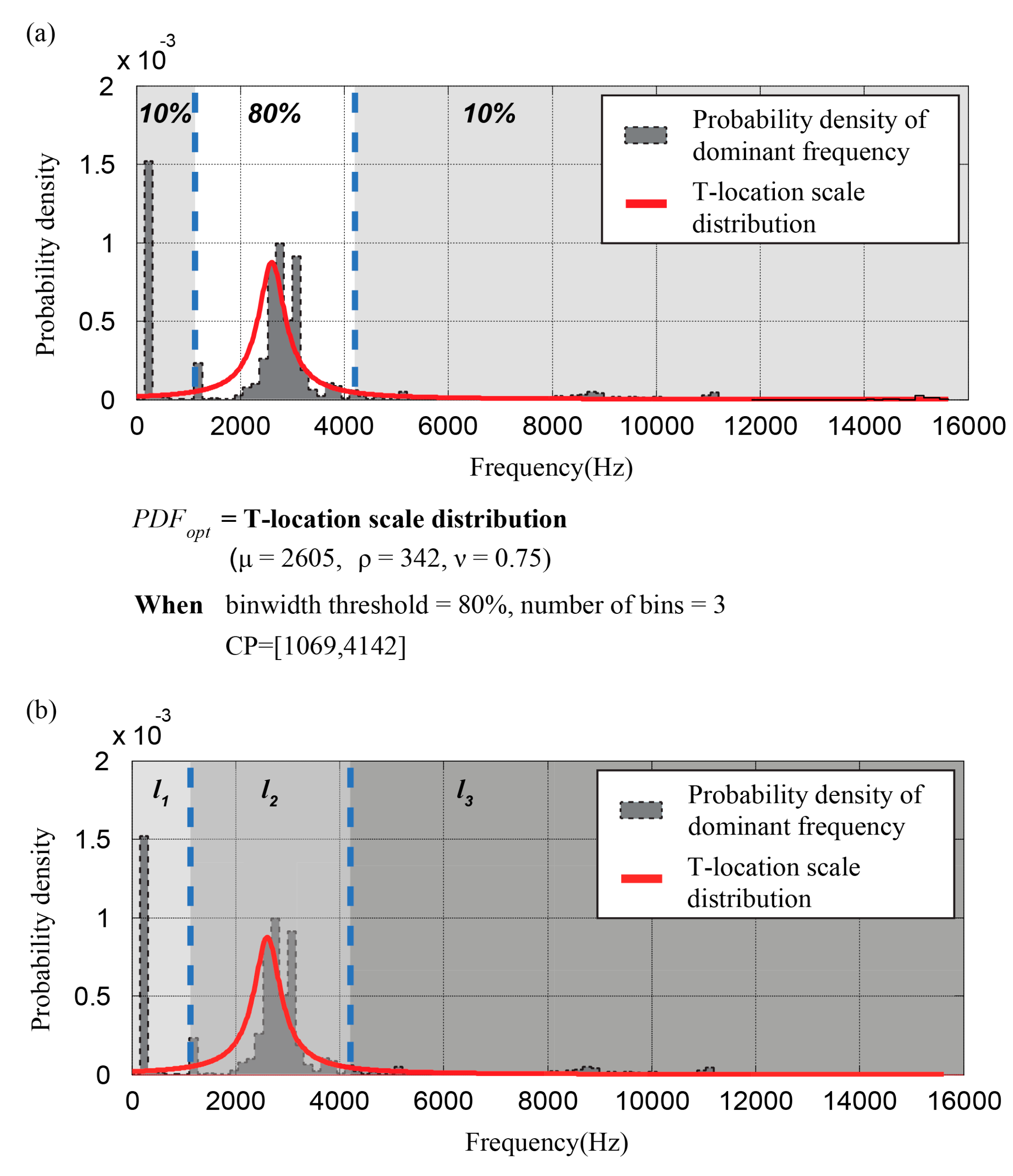
2.1. Frequency Variation-Based Discretized Time Series Generation
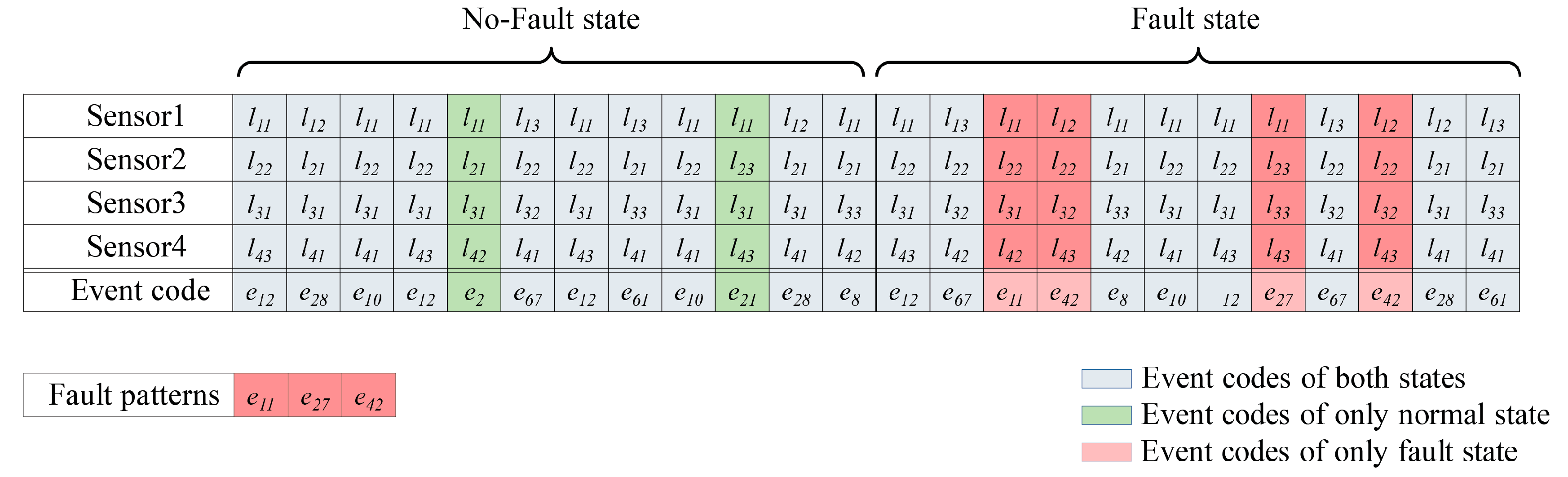
2.2. Discretization-Based Fault Pattern Extraction
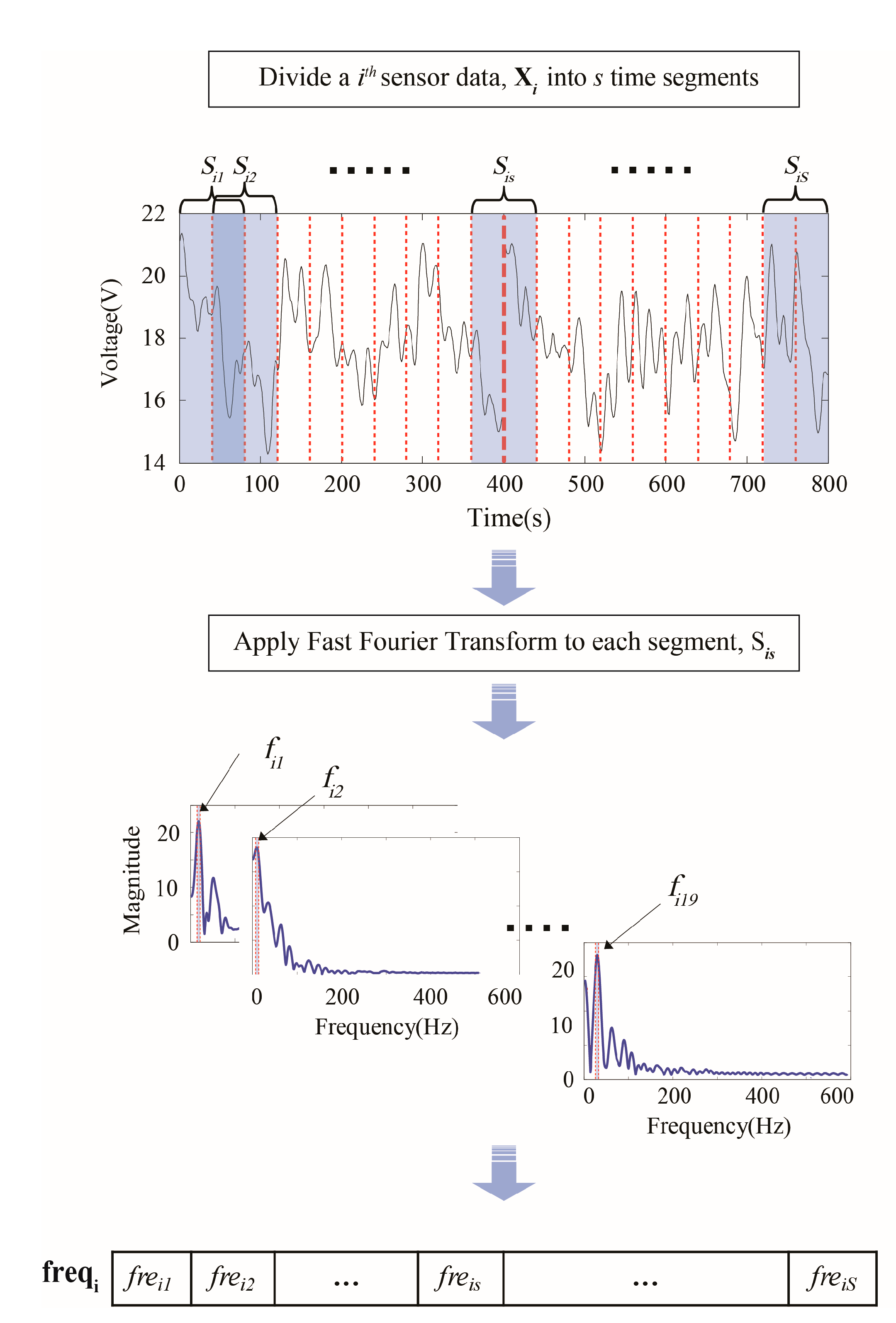
2.3. Dominant Frequency Extraction for Each Segment
2.4. Characterization of System Status Signals
3. Computational Experiment
3.1. Laser Welding Monitoring Data
3.2. Automotive Gasoline Engine Data
- Step 1. Turn on the engine
- Step 2. Control the amount of manifold air flow
- Step 3. An engine knocking occurs
3.3. Automotive Buzz, Squeak, and Rattle (BSR) Noise Monitoring Data
3.4. Marine Diesel Engine Data
4. Concluding Remarks
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Venkatasubramanian, V.; Rengaswamy, R. A review of process fault detection and diagnosis: Part iii: Process history based methods. Comput. Chem. Eng. 2003, 27, 327–346. [Google Scholar] [CrossRef]
- Isermann, R. Model-based fault-detection and diagnosis–status and applications. Ann. Rev. Control 2005, 29, 71–85. [Google Scholar] [CrossRef]
- Hellerstein, J.M.; Koutsoupias, E.; Papadimitriou, C.H. On the analysis of indexing schemes. In Proceedings of the Sixteenth ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, Tucson, AZ, USA, 11–15 May 1997. [Google Scholar]
- Nguyen, S.H.; Nguyen, H.S. Pattern extraction from data. Fundam. Inform. 1998, 34, 129–144. [Google Scholar]
- Lin, J.; Keogh, E.; Wei, L.; Lonardi, S. Experiencing sax: A novel symbolic representation of time series. Data Min. Knowl. Discov. 2007, 15, 107–144. [Google Scholar] [CrossRef]
- Pensa, R.G.; Leschi, C.; Besson, J.; Boulicaut, J.-F. Assessment of discretization techniques for relevant pattern discovery from gene expression data. In Proceedings of the Fourth International Conference on Data Mining in Bioinformatics, Copenhagen, Denmark, 28–29 April 2018. [Google Scholar]
- Dash, R.; Paramguru, R.L.; Dash, R. Comparative analysis of supervised and unsupervised discretization techniques. Int. J. Adv. Sci. Technol. 2011, 2, 29–37. [Google Scholar]
- Liu, H.; Hussain, F.; Tan, C.L.; Dash, M. Discretization: An enabling technique. Data Min. Knowl. Discov. 2002, 6, 393–423. [Google Scholar] [CrossRef]
- Dougherty, J.; Kohavi, R.; Sahami, M. Supervised and unsupervised discretization of continuous features. In Proceedings of the Twelfth International Conference on Machine Learning, Tahoe City, CA, USA, 9–12 July 1995. [Google Scholar]
- Wong, A.K.; Chiu, D.K. Synthesizing statistical knowledge from incomplete mixed-mode data. IEEE Trans. Pattern Anal. Mach. Intell. 1987, PAMI-9, 796–805. [Google Scholar] [CrossRef]
- Gupta, A.; Mehrotra, K.G.; Mohan, C. A clustering-based discretization for supervised learning. Stat. Probab. Lett. 2010, 80, 816–824. [Google Scholar] [CrossRef]
- Halim, E.B.; Choudhury, M.A.A.S.; Shah, S.L.; Zuo, M.J. Time domain averaging across all scales: A novel method for detection of gearbox faults. Mech. Syst. Signal Proc. 2008, 22, 261–278. [Google Scholar] [CrossRef]
- Huang, N.; Qi, J.; Li, F.; Yang, D.; Cai, G.; Huang, G.; Zheng, J.; Li, Z. Short-circuit fault detection and classification using empirical wavelet transform and local energy for electric transmission line. Sensors 2017, 17, 2133. [Google Scholar] [CrossRef] [PubMed]
- Zarei, J.; Poshtan, J. Bearing fault detection using wavelet packet transform of induction motor stator current. Tribol. Int. 2007, 40, 763–769. [Google Scholar] [CrossRef]
- Wang, H.; Li, R.; Tang, G.; Yuan, H.; Zhao, Q.; Cao, X. A compound fault diagnosis for rolling bearings method based on blind source separation and ensemble empirical mode decomposition. PLoS ONE 2014, 9, e109166. [Google Scholar] [CrossRef] [PubMed]
- Lu, C.; Wang, Y.; Ragulskis, M.; Cheng, Y. Fault diagnosis for rotating machinery: A method based on image processing. PLoS ONE 2016, 11, e0164111. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Feng, F.; Zhang, B. Weak fault feature extraction of rolling bearings based on an improved kurtogram. Sensors 2016, 16, 1482. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.J.; Lee, S.M.; Kim, I.Y.; Min, H.K.; Hong, S.H. Comparison between short time fourier and wavelet transform for feature extraction of heart sound. In Proceedings of the IEEE Region 10 Conference TENCON 99, Cheju Island, Korea, 15–17 September 1999. [Google Scholar]
- Yang, J.; Hamelin, F.; Sauter, D. Fault detection observer design using time and frequency domain specifications. IFAC Proc. Vol. 2014, 47, 8564–8569. [Google Scholar] [CrossRef]
- Patton, R.; Chen, J. Observer-based fault detection and isolation: Robustness and applications. Control Eng. Pract. 1997, 5, 671–682. [Google Scholar] [CrossRef]
- Chibani, A.; Chadli, M.; Shi, P.; Braiek, N.B. Fuzzy fault detection filter design for t–s fuzzy systems in the finite-frequency domain. IEEE Trans. Fuzzy Syst. 2017, 25, 1051–1061. [Google Scholar] [CrossRef]
- Li, L.; Chadli, M.; Ding, S.X.; Qiu, J.; Yang, Y. Diagnostic observer design for ts fuzzy systems: Application to real-time weighted fault detection approach. IEEE Trans. Fuzzy Syst. 2017. [Google Scholar] [CrossRef]
- Chibani, A.; Chadli, M.; Braiek, N.B. A finite frequency approach to h∞ filtering for T–S fuzzy systems with unknown inputs. Asian J. Control 2016, 18, 1608–1618. [Google Scholar] [CrossRef]
- Dai, X.; Gao, Z. From model, signal to knowledge: A data-driven perspective of fault detection and diagnosis. IEEE Trans. Ind. Inform. 2013, 9, 2226–2238. [Google Scholar] [CrossRef]
- Naderi, E.; Khorasani, K. Data-driven fault detection, isolation and estimation of aircraft gas turbine engine actuator and sensors. In Proceedings of the 2017 IEEE 30th Canadian Conference on Electrical and Computer Engineering (CCECE), Windsor, ON, Canada, 30 April–3 May 2017. [Google Scholar]
- McInerny, S.A.; Dai, Y. Basic vibration signal processing for bearing fault detection. IEEE Trans. Educ. 2003, 46, 149–156. [Google Scholar] [CrossRef]
- Byington, C.S.; Watson, M.; Edwards, D. Data-driven neural network methodology to remaining life predictions for aircraft actuator components. In Proceedings of the 2004 IEEE Proceedings on Aerospace Conference, Big Sky, MT, USA, 6–13 March 2004. [Google Scholar]
- Sejdić, E.; Jiang, J. Pattern Recognition Techniques, Technology and Applications; InTech: Vienna, Austria, 2008. [Google Scholar]
- Baek, S.; Kim, D.Y. Empirical sensitivity analysis of discretization parameters for fault pattern extraction from multivariate time series data. IEEE Trans. Cybern. 2017, 47, 1198–1209. [Google Scholar] [CrossRef] [PubMed]
- Peng, Z.K.; Chu, F.L. Application of the wavelet transform in machine condition monitoring and fault diagnostics: A review with bibliography. Mech. Syst. Signal Proc. 2004, 18, 199–221. [Google Scholar] [CrossRef]
- Fu, T.-C. A review on time series data mining. Eng. Appl. Artif. Intell. 2011, 24, 164–181. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
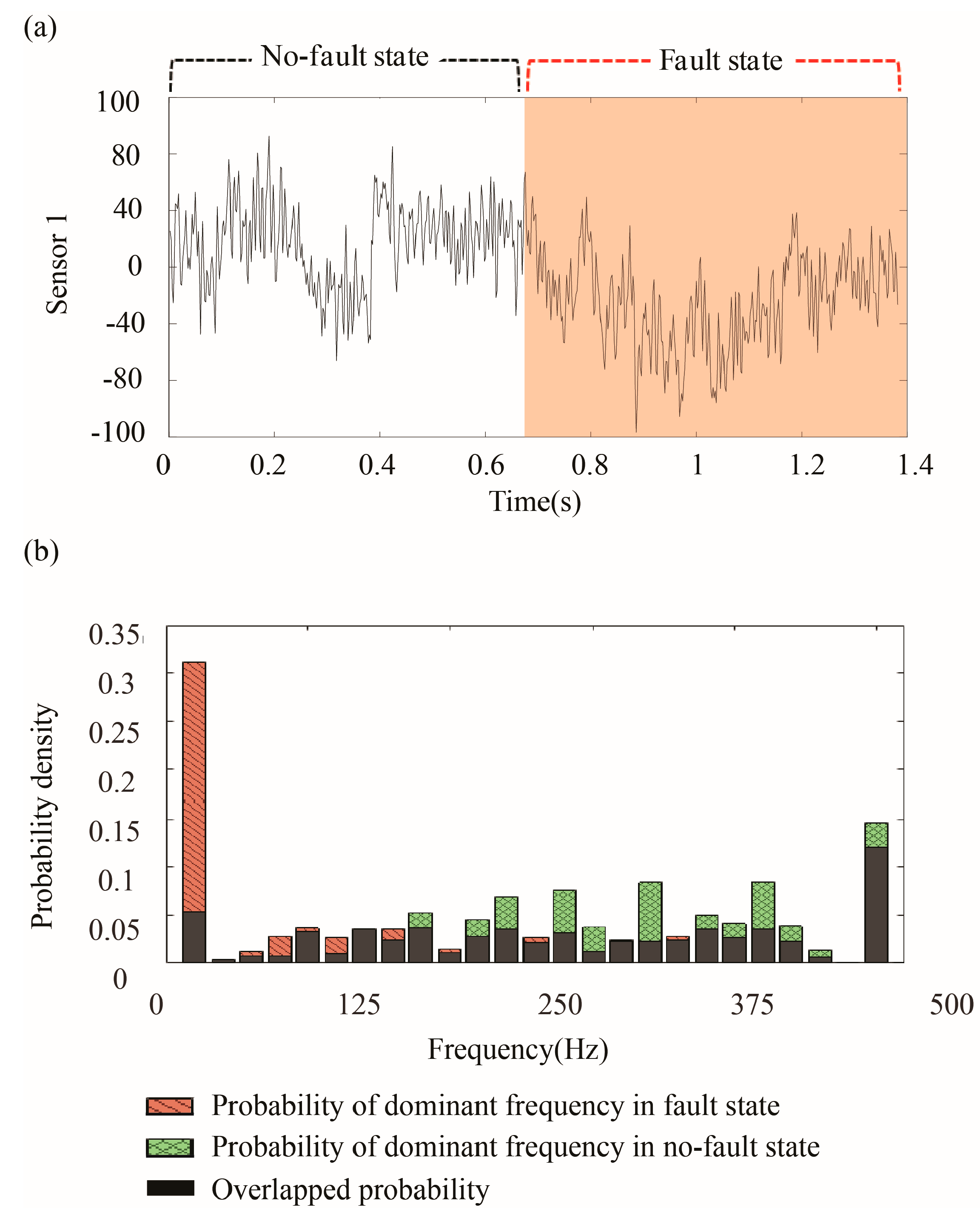{kind=link}
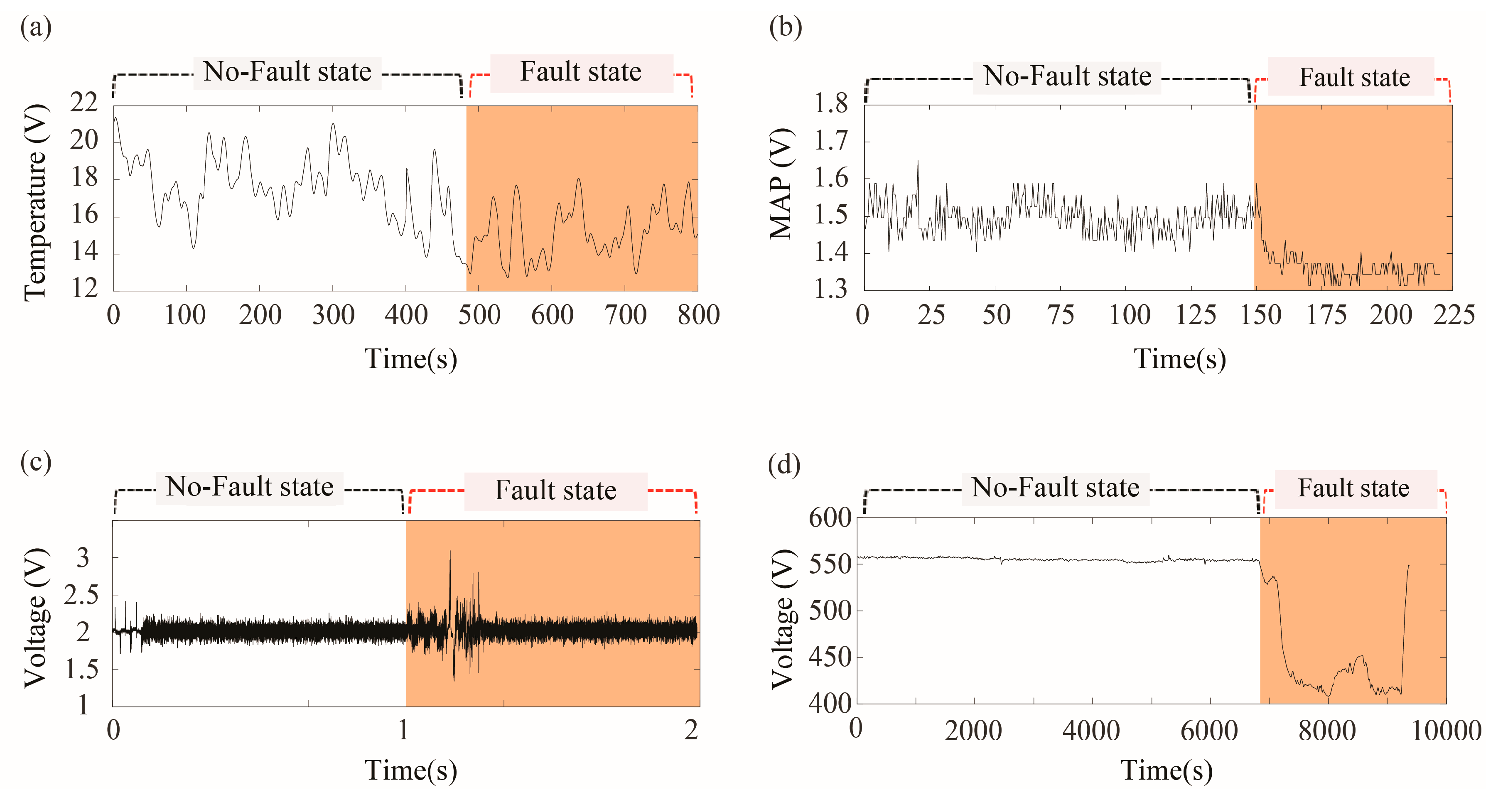{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| Indices | |
| number of the sensors (i = 1, 2, …, I) | |
| number of the data points (j = 1, 2, …, J) | |
| number of discretized segments (s = 1, 2, …, S) | |
| V | number of frequency bins (v = 1, 2, …, V) |
| Z | number of event codes (z = 1, 2, …, Z ) |
| Parameters | |
| b | number of bins |
| size of central bin | |
| window size of each segment | |
| Variables | |
| time series of ith sensor signal | |
| discretized time series of | |
| estimated probability density function of given data | |
| bth label defined at label definition step | |
| (b − 1)th cut point defined at label definition step | |
| a set of labels for : | |
| a set of cut points for : | |
| sth discrete state vector of ith sensor | |
| D(X) | a set of discrete state vector of |
| zth event code of , where z = | |
| a set of event codes of | |
| a set of event codes occurs in no-fault state | |
| a set of event codes occurs in fault state | |
| a set of event codes which only occur in fault state | |
| sth dominant frequency of ith sensor | |
| a set of dominant frequency of ith sensor |
| Dataset | Sensors | Total Number of Faults | Sampling Rate | Acquisition Time |
|---|---|---|---|---|
| laser welding | plasma intensity weld pool temperature back-reflection | 5 defects among 50 weldments | 1 KHz | 0.4 s/specimen |
| gasoline engine | crank position manifold absolute pressure throttle position #1 injector position; #2 injector position; #3 injector position | 50 deliberate engine knockings for 3 h engine run | 2 Hz | 3 h |
| BSR noise | sensor array of 9 microphones 4 parabolic external microphones | 22 defects among 47 door trims | 32,768 Hz | 2 s/inspection |
| marine diesel engine | air cooler pressure turbocharger inlet temperature lube oil inlet temperature turbocharger speed current for ignition power factor | 19 abnormal combustions for 2 months | 1 Hz | 2 months |
| Dataset | KCIs | Fault Detection Performance | ||||
|---|---|---|---|---|---|---|
| CI | DF | DI | aVar | FP1 Amplitude Variation | FP2 Frequency Variation | |
| Laser welding monitoring | 79.1 | 0.813 | 0.027 | 0.004 | 100% | 40% |
| Automotive gasoline engine | 51.5 | 0.671 | 0.232 | 0.034 | 92% | 92% |
| Automotive BSR noise monitoring | 12.0 | 0.522 | 0.770 | 0.004 | 80% | 95% |
| Marine diesel engine | 19.9 | 0.208 | 0.042 | 0.007 | 93% | 100% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baek, W.; Baek, S.; Kim, D.Y. Characterization of System Status Signals for Multivariate Time Series Discretization Based on Frequency and Amplitude Variation. Sensors 2018, 18, 154. https://doi.org/10.3390/s18010154
Baek W, Baek S, Kim DY. Characterization of System Status Signals for Multivariate Time Series Discretization Based on Frequency and Amplitude Variation. Sensors. 2018; 18(1):154. https://doi.org/10.3390/s18010154
Chicago/Turabian StyleBaek, Woonsang, Sujeong Baek, and Duck Young Kim. 2018. "Characterization of System Status Signals for Multivariate Time Series Discretization Based on Frequency and Amplitude Variation" Sensors 18, no. 1: 154. https://doi.org/10.3390/s18010154
APA StyleBaek, W., Baek, S., & Kim, D. Y. (2018). Characterization of System Status Signals for Multivariate Time Series Discretization Based on Frequency and Amplitude Variation. Sensors, 18(1), 154. https://doi.org/10.3390/s18010154