Comparison of SVM, RF and ELM on an Electronic Nose for the Intelligent Evaluation of Paraffin Samples



Abstract
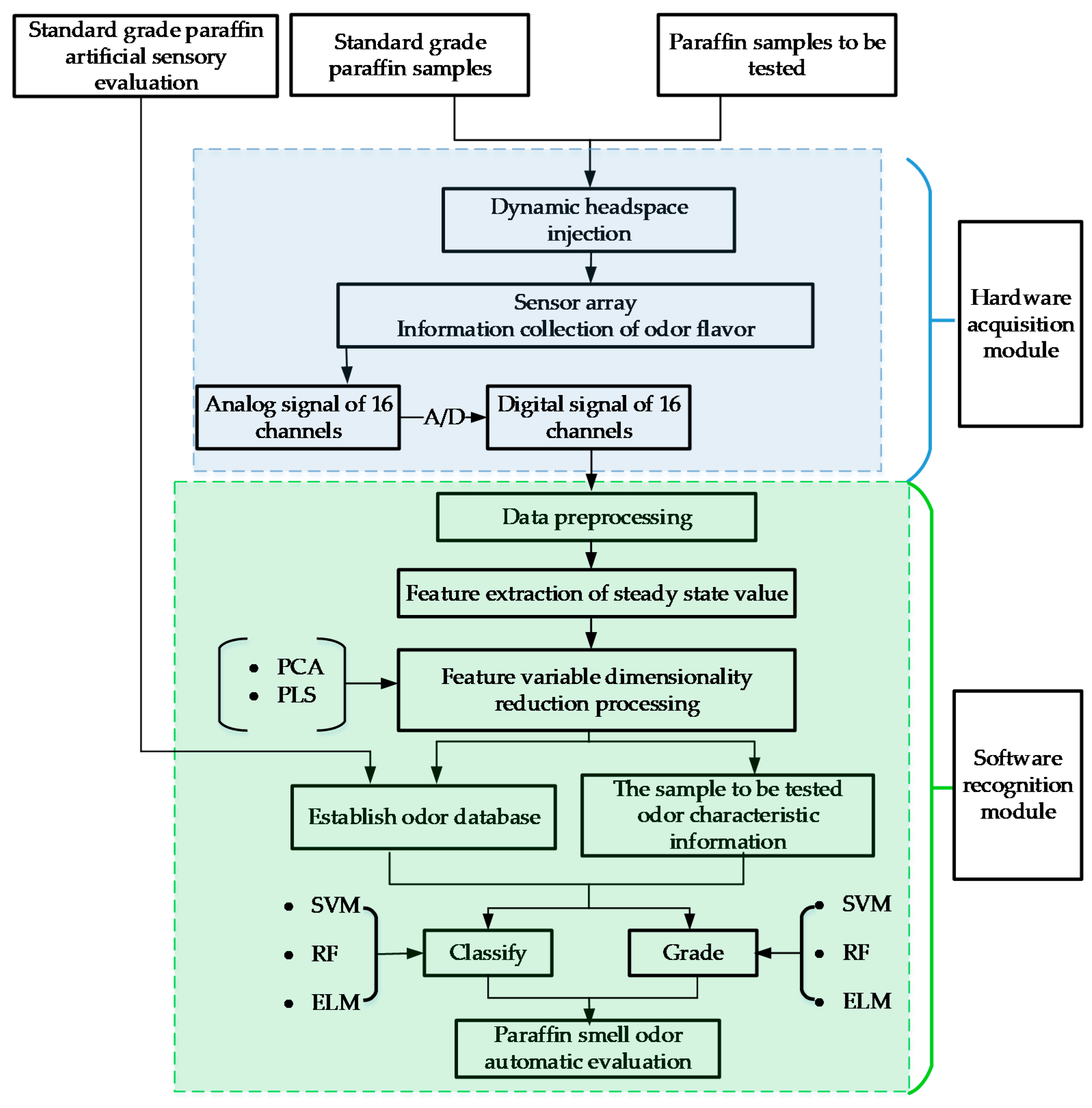
:1. Introduction
2. Materials and Methods
2.1. Materials
2.2. Sample Preparation
- (1)
- Cut the paraffin sample to be tested with a sharp scraper, obtain a non-adhesive sheet-shaped sample (about 0.5 mm).
- (2)
- Accurately weigh-out 20.00 g of sheet paraffin and place it into a 500 mL customized glass bottle and seal it with a cover, letting the sample stand for 20 min for later use.
2.3. Design and Development of Paraffin Odor Analysis System
2.4. Data Processing and Analysis Methods
2.4.1. Variable Selection Method
Principal Component Analysis (PCA)
Partial Least Squares (PLS)
2.4.2. Research Method
Support Vector Machine (SVM)
- (1)
- SVM usually uses the following minimization optimization model to determine the regression function:where w is the weight vector, is the expression of model complexity, c is the penalty factor, and are the relaxation factors, is a nonlinear transformation that maps data to high dimensional space, b is offset, and is the upper limit of error.
- (2)
- The Lagrange multipliers and are introduced. The optimization model shown in Equations (10) and (11) can be transformed into the following dual optimization problem:
- (3)
- The SVM regression function is obtained by solving the above problems:
Random Forest (RF)
- (1)
- Resampling is performed by Bootstrap to randomly generate T training sets S1, S2, …, ST.
- (2)
- The corresponding decision tree C1, C2, …, CT for each training set is generated. Before a property is selected on the internal node, m properties are randomly selected from M properties as the split property set of the current node (m < M). Generally speaking, the m value is stable during the overall forest development process.
- (3)
- Each tree is in complete development, pruning is not performed.
- (4)
- For test set sample X, a test is performed by using each decision tree to obtain the corresponding class C1(X), C2(X), …, CT(X).
- (5)
- By voting, the individual in T decision trees with the most outputs is selected as the test set sample X, then, the prediction is finished.
Extreme Learning Machine (ELM)
- (1)
- Set N different samples (xi, ti) ∈ Rn×m and the activation function; the activation function of the neurons in the hidden layer is g(x):where N is the number of neurons in the hidden layer; wi is the weight between the ith hidden node and the input node, wi = [wi1, wi2, …, win]T; βi is the output weight between the ith hidden node and the input node, βi = [βi1, βi2, …, βim]T; and bi is the deviation among the hidden nodes of the ith layer.
- (2)
- The activation function of the feedforward neural network of a standard single hidden layer g(x) can approximate the training sample with zero errors:Namely, the existence of βi, wi, and bi makes:
- (3)
- The above N equations can be written as Hβ = T:where H is the output matrix of the hidden layer of the neural network and β is the output layer connection weight.
- (4)
- To train the feedforward neural network of the single hidden layer, a specific βi’ should be found and wi’ can be obtained with the following formula:
3. Results and Discussion
3.1. Variable Selection Results
3.1.1. Variable Selection Results Based on PCA
3.1.2. Variable Selection Results Based on PLS
3.2. Classification and Level Assessment of the Paraffin Samples
3.2.1. Classification for the Paraffin Samples
Classification Based on SVM
Classification Based on RF
Classification Based on ELM
3.2.2. Level Assessment for the Paraffin Samples
Level Assessment Based on SVM
Level Assessment Based on RF
Level Assessment Based on ELM
4. Conclusions
- (1)
- Design of paraffin odor analysis system: in this paper, we introduced a new method for testing paraffin odor level based on the electronic nose, designed and developed the paraffin odor analysis system. This system can analyze, screen, and recognize the paraffin odor feature response and grade the odor of an unknown paraffin sample.
- (2)
- Classification of paraffin samples: SVM, RF, and ELM were applied to three different feature data sets to build the model and compare the model accuracy rate and regression parameters. By comprehensively comparing the three models, we found that during the classification of paraffin odor, the prediction model based on the SVM network, with an accuracy rate of 100%, was superior to the networks based on RF, with an accuracy rate of 98.33–100%, and ELM, with an accuracy rate of 98.01–100%.
- (3)
- Level assessment of paraffin samples: during the recognition of the paraffin samples with different odor levels, the prediction models based on the three different feature sets were able to predict the score of the paraffin sample. The R2 related to the training set of the model was above 0.97 and the R2 related to test set was above 0.87. The paraffin odor level scores were predicted by three methods, SVM, RF, and ELM, and the predicted score error was 0.0016–0.3494, which is considerably lower than the 0.5–1.0 error measured by industry standard experts. Therefore, the three methods have higher prediction precision for paraffin odor level scores. By comprehensively comparing the relevant coefficients of the three models, the generalization of the model based on ELM was superior to that based on SVM and RF.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Guan, X.; Qiu, X.; Wang, A. On the Quality Control of Paraffin Products. Technol. Superv. Petrol. Ind. 2012, 28, 40–42. [Google Scholar] [CrossRef]
- Guan, X. Manufacturing technology and current situation of food-grade paraffin. Chem. Eng. 2012, 22, 50–52. [Google Scholar] [CrossRef]
- Zhao, B. Determination of odor stability of paraffin wax by accelerated method. Pebrochem. Technol. Appl. 2004, 3, 30–32. [Google Scholar] [CrossRef]
- Yuan, P.; Zhao, B.; Pang, C. Odor source analysis and process solutions for fully refined paraffin wax. Petrol. Refin. Eng. 2013, 43, 12–17. [Google Scholar] [CrossRef]
- Sheng, X.; Hu, Y.Y.; Zhang, L.; Sun, H.; Zheng, P.; Tao, F.R.; Yang, Y.Y.; Hang, J. Application of Normal Phase Liquid Chromatography-Evaporative Light-Scattering Detection for Determination of Paraffin Wax in Food. Chin. J. Anal. Chem. 2009, 37, 1765–1770. [Google Scholar] [CrossRef]
- Liu, F. Determination of the Paraffin in Edible Fungus by GC/MS. Food Res. Dev. 2010, 31, 133–135. [Google Scholar] [CrossRef]
- Yang, J. Determination of Paraffin Illegally Added into Foods by GC and GC/MS Methods. J. Anhui Agric. Sci. 2011, 39, 18226–18228. [Google Scholar] [CrossRef]
- Simal Gándara, J.; Sarría Vidal, M.; Rijk, R. Determination of paraffins in food simulants and packaging materials by liquid chromatography with evaporative mass detection and identification of paraffin type by liquid chromatography/gas chromatography and Fourier transform infrared spectroscopy. J. AOAC Int. 2000, 83, 311–319. [Google Scholar] [CrossRef] [PubMed]
- Men, H.; Chen, D.; Zhang, X.; Liu, J.; Ning, K. Data Fusion of Electronic Nose and Electronic Tongue for Detection of Mixed Edible-Oil. J. Sens. 2014, 2014, 1–7. [Google Scholar] [CrossRef]
- Vito, S.D.; Massera, E.; Miglietta, M.; Fattoruso, G.; Francia, G.D. Electronic Nose as an NDT Tool for Aerospace Industry. Phys. Procedia 2015, 62, 23–28. [Google Scholar] [CrossRef]
- He, J.; Xu, L.; Wang, P.; Wang, Q. A high precise E-nose for daily indoor air quality monitoring in living environment. Integr.-VLSI J. 2016, 58, 286–294. [Google Scholar] [CrossRef]
- Kiani, S.; Minaei, S.; Ghasemi-Varnamkhasti, M. Application of electronic nose systems for assessing quality of medicinal and aromatic plant products: A review. J. Appl. Res. Med. Aromat. Plants 2016, 3, 1–9. [Google Scholar] [CrossRef]
- Dymerski, T.; Gębicki, J.; Wardencki, W.; Namieśnik, J. Application of an Electronic Nose Instrument to Fast Classification of Polish Honey Types. Sensors 2014, 14, 10709–10724. [Google Scholar] [CrossRef] [PubMed]
- Banerjee, R.; Tudu, B.; Shaw, L.; Jana, A.; Bhattacharyya, N.; Bandyopadhyay, R. Instrumental testing of tea by combining the responses of electronic nose and tongue. J. Food Eng. 2012, 110, 356–363. [Google Scholar] [CrossRef]
- Valdez, L.F.; Gutiérrez, J.M. Chocolate Classification by an Electronic Nose with Pressure Controlled Generated Stimulation. Sensors 2016, 16, 1745. [Google Scholar] [CrossRef] [PubMed]
- Aleixandre, M.; Santos, J.P.; Sayago, I.; Cabellos, J.M.; Arroyo, T.; Horrillo, M.C. A wireless and portable electronic nose to differentiate musts of different ripeness degree and grape varieties. Sensors 2015, 15, 8429–8443. [Google Scholar] [CrossRef] [PubMed]
- Fujioka, K.; Tomizawa, Y.; Shimizu, N.; Ikeda, K.; Manome, Y. Improving the Performance of an Electronic Nose by Wine Aroma Training to Distinguish between Drip Coffee and Canned Coffee. Sensors 2015, 15, 1354–1364. [Google Scholar] [CrossRef] [PubMed]
- Ferreiro-González, M.; Barbero, G.F.; Palma, M.; Ayuso, J.; Álvarez, J.A.; Barroso, C.G. Determination of Ignitable Liquids in Fire Debris: Direct Analysis by Electronic Nose. Sensors 2016, 16, 695. [Google Scholar] [CrossRef] [PubMed]
- Szulczyński, B.; Namieśnik, J.; Gębicki, J. Determination of Odour Interactions of Three-Component Gas Mixtures Using an Electronic Nose. Sensors 2017, 17. [Google Scholar] [CrossRef] [PubMed]
- Conner, L.; Chin, S.; Furton, K.G. Evaluation of field sampling techniques including electronic noses and a dynamic headspace sampler for use in fire investigations. Sens. Actuators B 2006, 116, 121–129. [Google Scholar] [CrossRef]
- Feldhoff, R.; Bernadet, P.; Saby, C.A. Discrimination of diesel fuels with chemical sensors and mass spectrometry based electronic noses. Analyst 1999, 124, 1167–1173. [Google Scholar] [CrossRef]
- Gobbi, E.; Falasconi, M.; Zambotti, G.; Sberveglieri, V.; Pulvirenti, A.; Sberveglieri, G. Rapid diagnosis of Enterobacteriaceae in vegetable soups by a metal oxide sensor based electronic nose. Sens. Actuators B 2015, 207, 1104–1113. [Google Scholar] [CrossRef]
- Berkhout, D.J.C.; Benninga, M.A.; Stein, R.M.V.; Brinkman, P.; Niemarkt, H.J.; Boer, N.K.H.D.; Meij, T.G.J.D. Effects of Sampling Conditions and Environmental Factors on Fecal Volatile Organic Compound Analysis by an Electronic Nose Device. Sensors 2016, 16, 1967. [Google Scholar] [CrossRef] [PubMed]
- Herrero, J.L.; Lozano, J.; Santos, J.P.; Suárez, J.I. On-line classification of pollutants in water using wireless portable electronic noses. Chemosphere 2016, 152, 107–116. [Google Scholar] [CrossRef] [PubMed]
- Huang, T.; Jia, P.; He, P.; Duan, S.; Jia, Y.; Wang, L. A Novel Semi-Supervised Method of Electronic Nose for Indoor Pollution Detection Trained by M-S4VMs. Sensors 2016, 16, 1462. [Google Scholar] [CrossRef] [PubMed]
- Jun, F.; Canqin, H.; Jianguo, X.; Junbao, Z. Pattern Classification Using an Olfactory Model with PCA Feature Selection in Electronic Noses: Study and Application. Sensors 2012, 12, 2818–2830. [Google Scholar] [CrossRef]
- Yu, H.C.; Wang, Y.W.; Wang, J. Identification of tea storage times by linear discrimination analysis and back-propagation neural network techniques based on the eigenvalues of principal components analysis of E-nose sensor signals. Sensors 2009, 9, 8073–8082. [Google Scholar] [CrossRef] [PubMed]
- Zugasti, E.; Mujica, L.E.; Anduaga, J.; MartãNez, F. Feature Selection—Extraction Methods Based on PCA and Mutual Information to Improve Damage Detection Problem in Offshore Wind Turbines. Key Eng. Mater. 2013, 569–570, 620–627. [Google Scholar] [CrossRef]
- Hines, E.L.; Boilot, P.; Gardner, J.W.; Gongora, M.A. Pattern Analysis for Electronic Noses. In Handbook of Machine Olfaction: Electronic Nose Technology; Pearce, T.C., Schiffman, S.S., Nagle, H.T., Gardner, J.W., Eds.; Wiley-VCHVerlag GmbH & Co. KGaA: Weinheim, Germany, 2003; pp. 133–160. [Google Scholar]
- Hong, X.; Wang, J.; Qiu, S. Authenticating cherry tomato juices—Discussion of different data standardization and fusion approaches based on electronic nose and tongue. Food Res. Int. 2014, 60, 173–179. [Google Scholar] [CrossRef]
- Daikuzono, C.M.; Shimizu, F.M.; Manzoli, A.; Antonio Riul, J.; Piazzetta, M.H.O.; Gobbi, A.L.; Correa, D.S.; Paulovich, F.V.; Oliveira, O.N., Jr. Information Visualization and Feature Selection Methods Applied to Detect Gliadin in Gluten-Containing Foodstuff with a Microfluidic Electronic Tongue. ACS Appl. Mater. Interfaces 2017, 9, S1–S10. [Google Scholar] [CrossRef] [PubMed]
- Cheng, H.; Qin, Z.H.; Guo, X.F.; Hu, X.S.; Wu, J.H. Geographical origin identification of propolis using GC–MS and electronic nose combined with principal component analysis. Food Res. Int. 2013, 51, 813–822. [Google Scholar] [CrossRef]
- Ammar, Z.; Md, S.; Hamid, A.; Noor, A.; Jamilah, M.; Abdul, A. Improved classification oforthosiphon stamineusby data fusion of electronic nose and tongue sensors. Sensors 2010, 10, 8782–8796. [Google Scholar] [CrossRef]
- Chen, Y. Reference-Related Component Analysis: A New Method Inheriting the Advantages of PLS and PCA for Separating Interesting Information and Reducing Data Dimension. Chemom. Intell. Lab. Syst. 2016, 156, 196–202. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, M.; Ma, J.; Zhang, Y.; Hong, G.; Sun, F.; Lin, G.; Hu, L. Metabolic changes in paraquat poisoned patients and support vector machine model of discrimination. Biol. Pharm. Bull. 2014, 38, 470–475. [Google Scholar] [CrossRef] [PubMed]
- Wei, Z.; Wang, J. Tracing floral and geographical origins of honeys by potentiometric and voltammetric electronic tongue. Comput. Electron. Agric. 2014, 108, 112–122. [Google Scholar] [CrossRef]
- Brudzewski, K.; Osowski, S.; Markiewicz, T. Classification of milk by means of an electronic nose and SVM neural network. Sens. Actuators B 2004, 98, 291–298. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the Third International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar] [CrossRef]
- Nitze, I.; Barrett, B.; Cawkwell, F. Temporal optimisation of image acquisition for land cover classification with Random Forest and MODIS time-series. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 136–146. [Google Scholar] [CrossRef]
- Abdel-Rahman, E.M.; Mutanga, O.; Adam, E.; Ismail, R. Detecting Sirex noctilio grey-attacked and lightning-struck pine trees using airborne hyperspectral data, random forest and support vector machines classifiers. ISPRS-J. Photogramm. Remote Sens. 2014, 88, 48–59. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B-Cybern. 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.; Huang, G.B.; Song, S.; You, K. Trends in extreme learning machines: A review. Neural Netw. 2015, 61, 32–48. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time | Selected Variable | Cross-Validation Discrimination Function |
|---|---|---|
| 1 | t1 | 1 |
| 2 | t2 | 0.7896 |
| 3 | t3 | 0.2248 |
| 4 | t4 | 0.1760 |
| 5 | t5 | −0.0638 |
| Feature Set | Best Parameter | Accuracy Rate for Training Set (%) | Accuracy Rate for 3-Fold Cross-Validation (%) | Accuracy Rate for Test Set (%) | |
|---|---|---|---|---|---|
| Penalty Factor c | Kernel Parameter γ | ||||
| #PCA | 1 | 1.4142 | 100 | 100 | 100 |
| #PLS | 0.00097656 | 0.00087656 | 100 | 100 | 100 |
| #Complete | 1.4142 | 0.35355 | 100 | 100 | 100 |
| Feature Set | The Best Parameter | Training Set | Test Set | |||
|---|---|---|---|---|---|---|
| c | γ | R2 | RMSE | R2 | RMSE | |
| #PCA | 32 | 0.1767 | 0.9829 | 00481 | 0.9502 | 0.1376 |
| #PLS | 5.6596 | 0.125 | 0.9894 | 0.0491 | 0.9639 | 0.1968 |
| #Complete | 2.8284 | 0.0883 | 0.9974 | 0.0289 | 0.8913 | 0.1317 |
| Feature Set | Maximum Error | Minimum Error |
|---|---|---|
| #PCA | 0.1448 | 0.0041 |
| #PLS | 0.2163 | 0.0044 |
| #Complete | 0.1690 | 0.0016 |
| Feature Set | Training Set | Test Set | ||
|---|---|---|---|---|
| R2 | RMSE | R2 | RMSE | |
| #PCA | 0.9767 | 0.1951 | 0.8717 | 0.3707 |
| #PLS | 0.9869 | 0.1197 | 0.9645 | 0.2022 |
| #Complete | 0.9865 | 0.1089 | 0.9896 | 0.1537 |
| Feature Set | Maximum Error | Minimum Error |
|---|---|---|
| #PCA | 0.3494 | 0.0121 |
| #PLS | 0.1793 | 0.0024 |
| #Complete | 0.1266 | 0.0045 |
| Feature Set | Training Set | TEST SET | ||
|---|---|---|---|---|
| R2 | RMSE | R2 | RMSE | |
| #PCA | 0.9730 | 0.0727 | 0.9438 | 0.1437 |
| #PLS | 0.9972 | 0.0208 | 0.9675 | 0.1793 |
| #Complete | 0.9878 | 0.0472 | 0.9341 | 0.1741 |
| Feature Set | Maximum Error | Minimum Error |
|---|---|---|
| #PCA | 0.1487 | 0.0016 |
| #PLS | 0.1239 | 0.0061 |
| #Complete | 0.1804 | 0.0033 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Men, H.; Fu, S.; Yang, J.; Cheng, M.; Shi, Y.; Liu, J. Comparison of SVM, RF and ELM on an Electronic Nose for the Intelligent Evaluation of Paraffin Samples. Sensors 2018, 18, 285. https://doi.org/10.3390/s18010285
Men H, Fu S, Yang J, Cheng M, Shi Y, Liu J. Comparison of SVM, RF and ELM on an Electronic Nose for the Intelligent Evaluation of Paraffin Samples. Sensors. 2018; 18(1):285. https://doi.org/10.3390/s18010285
Chicago/Turabian StyleMen, Hong, Songlin Fu, Jialin Yang, Meiqi Cheng, Yan Shi, and Jingjing Liu. 2018. "Comparison of SVM, RF and ELM on an Electronic Nose for the Intelligent Evaluation of Paraffin Samples" Sensors 18, no. 1: 285. https://doi.org/10.3390/s18010285
APA StyleMen, H., Fu, S., Yang, J., Cheng, M., Shi, Y., & Liu, J. (2018). Comparison of SVM, RF and ELM on an Electronic Nose for the Intelligent Evaluation of Paraffin Samples. Sensors, 18(1), 285. https://doi.org/10.3390/s18010285