Domain Correction Based on Kernel Transformation for Drift Compensation in the E-Nose System


Abstract
:1. Introduction
2. Related Work
2.1. Sensor Drift Compensation
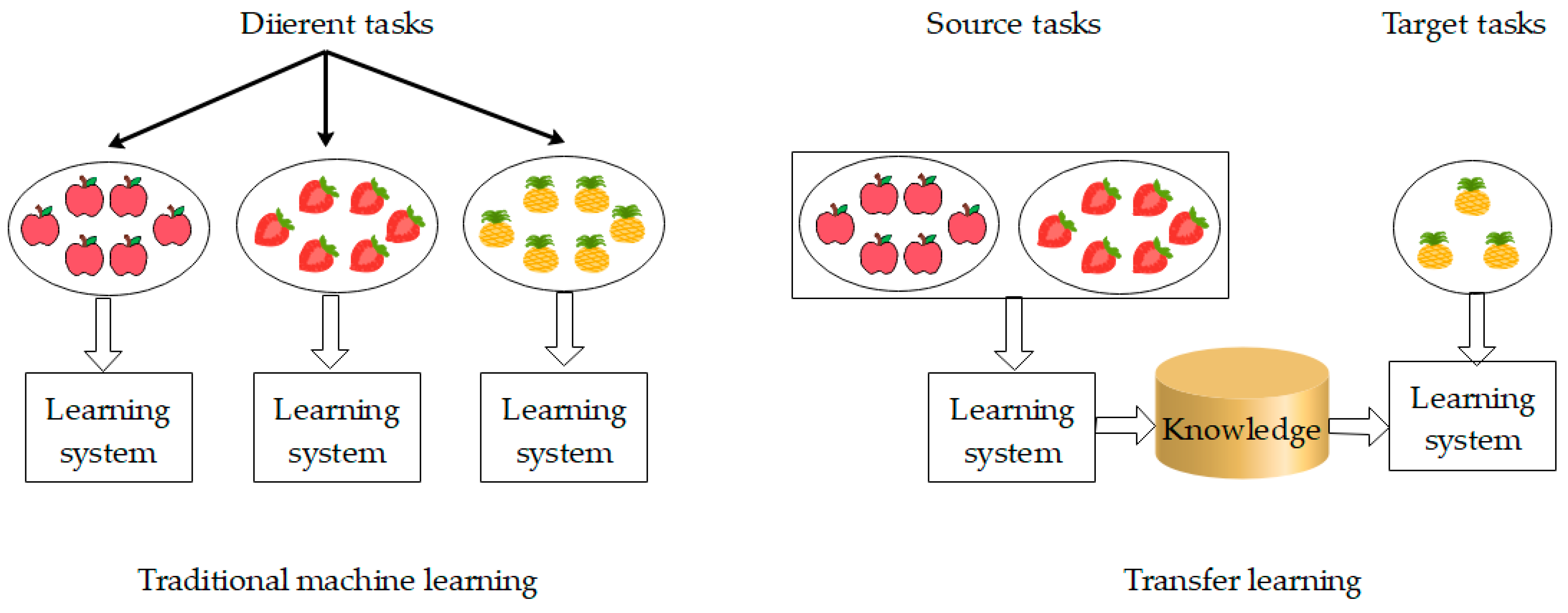
2.2. Transfer Learning
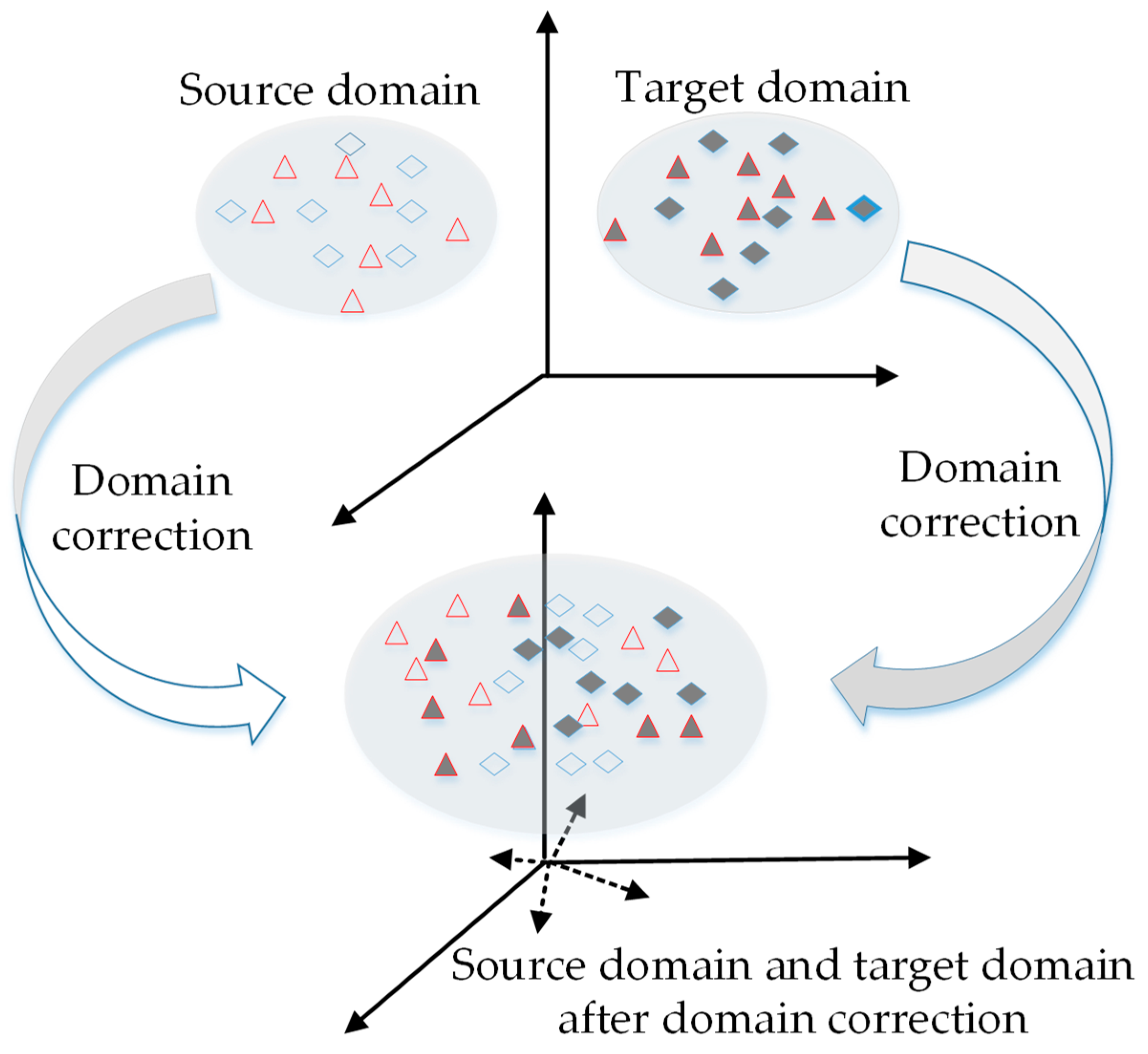
3. Domain Correction Based on Kernel Transformation (DCKT)
3.1. Notation
3.2. Domain Correction Based on Kernel Transformation
| Algorithm 1 DCKT |
| Input: Source data , target data , source label , regularization coefficients , and dimension m: Procedure: 1. Construct the kernel matrix K from and via (2), matric L via (3), and centering matric H via (6); 2. Solve the eigendecomposition of ; 3. Build P by m smallest eigenvectors via (8); 4. Compute the mapped source domain data ; 5. Compute the mapped target domain data ; 6. Train the SVM classifier with , and predict the odor label of ; |
| Output: The classification results of target data. |
4. Experimental and Performance Evaluation
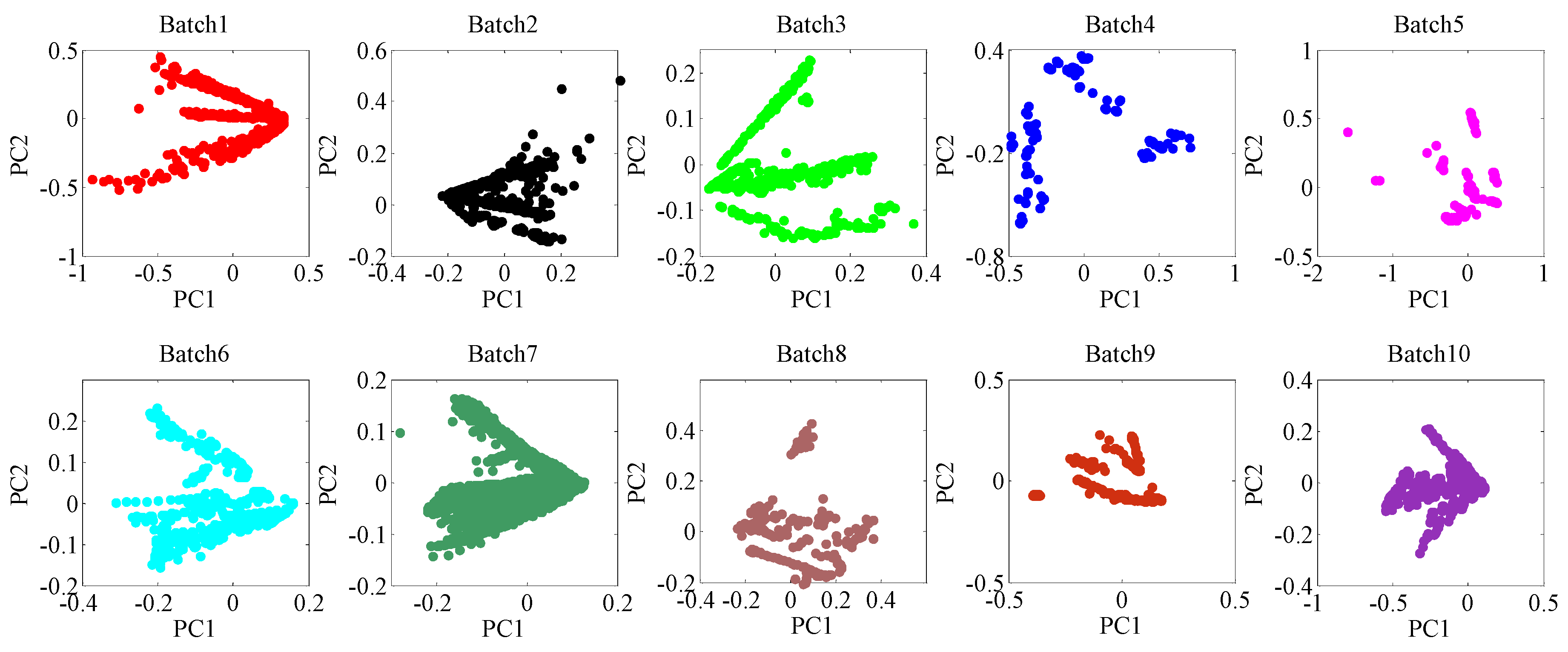
4.1. Experimental Data
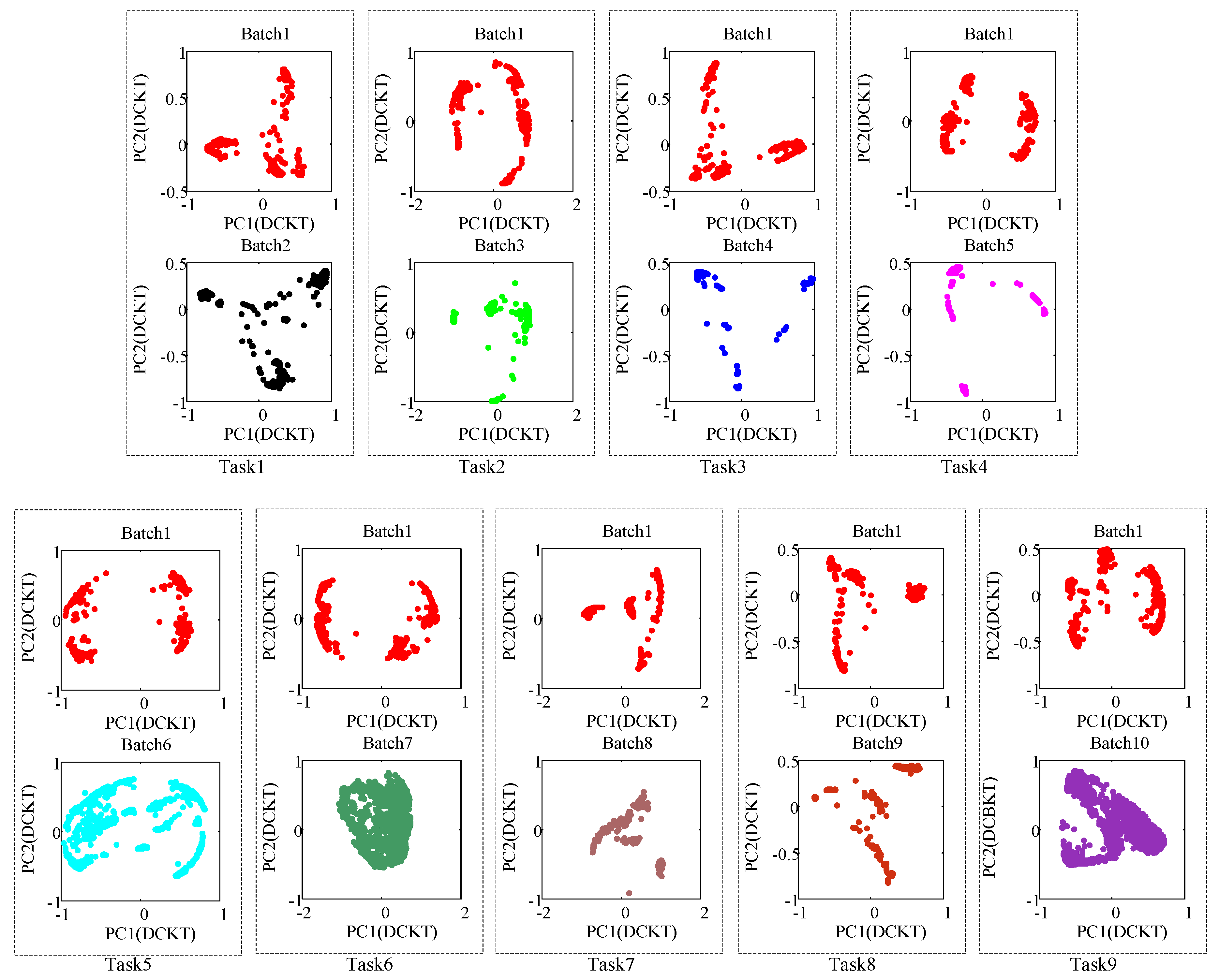
4.2. Qualitative Result
4.3. Quantitative Result
- Setting 1: Take Batch 1 as source domain for model training, and test on Batch i, i = 2, 3, ..., 10.
- Setting 2: Take Batch i as source domain for model training, and test on Batch (i + 1), i = 2, 3, ..., 10.
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Gutierrezosuna, R. Pattern analysis for machine olfaction: A review. IEEE Sens. J. 2002, 2, 189–202. [Google Scholar] [CrossRef]
- Marco, S.; Gutierrez-Galvez, A. Signal and Data Processing for Machine Olfaction and Chemical Sensing: A Review. IEEE Sens. J. 2012, 12, 3189–3214. [Google Scholar] [CrossRef]
- Laref, R.; Losson, E.; Sava, A.; Adjallah, K.; Siadat, M. A comparison between SVM and PLS for E-nose based gas concentration monitoring. In Proceedings of the 2018 IEEE International Conference on Industrial Technology (ICIT), Lyon, France, 20–22 February 2018. [Google Scholar]
- Modak, A.; Roy, R.B.; Tudu, B.; Bandyopadhyay, R.; Bhattacharyya, N. A novel fuzzy based signal analysis technique in electronic nose and electronic tongue for black tea quality analysis. In Proceedings of the 2016 IEEE First International Conference on Control, Measurement and Instrumentation (CMI), Kolkata, India, 8–10 January 2016. [Google Scholar]
- Paknahad, M.; Ahmadi, A.; Rousseau, J.; Nejad, H.R.; Hoorfar, M. On-Chip Electronic Nose for Wine Tasting: A Digital Microfluidic Approach. IEEE Sens. J. 2017, 17, 4322–4329. [Google Scholar] [CrossRef]
- Chen, L.Y.; Wong, D.M.; Fang, C.Y.; Chiu, C.I.; Chou, T.I.; Wu, C.C.; Chiu, S.W.; Tang, K.T. Development of an electronic-nose system for fruit maturity and quality monitoring. In Proceedings of the 2018 IEEE International Conference on Applied System Invention (ICASI), Chiba, Japan, 13–17 April 2018. [Google Scholar]
- Liang, Z.; Tian, F.; Zhang, C.; Sun, H.; Liu, X.; Yang, S.X. A correlated information removing based interference suppression technique in electronic nose for detection of bacteria. Anal. Chim. Acta 2017, 986, 145–152. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez-Lujan, I.; Fonollosa, J.; Vergara, A.; Homer, M.; Huerta, R. On the calibration of sensor arrays for pattern recognition using the minimal number of experiments. Chemom. Intell. Lab. Syst. 2014, 130, 123–134. [Google Scholar] [CrossRef]
- Jha, S.K.; Hayashi, K.; Yadava, R.D.S. Neural, fuzzy and neuro-fuzzy approach for concentration estimation of volatile organic compounds by surface acoustic wave sensor array. Measurement 2014, 55, 186–195. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, D.; Yin, X.; Liu, Y. A Novel Semi-Supervised Learning Approach in Artificial Olfaction for E-Nose Application. IEEE Sens. J. 2016, 16, 4919–4931. [Google Scholar] [CrossRef]
- Dixon, S.J.; Brereton, R.G. Comparison of performance of five common classifiers represented as boundary methods: Euclidean Distance to Centroids, Linear Discriminant Analysis, Quadratic Discriminant Analysis, Learning Vector Quantization and Support Vector Machines, as dependent on data structure. Chemom. Intell. Lab. Syst. 2009, 95, 1–17. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Xue, Y.; Hu, Y.; Yang, J.; Qiang, C. Land evaluation based on SFAM neural network ensemble. Trans. Chin. Soc. Agric. Eng. 2008, 24, 184–188. [Google Scholar]
- Vapnik, V.N. The Nature of Statistical Learning Theory. IEEE Trans. Neural Netw. 2002, 8, 1564. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Tian, F.; Nie, H.; Dang, L.; Li, G.; Ye, Q.; Kadri, C. Classification of multiple indoor air contaminants by an electronic nose and a hybrid support vector machine. Sens. Actuators B Chem. 2012, 174, 114–125. [Google Scholar] [CrossRef]
- Wolfrum, E.J.; Meglen, R.M.; Peterson, D.; Sluiter, J. Metal oxide sensor arrays for the detection, differentiation, and quantification of volatile organic compounds at sub-parts-per-million concentration levels. Sens. Actuators B Chem. 2006, 115, 322–329. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef] [Green Version]
- Carlo, S.D.; Falasconi, M. Drift Correction Methods for Gas Chemical Sensors in Artificial Olfaction Systems: Techniques and Challenges. Adv. Chem. Sens. 2012, 305–326. [Google Scholar] [CrossRef]
- Güney, S.; Atasoy, A. An electronic nose system for assessing horse mackerel freshness. In Proceedings of the 2012 International Symposium on Innovations in Intelligent Systems and Applications, Trabzon, Turkey, 2–4 July 2012. [Google Scholar]
- Liang, Z.; Tian, F.; Yang, S.X.; Zhang, C.; Sun, H.; Liu, T. Study on Interference Suppression Algorithms for Electronic Noses: A Review. Sensors 2018, 18, 1179. [Google Scholar] [CrossRef] [PubMed]
- Artursson, T.; Eklöv, T.; Lundström, I.; Mårtensson, P.; Sjöström, M.; Holmberg, M. Drift correction for gas sensors using multivariate methods. J. Chemom. 2010, 14, 711–723. [Google Scholar] [CrossRef]
- Jia, P.; Tian, F.; He, Q.; Feng, J.; Shen, Y.; Fan, S. Improving the performance of electronic nose for wound infection detection using orthogonal signal correction and particle swarm optimization. Sens. Rev. 2014, 34, 389–395. [Google Scholar]
- Padilla, M.; Perera, A.; Montoliu, I.; Chaudry, A.; Persaud, K.; Marco, S. Drift compensation of gas sensor array data by Orthogonal Signal Correction. Chemom. Intell. Lab. Syst. 2010, 100, 28–35. [Google Scholar] [CrossRef] [Green Version]
- Kerdcharoen, T. Electronic nose based wireless sensor network for soil monitoring in precision farming system. In Proceedings of the 2017 9th International Conference on Knowledge and Smart Technology (KST), Chonburi, Thailand, 1–4 February 2017. [Google Scholar]
- Vito, S.D.; Fattoruso, G.; Pardo, M.; Tortorella, F.; Francia, G.D. Semi-Supervised Learning Techniques in Artificial Olfaction: A Novel Approach to Classification Problems and Drift Counteraction. IEEE Sens. J. 2012, 12, 3215–3224. [Google Scholar] [CrossRef]
- Al-Maskari, S.; Li, X.; Liu, Q. An Effective Approach to Handling Noise and Drift in Electronic Noses. Databases Theory Appl. 2014, 8506, 223–230. [Google Scholar]
- Vergara, A.; Vembu, S.; Ayhan, T.; Ryan, M.A.; Homer, M.L.; Huerta, R. Chemical gas sensor drift compensation using classifier ensembles. Sens. Actuators B Chem. 2012, 166–167, 320–329. [Google Scholar] [CrossRef]
- Yan, K.; Zhang, D. Correcting Instrumental Variation and Time-Varying Drift: A Transfer Learning Approach with Autoencoders. IEEE Trans. Instrum. Meas. 2016, 65, 2012–2022. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, D. Domain Adaptation Extreme Learning Machines for Drift Compensation in E-Nose Systems. IEEE Trans. Instrum. Meas. 2015, 64, 1790–1801. [Google Scholar] [CrossRef]
- Yan, K.; Zhang, D. Calibration transfer and drift compensation of e-noses via coupled task learning. Sens. Actuators B Chem. 2016, 225, 288–297. [Google Scholar] [CrossRef]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain Adaptation via Transfer Component Analysis. IEEE Trans. Neural Netw. 2011, 22, 199–210. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Muller, K.; Mika, S.; Ratsch, G.; Tsuda, K.; Scholkopf, B.; Müller, K.R.; Rätsch, G.; Schölkopf, B. An introduction to kernel-based learning algorithms. IEEE Trans. Neural Netw. 2001, 12, 181–201. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, L.; Liu, Y.; He, Z.; Liu, J.; Deng, P. Anti-drift in E-nose: A subspace projection approach with drift reduction. Sens. Actuators B Chem. 2017, 253, 407–417. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Batch ID | Month | Acetone | Acetaldehyde | Ethanol | Ethylene | Ammonia | Toluene |
|---|---|---|---|---|---|---|---|
| Batch 1 | 1,2 | 90 | 98 | 83 | 30 | 70 | 74 |
| Batch 2 | 3,4,8–10 | 164 | 334 | 100 | 109 | 532 | 5 |
| Batch 3 | 11~13 | 365 | 490 | 216 | 240 | 275 | 0 |
| Batch 4 | 14,15 | 64 | 43 | 12 | 30 | 12 | 0 |
| Batch 5 | 16 | 28 | 40 | 20 | 46 | 63 | 0 |
| Batch 6 | 17~20 | 514 | 574 | 110 | 29 | 606 | 467 |
| Batch 7 | 21 | 649 | 662 | 360 | 744 | 630 | 568 |
| Batch 8 | 22,23 | 30 | 30 | 40 | 33 | 143 | 18 |
| Batch 9 | 24,30 | 61 | 55 | 100 | 75 | 78 | 101 |
| Batch 10 | 36 | 600 | 600 | 600 | 600 | 600 | 600 |
| Methods | Batch ID | Average Value | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| PCASVM | 82.40 | 84.80 | 80.12 | 75.13 | 73.57 | 56.16 | 48.64 | 67.45 | 49.14 | 68.60 |
| LDASVM | 47.27 | 57.76 | 50.93 | 62.44 | 41.48 | 37.42 | 68.37 | 52.34 | 31.17 | 49.91 |
| SVM-rbf | 74.36 | 61.03 | 50.93 | 18.27 | 28.26 | 28.81 | 20.07 | 34.26 | 34.47 | 38.94 |
| SVM-comgfk | 74.47 | 70.15 | 59.78 | 75.09 | 73.99 | 54.59 | 55.88 | 70.23 | 41.85 | 64.00 |
| DS | 69.37 | 46.28 | 41.61 | 58.88 | 48.83 | 32.83 | 23.47 | 72.55 | 29.03 | 46.98 |
| DRCA | 89.15 | 92.69 | 87.58 | 95.94 | 86.52 | 60.25 | 62.24 | 72.34 | 52.00 | 77.63 |
| DCKT | 90.27 | 90.29 | 83.23 | 76.14 | 96.26 | 75.51 | 66.67 | 71.06 | 65.06 | 79.39 |
| Batch ID | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|
| 0.001 | 10,000 | 20 | 1000 | 0.001 | 1000 | 10,000 | 1000 | 10,000 | |
| m | 16 | 5 | 8 | 11 | 8 | 8 | 4 | 11 | 5 |
| Methods | Batch ID | Average Value | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1⟶2 | 2⟶3 | 3⟶4 | 4⟶5 | 5⟶6 | 6⟶7 | 7⟶8 | 8⟶9 | 9⟶10 | ||
| PCASVM | 82.40 | 98.87 | 83.23 | 72.59 | 36.70 | 74.98 | 58.16 | 84.04 | 30.61 | 69.06 |
| LDASVM | 47.27 | 46.72 | 70.81 | 85.28 | 48.87 | 75.15 | 77.21 | 62.77 | 30.25 | 60.48 |
| SVM-rbf | 74.36 | 87.83 | 90.06 | 56.35 | 42.52 | 83.53 | 91.84 | 62.98 | 22.64 | 68.01 |
| SVM-comgfk | 74.47 | 73.75 | 78.51 | 64.26 | 69.97 | 77.69 | 82.69 | 85.53 | 17.76 | 69.40 |
| DS | 69.37 | 53.59 | 67.08 | 37.56 | 36.30 | 26.57 | 49.66 | 42.55 | 25.78 | 45.38 |
| DRCA | 89.15 | 98.11 | 95.03 | 69.54 | 50.87 | 78.94 | 65.99 | 84.04 | 36.31 | 74.22 |
| DCKT | 90.27 | 91.87 | 90.68 | 97.46 | 75.30 | 78.88 | 75.22 | 97.66 | 57.36 | 83.78 |
| Batch ID | 1⟶2 | 2⟶3 | 3⟶4 | 4⟶5 | 5⟶6 | 6⟶7 | 7⟶8 | 8⟶9 | 9⟶10 |
|---|---|---|---|---|---|---|---|---|---|
| 0.001 | 10,000 | 0.001 | 0.001 | 10,000 | 10,000 | 10,000 | 1000 | 10,000 | |
| m | 16 | 8 | 32 | 32 | 7 | 64 | 8 | 64 | 17 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tao, Y.; Xu, J.; Liang, Z.; Xiong, L.; Yang, H. Domain Correction Based on Kernel Transformation for Drift Compensation in the E-Nose System. Sensors 2018, 18, 3209. https://doi.org/10.3390/s18103209
Tao Y, Xu J, Liang Z, Xiong L, Yang H. Domain Correction Based on Kernel Transformation for Drift Compensation in the E-Nose System. Sensors. 2018; 18(10):3209. https://doi.org/10.3390/s18103209
Chicago/Turabian StyleTao, Yang, Juan Xu, Zhifang Liang, Lian Xiong, and Haocheng Yang. 2018. "Domain Correction Based on Kernel Transformation for Drift Compensation in the E-Nose System" Sensors 18, no. 10: 3209. https://doi.org/10.3390/s18103209
APA StyleTao, Y., Xu, J., Liang, Z., Xiong, L., & Yang, H. (2018). Domain Correction Based on Kernel Transformation for Drift Compensation in the E-Nose System. Sensors, 18(10), 3209. https://doi.org/10.3390/s18103209