1. Introduction
The classification of Synthetic Aperture Radar (SAR) targets into different classes is one of the most challenging algorithmic aspects of radar structures. Unlike optical remote sensing, which cannot achieve its role in bad weather and at night, SAR can operate in all-weather conditions day-and-night and make very high resolution images, and it has played an important role in military and civil applications, such as target classification, reconnaissance, and surveillance. However, the comprehension of SAR images requires specialists, because unlike natural images, SAR images reflect the backscattering electromagnetic wave intensity of targets and speckle. Moreover, for humans, searching for targets of interest in the massive SAR images will take a lot of time. Furthermore, SAR images are covered with speckle noise, which is an important reason behind the reduction of the images quality. Besides this, they are very sensitive to the variation of target pose, and vary suddenly and quickly with small change in aspect angles. Therefore, SAR Automatic Target Recognition (ATR) is a demanding mission and has become a serious research topic for many applications. In the last decade, several methods were proposed in order to analyze and classify SAR images. A basic architecture of SAR ATR was defined as three phases: Detection, discrimination, and classification [
1]. The primary two stages, also known as prescreening and low-level classification (LLC), are ordinarily referred to as the focus-of-attention module [
2]. Detection is to excerpt candidate targets from SAR images via a Constant False Alarm Rate (CFAR) detector [
3]. The output includes targets of interests such as armored vehicles, missile launchers, and tanks as well as false alarm clutter such as buildings, bridges, trees, and cars. In order to dispose of false alarms, several features are chosen to train a discriminator to distinguish between the two classes (target and clutter), which is the discrimination stage [
4]. The third stage, also called high-level classification (HLC) [
5], aims to classify the targets into different categories, which is the focus of this research.
Of the numerous methods, each approach that has been proposed to deal with the classification stage is included in one of the three main taxonomies, namely template-based [
6], model-based [
7] and pattern-based [
8]. In recent years, pattern-based algorithms have made significant breakthroughs in the image classification process. A variety of architectures have been proposed, and they are based on first designing a set of different features to represent the targets by extracting them directly from the raw images, and then using these feature vectors to train a classifier and hence the classification problem is solved. To obtain a suitable classification performance, the features together with the classifiers should be carefully constructed. On one hand, numerous algorithms are employed for feature extraction, for instance, scale invariant feature transform (SIFT) [
9], histogram of oriented gradients (HOG) [
10], non-negative Matrix Factorization (NMF) [
11,
12], Principal Component Analysis (PCA) [
13,
14], deep Convolutional Neural Networks (CNNs) [
15,
16]. On the other hand, several robust trainable classifiers have been developed such as mean square error (MSE) classifier [
17], Bayes classifier [
18] and support vector machine (SVM) [
19].
Deep CNN is currently one of the most promising technologies for classification. It has obtained the state-of-the-art results for object detection and automated land cover classification in high-resolution remote-sensing imagery. Deep CNN has been used to classify a wide variety of remotely sensed imagery, including SAR images [
20], hyperspectral [
21], and high resolution electro-optical imagery [
22]. Different from methods based on hand-crafted feature extraction, the deep CNN based method automatically learns the feature from large-scale datasets, and achieves extraordinary performance in object recognition. The goal of CNN is to catch exceptional representations, usually at various levels, using the unknown structure in the input data, where lower-level features make it possible to define and learn higher-level features and make them more abstract, with their individual features. Then, these discovered features are more invariant to most of the variations commonly present in the raw training distribution, while collectively conserving the essential information in the input. Taking the tremendous progress deep learning has made in object recognition into consideration, deep CNNs are expected to also solve the SAR target recognition issue. Several researchers replicate architectures of deep CNN, which were successfully applied on object classification on SAR images. However, they did not obtain the same results because training a deep CNN requires a very large dataset such as ImageNet [
23,
24,
25,
26], which is clearly not the case of SAR images. Nonetheless, the limited labeled SAR target data have not stopped researchers from achieving better classification rates. To address this problem, numerous approaches have been employed to achieve better results on SAR images like transfer learning and training CNN from scratch.
One technique consists of applying transfer learning from pre-trained deep CNNs that can be modified to produce accurate classifications for specific applications. The main idea of CNN transfer learning is to use the power of networks that are already trained on a large-scale data set of general images in different application areas. These types of networks can be regarded as general feature extractors or classifiers. This technique can be successfully applied in cases where we do not have a large data set for training a CNN from scratch. There are three famous scenarios for transfer learning of a CNN: A pre-trained net is used as a fixed feature extractor, a pre-trained net is used for fine-tuning and a pre-trained net is used for initialization in training from scratch [
27,
28,
29]. In the first approach, a neural network is trained with an independent general data set of images and the output of the network can be interpreted as a feature vector and used for further classification. In addition, features from the previous to last hidden layer can be used for classification. The fine-tuning method is based on the idea of training the last layers of the network to specialize them for a particular data set. The main benefits of this method are reduced training time and the possibility of effective training with a small data set. However, this technique does not perform well on SAR images since they refer to the backscattering characteristics of the ground features, representing a list of scattering centers, and each pixel intensity of the image depends on a range of factors, such as shapes, orientations and types of the scatterers in the area where the target is located. Other techniques were proposed to overcome this problem, one of which consist of training a CNN from scratch using data augmentation to increase the size of data [
20]. Another method uses transfer learning from pre-trained deep CNN. However, instead of using optical images data set in the training, it uses a large number of unlabeled SAR scene images [
27].
Another interesting point that is worth noting is the use of feature coding approaches in the process of images classification. The Bag-of-Words (BoW) [
30] approach is one of the famous models in this field. In order to have good classification accuracy, three steps were performed: First extract the features, then generate a codebook, and after that a histogram is generated to represent each image. Many modern approaches are based on the BoW model; for example Reference [
31] proposed a supervised incremental coding method based on the BoW model and proved that this method yielded much better features for SAR image classification. One recent method uses Fisher Vectors (FVs), which are in essence an image representation obtained by pooling local image features, and they are used as a global image descriptor in image classification. Compared to the previous coding approaches, its advantages are: First, its ability to store second-order information about the features. Secondly, FVs utilize Gaussian Mixture Models (GMMs) to generate the feature vocabulary. Therefore, it generates a probabilistic visual vocabulary instead of using a hard codebook, which allows it to be more flexible. This is an important feature, which helps in increasing the accuracy performance.
Another important technique that can be utilized to improve classification accuracy is fusion. Sensor fusion is a common technique in signal processing to combine data from various sensors. Feature fusion is another current method, ranging from simple concatenation to very advanced methods like fuzzy integrals. Finally, information fusion merges independent results from signal processing techniques that otherwise can be used alone as the final signal processing result. For example, Reference [
32] has obtained good results by using some of these techniques on Land Cover High-Resolution Imagery.
The CNN architectures proposed in the literature have proven that the activations from high-level layers of CNNs can generate powerful feature representations with outstanding performance. However, we noticed that the best classification accuracy for individual SAR classes varied among the different CNN architectures. In addition, features extracted from lower-level layers, particularly the convolutional layers, lack sufficient study. Only a few works has been conducted in this area; for example, Reference [
33] used cross-layer CNN features extracted from multiple layers of CNN for generic classification tasks. Reference [
34] on the other hand has used features extracted from the last convolutional layer of deep CNN using transfer learning for the scene classification of high-Resolution remote sensing images. They both demonstrate the capacity of lower-level layers of CNN architectures to achieve better performance.
The two reasons mentioned above encourage us to propose a new framework. The framework is drawn from the most contemporary techniques in image processing and deep learning. It is a combination of three different CNNs. The three CNNs have the same architecture; the main difference is the sizes of the convolution and pooling kernel in each one of them: Coarse Grain CNN (CG-CNN), Middle Grain CNN (MG-CNN) and Fine Grain CNN (FG-CNN). We train each CNN from scratch using the chosen sizes of convolutional and pooling kernel. We show that through a combination of recent techniques, we can obtain significant performance improvement on the Moving and Stationary Target Acquisition and Recognition (MSTAR) dataset classification task. We investigate how to obtain better accuracy classification compared to the state-of-the-art results that use the same dataset without data augmentation by forming better representations from the SAR images using CNNs activations. By deleting the last few layers of a CNN, we handle the remainder of the CNN as a fixed feature extractor. Considering that these CNNs are broad multi-layer architectures, we consider two ways of extracting CNN features with reference to different layers:
We simply calculate the CNN activations for the entire SAR images and consider the Fully-Connected (FC) layer activation vectors as the global feature representations for all images.
We first compute dense CNN activations from the last convolutional layer of the input image, and then we convert them into a global representation using the Fisher encoding. Then, the global features of the image are fed to a simple classifier for the classification task.
Extensive experiments prove that powerful features SAR images can be generated. The resulting features and classification outputs from each of these CNNs are then either combined or fused using a variety of methods into a final refined classification. Evaluation of the proposed approach is conducted with the MSTAR benchmark data set. Experimental results validate the superiority and effectiveness of the proposed approach.
The paper is formulated as follows. In
Section 2, we briefly review some related works corresponding to some state-of-the-art SAR images classification methods.
Section 3 describes the main methods and tools used in this work, followed by the fusion method used as well as the fuse classifiers for SAR images classification.
Section 4 presents the proposed framework used to extract, process, and classify the features. In
Section 5, experiments are carried out with the MSTAR database, and the performance of the proposed approach is described. Finally,
Section 6 lists the conclusions along with the discussion of the results.
4. Methodology
For SAR image classification, several CNN architectures were proposed in the literature and have proven that the activations from high-level layers of CNNs can generate powerful feature representations with outstanding performance. However, two important points were noticed. First, the best classification accuracy for individual SAR classes is varied between the different CNN architecture and second, features extracted from lower-level layers, particularly the convolutional layers, lack sufficient study. These two reasons have encouraged us to propose different scenarios for utilizing CNN features for SAR images classification for the sake of investigating the effectiveness of features from the last convolutional layer and FC layer as well as the effect of combination and fusion different features and classifiers.
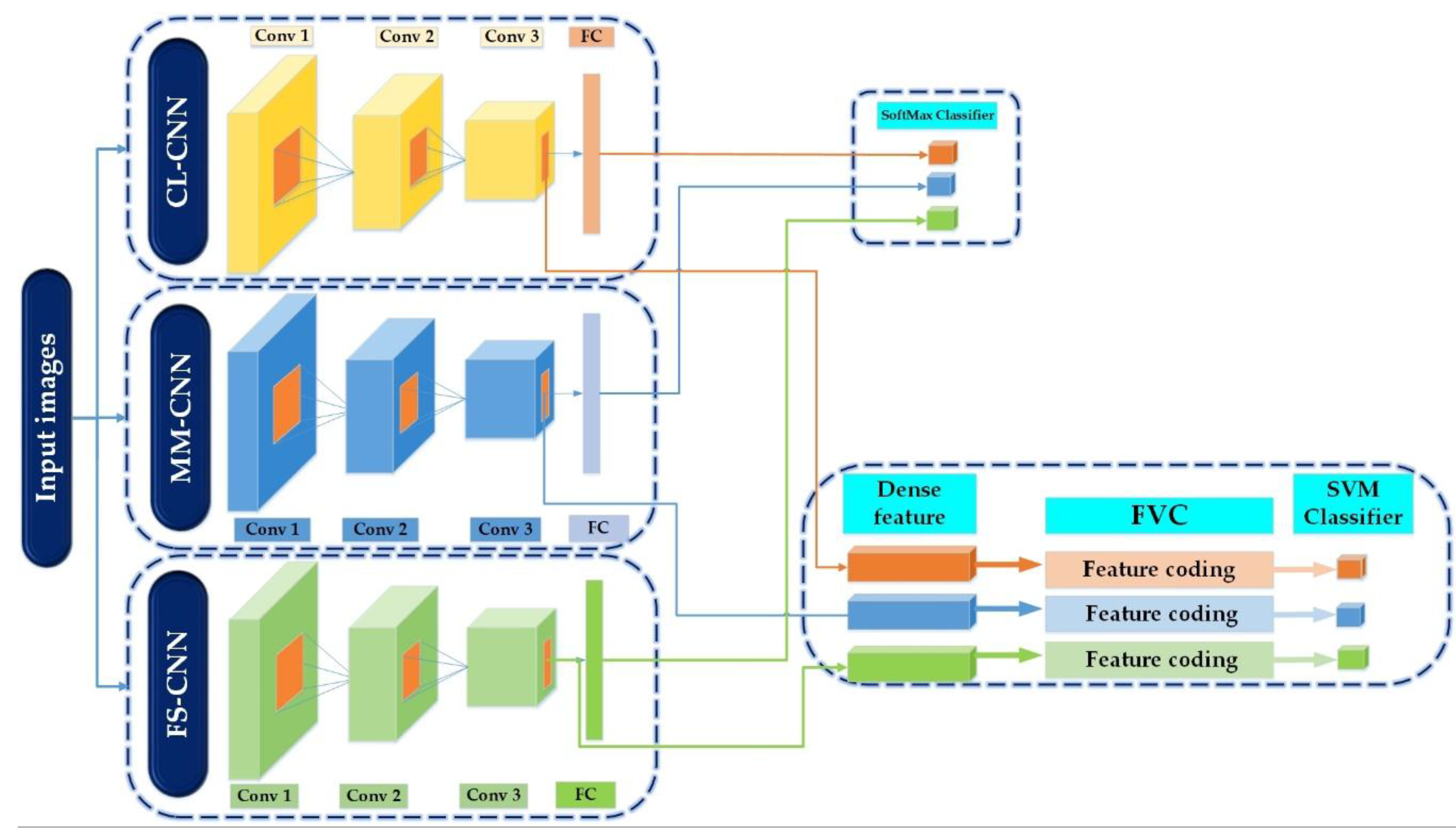
Figure 2 and
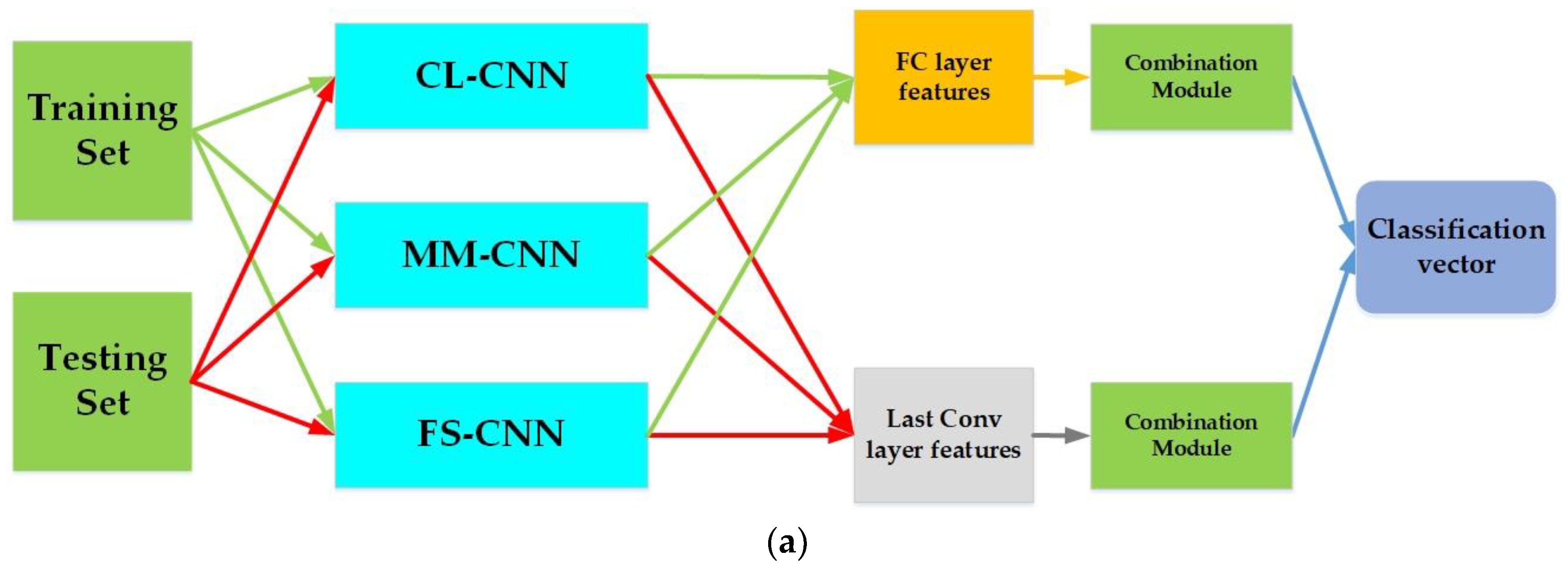
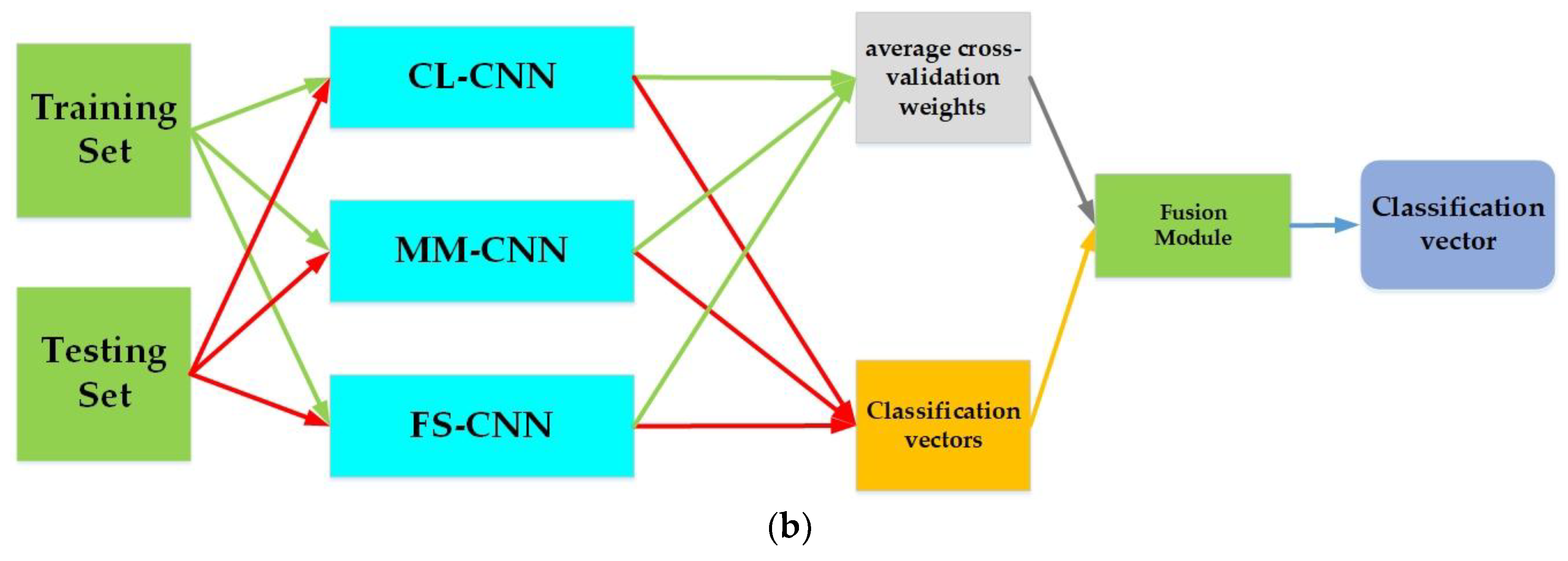
Figure 3 illustrate the framework of the proposed method.
The proposed method of SAR image classification is based on the following steps:
We use a set of different convolutional neural networks learning at different kernel sizes of convolution and pooling to produce high level invariant features;
The high-level features obtained from the FC layer are classified for each CNN model separately.
The features obtained from the last convolutional layer are classified after being encoded using the FVs coding.
A final feature vector from the FC layer is obtained by different combination of results of steps 2 and 3.
A final classification decision using different fusion methods based on results of steps 2 and 3 is obtained.
In this work, we have elected to apply the network topology presented in
Section 3. Three different CNNs models at different kernel sizes of convolution and pooling were designed and trained on the MSTAR training set.
The choice of different parameters of each CNN model was mostly based on both previous types of research architecture [
16,
20,
27,
28,
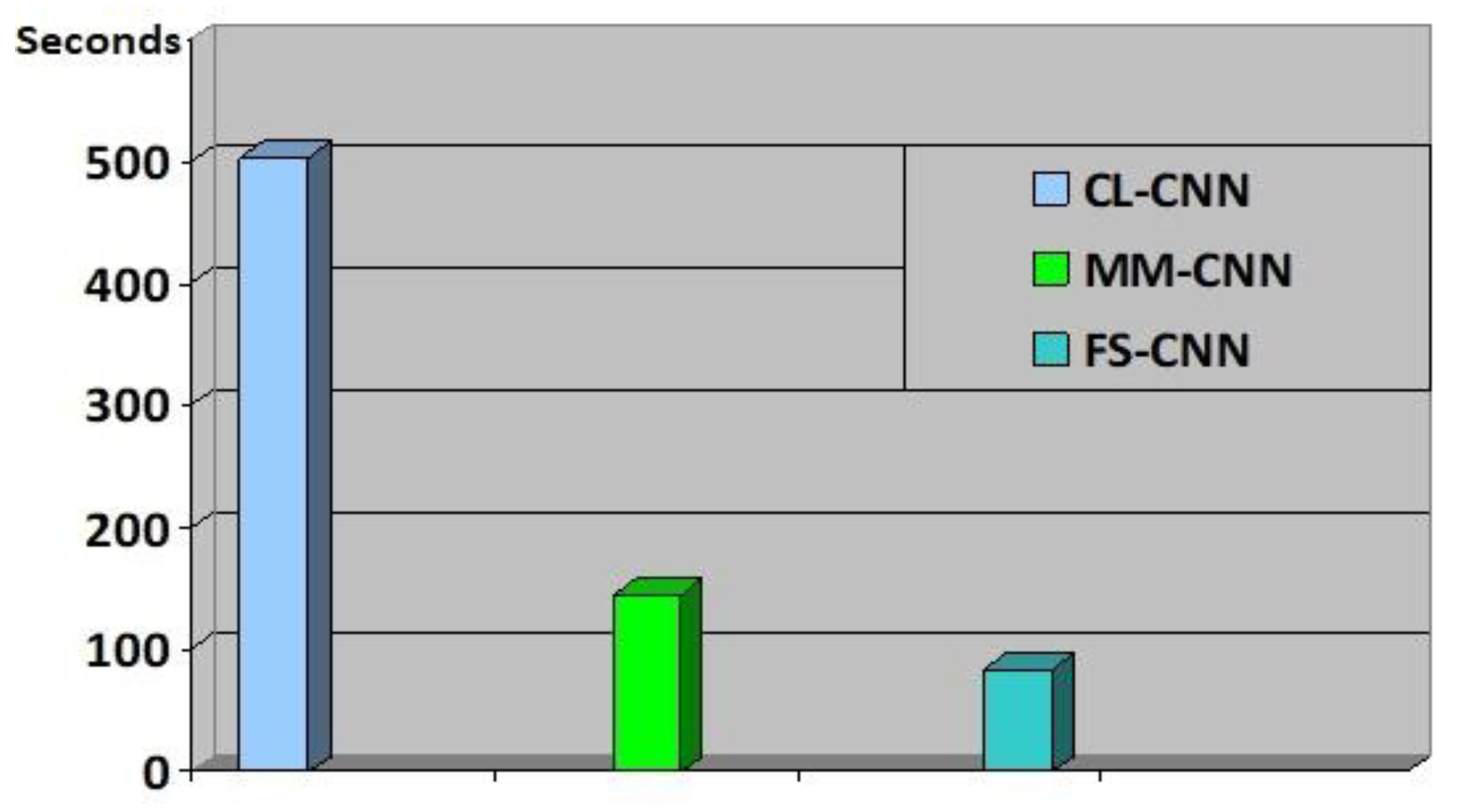
29] and experiments where we change the different parameters of CNN to obtain the architecture that achieves the best performances. We remark that several types of architecture can generate good SAR image representation. However, the best classification accuracy for individual classes is varied between the different forms of CNN architecture, which encourage us to exploit three kinds of CNN models with different convolution and pooling kernel size in each layer. We manage to have the same size of the FC layer in each architecture for reasons of simplicity in the two last steps of the proposed method, which are feature combination and the fusion. We chose the following appellation for the three architecture based on their respective convolution and pooling kernel sizes: CL-CNN, coarse grain with larger size, MM-CNN, middle grain with medium size, FS-CNN, fine grain with small size. The architecture of each network is given in
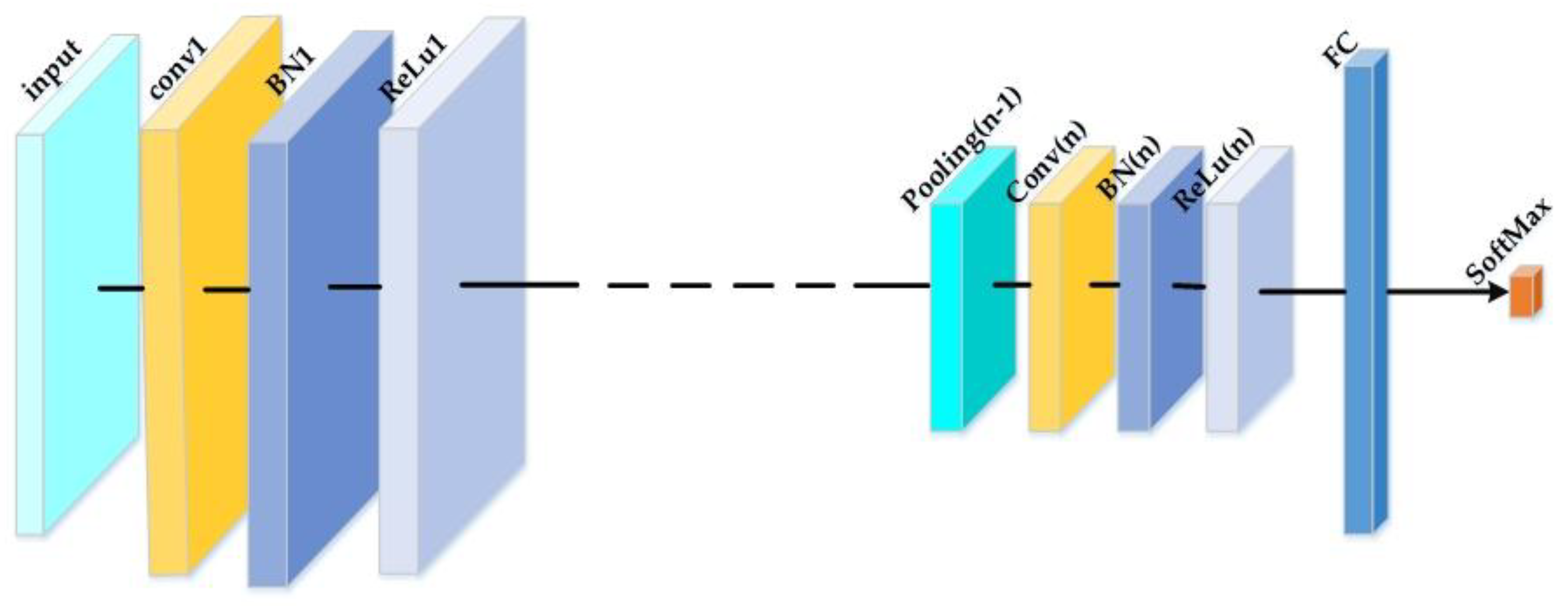
Table 1. The convolution layer receives inputs from a local region of the input volume located in the small neighborhood of the previous layer, which is called the local receptive field. A typical convolutional layer has several feature maps. Weight vectors between different feature maps are different but all the units within one feature map share the same set of weights. Due to the use of local receptive fields and weight sharing, the number of free parameters to be learned is significantly reduced. BN layer helps in obtaining higher overall accuracy and faster learning. ReLu layer improves the networks by speeding up the training since it keeps the computation of the gradient very simple. Subsampling layer usually implemented as max-pooling layer further reduces feature dimension with translational invariance. FC layer is similar to classical neural networks computing a dot product between their input vector and their weight vector. The Softmax nonlinearity is utilized as the final output layer to deal with the multiclass classification issue.
Accuracy is calculated from each FC layer of the three CNN models using the SoftMax classifier, as well as from the dense features obtained from the last convolutional layers of each model, using the SVM classifier after being encoded by FVC.
Figure 2 resumes the first three aforementioned steps of the proposed method.
Figure 3 resumes the last two above-mentioned steps of the proposed method. The combination module in
Figure 3a could be either the concatenation method or the addition. In
Figure 3b, the fusion module is one of the three aforementioned fusion methods in
Section 3.3. The average cross-validation weights are needed only in the case where the fusion module is the Accuracy Weighted Sum.
The results of each individual CNN model motivate us to use different techniques of combination and fusion. Since the CNN which produced the best classification accuracy for individual classes is varied between the different CNNs, this suggests that differences in the CNN architecture types may allow one network to consistently perform better on a subset of the SAR classes even though it underperforms, on average, across all the classes compared with another network. Consequently, feature combination and fusion of the CNNs information outputs as shown in
Figure 3 should improve the overall robustness and accuracy of the result compared to a single CNN.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}