A Non-Linear Filtering Algorithm Based on Alpha-Divergence Minimization


Abstract
:1. Introduction
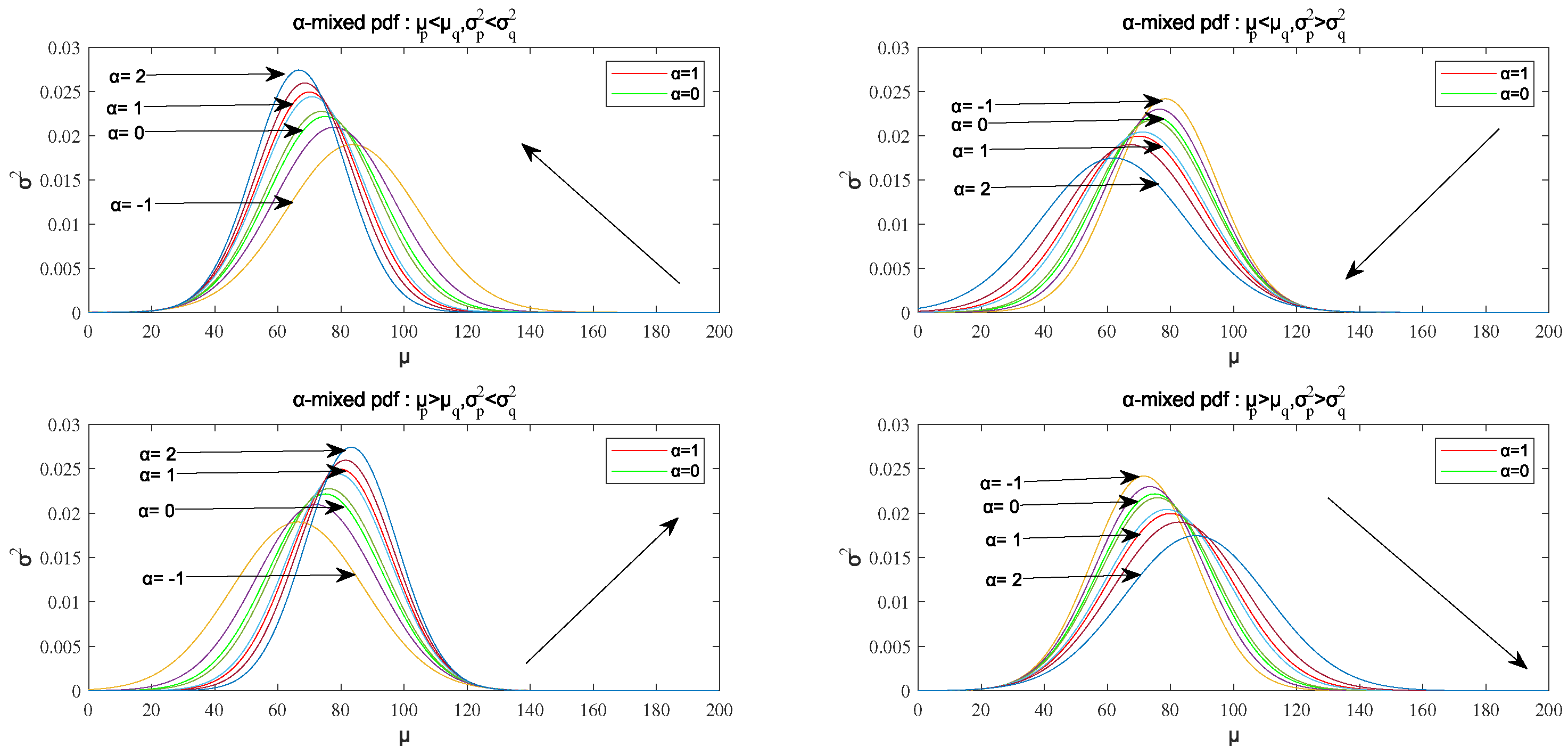
- We define an -mixed probability density function and prove that it satisfies the normalization condition when we specify the probability distributions and to be univariate normal distributions. Then, we analyze the monotonicity of the mean and the variance of the -mixed probability density function with respect to the parameter when and are specified to be univariate normal distributions. The results will be used in the algorithm implementation to guarantee the convergence.
- We specify the probability density function as an exponential family state density function and choose it to approximate the known state probability density function . After the -mixed probability density function is defined by and , we prove that the sufficient condition for alpha-divergence minimization is when and the expected value of the natural statistical vector of is equivalent to the expected value of the natural statistical vector of the -mixed probability density function.
- We apply the sufficient condition to the non-linear measurement update step of the non-linear filtering. The experiments show that the proposed method can achieve better performance by using a proper value.
2. Related Work
3. Background Work
3.1. Non-Linear Filtering
3.2. The Alpha-Divergence
- , if and only if , . This property can be used precisely to measure the difference between the two distributions.
- is a convex function with respect to and .
- As approaches one, Equation (8) is the limitation form of , and it specializes to the KL divergence from to as L’Hôpital’s rule is used:When and are normalized distributions, the KL divergence is expressed as:
- As approaches zero, Equation (8) is still the limitation form of , and it specializes to the dual form of the KL divergence from to as L’Hôpital’s rule is used:When and are normalized distributions, the dual form of the KL divergence is expressed as:
- When , the alpha-divergence specializes to the Hellinger divergence, which is the only dual divergence in the alpha-divergence:where is the Hellinger distance, which is the half of the Euclidean distance between two random distributions after taking the difference of the square root, and it corresponds to the fundamental property of distance measurement and is a valid distance metric.
- When , the alpha-divergence degrades to -divergence:
4. Non-Linear Filtering Based on the Alpha-Divergence
4.1. The -Mixed Probability Density Function
4.2. The Alpha-Divergence Minimization
| Algorithm 1 Approximation of the true probability distribution . |
| Input: Target distribution parameter of ; damping factor ; divergence parameter ; initialization value of Output: The exponential family probability function
|
4.3. Non-Linear Filtering Algorithm Based on the Alpha-Divergence
5. Simulations and Analysis
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Grewal, M.S.; Andrews, A.P. Applications of Kalman filtering in aerospace 1960 to the present [historical perspectives]. IEEE Control Syst. 2010, 30, 69–78. [Google Scholar]
- Durrant-Whyte, H.; Bailey, T. Simultaneous localization and mapping: Part I. IEEE Robot. Autom. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef]
- Darling, J.E.; Demars, K.J. Minimization of the Kullback Leibler Divergence for Nonlinear Estimation. J. Guid. Control Dyn. 2017, 40, 1739–1748. [Google Scholar] [CrossRef]
- Amari, S. Differential Geometrical Method in Statistics; Lecture Note in Statistics; Springer: Berlin, Germany, 1985; Volume 28. [Google Scholar]
- Minka, T. Divergence Measures and Message Passing; Microsoft Research Ltd.: Cambridge, UK, 2005. [Google Scholar]
- Amari, S. Integration of Stochastic Models by Minimizing α-Divergence. Neural Comput. 2007, 19, 2780–2796. [Google Scholar] [CrossRef] [PubMed]
- Raitoharju, M.; García-Fernández, Á.F.; Piché, R. Kullback–Leibler divergence approach to partitioned update Kalman filter. Signal Process. 2017, 130, 289–298. [Google Scholar] [CrossRef] [Green Version]
- Mansouri, M.; Nounou, H.; Nounou, M. Kullback–Leibler divergence-based improved particle filter. In Proceedings of the 2014 IEEE 11th International Multi-Conference on Systems, Signals & Devices (SSD), Barcelona, Spain, 11–14 February 2014; pp. 1–6. [Google Scholar]
- Martin, F.; Moreno, L.; Garrido, S.; Blanco, D. Kullback–Leibler Divergence-Based Differential Evolution Markov Chain Filter for Global Localization of Mobile Robots. Sensors 2015, 15, 23431–23458. [Google Scholar] [CrossRef] [PubMed]
- Hu, C.; Lin, H.; Li, Z.; He, B.; Liu, G. Kullback–Leibler Divergence Based Distributed Cubature Kalman Filter and Its Application in Cooperative Space Object Tracking. Entropy 2018, 20, 116. [Google Scholar] [CrossRef]
- Kumar, P.; Taneja, I.J. Chi square divergence and minimization problem. J. Comb. Inf. Syst. Sci. 2004, 28, 181–207. [Google Scholar]
- Qiao, W.; Wu, C. Study on Image Segmentation of Image Thresholding Method Based on Chi-Square Divergence and Its Realization. Comput. Appl. Softw. 2008, 10, 30. [Google Scholar]
- Wang, C.; Fan, Y.; Xiong, L. Improved image segmentation based on 2-D minimum chi-square-divergence. Comput. Eng. Appl. 2014, 18, 8–13. [Google Scholar]
- Amari, S. Alpha-Divergence Is Unique, Belonging to Both f-Divergence and Bregman Divergence Classes. IEEE Trans. Inf. Theory 2009, 55, 4925–4931. [Google Scholar] [CrossRef]
- Gultekin, S.; Paisley, J. Nonlinear Kalman Filtering with Divergence Minimization. IEEE Trans. Signal Process. 2017, 65, 6319–6331. [Google Scholar] [CrossRef]
- Hernandezlobato, J.M.; Li, Y.; Rowland, M.; Bui, T.D.; Hernandezlobato, D.; Turner, R.E. Black Box Alpha Divergence Minimization. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1511–1520. [Google Scholar]
- Tsallis, C. Possible Generalization of Boltzmann-Gibbs Statistics. J. Stat. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Tsallis, C. Introduction to Nonextensive Statistical Mechanics. Condens. Matter Stat. Mech. 2004. [Google Scholar] [CrossRef]
- Li, Y.; Turner, R.E. Rényi divergence variational inference. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 1073–1081. [Google Scholar]
- Amari, S.I. Information Geometry and Its Applications; Springer: Berlin, Germany, 2016. [Google Scholar]
- Nielsen, F.; Critchley, F.; Dodson, C.T.J. Computational Information Geometry; Springer: Berlin, Germany, 2017. [Google Scholar]
- Garcia-Fernandez, Á.F.; Morelande, M.R.; Grajal, J. Truncated unscented Kalman filtering. IEEE Trans. Signal Process. 2012, 60, 3372–3386. [Google Scholar] [CrossRef]
- Li, Y.; Cheng, Y.; Li, X.; Hua, X.; Qin, Y. Information Geometric Approach to Recursive Update in Nonlinear Filtering. Entropy 2017, 19, 54. [Google Scholar] [CrossRef]
- Martino, L.; Elvira, V.; Camps-Valls, G. Group Importance Sampling for particle filtering and MCMC. Dig. Signal Process. 2018, 82, 133–151. [Google Scholar] [CrossRef]
- Salomone, R.; South, L.F.; Drovandi, C.C.; Kroese, D.P. Unbiased and Consistent Nested Sampling via Sequential Monte Carlo. arXiv, 2018; arXiv:1805.03924. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Increases with the Increase of | Decreases with the Increase of | ||
|---|---|---|---|
| increases with the increase of | |||
| decreases with the increase of | |||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|
| EKF | 1.6414 | 1.8434 | 1.8245 | 1.7749 | 1.6666 | 1.3255 | ⋯ |
| UKF | 1.5400 | 1.7703 | 1.6688 | 1.6387 | 1.6241 | 1.2243 | ⋯ |
| AKF | 1.4819 | 1.5921 | 1.4710 | 1.4694 | 1.4389 | 1.1222 | ⋯ |
| Q | 0.05 | 0.1 | 1 | 10 |
|---|---|---|---|---|
| EKF | 0.2256 | 0.2950 | 0.7288 | 1.7827 |
| UKF | 0.2222 | 0.3002 | 0.7396 | 1.6222 |
| AKF | 0.2167 | 0.2767 | 0.7144 | 1.5244 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, Y.; Guo, C.; Zheng, J.; You, S. A Non-Linear Filtering Algorithm Based on Alpha-Divergence Minimization. Sensors 2018, 18, 3217. https://doi.org/10.3390/s18103217
Luo Y, Guo C, Zheng J, You S. A Non-Linear Filtering Algorithm Based on Alpha-Divergence Minimization. Sensors. 2018; 18(10):3217. https://doi.org/10.3390/s18103217
Chicago/Turabian StyleLuo, Yarong, Chi Guo, Jiansheng Zheng, and Shengyong You. 2018. "A Non-Linear Filtering Algorithm Based on Alpha-Divergence Minimization" Sensors 18, no. 10: 3217. https://doi.org/10.3390/s18103217
APA StyleLuo, Y., Guo, C., Zheng, J., & You, S. (2018). A Non-Linear Filtering Algorithm Based on Alpha-Divergence Minimization. Sensors, 18(10), 3217. https://doi.org/10.3390/s18103217