Enhancing the Isolation and Performance of Control Planes for Fog Computing



Abstract
:1. Introduction
- Lack of isolation: Recent studies [11,12,13,14,15] report that rapidly developed prototype control applications can go awry. Furthermore, third-party control applications can contain unexpected vulnerabilities, fatal instabilities or even malicious logic. These malfunctioning control planes can affect other tasks running on the same physical machine. In particular, when different virtual networks are simultaneously constructed [16,17], the faulty control planes can cause the crash of the entire system, which leads to the loss of network control. This is because existing OSs run control planes as user-level processes and do not provide additional access control or an isolated execution environment. Therefore, it becomes necessary to provide strong isolation in the execution environment of control planes.
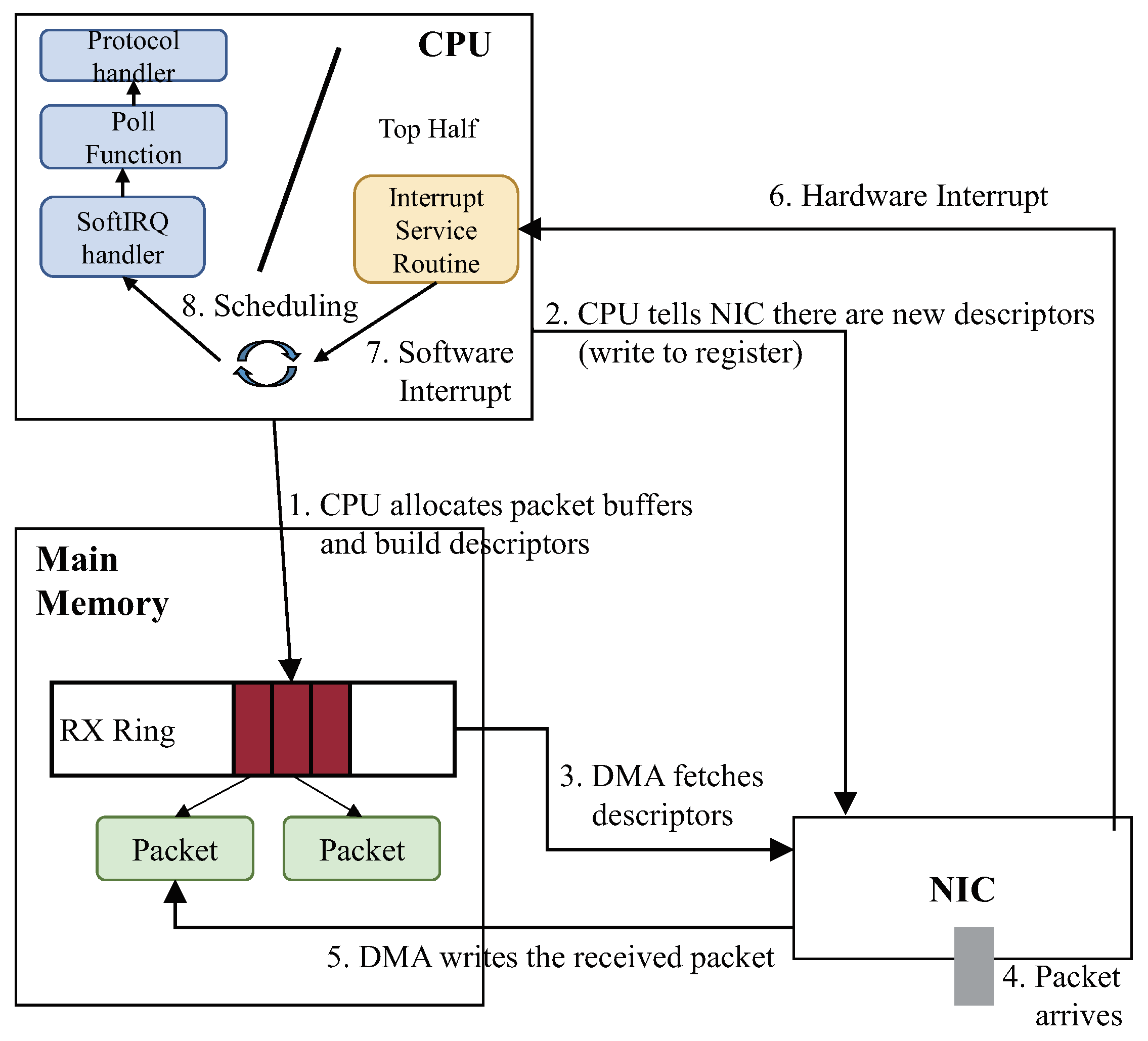
- Low performance: OSs are designed to support various applications including control planes, which offer a variety of network functions such as encryption/decryption, firewall and rate limiting. Every packet arriving at the system must go through the entire network stack of the OS before reaching the SDN controller. Moreover, incoming packets must wait to be processed in order by the corresponding SDN controller. This is due to the fact that the existing network stack processes packets one by one. Thus, incoming packets can be dropped, when packets arrive successively at high speed [18]. This can result in serious performance degradation of the SDN controller.
2. Related Work
3. Design
3.1. Design Goals
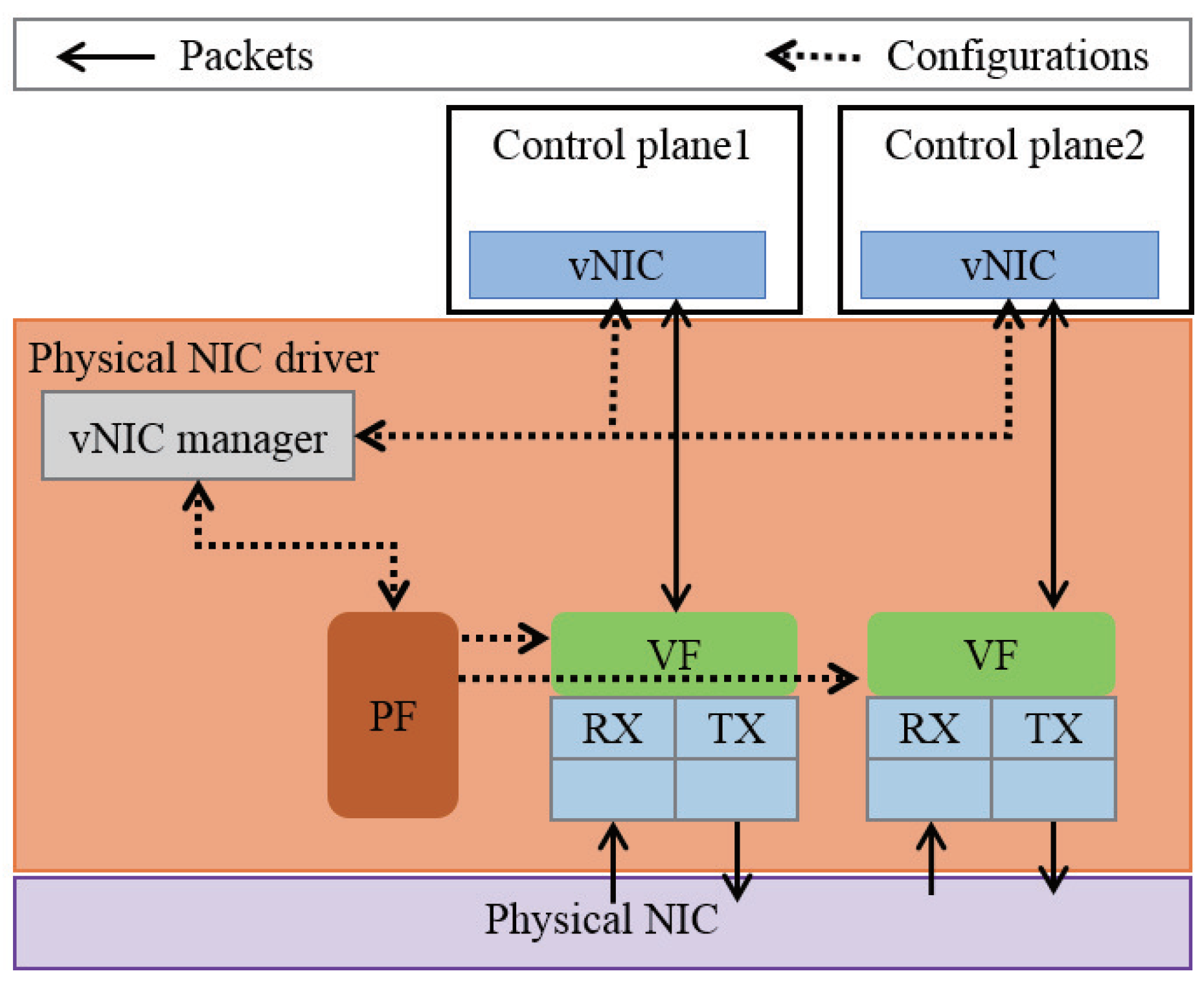
- Running existing SDN controllers and control applications without modification: Most of the SDN controllers and control applications are based primarily on Linux. To be compatible with existing SDN controllers and control applications, we maintain standard Linux APIs.
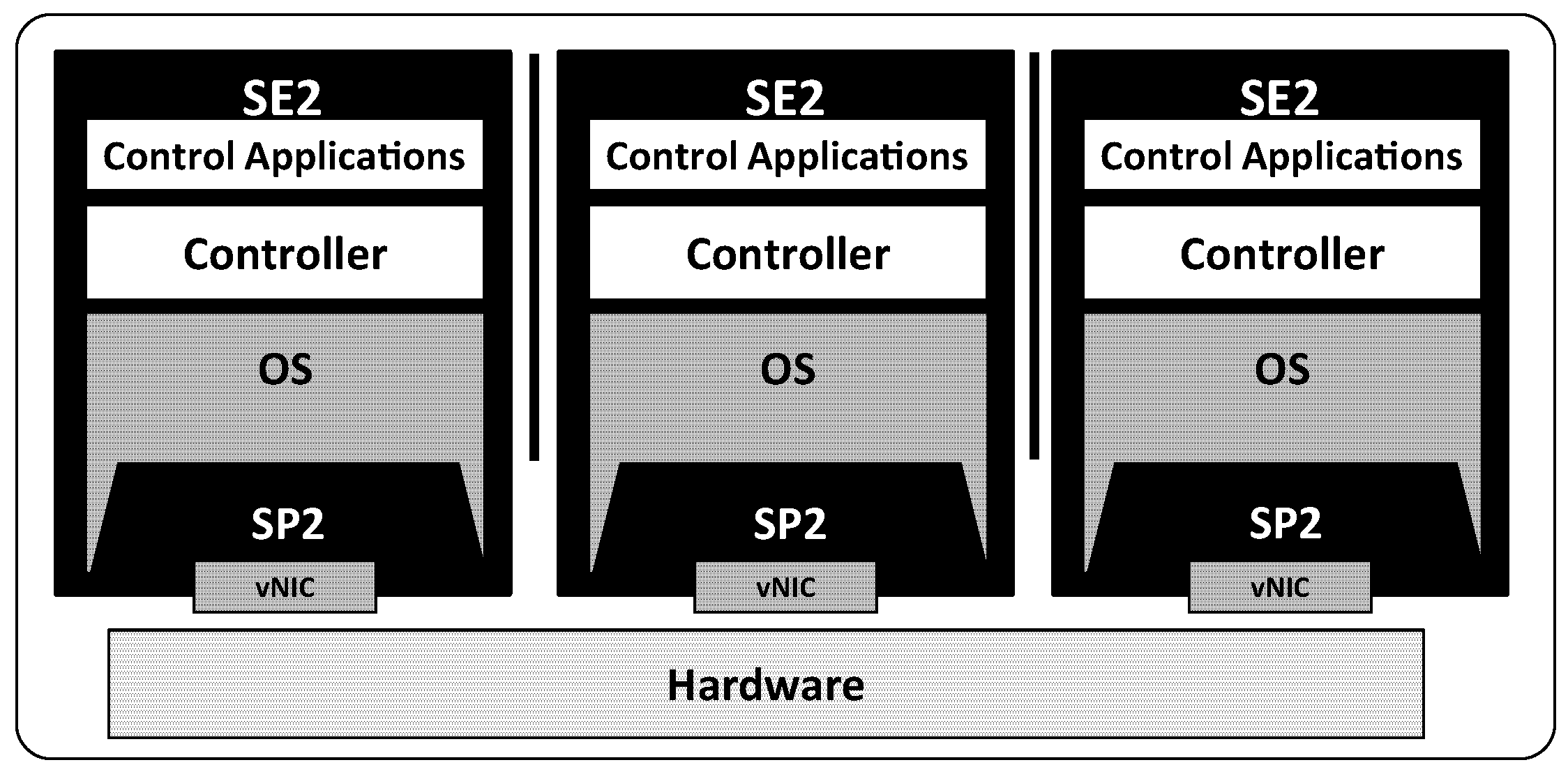
- Providing isolated execution environments while removing dependency on specific hardware: To be used in an existing SDN deployment, we provide a general execution environment architecture, which is not dependent on specific hardware. In addition, the control plane in the execution environment does not affect other control planes, when multiple control planes are co-located in the same physical server.
- Guaranteeing high control plane performance compared to existing Linux: Even though several studies improved the control plane performance, they focused on optimizing the control plane itself, leaving room for further improvement: the Linux kernel. We aim to achieve high performance of control planes during packet processing by optimizing the network stack of Linux.
3.2. SE2: Isolated Execution Environment
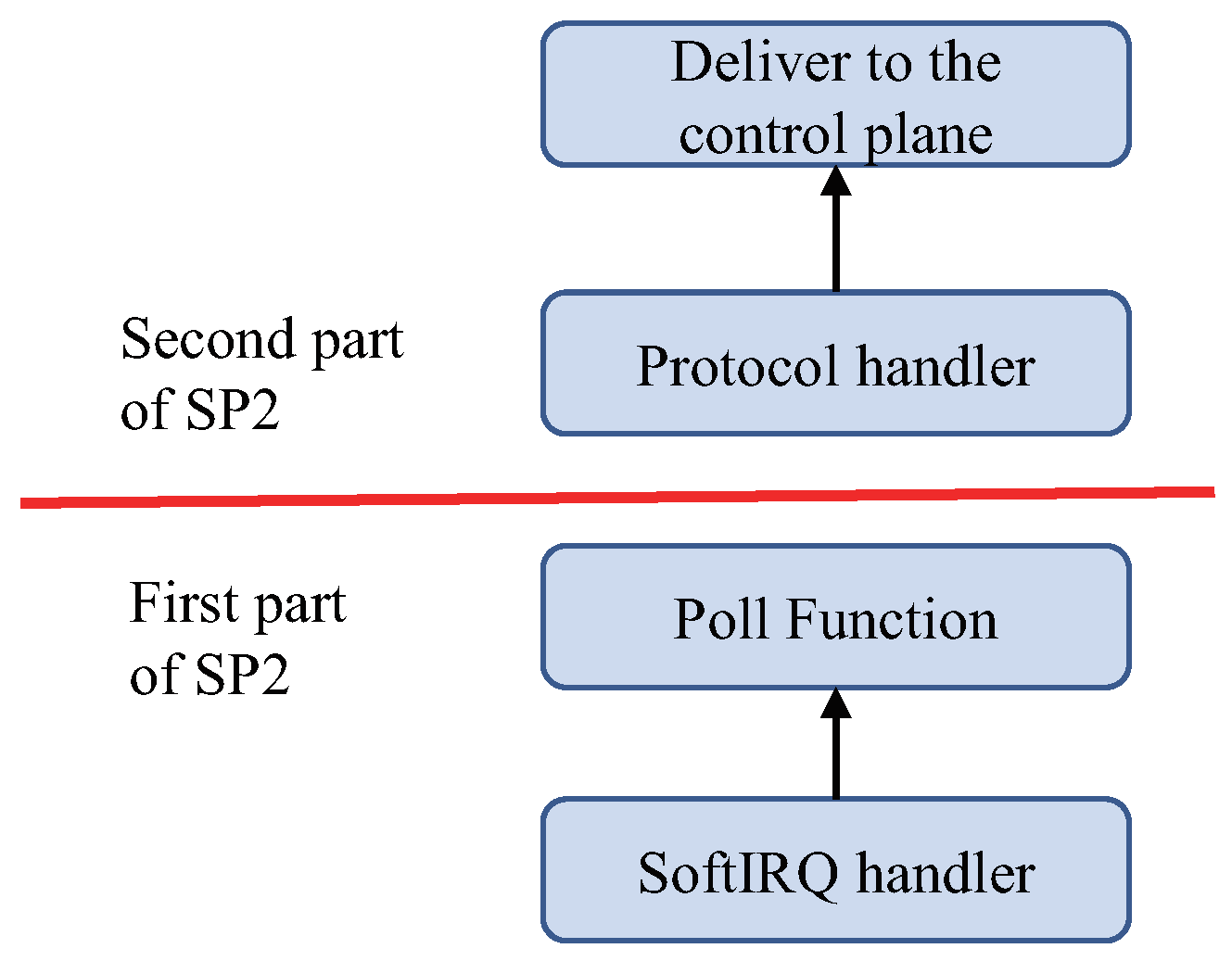
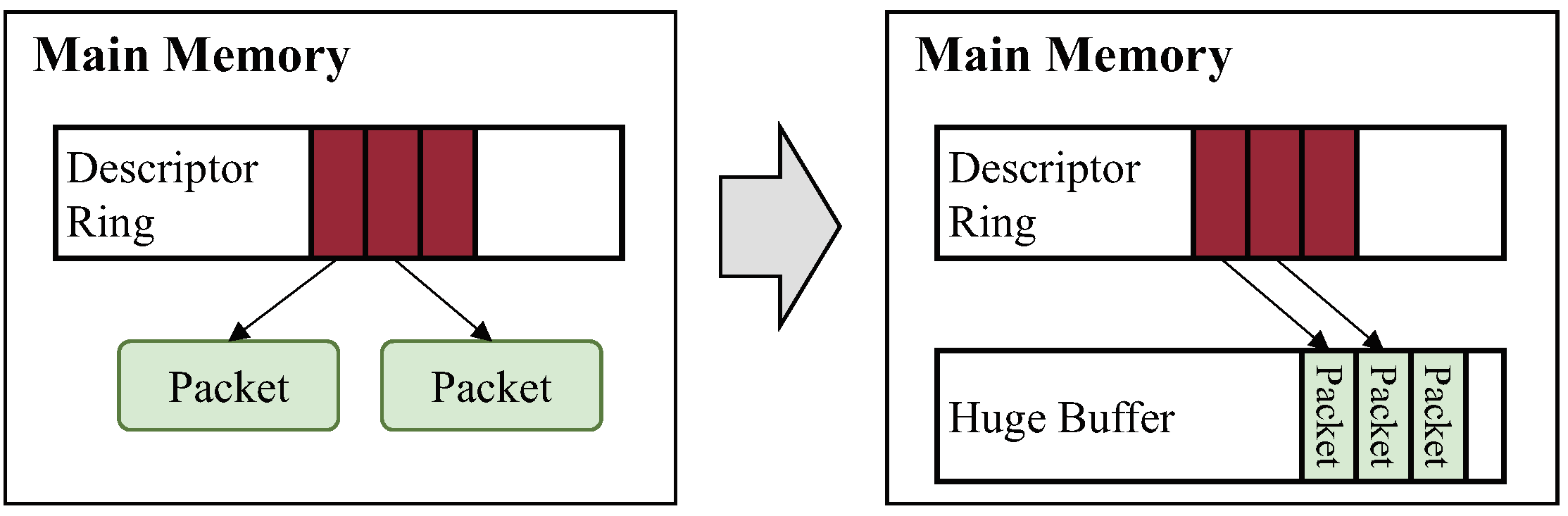
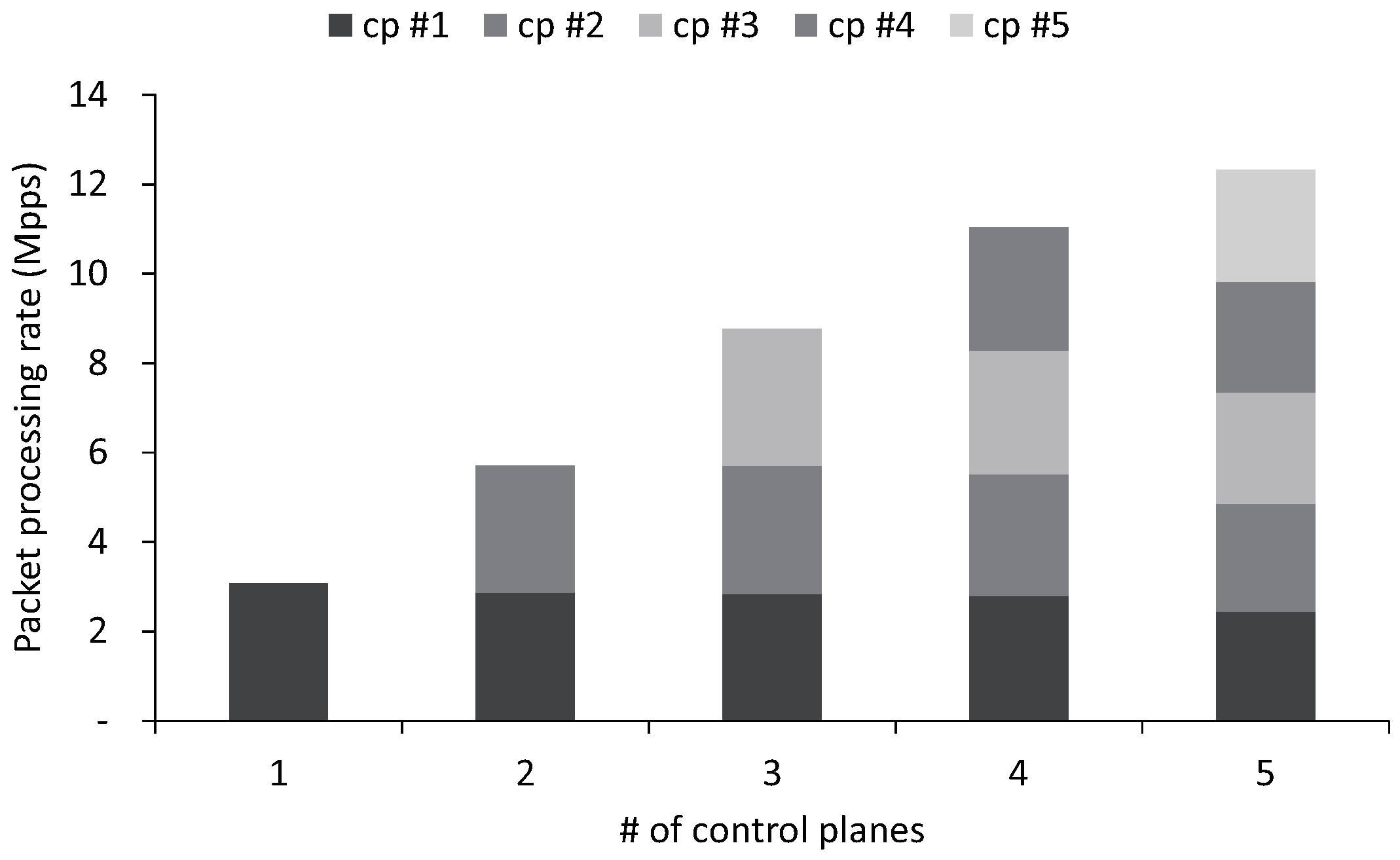
3.3. Separate Packet Processing
4. Implementation
5. Evaluation
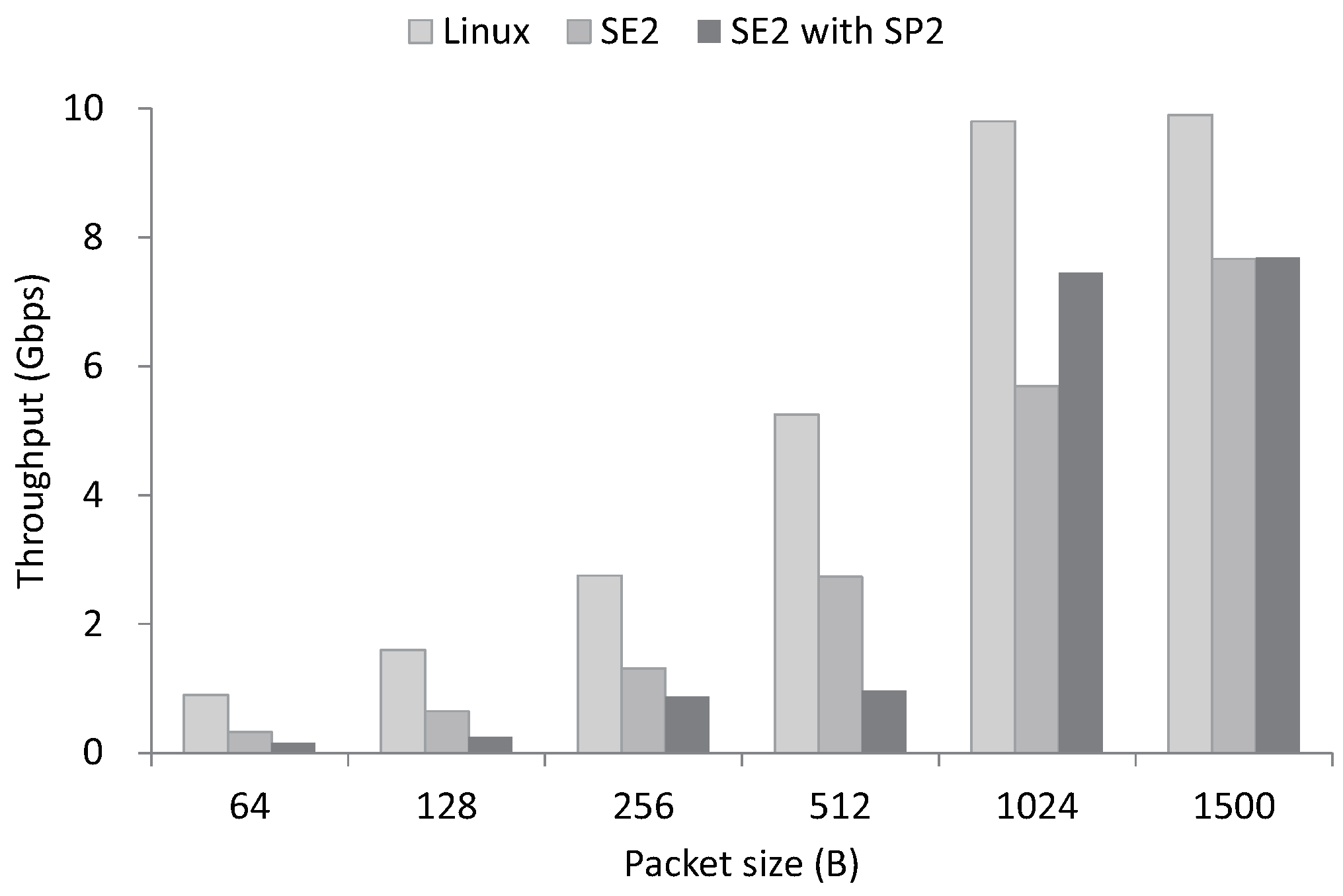
5.1. SE2
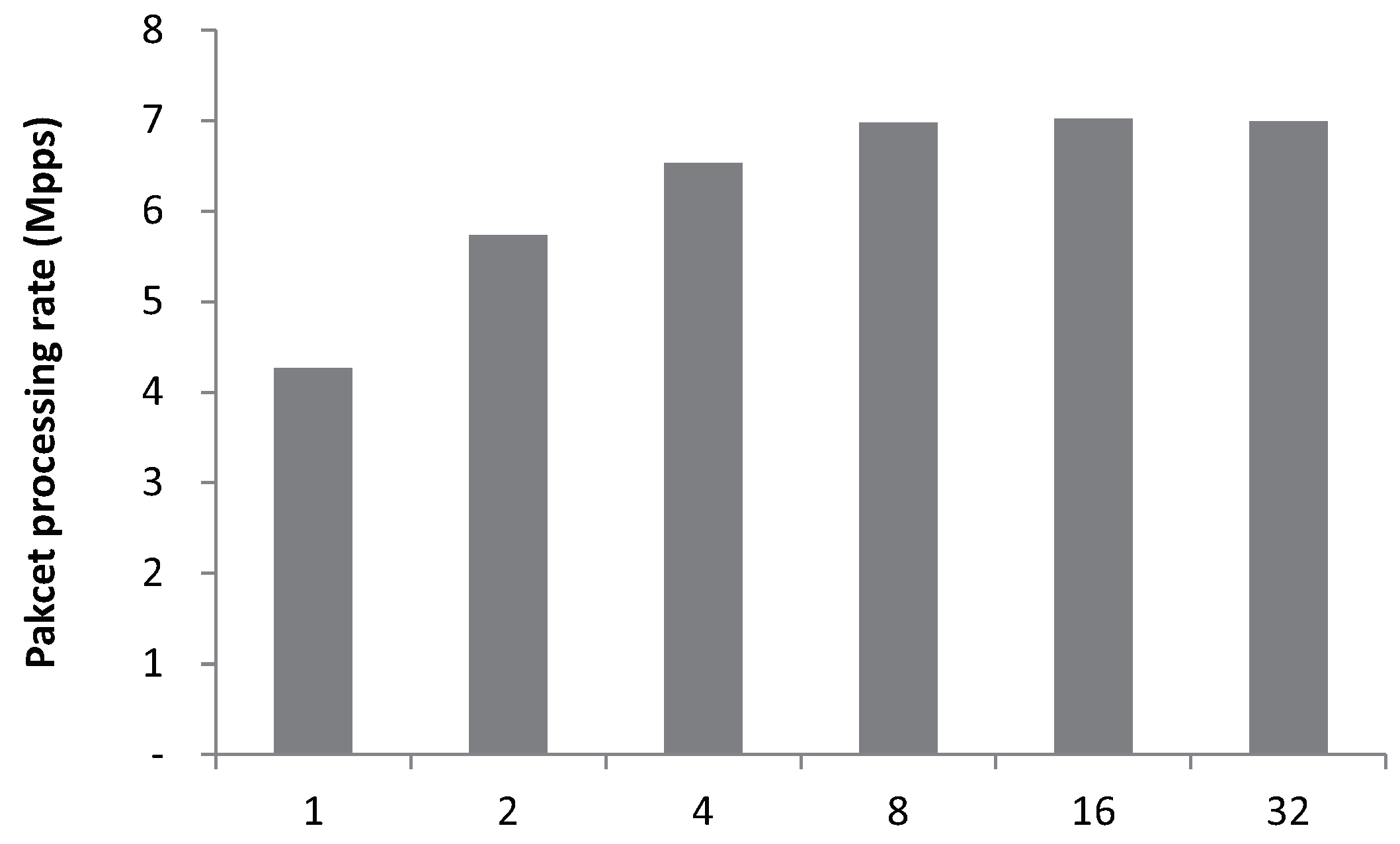
5.2. SP2
5.3. SE2 + SP2
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Moreno-Vozmediano, R.; Montero, R.S.; Huedo, E.; Llorente, I.M. Cross-site virtual network in cloud and fog computing. IEEE Cloud Comput. 2017, 2, 46–53. [Google Scholar] [CrossRef]
- Hakiri, A.; Sellami, B.; Patil, P.; Berthou, P.; Gokhale, A. Managing Wireless Fog Networks using Software-Defined Networking. In Proceedings of the 2017 IEEE/ACS 14th International Conference on Computer Systems and Applications (AICCSA), Hammamet, Tunisia, 30 October–3 November 2017; pp. 1149–1156. [Google Scholar]
- Yi, S.; Li, C.; Li, Q. A survey of fog computing: Concepts, applications and issues. In Proceedings of the 2015 Workshop on Mobile Big Data, Hangzhou, China, 21 June 2015; pp. 37–42. [Google Scholar]
- Yu, W.; Liang, F.; He, X.; Hatcher, W.G.; Lu, C.; Lin, J.; Yang, X. A survey on the edge computing for the Internet of Things. IEEE Access 2017, 6, 6900–6919. [Google Scholar] [CrossRef]
- Willis, D.; Dasgupta, A.; Banerjee, S. ParaDrop: A multi-tenant platform to dynamically install third party services on wireless gateways. In Proceedings of the 9th ACM Workshop on Mobility in the Evolving Internet Architecture, Maui, HI, USA, 11 September 2014; pp. 43–48. [Google Scholar]
- Hong, K.; Lillethun, D.; Ramachandran, U.; Ottenwälder, B.; Koldehofe, B. Mobile fog: A programming model for large-scale applications on the internet of things. In Proceedings of the Second ACM SIGCOMM Workshop on Mobile Cloud Computing, Hong Kong, China, 16 August 2013; pp. 15–20. [Google Scholar]
- Satyanarayanan, M.; Chen, Z.; Ha, K.; Hu, W.; Richter, W.; Pillai, P. Cloudlets: At the leading edge of mobile-cloud convergence. In Proceedings of the 2014 6th International Conference on Mobile Computing, Applications and Services (MobiCASE), Austin, TX, USA, 6–7 November 2014; pp. 1–9. [Google Scholar]
- Kreutz, D.; Ramos, F.M.; Verissimo, P.E.; Rothenberg, C.E.; Azodolmolky, S.; Uhlig, S. Software-defined networking: A comprehensive survey. Proc. IEEE 2015, 103, 14–76. [Google Scholar] [CrossRef]
- Zhao, Y.; Iannone, L.; Riguidel, M. On the performance of SDN controllers: A reality check. In Proceedings of the 2015 IEEE Conference on Network Function Virtualization and Software Defined Network (NFV-SDN), San Francisco, CA, USA, 18–21 November 2015; pp. 79–85. [Google Scholar]
- Bera, S.; Misra, S.; Vasilakos, A.V. Software-defined networking for internet of things: A survey. IEEE Int. Things J. 2017, 4, 1994–2008. [Google Scholar] [CrossRef]
- Shin, S.; Song, Y.; Lee, T.; Lee, S.; Chung, J.; Porras, P.; Yegneswaran, V.; Noh, J.; Kang, B.B. Rosemary: A robust, secure, and high-performance network operating system. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; pp. 78–89. [Google Scholar]
- Betgé-Brezetz, S.; Kamga, G.B.; Tazi, M. Trust support for SDN controllers and virtualized network applications. In Proceedings of the 2015 1st IEEE Conference on Network Softwarization (NetSoft), London, UK, 13–17 April 2015; pp. 1–5. [Google Scholar]
- Scott, C.; Wundsam, A.; Raghavan, B.; Panda, A.; Or, A.; Lai, J.; Huang, E.; Liu, Z.; El-Hassany, A.; Whitlock, S.; et al. Troubleshooting blackbox SDN control software with minimal causal sequences. ACM SIGCOMM Comput. Commun. Rev. 2015, 44, 395–406. [Google Scholar] [CrossRef]
- Porras, P.A.; Cheung, S.; Fong, M.W.; Skinner, K.; Yegneswaran, V. Securing the Software Defined Network Control Layer; NDSS: New York, NY, USA, 2015. [Google Scholar]
- Yoon, C.; Lee, S.; Kang, H.; Park, T.; Shin, S.; Yegneswaran, V.; Porras, P.; Gu, G. Flow wars: Systemizing the attack surface and defenses in software-defined networks. IEEE/ACM Trans. Netw. 2017, 6, 3514–3530. [Google Scholar] [CrossRef]
- Dalton, M.; Schultz, D.; Adriaens, J.; Arefin, A.; Gupta, A.; Fahs, B.; Rubinstein, D.; Zermeno, E.C.; Rubow, E.; Docauer, J.A.; et al. Andromeda: Performance, Isolation, and Velocity at Scale in Cloud Network Virtualization. In Proceedings of the 15th USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2018; Available online: https://www.usenix.org/system/files/conference/nsdi18/nsdi18-dalton.pdf (accessed on 11 June 2018).
- Yang, G.; Yu, B.Y.; Jeong, W.; Yoo, C. FlowVirt: Flow Rule Virtualization for Dynamic Scalability of Programmable Network Virtualization. In Proceedings of the International Conference on Cloud Computing, San Francisco, CA, USA, 2018; pp. 350–358. [Google Scholar]
- Rizzo, L. Netmap: A novel framework for fast packet I/O. In Proceedings of the 21st USENIX Security Symposium (USENIX Security 12), Bellevue, WA, USA, 8–10 August 2012; pp. 101–112. [Google Scholar]
- Tootoonchian, A.; Gorbunov, S.; Ganjali, Y.; Casado, M.; Sherwood, R. On Controller Performance in Software-Defined Networks. In Proceedings of the 2nd USENIX Workshop on Hot Topics in Management of Internet, Cloud, and Enterprise Networks and Services, San Jose, CA, USA, 24 April 2012; p. 10. [Google Scholar]
- Drutskoy, D.; Keller, E.; Rexford, J. Scalable network virtualization in software-defined networks. IEEE Int. Comput. 2013, 17, 20–27. [Google Scholar] [CrossRef]
- Jin, X.; Gossels, J.; Rexford, J.; Walker, D. Covisor: A compositional hypervisor for software-defined networks. In Proceedings of the 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI 15), Oakland, CA, USA, 4–6 May 2015; pp. 87–101. [Google Scholar]
- Renart, E.G.; Zhang, E.Z.; Nath, B. Towards a GPU SDN controller. In Proceedings of the 2015 International Conference and Workshops on Networked Systems (NetSys), Cottbus, Germany, 9–12 March 2015; pp. 1–5. [Google Scholar]
- Porras, P.; Shin, S.; Yegneswaran, V.; Fong, M.; Tyson, M.; Gu, G. A security enforcement kernel for OpenFlow networks. In Proceedings of the First Workshop on Hot Topics in Software Defined Networks, Helsinki, Finland, 13 August 2012; pp. 121–126. [Google Scholar]
- Luo, T.; Tan, H.P.; Quan, P.C.; Law, Y.W.; Jin, J. Enhancing responsiveness and scalability for OpenFlow networks via control-message quenching. In Proceedings of the 2012 International Conference on ICT Convergence (ICTC), Jeju Island, Korea, 15–17 October 2012; pp. 348–353. [Google Scholar]
- Li, Y.; Dong, L.; Qu, J.; Zhang, H. Multiple controller management in software defined networking. In Proceedings of the 2014 IEEE Symposium on Computer Applications and Communications (SCAC), Weihai, China, 26–27 July 2014; pp. 70–75. [Google Scholar]
- Jeong, E.; Woo, S.; Jamshed, M.A.; Jeong, H.; Ihm, S.; Han, D.; Park, K. mTCP: A Highly Scalable User-Level TCP Stack for Multicore Systems. NSDI. 2014, pp. 489–502. Available online: https://www.usenix.org/node/179774 (accessed on 28 September 2018).
- Intel Data Plane Development Kit. Available online: http://dpdk.org (accessed on 2 July 2018).
- Gelberger, A.; Yemini, N.; Giladi, R. Performance analysis of software-defined networking (SDN). In Proceedings of the 2013 IEEE 21st International Symposium on Modelling, Analysis and Simulation of Computer and Telecommunication Systems, San Francisco, CA, USA, 14–16 August 2013; pp. 389–393. [Google Scholar]
- Erickson, D. The beacon openflow controller. In Proceedings of the Second ACM SIGCOMM Workshop on Hot Topics in Software Defined Networking, Hong Kong, China, 16 August 2013; pp. 13–18. [Google Scholar]
- Phemius, K.; Bouet, M.; Leguay, J. Disco: Distributed multi-domain SDN controllers. In Proceedings of the 2014 IEEE Network Operations and Management Symposium (NOMS), Krakow, Poland, 5–9 May 2014; pp. 1–4. [Google Scholar]
- Floodlight Project. Available online: http://www.projectfloodlight.org/ (accessed on 2 July 2018).
- HP. SDN Controller Architecture; Technical Report; HP: Palo Alto, CA, USA, 2013. [Google Scholar]
- Tootoonchian, A.; Ganjali, Y. HyperFlow: A distributed control plane for OpenFlow. In Proceedings of the 2010 Internet Network Management Conference on Research on Enterprise Networking, 2010; p. 3. Available online: https://www.usenix.org/legacy/event/inmwren10/tech/full_papers/Tootoonchian.pdf (accessed on 11 June 2018).
- Koponen, T.; Casado, M.; Gude, N.; Stribling, J.; Poutievski, L.; Zhu, M.; Ramanathan, R.; Iwata, Y.; Inoue, H.; Hama, T.; et al. Onix: A Distributed Control Platform for Large-Scale Production Networks; OSDI, 2010; Volume 10, pp. 1–6. Available online: http://static.usenix.org/events/osdi10/tech/full_papers/Koponen.pdf (accessed on 11 June 2018).
- Ng, E. Maestro: A System for Scalable Openflow Control; Rice University: Houston, TX, USA, 2010. [Google Scholar]
- Banikazemi, M.; Olshefski, D.; Shaikh, A.; Tracey, J.; Wang, G. Meridian: An SDN platform for cloud network services. IEEE Commun. Mag. 2013, 51, 120–127. [Google Scholar] [CrossRef]
- Gude, N.; Koponen, T.; Pettit, J.; Pfaff, B.; Casado, M.; McKeown, N.; Shenker, S. NOX: Towards an operating system for networks. ACM SIGCOMM Comput. Commun. Rev. 2008, 38, 105–110. [Google Scholar] [CrossRef]
- Medved, J.; Varga, R.; Tkacik, A.; Gray, K. Opendaylight: Towards a model-driven sdn controller architecture. In Proceeding of the IEEE International Symposium on a World of Wireless, Mobile and Multimedia Networks, Sydney, Australia, 19 June 2014. [Google Scholar]
- Berde, P.; Gerola, M.; Hart, J.; Higuchi, Y.; Kobayashi, M.; Koide, T.; Lantz, B.; O’Connor, B.; Radoslavov, P.; Snow, W.; et al. ONOS: Towards an open, distributed SDN OS. In Proceedings of the Third Workshop on Hot Topics in Software Defined Networking, Chicago, IL, USA, 22 August 2014; pp. 1–6. [Google Scholar]
- Ferguson, A.D.; Guha, A.; Liang, C.; Fonseca, R.; Krishnamurthi, S. Participatory networking: An API for application control of SDNs. In Proceedings of the ACM SIGCOMM 2013 Conference on SIGCOMM, Hong Kong, China, 12–16 August 2013; Volume 43, pp. 327–338. [Google Scholar]
- McCauley, M. POX. 2012. Available online: http://www.noxrepo.org/ (accessed on 11th June 2018).
- Telegraph, N.; Corporation, T. RYU Network Operating System. 2012. Available online: https://ryu.readthedocs.io/ (accessed on 11 June 2018).
- Botelho, F.; Bessani, A.; Ramos, F.M.; Ferreira, P. On the design of practical fault-tolerant SDN controllers. In Proceedings of the 2014 Third European Workshop on Software Defined Networks, London, UK, 1–3 September 2014; pp. 73–78. [Google Scholar]
- Sasaki, T.; Perrig, A.; Asoni, D.E. Control-plane isolation and recovery for a secure SDN architecture. In Proceedings of the 2016 IEEE NetSoft Conference and Workshops (NetSoft), Seoul, Korea, 6–10 June 2016; pp. 459–464. [Google Scholar]
- Monitoring and Tuning the Linux Networking Stack: Sending Data. Available online: https://blog.packagecloud.io/eng/2017/02/06/monitoring-tuning-linux-networking-stack-sending-data (accessed on 11 June 2018).
- Farinacci, D.; Li, T.; Hanks, S.; Meyer, D.; Traina, P. RFC 2784—Generic Routing Encapsulation (GRE); IETF: Fremont, CA, USA, 2000. [Google Scholar]
- Benson, T.; Akella, A.; Maltz, D.A. Network traffic characteristics of data centers in the wild. In Proceedings of the 10th ACM SIGCOMM Conference on Internet Measurement, Melbourne, Australia, 1–30 November 2010; pp. 267–280. [Google Scholar]
- Wang, P.; Xu, H.; Huang, L.; Qian, C.; Wang, S.; Sun, Y. Minimizing Controller Response Time through Flow Redirecting in SDNs. IEEE/ACM Trans. Netw. 2018, 26, 562–575. [Google Scholar] [CrossRef]
- Yeganeh, S.; Tootoonchian, A.; Ganjali, Y. On scalability of software-defined networking. IEEE Commun. Mag. 2013, 2, 136–141. [Google Scholar] [CrossRef]
- Garfinkel, T.; Pfaff, B.; Chow, J.; Rosenblum, M.; Boneh, D. Terra: A virtual machine-based platform for trusted computing. In Proceedings of the Nineteenth ACM Symposium on Operating Systems Principles, Bolton Landing, NY, USA, 19–22 October 2003; Volume 37, pp. 193–206. [Google Scholar]
- Koponen, T.; Amidon, K.; Balland, P.; Casado, M.; Chanda, A.; Fulton, B.; Ganichev, I.; Gross, J.; Ingram, P.; Jackson, E.; et al. Network virtualization in multi-tenant datacenters. In Proceedings of the 11th USENIX Symposium on Networked Systems Design and Implementation (NSDI 14), Seattle, WA, USA, 2–4 April 2014; pp. 203–216. [Google Scholar]
- CVE Details. Available online: http://www.cvedetails.com (accessed on 11 June 2018).
- Santos, J.R.; Turner, Y.; Janakiraman, G.J.; Pratt, I. Bridging the Gap between Software and Hardware Techniques for I/O Virtualization. In Proceedings of the USENIX Annual Technical Conference, Boston, MA, USA, 22–27 June 2008; pp. 29–42. [Google Scholar]
- Liao, G.; Guo, D.; Bhuyan, L.; King, S.R. Software techniques to improve virtualized I/O performance on multi-core systems. In Proceedings of the 4th ACM/IEEE Symposium on Architectures for Networking and Communications Systems, San Jose, CA, USA, 6–7 November 2008; pp. 161–170. [Google Scholar]
- Intel. PCI-SIG SR-IOV Primer: An Introduction to SR-IOV Technology; Intel: Santa Clara, CA, USA, 2011. [Google Scholar]
- Firestone, D.; Putnam, A.; Mundkur, S.; Chiou, D.; Dabagh, A.; Andrewartha, M.; Angepat, H.; Bhanu, V.; Caulfield, A.; Chung, E.; et al. Azure Accelerated Networking: SmartNICs in the Public Cloud. In Proceedings of the 15th USENIX Symposium on Networked Systems Design and Implementation (NSDI 18), 2018; Available online: https://www.usenix.org/sites/default/files/conference/protected-files/nsdi18_slides_firestone.pdf (accessed on 11 June 2018).
- Kim, J.; Jang, K.; Lee, K.; Ma, S.; Shim, J.; Moon, S. NBA (network balancing act): A high-performance packet processing framework for heterogeneous processors. In Proceedings of the Tenth European Conference on Computer Systems, Bordeaux, France, 21–24 April 2015; p. 22. [Google Scholar]
- Yasukata, K.; Huici, F.; Maffione, V.; Lettieri, G.; Honda, M. HyperNF: Building a high performance, high utilization and fair NFV platform. In Proceedings of the 2017 Symposium on Cloud Computing, Santa Clara, CA, USA, 24–27 September 2017; pp. 157–169. [Google Scholar]
- Thimmaraju, K.; Shastry, B.; Fiebig, T.; Hetzelt, F.; Seifert, J.P.; Feldmann, A.; Schmid, S. Taking control of sdn-based cloud systems via the data plane. In Proceedings of the Symposium on SDN Research, Los Angeles, CA, USA, 28–29 March 2018; p. 1. [Google Scholar]
- Heller, B.; Sherwood, R.; McKeown, N. The controller placement problem. In Proceedings of the First Workshop on Hot Topics in Software Defined Networks, Helsinki, Finland, 13 August 2012; pp. 7–12. [Google Scholar]
- OpenFlow Switch Specification. Available online: https://www.opennetworking.org/wp-content/uploads/2014/10/openflow-switch-v1.5.1.pdf (accessed on 16 August 2018).
- Bahl, V. Cloudlets for Mobile Computing. 2014. Available online: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/11/Cloudlets-for-Mobile-Computing.pdf (accessed on 16 August 2018).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Programming Language | Operating Systems | Architecture | Northbound API |
|---|---|---|---|---|
| Beacon [29] | Java | Linux | centralized multi-threaded | Ad hoc API |
| DISCO [30] | Java | Linux, Mac OS | distributed | REST |
| Floodlight [31] | Java | Linux, Mac OS | centralized multi-threaded | RESTful API |
| HP VANSDN [32] | Java | Linux (Ubuntu) | distributed | RESTful API |
| HyperFlow [33] | C++ | Linux | distributed | N/A |
| Onix [34] | Python, C | N/A | distributed | NVP NBAPI |
| Maestro [35] | Java | Linux (Ubuntu 32bit) | centralized multi-threaded | Ad hoc API |
| Meridian [36] | Java | Linux, Mac OS | centralized multi-threaded | extensible API layer |
| NOX [37] | C++ | Linux | centralized | Ad hoc API |
| NOX-MT [19] | C++ | Linux | centralized multi-threaded | Ad hoc API |
| OpenDaylight [38] | Java | Linux | distributed | REST, RESTCONF |
| OSDN controller [39] | Java | OS X (Mavericks and later), Linux (Ubuntu 64 bit) | distributed | RESTful API |
| PANE [40] | Haskell | OS X (10.6 and up), Linux (Ubuntu) | distributed | PANE |
| POX [41] | Python | Windows, Mac OS, and Linux | centralized | Ad hoc API |
| RyuSDN controller [42] | Python | Linux | centralized multi-threaded | Ad hoc API |
| SMaRtLight [43] | Java | Linux | distributed | RESTful API |
| Packet Size | 64 Bytes | 1500 Bytes |
|---|---|---|
| Unmodified Linux | 374 Kpps | 381 Kpps |
| Linux with SP2 | 664 Kpps | 663 Kpps |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, K.; Lee, C.; Hong, C.-H.; Yoo, C. Enhancing the Isolation and Performance of Control Planes for Fog Computing. Sensors 2018, 18, 3267. https://doi.org/10.3390/s18103267
Lee K, Lee C, Hong C-H, Yoo C. Enhancing the Isolation and Performance of Control Planes for Fog Computing. Sensors. 2018; 18(10):3267. https://doi.org/10.3390/s18103267
Chicago/Turabian StyleLee, Kyungwoon, Chiyoung Lee, Cheol-Ho Hong, and Chuck Yoo. 2018. "Enhancing the Isolation and Performance of Control Planes for Fog Computing" Sensors 18, no. 10: 3267. https://doi.org/10.3390/s18103267
APA StyleLee, K., Lee, C., Hong, C. -H., & Yoo, C. (2018). Enhancing the Isolation and Performance of Control Planes for Fog Computing. Sensors, 18(10), 3267. https://doi.org/10.3390/s18103267