An End-to-End Deep Reinforcement Learning-Based Intelligent Agent Capable of Autonomous Exploration in Unknown Environments


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Our algorithm uses the DRL method for learning from scratch to explore and avoid obstacles in an unknown environment, in an end-to-end fashion or, in other words, without preprocessing our sensor data, in an autonomous, continuous and adaptive way.
- While our proposed algorithm in this paper is able to use discrete actions for exploration and obstacle avoidance, we enhanced our previous work even more in order to be able to work in a continuous action space as well.
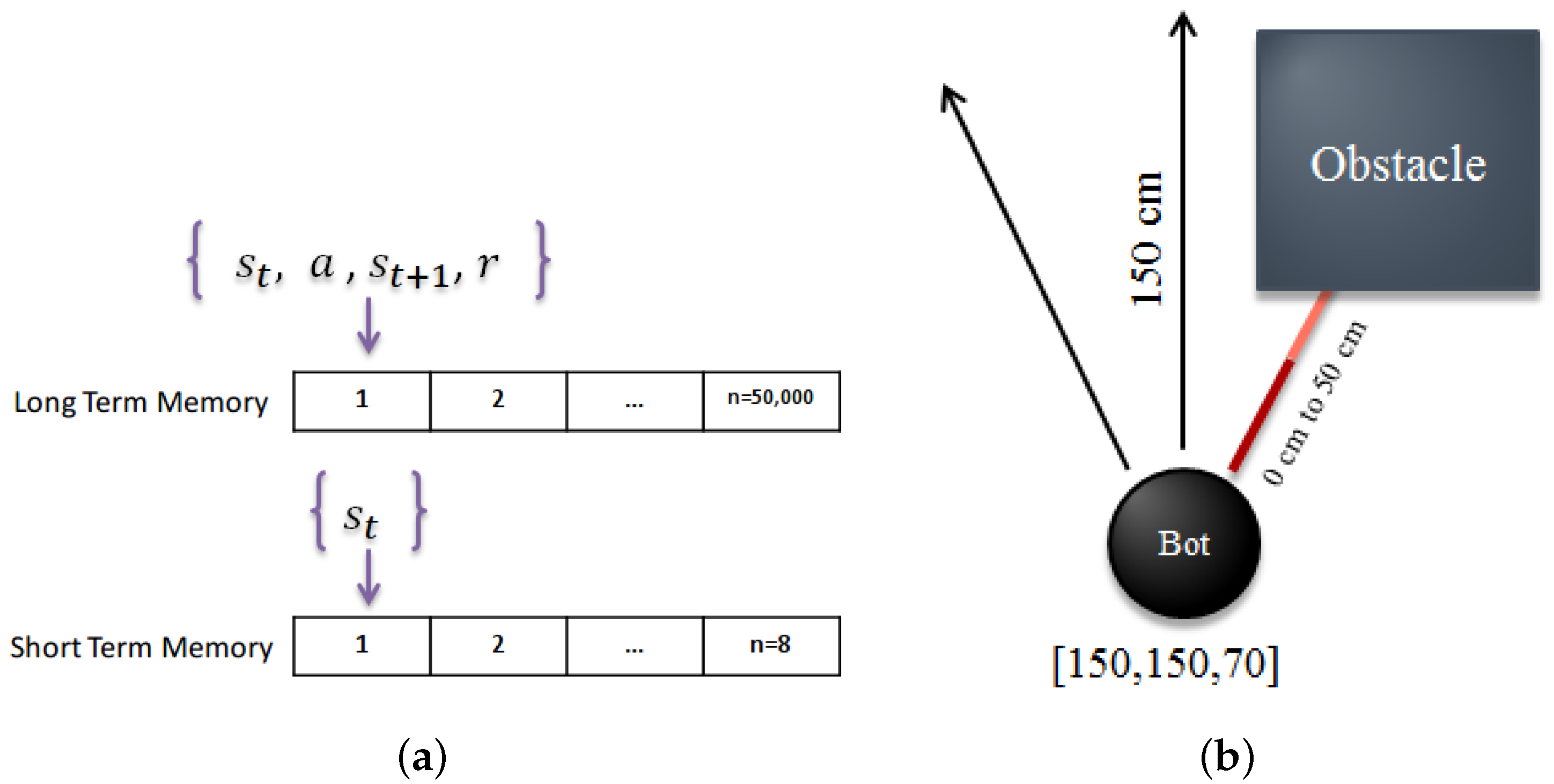
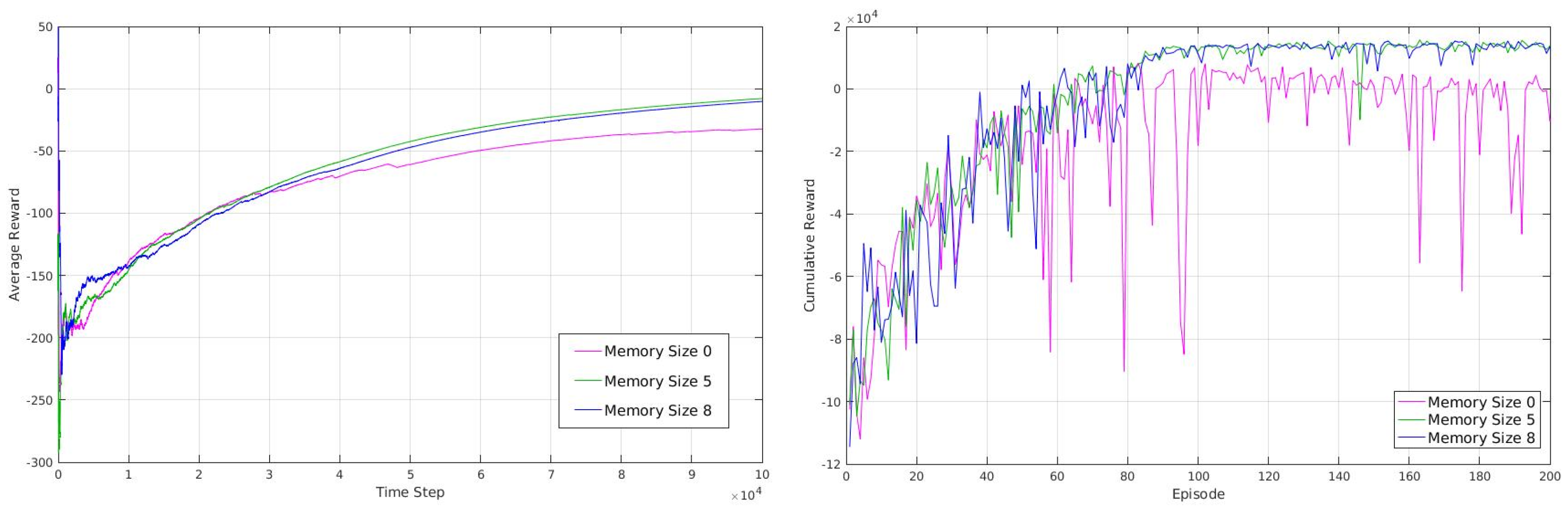
- Our algorithm benefits from having a memory-based implementation, it has a long-term and a short-term memory, which allows our robot to be able to distinguish between similar states and being able to learn from its own long-term experiences.
- We use a centralized sensor fusion technique in order to overcome the noise that exists in a real-world scenario and to be able to recognize the environment in a robust way.
- Our algorithm is tested in a simulated robot; nevertheless, in this paper, we moved further and implemented our algorithm in a real robot.
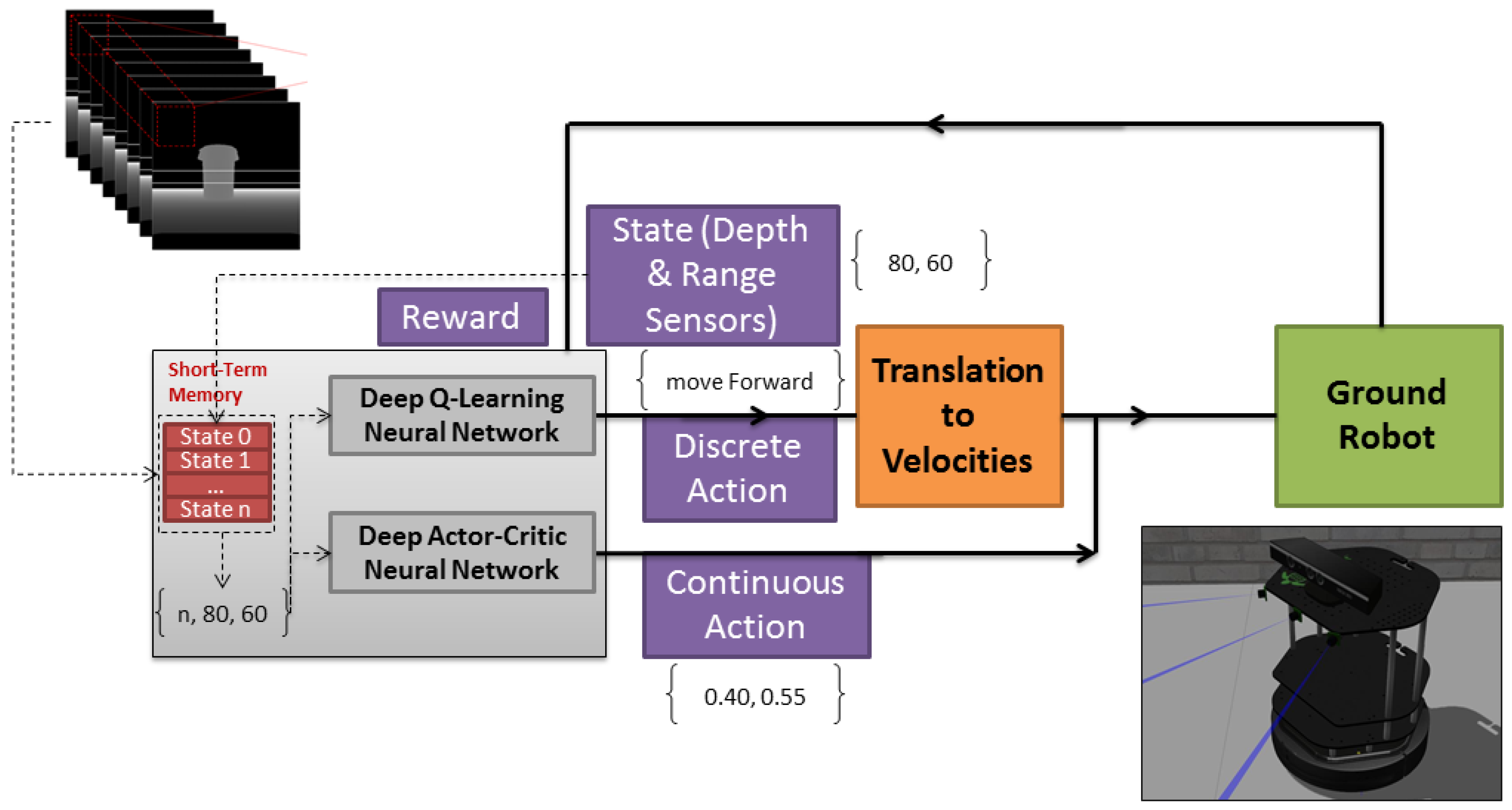
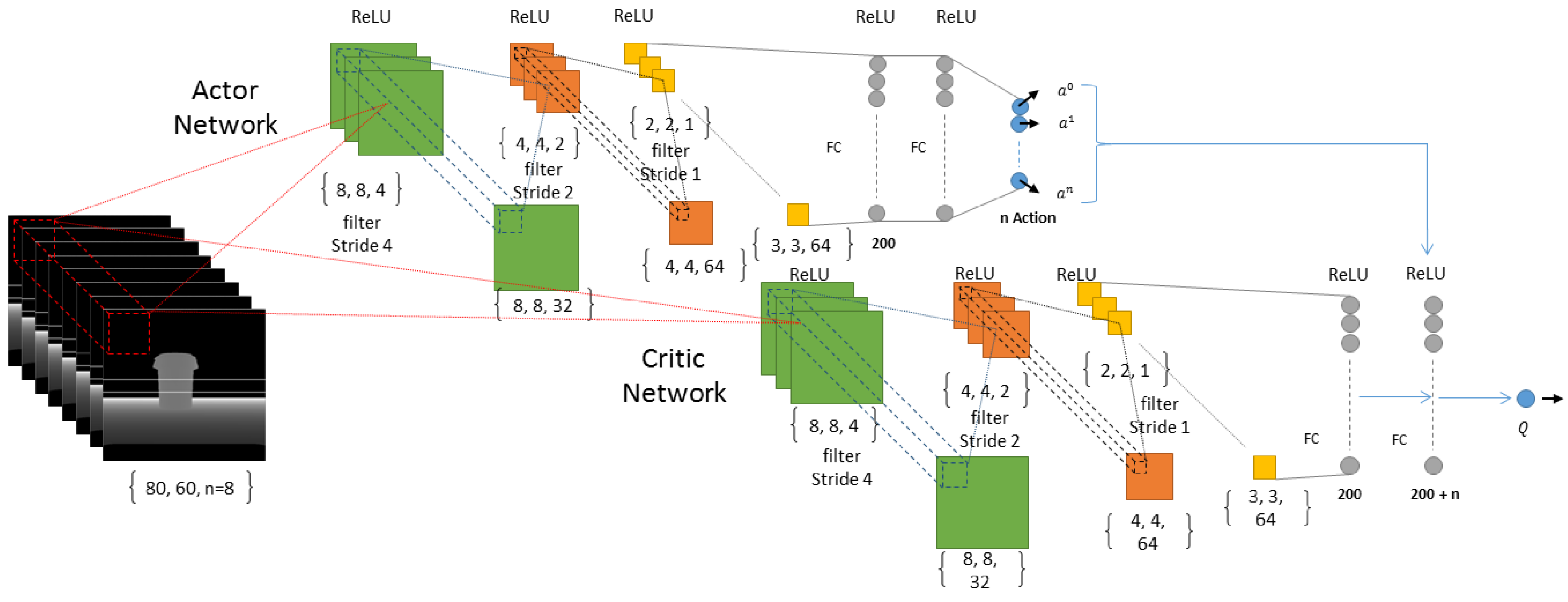
2. Memory-Based Deep Reinforcement-Learning (MDRL)
| Algorithm 1 Memory-based Deep Reinforcement Learning (MDRL) Algorithm | ||
| 1: | procedureSensor_Fusion() | |
| 2: | if (each RangeSensors Value <0.5 m) then | |
| 3: | DepthImage[at the related positions] = Particular RangeSensors Value | |
| 4: | end if | |
| 5: | return DepthImage | |
| 6: | end procedure | |
| 7: | procedureReward() | |
| 8: | ||
| 9: | ▹ Range Sensor values are scaled to be in range[0, 1.0], originally were [0, 200] cm | |
| 10: | ||
| 11: | if (Action_Type==Discrete_Action) then | |
| 12: | if (Action == forward) then: | |
| 13: | else if (Action == turning) then: | |
| 14: | end if | |
| 15: | else if (Action_Type==Continuous_Action) then | |
| 16: | ▹ Action[0] = real value generated for linear_velocity_x of robot | |
| 17: | end if | |
| 18: | ||
| 19: | return | |
| 20: | end procedure | |
| 21: | procedureGet_State() | |
| 22: | ||
| 23: | ||
| 24: | return s | |
| 25: | end procedure | |
| 26: | procedureMain() | ▹ main procedure |
| 27: | Initialize Action_Type | |
| 28: | if (Action_Type==Discrete_Action) then | |
| 29: | Randomly initialize deep network | |
| 30: | Initialize deep target network with weights | |
| 31: | while do | ▹ this procedure continues for ever |
| 32: | ||
| 33: | Select Action according to Policy | |
| 34: | ▹ or Random Action Considering an Annealing | |
| 35: | Wait for robot to move to the new position | |
| 36: | ||
| 37: | : Store transition in DeepReplayMemory | |
| 38: | Set | |
| 39: | Update deep Q -network by minimizing the loss: | |
| 40: | Update the deep target network, | |
| 41: | end while | |
| 42: | else if (Action_Type==Continuous_Action) then | |
| 43: | Randomly initialize deep Critic network and deep Actor network | |
| 44: | Initialize deep target network and with weights , | |
| 45: | while do | ▹ this procedure continues for ever |
| 46: | ||
| 47: | Select action | |
| 48: | ▹ | |
| 49: | Wait for robot to move to the new position | |
| 50: | ||
| 51: | : Store transition in DeepReplayMemory | |
| 52: | Set | |
| 53: | Update deep Critic network by minimizing the loss: | |
| 54: | Update deep Actor network by using the sampled policy gradient: | |
| 55: | ||
| 56: | Update the deep target networks: | |
| 57: | ||
| 58: | end while | |
| 59: | end if | |
| 60: | end procedure | |
2.1. Control and Decision-Making
- Our algorithm does not have a model of the problem (environment)
- Using long-term memory by implementing a method mentioned in [18], a model-free RL agent is needed
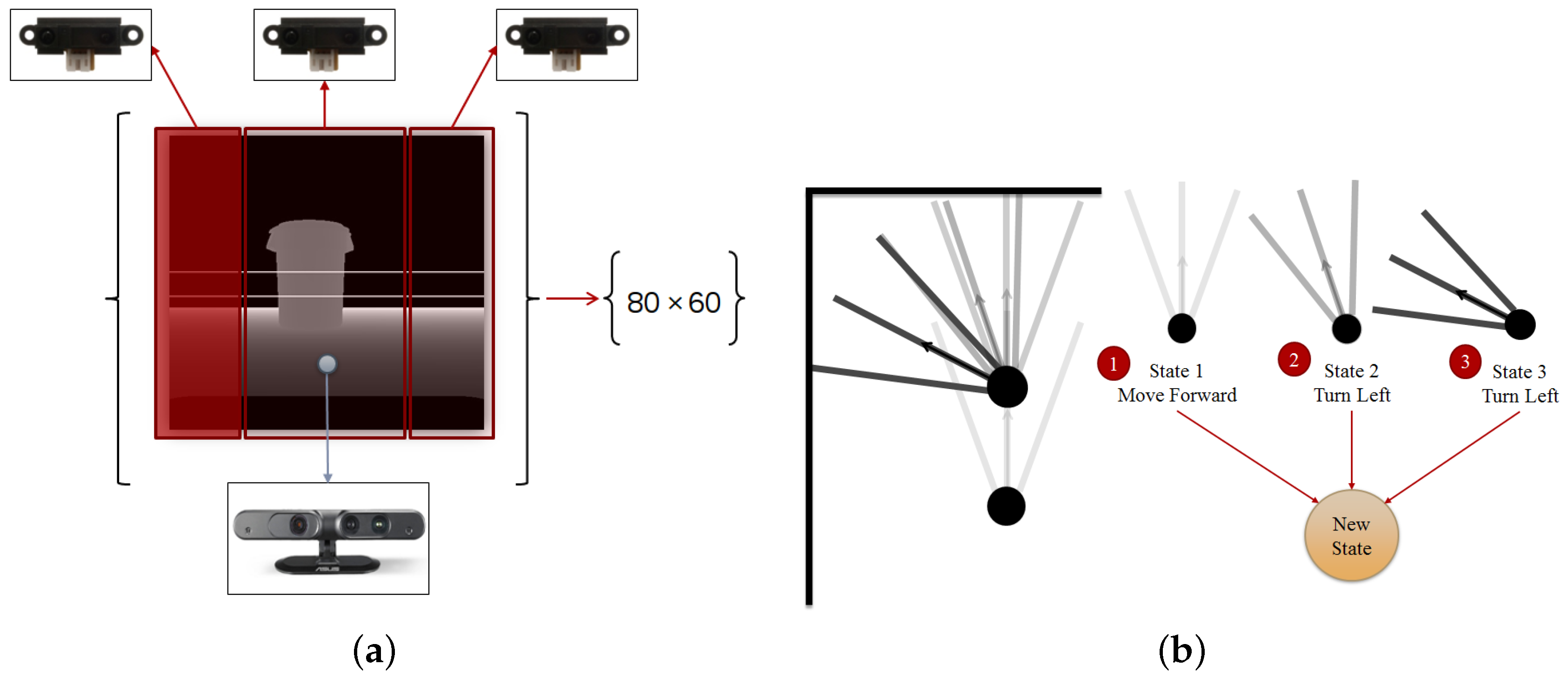
2.2. Discrete Action
2.3. Continuous Action
2.4. Sensor Fusion Technique
2.5. Memory-Based Method
2.6. State Perception
2.7. Agent Reward
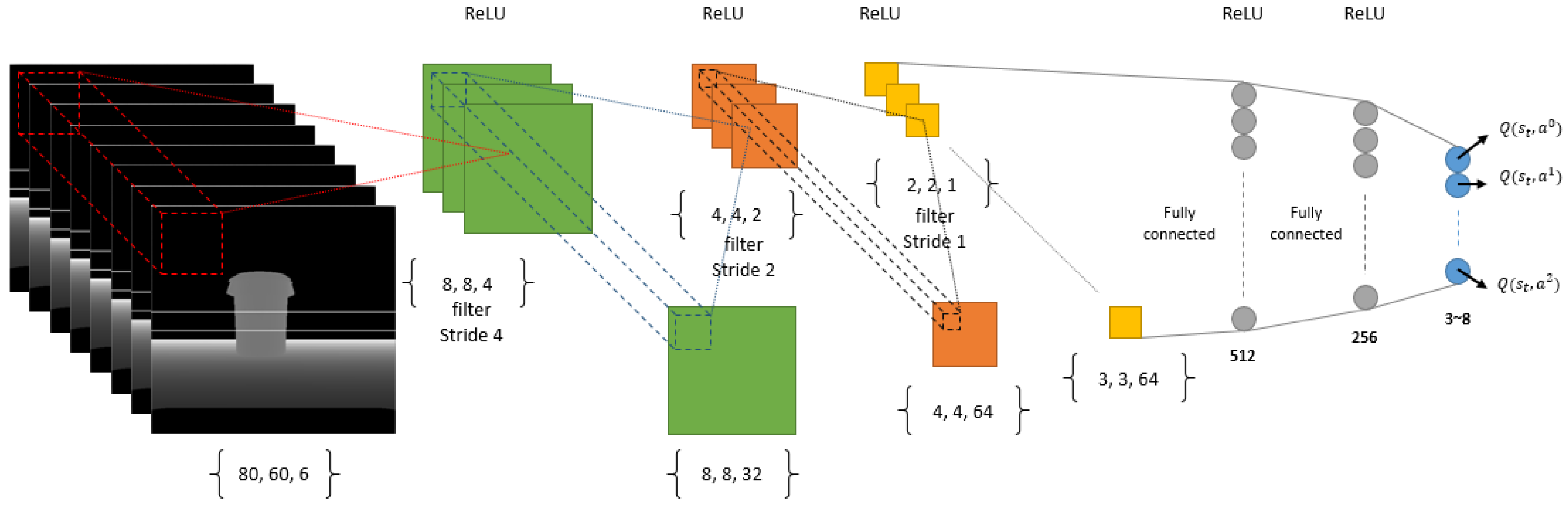
2.8. Deep Neural Network
3. Simulation
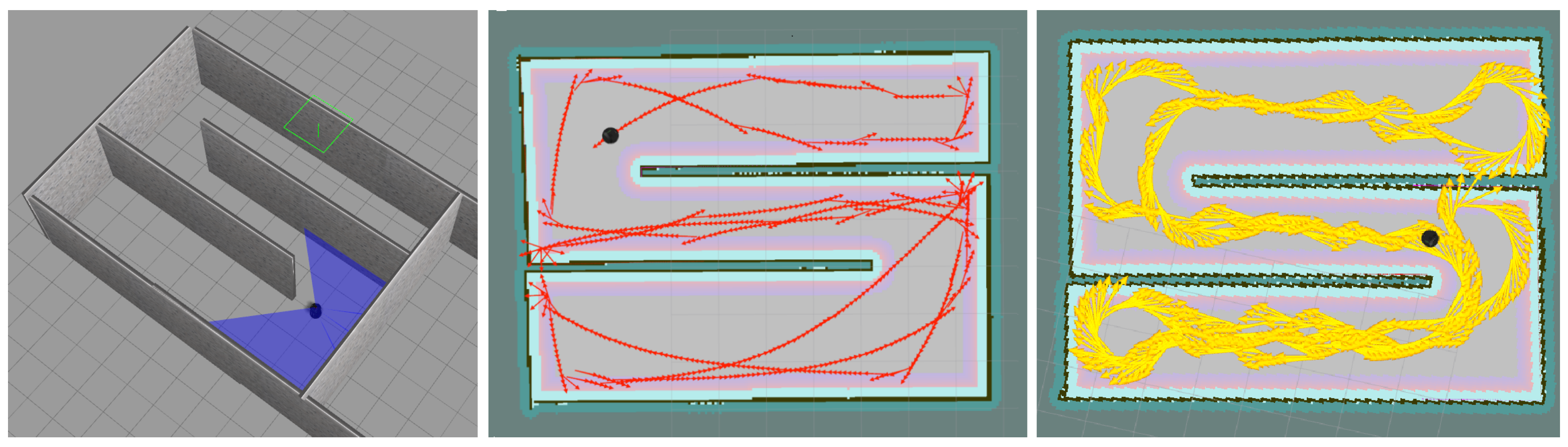
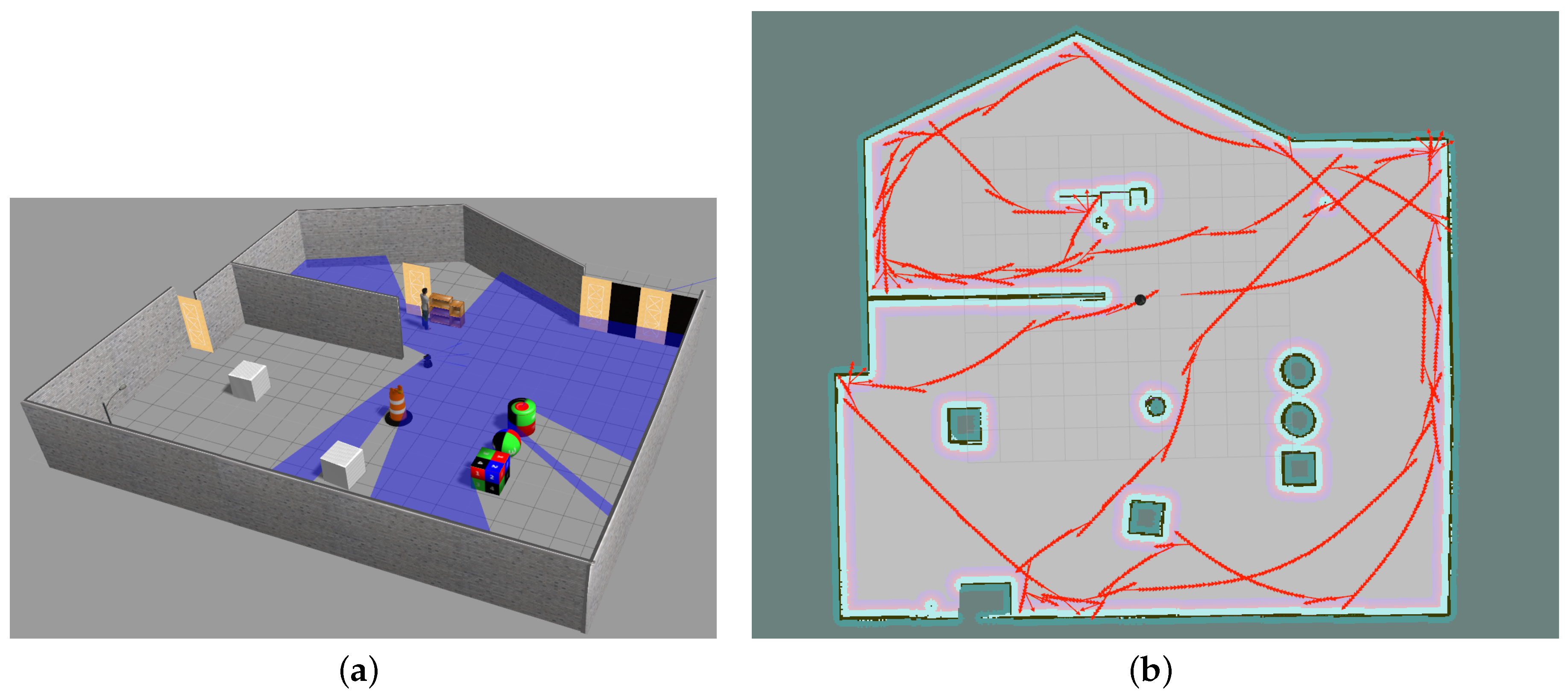
3.1. Environment
3.2. Result
4. Real Test
4.1. Environment
4.2. Robot
4.2.1. Sensors
4.2.2. Actuators
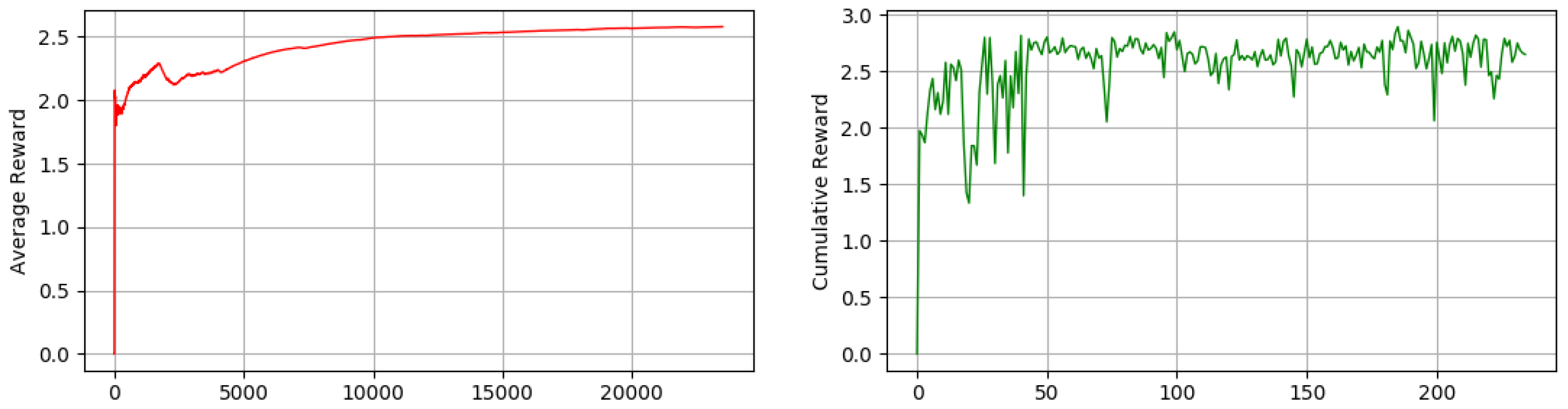
4.3. Training and Testing
- Train the robot using uninitialized DNN weights: In this scenario, the robot starts training from scratch similar to the simulation case. Implementing this method comes with some difficulties such as the limited energy source of the robot (Robot Battery). Nevertheless, it is crucial for a real robot to have power in order to run all the modules on board. In particular, in our robot we have different modules that are needed to be powered so the robot can execute our algorithm successfully and explore and avoid obstacles autonomously. For example, in our robot we have a TK1 processing unit, 3 Infrared Proximity Sensors, 1 Arduino, Kobuki Yujin, and a depth sensor. All in all, for training our robot using uninitialized DNN weights it needs some time to move around and fill the long-term memory, and using SGD in order to reduce the loss of our q-function and converge to an optimal policy. To solve the issue of power supply there are different possibilities:
- -
- Software-based solution: It is possible to measure the battery level using internal sensors of Kobuki Yujin, thus, one possibility is to write a procedure for the robot to alarm when the battery is low and stop the training procedure, so a human carer can move the robot and connect it to the power supply, as soon as the power supply level moves above a specific percentage then the robot can resume the training procedure.
- -
- Hardware-based solution: Adding to the battery cells is one possibility or adding an external battery, but the issue with this method is that it still is possible that the robot turns off in the middle of the training procedure and an external battery can make the robot much heavier. Thus, a better hardware-based solution can be the use of a flexible electrical wire that is hung from the roof and allows the robot to move around for training.
- Using the initialized DNN weights generated in the simulation: By attaching the depth and range sensors in the same position in the real robot that is defined and used in the simulated robot, the DNN weights that are generated by training the robot in a simulated world can be used in the real robot. The benefit of this method is that it can tackle the problem of energy limitation (Battery) and remove the time necessary for training. That being said, it is important to pay attention to two points. Firstly, even though our robot does not do the training step, it still is learning and updating its policy in case there is a change in the environment and this will let the robot to easily move to another unknown environment and adapt itself. Secondly, using DNN weights generated in simulation from scratch for the real robot that uses the same algorithm is totally different to initializing the DNN weights from the beginning in the simulated robot using supervised learning.
4.4. Result
5. Discussion
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| RL | Reinforcement Learning |
| DRL | Deep Reinforcement Learning |
| DQN | Deep Q-Network |
| DNN | Deep Neural Network |
| ROS | Robot Operating System |
| SLAM | Simultaneous Localization and Mapping |
| MDRL | Memory-based Deep Reinforcement Learning |
| DDPG | Deep Deterministic Policy Gradient |
| MLP | Multi-Layer Perceptron |
References
- Du, R.; Zhang, X.; Chen, C.; Guan, X. Path Planning with Obstacle Avoidance in PEGs: Ant Colony Optimization Method. In Proceedings of the 2010 IEEE/ACM Int’L Conference on Green Computing and Communications & Int’L Conference on Cyber, Physical and Social Computing, GREENCOM-CPSCOM ’10, Hangzhou, China, 18–20 December 2010; IEEE Computer Society: Hangzhou, China, 2010; pp. 768–773. [Google Scholar] [CrossRef]
- Pauplin, O.; Louchet, J.; Lutton, E.; Parent, M. Applying Evolutionary Optimisation to Robot Obstacle Avoidance. arXiv, 2004; arXiv:cs/0510076. [Google Scholar]
- Lin, C.J.; Li, T.H.S.; Kuo, P.H.; Wang, Y.H. Integrated Particle Swarm Optimization Algorithm Based Obstacle Avoidance Control Design for Home Service Robot. Comput. Electr. Eng. 2016, 56, 748–762. [Google Scholar] [CrossRef]
- Kim, C.J.; Chwa, D. Obstacle Avoidance Method for Wheeled Mobile Robots Using Interval Type-2 Fuzzy Neural Network. IEEE Trans. Fuzzy Syst. 2015, 23, 677–687. [Google Scholar] [CrossRef]
- Zhang, H.; Han, X.; Fu, M.; Zhou, W. Robot Obstacle Avoidance Learning Based on Mixture Models. J. Robot. 2016, 2016, 7840580. [Google Scholar] [CrossRef]
- Tai, L.; Li, S.; Liu, M. A deep-network solution towards model-less obstacle avoidance. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 2759–2764. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Introduction to Reinforcement Learning, 1st ed.; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Lee, H.; Shen, Y.; Yu, C.H.; Singh, G.; Ng, A.Y. Quadruped robot obstacle negotiation via reinforcement learning. In Proceedings of the 2006 IEEE International Conference on Robotics and Automation, Orlando, FL, USA, 15–19 May 2006; pp. 3003–3010. [Google Scholar] [CrossRef]
- Kominami, K.; Takubo, T.; Ohara, K.; Mae, Y.; Arai, T. Optimization of obstacle avoidance using reinforcement learning. In Proceedings of the 2012 IEEE/SICE International Symposium on System Integration (SII), Fukuoka, Japan, 16–18 December 2012; pp. 67–72. [Google Scholar] [CrossRef]
- Zhang, T.; Kahn, G.; Levine, S.; Abbeel, P. Learning Deep Control Policies for Autonomous Aerial Vehicles with MPC-Guided Policy Search. arXiv, 2015; arXiv:1509.06791. [Google Scholar]
- Sadeghi, F.; Levine, S. RL: Real Single-Image Flight without a Single Real Image. arXiv, 2016; arXiv:1611.04201. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Lei, T.; Ming, L. A robot exploration strategy based on Q-learning network. In Proceedings of the IEEE International Conference on Real-time Computing and Robotics (RCAR), Angkor Wat, Cambodia, 6–10 June 2016; pp. 57–62. [Google Scholar] [CrossRef]
- Smolyanskiy, N.; Kamenev, A.; Smith, J.; Birchfield, S. Toward low-flying autonomous MAV trail navigation using deep neural networks for environmental awareness. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 4241–4247. [Google Scholar] [CrossRef]
- Dooraki, A.R.; Lee, D.J. Memory-based reinforcement learning algorithm for autonomous exploration in unknown environment. Int. J. Adv. Robot. Syst. 2018, 15, 1729881418775849. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv, 2015; arXiv:1509.02971. [Google Scholar]
- Watkins, C.J.; Dayan, P. Technical Note: Q-Learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Lin, L.J. Reinforcement Learning for Robots Using Neural Networks. Ph.D. Thesis, Carnegie-Mellon Univ Pittsburgh PA School of Computer Science, Pittsburgh, PA, USA, 1992. [Google Scholar]
- Gazebo Simulator. Available online: http://gazebosim.org/ (accessed on 16 March 2017).
- Autonomous Deep Learning Robot. Available online: https://www.autonomous.ai/deep-learning-robot (accessed on 16 March 2017).
- ROS.org|Powering the World’s Robots. Available online: http://www.ros.org/ (accessed on 16 March 2017).
- Gmapping—ROS WIKI. Available online: http://wiki.ros.org/gmapping (accessed on 16 March 2018).














© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramezani Dooraki, A.; Lee, D.-J. An End-to-End Deep Reinforcement Learning-Based Intelligent Agent Capable of Autonomous Exploration in Unknown Environments. Sensors 2018, 18, 3575. https://doi.org/10.3390/s18103575
Ramezani Dooraki A, Lee D-J. An End-to-End Deep Reinforcement Learning-Based Intelligent Agent Capable of Autonomous Exploration in Unknown Environments. Sensors. 2018; 18(10):3575. https://doi.org/10.3390/s18103575
Chicago/Turabian StyleRamezani Dooraki, Amir, and Deok-Jin Lee. 2018. "An End-to-End Deep Reinforcement Learning-Based Intelligent Agent Capable of Autonomous Exploration in Unknown Environments" Sensors 18, no. 10: 3575. https://doi.org/10.3390/s18103575
APA StyleRamezani Dooraki, A., & Lee, D. -J. (2018). An End-to-End Deep Reinforcement Learning-Based Intelligent Agent Capable of Autonomous Exploration in Unknown Environments. Sensors, 18(10), 3575. https://doi.org/10.3390/s18103575