Evaluation of Strategies for the Development of Efficient Code for Raspberry Pi Devices


Abstract
:1. Introduction
2. Scope and Objectives
3. Related Work
4. Materials and Methods
- : without optimization for execution time. The objective of the compiler is to reduce the cost of compilation and to allow debugging to produce the expected results. This is the default. The other levels of optimization increase compilation time and the ability to debug the program may disappear.
- : optimization for code size and execution time.
- : the compiler performs nearly all supported optimizations that do not involve a space–speed tradeoff. This option increases both compilation time and the performance of the generated code.
- : maximum level of optimization (at the expense of compilation time, and possibly the ability to debug the program).
| Algorithm 1 Time measurement. |
|
#ifdef level #define OPTIMIZE __attribute__((optimize(level))) #else #define OPTIMIZE #endif
#include <chrono>
using namespace std::chrono;
class Watchtime{
std::chrono::system_clock::time_point m_start;
system_clock::duration diff;
public:
void startTime();
unsigned getTime();
};
void Watchtime::startTime(){
system_clock::time_point::min(); // clears the timer
Watchtime::m_start = std::chrono::system_clock::now(); // start the timer
}
unsigned Watchtime::getTime(){
Watchtime::diff = system_clock::now() - m_start;
return (unsigned)(duration_cast<milliseconds>(diff).count());
}
5. Techniques to Write Efficient Code
- T1
- Bit fields: a bit field is a data structure to hold a sequence of a certain number of bits with the objective of improving the use of memory space—for instance, to avoid the use of structures which require 8 bits of memory space, when only 2 of them are used. This is common with true/false variables. However, bit fields are usually accessed using pointers, which leads to aliasing problems. Consequently, in terms of speed, it is recommended to use an integer and, in any case, applying or masks to divide it. The experiment illustrates this problem, comparing the individual access to each of the four bits of a structure versus the use of a single integer.
- T2
- Boolean return: returning several boolean variables at the end of a function is not a recommended practice, since each one of these returns implies using a whole register by itself. Instead, the conversion of multiple bools into a single is advised, with the help of associated flag definitions. In this way, several checks can be made thanks to a single logical operation.
- T3
- Cascaded function calls: as far as possible, cascaded function calls that return pointers or references should be avoided. For instance, in this experiment, the result of the call to the function, which is repeated N times, can be replaced by a single call by storing the reference to and using it within the loop. In this case the programmer, unlike the compiler, can know that always returns the same reference.
- T4
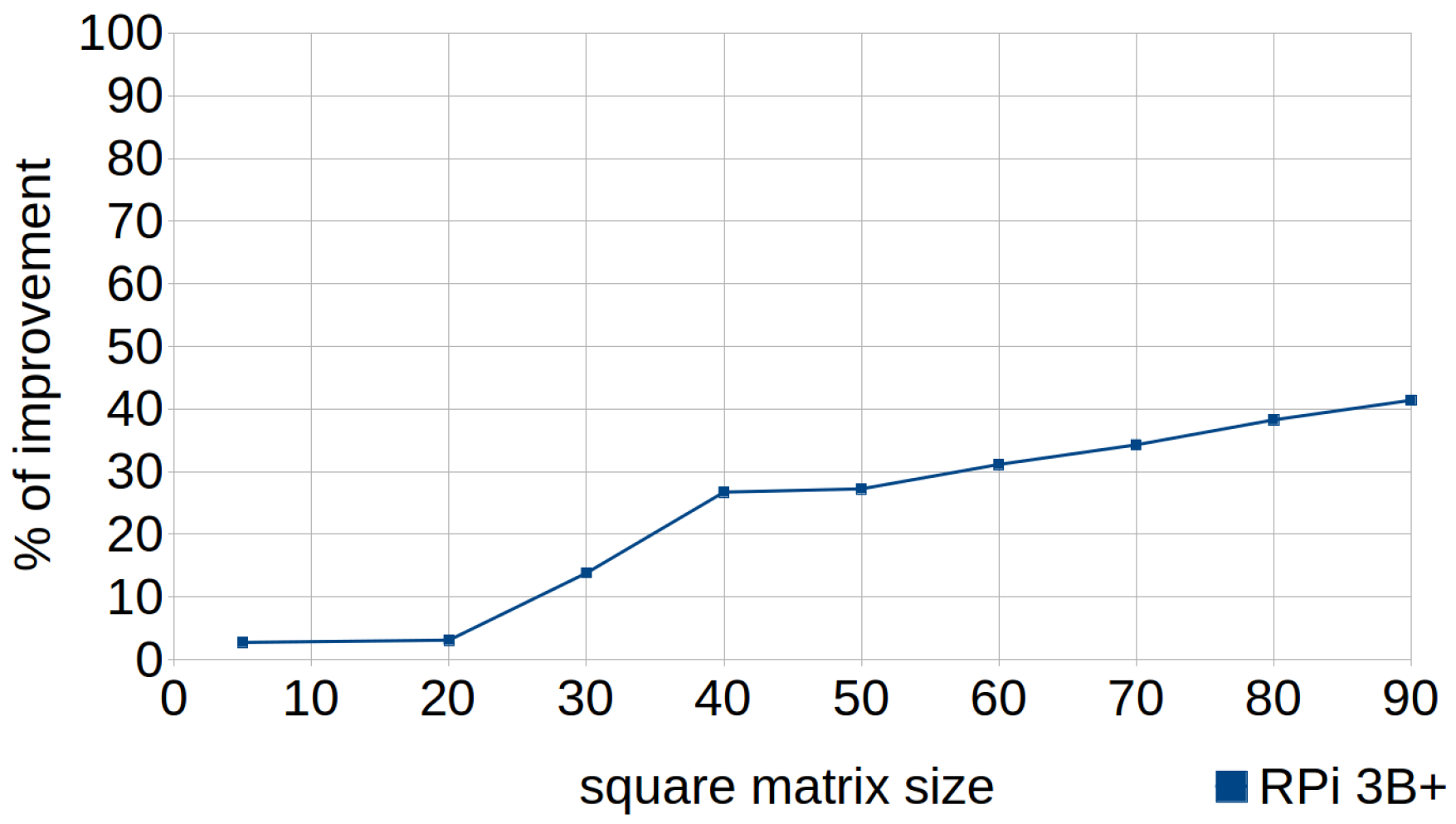
- Row-major accessing: languages such as Fortran or MATLAB support two-dimensional arrays stored in a contiguous by column-major order, whereas row-major is used in C and C++. This means that the element is stored right next to x. Thus, it is recommended to increment the leftmost index first when stepping through two-dimensional arrays, with the objective of achieving a higher rate of cache hits when accessing them. Both of these ways to traverse a two-dimensional array were used in the experiment.
- T5
- Constructor initialization lists: regarding the constructors, the use of initialization lists is recommended when setting the initial values of the variables. Otherwise, assignments within the body imply that the default constructors of the variables are always invoked, with the consequent overhead. For instance, in the experiment the constructor is called first for two attributes, then the assignment operator of is called inside the body of a class constructor to assign the values. Afterwards, the destructor of is called when the two attributes got out of scope. This code is compared to another one in which, in a class, the arguments in the initialization list are used to copy the variables directly.
- T6
- Common subexpression elimination: identical expressions that are computed repeatedly, without changing the values of their operands, can be replaced with single variables that hold the computed values. The experiment analyses the effect of storing an addition operation with an integer and a square root in a local variable, to use in the rest of the code.
- T7
- Mapping structures: the use of tables when mapping values to constants, changing the checklist of each of the possible cases (with nested statements) by a loop that traverses the table looking for the right constant is recommended.
- T8
- Dead code elimination: this is one of the best known and widely applied optimizations by compilers. When an instruction is totally unreachable or does not influence the result (e.g., in the case of variables that are never used), it can be eliminated. The experiment analyses the impact of two never-used variables assignments and an unreachable line.
- T9
- Exception handling: this is used with the objective of changing the normal flow of an execution when anomalous or exceptional conditions occur. In this way, exceptions are necessary to deal with unexpected errors. In fact, it should be noted that all the containers in the C++ standard library use new expressions that throw exceptions [22]. However, in some cases it is possible to significantly improve performance when they are used within a loop, since they can be replaced by or statements, as applied in this experiment.
- T10
- Global variables within loops: regarding the use of assignments to global variables within loops, it is recommended to move these allocations out of the loops by computing the corresponding operations in local variables and not performing the assignments in the global variables until the end of the loop is reached. The benefits of using this technique are analyzed in the experiment.
- T11
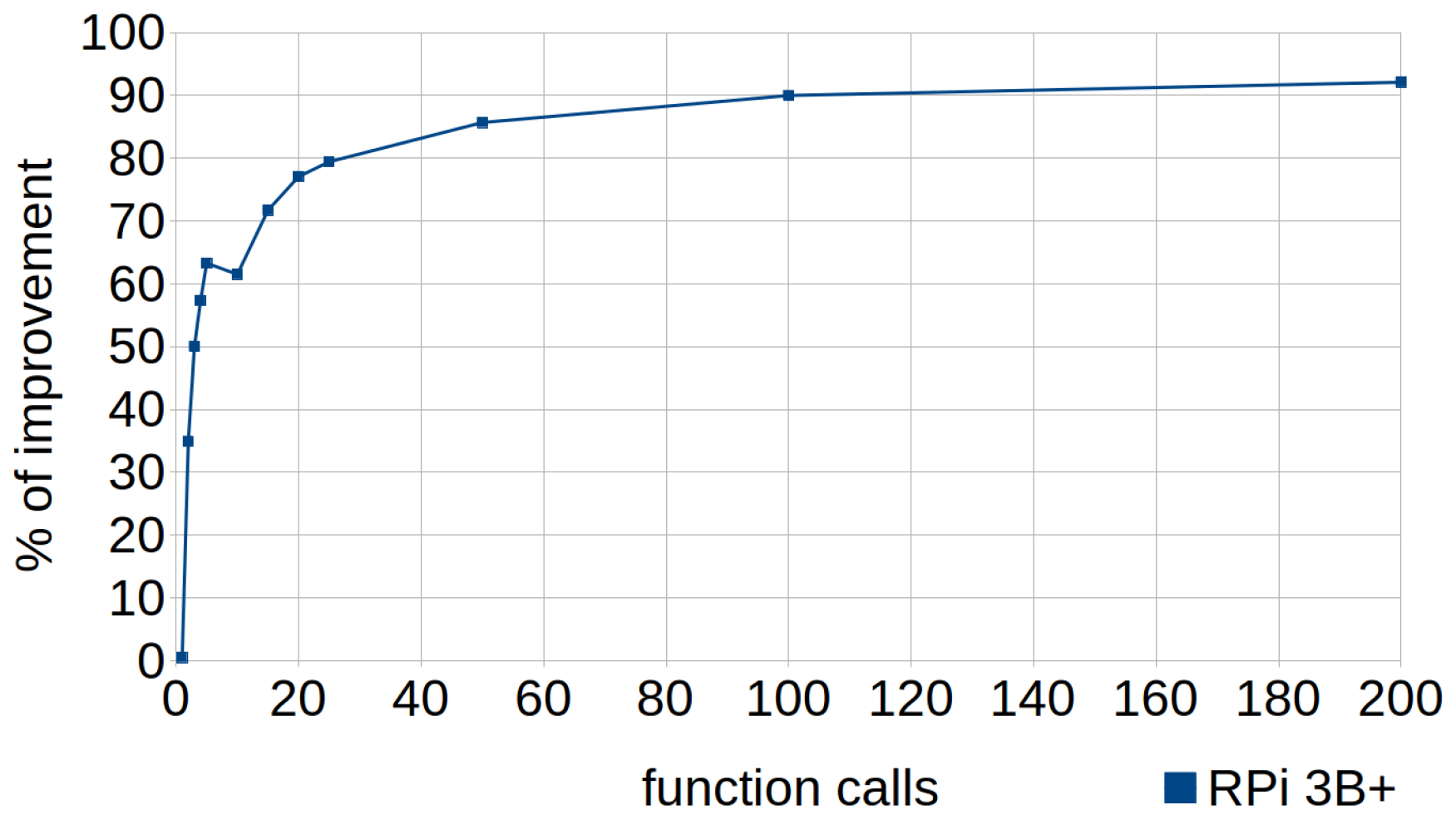
- Function inlining: it is an effective method to completely remove the overhead caused each time a function is called. In fact, it is reported by some researchers as the most powerful code optimization [22]. Besides, this technique is preferred over the use of macros because the latter does not check the types of function [20]. It consists of replacing a call, inserting the code for the function, instead of calling it and thus removing call and return statements. A simple example is used in the experiment, where an addition function is expanded inline inside a subtraction one.
- T12
- Global variables: global variables are defined outside all functions, so their scope is the whole program. Therefore, their use is not recommended in order to avoid functions interfering with each other as little as possible, since global values can be changed by any function and may cause programming problems later. In addition, global variables are not allocated to registers, so they should not be used within critical loops in order to avoid unnecessary overhead. Thus, regarding runtime, if a function uses global variables heavily, it is also beneficial to copy their values to local variables and use these instead to improve access times, as discussed in the experiment.
- T13
- Constants inside loops: as far as possible, continuous access to constants within loops should be avoided. In many cases, however, this often leads to poor readability.
- T14
- Initialization versus assignment: it is recommended to initialize variables directly, instead of using a subsequent assignment, and so avoid the unnecessary assignment of the instantiation. The experiment evaluates the benefit of this technique when using complex numbers.
- T15
- Division by a power-of-two denominator: this technique consists of changing division expressions with power-of-two denominators by shift expressions, as shown in the experiment.
- T16
- Multiplication by a power-of-two factor: this technique, similar to the previous one, consists of changing multiplication expressions with power-of-two factors by shift expressions.
- T17
- Integer versus character: the use of integers is preferred over characters when performing arithmetic operations because C and C++ convert char values to integers before operating, later converting the result back to char again. The experiments analyze the effects of using characters or integers to make a sum.
- T18
- Loop count down: this technique can be applied when the order of the loop counter is not determinative. It consists of traversing the loop in the opposite direction to take advantage of the fact that it is quicker to process “i- -” as the loop condition. Instead, traversing the loop forward ( condition) means more steps: subtract i to 100, evaluate if the result is zero, if not, increment the iterator and continue, which may result in a significant time difference. This deviation is increased when in addition the loop is controlled by a statement, as analyzed in the experiment. Another important point that must be taken into account is the reduction of the cost of the loop termination clause, given the extensive number of times that it can be evaluated.
- T19
- Loop unrolling: there is the possibility of unrolling small loops to improve runtime, reducing the number of iterations and repeating the loop body several times. However, loop unrolling has an important disadvantage (i.e., code size is increased), so it should be applied carefully. Therefore, to avoid decreasing the performance of the cache, only unrolling loops which really affect the final runtime is recommended.
- T20
- Passing structures by reference instead of value: structures should be passed by reference on function calls whenever possible in order to avoid the overhead associated with the complete copy of each structure (including constructor and destructor) when passed by value. Since reference arguments can modify the original instance (unlike value arguments), it is recommended that pointers to structures be declared as constants when their pointed values are not going to change. The experiment consists of a class with two members and a data structure containing one integer attribute which is passed by reference in a first test and by value in a second one.
- T21
- Pointer aliasing: this refers to the case where the same address is pointed to by two or more pointers. Thus, writing to one will affect the reading from the other. Due to this possibility, the compiler is prevented from applying certain optimizations, affecting efficiency. The experiment consists of a common subexpression elimination (aforementioned in T6) involving memory accesses through pointer, which cannot be automatically optimized by the compiler due to aliasing. There are four addition operations, which add the value pointed to by the same pointer to integer to the values stored in four different addresses (also pointers to integer).
- T22
- Chains of pointers: this technique is directly related to the previous one, since it consists of an optimizing chain of pointers (a pointer which points to another pointer, and so on). The experiment analyzes the effect of caching a pointer to an object in a local variable, to then access the rest of the pointers instead of using the entire chain every time.
- T23
- Pre-increment versus post-increment: the use of pre-increment operators is preferred with data types whose classes overload pre-increment and post-increment operators. While the post-increment operator needs to create a previous copy of the object, the pre-increment avoids it.
- T24
- Linear search: generally, linear search through a list implies two main comparisons—one to control the loop iterations, and another to determine if the current key is the desired one. The performance can be improved with a single comparison if a statement is used (). To avoid problems when the searched value is not contained in the list, the size of the array should be increased and the desired value inserted at the end. In this way, the algorithm can know if the value was contained in the list by simply checking that the found index does not correspond to the last position.
- T25
- Invariant IF statements within loops: regarding loops, another technique that can be applied consists of transforming one loop into two when it contains a loop-invariant statement. For this, it is necessary to take the conditional expression out of the loop, so that one identical loop is traversed within each condition of the .
6. Experimental Results and Discussion
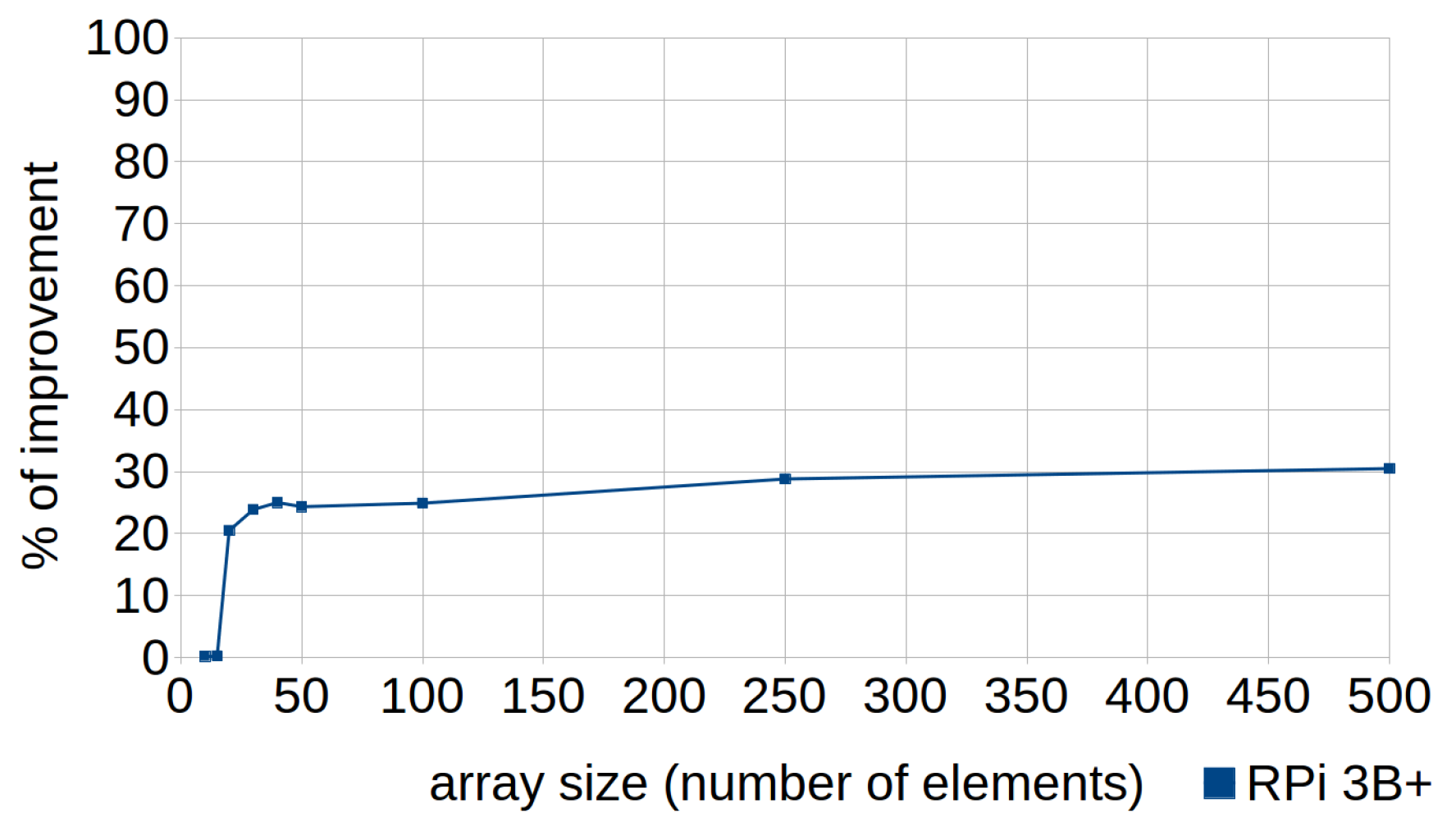
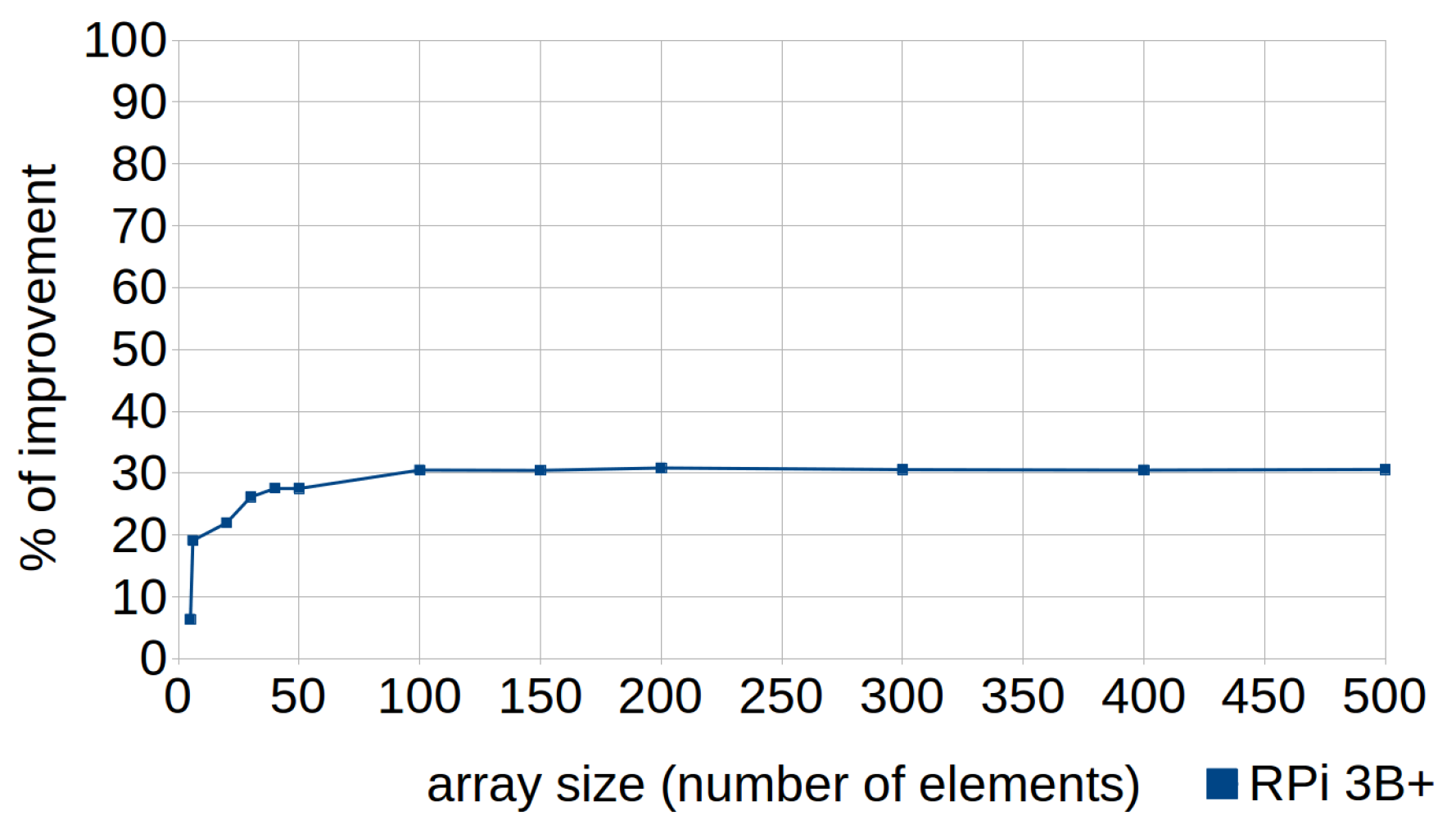
6.1. Cascaded Function Calls

6.2. Row-Major Accessing
int standard(){ int efficient(){
for (int j=0; j<N; j++) for (int i=0; i<N; i++)
for (int i=0; i<N; i++) for (int j=0; j<N; j++)
array[i][j] = 0; array[i][j] = 0;
} }
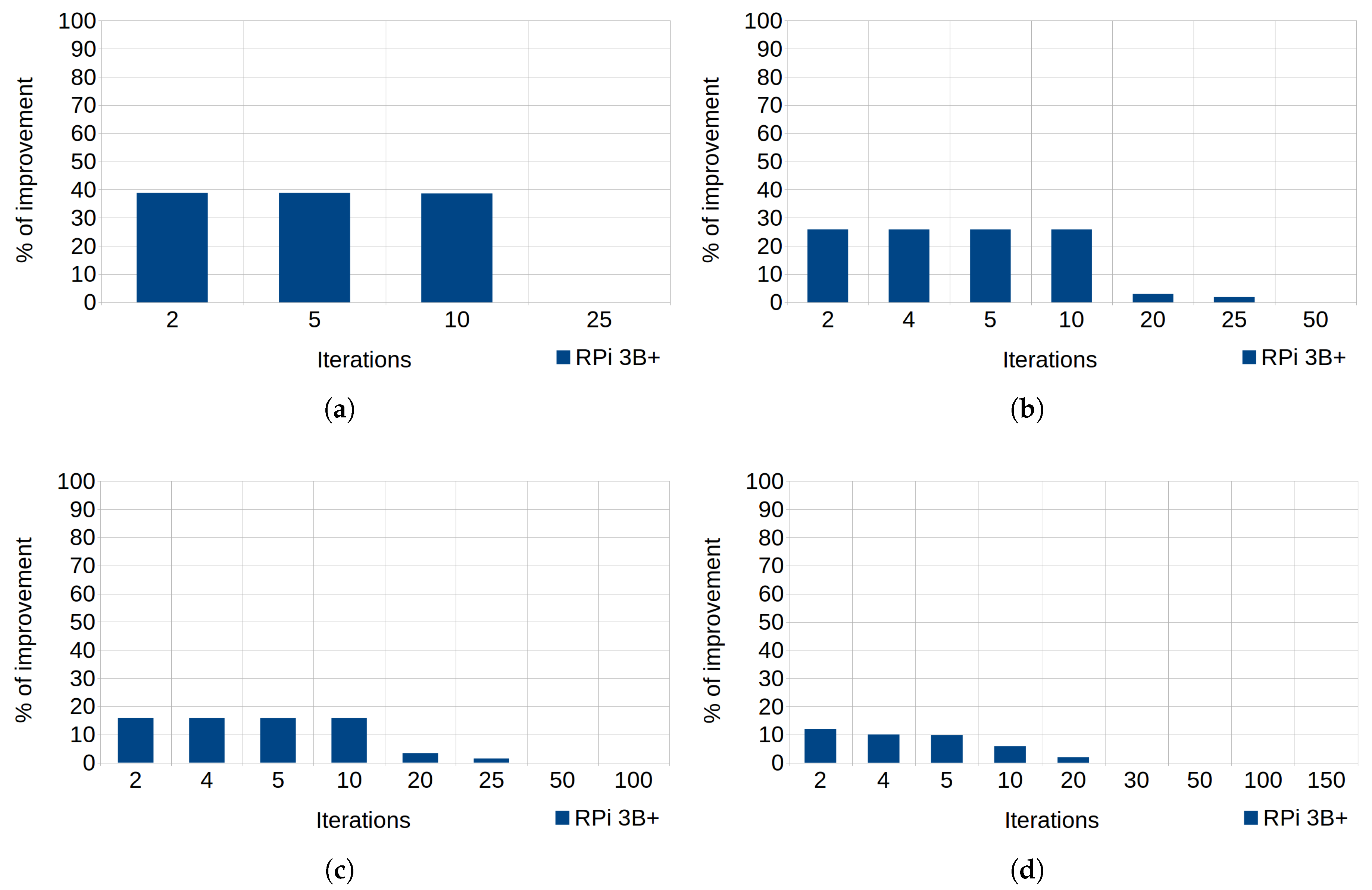
6.3. Exceptions
int num = 100; int num = 100;
for (int i=0; i<1; i++){ for (int i=0; i<1; i++){
try{ if (num != 100) {
if (num == 100) { continue;
throw myex; }
} }
} catch (exception& e){ return 0;
} }
}
return 0;
}
6.4. Initialization versus Assignment
void standard() { void efficient() {
std::complex<double> mycomplex; std::complex<double> mycomplex(3.14);
mycomplex = (3.14); }
}
6.5. Loop Count Down
void standard(){ void efficient() {
for (int i=0; i<N; i++) { int i = N+1;
a[i]=i; while (--i) {
} a[i] = i;
} }
}
6.6. Loop Unrolling
void standard(){ void efficient(){
int i; int i;
for (i=0; i<N; i++){ for (i=0; i<N; i+=5){
array[i] = 0; array[i] = 0;
} array[i+1] = 0;
} array[i+2] = 0;
array[i+3] = 0;
array[i+4] = 0;
}
}
6.7. Passing Structures by Reference Instead of Value
typedefstruct {int array[10]; int index;} Structure;
class Class {
private:
string attribute_a ;
string attribute_b;
Structure structure;
public:
Class(string attribute1, string attribute2, int i);
int getIndex();
};
Class::Class(string attribute1, string attribute2, int i) {
attribute_a = attribute1;
attribute_b = attribute2;
structure.index = i;
}
int Class::getIndex() {
return structure.index;
}
int standard(Class value){ int efficient(Class *reference){
return value.getIndex(); return reference->getIndex();
} }
6.8. Linear Search
int standard(int *list, int N, int search){ int efficient(int *list, int N, int search){
int i; int i;
for (i = 0; i < N; i++) list[N] = search;
if (list[i] == search) i = 0;
return i; while (list[i] != search)
return -1; i++;
} if (i == N)
return -1;
}
7. Limitations and Future Work
8. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Al-Fuqaha, A.; Guizani, M.; Mohammadi, M.; Aledhari, M.; Ayyash, M. Internet of Things: A Survey on Enabling Technologies, Protocols, and Applications. IEEE Commun. Surv. Tutor. 2015, 17, 2347–2376. [Google Scholar] [CrossRef]
- Hammoudi, S.; Aliouat, Z.; Harous, S. Challenges and research directions for Internet of Things. Telecommun. Syst. 2018, 67, 367–385. [Google Scholar] [CrossRef]
- Raspberry Pi Foundation. 2018. Available online: https://www.raspberrypi.org (accessed on 13 October 2018).
- Abbas, N.; Yu, F.; Fan, Y. Intelligent Video Surveillance Platform for Wireless Multimedia Sensor Networks. Appl. Sci. 2018, 8, 348. [Google Scholar] [CrossRef]
- Noriega-Linares, J.E.; Navarro Ruiz, J.M. On the Application of the Raspberry Pi as an Advanced Acoustic Sensor Network for Noise Monitoring. Electronics 2016, 5, 74. [Google Scholar] [CrossRef]
- Leccese, F.; Cagnetti, M.; Trinca, D. A Smart City Application: A Fully Controlled Street Lighting Isle Based on Raspberry-Pi Card, a ZigBee Sensor Network and WiMAX. Sensors 2014, 14, 24408–24424. [Google Scholar] [CrossRef] [PubMed]
- García Guzmán, J.; Prieto González, L.; Pajares Redondo, J.; Montalvo Martínez, L.; Boada, M.J. Real-Time Vehicle Roll Angle Estimation Based on Neural Networks in IoT Low-Cost Devices. Sensors 2018, 18, 2188. [Google Scholar] [CrossRef] [PubMed]
- Bayo-Monton, J.L.; Martinez-Millana, A.; Han, W.; Fernandez-Llatas, C.; Sun, Y.; Traver, V. Wearable Sensors Integrated with Internet of Things for Advancing eHealth Care. Sensors 2018, 18, 1851. [Google Scholar] [CrossRef] [PubMed]
- Hajji, W.; Tso, F.P. Understanding the Performance of Low Power Raspberry Pi Cloud for Big Data. Electronics 2016, 5, 29. [Google Scholar] [CrossRef]
- Valle, B.; Simonneau, T.; Boulord, R.; Sourd, F.; Frisson, T.; Ryckewaert, M.; Hamard, P.; Brichet, N.; Dauzat, M.; Christophe, A. PYM: A new, affordable, image-based method using a Raspberry Pi to phenotype plant leaf area in a wide diversity of environments. Plant Methods 2017, 13, 98. [Google Scholar] [CrossRef] [PubMed]
- Kölling, M. Educational Programming on the Raspberry Pi. Electronics 2016, 5, 33. [Google Scholar] [CrossRef]
- Abrahamsson, P.; Helmer, S.; Phaphoom, N.; Nicolodi, L.; Preda, N.; Miori, L.; Angriman, M.; Rikkila, J.; Wang, X.; Hamily, K.; et al. Affordable and energy-efficient cloud computing clusters: The bolzano raspberry pi cloud cluster experiment. In Proceedings of the 2013 IEEE 5th International Conference on Cloud Computing Technology and Science (CloudCom), Bristol, UK, 2–5 December 2013; Volume 2, pp. 170–175. [Google Scholar]
- GCC, the GNU Compiler Collection. 2018. Available online: https://gcc.gnu.org (accessed on 13 October 2018).
- Dawson-Haggerty, S.; Krioukov, A.; Culler, D.E. Power Optimization-a Reality Check; Tech. Rep. UCB/EECS-2009-140; EECS Department, University of California: Berkeley, CA, USA, 2009. [Google Scholar]
- Pereira, R.; Couto, M.; Ribeiro, F.; Rua, R.; Cunha, J.; Fernandes, J.A.P.; Saraiva, J.A. Energy Efficiency Across Programming Languages: How Do Energy, Time, and Memory Relate? In Proceedings of the 10th ACM SIGPLAN International Conference on Software Language Engineering (SLE 2017), Vancouver, BC, Canada, 23–24 October 2017; ACM: New York, NY, USA, 2017; pp. 256–267. [Google Scholar] [CrossRef]
- Abdulsalam, S.; Lakomski, D.; Gu, Q.; Jin, T.; Zong, Z. Program energy efficiency: The impact of language, compiler and implementation choices. In Proceedings of the International Green Computing Conference, Dallas, TX, USA, 3–5 November 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Shore, C. Efficient C Code for ARM Devices. In Proceedings of the ARM Technology Conference, Santa Clara, CA, USA, 10 November 2010; pp. 1–14. [Google Scholar]
- Corral-García, J.; González-Sánchez, J.L.; Pérez-Toledano, M.A. Towards automatic parallelization of sequential programs and efficient use of resources in HPC centers. In Proceedings of the 2016 International Conference on High Performance Computing Simulation (HPCS), Innsbruck, Austria, 18–22 July 2016; pp. 947–954. [Google Scholar] [CrossRef]
- Fog, A. Optimizing Software in C++—An Optimization Guide for Windows, Linux and Mac Platforms; Copenhagen University College of Engineering: Ballerup, Denmark, 2018. [Google Scholar]
- Sloss, A.; Symes, D.; Wright, C. ARM System Developer’s Guide: Designing and Optimizing System Software; Elsevier: Amsterdam, The Netherlands, 2004. [Google Scholar]
- Goldthwaite, L. Technical Report on C++ Performance; ISO/IEC PDTR 18015; International Organization for Standardization: Geneva, Switzerland, 2006. [Google Scholar]
- Guntheroth, K. Optimized C++: Proven Techniques for Heightened Performance; O’Reilly Media, Inc.: Newton, MA, USA, 2016. [Google Scholar]
- Malviya, N.; Khunteta, A. Code Optimization using Code Purifier. Int. J. Comput. Sci. Inf. Technol. (IJCSIT) 2015, 6, 4753–4757. [Google Scholar]
- Gupta, N.; Seth, N.; Verma, P. Optimal Code Compiling in C. Int. J. Comput. Sci. Inf. Technol. (IJCSIT) 2015, 6, 2050–2057. [Google Scholar]
- Cooper, K.D.; Mckinley, K.S.; Torczon, L. Compiler-Based Code-Improvement Techniques. 1998. Available online: https://www.clear.rice.edu/comp512/Lectures/Papers/survey.pdf (accessed on 13 October2018).
- Lee, M.E. Optimization of Computer Programs in C. 2018. Available online: http://leto.net/docs/C-optimization.php (accessed on 13 October 2018).
- Ghosh, K. Writing Efficient C and C Code Optimization. 2018. Available online: https://www.codeproject.com/Articles/6154/Writing-Efficient-C-and-C-Code-Optimization (accessed on 13 October 2018).
- Isensee, P. C++ Optimization Strategies and Techniques. 2018. Available online: http://www.tantalon.com/pete/cppopt/main.htm (accessed on 13 October 2018).
- Kim, D.; Hong, J.E.; Yoon, I.; Lee, S.H. Code refactoring techniques for reducing energy consumption in embedded computing environment. Clust. Comput. 2016. [Google Scholar] [CrossRef]
- Park, J.J.; Hong, J.E.; Lee, S.H. Investigation for Software Power Consumption of Code Refactoring Techniques. In Proceedings of the Twenty-Sixth International Conference on Software Engineering and Knowledge Engineering (SEKE 2014), Vancouver, BC, Canada, 1–3 July 2014; pp. 717–722. [Google Scholar]
- Gottschalk, M.; Jelschen, J.; Winter, A. Energy-efficient code by refactoring. Softwaretechnik-Trends 2013, 33, 2. [Google Scholar] [CrossRef]
- Bekaroo, G.; Santokhee, A. Power consumption of the Raspberry Pi: A comparative analysis. In Proceedings of the IEEE International Conference on Emerging Technologies and Innovative Business Practices for the Transformation of Societies (EmergiTech), Balaclava, Mauritius, 3–6 August 2016; pp. 361–366. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | RPi 2 B | RPi 3 B | RPi 3 B+ |
|---|---|---|---|
| SOC Type | Broadcom BCM2836 | Broadcom BCM2837 | Broadcom BCM2837B0 |
| CPU Clock | 900 MHz Quad Core ARM Cortex-A7 | 1.2 GHz Quad Core ARM Cortex-A53 | 1.4 GHz Quad Core ARM Cortex-A53 |
| RAM | 1 GB | 1 GB | 1 GB |
| GPU | Broadcom VideoCore IV 1080p30 | Broadcom VideoCore IV 1080p60 | Broadcom VideoCore IV 1080p60 |
| USB Ports | 4 | 4 | 4 |
| Ethernet | 100 Mbit/s base Ethernet | 100 Mbit/s base Ethernet | Gigabit Ethernet over USB 2.0 (maximum throughput 300 Mbps) |
| Power over Ethernet | No | No | Yes (requires separate PoE HAT) |
| WiFi | No | On Board WiFi 802.11n | On Board WiFi 802.11ac Dual Band 2.4 GHz & 5 GHz |
| Bluetooth | No | On Board Bluetooth 2.0/4.1 | On Board Bluetooth 2.0/4.1/4.2 LS BLE |
| Video Output | HDMI 3.5 mm Composite DSI (for LCD) | HDMI 3.5 mm Composite DSI (for LCD) | HDMI 3.5 mm Composite DSI (for LCD) |
| Audio Output | I S HDMI 3.5 mm Composite | I S HDMI 3.5 mm Composite | I S HDMI 3.5mm Composite |
| Camera Input | 15 Pin CSI | 15 Pin CSI | 15 Pin CSI |
| GPIO Pins | 40 | 40 | 40 |
| Memory | MicroSD | MicroSD | MicroSD |
| Technique | Runtime (without Optimization) | Runtime (Optimization Level 3) | |||||
|---|---|---|---|---|---|---|---|
| Standard (ns) | Efficient (ns) | Improvement (%) | Standard (ns) | Efficient (ns) | Improvement (%) | ||
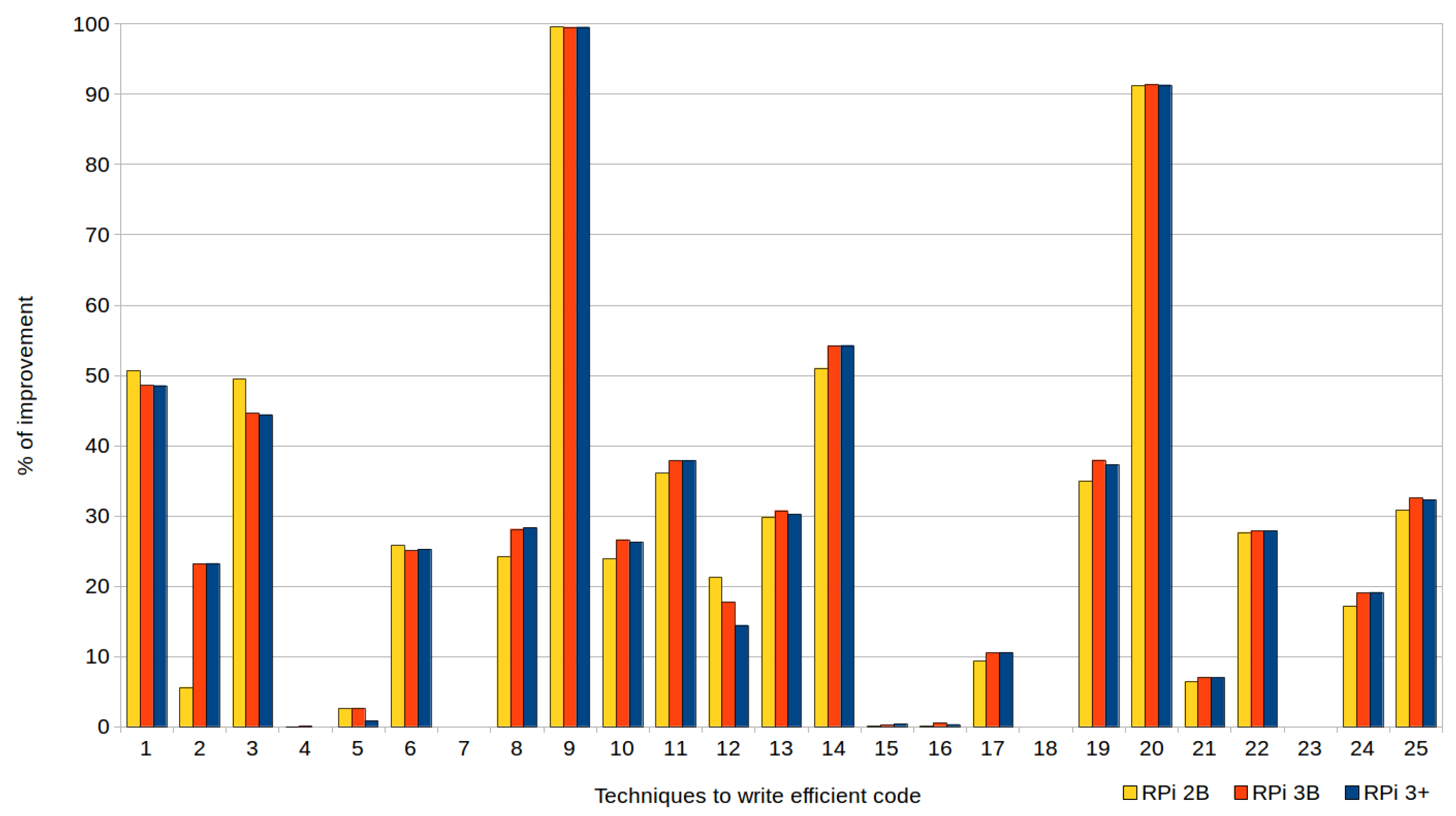
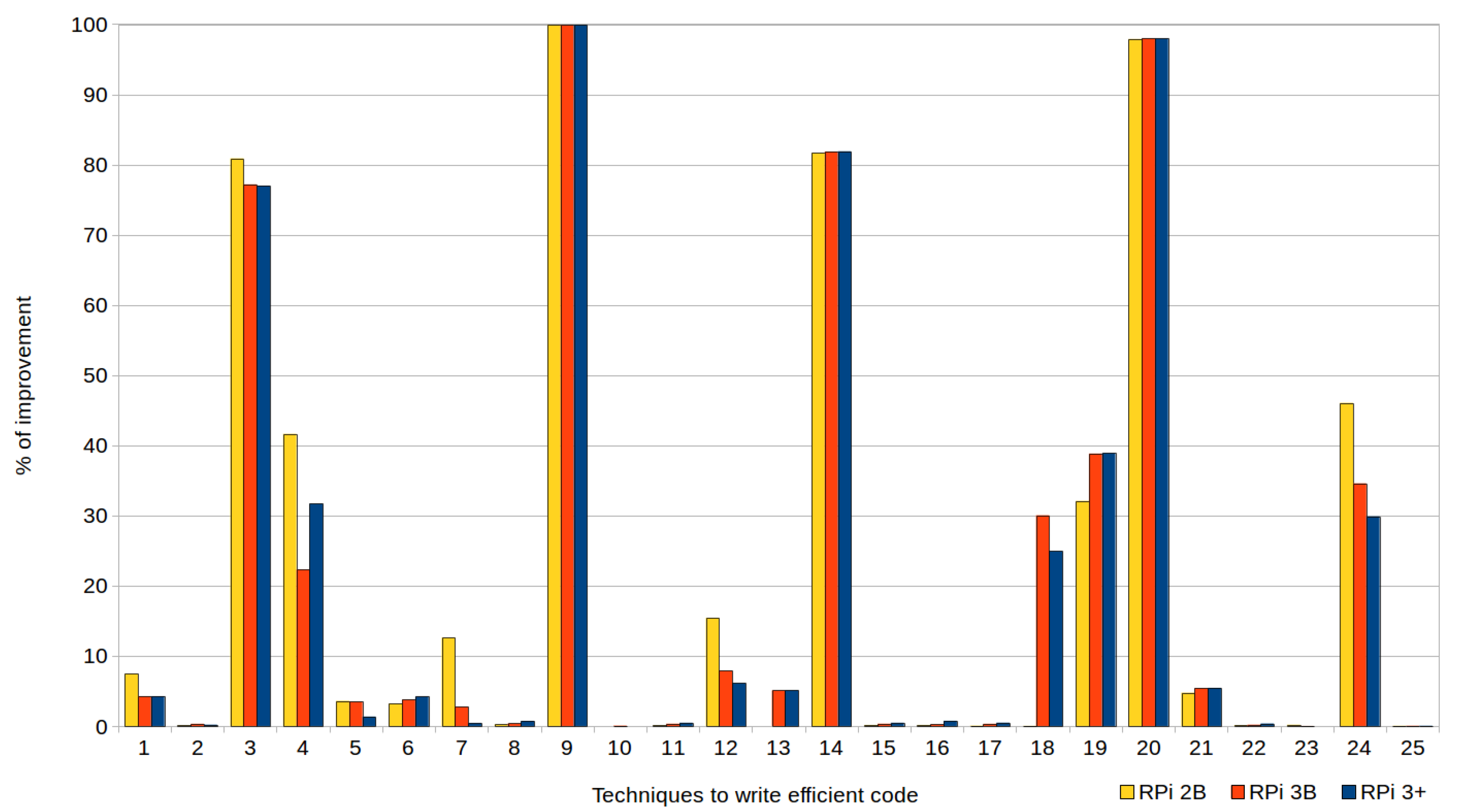
| 1 | Bit fields | 85.71 | 42.28 | 50.67 | 31.25 | 28.92 | 7.46 |
| 2 | Boolean return | 40.63 | 38.35 | 5.61 | 20.32 | 20.30 | 0.10 |
| 3 | Cascaded function calls | 828.28 | 418.60 | 49.46 | 514.83 | 98.46 | 80.88 |
| 4 | Row-major accessing | 94,096.73 | 94,096.72 | 0.00 | 12,850.10 | 7502.61 | 41.61 |
| 5 | Constructor initialization lists | 1158.58 | 1128.70 | 2.58 | 1148.76 | 1107.63 | 3.58 |
| 6 | Common subexpression elimination | 74.50 | 55.29 | 25.79 | 36.13 | 34.97 | 3.21 |
| 7 | Mapping structures | 522.61 | 812.45 | −55.46 | 505.80 | 442.10 | 12.59 |
| 8 | Dead code elimination | 32.47 | 24.61 | 24.21 | 16.82 | 16.78 | 0.24 |
| 9 | Exception handling | 9465.32 | 42.51 | 99.55 | 9406.65 | 10.06 | 99.89 |
| 10 | Global variables within loops | 558.62 | 425.40 | 23.85 | 87.27 | 87.29 | −0.02 |
| 11 | Function inlining | 55.66 | 35.60 | 36.04 | 20.15 | 20.13 | 0.10 |
| 12 | Global variables | 1538.84 | 1211.68 | 21.26 | 697.21 | 589.75 | 15.41 |
| 13 | Constants inside loops | 504.34 | 353.86 | 29.84 | 224.77 | 228.08 | −1.47 |
| 14 | Initialization versus assignment | 57.09 | 27.96 | 51.02 | 54.55 | 10.01 | 81.65 |
| 15 | Division by a power-of-two denominator | 35.83 | 35.79 | 0.11 | 20.16 | 20.13 | 0.15 |
| 16 | Multiplication by a power-of-two factor | 35.63 | 35.60 | 0.08 | 20.05 | 20.02 | 0.15 |
| 17 | Integer versus character | 60.45 | 54.82 | 9.31 | 20.14 | 20.13 | 0.05 |
| 18 | Loop count down | 1483.21 | 1824.74 | −23.03 | 360.35 | 360.29 | 0.02 |
| 19 | Loop unrolling | 770.95 | 501.29 | 34.98 | 115.28 | 78.31 | 32.07 |
| 20 | Passing structures by reference | 509.51 | 44.75 | 91.22 | 474.79 | 10.06 | 97.88 |
| 21 | Pointer aliasing | 121.96 | 114.11 | 6.44 | 71.63 | 68.24 | 4.73 |
| 22 | Chains of pointers | 84.58 | 61.19 | 27.65 | 24.64 | 24.61 | 0.12 |
| 23 | Pre-increment versus post-increment | 2706.01 | 2707.06 | −0.04 | 692.16 | 690.97 | 0.17 |
| 24 | Linear search | 2487.52 | 2060.83 | 17.15 | 700.99 | 378.30 | 46.03 |
| 25 | Invariant IF statements within loops | 2161.82 | 1496.00 | 30.80 | 156.92 | 156.88 | 0.03 |
| Technique | Runtime (without Optimization) | Runtime (Optimization Level 3) | |||||
|---|---|---|---|---|---|---|---|
| Standard (ns) | Efficient (ns) | Improvement (%) | Standard (ns) | Efficient (ns) | Improvement (%) | ||
| 1 | Bit fields | 55.09 | 28.35 | 48.54 | 21.05 | 20.16 | 4.23 |
| 2 | Boolean return | 32.84 | 25.23 | 23.17 | 12.65 | 12.61 | 0.32 |
| 3 | Cascaded function calls | 532.65 | 295.25 | 44.57 | 309.11 | 70.57 | 77.17 |
| 4 | Row-major accessing | 61,209.77 | 61,139.89 | 0.11 | 6796.87 | 5282.00 | 22.29 |
| 5 | Constructor initialization lists | 766.16 | 746.05 | 2.62 | 757.83 | 731.68 | 3.45 |
| 6 | Common subexpression elimination | 50.05 | 37.52 | 25.03 | 26.20 | 25.22 | 3.74 |
| 7 | Mapping structures | 399.75 | 524.69 | −31.25 | 381.80 | 371.36 | 2.73 |
| 8 | Dead code elimination | 21.03 | 15.12 | 28.10 | 10.96 | 10.92 | 0.36 |
| 9 | Exception handling | 5465.30 | 26.68 | 99.51 | 5460.63 | 6.67 | 99.88 |
| 10 | Global variables within loops | 382.89 | 281.08 | 26.59 | 74.11 | 74.07 | 0.05 |
| 11 | Function inlining | 37.88 | 23.54 | 37.86 | 12.54 | 12.50 | 0.32 |
| 12 | Global variables | 910.18 | 749.08 | 17.70 | 521.35 | 480.29 | 7.88 |
| 13 | Constants inside loops | 340.73 | 236.00 | 30.74 | 144.84 | 137.48 | 5.08 |
| 14 | Initialization versus assignment | 40.35 | 18.48 | 54.20 | 37.03 | 6.72 | 81.85 |
| 15 | Division by a power-of-two denominator | 23.41 | 23.35 | 0.26 | 12.55 | 12.51 | 0.32 |
| 16 | Multiplication by a power-of-two factor | 23.47 | 23.35 | 0.51 | 12.64 | 12.61 | 0.24 |
| 17 | Integer versus character | 40.07 | 35.86 | 10.51 | 12.64 | 12.60 | 0.32 |
| 18 | Loop count down | 1027.85 | 1292.02 | −25.70 | 269.68 | 188.72 | 30.02 |
| 19 | Loop unrolling | 532.41 | 330.48 | 37.93 | 93.45 | 57.18 | 38.81 |
| 20 | Passing structures by reference | 348.64 | 30.02 | 91.39 | 332.00 | 6.72 | 97.98 |
| 21 | Pointer aliasing | 84.31 | 78.39 | 7.02 | 48.47 | 45.86 | 5.38 |
| 22 | Chains of pointers | 60.54 | 43.69 | 27.83 | 16.82 | 16.79 | 0.18 |
| 23 | Pre-increment versus post-increment | 1867.60 | 1868.37 | −0.04 | 519.81 | 519.78 | 0.01 |
| 24 | Linear search | 1690.00 | 1368.81 | 19.01 | 435.44 | 284.90 | 34.57 |
| 25 | Invariant IF statements within loops | 1538.42 | 1038.22 | 32.51 | 123.54 | 123.50 | 0.03 |
| Technique | Runtime (without Optimization) | Runtime (Optimization Level 3) | |||||
|---|---|---|---|---|---|---|---|
| Standard (ns) | Efficient (ns) | Improvement (%) | Standard (ns) | Efficient (ns) | Improvement (%) | ||
| 1 | Bit fields | 47.92 | 24.67 | 48.52 | 18.18 | 17.41 | 4.24 |
| 2 | Boolean return | 28.35 | 21.77 | 23.21 | 10.90 | 10.88 | 0.18 |
| 3 | Cascaded function calls | 460.35 | 256.04 | 44.38 | 267.48 | 61.58 | 76.98 |
| 4 | Row-major accessing | 53,434.46 | 53,584.19 | −0.28 | 6764.78 | 4622.89 | 31.66 |
| 5 | Constructor initialization lists | 673.66 | 667.99 | 0.84 | 662.28 | 653.39 | 1.34 |
| 6 | Common subexpression elimination | 43.01 | 32.16 | 25.23 | 22.46 | 21.52 | 4.19 |
| 7 | Mapping structures | 338.54 | 460.12 | −35.91 | 324.79 | 323.35 | 0.44 |
| 8 | Dead code elimination | 17.94 | 12.86 | 28.32 | 9.50 | 9.43 | 0.74 |
| 9 | Exception handling | 4988.09 | 23.59 | 99.53 | 5056.53 | 6.03 | 99.88 |
| 10 | Global variables within loops | 330.50 | 243.72 | 26.26 | 63.54 | 63.81 | −0.42 |
| 11 | Function inlining | 32.21 | 20.01 | 37.88 | 10.93 | 10.88 | 0.46 |
| 12 | Global variables | 793.95 | 679.45 | 14.42 | 464.86 | 436.42 | 6.12 |
| 13 | Constants inside loops | 289.83 | 202.27 | 30.21 | 126.07 | 119.64 | 5.10 |
| 14 | Initialization versus assignment | 34.35 | 15.72 | 54.24 | 31.52 | 5.71 | 81.88 |
| 15 | Division by a power-of-two denominator | 20.08 | 20.01 | 0.35 | 10.93 | 10.88 | 0.46 |
| 16 | Multiplication by a power-of-two factor | 20.07 | 20.01 | 0.30 | 10.80 | 10.72 | 0.74 |
| 17 | Integer versus character | 34.88 | 31.20 | 10.55 | 10.77 | 10.72 | 0.46 |
| 18 | Loop count down | 889.60 | 1103.27 | −24.02 | 240.11 | 180.32 | 24.90 |
| 19 | Loop unrolling | 456.63 | 286.43 | 37.27 | 79.51 | 48.60 | 38.88 |
| 20 | Passing structures by reference | 301.95 | 26.29 | 91.29 | 285.03 | 5.85 | 97.95 |
| 21 | Pointer aliasing | 72.21 | 67.18 | 6.97 | 41.57 | 39.31 | 5.44 |
| 22 | Chains of pointers | 51.51 | 37.16 | 27.86 | 14.34 | 14.29 | 0.35 |
| 23 | Pre-increment versus post-increment | 1611.73 | 1652.95 | −2.56 | 469.88 | 486.87 | −3.62 |
| 24 | Linear search | 1455.65 | 1177.63 | 19.10 | 386.03 | 270.78 | 29.86 |
| 25 | Invariant IF statements within loops | 1321.56 | 895.18 | 32.26 | 105.90 | 105.86 | 0.04 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Corral-García, J.; González-Sánchez, J.-L.; Pérez-Toledano, M.-Á. Evaluation of Strategies for the Development of Efficient Code for Raspberry Pi Devices. Sensors 2018, 18, 4066. https://doi.org/10.3390/s18114066
Corral-García J, González-Sánchez J-L, Pérez-Toledano M-Á. Evaluation of Strategies for the Development of Efficient Code for Raspberry Pi Devices. Sensors. 2018; 18(11):4066. https://doi.org/10.3390/s18114066
Chicago/Turabian StyleCorral-García, Javier, José-Luis González-Sánchez, and Miguel-Ángel Pérez-Toledano. 2018. "Evaluation of Strategies for the Development of Efficient Code for Raspberry Pi Devices" Sensors 18, no. 11: 4066. https://doi.org/10.3390/s18114066
APA StyleCorral-García, J., González-Sánchez, J. -L., & Pérez-Toledano, M. -Á. (2018). Evaluation of Strategies for the Development of Efficient Code for Raspberry Pi Devices. Sensors, 18(11), 4066. https://doi.org/10.3390/s18114066