Robust Drivable Road Region Detection for Fixed-Route Autonomous Vehicles Using Map-Fusion Images

Abstract
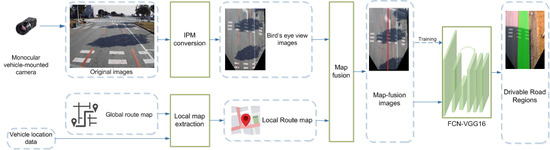
:
1. Introduction
2. Related Works
3. Problem Formulation
- S—the set of all pixels in the image ,
- —the set of pixels in the background area (or non-road area)
- —the set of pixels in the road region
- —the set of pixels in the drivable road region
- —the set of pixels in the non-drivable road region.
4. Drivable Road Region Detection
4.1. Inverse Perspective Mapping
4.2. Map-Fusion Image Generation
4.2.1. Map-Fusion Image Generation
4.2.2. Local Map Extraction
4.2.3. Map-Image Fusion
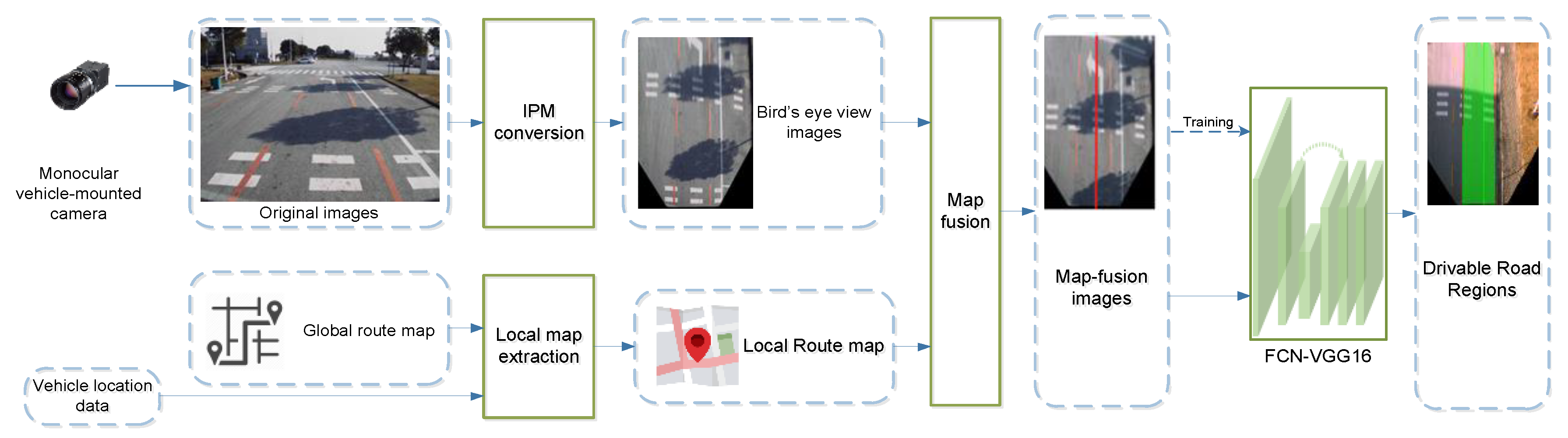
4.3. FCN-VGG16 for Drivable Road Region Detection
4.3.1. Neural Network Model
4.3.2. Selection of Loss Function
5. Experimental Study
5.1. Experiment Platform
5.2. Evaluation Metric
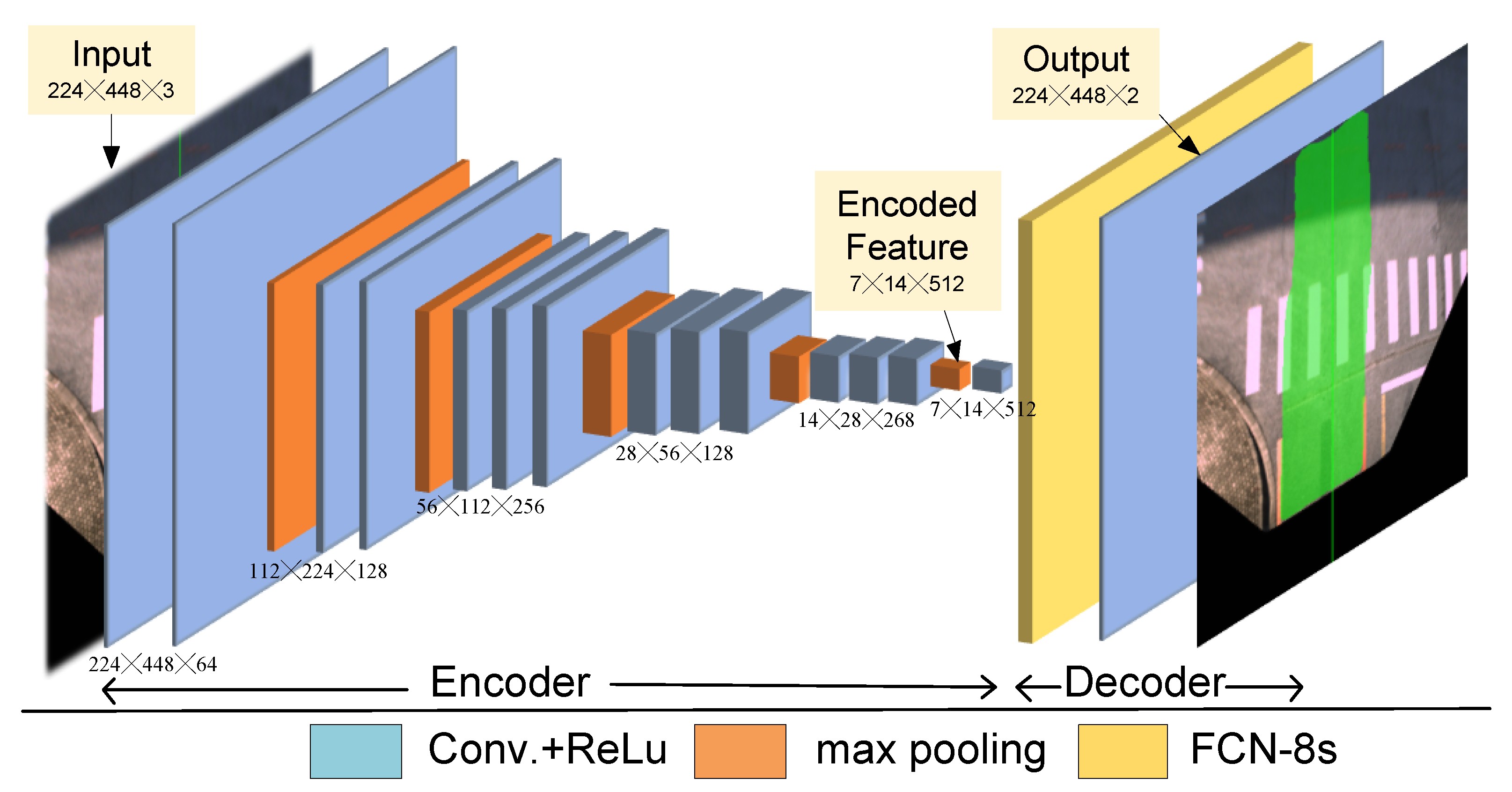
5.3. Evaluation of Detection Accuracy
5.4. Evaluation of Robustness
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yenikaya, S.; Yenikaya, G.; Düven, E. Keeping the vehicle on the road: A survey on on-road lane detection systems. ACM Comput. Surv. 2013. [Google Scholar] [CrossRef]
- Liu, X.; Deng, Z.; Yang, G. Drivable road detection based on dilated FPN with feature aggregation with feature aggregation. In Proceedings of the IEEE 29th International Conference on Tools with Artificial Intelligence (ICTAI), Boston, MA, USA, 6–8 November 2017; pp. 1128–1134. [Google Scholar]
- Gu, S.; Lu, T.; Zhang, Y.; Alvarez, J.M.; Yang, J.; Kong, H. 3D LiDAR + monocular camera: An inverse-depth induced fusion framework for urban road detection. IEEE Trans. Intell. Veh. 2018, 3, 351–360. [Google Scholar] [CrossRef]
- Shin, B.-S.; Tao, J.; Klette, R. A Superparticle Filter for Lane Detection. Pattern Recognit. 2015, 48, 3333–3345. [Google Scholar] [CrossRef]
- Wang, Y.; Dahnoun, N.; Achim, A. A novel system for robust lane detection and tracking. Signal Process. 2011, 92, 319–334. [Google Scholar] [CrossRef]
- Borkar, A.; Hayes, M.; Smith, M.T. Polar randomized Hough transform for lane detection using loose constraints of parallel lines. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Repulic, 22–27 May 2011; pp. 1037–1040. [Google Scholar]
- Yi, S.-C.; Chen, Y.-C.; Chang, C.-H. A lane detection approach based on intelligent vision. Comput. Electr. Eng. 2015, 42, 23–29. [Google Scholar] [CrossRef]
- Lim, K.H.; Seng, K.P.; Ang, L.-M. River flow lane detection and Kalman filtering-based B-spline lane tracking. Int. J. Veh. Technol. 2012. [Google Scholar] [CrossRef]
- John, N.; Anusha, B.; Kutty, K. A reliable method for detecting road regions from a single image based on color distribution and vanishing point location. Procedia Comput. Sci. 2015, 58, 2–9. [Google Scholar] [CrossRef]
- Zhou, S.; Jiang, Y.; Xi, J.; Gong, J.; Xiong, G.; Chen, H. A novel lane detection based on geometrical model and Gabor filter. In Proceedings of the IEEE Intelligent Vehicles Symposium, San Diego, CA, USA, 21–24 June 2010; pp. 59–64. [Google Scholar]
- Kong, H.; Audibert, J.-Y.; Ponce, J. General road detection from a single image. IEEE Trans. Image Process. 2010, 19, 2211–2220. [Google Scholar] [CrossRef] [PubMed]
- Shang, E.; An, X.; Li, J.; Ye, L.; He, H. Robust unstructured road detection: The importance of contextual information. Int. J. Adv. Rob. Syst. 2013, 10, 1–7. [Google Scholar] [CrossRef]
- Li, Z.-Q.; Ma, H.-M.; Liu, Z.-Y. Road lane detection with Gabor filters. In Proceedings of the International Conference on Information System and Artificial Intelligence (ISAI), Hong Kong, China, 24–26 June 2016; pp. 436–440. [Google Scholar]
- Janda, F.; Pangerl, S.; Schindler, A. A road edge detection approach for marked and unmarked lanes based on video and Radar. In Proceedings of the 16th International Conference on Information Fusion, Istanbul, Turkey, 9–12 July 2013; pp. 871–876. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv, 2016; arXiv:1704.06857. [Google Scholar]
- Zhang, W.-Z.; Wang, Z.-C. Rural road detection of color image in complicated environment. Int. J. Signal Process. Image Process. Pattern Recognit. 2013, 6, 161–168. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Oberweger, M.; Wohlhart, P.; Lepetit, V. Hands deep in deep learning for hand pose estimation. In Proceedings of the 20th Computer Vision Winter Workshop (CVWW), Seggau, Austria, 9–11 February 2015; pp. 1–10. [Google Scholar]
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated residual networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 636–644. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. ICNet for real-time semantic segmentation on high-resolution images. arXiv, 2017; arXiv:1704.08545. [Google Scholar]
- Dvornik, N.; Shmelkov, K.; Mairal, J.; Schmid, C. BlitzNet: A Real-Time Deep Network for Scene Understanding. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2380–7504. [Google Scholar]
- Lee, S.; Kim, J.; Yoon, J.S.; Shin, S.; Bailo, O.; Kim, N.; Lee, T.-H.; Hong, H.S.; Han, S.-H.; Kweon, I.S. VPGNet: vanishing point guided network for lane and road marking detection and recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1965–1973. [Google Scholar]
- Brust, C.-A.; Sickert, S.; Simon, M.; Rodner, E.; Joachim, D. Convolutional Patch Networks with Spatial Prior for Road Detection and Urban Scene Understanding. In Proceedings of the 10th International Conference on Computer Vision Theory and Applications (VISAPP), Berlin, Germany, 11–14 March 2015. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Pham, V.-Q.; Ito, S.; Kozakaya, T. BiSeg: Simultaneous Instance Segmentation and Semantic Segmentation with Fully Convolutional Networks. In Proceedings of the British Machine Vision Conference (BMVC), London, UK, 4–7 September 2017. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Teichmann, M.; Weber, M.; Zoellner, M.; Cipolla, R.; Urtasun, R. MultiNet: Real-time Joint Semantic Reasoning for Autonomous Driving. arXiv, 2016; arXiv:1612.07695. [Google Scholar]
- Kowsari, T.; Beauchemin, S.S.; Bauer, M.A. Map-based lane and obstacle-free area detection. In Proceedings of the International Conference on Computer Vision Theory and Applications, Lisbon, Portugal, 5–8 January 2014; pp. 523–530. [Google Scholar]
- Tao, Z.; Bonnifait, P.; Frémont, V.; Ibañez-Guzman, J. Mapping and localization using GPS, lane markings and proprioceptive sensors. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 406–412. [Google Scholar]
- Li, C.; Wang, X.; Liu, W. Neural features for pedestrian detection. Neurocomputing 2017, 238, 420–432. [Google Scholar] [CrossRef]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Li, B.; Hu, S. Traffic-Sign Detection and Classification in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2010–2118. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | |
|---|---|
| Model | Daheng MER-125-30-UC |
| CCD sensor | Sony® ICX445 |
| Resolution | 1292 × 964 |
| Frame rate | 30 fps |
| Lens | Basler 4 mm fixed focus length |
| Approach | PA |
|---|---|
| FCN without MFI | 0.811 |
| MFI and FCN-VGG16 | 0.917 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, Y.; Li, D.; Zhou, X.; Mou, X. Robust Drivable Road Region Detection for Fixed-Route Autonomous Vehicles Using Map-Fusion Images. Sensors 2018, 18, 4158. https://doi.org/10.3390/s18124158
Cai Y, Li D, Zhou X, Mou X. Robust Drivable Road Region Detection for Fixed-Route Autonomous Vehicles Using Map-Fusion Images. Sensors. 2018; 18(12):4158. https://doi.org/10.3390/s18124158
Chicago/Turabian StyleCai, Yichao, Dachuan Li, Xiao Zhou, and Xingang Mou. 2018. "Robust Drivable Road Region Detection for Fixed-Route Autonomous Vehicles Using Map-Fusion Images" Sensors 18, no. 12: 4158. https://doi.org/10.3390/s18124158
APA StyleCai, Y., Li, D., Zhou, X., & Mou, X. (2018). Robust Drivable Road Region Detection for Fixed-Route Autonomous Vehicles Using Map-Fusion Images. Sensors, 18(12), 4158. https://doi.org/10.3390/s18124158