Data-Driven Packet Loss Estimation for Node Healthy Sensing in Decentralized Cluster

Abstract
:1. Introduction
- First, we proposed a model to formulate the problem. Instead of modeling a link state to be reachable or unreachable, we model the link state to be healthy or unhealthy considering about unstable link. With a graph representing nodes and link states, the faulty nodes are found by solving a max clique problem(MCP). Moreover, we discuss the transitivity of the link state. For scenarios where link states have transitivity, we simplified the NP-Complete MCP to a linear complexity problem; For other scenarios, we proposed a square complexity heuristic algorithm which can find a maximal clique.
- Second, we proposed a data driven algorithm that solve the reliability issue in this specific case. Our algorithm uses an evaluation model to evaluate the link state basing on data from application layer. Basing on the evaluation results, the decision model takes care of the leader uniqueness issue and infers the faulty nodes.
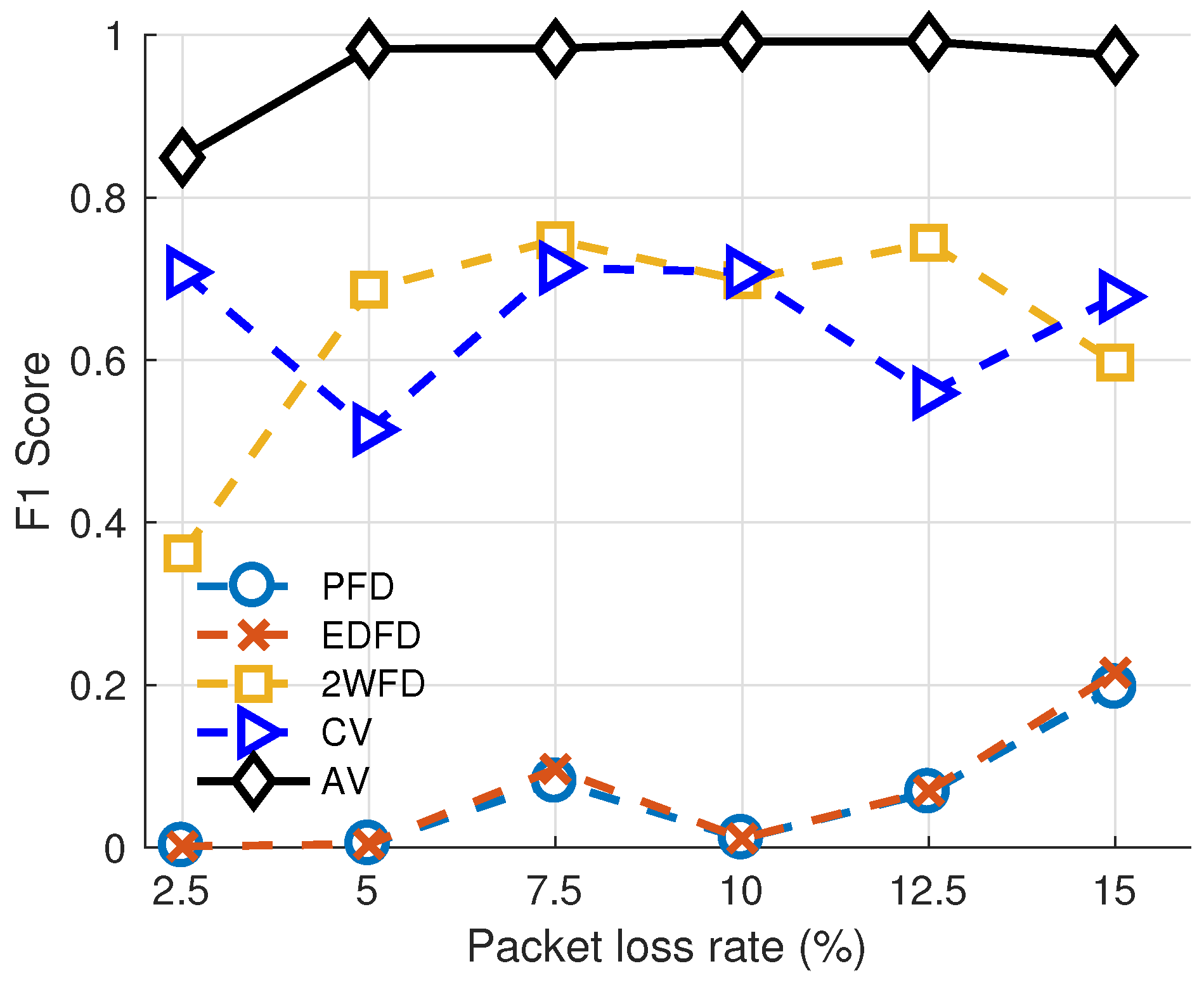
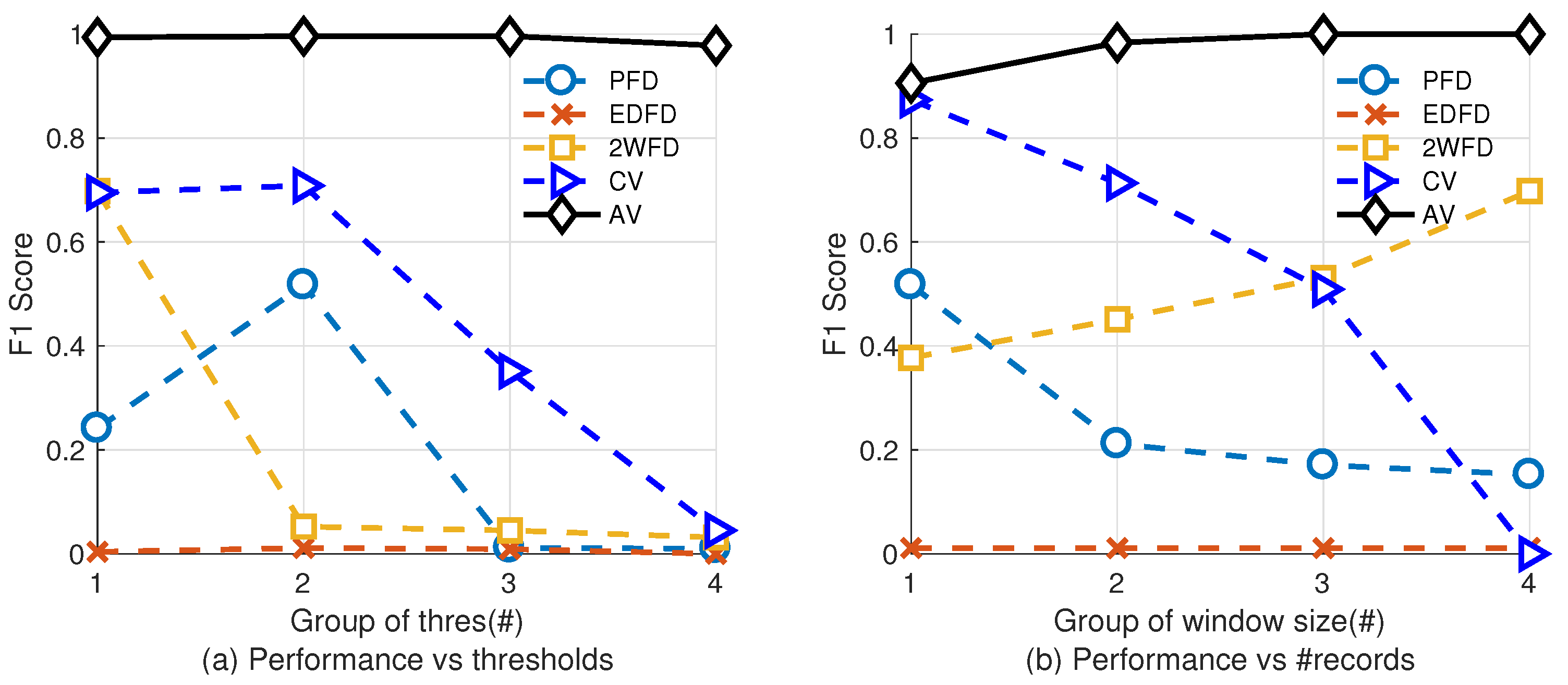
- Finally, extensive simulation results demonstrate that our approach is highly adaptable. Basing on statistical data, the F1 score of the link evaluation method reaches more than 90%. And our implementation makes a real-world product stably run for more than a week while some of the the packet loss failure is injected in some of the nodes.
2. Related Work
2.1. Akka Cluster
2.2. Other Link Failure Detecting Algorithms
2.3. Packet Loss Measurement
2.4. Other Works About Fault-Tolerance
3. System Overview and Problem Formulation
3.1. System Overview
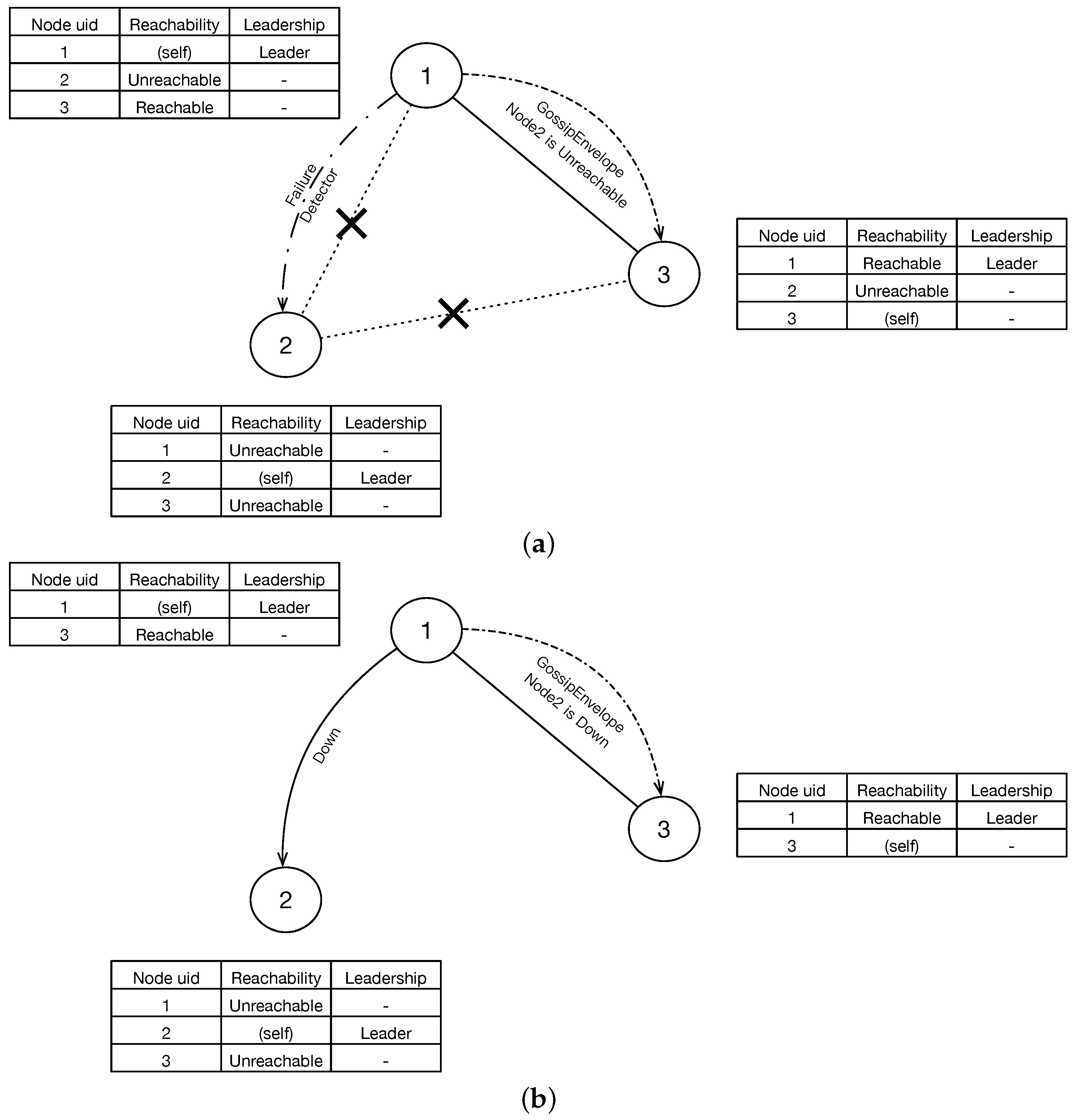
3.1.1. Gossip Based Membership
3.1.2. Failure Detection
3.1.3. Leadership
3.1.4. Downing
3.2. Mathematical Model
3.3. Problem Formulation
- The leader may remove normal nodes that are marked as unreachable by the problematic one if the downing rule is not reliable.
- There may be more than one nodes assume themselves to be leaders if all the normally working nodes with smaller unique id are marked by the problematic node.
4. The PingBasedDown Algorithm
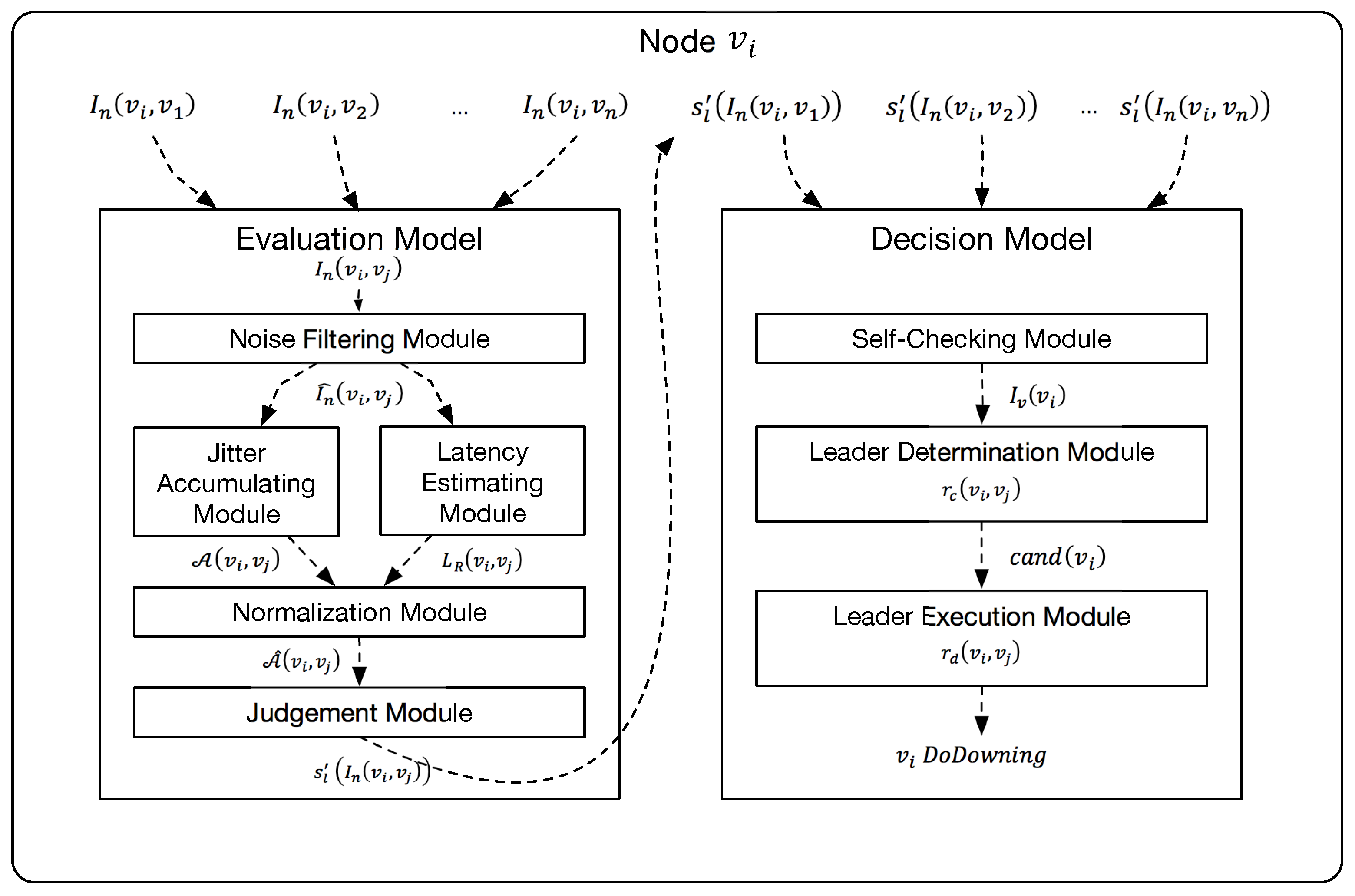
4.1. Link Evaluation Model
4.1.1. Noise Filtering Module
| Algorithm 1: Simple noise filtering algorithm. |
 |
4.1.2. Jitter Accumulating Module
4.1.3. Latency Estimating Module
4.1.4. Normalization Module
4.1.5. Judgement Module
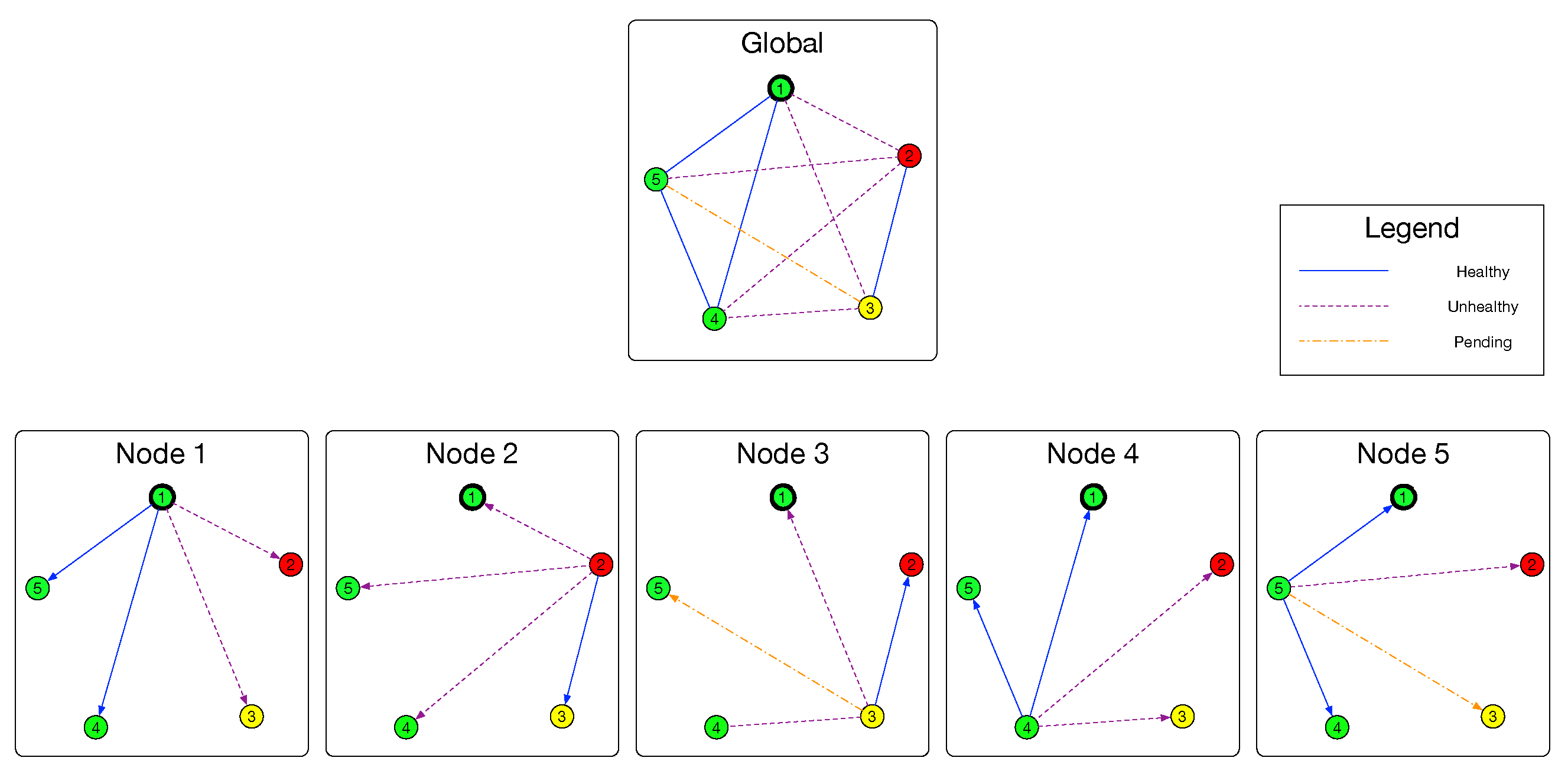
- Healthy, which stands for normally working link without packet loss;
- Unhealthy, it stands for abnormal link with packet losses;
- Pending, which stands for fuzzy link which may need further detection.
4.2. Decision Model
4.2.1. Self-Checking Module
4.2.2. Leader Determination Module
| Algorithm 2: Fetching and combining algorithm. FetchAndCombine(). |
 |
| Algorithm 3: Merging algorithm. Merge(). |
 |
| Algorithm 4: Replying algorithm. |
 |
4.2.3. Leader Execution Module
| Algorithm 5: Finding a maximal clique. |
 |
5. Performance Evaluation
5.1. Simulation Setup
5.1.1. Baseline Methods
5.1.2. Evaluation Metrics
5.1.3. Simulation Scenarios
5.2. Evaluation Results
5.2.1. Adaptability of Environment
5.2.2. Impact of Parameters
6. Conclusions
Author Contributions
Conflicts of Interest
References
- Wikipedia. Computer Cluster—Wikipedia, The Free Encyclopedia. Available online: https://en.wikipedia.org/w/index.php?title=Computer_cluster&oldid=802238893 (accessed on 20 October 2017).
- Kahani, M.; Beadle, H.W.P. Decentralised approaches for network management. ACM SIGCOMM Comput. Commun. Rev. 1997, 27, 36–47. [Google Scholar] [CrossRef]
- Xiong, N.; Yang, Y.; Cao, M.; He, J.; Shu, L. A survey on fault-tolerance in distributed network systems. In Proceedings of the IEEE International Conference on Computational Science and Engineering (CSE’09), Vancouver, BC, Canada, 29–31 August 2009; Volume 2, pp. 1065–1070. [Google Scholar]
- Sari, A.; Akkaya, M. Fault tolerance mechanisms in distributed systems. Int. J. Commun. Netw. Syst. Sci. 2015, 8, 471–482. [Google Scholar] [CrossRef]
- Renesse, R.V.; Minsky, Y.; Hayden, M. A Gossip-Style Failure Detection Service; Springer: London, UK, 1998; pp. 55–70. [Google Scholar]
- Bertier, M.; Marin, O.; Sens, P. Implementation and Performance Evaluation of an Adaptable Failure Detector. In Proceedings of the IEEE International Conference on Dependable Systems and Networks (DSN), Washington, DC, USA, 23–26 June 2002; pp. 354–363. [Google Scholar]
- Chen, W. On the quality of service of failure detectors. IEEE Trans. Comput. 2002, 51, 13–32. [Google Scholar] [CrossRef]
- Hayashibara, N.; Dfago, X.; Yared, R.; Katayama, T. The ϕ Accrual Failure Detector. In Proceedings of the 23rd IEEE International Symposium on Reliable Distributed Systems, Florianpolis, Brazil, 18–20 October 2004; pp. 66–78. [Google Scholar]
- Xiong, N.; Vasilakos, A.; Yang, Y.; Wei, S.; Qiao, C.; Wu, J. General Traffic-Feature Analysis for an Effective Failure Detector in Fault-Tolerant Wired and Wireless Networks; Technical Report; Georgia State University: USA, 2011. [Google Scholar]
- Tomsic, A.; Sens, P.; Garcia, J.; Arantes, L.; Sopena, J. 2W-FD: A failure detector algorithm with QoS. In Proceedings of the Parallel and Distributed Processing Symposium, Hyderabad, India, 25–29 May 2015; pp. 885–893. [Google Scholar]
- Liu, J.; Wu, Z.; Wu, J.; Dong, J.; Zhao, Y.; Wen, D. A Weibull distribution accrual failure detector for cloud computing. PLoS ONE 2017, 12, e0173666. [Google Scholar] [CrossRef] [PubMed]
- Turchetti, R.C.; Duarte, E.P.; Arantes, L.; Sens, P. A QoS-configurable failure detection service for internet applications. J. Internet Serv. Appl. 2016, 7, 9. [Google Scholar] [CrossRef]
- Ganesh, A.J.; Kermarrec, A.M.; Massoulie, L. Peer-to-peer membership management for gossip-based protocols. IEEE Trans. Comput. 2003, 52, 139–149. [Google Scholar] [CrossRef]
- Akka. Akka Introduction. Available online: https://doc.akka.io/docs/akka/current/scala/guide/introduction.html (accessed on 20 October 2017).
- Sommers, J.; Barford, P.; Duffield, N.; Ron, A. A geometric approach to improving active packet loss measurement. IEEE/ACM Trans. Netw. 2008, 16, 307–320. [Google Scholar] [CrossRef]
- Wu, H.; Gong, J. Packet Loss Estimation of TCP Flows Based on the Delayed ACK Mechanism; Springer: Berlin/Heidelberg, Germany, 2009; pp. 540–543. [Google Scholar]
- Basso, S.; Meo, M.; Martin, J.C.D. Strengthening measurements from the edges: Application-level packet loss rate estimation. ACM 2013, 43, 45–51. [Google Scholar] [CrossRef]
- Sun, X.; Coyle, E.J. Low-complexity algorithms for event detection in wireless sensor networks. IEEE J. Sel. Areas Commun. 2010, 28, 1138–1148. [Google Scholar] [CrossRef]
- Cerulli, R.; Gentili, M.; Raiconi, A. Maximizing lifetime and handling reliability in wireless sensor networks. Networks 2014, 64, 321–338. [Google Scholar] [CrossRef]
- Yim, S.J.; Choi, Y.H. An adaptive fault-tolerant event detection scheme for wireless sensor networks. Sensors 2010, 10, 2332–2347. [Google Scholar] [CrossRef] [PubMed]
- Şinca, R.; Szász, C. Fault-tolerant digital systems development using triple modular redundancy. Int. Rev. Appl. Sci. Eng. 2017, 8, 3–7. [Google Scholar] [CrossRef]
- Aysal, T.C.; Yildiz, M.E.; Sarwate, A.D.; Scaglione, A. Broadcast gossip algorithms for consensus. IEEE Trans. Signal Process. 2009, 57, 2748–2761. [Google Scholar] [CrossRef]
- Peng, K.; Lin, R.; Huang, B.; Zou, H.; Yang, F. Node importance of data center network based on contribution matrix of information entropy. J. Netw. 2013, 8, 1248–1254. [Google Scholar] [CrossRef]
- Feige, U.; Goldwasser, S.; Lovasz, L.; Saila, S.; Szegedy, M. Approximating clique is almost NP-complete. In Proceedings of the 32nd Annual Symposium on Foundations of Computer Science, San Juan, Puerto Rico, 1–4 October 1991; pp. 2–12. [Google Scholar]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) A set V of n nodes () (b) A set .Two functions , . maps link to link state; maps node to node state. (f) Two functions about non-electoral leader selection , |
| (a) The original implementation of function : (b) The original implementation of function : |
| Notation | Parameter Name | Description |
|---|---|---|
| History size | How many groups of rtt history we use as the basis. | |
| Filter strength | Indicates the strength of filtering, e.g., the proportion of noise in the records. | |
| Latency positioning factor | Indicates rate of pure latency participate in calculating among history of RTTs. | |
| Alert threshold | If the normalized accumulated value is higher than this threshold, mark the link as Unhealthy | |
| Safe threshold | If the normalized accumulated value is lower than this threshold, mark the link as Healthy |
| Edge State 1 | Edge State 2 | Merge Result |
|---|---|---|
| Conflict |
| Algorithm | Threshold #1 | Threshold #2 | Threshold #3 | Threshold #4 |
|---|---|---|---|---|
| PFD | ||||
| EDFD | ||||
| 2WFD | ms | ms | ms | |
| CV | ||||
| AV |
| Algorithm | Record Size #1 | Record Size #2 | Record Size #3 | Record Size #4 |
|---|---|---|---|---|
| PFD | 100 | 500 | 1000 | 2000 |
| EDFD | 100 | 500 | 1000 | 2000 |
| 2WFD | ||||
| CV | 10 | 30 | 60 | 400 |
| AV | 10 | 30 | 60 | 400 |
| Size of Cluster | Faulty Nodes | Packet Loss Rate (%) | Detection Rate | Mis-Kicking Rate |
|---|---|---|---|---|
| 5 | 1 | 15 | 44.7 | 0 |
| 5 | 1 | 25 | 58.3 | 0 |
| 5 | 1 | 40 | 61.9 | 0 |
| 5 | 1, 3 | 15, 15 | 47.5 | 0 |
| 5 | 1, 3 | 25, 25 | 58.6 | 0 |
| 5 | 1, 3 | 40, 40 | 60.2 | 0 |
| 5 | 1, 3 | 15, 40 | 61.3 | 0 |
| 5 | 1, 3 | 25, 40 | 60.8 | 0 |
| 5 | 1, 3 | 15, 25 | 57.5 | 0 |
| 7 | 1, 2, 3 | 15, 15, 15 | 54.4 | 0 |
| 7 | 1, 2, 3 | 25, 25, 25 | 56.1 | 0 |
| 7 | 1, 2, 3 | 40, 40, 40 | 66.4 | 0 |
| 7 | 1, 2, 3 | 15, 40, 25 | 63.1 | 0 |
| 7 | 1, 2, 3 | 40, 40, 15 | 67.2 | 0 |
| 7 | 1, 2, 3 | 25, 25, 40 | 58.3 | 0 |
| Size of Cluster | Faulty Nodes | Packet Loss Rate (%) | Detection Rate | Mis-Kicking Rate |
|---|---|---|---|---|
| 5 | 3, 4 | 15, 15 | 5.0 | 29.4 |
| 5 | 3, 4 | 25, 25 | 32.3 | 43.4 |
| 5 | 3, 4 | 40, 40 | 31.9 | 8.9 |
| 7 | 4, 5, 6 | 15, 15, 15 | 9.1 | 27.8 |
| 7 | 4, 5, 6 | 25, 25, 25 | 50.2 | 48.1 |
| 7 | 4, 5, 6 | 40, 40, 40 | 57.7 | 33.0 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, H.; Wang, H.; Li, Y. Data-Driven Packet Loss Estimation for Node Healthy Sensing in Decentralized Cluster. Sensors 2018, 18, 320. https://doi.org/10.3390/s18020320
Fan H, Wang H, Li Y. Data-Driven Packet Loss Estimation for Node Healthy Sensing in Decentralized Cluster. Sensors. 2018; 18(2):320. https://doi.org/10.3390/s18020320
Chicago/Turabian StyleFan, Hangyu, Huandong Wang, and Yong Li. 2018. "Data-Driven Packet Loss Estimation for Node Healthy Sensing in Decentralized Cluster" Sensors 18, no. 2: 320. https://doi.org/10.3390/s18020320
APA StyleFan, H., Wang, H., & Li, Y. (2018). Data-Driven Packet Loss Estimation for Node Healthy Sensing in Decentralized Cluster. Sensors, 18(2), 320. https://doi.org/10.3390/s18020320