1. Introduction
Including information from multiple cooperative sensors in a target tracking scenario can increase performance over using a single sensor or uncooperative sensors. For example, a bearings-only sensor requires more than one instance to recover point estimates of the target location. One concern that arises from the application of such a multiple-sensor system is its security. The sensors that comprise the system may come from various manufacturers and may be susceptible to interference by an adversary, either electronically or at their physical location. Therefore, as the number of sensors in a network increases, as does the number of potential vulnerabilities. This concern has been the subject of many studies by the cyberphysical systems community [
1,
2,
3].
While there are a wide variety of attacks that a sensor network can suffer, one potential vulnerability comes from an adversary compromising some sensor nodes. An attack that completely disables some sensors can be easily detected, and thus appropriate measures can be taken to diminish its impact. Alternatively, an attacker could inject false information or a bias into the system so that its core algorithms fail. Detecting such false information is a challenge, because the specific nature of that kind of disruption is not known in advance.
The computing community has long studied the intrusion detection problem in the context of network security. Most work has consisted of analyzing the data traffic in search of unusual patterns [
4,
5,
6]. In a wider context, the terms
anomaly and
outlier detection describe the search of any patterns that do not fit the nominal operation of a system. Searching for anomalies can be used for different purposes, such as for finding system faults or detecting intrusions [
7,
8].
In the context of a target tracking system, an attacker would be interested in disrupting the operation of the whole system to prevent some or all targets from being detected or to enable a tracked target to become unobservable or evade pursuit. A multiple-sensor system would be less vulnerable to a full takeover as a result of redundancy. As an alternative, an attacker in control of several nodes could introduce false measurements that deviate the tracker from the true target, making it follow a decoy or causing any estimation algorithms to diverge. Depending on the model, a simple disagreement among sensors may suffice to flag a possible compromise [
9].
When the underlying system dynamics follow a linear time-invariant (LTI) model, it has been shown that it is possible to deal with additive disturbance signals, successfully recovering the system state [
10,
11,
12]. If the specific nature of the attack cannot be anticipated, the search for anomalies in a system can be treated as a one-class classifier [
13]. In this case, the nominal operation of the system has to be known beforehand, and a model of the measurements that it produces is built for later comparison. One of the earliest approaches to outlier detection consists of building a probabilistic model, such that inliers are considered to originate from a known distribution [
14]. This idea has been extended to multi-dimensional datasets [
15]. A problem of multiple-sensor systems, which is closely related to our motivation, is fault detection and isolation (FDI). This issue is often approached by deploying per-sensor strategies, which are combined in a decision-making stage. Some recent works utilize this technique, combined with a priori knowledge of the system dynamics or for a class of systems [
16,
17,
18].
In this work, we present an algorithm to detect an intrusion in a multiple-sensor system. The algorithm works for a class of attacks that introduce a malicious signal at some sensor nodes with the purpose of deviating a target state estimator from the truth. We have applied the principles of hypothesis testing and the one-class classifier, which collects information about the system during nominal operation. This knowledge has then been applied to Bayesian networks (BNs) to perform an online detection of anomalous behavior in any subset of the sensors.
3. Methods
3.1. Preliminaries
We assume that some region
is being surveyed by
s sensors. We can pose the sensor compromise problem as an anomaly detection application. Referring back to the RFS formulation of the observation set in Equation (
6), the observation set with added anomalies for sensor
i can be described as
while in the nominal operation mode, the observation RFS
follows a certain model that includes noise derived from a known distribution. In
, the observation
has noise distributions that may not match the assumed model. The clutter model can also be modified by the attack. In addition, any attacks that consist of the introduction of decoys among the targets can be modeled as a new RFS,
.
While it may not be possible to characterize each and every attack or sensor failure, the model used in Equation (
15) allows us to enumerate the major categories into which an anomalous behavior may fall:
Modified observation of a given target: The sensor noise does not conform to the assumed distribution. This can be, for example, an added bias on the observations or an increased covariance in the noise distribution.
Modified probability of target detection: For instance, some targets can be omitted from the sensor observations.
Modified false alarm rate: This can include an increase in the clutter intensity, duplicate reports for a given target, and so on.
An attack or malfunction may combine any of the above.
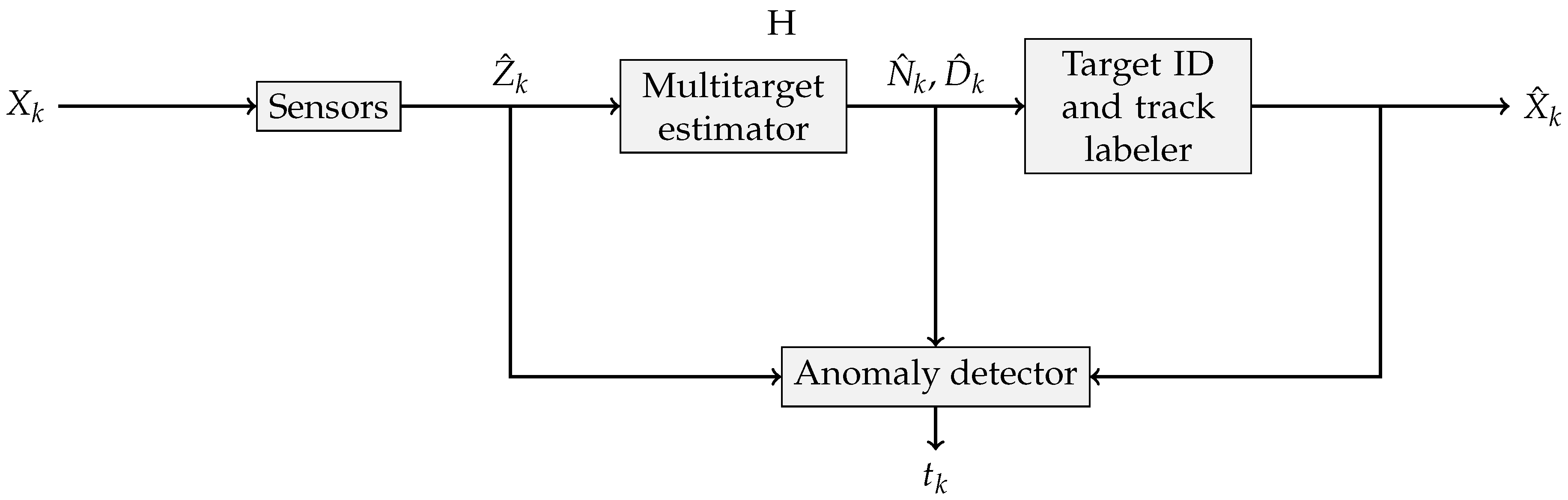
Confronted with the impossibility of modeling every kind of attack on the sensor system, an alternative is to resort to the one-class classifier approach. A diagnostics system is built that is only trained to recognize the nominal operation of the sensor array. Any measurements that deviate significantly from the learned model are then classified as being caused by a breach in the system or a hardware failure. The overall architecture of such an anomaly detection system is shown in
Figure 1.
Selecting which features to learn about a multiple-target tracker is not straightforward. Because we do not limit our analysis to a specific class of dynamical systems or observation models, we inspire our anomaly detection approach in the concept of hypothesis testing.
The multiple-target scenario includes the possibility of having target births, deaths and sensor clutter. Hence, it requires a way to quantify the deviation from each sensor with respect to the estimator as a whole. Before continuing with our exposition, we introduce some assumptions that we require to hold for the anomaly detection techniques studied.
Assumption 1. The observation spaces for all sensors are such that for , or there exist one-to-one transformations such that .
Assumption 2. is a Banach space, with metric .
Assumption 3. The observation noise for the sensor, with respect to each target, is a stationary process, with known mean. Moreover, the noise statistics for all observations from targets are equal and known.
The first assumption allows for the direct comparison of observations stemming from different sensors. The second enables us to use a metric to compare sensor observations. Finally, the third simplifies the analysis of the relative error between observations from different sensors.
3.2. OSPA Metric
For every estimation algorithm, there is a metric that can quantify its performance. As an example, any single-target estimation algorithm can use the
-norm to compute the difference between the estimated state and the true target state. This is no longer valid in the case of multiple targets, as the estimation error can consist not only of a distance in state space, but also of association errors between estimates and different target states. There can also be errors in the estimation of the cardinality of the target set. Metrics such as the Haussdorf distance have been proposed to capture these errors, and some developments have dealt with the limitations of this distance [
27]. An alternative that solves most of these problems and remains a valid metric, that is, it satisfies the axioms of identity, symmetry and the triangle inequality, is optimal sub-pattern assignment (OSPA) [
28]. To use this metric, one needs to specify a parameter called the cut-off
, in addition to
, which is the order of OSPA.
The OSPA metric is computed using the expression
where
, and
is the set of permutations on
for any
. The cardinalities of the sets being compared are
and
. Equation (
16) is only valid if
; otherwise
.
In the rest of this work, we make use of a decomposition of the OSPA metric into two components: localization error and cardinality error. The localization component is given by
and the cardinality component is
As before, these expressions only hold valid if
, and by definition,
and
if
.
3.3. Anomaly Detection: Single-Sensor Case
In the single-sensor case, the information available to the filter is limited to the estimated target states over time and the observations from a single source. Detecting an anomaly in the sensor behavior implies comparing its observations of the projections of the estimated states to .
In the single-sensor, single-target case, one solution to identify whether an estimator is operating nominally is the use of residual analysis [
29]. In a Kalman filter, the residual is given by
, where
y is an observation and
is the estimated target state. The residual in this case follows a
distribution; thus a hypothesis test would reveal the existence of an anomaly.
The single-sensor, multiple-target case with general nonlinear dynamics and non-Gaussian noise requires a different treatment. Each pair of dynamical and observation models would require a separate derivation of the statistics of the residuals. A general approach needs a training phase in which a statistical model of the residuals is built, to be used as the basis for anomaly detection during a deployment phase.
In a single-sensor, multiple-target tracker, the ability of an attacker to introduce decoys is limited by . In a trusted sensors framework, the target birth intensity is typically chosen to minimize the response time of the PHD filter, such that new targets are tracked as soon as possible. However, this renders any decoy injection attacks quite effective, as they all become new objects in the tracker. Tuning can delay the apparition of any decoys and enable the detection of an attack by imposing a limit on the expected number of new targets, but at the expense of delaying the detection of true targets. Another problem is that this countermeasure assumes that the attacker does not know about the modified , as otherwise, they would just introduce the decoys sequentially over time to avoid detection.
Proposition 1. Consider a single-sensor, multiple-target tracker based on the PHD filter. If an attacker has full knowledge of and the expected number of targets to track is always unknown a priori, the attacker can introduce decoys without being detected.
Proof. We show that even for the simplest multiple-target tracking case, an attacker would be capable of spawning a new target in the system. We consider a basic PHD filter with
,
and a single target, such that
is some unimodal density. The sensor is assumed to produce no clutter. Then,
after the prediction stage. An observation of the true target
is reported by the sensor. We assume that an attacker sends
, a false report of the location of a second target. For illustration purposes, we consider
and
to have negligible overlap. From Equation (
9), it follows that each observation will produce a term in the sum to compute
. The term due to the real observation is
while the term corresponding to the decoy is
and as a result of this reduction, integrating the resulting PHD produces
The introduction of the extra decoy can only be prevented if
.
As we have shown, even under the simplest conditions, it would not be possible to detect the insertion of a decoy by an attacker. As those conditions are relaxed, and because clutter, splitting and overlapping targets are included in the model, there are even more possible locations in which an attacker can successfully place a decoy without violating the sensor model. ☐
3.4. Anomaly Detection for Multiple-Sensor Systems
As discussed so far, the detection of anomalies in the single-sensor case, for a multiple-target tracking problem with nonlinear dynamics, has several difficulties that may not have a viable solution for all scenarios. If a redundant architecture with multiple sensors is introduced instead, new possibilities arise for compromise detection. For the multiple-sensor case, it is possible to use the observations from all sensors to measure the deviation of each from a consensus, under the following condition.
Assumption 4. An attacker cannot control more than sensors; thus a majority consensus set with all observations by all sensors at time k can be constructed. From Assumption 1, every element of belongs to a single .
As established in the previous section, the OSPA metric can indicate distances between finite sets with different cardinalities. Hence, we propose using quantities related to the OSPA metric to measure the distance between the observations of a sensor, , and the estimated target states . Because OSPA combines localization and cardinality errors in a single metric, we opt to use and as a way to separate the two kinds of sensing errors in multiple-target scenarios. Our anomaly detection goal does not need the symmetry property of OSPA and can benefit from a distinction between localization and cardinality disparities among sensors.
We consider, for each sensor
i, the set of its observations
. Hence, we can construct the set of all observations with the exception of those from sensor
i, which are
. In our exposition of the anomaly detection scheme, the
p and
c values of
and
are assumed to remain constant; thus we do not refer to them explicitly unless necessary. A calculation of the localization and cardinality errors of the observations from each sensor
i at time
k, when compared to the consensus set, can be denoted by
Because the probability distributions of
and
depend on many factors, such as the target dynamics, sensor models and number of targets, they can be constructed from experimental data during nominal system operation. A training phase with fully trusted sensors and estimator would be needed.
After the training data is gathered, sequences
and
need to be analyzed for each sensor. An adequate hypothesis test is necessary to evaluate if the null hypothesis,
, can be rejected. Useful tools in this context are the Kolomogorov–Smirnov two-sample test, and the Wilcoxon rank-sum test [
30,
31]. For this work, we apply the latter.
There can be a coupling between the sensor outputs and the estimated state. It would be desirable to isolate a faulty sensor from others. Unfortunately, as shown by Equation (
11), the iterated-corrector scheme for multiple-sensor information fusion processes the observations from each source in a sequential manner. Because we are proposing to compare each
to
, and because
is extracted from
, several sensors could be considered as anomalous, as
is rejected for each of them. The nature of the attack determines whether faulty sensors can be isolated or not, as evidenced later in our results section.
3.5. Algorithm for Multiple-Sensor Anomaly Detection
We summarize our anomaly detection methodology. We base the anomaly detection procedure on a BN. The rationale behind this choice is the observation that the two measurements and may have different values depending on the class of the attack. Most attacks, if they are of high enough intensity, will cause a mismatch in the number of objects detected by a sensor. Only a subset of attacks that introduce a small error signal, such as noise or bias, will provoke an increase in without affecting .
Data collection. Gather data from all sensors during nominal operation. This requires a trusted environment. This data is then used to compute and for all k in the recorded measurements.
Nonparametric statistical test. During a target tracking task, keep a history of measurements for every sensor using a fixed horizon; that is, collect for a lag l. At every time step k, perform a nonparametric statistical test between the history of measurements and the trusted data for each sensor, and save the p-value of the test.
Bayesian inference for anomaly detection. Denote the trustworthiness of each sensor by the indicator function:
There are two events associated with the result of a hypothesis test between a fixed number of observations of
and
:
The results of the nonparametric hypothesis test provide
and
. Then the probability of
can be updated over time in a Bayesian manner. The inspection of the effects of some attacks on
reveals that the dependence relations among
,
and
can be described by the BN depicted in
Figure 2. Hence, the posterior probability for
is given by
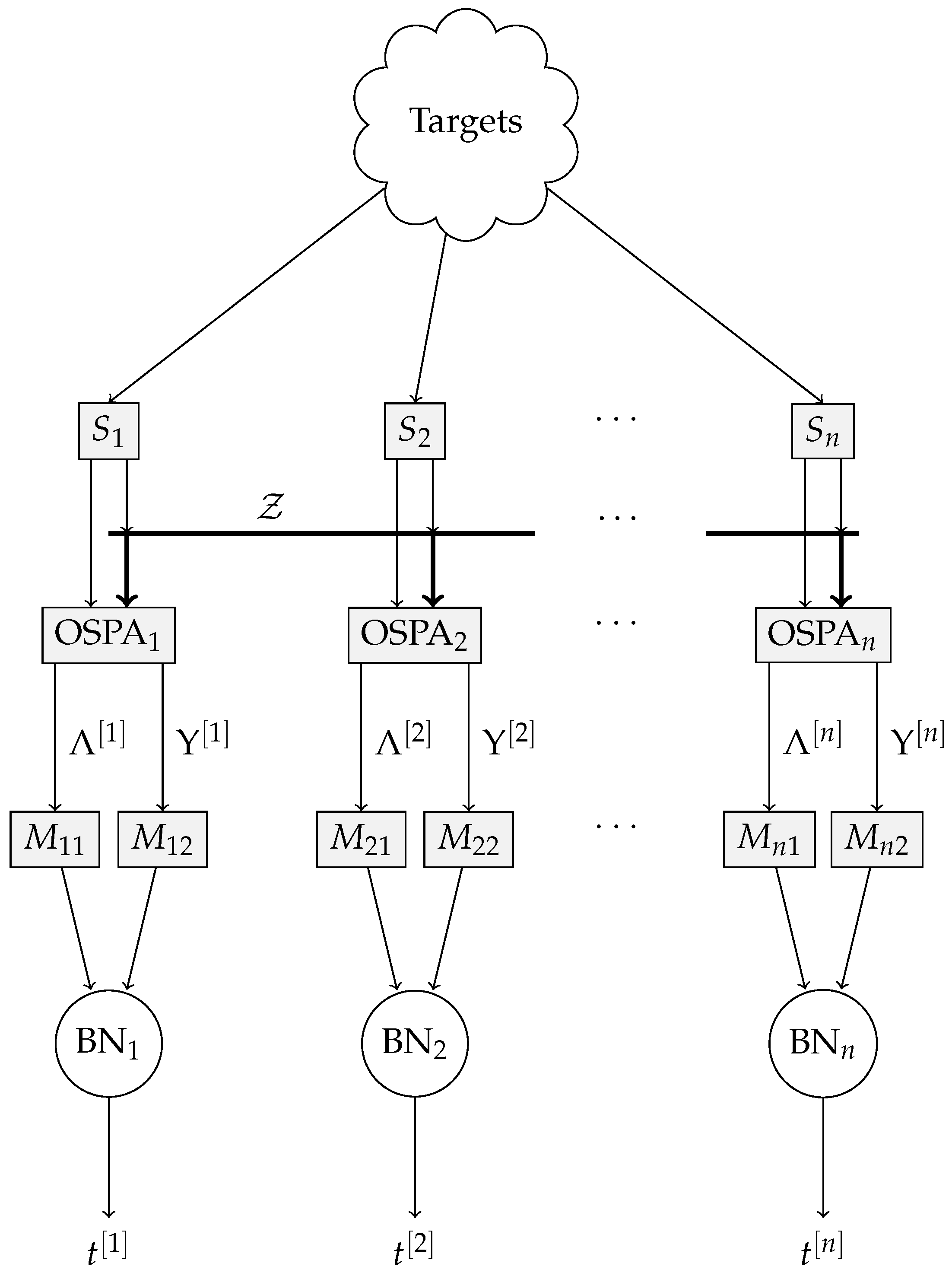
The full anomaly detection system is described in
Figure 3. The targets are (generally) visible to all sensors
. The components of OSPA
and
are computed for every sensor, and banks of delays
and
produce
and
, respectively, which are then fed to the individual BNs. The output of each BN is the estimated posterior probability of sensor trustworthiness,
.
5. Discussion
The numerical results report the precision and recall for each classifier, which we have combined by presenting the
F-score in
Table 1. We present two figures per scenario: local and global classification scores. Local indicates that we measured the
F-score per sensor, so that the overall attack was detected and the responsible sensors were flagged as being compromised. The global
F-score measured whether an attack was detected by the system, independently from which sensor may have caused it. Hence, the global
F-score was always expected to be higher.
The attack identifier number from the leftmost column coincides with the seven disruption modalities described before. The numbers in bold font highlight the highest F-score in that table row. The column titled “F-Score Mode” indicates whether the intrusion detection was computed on a sensor-by-sensor basis (“Per sensor”) or globally (“Global”). In most cases, the “Global” score is significantly higher than the “Per sensor” score. These attacks that were mostly related to the introduction of decoys were particularly well detected. A notable case is attack 6, for which some sensors stopped reporting a subset of the targets. The “Per sensor” F-score is low, as the sensors under attack were identified as nominal, and those in normal operation were flagged as compromised. However, the “Global” score is on par with those obtained for other attacks. In this instance, the SVM classifier outperformed the BN on the “Per sensor” F-score but not on the “Global” score.
In order to illustrate the effectiveness of both the BN and the SVM approaches under some attacks, we show in detail the results of three simulated attacks. Each attack had a different nature and degree of success. The iterated-corrector SMC–PHD filter had not been altered in any way to change its resilience when presented with the attacks. In these examples, the attack start time was 60 s, with an end time of 150 s.
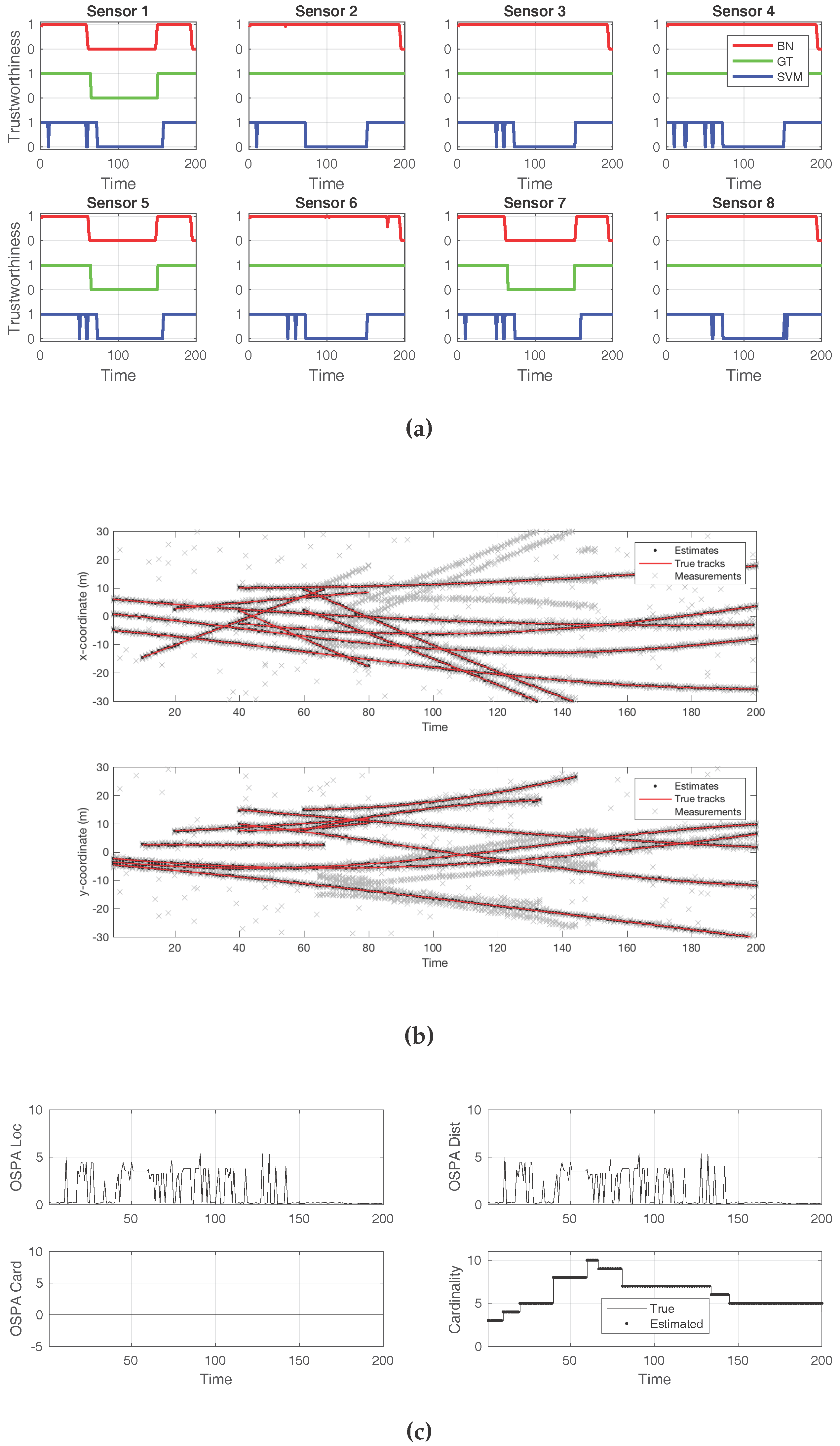
First, we show the result of adding several decoys to a minority of sensors, three out of eight.
Figure 5 displays plots that convey insight about the effects of the attack. The first plot is
Figure 5a, and it compares the ground truth for the attack (green line) to the detection offered by the BN (red line) and to that of the SVM classifier (blue line). In this case, both approaches successfully detected the presence of an attack from a global perspective. However, the SVM classifier flagged every sensor as being under attack. In contrast, the BN correctly identified which sensors were producing the false decoys.
Figure 5b shows the tracks detected by the SMC–PHD filter, compared to the true tracks. The gray crosses represent the sensor observations. While there was an abundance of false target reports, along with clutter, this attack was not sufficient to make the filter fail or report the decoys as true targets. The effects of the attack, in terms of the cardinality and localization errors, can be verified in
Figure 5c. As this attack was not successful in introducing decoys, the cardinality error was zero, while the localization error remained small.
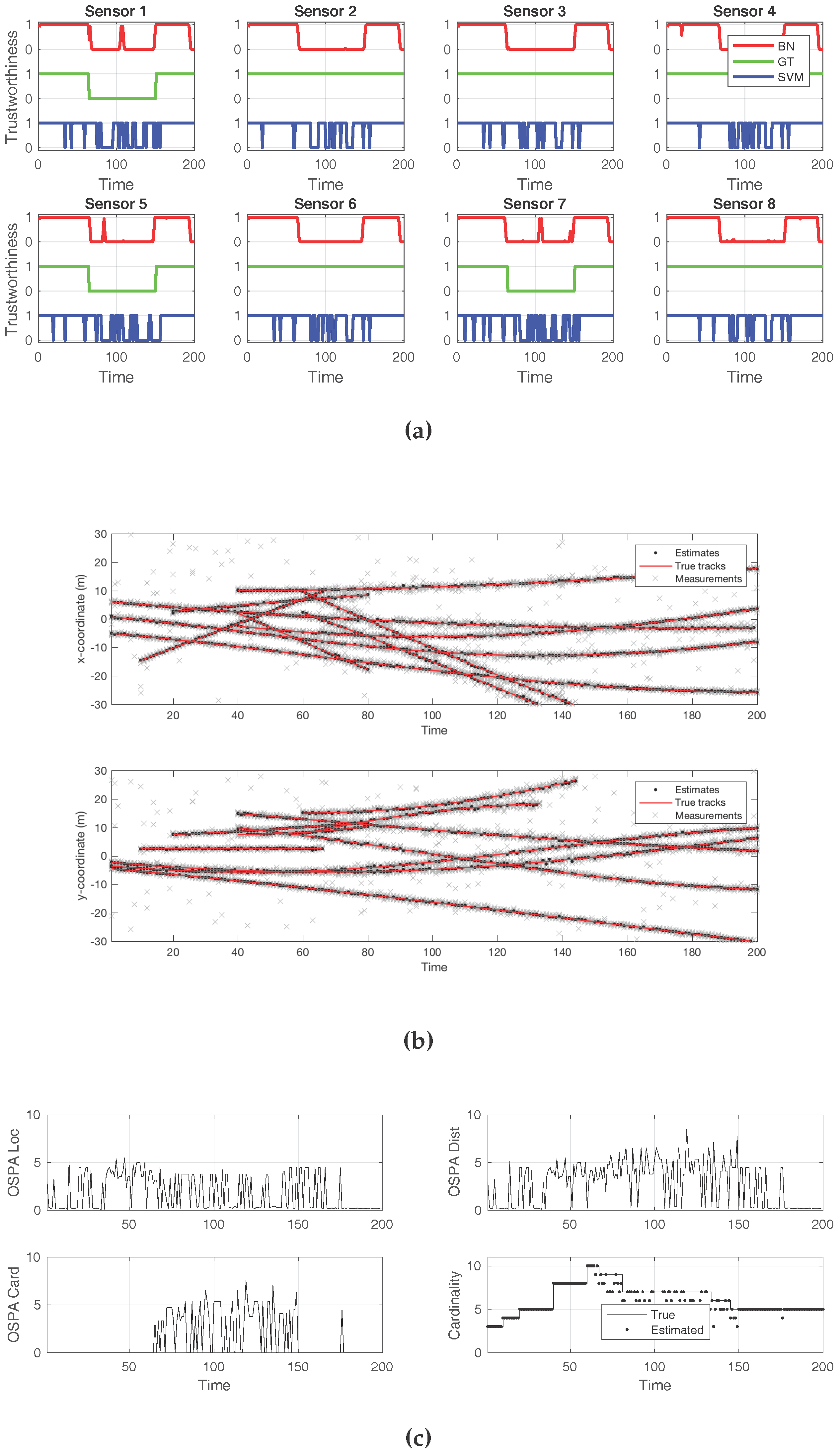
The second case, in
Figure 6, exemplifies a successful attack that made the SMC–PHD filter arrive to a wrong cardinality estimate during the times at which the sensors were compromised. Again, three out of the eight total sensors were being attacked. This attack introduced an elevated level of white noise, more than twice what was expected. As
Figure 6a depicts, the BN approach incurred several mistakes while identifying individual sensors under attack. The same happened to the SVM classifier. In both cases, even if the compromised sensors were not correctly isolated, the presence of an attack in the overall system was successfully reported. The effects of the attack on the estimated target positions are shown in
Figure 6b. Both the localization and the cardinality components of the OSPA error show adverse effects from the attack in
Figure 6c. When the estimated cardinality is compared to the ground truth, it can be verified that the noise attack resulted in missed target reports by the filter.
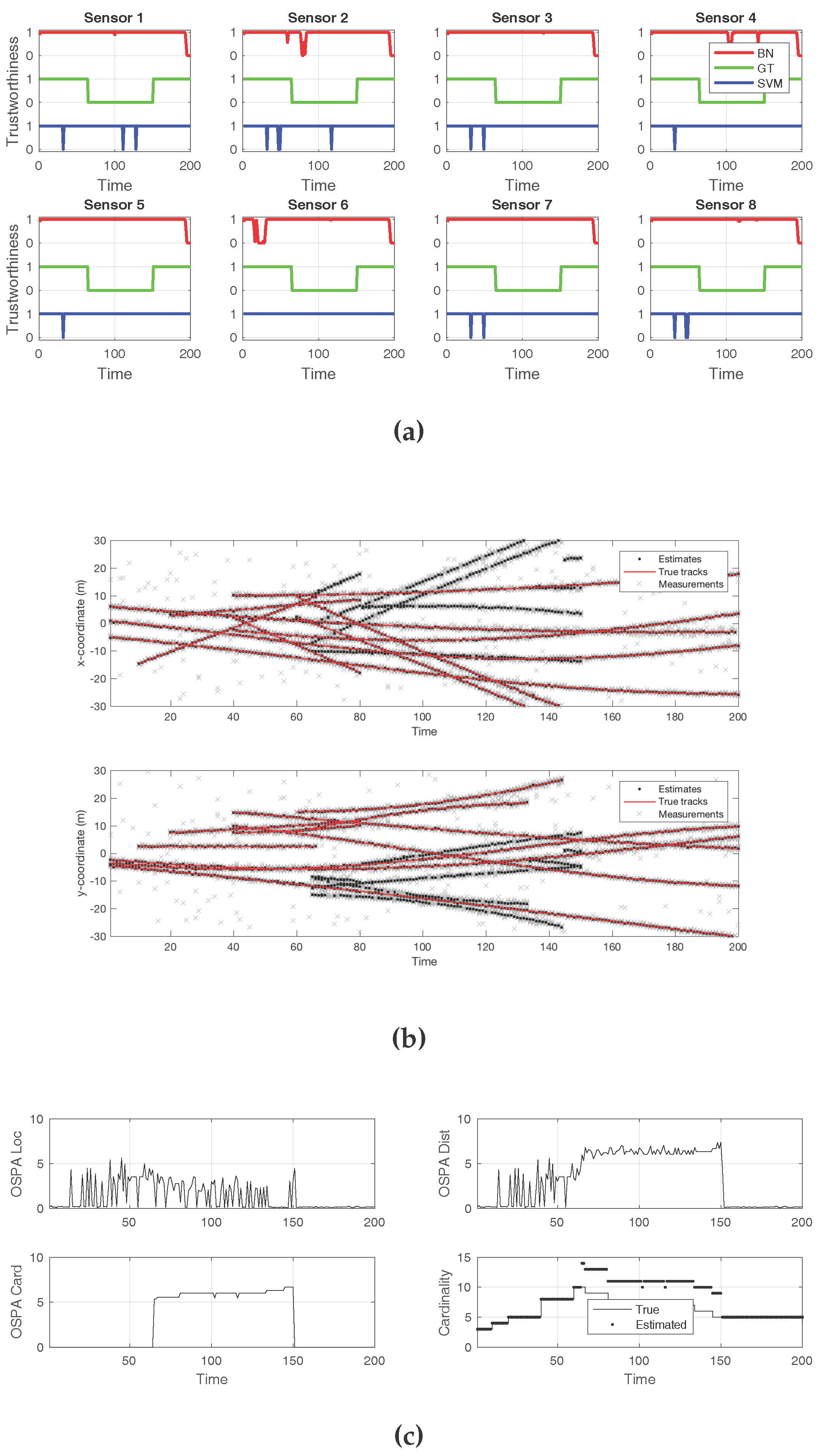
The final example scenario, which depicts the effects of an attack on all sensors, is shown in
Figure 7. Here, a decoy introduction attack was performed on every sensor, which could not be detected under the schemes discussed in this work.
Figure 7a shows that, while the ground truth contained attacks for all sensors, no detection technique reported any compromise. The new, false tracks that resulted from the attack can be seen in
Figure 7b. The cardinality error was constantly high during the time of the attacks, as seen in
Figure 7c. The comparison between the true and estimated cardinalities shows the increased number of targets during the decoy introduction attack.
6. Conclusions
Given the possibility of an intruder taking over a subset of sensors in a target detection and tracking system, we present an algorithm for an effective intrusion detection scheme. We use the principle of a one-class classifier to detect anomalies in the measurements collected by the sensors, without assuming a particular attack form is employed by the intruder. The main tool that enables us to detect the anomalies is the OSPA metric, along with its localization and cardinality error components. While we show that in the single-sensor case, the task of detecting an intrusion can vary from hard to impossible, depending on the type of attack, using multiple sensors opens up the option of forming a consensus set to have some reference behavior with which to compare the performance of individual elements.
As evidenced by our simulation results, the use of a BN per sensor, along with hypothesis testing for the localization and cardinality errors of each sensor with respect to the consensus set, is a powerful tool that identifies the anomalies in a wide variety of situations. Some border cases cannot be handled by this approach if an accurate identification of the culprit sensors is required, but even in these scenarios, an overall intrusion alarm can be raised.











{kind=link}
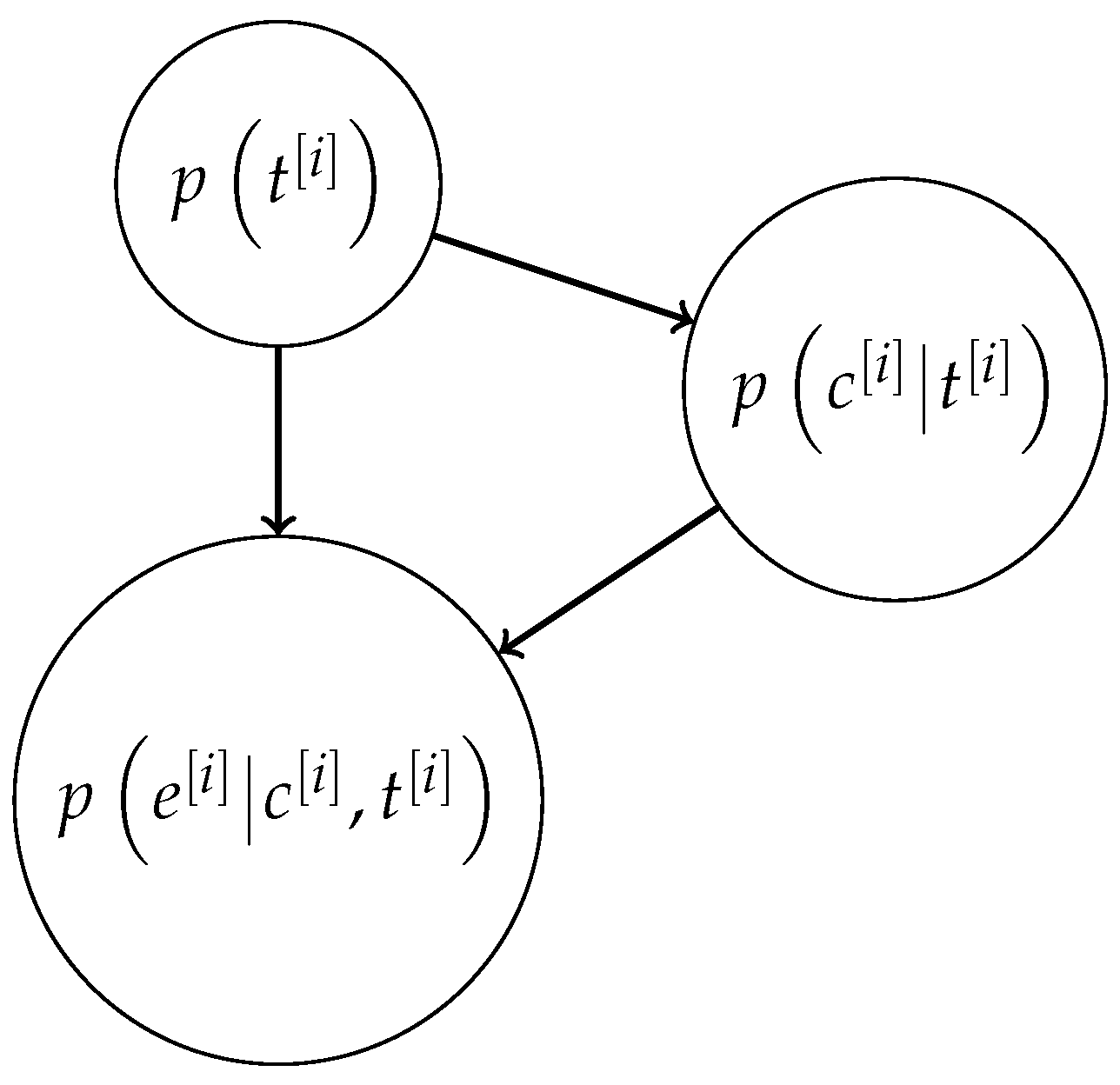{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}