An Unsupervised Deep Hyperspectral Anomaly Detector


Abstract
:1. Introduction
- Supervised training requires labeled training data, which are not always available.
- The technique of weighted coding for HSI anomaly detection using DBN is proposed for the first time.
- An effective statistical weight update technique is proposed to adaptively generate the neighbor weights.
- To the best of our knowledge, the results reported achieve the highest accuracy to date.
2. Literature Review
3. Proposed Adaptive Weight DBN Based HSI Anomaly Detection
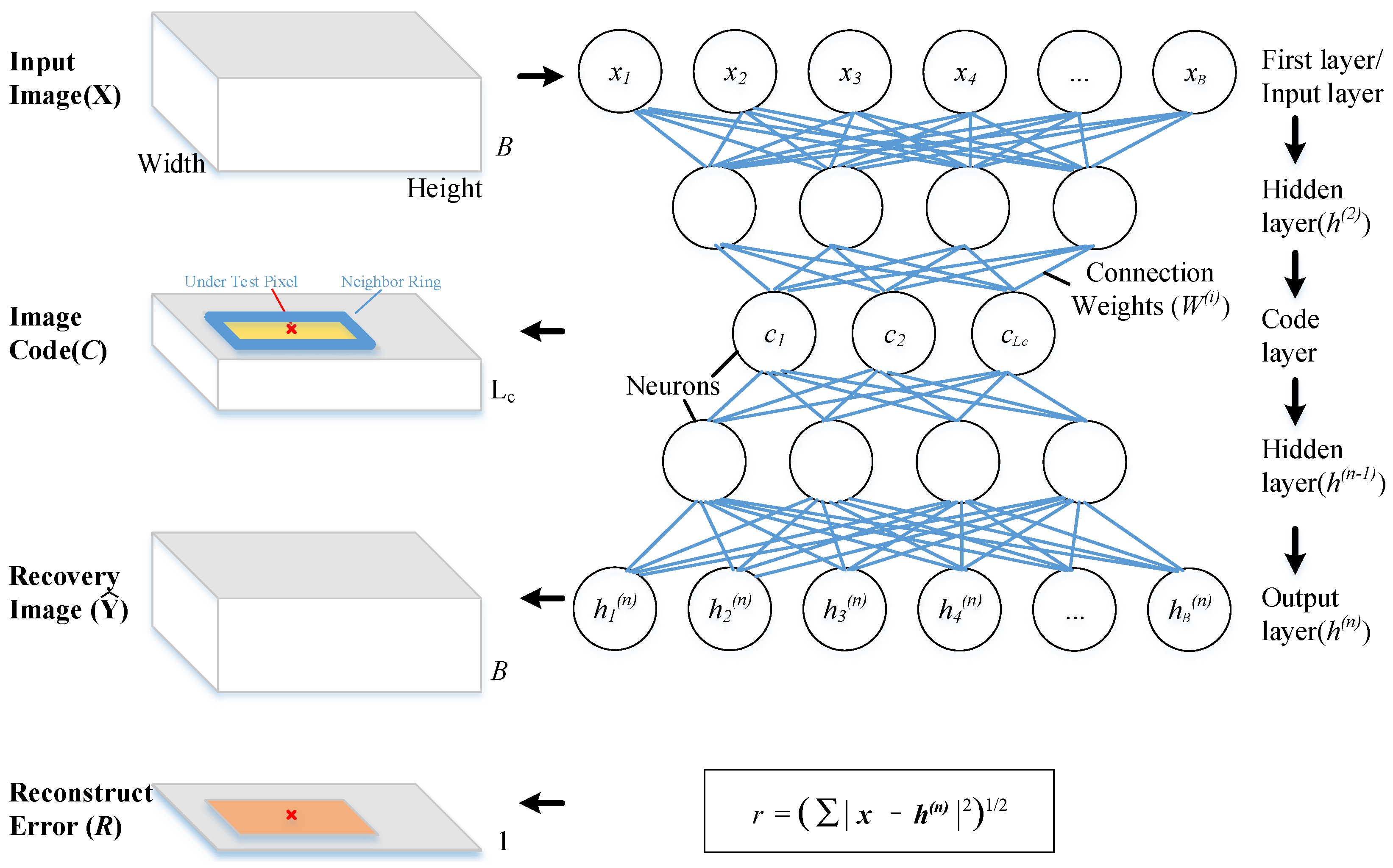
3.1. Deep Belief Network as an Auto-Encoder
3.2. The Framework of Proposed Method
- Step1.
- Train the DBN model in an unsupervised way with Input Image (X) which is constructed with all the under test pixels.
- Step2.
- Feed Input Image (X) to DBN model to generate the Image Code (C ) and Reconstruction Error (R). The C is generated from the output of the middle layer neurons. R is the differences between X and Recovery image () which is the decoded data array of C by DBN model.
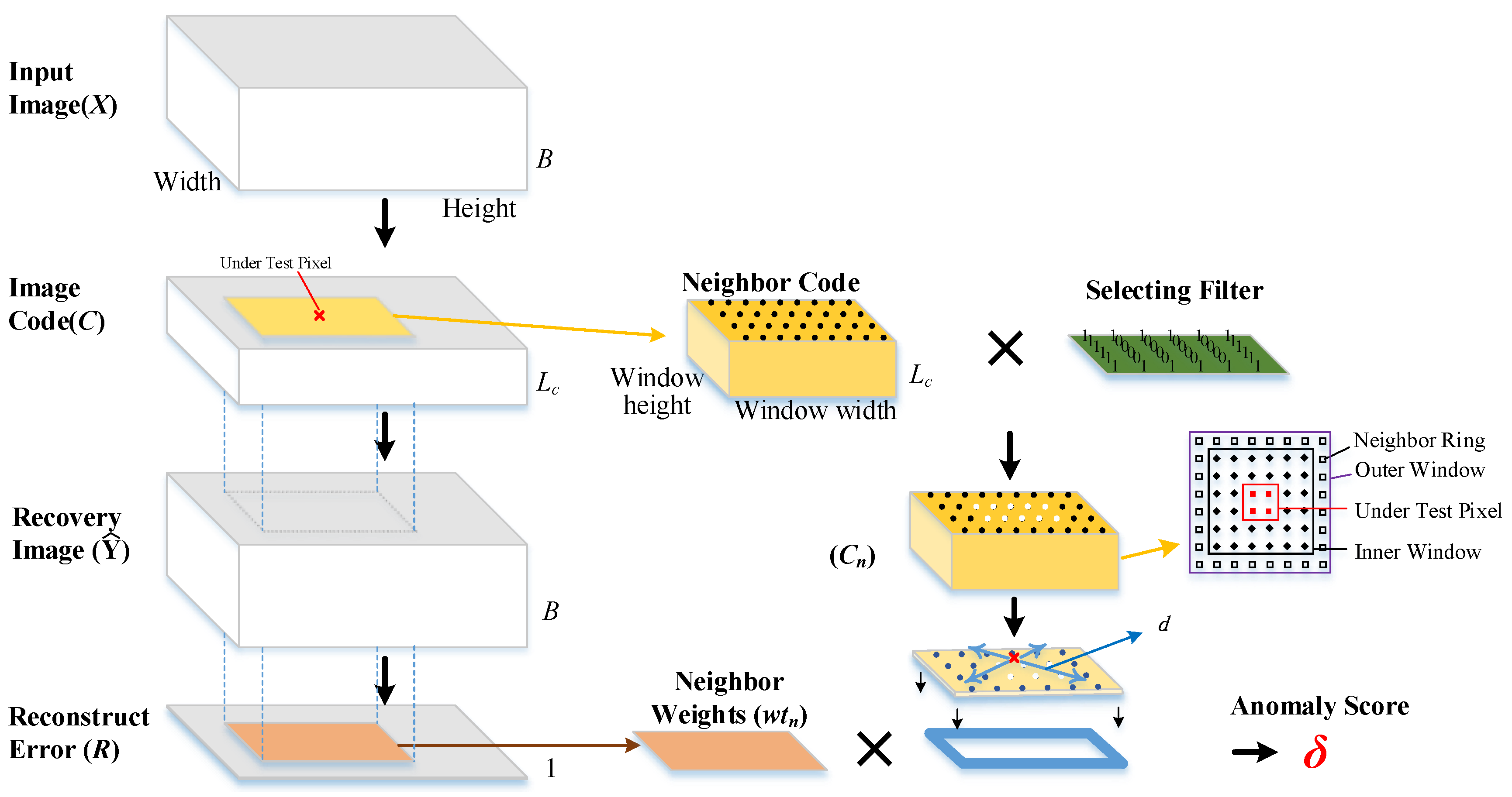
- Step3.
- Select neighboring pixels from the surrounding of under test pixel in C.
- Step4.
- Calculate the distances between neighboring pixels code and the under test pixel code in C.
- Step5.
- Calculate the neighbor weights by Reconstruction Error (R).
- Step6.
- Calculate the anomaly score by the neighbor weights and the distances.
| Algorithm 1 Adaptive Weight DBN Based HSI Anomaly Detection |
2: ← Training via gradient descent with X 3: (C, R) ← EncodeDecode() 4: for j = 1 to do 5: ← from C following Section 3.3 6: ← from R following Section 3.3 7: for to do 8: ← Equation (9) and Equation (10) with 9: i ← 10: end for 11: ← Equation (7) by using and 12: j ← 13: end for 14: return 15: end function 16: 17: function EncodeDecode() 18: Initialize the from 19: for j = 1 to do 20: x ← one pixel from X 21: Encode x with 22: ← output of middle layer of 23: ← decode with 24: ← Equation (5) with and x 25: j ← 26: end for 27: return R and C 28: end function |
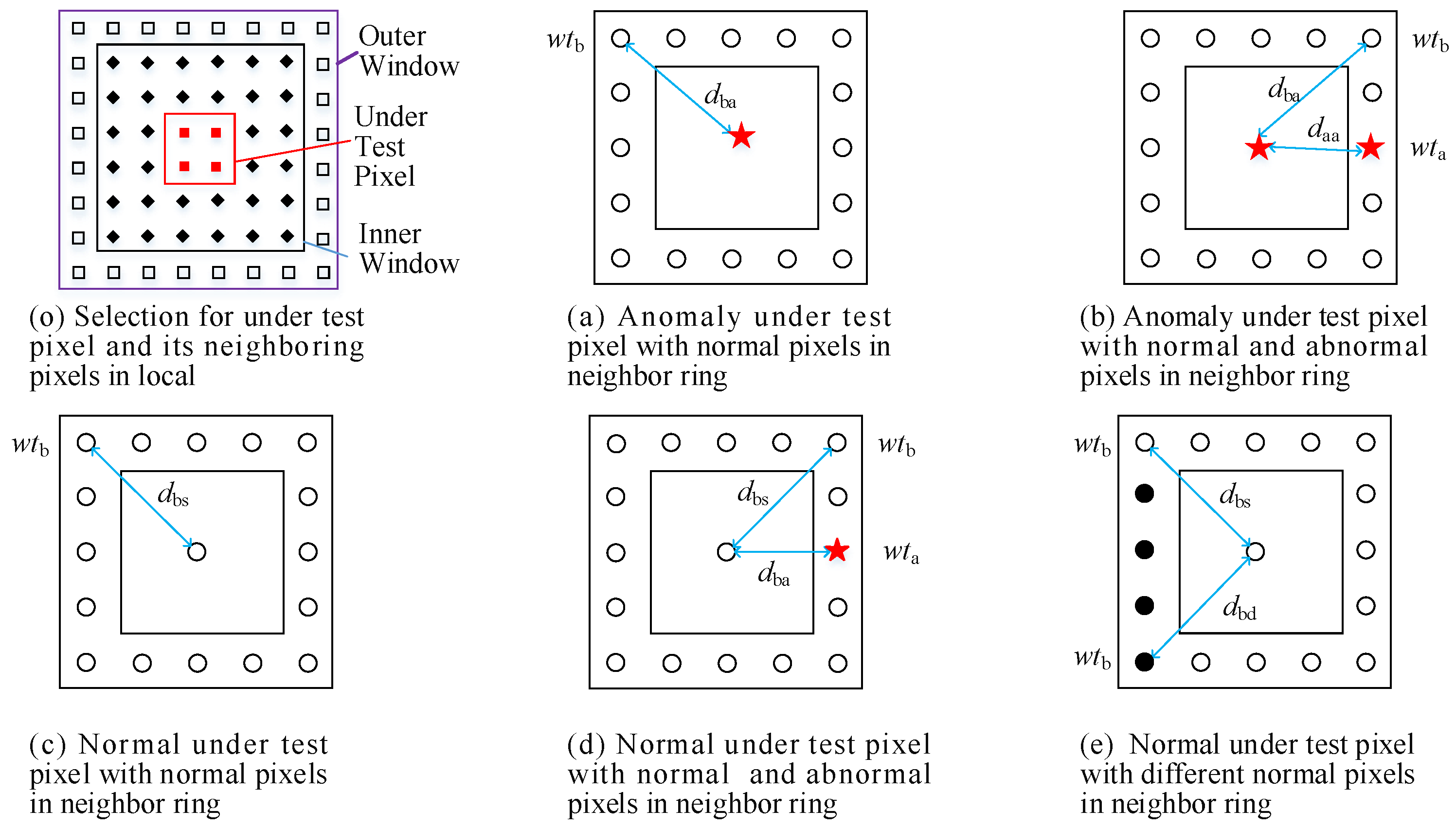
3.3. Proposed Adaptive Weight-Based HSI Anomaly Detector
4. Experiments
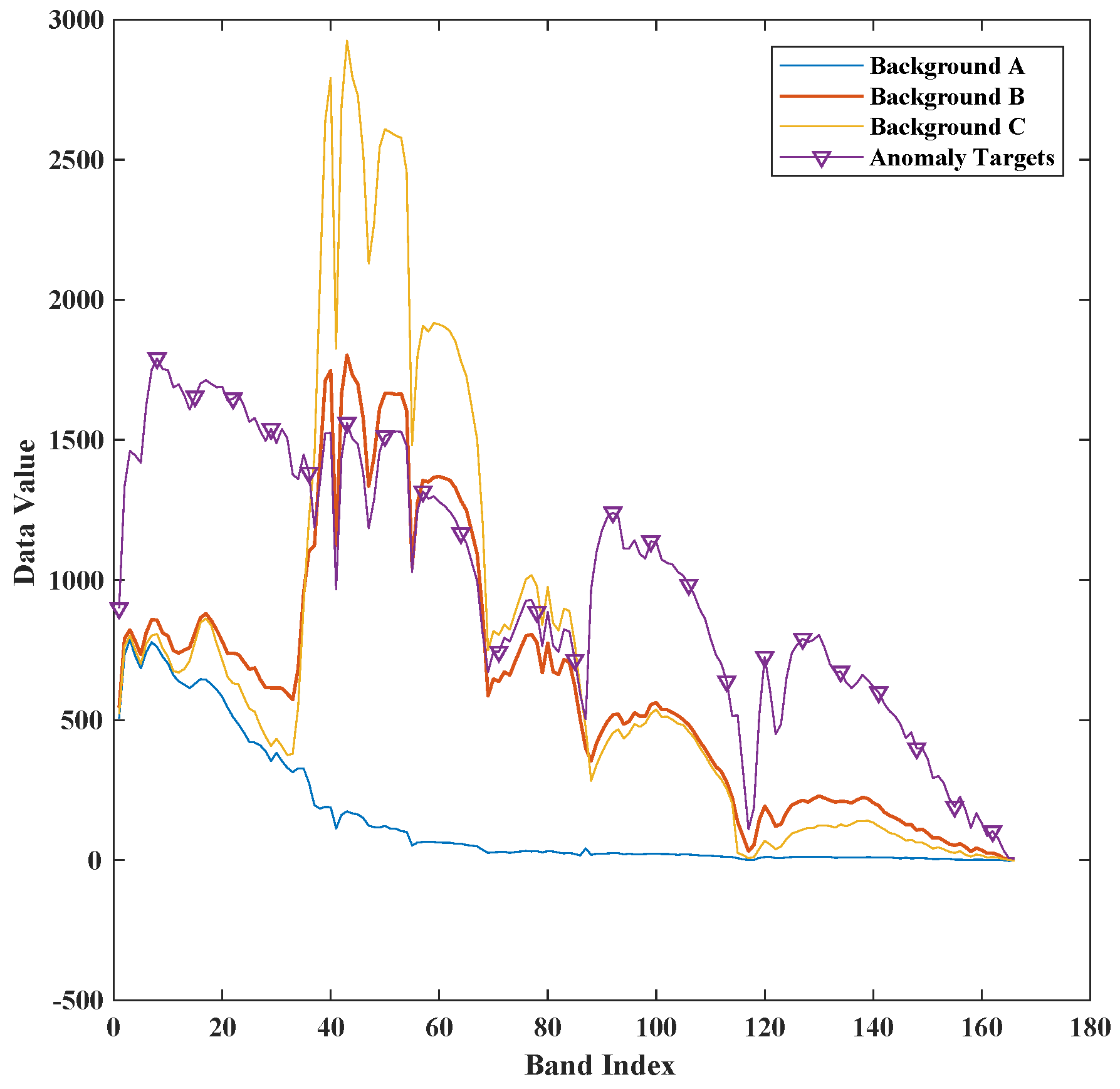
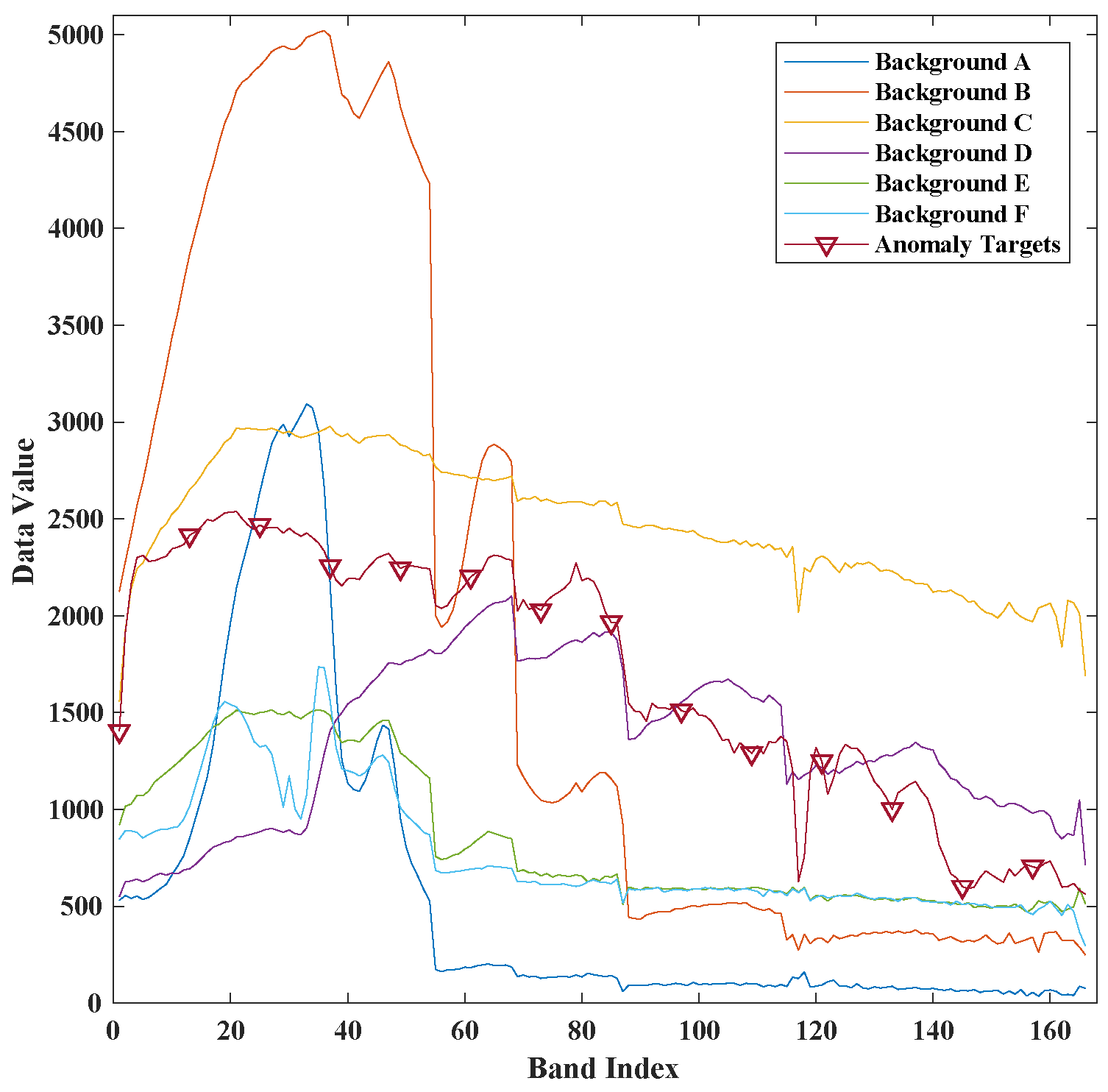
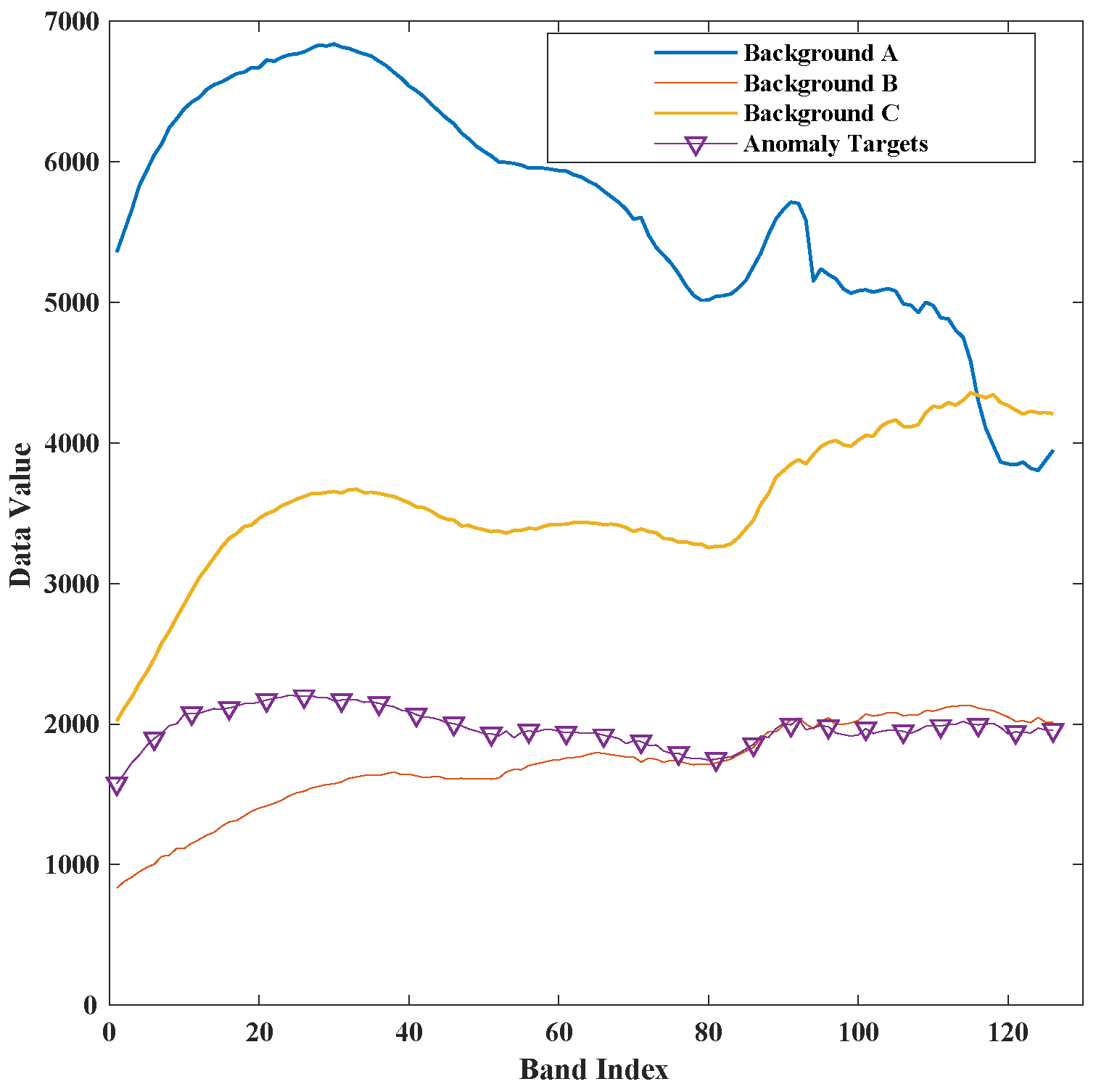
4.1. Dataset
4.2. Experiment Environment and Evaluation Criteria
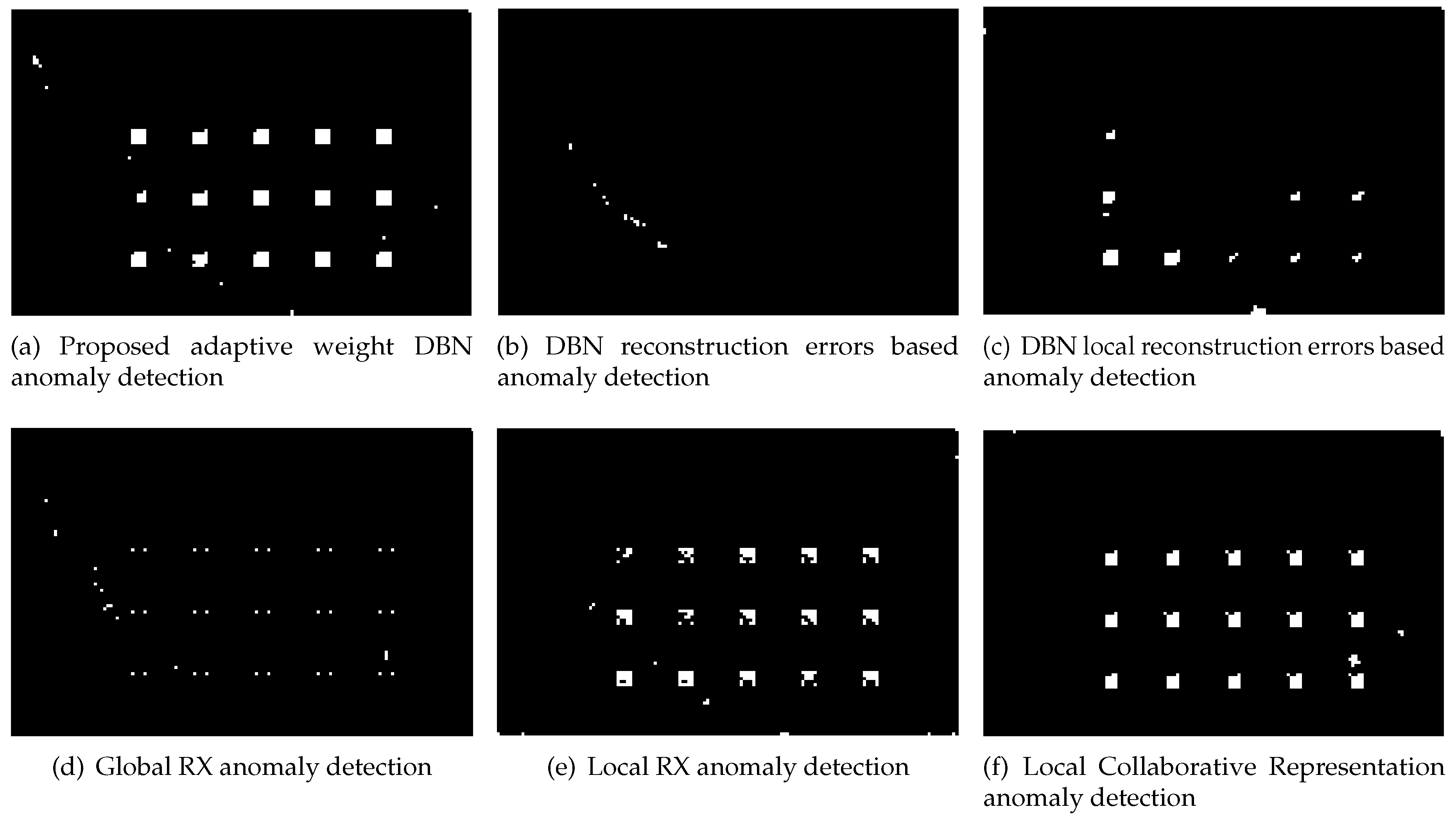
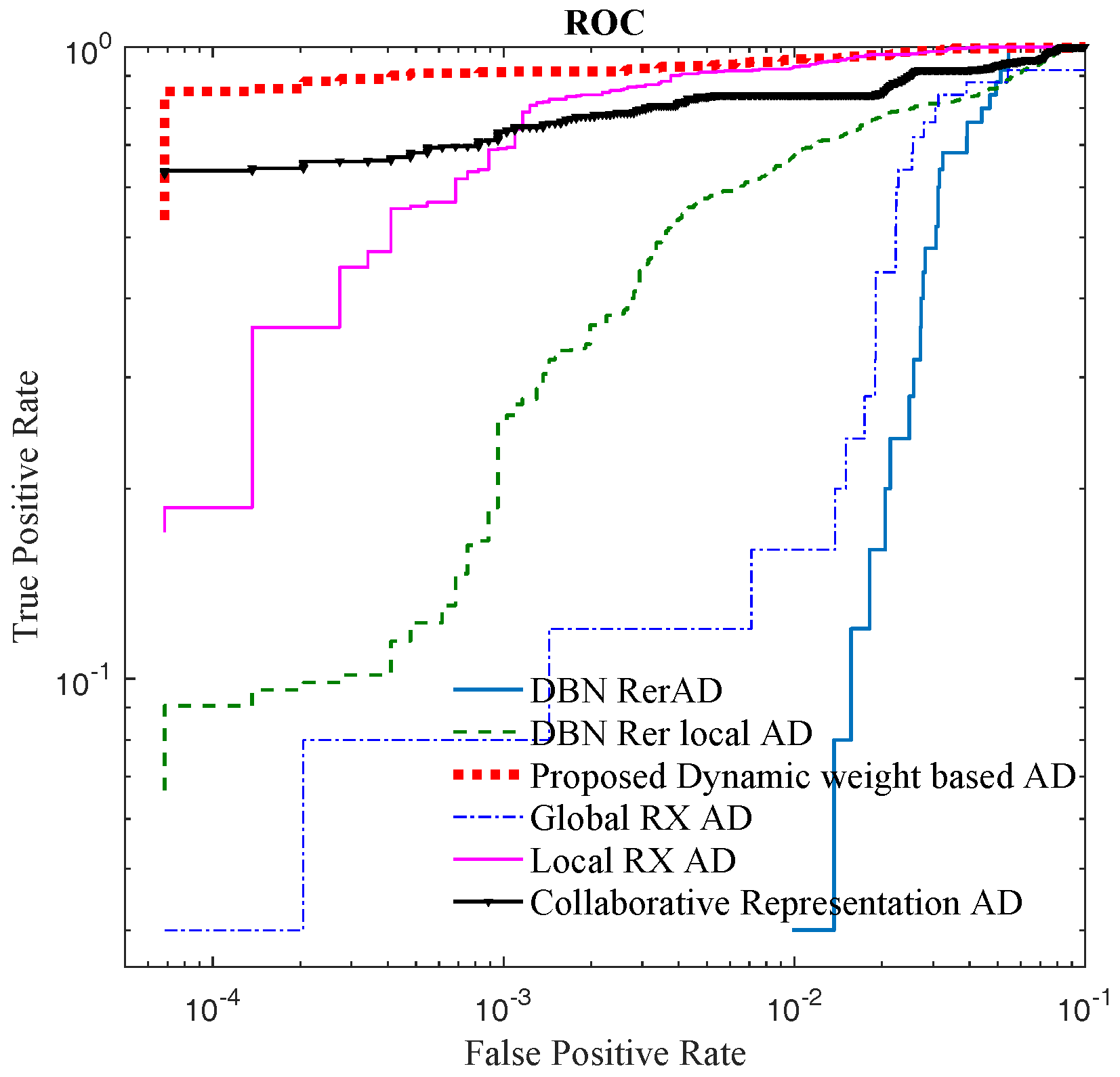
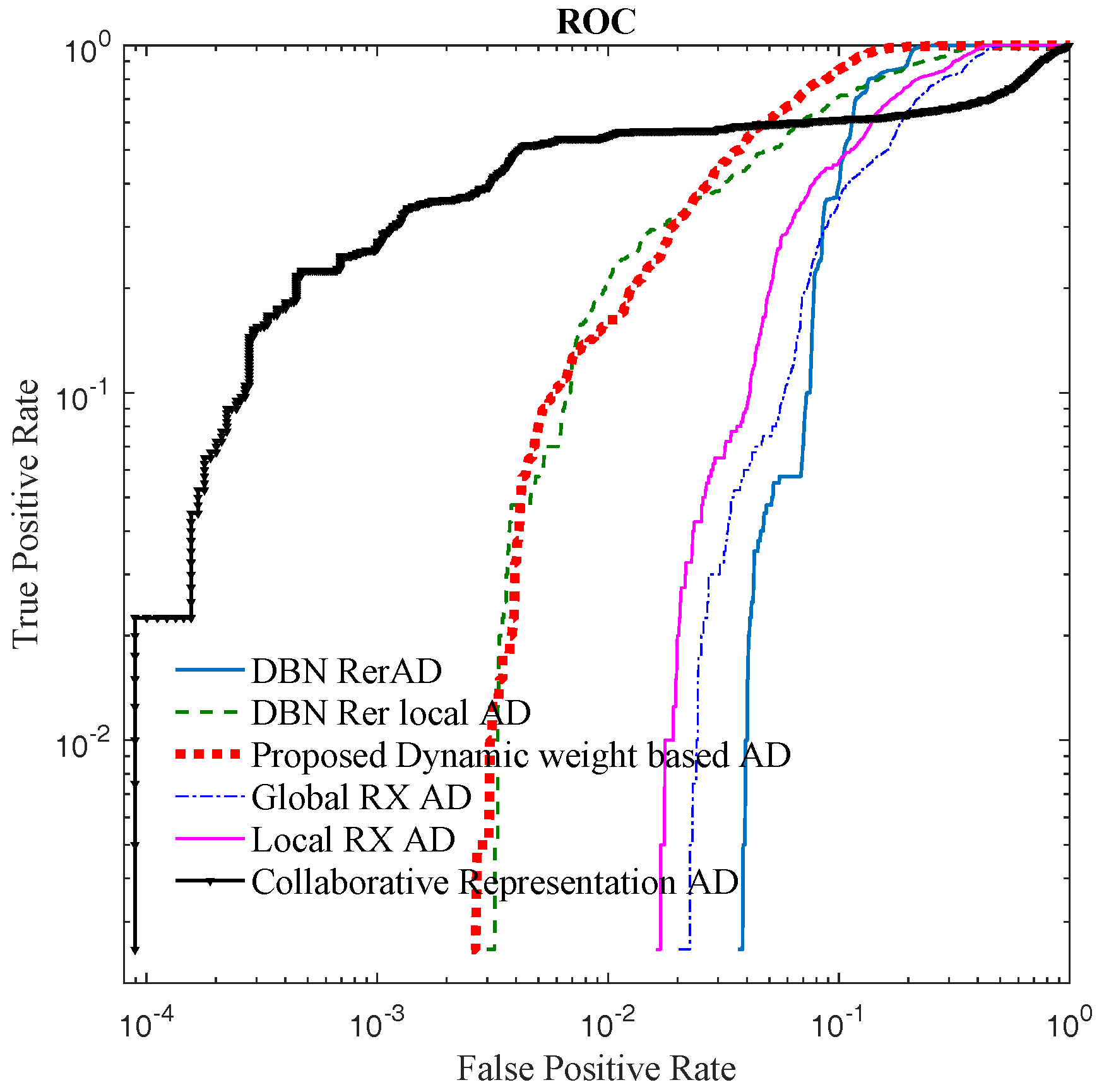
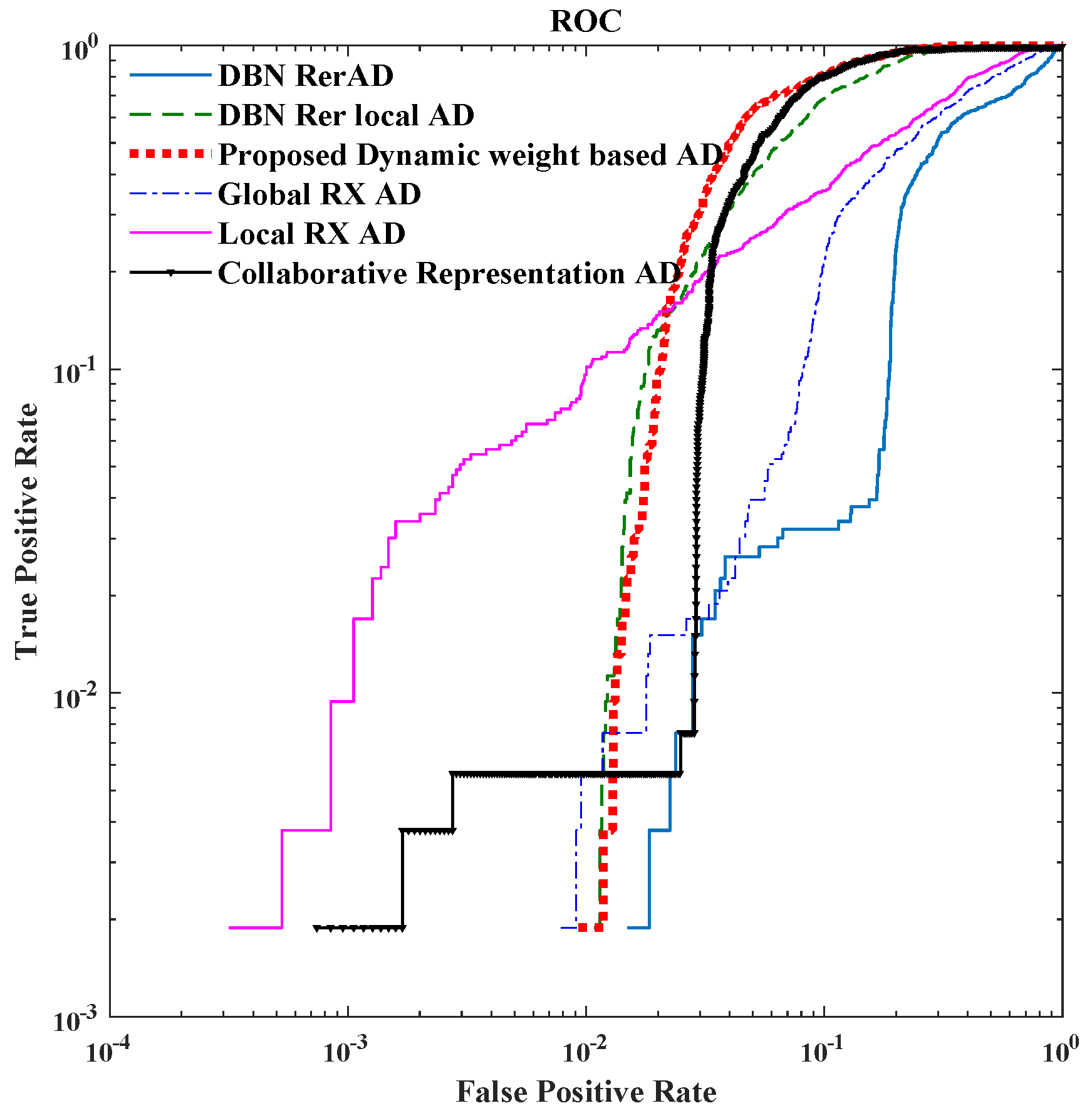
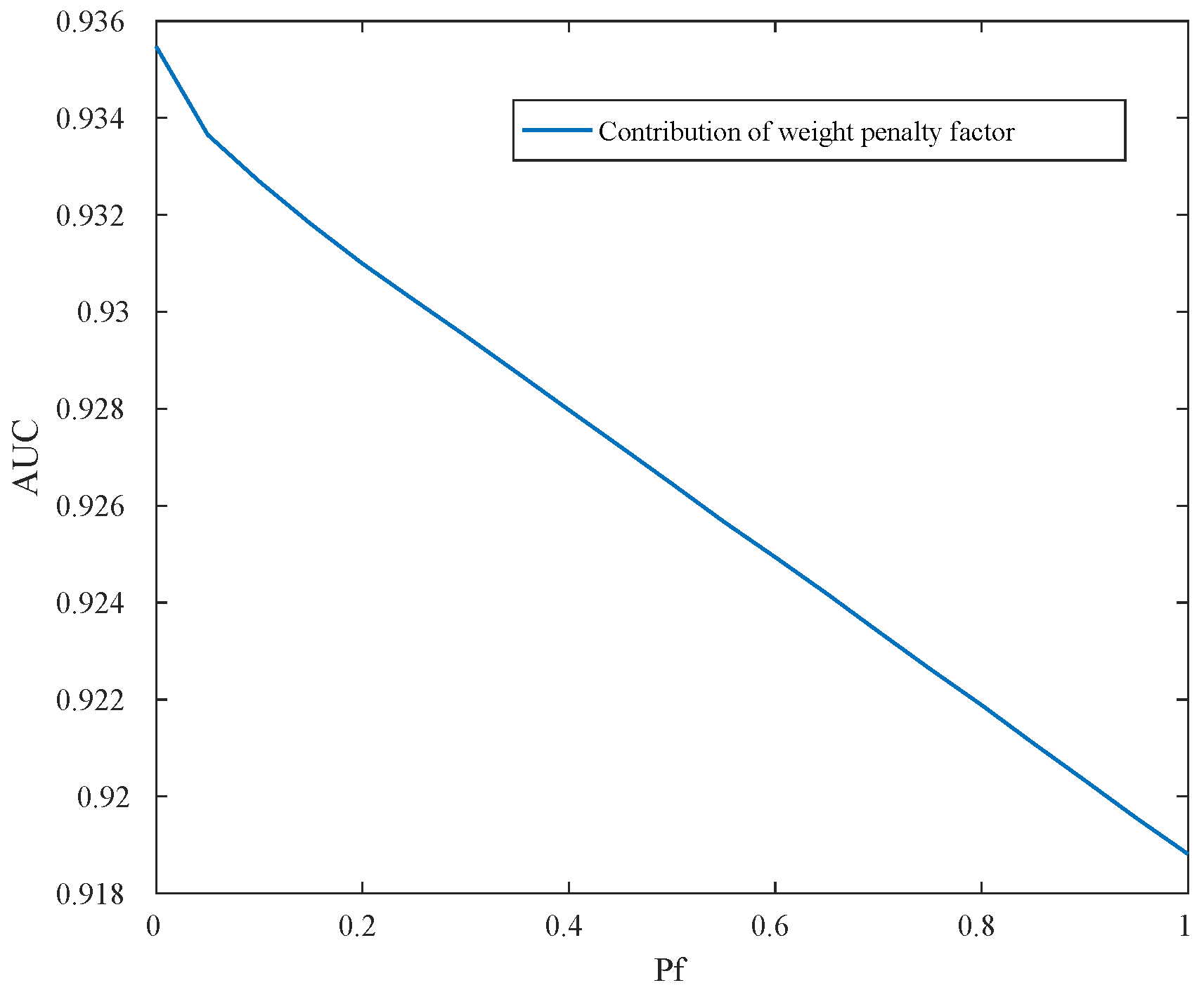
4.3. Results and Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| AD | Anomaly Detector |
| AUC | Area Under the ROC Curves |
| AVIRIS | Airborne Visible Infrared Imaging Spectrometer |
| CRD | Collaborative Representation Detector |
| DBN | Deep Belief Network |
| FPR | False Positive Rate |
| HSI | Hyperspectral Image |
| LRXD | Local RX Detector |
| ROC | Receiver Operating Characteristic Curve |
| RXD | Reed-Xiaoli Detector |
| TPR | True Positive Rate |
References
- Matteoli, S.; Diani, M.; Corsini, G. A tutorial overview of anomaly detection in hyperspectral images. IEEE Aeros. Electr. Syst. Mag. 2010, 25, 5–28. [Google Scholar] [CrossRef]
- Stein, D.W.; Beaven, S.G.; Hoff, L.E.; Winter, E.M.; Schaum, A.P.; Stocker, A.D. Anomaly detection from hyperspectral imagery. IEEE Signal Process. Mag. 2002, 19, 58–69. [Google Scholar] [CrossRef]
- Healey, G.; Slater, D. Models and methods for automated material identification in hyperspectral imagery acquired under unknown illumination and atmospheric conditions. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2706–2717. [Google Scholar] [CrossRef]
- Robila, S.A. A class of detection filters for targets and anomalies in multispectral/hyperspectral imagery. In Proceedings of the 2006 Conference on Computer Vision and Pattern Recognition Workshop (CVPRW’06), New York, NY, USA, 17–22 June 2006; pp. 132–132. [Google Scholar]
- Hunt, B.; Cannon, T. Nonstationary assumptions for Gaussian models of images. IEEE Trans. Syst. Man Cybern. 1976, 6, 876–881. [Google Scholar]
- Reed, I.S.; Yu, X. Adaptive multiple-band CFAR detection of an optical pattern with unknown spectral distribution. IEEE Trans. Acoust. Speech Signal Process 1990, 38, 1760–1770. [Google Scholar] [CrossRef]
- Zhao, C.; Wang, Y.; Qi, B.; Wang, J. Global and local real-time anomaly detectors for hyperspectral remote sensing imagery. Remote Sens. 2015, 7, 3966–3985. [Google Scholar] [CrossRef]
- Chang, C.I.; Chiang, S.S. Anomaly detection and classification for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2002, 40, 1314–1325. [Google Scholar] [CrossRef]
- Kwon, H.; Nasrabadi, N.M. Kernel RX-algorithm: A nonlinear anomaly detector for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2005, 43, 388–397. [Google Scholar] [CrossRef]
- Guo, Q.; Zhang, B.; Ran, Q.; Gao, L.; Li, J.; Plaza, A. Weighted-RXD and linear filter-based RXD: Improving background statistics estimation for anomaly detection in hyperspectral imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2351–2366. [Google Scholar] [CrossRef]
- Taitano, Y.P.; Geier, B.A.; Bauer, K.W. A locally adaptable iterative RX detector. EURASIP J. Adv. Signal Process. 2010, 2010, 341908. [Google Scholar] [CrossRef]
- Banerjee, A.; Burlina, P.; Diehl, C. A support vector method for anomaly detection in hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2282–2291. [Google Scholar] [CrossRef]
- Khazai, S.; Homayouni, S.; Safari, A.; Mojaradi, B. Anomaly detection in hyperspectral images based on an adaptive support vector method. IEEE Geosci. Remote Sens. Lett. 2011, 8, 646–650. [Google Scholar] [CrossRef]
- Yuan, Z.; Sun, H.; Ji, K.; Li, Z.; Zou, H. Local sparsity divergence for hyperspectral anomaly detection. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1697–1701. [Google Scholar] [CrossRef]
- Cheng, B.; Zhao, C.; Zhang, L. An anomaly detection algorithm for hyperspectral images using subspace sparse representation. J. Harbin Eng. Univ. 2017, 38, 640–645. [Google Scholar]
- Li, W.; Du, Q. Collaborative representation for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1463–1474. [Google Scholar] [CrossRef]
- Basener, B.; Ientilucci, E.J.; Messinger, D.W. Anomaly detection using topology. In Proceedings of the Defense and Security Symposium. International Society for Optics and Photonics, Orlando, FL, USA, 9–12 April 2007; p. 65650J. [Google Scholar]
- Messinger, D.W.; Albano, J. A graph theoretic approach to anomaly detection in hyperspectral imagery. In Proceedings of the 2011 3rd Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Lisbon, Portugal, 6–9 June 2011; pp. 1–4. [Google Scholar]
- Olson, C.; Coyle, M.; Doster, T. A study of anomaly detection performance as a function of relative spectral abundances for graph-and statistics-based detection algorithms. In Proceedings of the Algorithms and Technologies for Multispectral, Hyperspectral, and Ultraspectral Imagery XXIII, Anaheim, CA, USA, 9 April 2017; Volume 10198, pp. 1–12. [Google Scholar]
- Bachmann, C.M.; Ainsworth, T.L.; Fusina, R.A. Exploiting manifold geometry in hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2005, 43, 441–454. [Google Scholar] [CrossRef]
- Olson, C.; Judd, K.; Nichols, J. Manifold learning techniques for unsupervised anomaly detection. Expert Syst. Appl. 2018, 91, 374–385. [Google Scholar] [CrossRef]
- Hoffmann, H. Kernel PCA for novelty detection. Pattern Recognit. 2007, 40, 863–874. [Google Scholar] [CrossRef]
- Ziemann, A.K.; Messinger, D.W. An adaptive locally linear embedding manifold learning approach for hyperspectral target detection. In Proceedings of the Algorithms and Technologies for Multispectral, Hyperspectral, and Ultraspectral Imagery XXI, Baltimore, MD, USA, 21 May 2015; Volume 9472, pp. 1–15. [Google Scholar]
- Ziemann, A.K.; Theiler, J.; Messinger, D.W. Hyperspectral target detection using manifold learning and multiple target spectra. In Proceedings of the Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 13–15 October 2015; pp. 1–7. [Google Scholar]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Zhao, C.; Li, X.; Zhu, H. Hyperspectral anomaly detection based on stacked denoising autoencoders. J. Appl. Remote Sens. 2017, 11, 1–19. [Google Scholar] [CrossRef]
- Erfani, S.M.; Rajasegarar, S.; Karunasekera, S.; Leckie, C. High-dimensional and large-scale anomaly detection using a linear one-class SVM with deep learning. Pattern Recognit. 2016, 58, 121–134. [Google Scholar] [CrossRef]
- Liu, Q.; Zhou, F.; Hang, R.; Yuan, X. Bidirectional-Convolutional LSTM Based Spectral-Spatial Feature Learning for Hyperspectral Image Classification. arXiv, 2017; arXiv:1703.07910. [Google Scholar]
- Xiong, Y.; Zuo, R. Recognition of geochemical anomalies using a deep autoencoder network. Comput. Geosci. 2016, 86, 75–82. [Google Scholar] [CrossRef]
- Ma, N.; Wang, S.; Yu, J.; Peng, Y. A DBN based anomaly targets detector for HSI. In Proceedings of the AOPC 2017: 3D Measurement Technology for Intelligent Manufacturing. International Society for Optics and Photonics, Beijing, China, 4–6 June 2017; Volume 10458. [Google Scholar]
- Li, W.; Wu, G.; Du, Q. Transferred Deep Learning for Anomaly Detection in Hyperspectral Imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 597–601. [Google Scholar] [CrossRef]
- Boureau, Y.L.; Cun, Y.L. Sparse feature learning for deep belief networks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 1185–1192. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y. Learning Deep Architectures for AI; Foundations and Trends® in Machine Learning; Now Publishers Inc.: Hanover, MA, USA, 2009; Volume 2, pp. 1–127. [Google Scholar]
- Deng, L.; Yu, D. Deep Learning: Methods and Applications; Foundations and Trends® in Signal Processing; Now Publishers Inc.: Hanover, MA, USA, 2014; Volume 7, pp. 197–387. [Google Scholar]
- Larochelle, H.; Erhan, D.; Courville, A.; Bergstra, J.; Bengio, Y. An empirical evaluation of deep architectures on problems with many factors of variation. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; ACM: New York, NY, USA, 2007; pp. 473–480. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Senior, A.; Heigold, G.; Yang, K.; Ranzato, M. An empirical study of learning rates in deep neural networks for speech recognition. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 6724–6728. [Google Scholar]
- Schaul, T.; Zhang, S.; LeCun, Y. No more pesky learning rates. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 343–351. [Google Scholar]
- Green, R.O.; Eastwood, M.L.; Sarture, C.M.; Chrien, T.G.; Aronsson, M.; Chippendale, B.J.; Faust, J.A.; Pavri, B.E.; Chovit, C.J.; Solis, M.; et al. Imaging spectroscopy and the airborne visible/infrared imaging spectrometer (AVIRIS). Remote Sens. Environ. 1998, 65, 227–248. [Google Scholar] [CrossRef]
- Gao, B.C.; Heidebrecht, K.B.; Goetz, A.F. Derivation of scaled surface reflectances from AVIRIS data. Remote Sens. Environ. 1993, 44, 165–178. [Google Scholar] [CrossRef]
- Rodger, A.; Lynch, M.J. Determining atmospheric column water vapour in the 0.4–2.5 μm spectral region. In Proceedings of the AVIRIS Workshop; Available online: https://aviris.jpl.nasa.gov/proceedings/workshops/01_docs/2001Rodger_web.pdf (accessed on 18 October 2017).
- Curran, P.J.; Dungan, J.L. Estimation of signal-to-noise: A new procedure applied to AVIRIS data. IEEE Trans. Geosci. Remote Sens. 1989, 27, 620–628. [Google Scholar] [CrossRef]
- Zhang, L.; Peng, B.; Zhang, F.; Wang, L.; Zhang, H.; Zhang, P.; Tong, Q. Fast real-time causal linewise progressive hyperspectral anomaly detection via cholesky decomposition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4614–4629. [Google Scholar] [CrossRef]
- Zhao, R.; Zhang, L. GSEAD: Graphical Scoring Estimation for Hyperspectral Anomaly Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 725–739. [Google Scholar] [CrossRef]
- Zhao, C.; Deng, W.; Yan, Y.; Yao, X. Progressive line processing of kernel RX anomaly detection algorithm for hyperspectral imagery. Sensors 2017, 17, 1815. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.I. Multiparameter receiver operating characteristic analysis for signal detection and classification. IEEE Sens. J. 2010, 10, 423–442. [Google Scholar] [CrossRef]
- Borghys, D.; Kåsen, I.; Achard, V.; Perneel, C. Hyperspectral anomaly detection: Comparative evaluation in scenes with diverse complexity. J. Electr. Comput. Eng. 2012, 2012, 1–16. [Google Scholar] [CrossRef]
- Gorelnik, N.; Yehudai, H.; Rotman, S.R. Anomaly detection in non-stationary backgrounds. In Proceedings of the 2010 2nd Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Reykjavik, Iceland, 14–16 June 2010; pp. 1–4. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distance Name | Expected Trend | Distance Type | Weight | Distance Type | Weight |
|---|---|---|---|---|---|
| in Equation (8a) | △ | - | - | ||
| in Equation (8b) | △ | ||||
| in Equation (8c) | ▽ | - | - | ||
| in Equation (8d) | ▽ | ||||
| in Equation (8e) | ▽ |
| Dataset Name | Window Size of Proposed Detector & DBA-LAD | Window Size of LRXD | Window Size of CRD |
|---|---|---|---|
| San Diego airport | outer window: , inner window: | ||
| Lake Salvador | outer window: , inner window: | ||
| San Jose | outer window: , inner window: |
| Method | AUC Value | Detection Time (s) | Training Times (s) |
|---|---|---|---|
| Proposed adaptive weight DBN Detector | 0.998 | 19.510 | 3.812 |
| Local Reed-Xiaoli Detector [7] | 0.998 | 66.455 | - |
| Collaborative Representation Detector [16] | 0.993 | 41.174 | - |
| DBN local reconstruction errors Detector | 0.985 | 3.361 | 3.812 |
| Global Reed-Xiaoli Detector [6] | 0.972 | 0.306 | - |
| DBN-AD [30] | 0.968 | 0.435 | 3.812 |
| Method | AUC Value | Detection Time (s) | Training Times (s) |
|---|---|---|---|
| Proposed adaptive weight DBN Detector | 0.949 | 26.424 | 13.278 |
| DBN local reconstruction errors Detector | 0.915 | 8.722 | 13.278 |
| DBN-AD [30] | 0.885 | 0.143 | 13.278 |
| Local Reed-Xiaoli Detector [7] | 0.858 | 284.978 | - |
| Global Reed-Xiaoli Detector [6] | 0.820 | 1.423 | - |
| Collaborative Representation Detector [16] | 0.762 | 558.823 | - |
| Method | AUC Value | Detection Time (s) | Training Times (s) |
|---|---|---|---|
| Proposed adaptive weight DBN Detector | 0.935 | 2.483 | 3.58 |
| Collaborative Representation Detector [16] | 0.917 | 34.380 | - |
| DBN local reconstruction errors Detector | 0.907 | 1.511 | 3.58 |
| DBN-AD [30] | 0.870 | 0.985 | 3.58 |
| Local Reed-Xiaoli Detector [7] | 0.776 | 26.682 | - |
| Global Reed-Xiaoli Detector [6] | 0.698 | 0.150 | - |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, N.; Peng, Y.; Wang, S.; Leong, P.H.W. An Unsupervised Deep Hyperspectral Anomaly Detector. Sensors 2018, 18, 693. https://doi.org/10.3390/s18030693
Ma N, Peng Y, Wang S, Leong PHW. An Unsupervised Deep Hyperspectral Anomaly Detector. Sensors. 2018; 18(3):693. https://doi.org/10.3390/s18030693
Chicago/Turabian StyleMa, Ning, Yu Peng, Shaojun Wang, and Philip H. W. Leong. 2018. "An Unsupervised Deep Hyperspectral Anomaly Detector" Sensors 18, no. 3: 693. https://doi.org/10.3390/s18030693
APA StyleMa, N., Peng, Y., Wang, S., & Leong, P. H. W. (2018). An Unsupervised Deep Hyperspectral Anomaly Detector. Sensors, 18(3), 693. https://doi.org/10.3390/s18030693